面向工艺文本的命名实体识别方法研究
2022-04-19王裴岩张桂平蔡东风
贾 猛,王裴岩,张桂平,蔡东风
(沈阳航空航天大学 人机智能研究中心,辽宁 沈阳 110136)
0 引言
命名实体识别(Named Entity Recognition,NER)的主要任务是识别出文本中的人名、地名等专有名称和有意义的时间、日期等数量短语并加以归类[1],是机器翻译、信息检索、知识图谱等应用的核心组件之一。面向工艺文本的命名实体是对产品制造中所遵照或是产生的工艺标准、工艺大纲、工艺规范、指导书等文本中蕴含的工程图纸、参考标准、结构特征、零件和零件号、零部件属性和属性值等进行识别,对于工艺知识库构建[2-3]与工艺自动生成[4-5]等具有重要作用。
近年来,深度学习模型被广泛用于通用领域NER任务中,并表现出优越的性能。此类方法将命名实体识别转化为序列标注问题,基于RNN[6]、LSTM[7]或GRU[8]网络,预测每个字在实体中的构成成分。如文献[9]首先将LSTM应用于命名实体识别任务,取得了不错的识别效果。文献[10]首次将BiLSTM-CRF模型应用于NLP序列标注的命名实体识别数据集上,实验结果表明,BiLSTM-CRF模型相较于LSTM获得了更好的结果。文献[11]将BiLSTM与CNN进行结合,用于命名实体识别,取得了不错的识别效果。文献[12]提出了基于BiLSTM和基于Stack-LSTM两种神经网络模型,在四种语言上均获得了很好的识别效果。最近,针对中文的命名实体识别,文献[13]提出了一种融合字词的BiLSTM模型,在《人民日报》和MSRA语料上均取得不错的识别效果。文献[14]提出了一种神经网络结构Lattice LSTM,将潜在词信息融入到基于字符的LSTM-CRF中,在中文NER中,取得了目前最佳的效果。上述通用领域模型中均未引入外部知识,文献[15]研究并证明了外部知识对于命名实体识别的重要性。文献[16]从维基百科语料中获得地名词典,并将其作为特征加入到BiLSTM-CRF模型中训练,在两种不同的语言中获得了命名实体识别性能的提升。该方法将词典作为外部知识加入到模型中,未考虑规则这类外部知识,但在专业领域中,语料中大都含有大量的句型和构词规则,如何将这类规则和词典相结合提升实体识别效果是一个难点。
相较于通用领域,专业领域中命名实体的识别需要以该领域的知识为依据,并兼顾其语言规律特性,使得专业领域的命名实体识别具有一定的难度[15]。在化学领域,文献[17]针对化学资源文本的语言规律及特点,建立BiLSTM-CRF模型对命名实体进行初步识别,并使用基于词典与规则相结合的方法对识别结果进行校正;在军事领域,文献[18]针对军事文本的语法特点建立特征集合,基于CRF对军事命名实体进行识别,并依次使用基于词典的方法和基于规则的方法对识别结果进行校正;在小语种识别领域,文献[19]针对维吾尔语命名实体识别中存在的语义信息欠缺及数据稀疏等问题,基于BiLSTM进行初始识别,并将维吾尔语单语知识引入后处理校正模块。上述方法都关注在深度学习模型识别后,使用领域知识规则对个别实体结果进行修正,但并没有利用这部分知识在提高此部分实体识别效果的同时帮助其他实体的识别。其原因在于,“校正”方法只能对具有词典或规则的实体在模型识别后对识别结果进行校正,而对于没有词典或规则的实体,“校正”方法并不能在模型识别后通过后处理校正来提升该部分实体的识别效果,也就是识别模型与词典及规则相脱离,词典及规则指导信息没有利用于模型的训练与预测过程。
针对以上问题,本文面向工艺文本提出了一种融入领域知识的神经网络命名实体识别方法。该方法利用领域词典与规则预识别出部分实体作为预识别实体特征,提出一种神经网络模型CNN-BiLSTM-CRF,通过CNN网络利用预识别实体整体特征指导字序列标注模型的训练与预测。实验表明,本方法不但能够提高词典及规则覆盖的实体识别效果,还能够提高其他类实体的识别效果,优于其他参与比较的方法,实体识别的F1值从90.99%提升到93.03%。
本文的组织结构如下: 第1节阐述工艺文本的实体识别;第2节阐述CNN-BiLSTM-CRF网络结构;第3节对实验结果进行分析,验证了所提方法的识别效果;第4节作出结论。
1 工艺文本实体识别
本文在工艺文本中识别的实体涉及12大类(表1),这些实体表现出了如下特点。首先,因为某类编号或包含编号的实体比重很大,由于编号具有规则,所以能使用规则识别出此类实体。但由于同一套编号规则能够适用于不同类实体,也造成了歧义。例如,零件号与工程图纸号编号规则完全一致,又如,参考标准、工艺规范、方法图等编号规则有重叠。这就需要在使用规则识别的同时,使用上下文信息进一步消除歧义或修正规则识别结果。其次,常用标准件如“螺钉”与“轴承”等及结构特征如“孔”“凸台”等能够使用词典识别。但还存在“下防撞灯电源盒”等无法基于词典识别的实体。再者,工艺文本中的实体存在嵌套现象,如“铆钉孔”结构特征实体中嵌套有“铆钉”零件实体。这些特点就需要在使用深度学习模型识别实体的同时融入规则或词典信息,帮助模型训练及预测。

表1 工艺文本数据表
2 CNN-BiLSTM-CRF网络结构
本文提出了一种基于CNN-BiLSTM-CRF的神经网络模型,并将领域知识融入其中,用于工艺文本的命名实体识别。该模型将实体识别视为字序列标注问题,模型的输入为字序列,输出为字序列所对应的实体标记。首先将输入的字序列信息处理为字特征向量和实体预识别特征向量,然后分别通过CNN网络提取深层次局部字符级特征信息并将输出向量进行拼接,最后将拼接后的向量输入到BiLSTM-CRF网络中。基于BiLSTM,该模型能够有效利用工艺文本序列数据的上下文输入特征;基于CRF,该模型能够考虑输出标签之间的依赖性,输出最优标签序列。模型结构如图1所示,该模型由五部分组成: Input层、Embedding层、CNN层、BiLSTM层和CRF层。
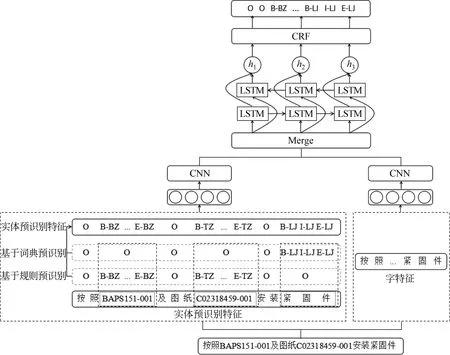
图1 CNN-BiLSTM-CRF命名实体识别模型
2.1 Input层
2.1.1 字特征
现有的命名实体识别有基于字[7]、基于词[10]以及字词联合[13]的三种输入方式。由于基于词的输入方式受分词结果的影响,并且没有专门的工艺文本分词工具,因此本文选用基于字特征输入的方式。将工艺文本数据按字进行切分,并统计每个字的出现次数,按从高到低进行排序。同时需要向字表中加入未登录字
2.1.2 实体预识别特征
实体预识别特征由基于词典的预识别特征和基于规则的预识别特征构成。基于词典的预识别是对零件和结构特征两种实体的预识别,基于规则的预识别是对工程图纸号、零件号、参考标准号、方法图和工艺规范五种实体的预识别。将上述预识别结果进行组合,为基于词典及规则的实体预识别特征,并将输入字序列对应的预识别实体标注结果转化为独热向量的形式表示。
2.1.2.1 基于词典的预识别
由于工艺文本中零件实体和结构特征实体存在嵌套交叉现象,如“高锁螺栓孔”,该实体为结构特征实体,但里面嵌套着“高锁螺栓”零件实体。为了提高该部分实体的识别效果,本文通过人工收集建立零件和结构特征命名实体库即词典,零件和结构特征词典大小为1 384,如“沉头螺栓”“自锁螺母”“导孔”等。依据该词典对输入字序列进行逆向最大匹配[20]并对结果做初始标注,如“沉头螺栓”标注结果为“B-LJ I-LJ I-LJ E-LJ”,将标注结果作为基于词典的预识别实体特征。
2.1.2.2 基于规则的预识别
经过人工分析发现,工艺文本中部分实体的上下文构成和构词本身存在一定的规律。本文通过分析这部分实体上下文和实体本身的用词特点,人工总结出一些启发式的句型和构词规则,制定出规则模板,依据该模板对输入字序列进行规则匹配并对结果做初始标注,将标注结果作为基于规则的预识别实体特征。句型规则示例如表2第1行所示,“按534GD601要求进行制孔”匹配规则“按BZ要求进行制孔”后,得到实体预标注序列“O B-BZ I-BZ I-BZ I-BZ I-BZ I-BZ I-BZ E-BZ O O O O O O”。触发词规则示例如表2第2行所示,“定位NAS578-5B”匹配规则“定位LJH”后,得到实体预标注序列“O O B-LJH I-LJH I-LJH I-LJH I-LJH I-LJH I-LJH I-LJH E-LJH”。构词规则示例如表2第3行所示,“GYGF036-078”匹配规则“GYGF数字串-数字串”后,得到实体预标注序列“B-GYGF I-GYGF I-GYGF I-GYGF I-GYGF I-GYGF I-GYGF I-GYGF I-GYGF I-GYGF E-GYGF”。下面介绍详细的规则模板说明。

表2 规则说明
(1)句型规则
工艺文本中频繁使用大量固定的句型,如“按照图纸……制……与……的导孔”、“根据……对……的调整检查”、“按……及参考……定位……并钻定位孔”等。其中,工程图纸号、参考标准号和零件号实体经常嵌套在上述结构中,并且零件后面一般紧跟其对应的零件号,此类句型归纳总结为25条。因此可通过对固定句型的识别来判定工艺文本命名实体中的工程图纸号、零件号和参考标准号实体。
(2)触发词规则
在句型规则中,经常包含一类固定的词,这些词的出现预示着工程图纸号、零件号和参考标准号实体的出现,将这些词称为触发词,如“按照BAPS151-001手工安装ZCB4023V3CR8粘接支架”,在上述例子中,参考标准号和零件号实体出现在“按照”和“安装”触发词之后。除上述触发词之外,还有“定位”“钻制”“拆除”等,此类触发词归纳总结为19个,在一定程度上标识着实体类别和边界。因此,本文建立了完备的触发词知识库来判定工艺文本命名实体中的工程图纸号、零件号和参考标准实体。
(3)构词规则
工艺文本中实体的内部构成存在一定的规律,如工艺规范实体“GYGF036-078”,是由“GYGF”作为开始字符,其后紧跟一个由数字和字母构成的字符串。有类似构词规律的实体还有方法图和参考标准实体。因此通过该构词规则来判定工艺文本命名实体中的工艺规范、方法图和参考标准实体。
2.2 Embedding层
文本向量化有两种表示方法: 独热表示和分布式表示[21]。分布式向量能够从大规模的语料中学习到单词间的语义相关性,并且可有效降低维度,本文采用分布式的向量表示。分布式表示使用Word2Vec[22]预训练模型,Word2Vec有两种实现模型: Skip-gram和CBOW。文献[23]对两种模型进行了比较,当语料规模在百兆级别时,CBOW模型表现更好。结合本文所用的语料,选用CBOW模型。
2.3 CNN层
CNN是有效提取句子局部特征信息的方法[24]。本文中预识别的实体特征形成了指导标注的局部特征,利用CNN提取该局部特征信息。图2是本文所用的CNN模型结构。对于每个输入,使用一个卷积层和一个池化层从每个输入特征向量中提取一个新的特征向量。在字符经过Embedding层输入卷积层之前,先经过一个Dropout[25]层。输入特征向量包括基于字的特征向量和实体预识别特征向量。
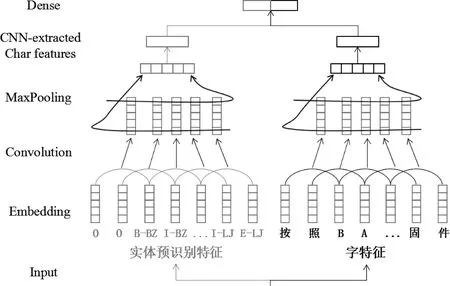
图2 CNN提取字符级特征
2.4 BiLSTM层
2.4.1 LSTM网络
LSTM是在RNN的基础上改进而来的一个模型,t时刻,给定输入xt,LSTM的记忆单元结构的内部实现如式(1)所示。
(1)
其中,W表示连接两层的权重矩阵(如Wxi表示输入层到隐藏层的输入门的权重矩阵),b表示偏置向量(如bi表示隐藏层的输入门的偏置向量),c表示记忆单元的状态,σ()和tanh()表示两种不同的神经元激活函数,i,f和o分别表示输入门、遗忘门和输出门。
2.4.2 BiLSTM网络

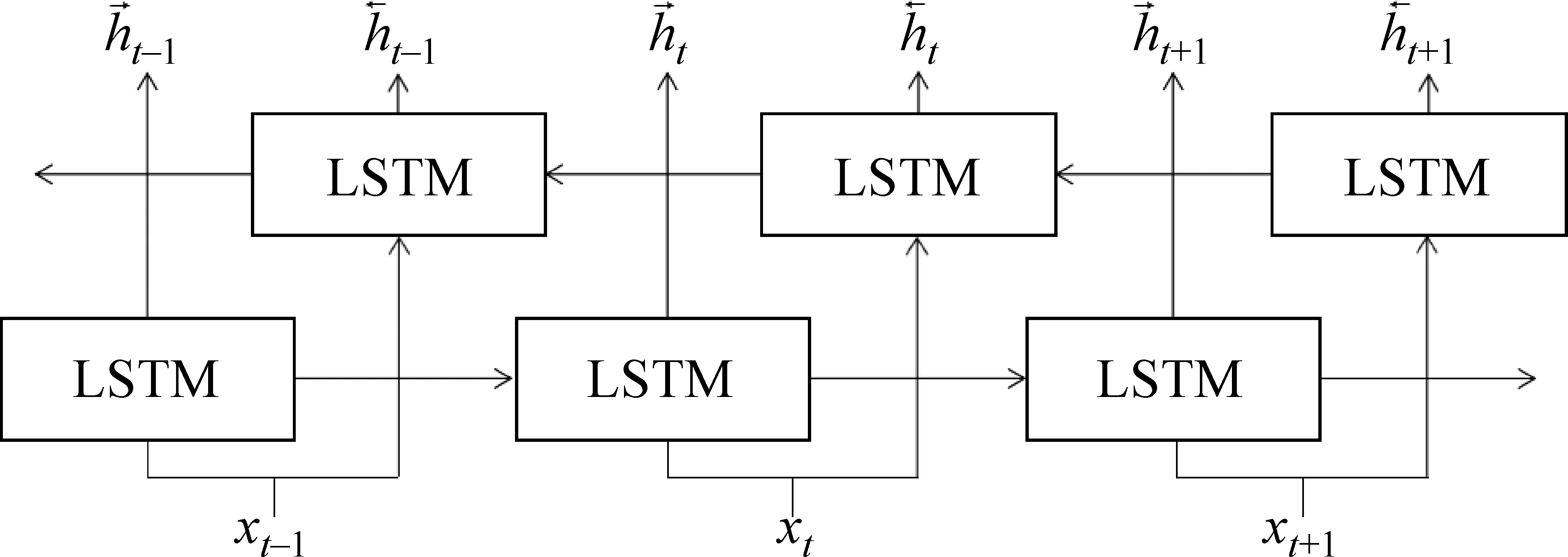
图3 BiLSTM模型结构
2.5 CRF层
CRF模型是Lafferty等[27]提出的一种判别式概率无向图学习模型。工艺文本命名实体识别任务的标签之间并不独立,具有较强的依赖关系,如文本中所识别零件实体LJ和工程图纸实体TZ,通常B表示开始的字,I表示中间的字,E表示最后的字,O表示非实体,B-LJ标签后面可能是I-LJ标签和E-LJ标签,但不可能是I-TZ标签。由于CRF能考虑相邻标签之间的关系,所以本文使用CRF对标签序列进行建模,而不是独立地对每个标签进行解码。
在这里,定义输入句子X、输出标签序列y的分值s(X,y),如式(2)所示。
(2)
其中,A是转移矩阵,表示将所有状态一步转移的概率;P是BiLSTM输出的矩阵,Pi,j是假设从第i个字到第j个字作为一个命名实体的得分。
为了最大化正确标签序列的概率,解码搜索条件概率最大的标签序列y*,如式(3)所示。
(3)
其中,YX表示y所有可能的标签序列。
3 实验结果与分析
3.1 实验数据集
本实验以某型飞机装配所遵照的工艺文本作为数据集,该工艺文本数据来源于工艺标准、工艺大纲、工艺规范和指导书中的操作说明语句,共10 350条,经过人工标注后为实验语料。该数据集中包含命名实体99 704个,实体类型如表1所示,平均句长为194个字,数据标注方式采用BIEO形式的标注方式。本文实验均在十折交叉验证下进行,并且取十次结果的平均值作为对算法精度的估计。
3.2 评价标准
本文主要通过准确率P(Precision)、召回率R(Recall)和F1值这三个指标来对工艺文本的实体识别结果进行评测。具体如式(4)~式(6)所示。
3.3 参数设置
本文采用基于batch的梯度下降优化超参数,其中批次大小为64,使用Adam优化器,并设置学习率为0.001;为了防止过拟合问题,设置Dropout参数为0.2;LSTM前向传播和反向传播的隐层节点数为200。CNN层设置卷积核大小为2,卷积核个数为200,卷积层数为1,采用ReLU()激活函数。具体模型最佳训练参数设置如表3所示。Embedding层使用Word2Vec的CBOW模型生成的向量,各参数取表4中的值时,模型的综合实验效果达到最佳。
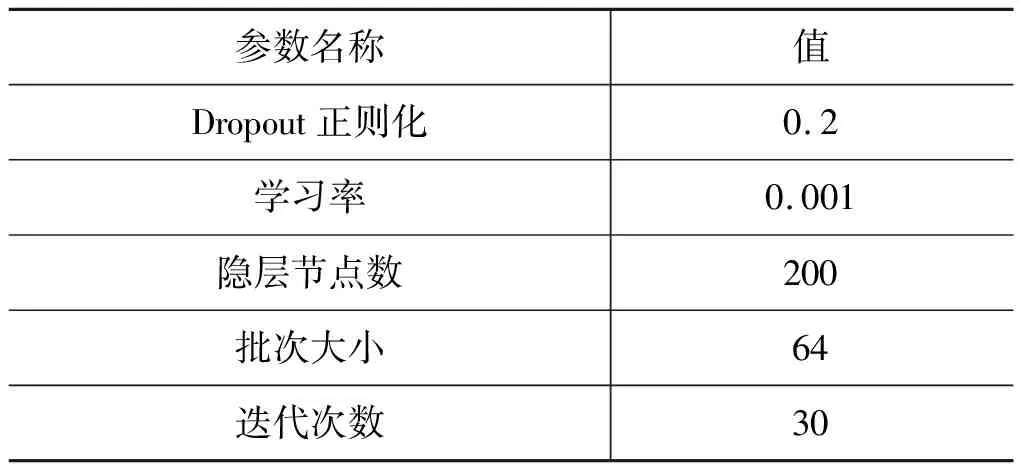
表3 最佳训练参数设置
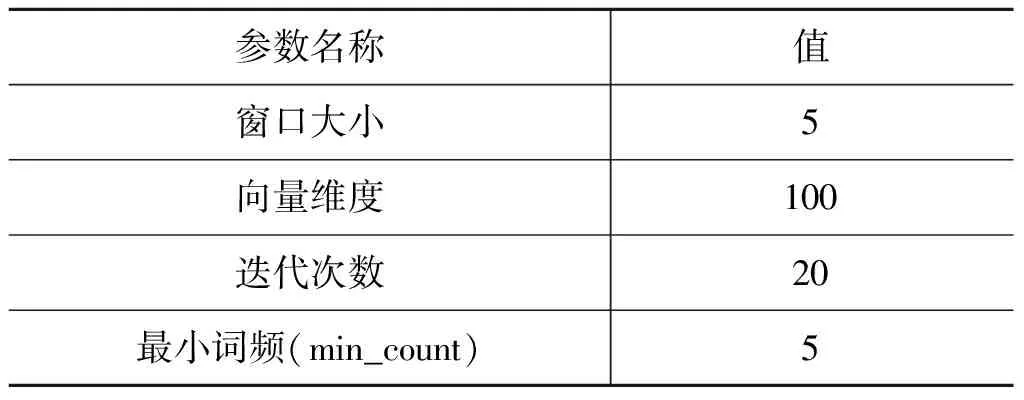
表4 CBOW模型参数表
3.4 对比实验
为了验证融入基于领域词典及规则预识别特征的有效性,本文设计了8组对比实验,如表5所示。模型均使用2.2节所提到的CBOW模型在中文维基百科语料上训练而成的100维的字向量。模型1~5的输入向量是基于字特征的向量,未加入额外特征;模型6使用的输入向量是基于字特征的向量,未加入额外特征,在模型识别后使用词典及规则进行校正;模型7中的Pre_dic表示的是在基于字特征输入的基础上,加入额外基于词典的预识别实体特征向量作为模型输入;模型8中的Pre_dic_reg表示的是在基于字特征输入的基础上,加入额外基于词典及规则的预识别实体特征向量作为模型输入。

表5 8种模型对比实验结果
对表5中的实验结果进行分析发现,模型1~5在基于字特征输入的对比实验中,模型5识别效果最好,准确率、召回率和F1值可达到88.59%、93.82%和90.99%。模型5和模型2相比,增加了CNN,其中模型5采用了模型2的BiLSTM-CRF层结构,准确率、召回率和F1值分别提高了0.08%、3.37%和1.52%,说明加入CNN用于提取工艺文本输入字向量中存在的局部信息是有效的;模型5和模型4相比,将模型4的BiGRU使用BiLSTM代替,准确率、召回率和F1值分别提高了0.24%、2.59%和1.29%,说明BiLSTM相较于BiGRU在本实验数据上表现出了更好的识别效果;模型6、7和8均采用了模型5的CNN-BiLSTM-CRF层结构。模型6和模型5相比,在模型5的基础上加入后处理“校正”,准确率、召回率和F1值分别提高了1.11%、0.69%和1%,说明在模型识别后使用词典及规则对部分实体校正后,该部分实体识别效果的提升使得整体的结果有了一定的提升;模型8和模型7相比,输入特征由字特征加基于词典的预识别特征变为字特征加基于词典及规则的预识别实体特征,准确率、召回率和F1值分别提高了1.1%、1.56%和1.25%,原因在于,基于词典的预识别只是对零件和结构特征两类实体做预识别,而基于词典及规则的预识别是在上述两类实体的基础上又增加了对零件号、工程图纸、参考标准、工艺规范和方法图五类实体的预识别,实体覆盖范围更广,向量中所隐含的特征信息更加丰富,使得模型表现更好;从模型8和模型6的对比实验结果可以看出,相较于使用词典及规则在模型识别后面校正的方法,将基于词典及规则的预识别实体特征加入到模型中效果更好,准确率、召回率和F1值分别提高了1.25%、0.85%和1.04%,究其原因,主要在于“校正”方法仅能用后处理的方法修正具有词典与规则的那部分实体的识别效果,不能帮助其他类实体的识别,而所提出的方法不但能够提高具有词典和规则的实体识别效果,还能帮助其他类实体的识别,该方法使得识别模型与词典及规则相结合,词典及规则指导信息更好地利用于模型的训练与预测过程,使模型整体的泛化能力更强,获得了更好的识别效果。
由2.1节可知,在工艺文本待识别的12种实体中,参考标准、结构特征、零件、零件号、工程图纸、工艺规范和方法图七种实体能用词典或规则的方法预识别出,识别结果如表6所示。
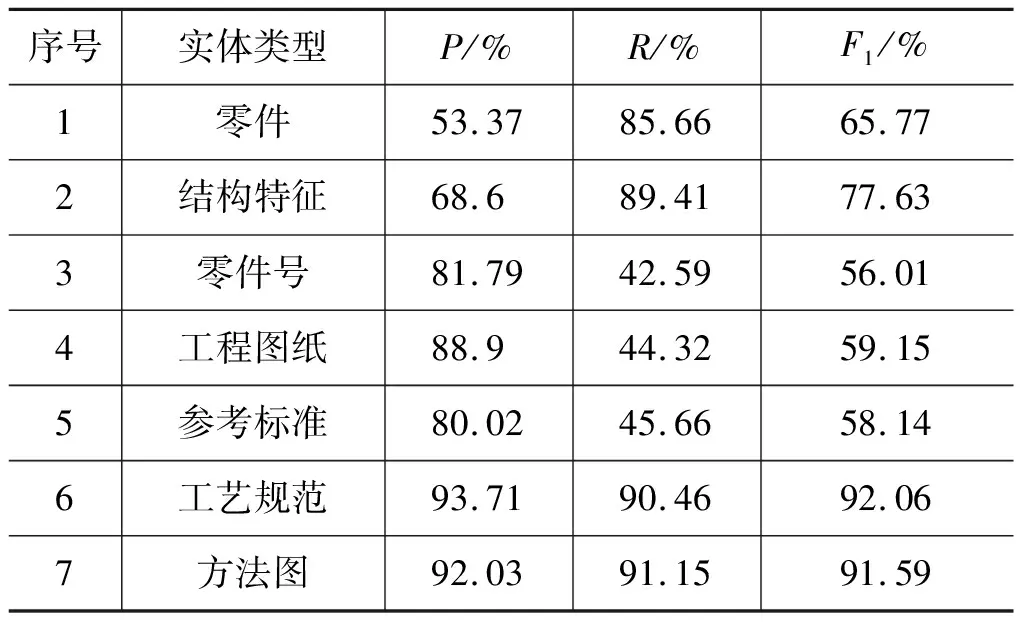
表6 词典及规则覆盖度
通过分析表6可知,工艺规范和方法图实体准确率和召回率都比较高,原因在于这两类实体规则较为明显,通过人工能很好地总结出构词规律。对于零件号、参考标准和工程图纸这三类实体,召回率较低,准确率较高,原因在于这三类实体的构词形式较多,只能从中总结出相对较为普遍的构词规律。对于零件和结构特征实体,召回率较高,准确率较低,主要在于零件和结构特征实体存在嵌套交叉现象,在基于词典进行逆向最大匹配的过程中会将两类实体混淆。
为进一步验证加入基于词典及规则预识别特征的有效性,对于工艺文本中的各类实体,选取表5中模型5、模型6和模型8三种模型做对比,其中,模型5是基于字特征输入中识别效果最好的模型,模型6是在模型5后使用词典及规则校正的方法,模型8是在模型5基础上加入额外的基于词典及规则的预识别实体特征。对于具有词典及规则的各类实体,模型对比结果如表7所示,对于无词典及规则的各类实体,模型对比结果如表8所示。
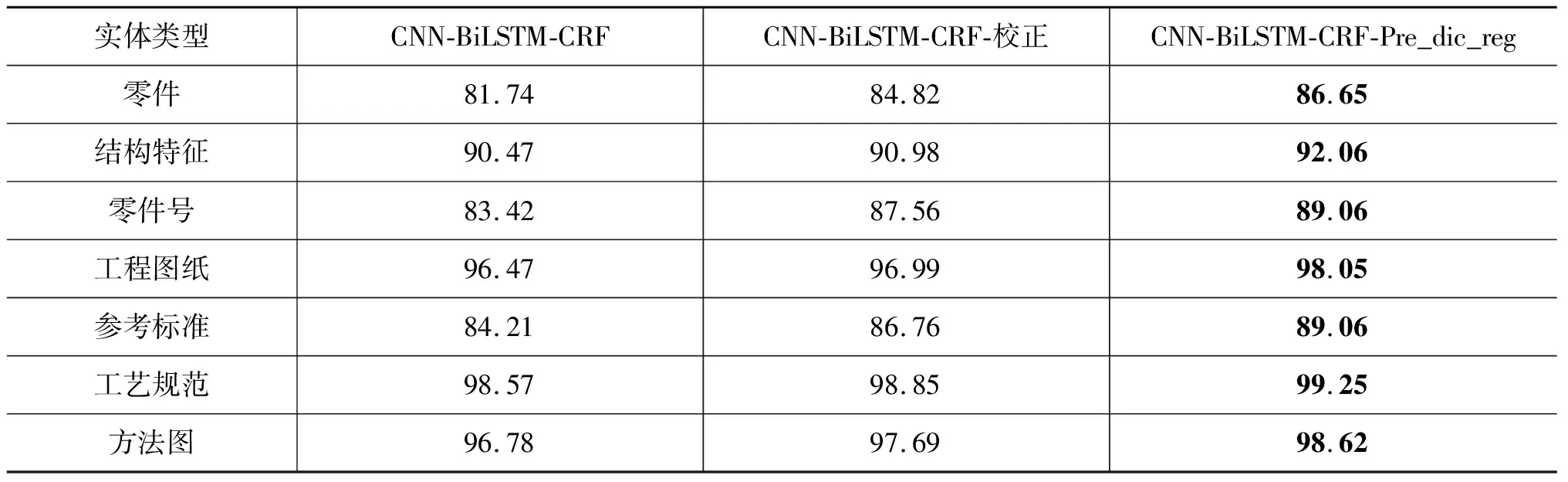
表7 具有词典及规则的各类实体识别结果 (单位: F1/%)

表8 无词典及规则的各类实体识别结果 (单位: F1/%)
通过分析表7可知,有词典及规则的各类实体在加入额外基于词典及规则预识别特征后,每类实体的F1值均有一定的提升,并且高于在模型识别后使用词典及规则校正的方法,说明这类实体在词典及规则信息特征的指导下,模型发挥出了更好的效果。从表8可以看出,“校正”方法仅能用后处理的方法修正具有词典与规则的那部分实体的识别效果,无法对无词典及规则类实体在模型识别后使用词典及规则进行校正,因此模型5和模型6在该类实体上识别效果一样,而本文方法不但能够提高具有词典和规则的实体识别效果,对于无词典及规则的每类实体的F1值也均有提高,主要原因在于向量的分布中隐含了额外的词典及规则指导信息,经过CNN-BiLSTM-CRF模型的抽象,可以更好地学习出来。也进一步说明了加入CNN和基于词典及规则的预识别实体特征后,在提高模型整体识别效果的同时,对于每一类实体均有提升,验证了本文方法的有效性。
4 结论与展望
现有的专业领域命名实体识别研究大都关注在深度学习模型识别后,使用领域词典及知识规则对个别实体结果进行校正,但并没有利用这部分领域词典及知识规则在提高此部分实体识别效果的同时帮助其他实体的识别。其根本原因在于,识别模型与领域词典及知识规则相脱离,词典及规则指导信息没有利用于模型的训练与预测过程。针对该问题,本文提出建立基于CNN-BiLSTM-CRF的神经网络模型用于工艺文本命名实体的识别,引入基于领域词典及规则的预识别实体特征,将其用来指导模型的训练与识别,实验表明,本方法可有效提高工艺文本命名实体识别的性能。同时本文提出使用特征提取器CNN,抽取工艺文本输入特征向量中存在的局部字符级信息,进一步提高了系统的性能。
未来工作中,我们将考虑模型在基于字输入的基础上融入词或者句子信息,期许能在模型隐层中提取出更多特征信息,获得更好的识别性能。
