面向番茄病害识别的改进型SqueezeNet轻量级模型
2022-04-25胡玲艳汪祖民裴悦琨
胡玲艳,周 婷,许 巍,汪祖民,裴悦琨
(大连大学 信息工程学院 辽宁 大连 116622)
0 引言
近年来,气候变化、授粉者减少、植物病害等多种因素对全球粮食安全构成严重威胁[1-2],其中植物病害是导致农产品质量和数量下降的重要因素[3]。当农作物遭受病害时,其生理机能会大大下降,导致植株瘦小,无法达到最优生长状态,从而产量不高,影响农户经济效益。由于作物植株普遍较多且小,因此病害通常很难被发现,或当发现时已经扩散了很大的面积[4]。番茄是我国重要的经济作物之一,不仅富含丰富的营养物质,还可以加工成各种可食用的调味品。随着番茄种植面积的扩大,其病害发生加剧,严重影响番茄生产[5]。因此,提高现有农田的生产力,早期发现并准确地诊断出番茄病害具有重要的研究意义。
植物病害识别是作物病害诊断和防治的基础,也是作物产量和品质的保障。在已有的研究工作中,植物病害检测技术的发展历程大致可以划分为以下阶段。第一阶段是人工识别途径。该方法依靠农民长期积累的农业知识和实践经验,凭借肉眼观察、对比来判别病害类型;或者请专家上门指导,通过烦琐的检查、测量与统计等工作,根据其经验判断病害种类[6]。这种方法耗时耗力,存在着识别速度慢、准确度低和主观性强的缺点,不能满足当前农业生产的需要[7]。第二阶段是传统机器学习识别方法。该方法实现病害识别的原理是利用特征工程提取特征,然后通过分类器进行分类识别,实现过程主要包括植物病害图像采集、预处理、分割、特征提取、分类器识别病害类别等步骤。基于机器学习的识别方法相较于传统方法有很大优势,但仍存在一些缺陷,例如数据的预处理和特征工程复杂,手工选取的特征单一,分割结果不可靠,识别准确率不高等,且识别过程仍然包含大量的人为影响因素。第三阶段是深度学习识别方法。该方法能够自动地学习有利于检测识别的黑盒特征,不需要人工参与特征的选取过程[8],实现了端到端的系统工程。
从深度学习提出至今,涌现了许多经典且功能强大的网络结构,例如AlexNet、GoogLeNet、VGG、ResNet、DenseNet、Inception等。经典的大型网络虽然在ImageNet上取得了非常好的结果,但这些网络结构复杂且参数多,对硬件要求高,通常只考虑如何提高模型泛化性能,忽略了效率问题。
近年来,在番茄病害识别的研究过程中,针对深层网络层数较多且结构复杂的问题,科研工作者将研究焦点逐步转向了轻量级网络。Durmus等[9]为实时检测发生在番茄地里的植物病害,通过实验对比了AlexNet和SqueezeNet在嵌入式芯片上的识别准确率,结果表明,在达到与AlexNet网络同等精度的情况下,SqueezeNet的参数量大大减少。Elhassouny等[10]利用Plant Village数据集训练MobileNet识别10种常见番茄病,结果表明,在手机上实现紧凑的深层卷积神经网络用于植物病害识别是可行的。
此外,为了提高番茄病害识别的准确率,李晓振等[11]引入注意力机制,将并行注意力模块与残差结构相结合构建PARNet模型,最终的识别准确率超过96%,优于VGG16、ResNet50等网络结构。由此可知,将注意力机制与神经网络子模块结合,可以提升网络的学习效率和综合性能,但目前将轻量级网络与注意力模块结合的研究较少。在实际的农业生产中,农户对移动端的病害识别需求较大,这就需要将网络轻量化,且不能影响网络对病害的识别精度。因此,本文在轻量级网络SqueezeNet的基础上进行了模型改进,简化模型结构并与注意力模块相结合,使改进的模型在保证较高准确率的同时占用较少的内存,为移动端的番茄病害识别提供了可供参考的方法。
1 改进的SqueezeNet神经网络模型
为构建一种识别番茄病害的高精度轻量化神经网络模型,对经典的轻量级网络SqueezeNet[12]的结构进行修改。一方面,改变fire模块的卷积核大小和通道数,缩减网络参数量;另一方面,在网络中引入ECA模块[13],增加对重要特征的提取,提高识别效率。
1.1 改进fire模块

图1 fire模块Figure 1 The fire module

图2 改进的fire模块Figure 2 Improved fire module
改进前,fire模块的参数量为
Nbefore=S×1×1×E+S×3×3×E=
10×S×E;
(1)
计算量为
Cbefore=S×H×W×E×1×1+S×H×
W×E×3×3=10×S×H×W×E。
(2)
改进后,fire模块的参数量为
(3)
计算量为
(4)
在SqueezeNet结构中,E=4S,因此对于改进后的fire模块,参数量和计算量均变为原模块的9/10,明显减少了网络的参数量,该方式实现了对经典模型的有效缩减。
1.2 引入ECA模块
为提升模型对病害特征的学习能力,在SqueezeNet网络中加入ECA模块。该模块是一种超轻量级的注意力模块,通过对特征通道的学习,为每个通道划分不同的注意力值,进而使网络合理地分配计算资源,最终实现在增加微小参数量的情况下,模型准确率得到明显提升。
ECA模块结构如图3所示,该模块通过全局平均池化层将输入特征图的全局信息压缩为一个具有全局感受野的通道描述符,大小为K的一维卷积从该通道描述符中获取局部通道之间的相关性,再利用Sigmoid函数根据通道间的相关性计算出各通道的注意力值,最后作用在输入的特征图上,实现对特征通道的重标定。其中,一维卷积的核大小K由通道维数的函数来自适应确定,计算公式为

图3 ECA模块结构Figure 3 ECA module structure
(5)
其中:C为通道数;odd表示向上取最近的奇数。本文取r=2,b=1,K代表了局部跨通道交互的覆盖范围。
2.3 妊娠结局 研究组产妇胎膜早破、早产、剖宫产、胎儿窘迫发生率均低于对照组,差异有统计学意义(P<0.05);研究组胎死宫内发生率略低于对照组,但差异无统计学意义(P>0.05)。见表3。
1.3 改进的SqueezeNet网络结构
将改进的fire模块与ECA模块相结合,构建改进型SqueezeNet,网络整体结构如图4所示。将病害图片输入到网络中,先经过conv层、pool层以及fire模块对疾病特征进行逐层提取,再通过ECA模块对这些提取的特征图进行学习,并判断出重要特征和无关特征,网络根据特征的重要程度合理分配计算资源,最终实现用较少的参数量获得较高的识别准确率。

图4 改进的SqueezeNet网络结构Figure 4 Improved SqueezeNet network structure
2 实验部分
2.1 数据集
本文研究的番茄病害图片来自公开数据集Plant Village[14],该数据集包括14种作物的54 309幅图片,从中选取8种番茄病害(包含健康叶片)图片进行识别,分别为健康1 591张、细菌性斑点病2 127张、早疫病1 000张、叶霉病952张、晚疫病1 909张、斑枯病1 771张、红蜘蛛损伤病1 676张以及叶斑病1 404张。这8种番茄病害图片如图5所示,可以看出,这些叶片背景简单,没有任何遮挡。

图5 番茄病害图片Figure 5 Pictures of tomato diseases
Plant Village数据集中的番茄叶片图片存在着类别间数量不均等的现象,样本数据的不均衡会导致模型无法进行充分训练,容易产生过拟合现象。此外,训练出的模型在进行预测时,会更倾向于将结果预测为训练集中样本较多的类别,从而导致少数类别的分类误差较大。为了解决数据不均衡的问题,可以利用某些机制来重构数据,从而获得一个较为均衡的数据分布[15],这个过程通常被称为数据重采样。
为了保证信息损失最小以及保留绝大多数有用信息,降低数据的不平衡度,本文对数据进行重采样处理。首先计算8种类别样本数量的平均值,然后对低于平均值的类别进行随机过采样,即通过随机复制、缩放等方式增加少数类别的数量,而高于平均值的类别不做处理,处理后的数据集包括13 736张番茄病害图片。数据重采样前后的分布情况如图6所示。重采样处理后每种疾病的数量相近,有效缓解了不同类别间样本不均衡的问题。

图6 数据重采样前后对比Figure 6 Comparison of data before and after resampling
2.2 实验细节
2.2.1模型训练环境设置 实验在服务器上进行,硬件配置为CPU(Intel Xeon E5-2620)、64G内存、GPU(NVIDIA GTX1080ti)、11G显存,并基于该硬件环境搭建了Window10操作系统。在CUDA环境下采用深度学习框架Tensorflow2.0,结合Python3.6构建神经网络模型。
为了更全面地获取模型的学习情况,将重采样后的番茄图片按照训练集、验证集、测试集为7∶2∶1的比例进行划分,训练神经网络模型。根据实验的数据总量并结合经验值,将迭代次数设置为100,训练集和验证集的批次大小设置为64,测试集的批次大小设置为128,正则化系数为0.000 5。学习率和优化器的选取通过实验确定,具体选取过程如下。
2.2.2模型超参数的选择 在训练过程中,超参数会在很大程度上影响网络的训练和识别结果。不同的网络结构因其包含的网络层数、参数量以及复杂度不同,对应的最优超参数也不尽相同。为确定模型训练的优化器,将经典优化器随机梯度下降法(SGD)和自适应矩阵估计算法(Adam)进行对比,两种优化器下模型的训练过程如图7所示。
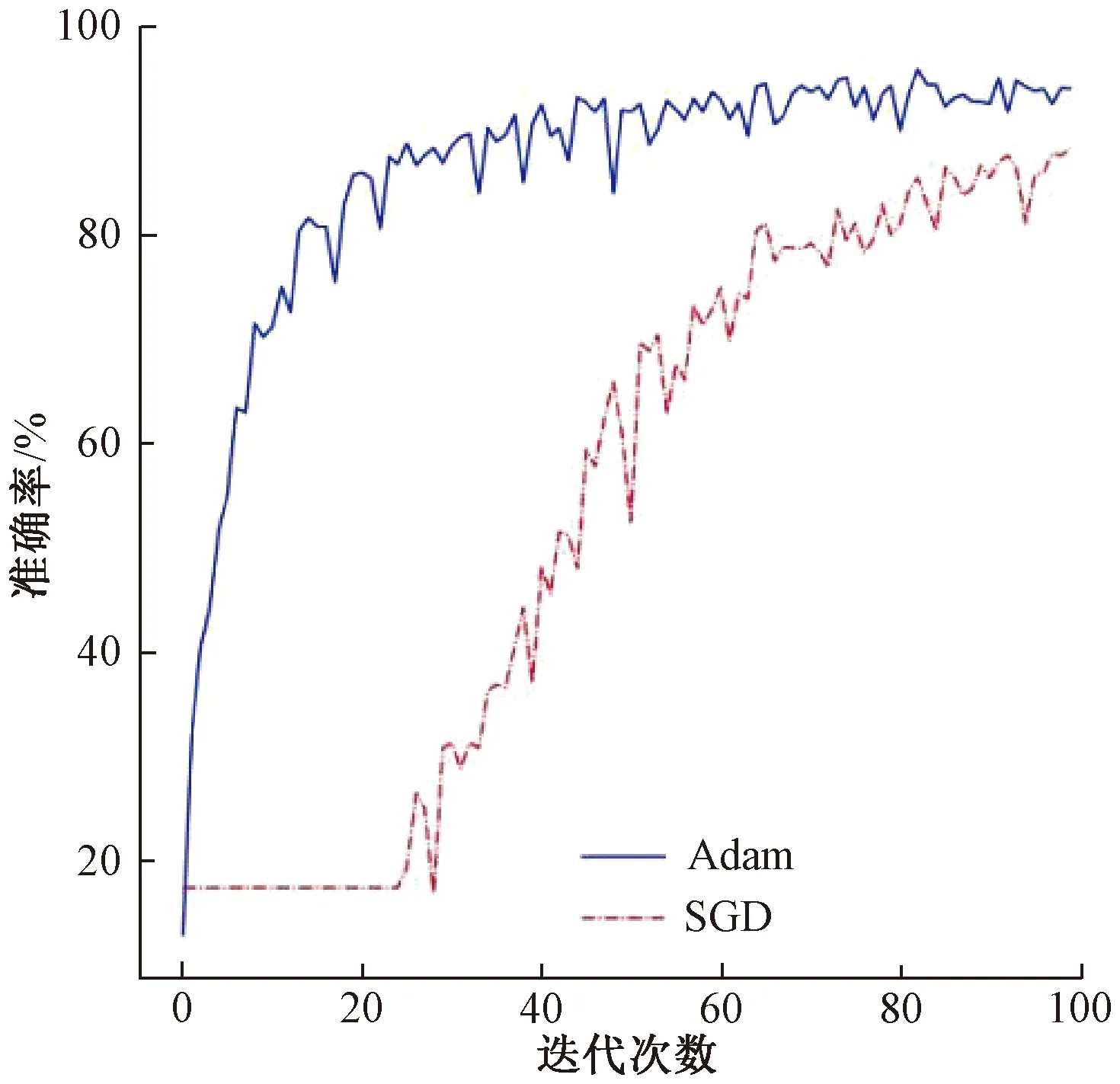
图7 两种优化器下模型的训练过程Figure 7 The training process of the models under the two optimizers
在训练初期,网络在Adam优化器下准确率快速上升,收敛快,且最终收敛的准确率较高;在使用SGD优化器时,网络在前20轮的准确率不变,说明期间网络并没有进行有效的学习和训练,20轮以后准确率开始缓慢上升,训练到100轮时网络仍未达到收敛,且准确率较低。因此,考虑到训练时间和收敛效果,本文选择Adam对模型进行优化。
学习率控制着网络的学习进度,是关键的超参数之一。为了找到适合本文模型的学习率,在同样使用Adam作为优化器的情况下,对比网络在不同学习率下的训练过程,准确率和损失值变化曲线如图8所示。

图8 不同学习率下网络训练的准确率和损失值变化曲线Figure 8 The change curve of accuracy and loss value of network training under different learning rate
当学习率为0.000 2时,网络识别准确率最高为94.70%,但此时曲线振荡明显,模型不稳定;当学习率为0.000 5时,准确率为91.76%,且训练到60轮以后,出现准确率上升而损失值也上升的现象,模型发生过拟合;当学习率为0.000 3和0.000 4时,网络曲线振荡小,准确率分别为93.61%和94.07%,能够使网络得到较好的训练。因此,本文选择0.000 4作为学习率。
2.3 结果与分析
2.3.1改进的fire模块对模型性能的影响 在相同实验条件下分别搭建两种网络结构:一种是传统的SqueezeNet;另一种是将改进后的fire模块替换原SqueezeNet中的fire模块,并标识为模型Ⅰ。两种模型在8种番茄病害数据集上进行训练,结果表明,SqueezeNet的参数量为1 255 431,准确率为95.91%。与其相比,模型Ⅰ的准确率为94.07%,虽略微下降,但参数量大大减少,仅为SqueezeNet参数量的7/10。说明对fire模块采用的轻量化策略在损失较少准确率的情况下,可以明显减少模型的参数量,缩小模型大小。
2.3.2ECA模块的引入对模型性能的影响 为了研究模型中加入ECA模块对性能的影响,分别在模型Ⅰ结构中的4个不同位置嵌入注意力模块,然后在处理后的同一番茄数据集上进行训练。结果显示,模型Ⅰ的参数量为886 791,准确率为94.07%;在pool 2、fire 7、 fire 9和conv 10后面分别添加一个ECA模块时,参数量均为886 797,对应的准确率分别为93.89%、97.29%、93.20%和95.28%。可以看出,ECA模块的加入只增加微量的参数,同一个注意力模块引入到不同的位置,对网络所产生的影响也不尽相同,如果位置选取不当,在网络中靠前或者靠后,都可能会削弱原来的识别能力。对于本文提出的改进模型,当在fire 7后面嵌入ECA模块时准确率最高。说明将ECA模块放在这个位置时,能够利用该层的输出信息找到关键的特征,并通过权重矩阵增强有用特征的表达,抑制无用特征,从而提升了网络准确率。
为进一步探究ECA模块对模型Ⅰ稳定性的影响,在Plant Village数据集中加入高斯和椒盐噪声,对比在网络不同位置嵌入ECA模块时的识别性能,稳定性结果见图9。可以看出,与没有噪声的数据集相比,在添加了噪声后模型准确率下降。此外,只有ECA模块嵌入fire 9后面时网络的稳定性有所提升,而在pool 2、fire 7和conv 10后面时均出现下降。因此,将ECA模块放在fire 9后面时有助于网络学习到病害的重要特征,可以抵抗一定的噪声干扰,稳定性较好。
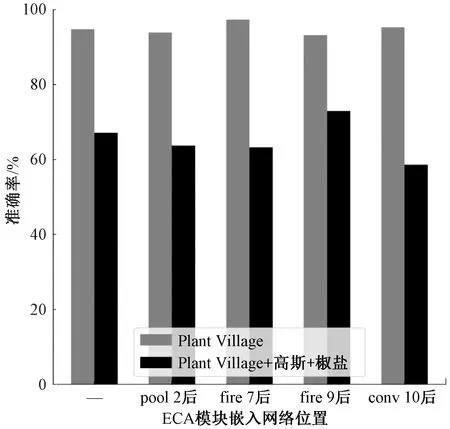
图9 ECA模块嵌入网络不同位置时模型的稳定性Figure 9 Stability of the model when ECA module was embedded at different locations of the network
综上可知,将ECA模块嵌入到网络中合适的位置,可以有效地提高网络的准确率以及增强稳定性。在fire 7后面添加一个ECA模块时网络的识别准确率最高,达到97.29%,虽然此时模型的稳定性略有下降,但幅度较小,在可接受的范围内。因此,为了构建一个高精度的番茄病害识别模型,最终确定在模型Ⅰ的fire 7后面嵌入一个注意力模块,构建识别番茄病害的改进型SqueezeNet网络模型。
2.3.3改进型SqueezeNet与其他模型的比较 表1展示了不同网络模型在番茄病害图片上的性能对比结果。

表1 不同网络模型的性能对比Table 1 Performance comparison of different network models
从表1可以看出,与经典网络模型LeNet相比,改进的SqueezeNet模型在准确率和模型大小方面具备明显优势;与轻量级网络模型MobileNet和SqueezeNet相比,改进的SqueezeNet模型的准确率均高于这两种模型,且模型所需内存空间更小。因此,改进型SqueezeNet模型的准确率和模型大小均优于现有的三种网络模型,能够满足高精度和轻量化的需求。
3 小结
本文在已有的植物病害研究基础上,将深度学习技术与农业需求相结合,提出改进型SqueezeNet模型来识别番茄病害,包括对fire模块进行轻量化,同时加入注意力机制。实验结果表明,与现有的几种神经网络模型相比,改进的SqueezeNet模型准确率最高,所占的内存最小,具有一定的可移植性。
本文采用的图片来自大型公开数据集,背景简单且“一图一叶一病”,即每张图片只有一个叶片,每个叶片只有一种疾病,这样的情形是比较理想的状态。但在真实的作物生存环境下,存在着叶片重叠、一叶多病、多病叠加等情况,而且现场拍摄的图片在很大程度上会受到光照强度、拍摄角度的影响。因此,如何让网络模型具有强鲁棒性、稳定性以及泛化性是在实际应用中需要解决的问题,也是未来值得深入研究的方向。
