基于机器学习方法的ERα 抑制剂活性预测
2022-04-20杜雪平
杜雪平*
(湖北工业大学理学院,湖北 武汉 430068)
乳腺癌是世界上最常见且致死率较高的癌症类型[1]。近十年来我国的乳腺癌发病率上升了47 %,发病率还在逐年增加,且乳腺癌发病逐渐呈年轻化。
雌激素受体(ER)在乳腺癌发展过程中起着非常重要的作用,是乳腺癌内分泌疗法最主要的靶点[2]。ER 分为ERα 和ERβ 两种亚型[3],ERα 主要分布在乳房和子宫内膜中,ERβ 与神经系统和免疫系统有关。ERα 在正常的乳腺组织中表现水平很低,但在乳腺癌患者的乳腺组织中表达水平异常增高,因此ERα 被认为是治疗乳腺癌的重要靶标,抑制ERα 受体的活性是治疗乳腺癌的重要手段,能够抑制ERα 活性的化合物可能是治疗乳腺癌的候选药物。通过实验的方法来高通量筛选化合物费时费力,因此可以采用基于计算的虚拟筛选方法,其中基于机器学习来构建化合物的定量结构-活性关系(Quantitative Structure-Activity Relationship, QSAR)模型是最主流的方法。目前构建化合物的QSAR 模型有如下要求[4]:(1)确定的目标(化合物生物活性);(2)明确的算法;(3)确定的应用领域;(4)显著的相关性、良好的稳健性和预测能力;(5)模型易于解释。Dadfar E 等人[5]利用人工神经网络(ANN)方法建立磺胺类药物化合物的活性预测模型,虽有较好的预测能力,但ANN 方法存在黑箱。Kurunczi L 等人[6]在构建QSAR 模型时利用偏最小二乘法(PLS)进行变量选择,Asikainen A H 等人[7]利用k-近邻(KNN)方法进行变量选择,采用PLS 方法和KNN方法筛选出的变量较多,不易于对模型进行有效解释。
本文使用方差过滤法和Lasso 回归对分子描述符进行合理筛选,基于随机森林、支持向量机和多元线性回归三种机器学习方法构建ERα 抑制剂的活性预测模型,其中使用随机森林具有更好的预测能力和稳健性。
1 数据集划分与特征筛选
本文数据使用“华为杯”第十八届中国研究生数学建模竞赛D 题中数据,包括1974 个化合物的729 个分子描述符和生物活性 pIC50 值。 使用 sklearn.model_selection 模块中的train_test_split 函数来将1974个化合物以4:1 划分为训练集和测试集,训练集样本数为1579,测试集样本数为395。在训练集上训练模型,再用测试集的数据来考察模型的预测效果。
本文数据集有729 个分子描述符,特征维度大,不利于模型的构建,因此需要进行变量筛选。结合数据集存在特征维度庞大的特点,本文将过滤法[8]与嵌入法[8]相结合,首先使用方差过滤法对分子描述符变量进行初步筛选,方差过滤法简单,能够快速剔除掉信息量很小的特征变量。再使用Lasso 回归[9]消除噪声特征(即对生物活性值影响很小的特征)和关联特征(即特征之间相关性较强的特征),不仅能够保证模型拥有良好的性能,还节省了大量的处理时间和计算能力。特征筛选具体步骤如下:(1)方差过滤法:本文首先基于方差过滤法利用Python 软件对数据集中729 个分子描述符进行初步筛选,将方差阈值设定为0.05。对任一分子描述符,遍历所有样本计算该分子描述符的方差,如果方差小于等于0.05 则将其剔除,即删除取值变化不明显的分子描述符,保留方差大于0.05 的分子描述符。经过方差过滤法最终在729 个变量中剔除了369 个变量,保留了360 个变量。(2)Lasso 回归算法:分子描述符经过初步筛选之后,再使用Lasso 回归进一步筛选。以化合物活性pIC50 值作为目标变量,360 个分子描述符作为自变量构建Lasso 回归模型,通过对损失函数加入惩罚项,使得训练求解参数过程中会考虑系数的大小,通过设置缩减系数(惩罚系数=0.001),使得影响较小的特征的系数衰减到0。Lasso回归系数代表了分子描述符变量对生物活性pIC50 值的重要性,Lasso 回归系数绝对值越大,说明分子描述符对pIC50 值越重要,根据重要性排序,选择对pIC50 值影响最大的50 个分子描述符。
2 基于机器学习方法对ERα 抑制剂活性的预测
本文分别用随机森林、支持向量机和多元线性回归等机器学习方法对ERα 抑制剂的活性进行预测,并用均方误差MSE 来评价模型预测效果。MSE 是预测值与真实值差的平方和的平均,即:
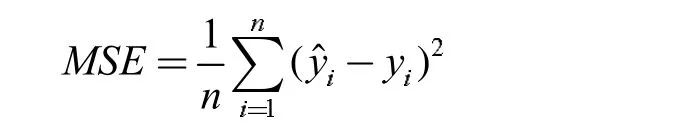
MSE 的范围是[0,+∞),当预测值与真实值完全相同时,MSE 等于0,MSE 越大,代表预测误差越大。
2.1 基于随机森林对ERα 抑制剂活性的预测
2.1.1 随机森林算法
随机森林(Random Forest,简称RF)是通过Bagging思想将多棵CART 回归树集成的一种有监督学习算法[10]。Bagging 是根据Bootstrap 思想(有放回的随机抽样)构建的一种集成学习算法[11]。CART 回归树最优特征和划分点的选择依据是最小均方差,即对任意划分特征A,其对应的任意划分点a 所划分成的数据集和,找出使集合和的均方差最小,同时使和的均方差之和最小的划分特征和划分点,可以表达为:

其中,cleft为数据集Dleft的样本输出均值,cright为数据集的样Dright本输出均值。
本文利用随机森林回归模型进行预测的步骤如下:
(1)从样本量为N 的化合物训练集中有放回的随机抽取n(n < N)个样本,重复m 次,共生成m 个训练样本集;
(2)使用训练样本集构建回归树,在节点的所有分子描述符中随机选取部分分子描述符,依据最小均方差选择最优分子描述符和划分点,将当前节点划分为两个子节点,递归划分直至满足终止条件;
(3)重复步骤(2),构建的m 棵回归树就组成了随机森林回归模型;
(4)输入化合物测试样本,m 棵树预测值的平均值为最终预测结果,将其与真实值对比,来评价模型的预测效果。
2.1.2 随机森林调参与结果分析
使用筛选出的50 个分子描述符作为自变量,以化合物的活性值作为因变量构建随机森林回归预测模型。利用Python 的sklearn 包做随机森林回归预测时,主要涉及到三个重要超参数:n_estimators (回归树的个数)、max_depth(回归树的最大深度)和min_samples_leaf(叶子结点最少样本数)。回归树的个数太小,模型容易欠拟合;回归树的个数太大会导致计算量过大,并且回归树个数增加到一定数量后,模型效果不再显著提升。回归树的最大深度过小容易导致模型欠拟合,过大容易导致模型过拟合。叶子结点最少样本数涉及到回归树的剪枝,如果叶子结点数小于min_samples_leaf,则该叶子结点和兄弟节点都将被剪枝,剪枝过程可以提高随机森林回归模型的泛化能力。手工调制超参数需要耗费大量时间来探索不同组合得到的效果,我们使用网格搜索来选择最优参数。分别设置n_estimators 的取值有50, 60, 70, 80,90,100,max_depth 的取值有8, 10, 12,min_samples_leaf的取值有20, 25, 30, 35, 40,同时使用5 折交叉验证,共有90 种n_estimators、max_depth 和min_samples_leaf的组合方式。而每一种组合方式要在训练集上训练5次,所以一共要训练450 次。利用网格搜索,进行五折交叉验证训练随机森林回归模型,训练结束后得到的最优超参数组合方式为n_estimators = 70、max_depth =12 和min_samples_leaf = 20。分别在训练集和测试集上截取40 个数据,预测效果如图1 所示。
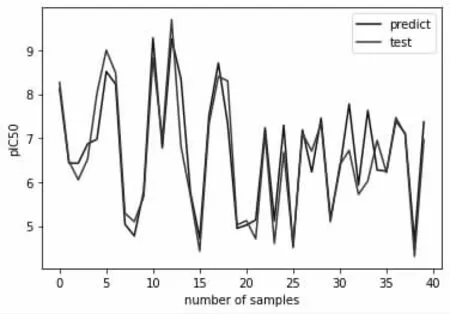
图1(a)训练集预测效果

图1(b)测试集预测效果
由图1 可以看出,随机森林回归模型的预测效果较好,且在测试集上的预测效果与训练集上的预测效果相似,说明调参后的随机森林回归模型具有良好的稳健性。利用网格搜索得到的最优参数组合和随机森林默认参数分别构建随机森林回归预测模型得到的均方误差结果如表1 所示。
由结果可知,使用默认参数构建的随机森林回归预测模型,在训练集上的预测精度很高,但测试集均方误差相对训练集均方误差过大,产生了过拟合现象。通过网格搜索调整参数和使用交叉验证训练模型之后,训练集和测试集的预测效果都很好,均方误差很接近,模型的泛化能力明显提升,可以对ERα 抑制剂的活性进行有效预测。
2.2 基于其他机器学习方法对ERα 抑制剂活性的预测
2.2.1 基于支持向量机对ERα 抑制剂活性的预测
支持向量机(Support Vector Machine,简称SVM)由Corinna Cortes 等人于1995 年首次提出,属于有监督的机器学习方法,在解决非线性、小样本和高维特征的分类和回归问题时有很好的的效果[12]。支持向量机回归(SVR)通过加入距离误差epsilon 的损失函数来度量回归精度。使用高斯函数作为支持向量机回归模型的核函数,设置模型参数为:高斯核函数(惩罚系数C = 1.25,距离误差epsilon = 0.1,核函数参数gamma = 0.1),在训练集上和测试集上的均方误差分别为0.653, 0.792,可知支持向量机回归模型用于ERα 抑制剂的活性预测效果较好。
2.2.2 基于多元线性回归对ERα 抑制剂活性的预测多元线性回归(multiple linear regression, 简称MLR)是QSAR 中最早采用和最经典的数学建模方法[13]。用复相关系数R2来对多元线性回归模型的拟合程度进行评价。
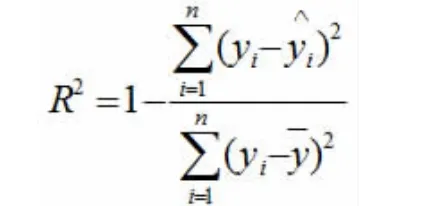
2.3 各机器学习方法预测能力的比较
本文使用三种机器学习方法对ERα 抑制剂的活性进行预测,对于随机森林和支持向量机模型的建立,需要调整参数以得到更好的预测效果,对于多元线性回归模型,需要进行拟合优度检验来判断模型的可用性,具体预测效果如表2 所示。三个模型均有良好的预测能力,且随机森林方法在训练集和测试集上的均方误差都比其他两种方法的要小,表现出了更好的预测能力和泛化能力。
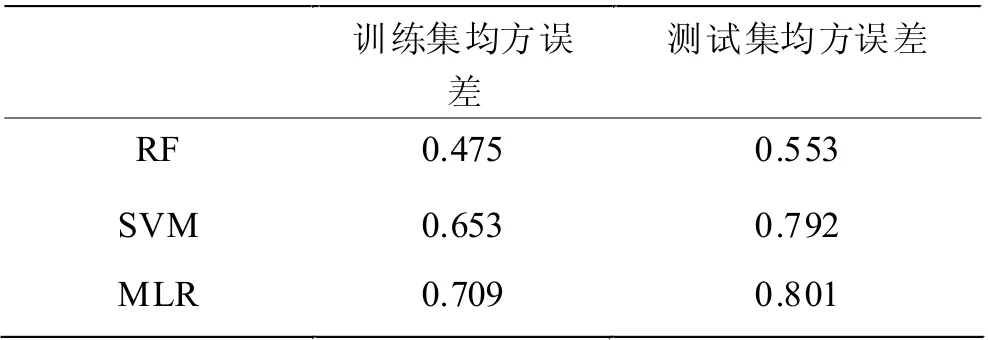
表2 三种模型预测效果比较
3 结论
本文分别使用随机森林、支持向量机和多元线性回归构建了ERα 抑制剂生物活性预测模型,使用方差过滤法和Lasoo 回归筛选出与ERα 抑制剂活性最相关的分子描述符。通过对分子描述符的合理筛选和模型参数的优化,本文建立的ERα 抑制剂活性活性预测模型具有良好的预测效果,且随机森林表现出了更好的预测能力和稳健性,认为随机森林模型更适用于ERα 抑制剂的活性预测。
