基于改进ShuffleNet V2模型的苹果叶部病害识别及应用
2022-04-19周云成刘忠颖李昕泽
张 旭,周云成,刘忠颖,李昕泽
(沈阳农业大学信息与电气工程学院,沈阳 110161)
我国是世界上最大的苹果生产国和消费国,苹果产业在国民经济中占据着重要地位,大力发展苹果产业有利于提高苹果种植户的收入水平,促进当地经济发展,是带动种植户脱贫致富的有效途径。然而,在苹果种植过程中,经常会发生病害,从而影响苹果的产量和质量,给种植户带来经济损失。因此,快速、准确地识别出苹果病害,并及时给出相应措施,指导种植户正确用药,对降低病害造成的经济损失,增加苹果产量,以及促进苹果产业的发展等具有重要意义。
近年来,卷积神经网络(convolutional neural network,CNN)在图像识别任务中取得了巨大的进展,并逐渐在植物病害识别中得到了应用。龙满生等应用AlexNet网络,通过迁移学习实现了油茶病害的识别;赵立新等应用改进AlexNet网络对棉花叶部病虫害进行识别;许景辉等通过改进VGG16网络,在小样本玉米叶部病害识别上获得了理想的识别效果;王忠培等使用5种经典网络模型对常见水稻病害的识别进行了分析比较;张文静等使用Inception V3网络实现了5种常见烟草病害的识别;张宁等基于该网络,提出了一种基于多尺度和注意力机制的番茄病害识别方法;DECHANT等对多个CNN进行集成,实现了玉米斑病的识别;金瑛等用ResNet-50网络实现了4种常见果树病害的识别,且取得较高的精度。
尽管CNN已经在植物病害识别中取得了较好的效果,但由于其本身的计算复杂度和存储空间的需求量,使其很难应用在移动或嵌入式设备中。轻量级CNN的发展使得在移动设备上部署病害识别模型成为了可能。刘洋等比较了MobileNet和Inception V3两种网络模型在手机上的识别精度、运算速度和网络尺寸等;冯晓等基于MobileNet V2网络,在手机上实现了3种小麦叶部病害的快速识别;石晨宇等基于改进GhostNet网络,实现了3种番茄叶部病害的识别;洪惠群等在ShuffleNet V2 0.5×网络的基础上进行改进,实现了多种作物叶部病害的快速识别。然而轻量级CNN的识别准确率一般会低于大型网络模型。因而如何提升准确率,并在精度和速度上适当平衡,是轻量级CNN设计的一个待解决的问题。
鉴于以上问题,本研究构建不同场景下的苹果叶部病害图像数据集,在分析轻量级CNN模型ShuffleNet V2结构的基础上,对该网络模型进行改进,以期构建一个轻量、准确且适用于不同场景下苹果叶部病害识别的诊断模型,并实现其在移动设备上的应用部署。
1 苹果叶部病害数据集构建及增广处理
苹果叶部病害图像数据集来源于PlantVillage工程和Kaggle植物病理学2021挑战赛中使用的数据。其中PlantVillage图像数据为简单背景下的苹果叶片图像,拍摄于实验室,背景为白、黑板,叶片位于图像中心,且占主要位置。Kaggle图像数据则拍摄于果园真实环境,背景复杂,且图像中含多个叶片。图像数据集共包括4个类别,分别为苹果健康、疮痂病、黑腐病和锈病叶片,各类别图像的数量及来源见表1。
表1 各类别图像的数量及来源
Table 1 Number and source of imges in each class
?
为降低叶部病害诊断模型在训练过程中的过拟合风险,并提高其泛化效果,在现有图像数据基础上,采用数据增广方法对样本进行扩充。采用的主要方法包括添加高斯噪声、添加椒盐噪声、图像平移、调整图像明暗度和图像旋转(分别逆时针旋转90°,180°,270°),这些方法均采用OpenCV开源计算机视觉库中的相关函数实现。经过数据增广后的最终数据集,共包含40000张RGB图像,每类图像各10000张。从最终数据集中分别随机抽取70%作为训练集,20%作为验证集,10%作为测试集,用于后续试验。
2 网络结构设计及改进
2.1 ShuffleNet V2网络模型
现有研究通常采用FLOPs(浮点数运算量)作为网络计算复杂度的评价标准。然而FLOPs只能在理论上评估模型的复杂程度,仅将其作为衡量网络模型好坏的评价指标是不充分的,还应考虑网络的实际推理速度和计算延迟等。在网络推理过程中,除卷积运算以外,还存在一些影响计算速度的其他因素,如内存访问成本和并行等级等,且相同FLOPs的网络在不同计算平台上消耗的时间也是不同的。MA等提出了网络高效设计的4条准则:(1)卷积层输入和输出特征图的通道数应保持一致,此时内存消耗最小、运行速度最快;(2)分组卷积中分组的数量与网络运行速度成反比;(3)降低网络的分支数量,能降低并行度,提升运行效率;(4)不能忽视元素级操作对网络运行速度的影响。根据上述4条准则,设计了基本残差单元(图1a),并在此基础上,构建了ShffleNet V2网络(图1b)。
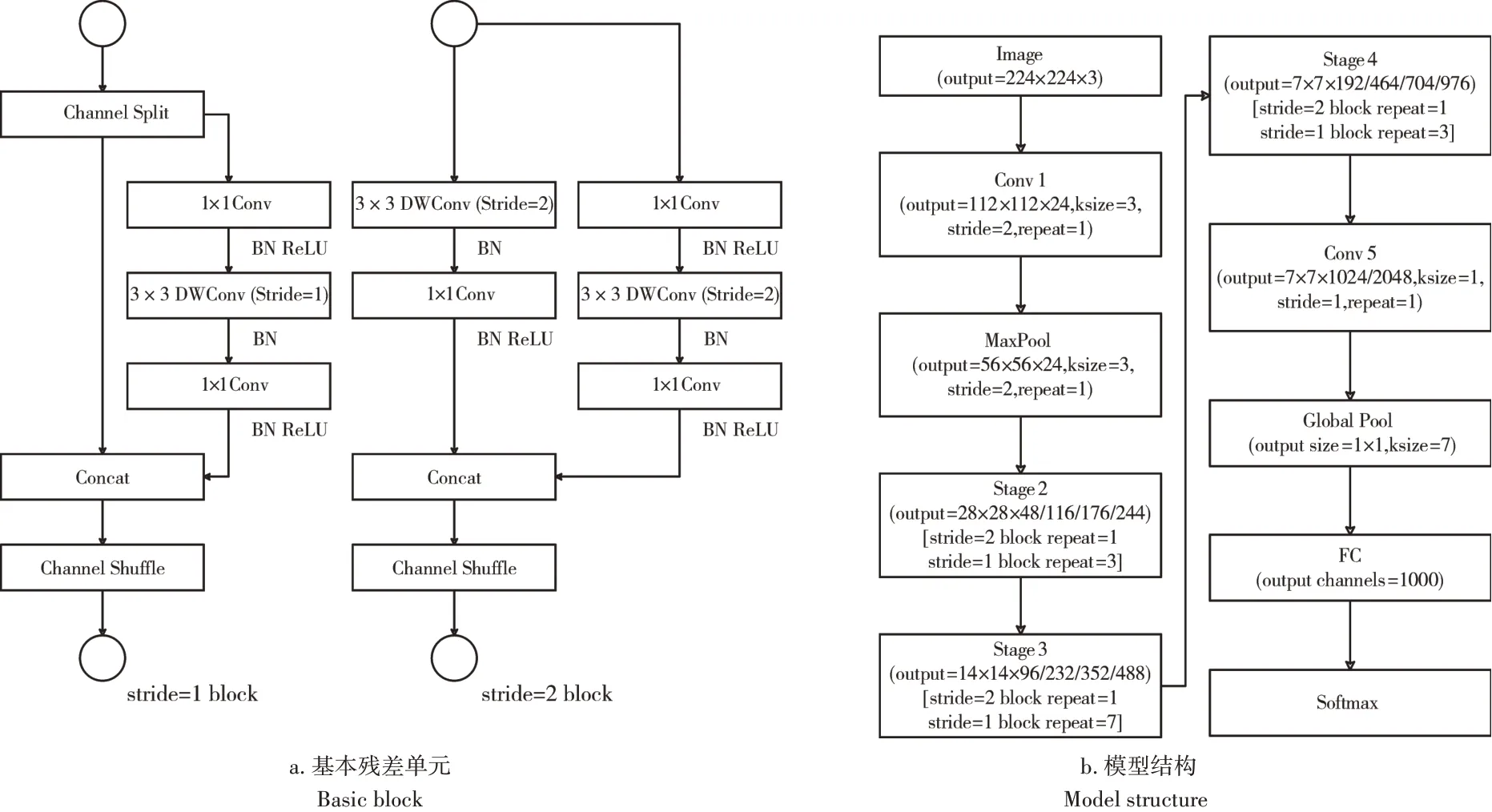
图1 ShuffleNet V2模型Figure 1 ShuffleNet V2 model
基本残差单元(block)是一种高效的轻量级卷积模块,其共有两种结构。其中一种首先在输入端进行一次通道分割,将输入特征图分为两个分支,其中主分支含3个卷积操作,中间操作为3×3深度可分卷积,两端为1×1点卷积,侧分支则为恒等映射。另一种结构为了加倍输出特征图,在输入端不进行通道分割,该结构的主分支同样为3个卷积操作,其中深度可分卷积的步长(stride)为2,侧分支则包含1个stride=2的深度可分卷积和1个点卷积。block在输出端通过通道拼接(concat)合并两个分支的输出特征图,并进一步对合并后的特征图进行通道混洗(channel shuffle)。该操作采取一种通道稀疏连接的方式,首先将输入特征图按通道划分为若干个子组,再分别交由不同的卷积核做组卷积。为了解决堆叠多个组卷积可能会造成某个通道的输出只来自于一小部分输入通道的问题,随机地抽取不同子组进行重新排列成新的特征图,使下一次组卷积能融合来自不同组的输入特征信息,从而加强了通道组之间的信息流动,保证了输入和输出通道之间是完全相关的。Shuf⁃fleNet V2网络包括Conv1层、MaxPool层、Stage2层、Stage3层、Stage4层、Conv5层和FC层,其中Stage2层、Stage3层、Stage4层是由上述block堆叠组成,Stage2层和Stage4层共堆叠4个block,Stage3层共堆叠8个block,每个Stage中的第一个block的stride=2,主要用于下采样,其他均为stride=1的block。可以通过缩放网络结构中各层的输出通道数量来设计不同复杂度的网络,以ShuffleNet V2 1×为基准网络,其Conv1层、MaxPool层、Stage2层、Stage3层、Stage4层、Conv5层、FC层的输出通道数量分别为24,24,116,232,464,1024,1000。本研究参考该网络,设计苹果叶部病害诊断模型。
2.2 网络结构改进
在CNN中,点卷积通常用于调整特征图通道数和通道间信息融合。在block中,由于主分支各卷积操作的输入、输出通道数一致,两端的点卷积不会用于通道调整,只起到信息融合的作用,保留两端的信息融合有可能是冗余的。因此,本研究移除了主分支末端的点卷积,用于降低计算量,修改后的结构如图2a。为了减少可能由此产生的精度损失,进一步对ShuffleNet V2网络结构进行了改进,设计出一种名为ShuffleNet#的网络。首先重新设计了网络宽度,将Conv1层、MaxPool层、Stage2层、Stage3层、Stage4层、Conv5层、FC层的输出通道数分别设计为32,32,240,480,960,1024,4。改进后的block和网络结构如图2b。现有研究表明,在CNN模型中,引入自注意力机制,可显著提高模型的性能,因此本研究也采用这一思想,分别在Stage2层、Stage3层、Stage4层的最后一个block之后加入一个CBAM模块(图2c)。该模块“串连”了通道注意力模块(channel attention mod⁃ule,CAM)和空间注意力模块(spartial attention module,SAM)。在CAM中首先将输入特征图分别基于宽高进行一次全局最大池化(global max pooling,GMP)和全局平均池化(global average pooling,GAP),将得出的结果送入到一个两层的多层感知器(multilayer perceptron,MLP)中,将MLP的输出进行相加并使用Sigmoid进行激活作为该模块的输出。SAM是将CAM的输出和原始输入特征图做乘法的结果作为该模块的输入,首先进行一次基于通道的GMP和GAP,再将输出的2个单通道的特征图进行concat,然后进行一次卷积操作并使用Sigmoid进行激活作为该模块的输出。最终将经过这2个模块的输出和原始特征图做乘法作为最终的输出特征图。原始特征图通过CBAM模块后,分别进行了一次通道注意力加权和空间注意力加权,加强了各通道之间的联系并使网络更加关注特征图中对分类起决定性作用的像素区域,从而使网络可以有选择性地强调和抑制某些信息,提升了网络的性能。并且该模块是一个即插即用的轻量级模块,将其集成到现有网络架构中并不会打乱网络原有的主体结构且只会增加少量的计算量。

图2 改进模型Figure 2 Improved model
3 模型试验及评估方法
3.1 模型训练及测试
在PyTorch深度学习计算框架基础上,采用Python实现了ShuffleNet#网络模型及相应评估程序。采用Ad⁃am优化算法对网络参数进行优化训练。在训练过程中,将图像尺寸调整为224×224像素,并进行数据增广后输入网络模型。用小批量随机梯度下降法更新网络参数,每批次样本数设置为64,初始学习率设置为0.02,每训练一个代次(epoch)学习率乘以0.95。预试验表明,经过50个epoch迭代后,模型的损失函数和精度可收敛到稳定值。所有试验均在一台配置为Inter Xeon E5 V3 2600处理器、NVIDIA GeForce RTX 2080 Ti 11GB计算卡、Linux Ubuntu 18.04操作系统的服务器上进行。
3.2 模型评估标准
采用精确率(precision)、召回率(recall)、特异度(specificity)、F
1分数(F
1 score)和准确率(accuracy)评估网络性能。其中,精确率反映的是模型识别出的所有正样本中,识别正确的比例;召回率反映的是所有真实正样本中,模型识别正确的正样本的比例;特异度反映的是所有真实负样本中,模型识别正确的负样本的比例;F
1分数为精确率和召回率的调和平均数,是兼顾了二者的综合评价指标;准确率反映的是模型识别出的所有正样本占总样本数的比例。其公式分别为式(1)~式(5)。
TP
(true positive)为网络识别正确的正样本的数量;TN
(true negative)为网络识别错误的负样本的数量;FN
(false negative)为网络识别正确的负样本的数量;FP
(false positive)为网络识别错误的正样本的数量。4 结果与分析
4.1 不同CNN模型对比
为分析比较ShuffleNet#网络的性能,本研究引入4种大型CNN模型ResNet18、ResNet34、ResNet50、ResNet101和9种轻量级CNN模型EfficientNet-B0、MobileNet V2、MobileNet V3-small、MobileNet V3-large、GhostNet、ShuffleNet V2 0.5×、ShuffleNet V2 1×、ShuffleNet V2 1.5×、ShuffleNet V2 2×。不同网络训练过程中图像预处理方式和超参数等设置相同。对上述网络的训练集准确率、验证集准确率、测试集准确率、FLOPs、参数规模、内存消耗、模型大小和推理时间8个评价指标进行统计,结果见表2。其中推理时间是将网络部署到型号为vivo iQOOV1824A,处理器为8核骁龙855,运行内存为12GB的Android手机上进行推理测试,以识别100张图像的平均时间作为最终结果。
由表2可知,本研究构建的ShuffleNet#网络的训练集准确率为98.63%,在所有模型中最高。验证集准确率为98.73%,低于ResNet34、ResNet50、ResNet101、EfficientNet-B0模型。测试集准确率为98.95%,仅低于ResNet101模型,在轻量级CNN模型中最高。FLOPs、参数规模、内存消耗、模型大小、推理时间分别为3.52×10,3.95×10,30.00MB,11.35MB,39.38ms,上述5个性能评价指标在轻量级CNN模型中表现并非最好,但是相比于大型CNN模型具有较大的优势。和大型ResNet101模型相比,本模型在测试集准确率仅降低0.05%的情况下将FLOPs、参数规模、内存消耗、模型大小、推理时间分别缩减95.51%、91.12%、81.45%、93.03%、87.94%。通过上述分析可知,ShuffleNet#网络是一个高效的轻量级网络模型,综合诊断性能良好,很好地解决了大型CNN模型在移动设备上部署困难以及轻量级CNN模型识别精度不高的问题,更适合在移动设备上部署。
表2 不同模型的对比
Table 2 Comparison of different models
?
4.2 苹果诊断模型性能及类间误识别分析
为进一步分析苹果叶部病害诊断模型在各类苹果叶部病害上的识别性能,用其对测试集中的4000张图像进行分类识别,结果如表3。同时为分析类别间的误识别问题,采用混淆矩阵来可视化各类别间的易混淆程度,结果如图3。
由表3可知,病害诊断模型对4个类别图像的识别精确率均在97.93%以上,召回率均在97.80%以上,特异度均在99.30%以上,F
1分数均在98.49%以上。其中对苹果健康的识别效果最好,精确率为99.50%,召回率为100%,特异度为99.83%,F
1分数为99.75%,与其他3个类别相比4项数值均最高,其次为苹果黑腐病,对疮痂病和锈病的识别效果较差。总体来看,该模型在测试集上的平均识别准确率为98.95%,识别效果较为理想,基本能够满足种植户对识别精度的需求。表3 模型在测试集上的试验结果
Table 3 Test results of the model on the test set
?
由图3可知,病害诊断模型对苹果健康的识别效果最好,没有被错分类为其他类别;对锈病的识别效果最差,有16张图像被错分类为疮痂病,分别有3张图像被错分类为苹果健康和黑腐病;黑腐病分别有7,5,2张图像被错分类为锈病、疮痂病和苹果健康;疮痂病分别有5和1张图像被错分类为黑腐病和锈病。结合混淆矩阵和原始数据集中的图像可以发现,不同类别之间差异较小是病害易被错分类为其他类别的主要原因,某些病害叶片仅在患病中后期才会出现明显的病斑,在患病初期并没有明显的病征,人工也难以准确区分,从而增加了识别的难度。另外在复杂背景图像中周围自然环境因素的影响也可能会导致图像被错分类。通过上述分析可知,虽然本模型无法对测试集中所有图像给出准确的类别,但从总体来看绝大多数测试数据分布在混淆矩阵的对角线上,依然能准确地识别出大部分图像的类别,被错分类的图像依然占少数,基本可以满足实际应用的需求。
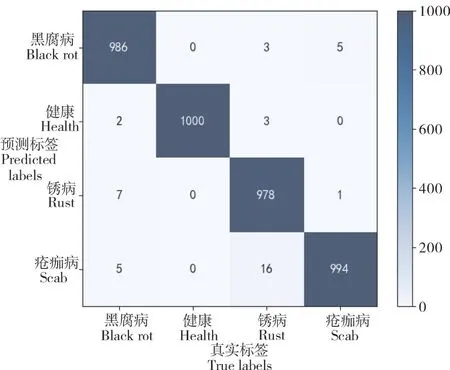
图3 混淆矩阵Figure 3 Confusion matrix
4.3 叶部病害诊断模型机理分析
4.3.1 网络特征提取能力分析 为了更直观地了解病害诊断模型的特征提取能力,对网络结构中的Conv1层、Max⁃Pool层、Stage2层、Stage3层、Stage4层和Conv5层的输出特征图进行可视化,由于篇幅限制,只展示每层的前5张输出特征图(图4)。可通过观察特征图中区域的明暗程度来理解每张特征图所关注到的一些特征信息,亮度高的区域即为该特征图感兴趣的区域。由图4可知,每张特征图都能学习到原始图像中一些有助于分类的特征信息,并且在同一层中不同特征图所提取到的特征几乎都不相同,如在Conv1层的前5张特征图中,第1和第4张特征图能够学习到病害叶片以外的其他叶片的部分特征信息,对应区域高亮,且明暗程度不同,第2和第3张特征图能够学习到病害叶片上3处明显病斑区域的特征信息,第5张特征图则能够学习到病害叶片以外的树枝区域的特征信息。在浅层网络中提取到的特征信息一般比较完整,如在Conv1和MaxPool层中的特征图依然可以肉眼辨别出图像中病害叶片的形状和轮廓等,从Stage2层开始随着网络深度不断增加,特征图的抽象化程度不断增高,网络提取到的特征信息也更加细小,在深层的Conv5层则只保留了原始图像中的一些高阶像素信息。通过上述分析可知,本研究构建的病害诊断模型具有很强的特征提取能力,能充分地学习到原始图像中足够多的特征信息,对后续给出病害的准确类别具有关键性的作用。
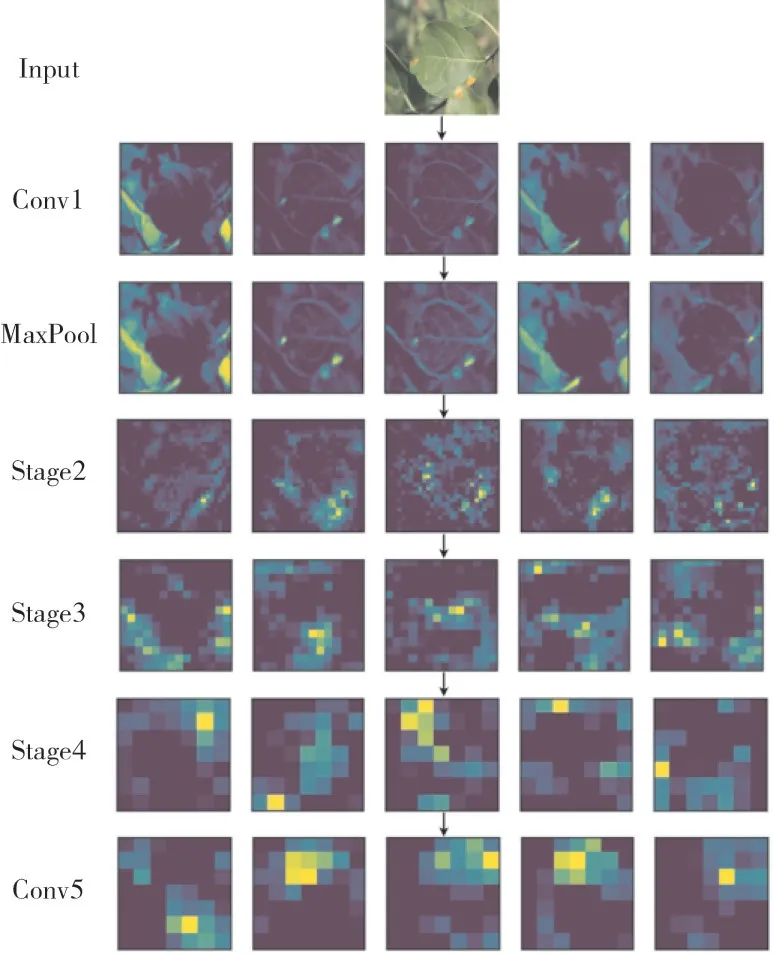
图4 可视化部分输出特征图Figure 4 Visualized part of the output feature map
4.3.2 模型可解释性分析 近年来,CNN的可解释性已成为深度学习领域的研究热点之一。CNN的可解释性可以认为是一种映射过程,是将参数化表示的特征映射到如图像或文字等人类可以直观感受的表达形式,目的是以某种人类能够理解的方式来描述CNN的内部机制。
CAM(class activation mapping)类激活映射是一种通过生成类激活图来表达CNN“可解释性”的一种方式。类激活图是采取将类别相关区域高亮的方式来可视化感兴趣的区域,其原理是将具有丰富语义信息的最后一个卷积层之后的全连接层替换为GAP层,再将GAP层的特征图分别求均值作为新的特征图送入到Soft⁃max层中,之后将每一个特征图和Softmax层之间对应的权重分别相乘相加,采样到原始输入图像的尺寸,即可生成能够区分类别信息的类激活图。
由于使用CAM对CNN进行可视化时往往需要对网络进行重新改造并训练,这无疑大大增加了工作量,为解决这个问题,SELVARAJU等提出了一种基于梯度加权类激活映射Grad-CAM(gradient-weighted class acti⁃vation mapping)的技术。Grad-CAM在技术上基本和CAM等价,区别在于Grad-CAM不再依赖GAP层,而是将CNN的最后一个卷积层中每个特征图的所有像素值进行求导并取平均值作为该特征图的权重,因而不再需要重新改造网络结构并训练,可以减少大部分工作量。
本研究使用Grad-CAM对病害诊断模型进行类激活映射可视化,以测试集中的部分图像为例,结果如图5(图中的P
为模型通过Softmax层后给出的最高可能性类别的概率)。在Grad-Cam热力图中,激活区域颜色越深说明该区域与特定类别越相关。通过对比图5中原始图像和Grad-Cam热力图可以看出,病害诊断模型能对识别结果给出很好的解释,在热力图中可以很直观地看出其能够准确地定位到原始图像中的一些关键区域,如病害叶片上的病斑区域,说明该区域对模型识别出病害的类别发挥了重要的作用。通过对比简单背景和复杂背景图像的热力图可以发现,模型在上述2种不同的背景下都能提取到图像中的关键信息,在复杂背景的图像中受周围自然环境因素的影响较小,并且激活区域对病斑区域的覆盖程度较为全面,当病害叶片上存在多个病斑或较小病斑时激活区域也能准确地覆盖到。另外,模型对图中8张测试图像的识别结果与图像的真实类别相一致,且P
值均为1,说明模型能够根据热力图中的激活区域给出图像的准确分类且概率高。通过上述分析可知,该模型能够关注到图像中一些与分类相关的关键信息并准确地识别出苹果病害,且在简单和复杂背景图像中都能有很好的识别效果,具有很强的鲁棒性和泛化能力。
图5 Grad-CAM热力图Figure 5 Grad-CAM heatmap
5 苹果叶部病害识别模型应用测试
为进一步验证本研究模型的可用性,基于Android手机系统,采用Java语言编程实现了苹果叶部病害识别手机应用(APP),识别结果示例如图6。在田间实际环境下对该APP的诊断性能进行了测试。采用手机摄像头拍照的方式获取图像,每个类别分别拍摄了25张图像,共测试100张图像,对识别准确率和平均推理时间进行了统计,结果如表4。表4可知,该APP能准确识别出苹果健康和锈病这2个类别的所有测试图像,识别准确率达到100%,对疮痂病和黑腐病测试图像识别准确率分别为96%和92%。总体来看,4个类别的平均识别准确率为97%,平均推理时间为39.38ms。结果表明,该APP对田间实际环境下的病害诊断性能较好,能够适用于果园内苹果叶部病害的实时识别要求。
表4 APP测试结果
Table 4 APP test results
?

图6 APP识别结果示意图Figure 6 Schematic diagram of APPrecognition results
6 讨论与结论
近年来,随着卷积神经网络的快速发展,越来越多的专家和学者开始将其用于植物病害识别领域。黄双萍等提出了一种基于GoogLeNet的水稻稻瘟病的识别方法,以大田环境下的水稻稻瘟病穗株为研究对象,平均识别准确率达到92.00%。张建华等通过优化全连接层层数等方式对VGG16模型进行改进,实现了棉花褐斑病、炭疽病、黄萎病、枯萎病、轮纹病和健康叶的识别,平均识别准确率达到89.51%,比相同试验条件下的BP神经网络、支持向量机、AlexNet、GoogLeNet、VGG16模型的识别性能更佳。苏仕芳等对VGG16模型的全连接层进行改进,并基于迁移学习的方式,实现了小样本葡萄褐斑病、轮斑病、黑腐病和健康叶的识别,平均识别准确率达到96.48%。帖军等以果园环境内的柑橘黑斑病、黄龙病、疮痂病、溃疡病和健康叶为研究对象,在ResNet34模型的基础上对其进行改进,将ResNet34中部分残差结构中的恒等映射移除,得到S-ResNet模型,将ResNet34中首层7×7大小的卷积核替换为3×3大小的卷积核,得到M-ResNet模型,最后通过模型融合的方法将二者融合,得到F-ResNet模型,该模型的平均识别准确率达到93.6%。以上研究方法都能准确地识别出植物病害的类别,然而模型复杂度较高,在移动端进行部署较为困难,并且通常只针对一种图像背景。
本研究以简单和复杂背景下的苹果疮痂病、黑腐病、锈病和健康叶为研究对象,对轻量级网络ShuffleNet V2进行改进,提出了一种改进型ShuffleNet#网络的苹果叶部病害识别方法。使用该网络构建的病害诊断模型具有识别精度高和识别速度快的优点,能够快速、准确地识别出上述2种不同背景的4类图像,在测试集上的识别准确率达到98.95%,在移动设备上单张图像的平均推理时间为39.38ms,综合诊断性能良好。将此模型在Android移动端进行部署,开发一款苹果叶部病害识别手机应用,经过测试可知该应用可以满足种植户日常使用的需求,具有较好的应用前景。
