基于CPM及亲和度向量的服装关键点检测方法
2022-04-25汤启凡何儒汉
汤启凡,黄 晋,何儒汉,彭 涛,陈 佳
(1.纺织服装智能化湖北省工程研究中心 湖北 武汉 430200;2.武汉纺织大学 计算机与人工智能学院 湖北 武汉 430200;3.湖北省服装信息化工程技术研究中心 湖北 武汉 430200)
0 引言
随着服装网购的迅速发展,消费者可以便捷地选购服饰,同时也对服装样式提出了个性化的需求。为了尽可能准确地描述并展示在消费者面前各种款式的服装姿态,现有的方法主要是利用服装关键点对服装进行定位,然后连接所有关键点以确定服装的大致轮廓[1]。服装关键点的定位是一项基础性的工作,能够推动在线试衣、服饰部位对齐、服饰局部属性识别、服饰图像自动编辑等应用[2]。
与人体关键点检测相比,服装关键点检测有其自身的特殊性。首先类别作为服装重要的属性,影响着关键点的数量和关键点的空间分布。例如连衣裙的关键点数量为15个,分布在连衣裙的肩部、腰部等位置。裤子的关键点数量为7个,分布在裤脚等位置。在关键点数量和分布上,连衣裙和裤子存在明显的差别;相同类别服装在款式设计上也存在差异,且柔性的服装容易受外部因素的影响而发生较大的形变;在真实环境中服装可能部分被遮挡,这会破坏了服装的完整性,直接改变了服装关键点的个数和分布;服装在展示时可能出现多个部位重叠,这会导致多个关键点重合或聚集。
本文针对服装关键点检测难点,借鉴人体关键点检测方法,提出了一个两阶段的检测方法。首先,Faster RCNN能够确定服装的类别和目标区域,旨在缩小关键点检测的范围,降低复杂背景的干扰。通过类别属性确定服装关键点的数量和空间分布,减小由于关键点数量不定对检测的影响。其次,借鉴并改进人体关键点检测方法,同时采用亲和度向量对服装关键点信息建模,实现相邻点间相对距离和相对角度约束,该模型对多类别服装的形变、部分遮挡等都具有较强鲁棒性,能更准确地提取关键点特征。
本文贡献如下:
1) 提出了一种两阶段服装关键点检测模型,将服装的类别属性和边界框信息作为先验信息[3]加入到服装关键点检测中。不仅有效缩小了检测的范围,并根据服装类别确定服装关键点的空间分布。
2) 根据服装关键点位置分布不定的特点改进原有的CPM网络,加入空洞卷积以增大感受野,使单张特征图[4]上包含更多关键点信息,获得更多有效特征。同时使用中间监督机制,加快模型的训练。
3) 提出了一种基于亲和度向量的关键点检测方法,定义了服装相邻关键点的亲和度向量。依据相邻关键点之间的空间相关性,建立相邻点间相对距离和相对角度约束,不仅可以防止检测中遗漏关键点,还可以有效解决关键点的分散性、背景复杂、遮挡等难题。
1 相关工作
1.1 人体关键点检测
现有人体关键点检测的研究主要集中在提取关键点位置信息和消除复杂背景影响两个方向。针对关键点位置信息的提取,Wei[5]等综合考虑了关键点的位置特征和空间分布信息,引入关键点之间空间依赖的热图来表达关键点信息,提出了人体关键点检测任务的通用方法卷积姿态机(convolution pose machines,CPM),该方法在多个数据集上精确度最高。同年,Newell[6]等采用沙漏型结构先降采样后上采样的方式提出SHN(stacked Hourglass network)网络进行人体关键点的检测。上采样使用最近邻插值和反卷积[7]的方式,使网络输出的特征图有较高分辨率和较大的感受野。该方法能有效防止关键点信息丢失,在MPII数据集姿态分析中获得最优效果。
针对复杂背景影响的问题,研究者提出了关键点位置信息关联和关键点位置局部调整的方法。在基于关键点位置信息关联的方法中,Cao等采用bottom-up的模式对人体关键点进行检测[8],引入亲和度向量场(part affinity fields,PAF)来确定各个关键点的连接关系。该方法较好地解决了关键点只有位置编码,没有方向编码的问题,对遮挡、重叠等问题有较强的鲁棒性。在基于关键点位置局部调整的方法中,Chen等针对人体关键点不可见和复杂背景下检测误差大的问题提出了级联金字塔网络(cascaded pyramid network,CPN)[9]。该方法可以提取更加丰富的语义信息,但随着网络模型复杂化,更多的参数将导致检测效率的降低。
1.2 服装关键点检测
随着时尚行业的迅速发展,服装姿态估计和服装关键点检测也成为计算机视觉的重要研究方向。由于服装具有款式多样、姿态多变的特点,导致服装关键点检测比人体关键点检测更加复杂。Liu等通过多任务复合网络FashionNet联合预测服装类别和关键点位置[10]。Yan等提出了一种DLAN网络[11],该方法通过不同尺度特征空间的转换器,建立高层特征图和原图的映射,旨在消除复杂背景的影响。在服装关键点数量少且数量不变时可以完成检测,但当服装类别增加时准确度会明显降低。Yu等为了解决服装关键点不规则分布导致的关键点位置特征难以提取的问题[12],将提取到的关键点特征映射为结构化的图节点,然后根据图节点的位置变化推理出关键点的位置,最后将图节点位置映射回特征空间。该方法可以有效地增强关键点的特征,但该方法对图节点位置变化趋势的预测受很多因素的影响,模型训练时需要有更大的数据量。李维乾等为了更准确地提取关键点位置信息,提出了CSPN(cascaded stacked pyramid network)模型[13]。该方法在Deepfashion数据集下检测效果较好,但未考虑服装类别对关键点检测的影响,仅对关键点数量不变的情况具有鲁棒性。Wang等为了在服装关键点检测中加入先验知识来引导关键点位置的变化[14],提出了卷积递归神经网络(bidirectional convolutional recurrent neural networks,BCRNNs)。该方法根据人体运动学和服装对称性的原理,对服装关键点建立拓扑结构以增强关键点之间的联系。其方法具有一定的有效性,但柔性的服装与人体运动变化有一定的差异,且服装的对称性难以保证。
已有的服装关键点检测方法未能很好地解决服装姿态变化多、易受环境影响的问题,受亲和度向量场的启发,根据服装关键点虽分布范围广,但相邻关键点空间位置相近且相互约束的特点,本文提出具有广泛应用性的基于CPM及亲和度向量的两阶段服装关键点检测模型。该方法运用亲和度向量将服装关键点两两相连,不仅加强空间位置相近的相邻点的联系,同时,间接地将所有关键点形成一个整体,使得远距离的点也产生了联系。
2 基于CPM及亲和度向量的两阶段服装关键点检测方法
2.1 两阶段服装关键点检测方法架构
本文提出的基于CPM及亲和度向量的两阶段服装关键点检测模型如图1所示,该方法将目标分类和回归检测两个部分相结合。第一阶段利用Faster RCNN获得原图像中服装的位置和类别。第二阶段将处理后的服装图像送入关键点检测器中,检测器根据服装类别所确定的关键点数量和空间位置选择检测网络。

图1 关键点检测流程图Figure 1 Key point detection flow chart
2.2 基于CPM及亲和度向量的关键点检测器
2.2.1亲和度向量 虽然服装关键点存在分散性、背景复杂等特点,导致特征难以提取、信息易丢失,但点与点之间相互依赖、相互约束,相邻关键点之间存在自相关性。本文对相邻关键点的相对位置信息进行抽象,利用亲和度向量将离散的关键点按序有向连接,旨在提高相邻关键点的相互约束,形成点与点之间的传递链,使所有服装关键点形成一个整体,以此来适应服装复杂的变化。
本文定义亲和度向量用于表示相邻服装关键点的相对位置关系,如图2(a)所示。关键点个数为6个,点Xj、Xk为相邻关键点坐标,图2(c)中亲和度向量Xk-Xj的长度d=|Xk-Xj|,方向为Xj指向Xk,与水平线的夹角为θ。如图2(b)为网络训练过程中的亲和度向量,节点表示预测的关键点,节点上的值表示预测点的置信值。

图2 亲和度向量Figure 2 Affinity vector
亲和度向量在模型训练过程中通过相邻点的距离和向量角度计算,经过网络不断学习优化,逐步缩小距离偏差Δd和角度偏差Δθ。如图2(d)所示为预测亲和度向量与真实亲和度向量,其中距离偏差Δd=‖Xk-Xj|-|xk-xj‖,角度偏差Δθ=|θk-θj|。
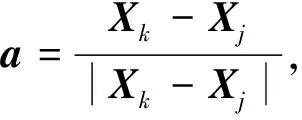

2.2.2关键点检测网络 第二阶段在已知服装类别和服装位置的情况下进行关键点检测。关键点检测器中包含多个检测网络,每个检测网络只对一种类别服装进行检测。检测网络应具有以下特点。
1) 为了加快检测的速度,减少参数的数量,每个单独的网络结构不能过于复杂。
2) 在关键点回归时,低像素的特征图有更丰富的语义信息[15],检测网络应具有较好的特征提取能力。
3) 关键点之间存在着或近或远的关系,检测网络要有足够大的感受野[16],不能丢失重要信息。
因此模型选用CPM分阶段重复地提取特征,每个阶段都采用相对简单的网络结构。经过多阶段持续地对关键点位置信息进行加强,调整关键点的置信值,从而极大地提高检测的精度。本文对CPM网络进行如下改进。
1) 在每个阶段的中间加入特征融合,充分提取关键点特征且防止信息丢失。每个阶段之间加入中间监督,防止反向传播的梯度随着过多层传播而消失。
2) 网络中加入空洞卷积来增大感受野,旨在尽可能保留关键点之间的空间位置信息。
2.3 关键点空间位置和损失函数
2.3.1关键点空间位置 为了更好地描述关键点之间的空间位置关系,本文采用高斯热图的方式描述关键点的坐标信息。热图中每个坐标点上的数值对应的是置信值,置信值越大就越有可能是关键点,数值的大小同时也反映了关键点之间的联系,越靠近关键点的点在热图上对应坐标点上的置信值越大,置信值服从高斯分布。关键点坐标对应的置信值计算为
其中:(x0,y0)代表置信值为1的关键点坐标;(x,y)为热图上除关键点外的其他坐标点;bv为热图上坐标点(x,y)上对应的置信值。
2.3.2损失函数 模型在定义损失函数时对CPM每个阶段输出的热图和亲和度向量都有一次损失。损失函数主要由3个部分组成,关键点检测网络每个阶段输出的热图与标签热图的偏差(L2损失)、相邻点预测距离与相邻点真实距离的偏差Δd、亲和度向量的方向与真实方向的偏差Δθ,损失函数L计算为
其中:α=0.5,β=0.3,γ=0.2为权重;C=256为亲和度向量长度归一化常量;a为阶段数,共有6个阶段;n为关键点个数,根据不同类别的服装确定;Yj表示第j个真实关键点坐标生成的单张热点图;Hij表示在网络训练过程中第i阶段输出的第j个关键点对应的热图;Xj表示第j个真实关键点坐标;Xk表示Xj的相邻关键点坐标;Xk-Xj表示真实相邻坐标点的亲和度向量;xj表示在模型训练过程中预测的第j个关键点坐标;xk表示xj的相邻关键点坐标;xk-xj表示模型预测的相邻关键点亲和度向量。
3 实验
3.1 数据集
本文实验选取2018 FashionAI服装关键点定位数据集,共有76 866个样本,服装图片被分为5大类,分别为外套、上衣、裤子、连衣裙、半身裙。服装关键点的个数和空间位置由类别决定,图3为不同类别服装的关键点位置和数量。

图3 服装数据集Figure 3 Clothing dataset
3.2 实验参数和评价指标
3.2.1实验参数 本文实验在Ubuntu16.04系统下的tensorflow1.13环境中完成。第一阶段,使用了预训练模型,在已经训练好的模型基础上继续进行训练,输入的原图大小为224×224像素,batch_size为16。第二阶段,为了提高模型的精度,加快损失的收敛,实验采用学习率下降的策略。初始的学习率为0.001,每经过1 000个batch下降一次。
3.2.2评价指标 本文实验选择归一化误差率(normalized error,NE)作为评价指标,
式中:k为关键点编号;dk为预测关键点和标注关键点的距离;sk为距离的归一化参数;vk表示关键点是否可见,vk=1表示只考虑可见的关键点。NE值越小表示关键点平均误差越小,预测值越接近真实值。
3.3 实验结果与分析
为了验证本文提出的方法在服装关键点检测上的有效性和优越性,在测试时选取了6 000张不同类型的服装,比较不同方法的NE值。
3.3.1目标检测和分类模块的有效性 为了验证模型第一阶段目标检测和分类模块的有效性,实验比较了不同网络在加入目标检测和分类模块前、后对检测精确度的影响,如图4所示。可见加入目标检测和分类模块后的各个模型的误差都有一定程度的减小。该模块不仅缩小了网络检测的范围,同时,通过类别属性确定关键点的数量和分布,有效地提高了检测的准确率。

图4 目标检测模块对关键点检测的影响Figure 4 Influence of target detection
接下来深入分析不同网络加入亲和度向量前后检测误差的变化,亲和度向量对不同类别服装检测的影响。后续实验建立在第一阶段的基础上。
3.3.2亲和度向量对关键点检测的适用性 图5展示了不同模型加入亲和度向量前、后NE值的变化,可见加入亲和度向量后所有网络模型的检测误差有所减小。其中CPN原模型的检测效果优于CPM,在加入亲和度向量后,CPM模型的检测效果有明显的提升,与CPN模型的效果相差不大。由于CPN网络过于复杂、参数过多,在预测关键点位置时效率低,所以本文选择CPM作为基础网络。表1比较了不同模型的参数量、计算量、检测16张图片的速度。可见,本文方法相对于CPN方法参数量和计算量减小,检测速度有明显的提升。
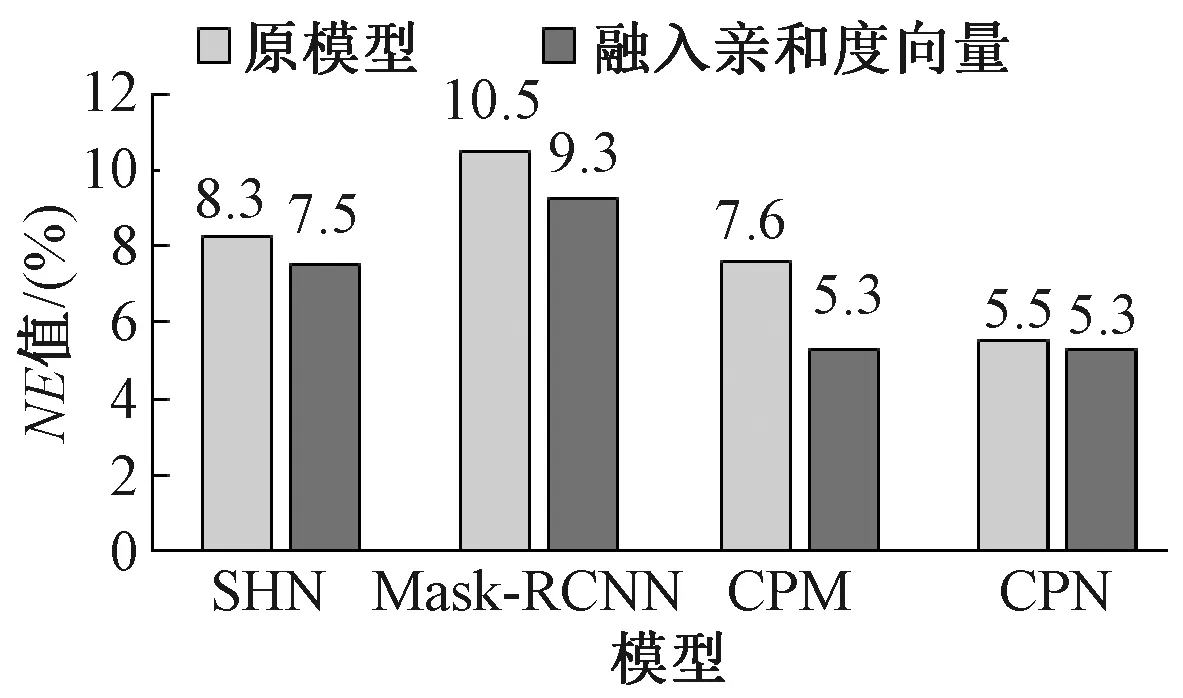
图5 亲和度向量对检测的影响Figure 5 Influence of affinity vector on detection
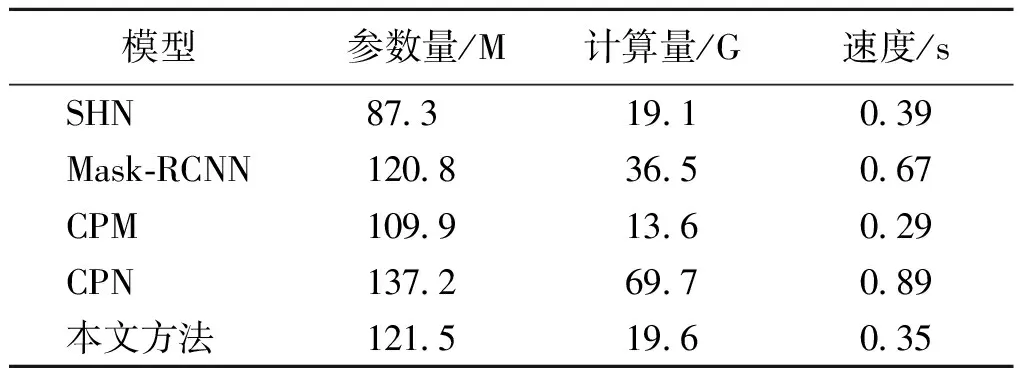
表1 不同模型参数量和效率Table 1 The models′ parameter and efficiency
图6对比了不同类别服装加入亲和度向量前、后NE值,可见,亲和度向量可以大幅提高连衣裙、外套、裤子3个类别服装关键点检测的精确度。在检测过程中,关键点的数量和分布是影响检测精度的重要因素。亲和度向量对连衣裙、外套、裤子三种类别更有效的原因是亲和度向量更加适用于关键点数量多、相邻点距离远的服装类别。
3.3.3对比实验 为了具体地比较不同方法的检测效果,本文利用不同方法在单一类别服装中检测,检测结果NE值如表2所示。
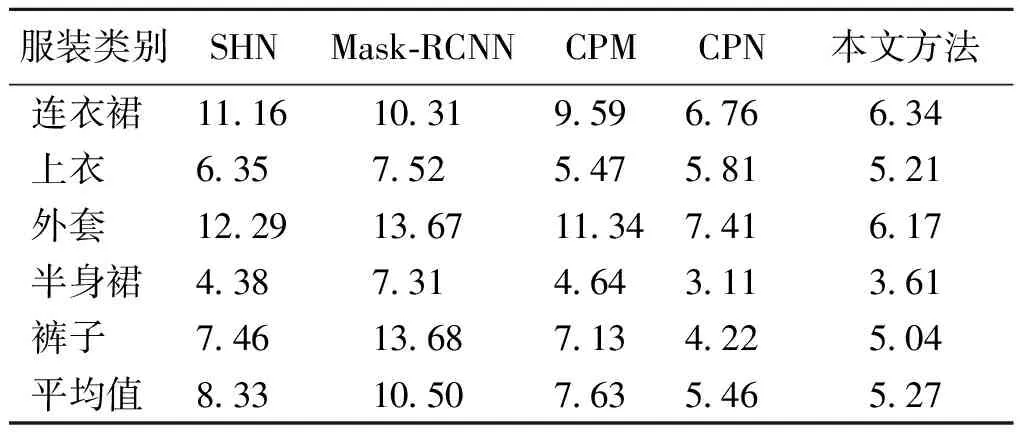
表2 不同模型在单类服装下检测的NE值Table 2 The NE value of single clothing with different models 单位:%
从表2中可以看出,本文方法预测的各类服装关键点NE值的平均值最小,预测值最接近真实值,在复杂服装类别上(例如外套)明显地提高了预测的精确度,说明本文方法能更好地提取单一类别服装关键点的特征,保留更多的关键点之间的关联信息。在与CPN模型对比中,半身裙和裤子两个类别CPN模型更优,可能的原因是这两个类别的关键点数量少,CPN网络模型较为复杂,在特征提取方面有一定的优势。
如图7所示为不同模型在不同迭代次数下对不同类别服装检测的平均NE值变化。可以明显发现,本文方法在训练过程中关键点检测的平均NE值优于其他方法。

图7 不同模型平均NE值Figure 7 NE value with different models
完成对单一类别服装预测后,证明了本文方法的有效性,然后将模型在混合类别服装中进行训练。表3为不同模型在混合类别服装测试集中检测的NE值。

表3 混合类别服装在不同模型下检测的NE值Table 3 NE value of mixed category clothing with different models 单位:%
由表2与表3对比可知,不同方法对单一类别和混合类别服装的检测中,类别对服装关键点检测有较大影响,对服装关键点进行检测时融入类别信息能有效地减小类别对服装关键点检测精度的影响。本文所提基于亲和度向量的服装关键点检测方法在混合类别服装关键点检测中具有明显的优势,平均每个类别NE值比CPN网络模型降低了4.58%,对服装部分重叠、多视角、关键点密集等问题有一定的解决能力,如图8所示。

图8 复杂场景模型预测结果Figure 8 Prediction results of complex scene
图8(a)、(b)中关键点数量多时,模型利用亲和度向量将所有点连成一个整体,不会漏掉部分关键点。图8(c)中所示裤脚部分重叠,模型通过相邻关键点可以对部分点进行调整。图8(e)中模特的手将其中一个关键点挡住,模型仍然能准确地检测出来。图8(g)中关键点分布密集,模型通过增大感受野对这类服装有明显的作用。但是,模型还有需要改进的地方,如8(h)中由于裤腿重叠导致裤裆的高度变化不定甚至两条裤腿重合,导致在检测中有较大的误差。
图9为不同模型的比较,从图9可以看出,CPM、SHN、CPN、Mask-RCNN模型虽然检测出了关键点,但与真实值有较大偏离,出现漏检、错检等问题。图9中SHN方法在检测过程中将手提包误认为裤脚;由于上衣中手臂与腰身重合,Mask-RCNN方法无法准确地识别左胳肢窝的关键点,并且遗漏了裤脚的一个关键点;单独的CPM方法将脚部识别为裤脚;CPN方法对肢体遮挡关键点或肢体与关键点部分重合的问题不能较好地解决。本文方法能更好地适应复杂场景,降低由于角度、重叠等因素对检测的影响,检测结果更接近真实值。

图9 不同模型检测结果对比Figure 9 Comparison of test results of different models
4 结语
本文提出了一种基于CPM及亲和度向量的两阶段服装关键点检测方法。该方法根据服装相邻关键点空间位置分布相近的特点,采用亲和度向量表达相邻关键点的相对距离和相对角度,利用相邻关键点坐标信息对当前点进行约束,以增强相邻关键点相对位置关系。并通过所有关键点前后相连的方式,结合CPM网络实现多类别服装关键点的检测。实验结果表明,该方法对关键点数量多、相邻关键点距离远的服装类别效果明显,且可以较好地适应服装多变性,对于遮挡和重叠有一定的解决能力。但本文方法优先获得类别属性和不同类别区分检测的方式存在效率低的问题。今后的研究工作将集中在对关键点检测更加有效建模,进一步提高网络对关键点特征提取的能力,增强有效的特征并减少无效干扰信息,以提高检测的精度和速度。
