基于多粒度语义交互理解网络的幽默等级识别
2022-04-19张瑾晖张绍武林鸿飞樊小超
张瑾晖,张绍武,林鸿飞,樊小超,2,杨 亮
(1.大连理工大学 计算机科学与技术学院,辽宁 大连 116024;2.新疆师范大学 计算机科学技术学院,新疆 乌鲁木齐 830054)
0 引言
幽默普遍存在于人们的日常交流中,是化解尴尬、活跃气氛、促进交流的重要手段,可以对人类身心健康产生积极的影响[1]。随着人工智能的快速发展,如何让计算机识别幽默,并进一步识别幽默的等级成为了目前自然语言处理领域的研究热点之一。幽默识别涉及认知语言学、人工智能、心理学等多个学科,其研究能够更好地促进计算机对人类语言的理解。同时,幽默识别能够赋予计算机从更深层次理解人类情感的能力,在机器翻译和人机交互等领域有着广泛的应用。因此,幽默识别及幽默等级识别具有重要的理论研究价值和广泛的应用价值。
传统的幽默识别通常是识别一个句子或段落是否具有幽默的含义[2-4]。许多研究表明,幽默具有连续性[4-6]。幽默等级识别,作为幽默识别任务的延伸,旨在根据幽默程度的不同将幽默文本划分为不同的等级。Paulos[7]的研究表明,幽默文本通常能够被划分为“铺垫”和“笑点”两个部分,其中“铺垫”一般先于“笑点”表述,是对背景和前提的交代,而“笑点”则是“铺垫”的延续和反转。Weller等[5]指出,对“铺垫”和“笑点”两部分语义及其关系的深入理解有助于幽默等级识别。表1展示了一个幽默文本及其铺垫和笑点两部分。

表1 幽默中的铺垫和笑点
在表1中,幽默文本被划分为两个子句,子句1为“铺垫”,子句2为“笑点”。“笑点”既对铺垫中的“failure”做了补充说明,是“铺垫”的延续,又使用“successful”与“铺垫”中的“failure”形成反转。“铺垫”和“笑点”之间对立统一的关系使句子包含了一定程度的幽默。
现有的幽默识别与幽默等级识别研究通常分两步进行:首先基于幽默理论,设计并实现一系列的幽默特征;然后采用传统的机器学习方法或结合神经网络方法对幽默文本或幽默等级进行识别。Weller等[5]采用基于Transformer的预训练模型对幽默等级进行识别并取得了较好的效果。人工构造特征耗时耗力,且难以对多样性的幽默表达进行全面表征,模型的泛化能力较弱。现有的神经网络模型和预训练模型将“铺垫”和“笑点”作为整体进行建模,忽略了其独立的语义信息和交互的关联信息。此外,由于语言的细微差别可能造成幽默的程度不同,仅从单一的粒度提取幽默特征,模型的性能可能受到限制。
综上所述,为了缓解幽默等级识别中的问题,本文提出了一种基于多粒度语义交互理解网络的幽默等级识别方法。针对幽默语言多样性的特点,采用了多种词嵌入表示融合的方法对幽默文本进行表征;针对幽默语义复杂性的特点,采用了局部语义交互理解模块和全局语义交互理解模块,分别从单词粒度和子句粒度提取幽默文本的高维潜在语义特征;针对幽默中“铺垫”和“笑点”的语义关联特点,采用“交互型”的神经网络模型对二者的关联信息进行建模;最后对多粒度的语义特征和交互关联特征进行融合,并对幽默等级进行识别。本文的贡献有以下3点:
(1)本文基于多种嵌入表示融合的幽默文本表示,提出了一种基于局部和全局语义理解的神经网络模型,分别从单词级别和子句级别提取幽默文本特征。
(2)本文提出了一种基于交互语义关联特征的神经网络模型,对幽默文本中“铺垫”和“笑点”的关联信息进行建模以抽取幽默语义关联特征。
(3)本文使用基于多粒度语义交互理解网络的幽默等级识别方法,在Reddit公开幽默数据集上进行对比实验。结果表明,本文方法能有效提升幽默等级识别的性能。
1 相关工作
作为日常生活中常见的语言现象,幽默理论研究历史久远,基于幽默理论,幽默识别也有很多的研究成果,而幽默等级识别研究则刚刚起步。本节将从幽默理论、幽默识别和幽默等级识别三个方面总结前期的工作。
1.1 幽默理论
幽默理论对幽默等级识别研究具有重要的指导意义。在众多幽默理论中,乖讹论被广泛接受且具有深远的影响。乖讹论认为幽默是人类对不协调事物的感知,当事物的发展违背人们的常识和期望时,幽默就产生了[8]。基于乖讹论,Raskin等[9]提出了第一个语言学意义上的幽默理论——脚本语义理论(Script Semantic Theory of Humor,SSTH),该理论认为语义对立是幽默产生的重要原因。基于以上幽默理论,Paulos等[7]将幽默分为“铺垫”和“笑点”,认为两部分之间存在对立统一的关系。
1.2 幽默识别
传统的机器学习方法被广泛应用于幽默识别领域。Yang等[10]从不一致性、歧义性、语音特性和人机交互特性四个方面提取幽默的语义特征,并采用了随机森林方法识别幽默。Barbieri等[11]根据幽默问题的语音和歧义性特点,构造了多种幽默特征。Zhang等[3]基于幽默的语言学理论,构建50多种幽默特征并将它们划分为五个类别。Liu等[12]提取了对话中的情感特征及情感关联特征识别对话中的幽默。此外,他们对幽默文本中句法结构特征进行了深入的分析,并指出句法结构和幽默文本具有高度的相关性[13]。
近年来,越来越多的深度学习方法被用于识别幽默。杨勇等[14]从音、形、义三个维度对幽默特征进行建模,采用层次注意力机制对幽默进行识别。Bertero等[15-16]由《生活大爆炸》中的文本和语音内容构建幽默数据集,采用长短时记忆网络和卷积神经网络自动抽取文本语义特征,从而预测对话中的幽默。Baziotis等[17]利用注意力机制,更好地关注到句子中的特定单词,从而提高了幽默识别的性能。Zhao等[18]提出了一种采用张量分解的方法提取幽默的语义特征。除了英文,研究者采用深度学习方法对西班牙文[19]和俄文[4]语料进行了幽默识别。
1.3 幽默等级识别
幽默等级识别使计算机能够理解哪些语义和语义关系使句子更加有趣。Westbury等[20]对单词的幽默程度建模并对4 997个单词的幽默程度进行了评分。Hossain等[6]通过重新编辑新闻标题使其变得更加幽默,并对编辑前后文本语义的幽默程度进行了分析。Cattle等[21]将文本划分为“铺垫”和“笑点”两个部分,并指出二者的语义相关性对文本的幽默等级具有显著影响。此外,一些国际著名评测也将幽默等级识别任务作为评测主题[22]。
综上所述,幽默理论为幽默等级识别的研究提供了理论基础。此外,从不同粒度提取幽默文本中“铺垫”和“笑点”的语义特征和语义关系特征有助于幽默等级识别性能的提升。
2 幽默等级识别方法
基于多粒度语义交互理解网络的幽默等级识别方法主要包括两个层次,语义的嵌入式表示层和交互语义特征提取层。交互语义特征提取层包括两个部分: 局部语义交互理解模块和全局语义交互理解模块。
基于多粒度语义交互理解的神经网络(MSIU)模型如图1所示。语义的嵌入式表示层能够获取幽默文本中“铺垫”和“笑点”的高维潜在语义表示。首先为了更好地获取不同词嵌入表示的语义信息,融合多种词嵌入表示对“铺垫”和“笑点”中的单词进行表征;其次,为了获取高维潜在语义表示,采用双向长短时记忆网络(Bi-directional LSTM,Bi-LSTM)分别提取“铺垫”和“笑点”的语义信息并得到上下文表示。交互语义特征提取层将上下文表示作为输入,从局部和全局两个维度交互地提取“铺垫”和“笑点”中的语义特征及两者之间的语义关联特征。局部语义交互理解模块计算得到“铺垫”中单词语义表示和“笑点”中单词语义表示的关联信息,全局语义交互理解模块计算“铺垫”子句和“笑点”子句的关联信息。最后对局部和全局信息进行融合并对幽默等级进行识别。
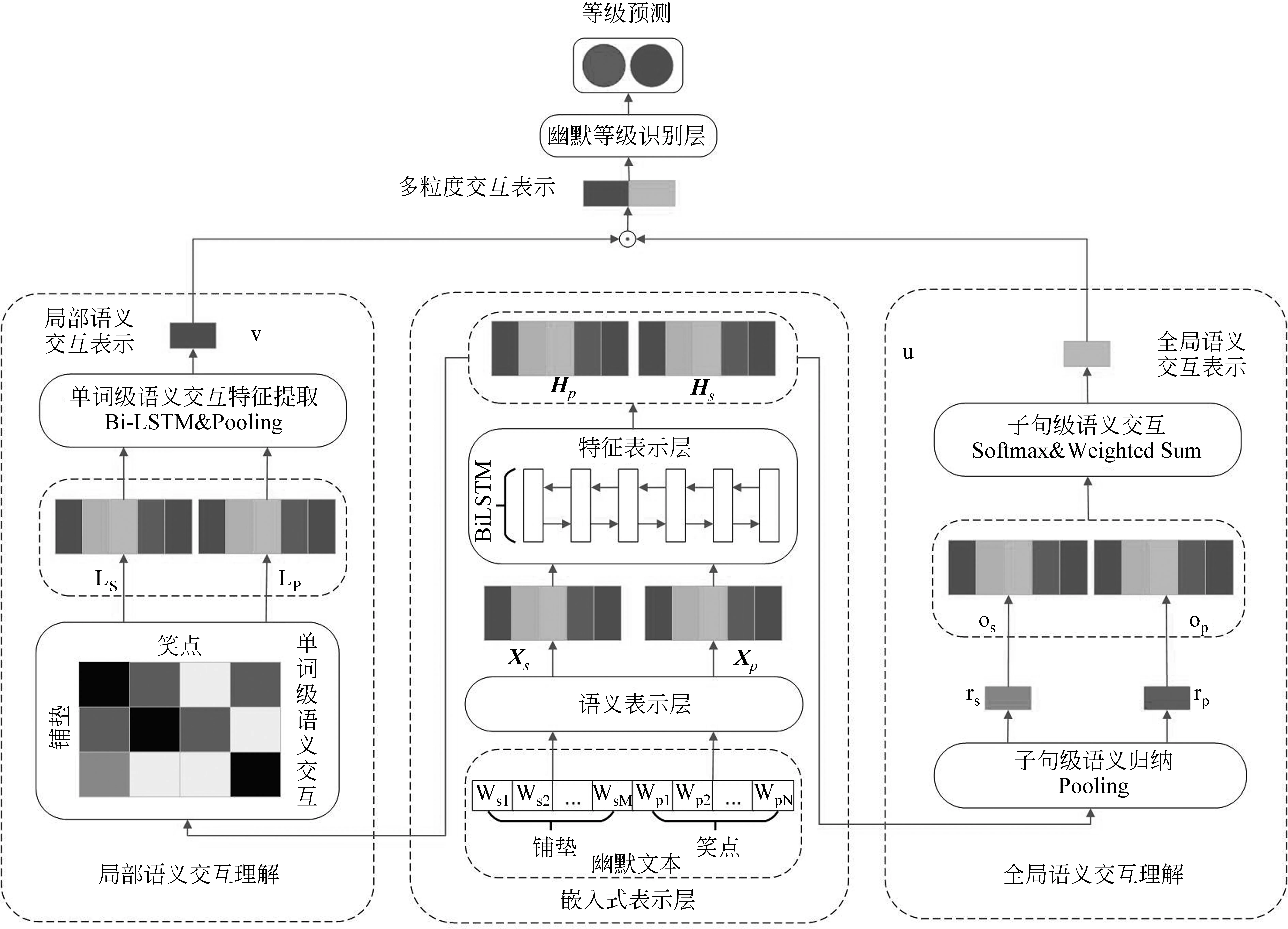
图1 MSIN模型框架图
2.1 语义的嵌入式表示层
幽默是一种复杂的语言现象,一词多义等特征使得幽默特征表示和提取变得更加困难[10]。Xu等[23]指出领域内和领域外的词嵌入表示的融合有助于文本分类模型性能的提升。目前还没有由幽默语料训练得到的词嵌入表示,而大规模的词嵌入表示,如GloVe[24]、BERT[25]等,一般是利用通用语料或者新闻语料训练得到的。直接采用单一的词嵌入表示往往使得幽默等级识别的性能欠佳。此外,“铺垫”和“笑点”在幽默等级识别中发挥着不同的作用,将二者统一建模,不利于文本的幽默等级识别。因此,本文将幽默文本的“铺垫”和“笑点”分别建模,采用多个领域词嵌入表示进行融合,并采用Bi-LSTM提取两个部分的高维语义特征。
2.1.1 语义表示层
该层将“铺垫”和“笑点”中的每个单词映射到多个高维特征空间,并对其进行融合以获取有意义的语义表示。设幽默语句为W={ws1,ws2,…,wsM,wp1,…,wpN},其“铺垫”为WS={ws1,ws2,…,wsM},“笑点”为WP={wp1,wp2,…,wpN},其中,wi为语句中的任一单词,M+N为句子总长度,M和N分别为“铺垫”和“笑点”的长度。将幽默语句中每个单词表示为K种低维稠密向量,并对同一单词的多种向量进行拼接,得到单词的向量表示。则“铺垫”的向量表示为XS={xs1,xs2,…,xsM}∈D×M,“笑点”的向量表示为XP={xp1,xp2,…,xpN}∈D×N,D是词向量的维度,D=D1+D2+…+DK。
2.1.2 特征表示层
在该层中,模型利用Bi-LSTM分别提取“铺垫”和“笑点”子句的语义特征,作为幽默文本的“铺垫”和“笑点”的特征表示。LSTM[26]能够对文本语义上的长距离依赖关系进行建模,而Bi-LSTM能够从正反两个方向提取潜在语义特征,并融合两部分的语义信息。在每个时间步t,正向和反向LSTM对输入词向量xt的处理过程可以分别形式化地表示为:
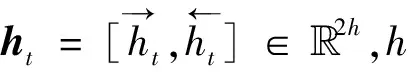
特征表示层能够得到幽默文本的潜在语义特征,记为H=[HS,HP]=[hs1,hs2,…,hsM,hp1,hp2,…,hpN]∈(M+N)×2h,其中,HS和HP分别是铺垫和笑点的潜在语义表示。
2.2 交互语义特征提取层
Chen等[27]指出不同粒度的语义单元及其交互信息能够有效地提高模型对文本语义的理解。“铺垫”和“笑点”作为两个语义单元,两者在不同粒度上相互作用,铺垫中单个词语及铺垫整体都会影响到笑点的语义表达,反之亦然。此外,Engelthaler等[28]指出不同单词在句子中表现出不同的幽默程度。单词的语义信息与语句的幽默等级具有一定的相关性。
为使神经网络模型能够学习到单词和句子的语义信息,并且能够获取“铺垫”和“笑点”之间的关联信息,本文采用局部语义交互理解模块和全局语义交互理解模块对来自上层的潜在语义表示做处理。
2.2.1 局部语义交互理解模块
Yang等[10]研究发现,在幽默文本中,不同词语的重要程度不同,当删除幽默文本中的某些词语后,文本的幽默程度下降,甚至完全消失。本文采用局部语义交互理解模块从单词级别提取幽默文本的语义信息和语义关联信息。局部语义交互理解模块包括单词级语义交互层和单词级语义特征提取层。
单词级语义交互层单词级语义交互层使用软对齐的方式获取“铺垫”和“笑点”的单词粒度语义交互表示。具体地讲,对来自特征表示层的“铺垫”和“笑点”的潜在语义表示HS和HP,该层首先将两者中每个单词对应向量两两之间做点乘,如式(3)所示。
(3)
可以得到“铺垫”和“笑点”的相似度矩阵E={eij|i∈[1,M],j∈[1,N]}∈M×N,其中,eij表示“铺垫”中第i个单词和“笑点”中第j个单词的相似度。
然后,该层以加权求和的形式求出“铺垫”和“笑点”中每个单词对应的交互表示,如式(4)、式(5)所示。
由上面两个式子可知,交互表示包括由“铺垫”表示的笑点和由“笑点”表示的铺垫,模型使用“铺垫”或者“笑点”中所有向量的加权和来得到对方每个单词的表示,以这种方式实现“铺垫”和“笑点”的交互。
最后,模型融合每部分文本各自的潜在语义表示及交互表示,得到两部分在该层的输出,如式(6)、式(7)所示。
其中,LS∈M×8h、LP∈N×8h分别是“铺垫”和“笑点”的单词级语义交互表示。本文使用如下方法对每个单词的潜在语义表示和交互表示进行融合,如式(8)、式(9)所示。
其中,lsi、lpj∈8h。
单词级语义交互特征提取层该层对单词级交互信息进一步抽象,获取单词级语义交互特征。首先,该部分分别将LS和LP经过Bi-LSTM来提取单词级交互表示的高层特征,计算过程如式(10)、式(11)所示。
其中,GS∈M×2h,GP∈N×2h。分别对GS和GP做平均池化和最大池化,并将池化获得的四个向量拼接,最终得到幽默文本的局部语义交互特征向量v,计算过程如式(12)~式(14)所示。
2.2.2 全局语义交互理解模块
Ma等[29]研究表明,对于文本中的不同语义单元,其单词的含义会受到其他语义单元的影响。“铺垫”和“笑点”作为幽默文本的两个子句级语义单元,二者互相作用,对幽默等级识别产生重要影响。本文采用全局语义交互理解模块从子句级别提取幽默文本的语义信息和语义关联信息。全局语义交互理解模块包括子句级语义归纳层和子句级语义交互层。
子句级语义归纳层该层分别对“铺垫”和“笑点”子句的上下文表示(HS或者HP)做平均池化和最大池化,将两部分拼接得到二者的归纳表示,如式(15)~式(18)所示。
得到的向量rs、rp通过全连接层把它们的维度投影到2h。
子句级语义交互层该层对“铺垫”和“笑点”子句做交互,然后对交互信息进一步抽象,以获取全局的语义交互特征。首先,计算子句与各词之间的交互权重,如式(19)、式(20)所示。
其中,OS∈M×2h,OP∈N×2h。
然后,通过加权求和的方式获得两个子句的交互特征,并最终得到全局语义交互特征向量u,如式(21)~式(23)所示。
其中,us、up∈2h分别是“铺垫”和“笑点”的子句级别交互特征,将两者拼接得到u。
2.3 幽默等级识别层
该层由全连接层及softmax层组成。首先将局部和全局语义信息进行融合,然后通过全连接层和softmax层,得到幽默等级的概率分布,计算如式(24)、式(25)所示。
其中,T∈12h,humorcls∈C是概率分布,C是幽默等级数量。本文采用交叉熵作为损失函数,其形式化表示如式(26)所示。
(26)
3 实验结果
本节首先介绍了实验数据、评价指标、实验设置和基线方法,然后对比了基线方法和本文提出的MSIN方法的幽默等级识别性能,最后通过实验分析了本文方法的有效性。
3.1 实验数据与评价指标
Reddit数据集:该数据集由Weller等[5]构建。幽默语句来自Reddit中带有“humor”标签的文本,采用众包方式对幽默语句的“铺垫”和“笑点”进行了标注,且对幽默语句的强弱进行了人工标注。数据集规模详见表2。
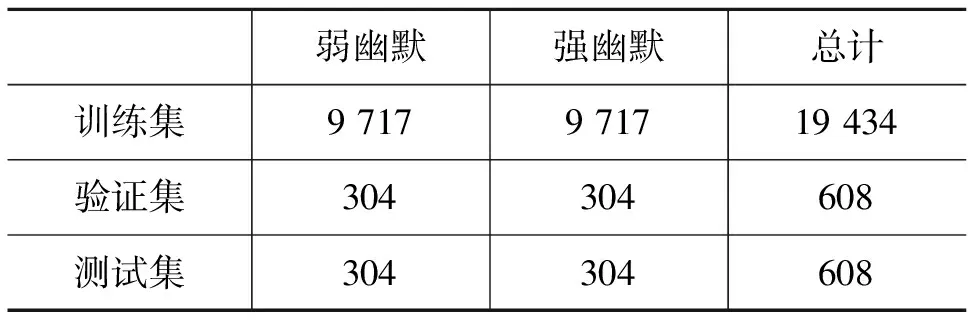
表2 Reddit幽默数据集统计信息
评价指标:为了便于和基线方法进行比较,本文采用了被广泛接受并应用于文本分类任务中的精确率(Acc)、准确率(P)、查全率(R)和F1 Score(F1)作为评价指标。
3.2 实验设置
词嵌入:在训练过程中,词嵌入表示分别采用了Glove(1)https://nlp.stanford.edu/projects/glove/以及Word2Vce(2)https://code.google.com/archive/p/word2vec/[30],维度均为300,词嵌入在训练的过程中固定。对未登录词使用(-0.01,0.01)上的平均分布随机初始化。
超参数:在实验中,设置L2正则化项的超参数λ=10-5,Bi-LSTM的神经元个数为128,CNN三个卷积核的尺寸分别为2、3和5,优化方法为Adam[31],Batch大小为64,dropout为0.5。为了防止过度拟合,在训练过程中使用了学习率衰减和早停机制。为了便于和基线模型对比,采用了Weller等[5]对数据的划分。
3.3 基线方法
本文使用下述基线方法进行对比实验:
•Human[5]:人工预测结果。
•CNN[5]:采用CNN自动提取幽默语句的潜在语义特征并进行幽默等级识别。
•CNN[32]:本文复现的基于CNN的方法,使用3种不同尺寸卷积核的CNN提取幽默文本特征进行幽默等级识别。
•LSTM[26]:使用LSTM提取幽默特征并进行幽默等级识别。
•Bi-LSTM-Attention:使用双向LSTM和注意力机制提取幽默文本特征,并对幽默等级进行识别。
•Transformer[5]:使用基于Transformer结构[33]的预训练模型对幽默文本整体做特征提取,以进行幽默等级识别。
•BERT[25]:本文复现的基于BERT方法的结果,在任务语料上做微调,然后进行幽默等级识别。
•ESIM[27]:只基于局部语义交互信息进行幽默等级识别。
•MSIN:本文提出的多粒度语义交互理解网络,综合使用语义嵌入、局部语义交互和全局语义交互进行幽默等级识别。
3.4 实验结果分析
本文在Reddit数据集上的实验结果如表3所示。表格整体分为三部分,第一部分为人工进行幽默等级识别的结果;第二部分采用之前研究的通用方法,将幽默等级识别视作文本分类任务,把幽默文本整体编码后进行分类;第三部分基于本文观点,将幽默等级识别任务视作自然语言推理任务,把幽默文本划分为“铺垫”和“笑点”两个语义部分,以这两部分作为模型的输入,使用表示型模型或交互型模型预识别文本蕴含的幽默等级。
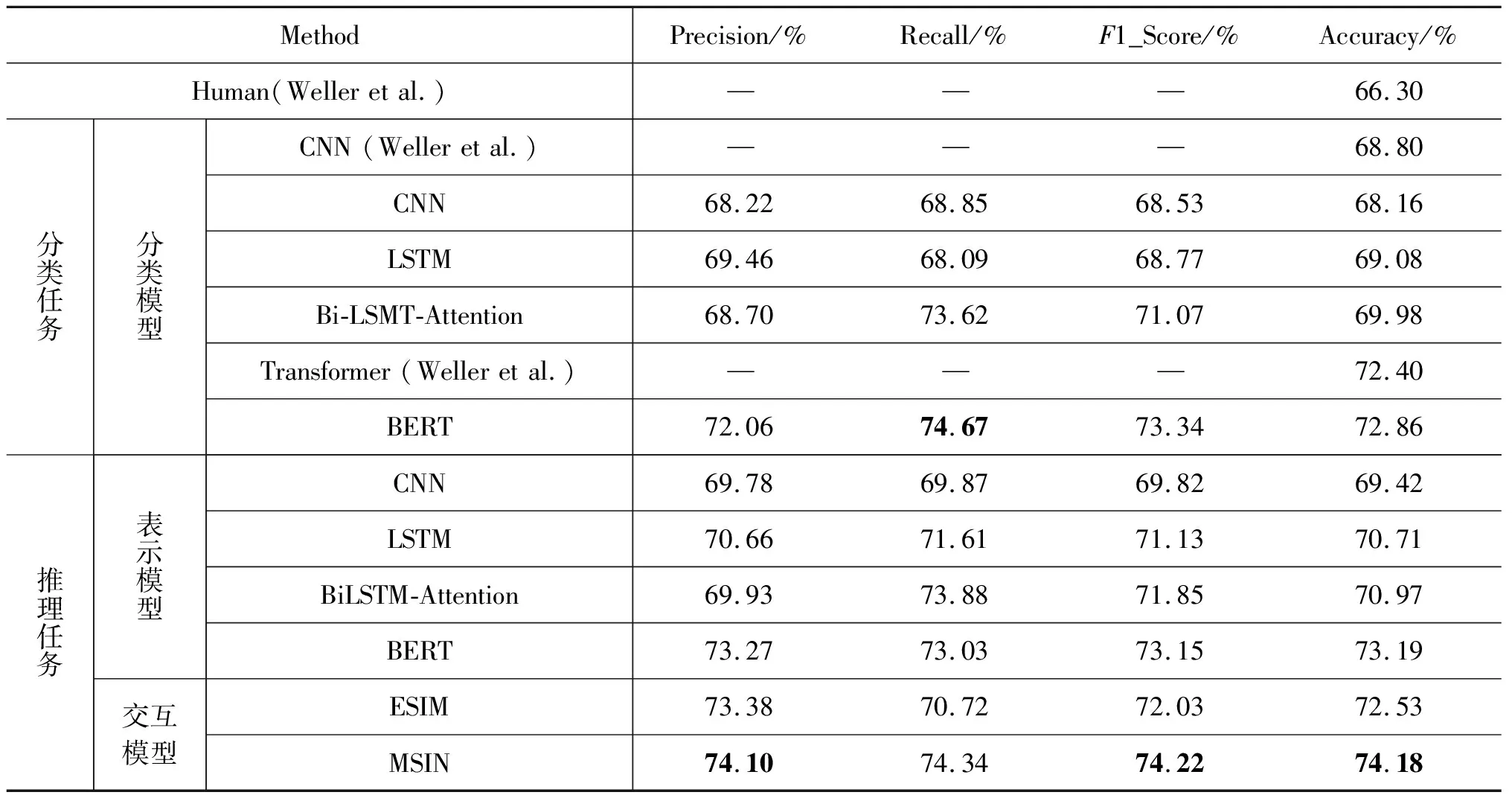
表3 Reddit数据集实验结果
在第二部分,本文使用的CNN与Weller等[5]的CNN结果相近,且两者均取得了明显好于人工预测的结果,证明了神经网络在幽默等级识别上的有效性。然而CNN由于卷积核尺寸固定,难以捕获长距离的语义关系,这对需要充分理解上下文的幽默等级识别任务是不利的。相比CNN,LSTM使用隐态向量捕获句子在长距离上的语义关系,可对时间序列进行有效建模,在数据集上取得了好于CNN的结果。然而LSTM是有偏倚的模型,后送入模型的信息会比先送入模型的信息拥有更大的权重,因此文本又使用Bi-LSTM+Attention进行改进。一方面,BiLSTM可以编码句子从前到后和从后到前两个方向上的信息,获取的特征更丰富;另一方面,Attention将所有时间步上的隐态向量赋予权重,让模型关注在文本分类过程中起关键作用的部分,缓解了由于LSTM的偏倚性造成的信息损失,因此模型相比LSTM取得了更好的结果。最后,本文使用BERT识别文本的幽默等级,其结果与Weller等[5]使用Transformer的结果相近,并且两者均明显优于之前的模型。
本文第三部分分别使用表示型和交互型两类模型进行幽默等级识别。
表示模型分别将“铺垫”和“笑点”编码为向量,然后将两向量与它们之间作差及点乘的结果拼接以捕获两部分的关系,最后基于拼接后的向量进行分类。为方便与第一部分的结果做比较,本文仍采用CNN、LSTM、Bi-LSTM-Attention和BERT四个模型。首先做内部比较,可以发现四个模型的结果依次递增,与第一部分的趋势保持一致;其次将表示模型与第一部分比较,发现四个模型的结果均高于第一部分中对应的模型,证明将幽默文本拆分为“铺垫”和“笑点”两部分,并让模型学习两部分之间的关系信息,有助于幽默等级的识别。
在交互模型部分,本文使用ESIM与本文提出的MSIN进行比较。ESIM通过计算两部分文本之间单词的相似度矩阵来构建局部语义交互表示,并以此来推断前后文本的关系,在没有大量预训练知识的情况下,取得了略低于BERT的结果。本文提出的MSIN综合考虑交互过程中局部和全局语义信息的影响,取得了好于ESIM的最优结果。
因此可以证明,相比表示模型,交互模型可以更好地捕捉到“铺垫”和“笑点”之间的关系;本文提出的多粒度语义交互理解模型融合单词和子句两个级别的交互信息,在幽默等级识别任务上取得了提升。
同时,本文进行消融实验,证明了词向量融合及多粒度交互两个结构的有效性,实验结果分别见表4和表5。表4前两行分别为只使用Glove和只使用Word2Vec的结果,第三行是使用融合词向量的结果,可以发现,融合之后效果更佳。表5前两行分别为只使用单词和子句交互的结果,第三行为融合两个粒度进行交互的结果,可以发现,多粒度交互网络取得了最优结果。
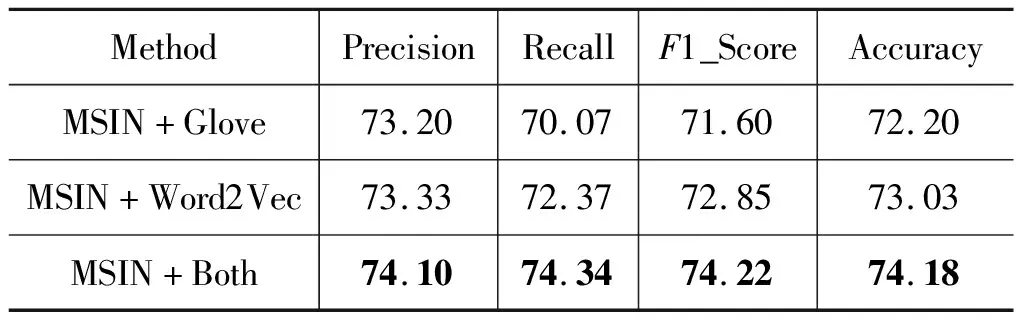
表4 不同词向量使用方式结果比较
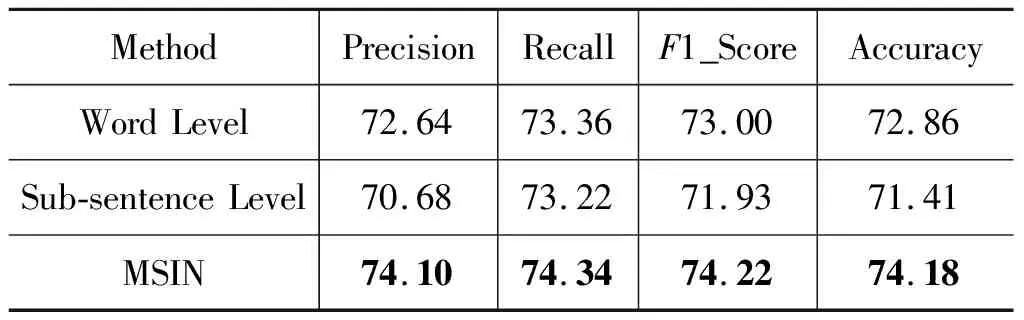
表5 不同粒度实验结果比较
4 结论
本文将幽默文本划分为“铺垫”和“笑点”两部分,发现对两者之间的关系进行建模可以显著提升模型识别幽默等级的性能。基于这个观点,首先,本文在融合多种嵌入表示的基础上,从局部和全局两个粒度来对幽默中的语义关系进行理解和建模。其次,本文对幽默中“铺垫”和“笑点”两部分的关联信息做交互建模,从而实现充分挖掘“铺垫”和“笑点”之间的关系。最后,本文在Reddit幽默数据集上进行实验,取得了最优结果,同时结合消融实验证实了模型设计的有效性。未来工作中,我们将在幽默文本自动切分及基于“铺垫”的“笑点”文本生成方面做更多的探索。
