联合多层注意力网络矩阵分解的推荐算法
2022-04-19李建红黄雅凡王成军丁云霞郑文军李建华钱付兰
李建红,黄雅凡,王成军,丁云霞,郑文军,李建华,钱付兰,赵 鑫
(1.安徽理工大学 人工智能学院,安徽 淮南 232001;2.安徽中科美络信息技术有限公司,安徽 合肥 230601;3.安徽大学 计算机科学与技术学院,安徽 合肥 230601)
0 引言
近年来,随着科学技术的发展,个性化服务开始应用于日常生活中如在线购物和电影推荐等,展现出蓬勃的生机。但是数据量爆炸式增长导致数据“过载”的情况使得用户无法获得较好的个性化服务体验。与此同时,这些数据往往能带来巨大的经济效益[1]。推荐系统应运而生,在缓解数据“过载”问题的同时还能提供较好的个性化推荐,并且能给商家带来可观的经济效益,如淘宝、亚马逊和京东等电商平台就大规模使用推荐系统。推荐系统的核心是推荐算法,协同过滤算法[2]是常用的推荐算法,其基本形式主要包括基于用户和基于项目两种。基于用户的协同过滤算法是计算用户间的相似性大小;而基于项目的协同过滤算法是计算用户所有的项目存在的相似性。最后预测出用户可能喜欢的项目。与项目总数相比,项目被用户评分的数据非常少,预测的准确性也会受到影响。随着数据的增加,数据的稀疏性会变得越来越大,从而导致获得用户偏好信息比较困难。因此许多研究人员在协同过滤算法的基础上改进的矩阵分解算法是现在许多推荐系统广泛使用的一种推荐算法[3-5]。矩阵分解的核心思想是根据用户和项目之间可以建立的某种关系,将用户和项目映射到相同的空间,然后利用算法学习用户和项目的低维度表示。最后采用点积作为匹配函数计算匹配得分。在此基础上,He等[6]提出了eALS算法,其做法是利用没有观察到的交互数据作为负采样,并利用项目流行度对其赋值。这类算法的缺点是没有充分挖掘用户对项目的偏好信息,无法获得较好的推荐效果。
近年来,以深度学习[7]为代表的人工智能技术不断在计算机视觉、自然语言处理和语音识别等方面取得突破性进展,原因在于深度学习技术对各种异构数据如图像和文本数据能够映射到同一空间中并学习到很好的向量表示,因此许多专家学者尝试将深度学习技术应用于推荐算法中,对用户与项目交互数据的特征表示进行学习,利用学习到的特征而获得用户对项目的偏好信息,从而提升推荐精度。Xue等[8]提出了深度矩阵分解技术(DMF),他们认为对输入信息分别设计用户神经网络和项目神经网络来学习较好的表示。相比于原始的矩阵分解算法,深度矩阵分解不仅采用点积获得匹配分数,同时还利用深度神经网络学习输入信息的表示,从而能够获得较好的推荐效果。
此外,由于深度学习具有强大的表示学习能力,许多专家学者提出了各种基于深度神经网络的推荐算法,如Cheng等[9]提出了Wide & Deep 算法并成功应用于APP推荐,其核心思想是利用Wide模型学习数据中的记忆信息。因为他们分析数据发现数据中存在“记忆信息”,即如果用户喜欢淘宝购物,那么他也有可能在京东商城购物;而对于Deep模型通过非线性结构学习用户对项目的偏好信息。Guo等[10]认为Wide &Deep 算法不能共享输入和参数优化。此外,钱等[11]在此基础上提出了深度混合模型(DeepHM)的推荐算法,使模型在共享算法和参数优化的情况下能够提升评分推荐的性能。但是这些算法只是简单利用深度神经网络而没有获得各用户和项目的权重值,即没有充分使用交互数据获得的关系信息。此外,随着深度学习技术的不断发展,注意力网络[12]也开始广泛应用于图像和自然语言处理等领域,然而很少有人将其结合矩阵分解技术应用于个性化推荐当中。
为了解决上述问题,本文提出了联合多层注意力网络的矩阵分解算法(MAMF)。首先,该算法扩展了深度神经网络框架,并加入原始点积操作而得到DeepMF,以获得用户的偏好信息。此外,在DeepMF基础上,加入多层注意力网络,从而使用户对不同项目分配不同的权重而得到DeepAMF;最后将两者结合得到MAMF。实验表明,相比于其他算法,该文提出的MAMF算法具有较好的推荐效果。
本文的主要贡献如下:
(1)对输入信息分别进行多层感知机学习和点积操作,获得用户对项目的偏好信息。
(2)在多层感知机中加入多层注意力网络和输出进行点积操作,是因为能够利用用户对不同项目分配的权重,从而能够获得不同用户对不同项目的偏好信息。
(3)将以上两点融合在一起并提出联合多层注意力网络的矩阵分解算法(MAMF),在多个数据集和算法上进行相关对比实验,实验结果证明了本文提出的MAMF算法的有效性。
1 相关工作
近年来,随着基于深度学习的算法在计算机视觉、自然语言处理等领域不断取得成功,很多专家学者将其应用于推荐系统中并获得了较好的推荐效果,包括深度矩阵分解技术(DMF)、宽度和深度学习算法(Wide & Deep)、深度混合模型(DeepHM)等算法,但是这些算法只是为了挖掘出用户潜在的偏好信息而无法准确地描述用户对不同项目的偏好。随着注意力机制的提出,很多学者利用注意力机制解释用户对项目的偏好。
王等[13]提出了融合注意力机制的深度协同过滤推荐算法(DACF),其做法是在项目特征中构建注意力机制学习用户偏好。He等[14]提出神经注意力项目相似性算法,其核心是通过注意力获知哪些历史项目对推荐更重要。张等[15]提出联合注意力机制和元数据的推荐算法,其做法是利用自动捕捉用户/项目关键属性对推荐性能的影响。张等[16]使用项目交互注意力网络感知不同历史项目与目标项目之间的交互关联度。但是这些基于注意力算法仅依赖注意力机制捕获一个用户对其他用户的权重,而忽略了原始数据信息对用户信息的重要性,并且层级间的特征表示如果没有注意力机制的表示则无法将偏好信息较好地保存,从而不能够获得较好的推荐性能。
2 问题定义
用户-项目交互信息是一种隐式反馈信息,因此无法反映出用户的喜好程度。此外,针对具有显式反馈的推荐问题的常见做法是对评分进行预测。类似地,为了解决带有隐式反馈的推荐问题,也可以将推荐问题转化为一个是否有交互的二分类预测问题,该问题与基于交互矩阵的评分预测的问题不一样。即预测用户与项目是否会发生未观察到的交互。但是,与显式反馈不同,隐式反馈是离散的二进制信息。因此,要解决以上二进制分类问题,一个可行的解决方案是对交互矩阵的值进行二值处理,根据He等[17]的方法:数据集中(数据集的评分值为1到5分)有评分记录则交互值设置为1,没有评分记录的则交互值设置为0。因此在Top-N的排序推荐中,这类推荐问题则转化为对于一个用户,存在一个项目是否给予推荐的二值推荐问题,即推荐或者不推荐,然后取前Top-N个概率最高的项目推荐给用户。
在介绍算法之前,首先定义一些操作符号,这样对理解MAMF算法很重要,本文中使用到的符号和意义如表1所示。

表1 本文的主要标识符
3 MAMF
本节主要介绍我们提出的MAMF算法,其框架如图1所示。整个算法框架包括两个部分:DeepMF 和DeepAMF。下文将逐一进行介绍。
在将数据传入MAMF模型中时,首先对数据做嵌入操作[18],如图1中Embedding层所示。其目的是将输入数据转换为嵌入向量表示,这样就能对数据进行统一表示,如式(1)、式(2)所示。
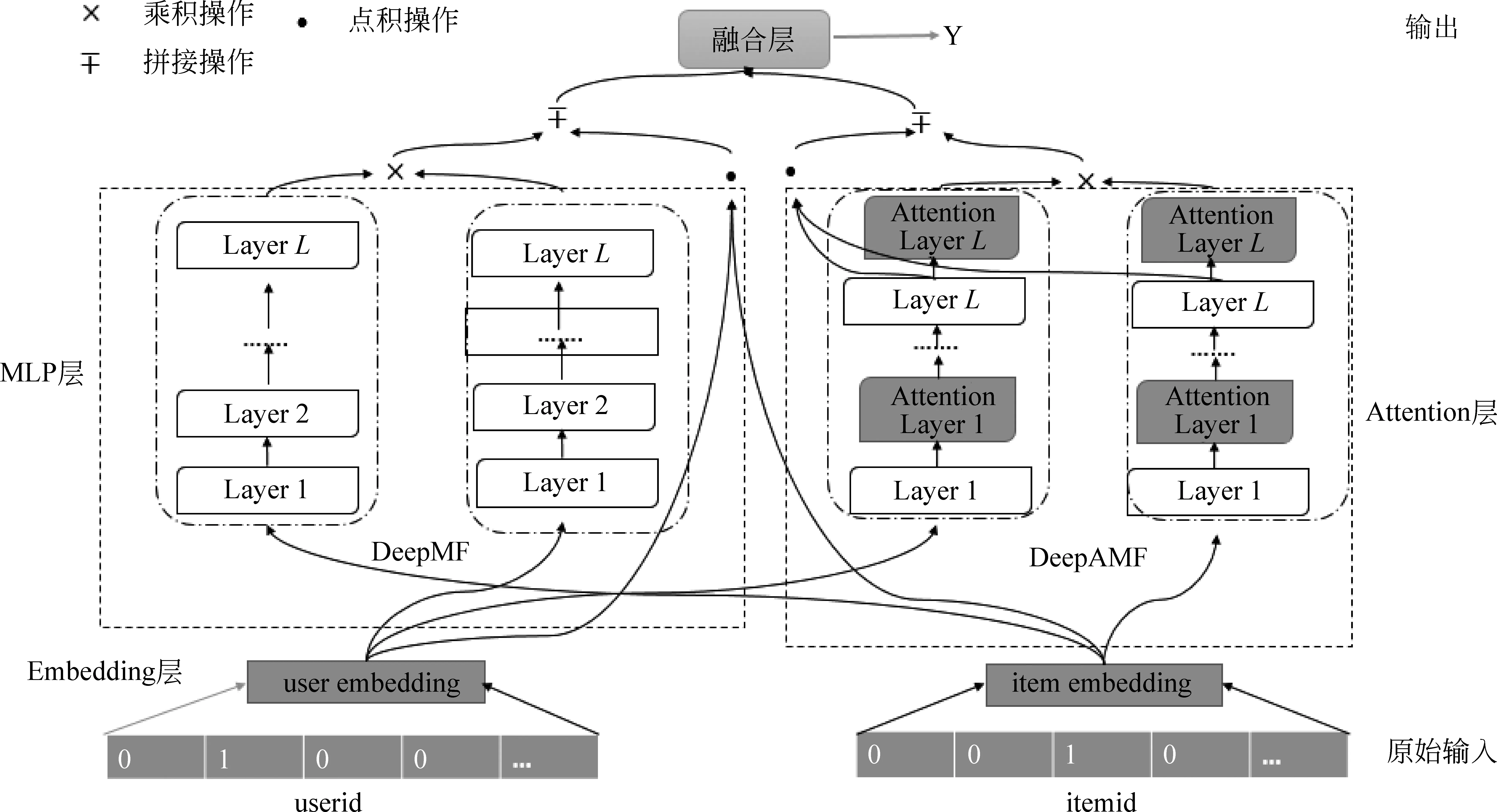
图1 MAMF算法框架
其中,embedded()函数表示嵌入操作,uemb和iemb分别表示用户编号和项目编号经过嵌入层操作后的结果。
3.1 DeepMF
在DeepMF算法中,当数据经过Embedding层处理过后,首先是直接采用点积的做法将信息融合,原因是能够获得原始数据中用户与项目的交互关系信息,这样就能得到用户对项目的偏好信息,计算如式(3)所示。
(3)
其中,,ui表示点积后的结果。
此外,经过Embedding层处理的输入数据还可经过多层感知机(MLP)[19]进行操作,这样就能得到输入数据的较好的特征表示,如式(4)、式(5)所示。
其中,b表示偏差。ul+1和il+1分别表示经过l+1层感知机运算后得到的向量结果,并且有u0=uemb,i0=iemb。利用多层感知机学习用户与项目特征表示后,再进行点乘操作,其目的是通过对用户和项目多层感知机学到的特征表示的向量相乘,从而得到较好的用户对不同项目的偏好信息,如式(6)所示。
(6)
其中,u×i表示乘积得到的结果。
通过对点积运算的结果与乘积运算的结果进行拼接,得到DeepMF的输出结果,如式(7)所示。
(7)
其中,u∓i表示拼接操作后得到的结果。
3.2 DeepAMF
根据图1 可知,DeepAMF相比于DeepMF的不同之处在于DeepAMF不仅在多层感知机中添加多层注意力(Attention),而且点积操作也是在最后进的。下面对DeepAMF进行详细介绍。
在输入数据经过Embedding层处理后,将传入MLP层,之后再传入Attention层[20],即MLP-Attention两层不断地迭层传递,其目的是获得相应输入信息的权重,从而得到较好的偏好信息,如式(8)~式(11)所示。
(8)
其中,dk表示向量维度为k维,fa表示激活函数为softmax激活函数。wa,wmlp,b和bmlp分别表示注意力网络层权重、多层感知机层权重、注意力网络层误差和多层感知机误差。umlp和ua分别表示多层感知机层和注意力网络层用户编号的向量表示。imlp和ia分别表示多层感知机层和注意力网络层项目编号的向量表示。因此,整个DeepAMF是MLP-Attention层迭层数据传入的,即MLP层的输出为Attention层的输入,而Attention层的输出则为MLP的输入,依此类推。
与DeepMF一样,输入数据经过MLP层和Attention层处理后,再对其进行点积操作和乘积运算,计算如式(12)、式(13)所示。
其中,uatt×iatt和umlp·imlp分别表示乘积和点积后运算的结果。
最后将点积运算结果跟乘积运算结果进行拼接,得到DeepAMF的输出结果,如式(14)所示。
(14)
其中,uatt∓iatt表示拼接操作后得到的结果。
3.3 MAMF
将DeepMF和DeepAMF的输出在融合层进行融合,这样就能得到用户对不同项目的偏好信息并输出预测结果,从而达到较好的推荐精度。融合层主要包括数据融合和一层MLP层运算,整个计算过程如式(15)、式(16)所示。
其中,Y表示输出结果,X表示整个输入信息。由于我们算法是Top-N推荐,因此是一个二分类问题:即如果Y=1,则项目y被推荐;否则不予推荐。fs()表示sigmoid激活函数。
通过上面描述可知,将DeepMF和DeepAMF合并成MAMF,就能够对两个模型进行联合训练,然后利用优化函数通过反向传播优化参数,从而获得最佳的推荐精度。
3.4 学习过程
为了使本文提出的MAMF算法能够获得较好的性能,作为一个二分类问题,我们这里使用交叉熵损失作为算法的最终训练的损失函数,如式(17)所示。
(17)
其中,n表示训练集大小,yj表示第j个项目是否推荐,即值为0或1,Y为标签值。
4 实验与结果分析
4.1 数据集
本文中使用在推荐领域中被广泛使用的4个公开的数据集来验证所提算法的优越性。这4个数据集分别是:
Movielens 1M(ml-1m):包括6 040个用户和3 706部电影,电影评分数量为1 000 209条记录。
Last-FM(lastfm):数据集包括1 741个用户,2 665个主题,评分数量为69 149条记录。
Amazon Music(AMusic):数据集包括1 776个用户,12 929个主题,评分数量为46 087条记录。
AmazonToys(AToy):数据集包括3 137个用户,33 953个主题,评分数量为84 642条记录。具体信息如表2所示。
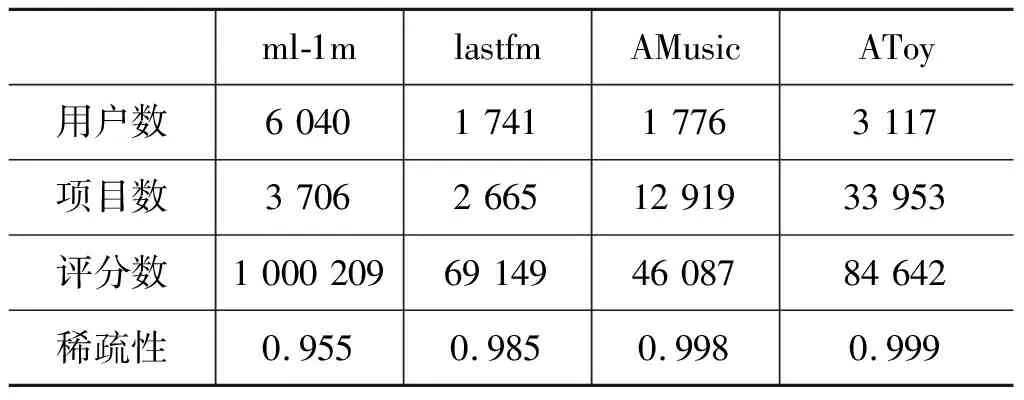
表2 数据集描述
根据表中对数据集的描述可知,用户与项目的数目越多,而评分数越少则数据稀疏性越高,其稀疏性XSX计算如式(18)所示。
(18)
4.2 评价指标
本文实验是进行Top-N推荐,即选取前N个项目推荐给用户,本文实验选取前10个即Top-10。因此我们选取命中率HR(Hit Ratio)和归一化折损累计增益NDCG(Normalized Discounted Cumulative Gain)这两个广泛应用于推荐系统中的评价指标作为算法的评价标准,其计算如式(19)、式(20)所示。
其中,|REL|表示具有用户项目连接对的格式,relj表示是否存在关系,值为0或者1。根据公式可知,这两个指标值越大,说明算法效果越好。
4.3 对比算法
本文采用的对比方法如下:
•ItemPop:常用的矩阵分解算法,其核心思想是根据项目的流行度进行推荐。
•eALS:基于矩阵分解的推荐算法,其核心思想是,对于没有观测到的用户与项目交互信息,则使用项目流行度来给它们赋值权重。
•DMF:基于深度神经网络的矩阵分解方法。
•Wide&Deep:联合Wide模型和Deep模型的推荐算法。
•DeepHM:基于Wide &Deep 模型的推荐算法。
•DACF:融合注意力机制协同过滤算法。
•NAIS:神经注意力项目相似性模型。
•DJRMA:融合元数据和注意力机制的推荐算法。
•DMRACF:基于双重最相关注意力网络的协同过滤推荐算法。
另外,还包括我们提出的DeepMF和DeepAMF算法。
4.4 算法训练参数
MAMF及其对比算法实验在ml-1m、AToy、AMusic和lastfm上进行。本文中的实验只使用用户编号、项目编号和评分三元组信息,不会添加任何其他信息。实验参数设置:使用随机梯度下降优化函数的一个变种Adam优化函数且学习率为0.000 1;MLP层为3层,注意力层也为3层;连接点分别为512、256和128。所使用的激活函数为relu,最后一层使用的激活函数为sigmoid做二值推荐。编程语言使用的是Python 3。整个模型基于Keras 构建,后端使用TensorFlow。实验使用的GPU为NVIDIA Tesla P100,其目的是来加速实验运行。
4.5 实验结果与分析
MAMF算法及其对比算法的实验结果如表3所示,根据表3中的实验结果可知:相比于基于矩阵分解方法如ItempPop、eALS和DMF在4个数据集上的HR和NDCG指标,MAMF都取得了不错的结果,这也证明了本文提出的算法的优越性。即通过DeepMF和DeepAMF两个模型充分挖掘用户对不同项目的偏好信息,因此能够获得较好的推荐效果。
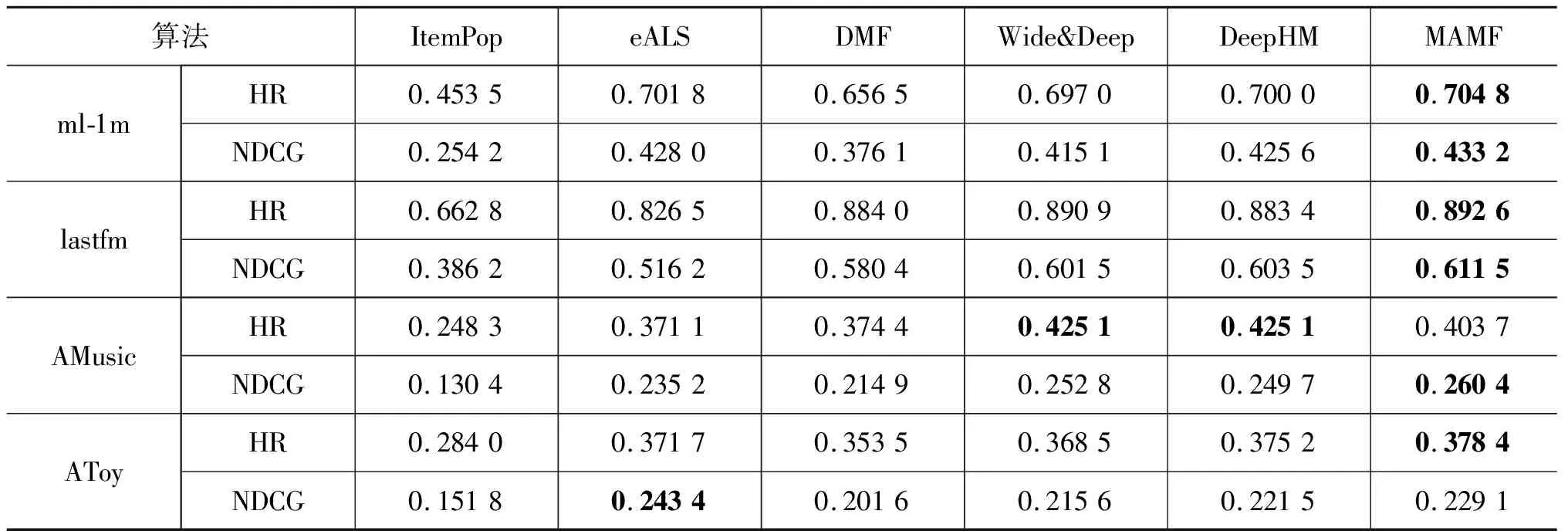
表3 MAMF及其对比算法在几个公开数据集上的实验结果
与此同时,我们也注意到表中的实验结果,即MAMF算法在AToy数据集上NDCG的指标与eALS算法相比,没有达到最优的实验结果;同时在AMusic数据集上我们的MAMF算法也没有获得最优的实验结果。结合表2中的数据集统计分析后我们认为是AToy和AMusic项目数目过多导致MAMF算法中用户对不同项目的权重值划分较低,导致算法的精确度不够好,影响了我们算法的推荐精度。
Wide & Deep及其扩展算法DeepHM在4个数据集上的HR和NDCG实验结果可知,除了AMusic数据集的HR指标外,MAMF算法都是最好的实验结果,这也说明MAMF算法在不同的数据集上都能获得较好的推荐性能。根据表2中对数据集的描述,我们认为原因也是数据集中用户与项目的比例过小,导致MAMF算法无法学到较好的偏好信息而无法获得较好的推荐效果。综合以上分析,我们认为MAMF算法在4个数据上的推荐精度均有一定的提升。
此外我们也对比了DeepMF,DeepAMF和MAMF算法,实验结果如表4所示。根据实验结果可知,MAMF算法在几个数据集上都有不同程度的精度提升,这也证明了本文提出的MAMF算法的优越性。同时我们也注意到DeepAMF在AMusic上的结果优于MAMF算法,故认为是DeepMF与DeepAMF融合输出时,影响到用户学习对不同用户分配权重,这也使得用户能获到较好的偏好信息,从而导致DeepAMF的HR指标相比于MAMF算法的结果提升了0.18%。另外,我们需要注意的是,相比于基于矩阵分解的对比算法如ItemPop、eALS和DMF等DeepMF和DeepAMF在几个数据集上均有不同程度的精度提升。因此,我们提出的基于深度学习的多层注意力网络矩阵分解算法具有较好的推荐效果。
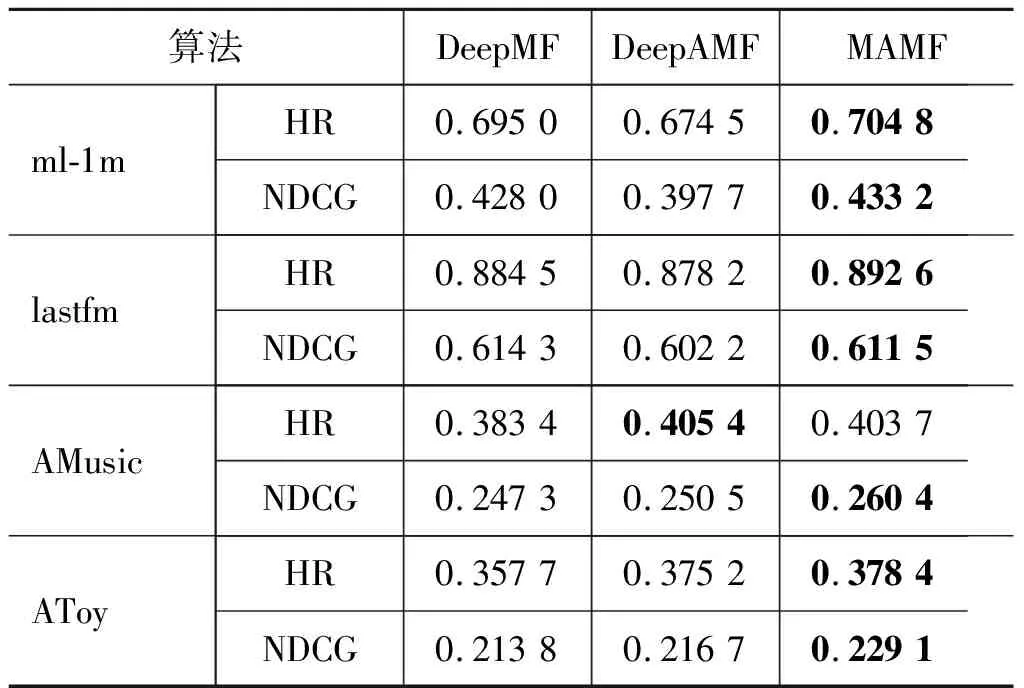
表4 DeepMF,DeepAMF和MAMF实验结果
我们将相关注意力机制推荐算法在ml-1m上进行比较,其结果如表5所示。根据结果可知,我们的推荐算法在NDCG上还是保持较好的推荐系统,但是在HR指标上则比DJRMA算法低,其原因我们认为是DJRMA主要是利用现矩阵非线性分解以学习用户/项目个性化关系结合注意力机制来获得较好的推荐性能,而MAMF单纯依赖交互信息和注意力机制,因此未能在NDCG上取得令人满意的结果。

表5 不同注意力机制推荐算法和MAMF在ml-1m上的实验结果
最后,对本文提出的MAMF算法进行模型适用性的分析,通过表3、表4的结果可知,当数据的稀疏性较高的时候,MAMF算法的性能则不能获得最优解,主要是因为当用户与项目数目较多,而整体交互记录较少时,算法会对很多的项目进行权重分配,而过多的项目导致各项目权重值较小,致使推荐项目出错。例如,当一个用户只与10个项目过交互记录,而整个数据集中项目多达10万个左右,此时注意力机制分配给每一个项目的权重可能是1/100 000=0.000 001,而当训练完成后,有的权重可能低于0.000 001,有的则高于0.000 001,但是权重之间的差别还是很小,接近于0。因此算法很容易出现错误解,不能很好地获得推荐性能。相对来说,稀疏性低的数据集上的推荐效果比较好。
5 总结
本文提出了一种基于矩阵分解和多层注意力网络模型的新型Top-N推荐算法——联合多层注意力网络的矩阵分解(MAMF)。它可以充分利用用户-项目信息矩阵来获取用户对项目的排序信息和权重信息,从而得到用户对不同项目的偏好信息,即使数据稀疏也具有良好的推荐能力。由于文本信息如用户年龄、项目主题等能很好地刻画用户的偏好,这对于推荐系统性能的提升具有帮助。此外,知识图谱[21]对社交网络和人物画像等具有较好的刻画效果。接下来的工作是结合MAMF算法和知识图谱扩展算法框架使其推荐效果更好。
