基于端到端的蒙古语异形同音词声学建模方法
2022-04-19李图雅马志强谢秀兰王洪彬
陈 艳,李图雅,马志强,2,谢秀兰,王洪彬
(1.内蒙古工业大学 数据科学与应用学院,内蒙古 呼和浩特 010080;2.内蒙古工业大学 内蒙古自治区基于大数据的软件服务工程技术研究中心,内蒙古 呼和浩特 010080)
0 引言
基于深度神经网络-隐马尔可夫声学模型(Deep Neural Network-Hidden Markov Model,DNN-HMM)是一种主流的语音识别声学模型建模方法。基于DNN-HMM声学模型训练,首先需要使用传统混合高斯-隐马尔可夫模型(Gaussian Mixture-Hidden Markov Model,GMM-HMM)获取声学特征向量对应标注状态的概率值,即对齐数据,然后才能对标注数据进行建模,建立标注数据与不同状态之间的关系[1-3]。然而,由于GMM模型是多个单高斯模型并排组合形成的浅层网络模型[4],所以在对时域和频域上分布复杂的语音数据进行建模时,会导致对齐数据存在一定的误差。同时,DNN-HMM声学模型的输入数据是语音的切片信息[5-6],并不是完整的语音信息,没有考虑到语音的完整性。
近年来,基于端到端(End-to-End)语音识别模型的提出,简化了DNN-HMM声学模型的训练过程,因此基于端到端的语音识别模型成为了研究的热点模型。Alex Graves 等人使用时序类分类(Connectionist Temporal Classification,CTC)作为目标函数训练了双向长短时记忆循环神经网络(Bi-directional Long Short-Term Memory, Bi-LSTM),直接对语音句子进行建模,通过插入blank帧和blank标签实现声学特征到标注数据的对齐,完整地实现了从音频到标注序列的计算过程[7-9]。基于CTC的端到端识别模型主要是对输入的语音按标注信息进行分类,建模粒子的选择将会影响识别的性能。
蒙古语语音识别系统声学建模过程仍是一个构建蒙古语发音数据与标注数据之间关系的过程。然而,在蒙古语中存在着一种异形同音词的发音现象。在蒙古语声学建模中,由于蒙古语不同词发音相同现象,当以音素作为建模粒子时,造成蒙古语相同发音对应的标注数据相同的结果,所以,在基于CTC端到端蒙古语声学模型训练时很难区分异形同音词。同时,在进行蒙古语语音识别的解码时,通过标注数据寻找对应的蒙古语词,也会出现一种一对多的映射现象,造成解码出的蒙古语文本与原始蒙古语发音句子文本不匹配,降低了蒙古语语音识别系统的识别率。
本文根据蒙古语的发音特点,采用蒙古语字母作为蒙古语声学模型的建模粒子,提出了基于端到端的蒙古语异形同音词声学模型建模方法,在建模过程中实现了自动对齐语音数据,保证了蒙古语句子的完整性,解决了蒙古语语音识别中的异形同音词的问题。
1 蒙古语异形同音词建模粒子

对于蒙古语语音识别中的异形同音词而言,以蒙古语音素为建模粒子时,构成该蒙古语词的音素序列就会相同,即该蒙古语词的标注数据是相同的,建模过程中蒙古语异形同音词存在一对多的问题,就无法对异形同音词进行区分,如图1所示。
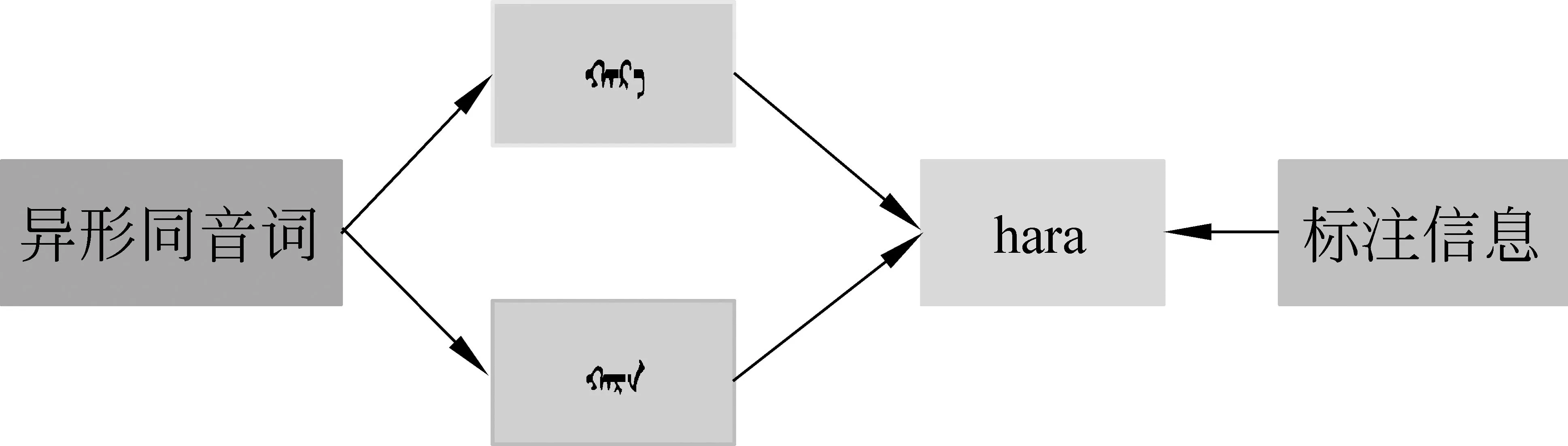
图1 以音素标注的蒙古语异形同音词

图2 以蒙古语字母为标注的异形同音词
2 端到端蒙古语声学模型
2.1 BLSTM-CTC蒙古语声学模型
BLSTM-CTC蒙古语声学模型可以直接对原始蒙古语句子进行建模,在建模过程中实现了对语音数据的对齐,并且保证了蒙古语句子的完整性。BLSTM-CTC 蒙古语声学模型由三层的模型结构M=(TI,TH,TO)组成,其中,TI表示模型输入层的层模型结构,TH表示隐含层的层模型结构,TO表示模型输出层的层模型结构,如图3所示。

图3 BLSTM-CTC蒙古语声学模型
对端到端蒙古语声学模型进行设计。首先是对TI层模型结构进行设计,由于端到端蒙古语声学模型是对整个蒙古语句子进行建模,所以将TI层模型结构中的网络节点设置为最长蒙古语句子的FBANK蒙古语声学特征帧的个数。其次,是对TH隐含层的层模型结构进行设计,采用多个BLSTM层堆叠形成TH层模型结构TH=(N,F,P,L)。其中,TH·N表示TH层模型结构中的网络节点,决定存储着语音的上下文信息的长度;TH·F表示TH层模型结构中的激活函数,能够将神经网络中权值传递进去的结果转化为分类结果;TH·P表示TH层模型结构中的参数矩阵;TH·L表示BLSTM堆叠的层数,能有效地提取出深层次的蒙古语语音。最后是对TO模型输出层的层模型结构的设计,其中,TO层模型结构中的网络节点有两层设计,一是将输入的蒙古语语音特征转化成标注数据的后验概率,该后验概率是蒙古语语音帧级别的后验概率;二是整合标注数据的后验概率,形成蒙古语句子标注序列的后验概率;所以,TO层模型结构中的网络节点的设计与标注数据有关。
图3中,BLSTM 模型结构中每一个BLSTM层为一层隐含层,隐含层是由多个BLSTM层堆叠而成的。对于给定输入的蒙古语声学特征数据向量x=(x1,x2,…,xt-1,xt),BLSTM 模型结构通过t=1到t迭代计算隐式向量c=(c1,c2,…,ct)和输出向量d=(d1,d2,…,dt),如式(1)、式(2)所示。
其中,xt-1表示t-1时刻的网络输入,dt-1表示t-1时刻的网络输出,Fout表示网络输出层,Wic、Wcc、Wco表示权重矩阵,bc、bo表示偏置向量,σ()表示隐藏层激活函数。每个隐式cn分别经过一个正向的隐含层以及一个反向的隐含层的计算,得到一个汇总的向量结果,完成一层的 BLSTM层的计算,将计算得到的结果作为下一层BLSTM的输入进行计算,以此类推。
2.2 异形同音词下BLSTM-CTC蒙古语声学模型训练
本文将异形同音词中端到端蒙古语声学模型分为两种,一种是以蒙古语音素为建模粒子构建的端到端蒙古语声学模型(命名为YBLSTM-CTC蒙古语声学模型),另一种是以蒙古语字母为建模粒子构建的端到端蒙古语声学模型(命名为ZBLSTM-CTC蒙古语声学模型)。
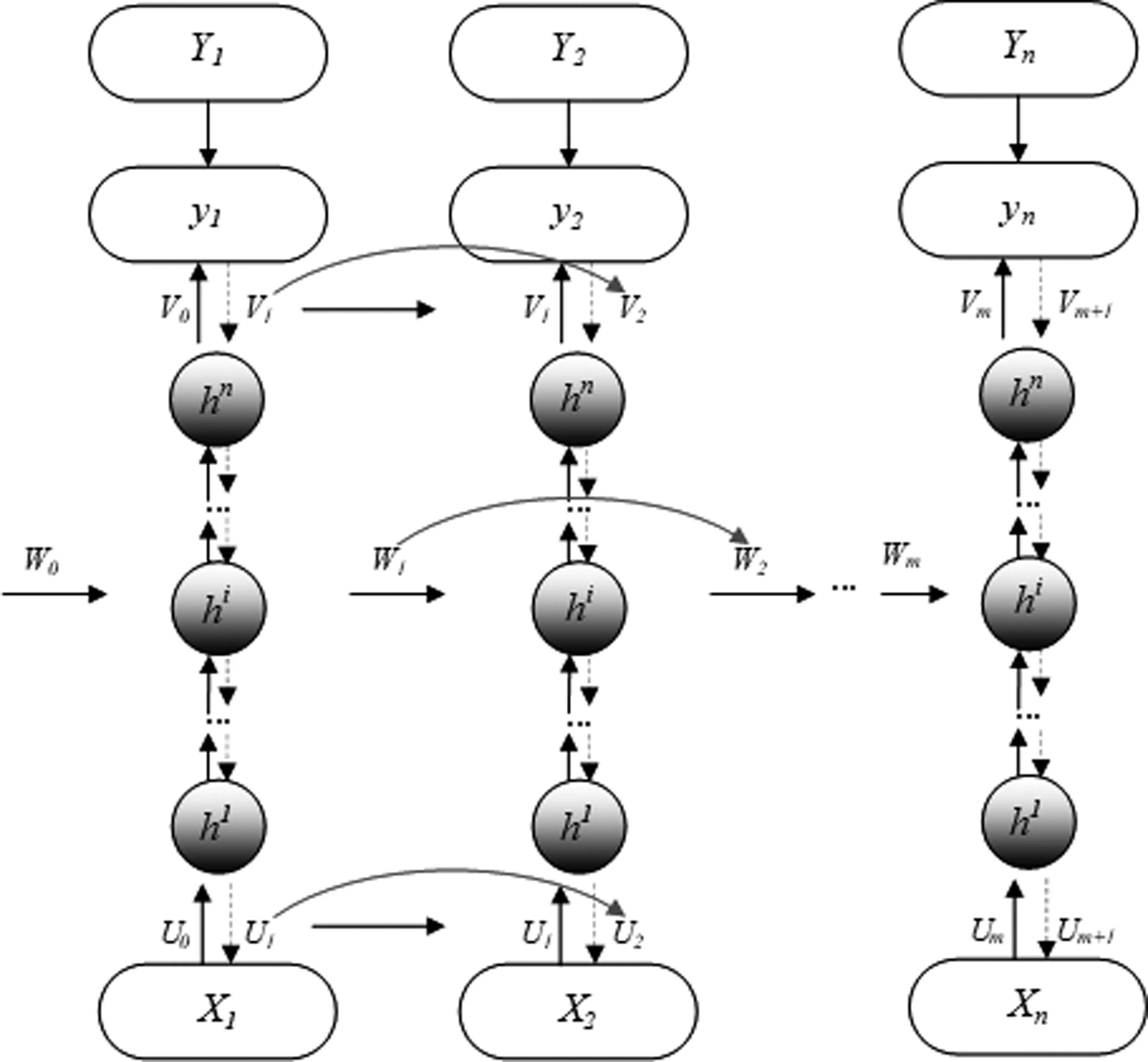
图4 BLSTM-CTC蒙古语声学模型的训练过程
其中,X1与X2是一组蒙古语异形同音词,{X1,X2,…,Xn}表示输入BLSTM-CTC蒙古语声学模型的训练序列,{Y1,Y2,…,Yn}表示训练序列的标注数据,{y1,y2,…,yn}表示训练序列通过BLSTM-CTC蒙古语声学模型得到的预测序列,Um、Vm、Wm分别表示BLSTM-CTC蒙古语声学模型经过第m次迭代更新后输入层的权值、输出层的权值和隐含层的权值,hi表示第i层的BLSTM层。实线表示的是模型训练过程中的正向传播计算,虚线表示的是模型训练过程中的反向传播计算。
在YBLSTM-CTC蒙古语声学模型的训练过程中,对于给定蒙古语异形同音词X1与X2而言,可以表示为X1=X2,Y1=Y2。当预测值y1与y2逐渐逼近Y1与Y2,由于Y1=Y2,所以,y1与y2的值几乎相同;通过预测值y1与y2反向搜索得到的X1与X2序列对应的文本序列就会相同,因此模型无法区分发音序列X1与X2所对应的文本序列。在对ZBLSTM-CTC蒙古语声学模型训练时,对于给定的异形同音词X1与X2而言,可以表示为X1=X2,Y1≠Y2。因为X1=X2,Y1≠Y2,所以预测值y1≠y2,通过y1和y2搜索得到发音序列X1和X2所对应的蒙古语文本就不同。
使用ZBLSTM-CTC蒙古语声学模型对蒙古语句子建模,可以充分考虑到蒙古语中异形同音词的上下文信息,在对蒙古语异形同音词的发音建模时,很容易生成蒙古语异形同音词发音所对应的蒙古语字母序列,而这一点对于YBLSTM-CTC蒙古语声学模型而言,生成蒙古语异形同音词发音所对应的蒙古语音素序列仍然相同。所以,ZBLSTM-CTC蒙古语声学模型更有利于异形同音词的识别。
BLSTM-CTC蒙古语声学模型的训练算法是采用动量和小批量梯度下降算法结合的算法,动量的加入能够加快端到端蒙古语声学模型训练的速度,具体训练算法如表1所示。

表1 动量梯度下降算法
3 实验设置与评价指标
3.1 实验设置
本文实验中语音数据均为8 kHz采样率、16 bit、单通道的格式,蒙古语文本的存储格式为UTF-8。本文设计两个不同规模的蒙古语训练集语料库,一个是句子中含有异形同音词的蒙古语句子,一共是1 255句(命名为IMUT1255),另一个语料库是含有异形同音词的3 765句蒙古语句子的语料库,即IMUT3765。其中,IMUT3765是IMUT1255的扩展语料库。蒙古语测试集采用含有异形同音词的378句蒙古语语句,命名为IMUT378。IMUT1255、IMUT3765和IMUT378中含有的蒙古语异形同音词如表2所示。
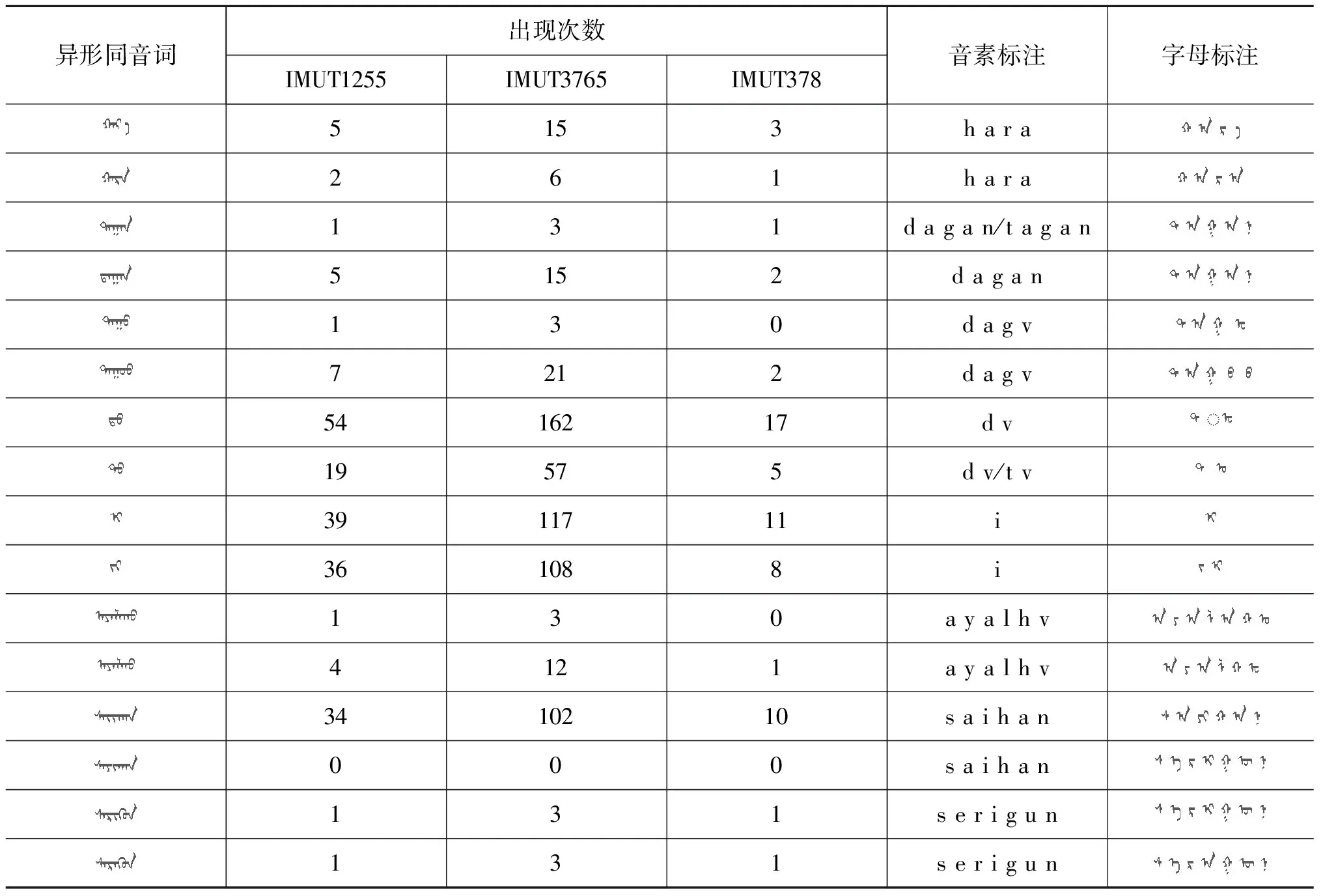
表2 IMUT1255、IMUT3765、IMUT378蒙古语语料下异形同音词
实验中声学特征采用的是 40 维的 FBANK 蒙古语声学特征。模型训练的epoch =15,batch_size=256,momentum =0.5,初始化学习率为0.001 5,采用Relu激活函数。实验中BLSTM-CTC蒙古语声学模型采用3层双向BSTM,均包含160个隐藏单元。
为了增加实验的对比性,本文将DNN-HMM蒙古语声学模型、YBLSTM-CTC蒙古语声学模型和ZBLSTM-CTC蒙古语声学模型进行对比,通过准确性和稳定性两个方面的实验,验证本文提出的基于端到端的蒙古语异形同音词声学模型建模方法对蒙古语语音识别中异形同音词的有效性。
3.2 评价指标
本文使用词错率来评价蒙古语语音识别系统识别的准确性,并且使用平均绝对误差和F1-score评价蒙古语语音识别系统识别的稳定性。
词错率(wer): 指的是解码出来的词与原真实文本做对比,解码出来正确的句子的个数占总句子数的百分比,词错率计算如式(3)所示。
wer=(S+I+D)/N*100%
(3)
其中,S表示词替代(Substitution,S)错误、I表示词的插入(Insertion,I)错误和D表示词的删除(Deletion,D)错误,N表示总蒙古词的个数。
异形同音词的词错率(hwer): 指的是解码出来的异形同音词本文与原真实文本作对比,解码出来正确的句子的个数占总句子数的百分比,异形同音词词错率计算如式4所示。
hwer=[(HS+HI+HD)/HN]*100%
(4)
其中,HS表示异形同音词词替代(Homophone Substitution,HS)错误、HI表示异形同音词词的插入(Homophone Insertion,HI)错误和HD表示异形同音词词的删除(Homophone Deletion,HD)错误,HN表示总异形同音词的个数。
平均绝对误差(MAE): 计算解码出来的词与原真实值的绝对误差,从而评价预测值相对于真实值的波动程度,绝对误差值越小表示系统识别越稳定。平均绝对误差的计算如式(5)所示。
(5)
其中,N为样本数量,Xi为第i个蒙古语样本的预测值,X′i为第i个蒙古语样本的真实值。
F1-score: 是统计学中的一种评价指标。它可以通过统计出的异形同音词计算出模型对异形同音词的识别结果。F1-score的计算如式(6)所示。
F1=2*TP/(2*TP+FP+FN)
(6)
其中,TP表示预测值为正,实际值也为正;FP表示预测值为正,实际值为负;FN表示预测值为负,实际值为正。
3.3 实验结果与分析
本文通过对比DNN-HMM蒙古语声学模型、以蒙古语音素为建模粒子的端到端蒙古语声学模型(即YBLSTM-CTC)和以蒙古语字母为建模粒子的端到端蒙古语声学模型(即ZBLSTM-CTC)的语音识别系统识别效果来说明端到端蒙古语声学模型的有效性。
3.3.1 模型准确率分析
本文对比DNN-HMM蒙古语声学模型、YBLSTM-CTC蒙古语声学模型和ZBLSTM-CTC蒙古语声学模型的蒙古语语音识别词错率以及异形同音词的词错率,具体实验结果如表3、表4所示。
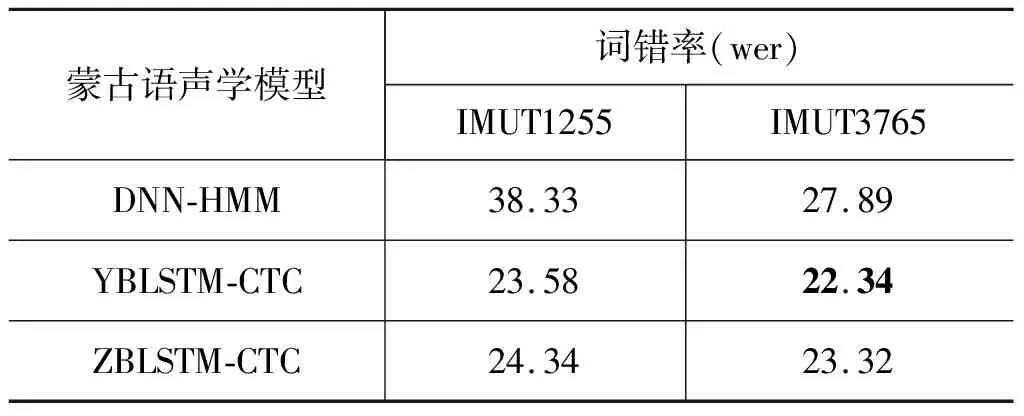
表3 不同声学模型下蒙古语语音识别的词错率 (单位: %)
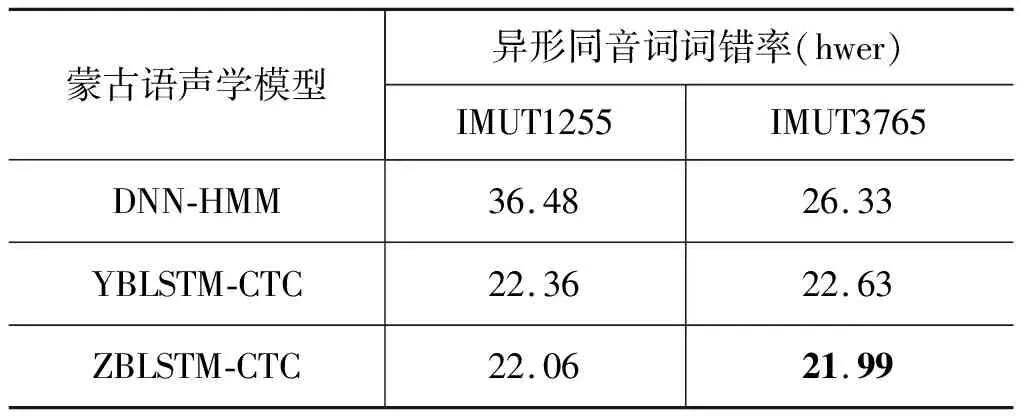
表4 不同声学模型下蒙古语语音识别异形同音词的词错率 (单位: %)
从表3、表4可以看出,DNN-HMM蒙古语声学模型随着训练集数据的增加wer、hwer均降低,但是仍高于端到端声学模型下的wer、hwer,表明端到端蒙古语声学模型对于语音识别任务有较好的识别效果。另外,从表3可以看出,在IMUT1255蒙古语语料下,ZBLSTM-CTC蒙古语声学模型的wer高于YBLSTM-CTC蒙古语声学模型的wer,而在IMUT3765蒙古语语料下,ZBLSTM-CTC蒙古语声学模型的wer低于YBLSTM-CTC蒙古语声学模型的wer,说明随着数据集的增大ZBLSTM-CTC蒙古语声学模型的识别效果更好。从表4可以看出,在IMUT1255和IMUT3765蒙古语语料下,ZBLSTM-CTC蒙古语声学模型的hwer均低于YBLSTM-CTC蒙古语声学模型,说明ZBLSTM-CTC蒙古语声学模型对异形同音词的识别效果要更好一些。综合来说,异形同音词的存在影响了蒙古语语音识别的wer,也说明ZBLSTM-CTC蒙古语声学模型更适合对异形同音词进行建模。
为了说明DNN-HMM、YBLSTM-CTC和ZBLSTM-CTC蒙古语声学模型的异形同音词识别效果对整个蒙古语语音识别效果的影响,本文定义了词错误下降率,如式(7)所示。
词错误下降率=词错误率-异形同音词的词错率
(7)
具体结果如图5所示。
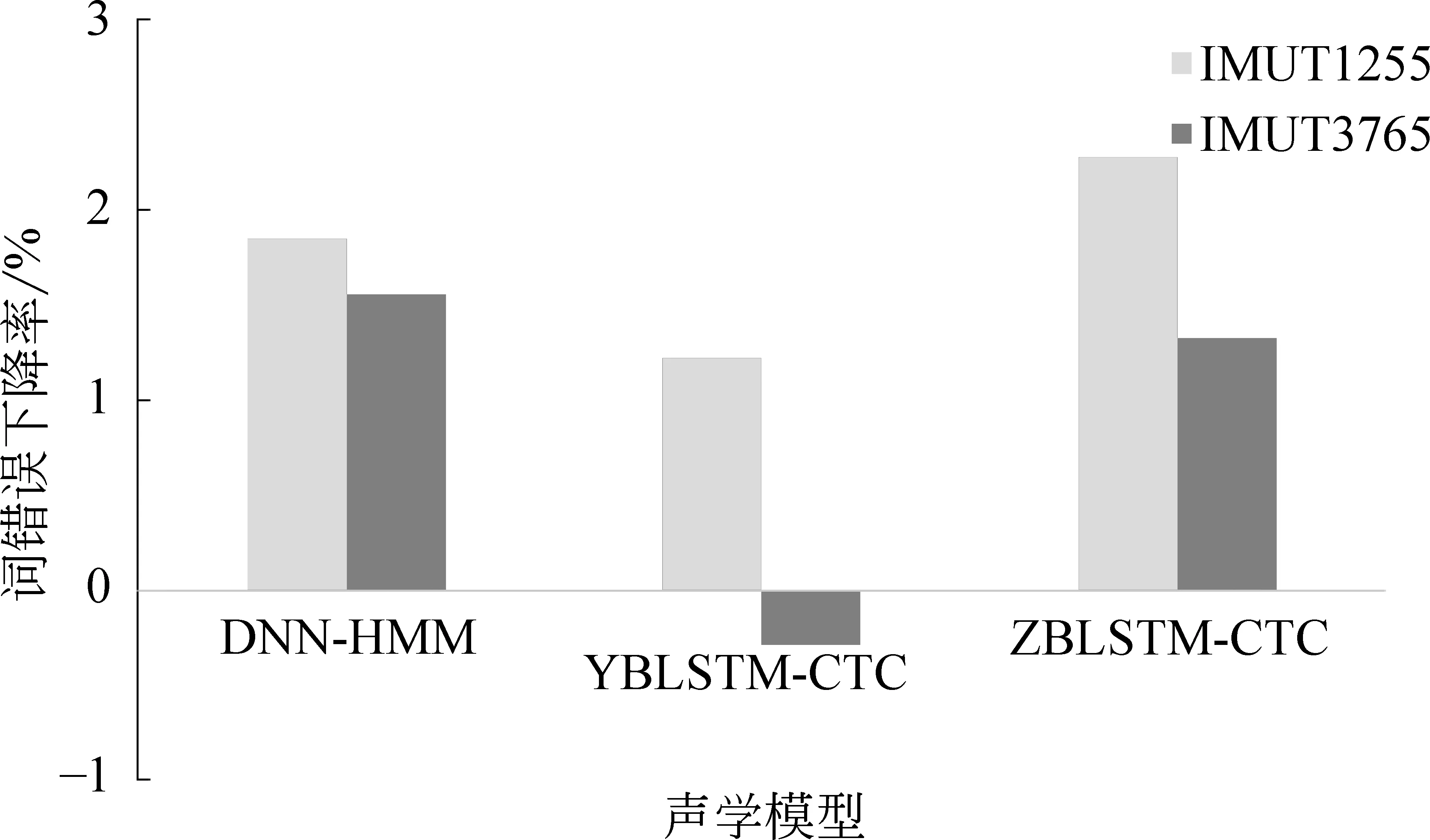
图5 不同蒙古语声学模型下异形同音词识别效果对整个蒙古语语音识别效果的影响
从图5可以看出,①在IMUT1255蒙古语语料下,在DNN-HMM、YBLSTM-CTC和ZBLSTM-CTC蒙古语声学模型下蒙古语的词错误下降率皆为正数,说明DNN-HMM、YBLSTM-CTC和ZBLSTM-CTC蒙古语声学模型的异形同音词的识别效果对蒙古语语音识别效果产生的是正面影响;②在IMUT3765蒙古语语料下,YBLSTM-CTC蒙古语声学模型的词错误下降率为负值,说明YBLSTM-CTC蒙古语声学模型的蒙古语语音识别对异形同音词识别提高了蒙古语语音识别的词错率,此时,异形同音词的识别效果对蒙古语语音识别效果产生的是负面影响。③在不同规模的蒙古语语料下,ZBLSTM-CTC蒙古语声学模型的蒙古语词错误下降率都高于YBLSTM-CTC蒙古语声学模型的蒙古语词错误下降率,说明ZBLSTM-CTC蒙古语声学模型的蒙古语语音识别在异形同音词的识别效果方面要优于YBLSTM-CTC蒙古语声学模型。
3.3.2 模型稳定性分析
本文将蒙古语测试集IMUT378整体混洗打乱后,划分为三个测试集(即IMUT378-1,IMUT378-2,IMUT378-3),并且分别对测试集IMUT378-1,IMUT378-2,IMUT378-3进行了实验。实验结果如表5所示。
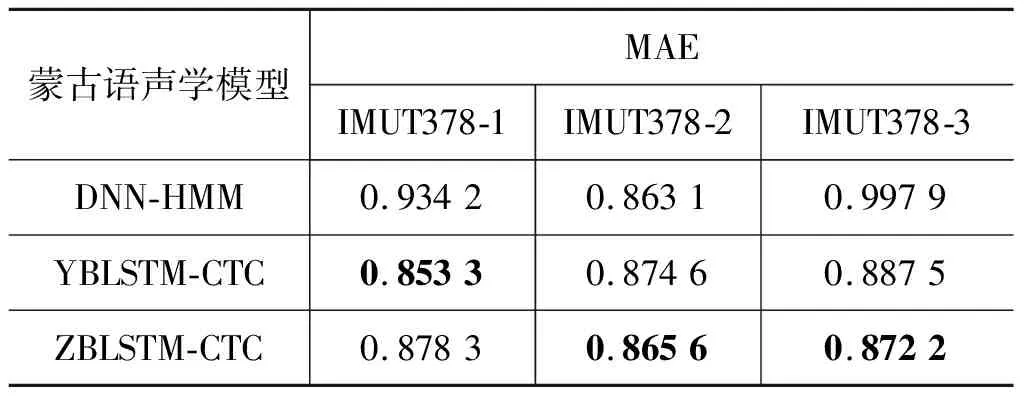
表5 不同声学模型下蒙古语语音识别的MAE结果对比
表5使用MAE评价指标分别对比了不同模型的效果,实验结果表明: ①端到端蒙古语声学模型在3个测试集上均取得了最优的MAE结果,说明了端到端蒙古语声学模型在蒙古语语音识别的稳定性方面具有优势;②ZBLSTM-CTC声学模型,虽然在IMUT378-1上的MAE值上升,但显著降低了IMUT378-2、IMUT378-3的MAE值,表明YBLSTM-CTC蒙古语声学模型的语音识别系统的稳定性逊色于ZBLSTM-CTC蒙古语声学模型的语音识别系统。
为进一步说明蒙古语声学模型的稳定性,采用不同规模蒙古语数据集进行训练,统计IMUT378数据集中蒙古语异形同音词识别的个数,并对统计结果使用F1-score进行打分。具体统计结果如表6所示。
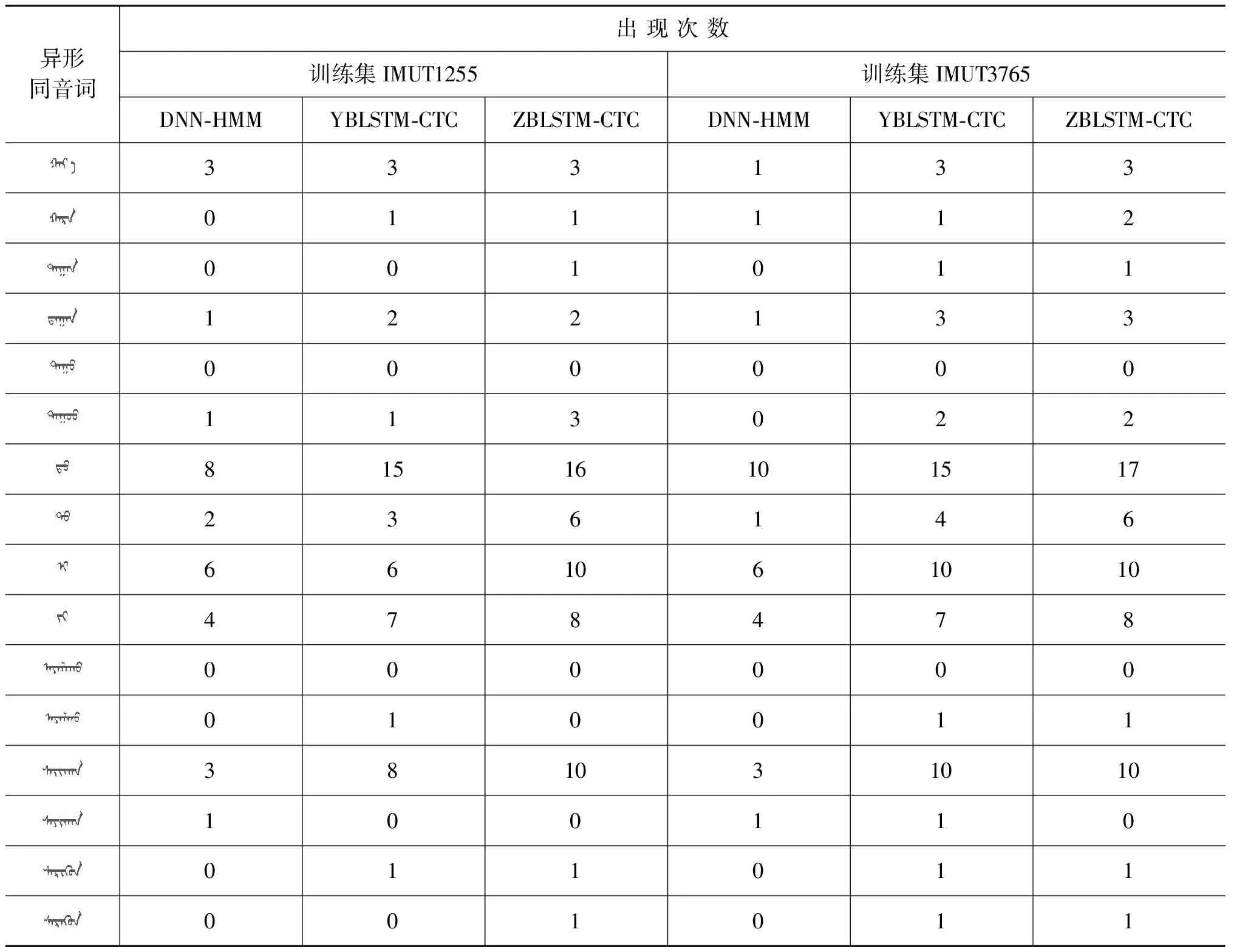
表6 不同规模训练集下IMUT378数据集中异形同音词的识别结果
根据表6,对统计结果使用F1-score进行打分,结果如表7所示。
通过表7可以看出: ①采用训练集IMUT3765蒙古语语料库训练的蒙古语声学模型F1-score 始终高于采用训练集IMUT1255训练的蒙古语声学模型的F1-score, 说明语料库规模越大,蒙古语语音识别系统性能越好;②不论采用哪个语料库进行训练,ZBLSTM-CTC模型的F1-score值都始终高于YBLSTM-CTC的F1-score值,说明在蒙古语异形同音词的识别效果方面,ZBLSTM-CTC蒙古语声学模型的性能高于YBLSTM-CTC蒙古语声学模型。

表7 不同规模蒙古语数据集下蒙古语声学模型异形同音词的F1-score
通过以上实验结果可以看到,ZBLSTM-CTC蒙古语声学模型稳定性明显高于YBLSTM-CTC蒙古语声学模型,说明基于ZBLSTM-CTC蒙古语声学模型对异形同音词的建模能力更为稳定。采用蒙古语字母作为端到端蒙古语声学模型的建模粒子,可以解决蒙古语语音识别中异形同音词的识别问题。
4 结论
针对以蒙古语音素为建模粒子时蒙古语异形同音词在建模过程中存在一对多的问题,该文提出使用蒙古语字母作为蒙古语声学模型的建模粒子,结合BLSTM-CTC蒙古语声学模型、蒙古语字母考虑蒙古语标注信息上的唯一性,使得模型训练过程中实现训练序列和标注序列上的一对一映射。
实验结果表明: ①通过对实验进行对比,ZBLSTM-CTC 蒙古语声学模型的F1-score 要更高,且异形同音词的词错误率要更低,证明了ZBLSTM-CTC 蒙古语声学模型对蒙古语异形同音词的建模效果更好;②在蒙古语识别的准确性和稳定性方面,ZBLSTM-CTC蒙古语声学模型比YBLSTM-CTC 蒙古语声学模型、DNN-HMM蒙古语声学模型取得了更好的识别效果,证明了ZBLSTM-CTC在蒙古语语音识别中对异形同音词识别任务的优越性。综合可得,ZBLSTM-CTC 蒙古语声学模型对蒙古语异形同音词的建模能力要比 YBLSTM-CTC 蒙古语声学模型更好。
然而,目前蒙古语语音识别中异形同音词识别任务使用蒙古语字母作为蒙古语声学模型建模粒子的BLSTM-CTC蒙古语声学模型仍然不能取得很好的识别效果。未来可针对提高识别准确率做进一步研究,提高异形同音词蒙古语语音识别系统的准确率。
