结合注意力机制与特征融合的静态手势识别算法
2022-04-18胡宗承周亚同史宝军
胡宗承,周亚同,史宝军,何 昊
(1.河北工业大学 电子信息工程学院,天津 300401;2.河北工业大学 机械工程学院,天津 300401)
0 概述
手势识别是人机交互的一个重要研究方向,在体感游戏、智能家居等场景有着广泛应用。LIAN[1]及YANG 等[2]利用穿戴设备识别简单手势,但穿戴设备使用不便且难以推广。基于视觉的手势识别方法,由于其灵活便捷的优势成为研究热点。在深度学习成为研究热点之前,基于视觉的手势识别的重大突破多是由于使用了人工特征提取方法,如方向梯度直方图[3-5]、SIFT[6]等。对特征分类多采用支持向量机(Support Vector Machine,SVM),如文献[7]提出一种基于RGB-D 数据的手势识别方法,通过分割手部区域提取手势特征,进而使用SVM 进行分类。TARVEKAR 等[8]提出一种用于非接触式的手势识别系统,该系统在多种颜色空间中检测肤色信息,应用皮肤阈值从分割图像中分割手部区域,从中提取颜色和边缘特征,并利用SVM 分类器进行手势识别。文献[9]提出一种基于梯度方向直方图与局部二值模式融合的手势识别方法,利用主成分分析对梯度方向直方图特征描述算法进行降维,将降维后的数据与局部二值模式特征融合,最后利用SVM 实现静态手势识别。
随着深度学习的发展,卷积神经网络逐渐被应用于各种领域。文献[10]通过Faster RCNN 深度网络模型进行手势识别,能够在识别手势的同时进行手势检测。ZHANG 等[11]采用改进的YOLOV3 算法对静态手势进行识别,并综合使用Kinect 设备采集的4 种信息的优势,利用K-Means 聚类算法对YOLOV3 候选框参数进行优化,以提高手势识别精度。ZHOU 等[12]基于DSSD 算法提出一种静态手势识别算法,DSSD 算法中的先验框宽高比并非手动设定,而是使用K-Means 聚类算法和手肘法共同决定先验框宽高比,同时还利用迁移学习解决数据量小的问题。CHAUDHARY 等[13]提出一个用于光不变手势识别系统的神经网络,利用方向直方图提取手势特征向量并对6 类手势分类,结果表明,该网络在极端光照强度变化环境下的总体精度达到92.86%。ALNUJAIM 等[14]利用手势对天线阻抗产生的变化进行分类,并将采集阻抗转化为光谱图,在采集时将信号转变为图像,利用卷积神经网络进行分类。
针对现有神经网络模型对手势特征表征不足的问题,本文提出一种结合注意力和特征融合的静态手势识别算法。引入注意力机制对输入特征图进行选择性输入,并通过特征融合将高级特征经上采样与低级特征相结合,增强特征表征能力,提高手势识别的分类精度。
1 相关工作
注意力机制研究源于19 世纪的实验室心理学,Google DeepMind 团队提出注意力机制并将其用在图片分类中[15]。注意力机制的本质是对输入数据特定选择,使网络模型更加关注输入数据中的重要信息,抑制非重要信息。
WANG 等[16]提出残差注意力网络,残差学习机制由多个注意力模块堆叠而成,注意力模块内部采用自底向上、自顶向下结构与堆叠的沙漏网络,能够快速收集图像全局信息,并将全局信息与原始特征图相结合,但存在计算量大的问题。HU 等[17]提出SENet 网络,通过压缩—激励方法使特征图通道间建立相互依赖关系,自适应调整特征图通道权重。WOO 等[18-19]提出BAM 及CBAM 两种不同注意力模块,同时考虑空间注意力和通道注意力。BAM 在深度神经网络下采样前发挥作用,其中通道注意力模型和空间注意力模型采用并联方式。CBAM 通道注意力模型和空间注意力模型采用串联方式相结合,是一个轻量级注意力模块。WANG 等[20]提出一种有效的通道注意力深度卷积神经网络ECA,通过借鉴SENet 思想,将全连接层替换为一维卷积,并且采用自适应一维卷积对通道进行特征提取,联合相邻通道信息,虽然实验取得不错结果,但没有引入特征图空间关系。WU 等[21]将多通道注意力机制用于人脸替换的鉴别任务中,在多通道注意力中融合了全局注意力和局部注意力。LU 等[22]提出一种特征图注意力机制用于超分辨率图像重建,并获取特征通道间依赖关系,自适应地调整特征图通道权重。
特征融合多用于目标检测、图像分割领域中,通常通过融合多层特征提升检测和分割能力。LIN等[23]提出目标检测的特征金字塔网络,采用具有横向连接、自顶向下结构将高层语义特征与低层语义特征相结合,提高小目标检测能力。LIU 等[24]提出路径聚合网络(Path Aggregation Network,PANet),采用自底向上的路径增强方法,以较底层的精确定位信号增强整个特征层,缩短较底层与最上层间的信息路径,并且提出自适应特征池化,将特征网络与各特征层连接。CAO 等[25]提出一种基于注意力引导的语义特征金字塔网络(Attention-guided Context Feature Pynamid Network,ACFPN),利用注意力机制整合不同大规模区域信息。CHEN 等[26]提出基于级联的多层特征融合策略,将浅层特征图与深层特征图按通道维度连接,解决小目标识别效果差的问题。LI 等[27]针对目标尺度不同的问题,采用多尺度融合的思想,构建三分支网络,然后对低层特征和高层特征进行选择性融合。
2 本文算法
本文算法创新点在于提出了一种新的注意力机制ACAM 及特征图融合方式CFP。ACAM 综合特征图的通道和空间信息,CFP 融合低层和高层特征,有效提高了分类的准确度。除以上两点外,本文将ACAM、CFP 运用在改进的MobileNetV2[28]上,提出了r-mobilenetv2 算法。
2.1 注意力机制ACAM
本文提出的注意力模块ACAM 如图1 所示。ACAM 由通道注意力模型和空间注意力模型两部分组成。通道注意力模型采用自适应一维卷积操作,且在通道注意力模型后添加跳跃连接,将通道注意力模型输出特征图F1与空间注意力模型输出特征图F2线性相加。假设初始输入特征图F大小为H×W×C,通过ACAM 中的通道注意力模型可得大小为1×1×C的一维通道注意力特征图;通过ACAM 中的空间注意力模型可得大小为H×W×1 的二维空间注意力特征图。

图1 自适应通道注意力模块Fig.1 Adaptive convolution attention module
整体注意力过程如式(1)所示:

其中:CA 为通道注意力模型;SA 为空间注意力模型;F为输入特征图;F1为经过通道注意力模型处理后的特征图;F2为经过空间注意力模型处理后的特征图;F3为整体注意力模型处理后的重建特征图。
通道注意力模型采用一维卷积对特征图通道信息处理,根据特征图通道数动态选择卷积核大小。通道注意力模型的工作流程如图2 所示。首先对输入特征图进行压缩,即在空间方向进行压缩,得到大小为1×1×C的特征图。然后,根据特征图通道数C,自适应选择一维卷积核大小,并根据卷积核大小使用一维卷积对相邻通道特征进行处理,增加通道间的相关性。再将一维卷积处理后的特征图通过激活函数进行重建。最后,将一维通道注意力特征图与输入特征图F相乘,输出为通道注意力输出特征图F1。

图2 通道注意力模型Fig.2 Channel attention model
根据特征图共享卷积核的原则,可以推断通道数C与一维卷积核kernel-size:k必然存在某种联系,即满足C=ϕ(k)=2(r×k+b)。最基础假设从简单的线性映射验证该函数,即C=r×k+b,但线性映射表达性有限。另一方面由于计算机是二进制,而卷积神经网络中batch-size、通道维度大多习惯设为2n,故设C=ϕ(k)=2(r×k+b)。采用非线性表示通道数C与一维卷积核k之间关系,相较线性关系有更强的表现型,如式(2)所示:

其中:k为一维卷积核大小;C为输入特征图通道数;r、b为超参数,这里分别取r为2,b为1。
空间注意力模型在通道注意力输出特征图F1的基础上进行操作,如图3 所示。首先沿着通道所在维度方向进行均值化处理,得到大小为H×W×1的特征图。然后对其进行二维卷积操作,得到的特征图经激活函数激活后输出为二维空间注意力特征图。最后,将二维空间注意力特征图与通道注意力输出特征图F1相乘得到空间注意力输出特征图F2。

图3 空间注意力模型Fig.3 Spatial attention model
2.2 特征融合
本文借鉴特征金字塔的思想,提出分类特征金字塔CFP。CFP 的整体结构如图4 所示,采用横向连接、自顶向下与自底向上结合的连接方式。在stage2中高层特征A经上采样和stage1中低层特征B经一维卷积后得到的特征图线性相加,得到特征图G,特征图G经二维卷积得到特征图D,特征图D与高层特征A空间维度匹配后,在通道维度上连接,得到新特征图E,并送入后序网络中分类。

图4 分类特征金字塔Fig.4 Classification feature pyramid
CFP 主 要分 为stage1、stage2、stage33 个部分,分别对应特征提取、上采样、特征融合3 个方面。在stage1中,采用卷积神经网络对输入数据进行特征提取,自底而上的特征图空间维度依次减半,取最上两层特征图A、B作为最终特征融合所需特征图。stage2应用stage1中最上层高级语义特征A进行上采样,经上采样后的特征图空间尺度变为原来2 倍,与stage1中特征图B在空间维度上匹配。stage1中特征图B经过1×1 卷积调整通道数,使其与stage2中特征图A通道维度相匹配,两者进行简单线性相加。stage3将stage2中高分辨率特征图G经卷积操作使空间维度与低分辨率特征图A 相匹配,并在通道维度连接。最后将融合特征图E 送入后序网络分类。
2.3 r-mobilenetv2 算法
r-mobilenetv2 在MobileNetV2 基础上引入ACAM和CFP 的同时,对原网络结构进行调整。具体为,删除最后一个输入尺寸为7×7×160 的Inverted Residuals 模块,并加入注意力机制ACAM 和特征融合CFP。
MobileNet 系列[28-30]为轻量级网络,虽然相较其他网络需要牺牲部分准确度,但在计算量和参数量上有着巨大优势。在224×224 像素的RGB 图片上,MobileNetV2 的参数量仅为VGG16 参数量的1.72%,是ResNet-18 参数量的20.63%。故MobileNet系列及变体能够有效地部署在移动端。本文主要对MobuleNetV2 进行改进。r-mobilenetv2 的网络结构如表1 所示。其中:当重复次数大于1 时,每组的第一个bottleneck 中卷积步数为表中的值,其他默认卷积步数取1。一组bottleneck 构成一个Inverted Residuals 模块。

表1 r-mobilenetv2 的网络结构Table 1 Network structure of r-mobilenetv2
r-mobilenetv2 在 Inverted Residuals 模块中Strides 等于1 和2 时的共同部分后添加ACAM,最后在两个Inverted Residuals 模块中引入CFP。加入ACAM 的位置如图5 所示。

图5 ACAM 机制在Inverted Residuals 中的位置Fig.5 Position of ACAM mechanism in Inverted Residuals
3 实验结果与分析
本文的实验硬件环境为Inter®Xeon®CPU E5-2640 v4@ 2.40 GHz,GPU 为一块显存为11 GB 的GTX 1080Ti。软件环境为Ubuntu16.04,Keras2.2.2。使用RMSprop 对网络进行训练,初始学习率为0.001,权重衰减系数为1×10-6,batch-size 设为64,若10 个epoch 后测试集准确率没有提升,学习率将衰减为原来的1/10,若30 个epoch 后测试集准确率没有提升,则程序停止。
3.1 数据来源及预处理
本文在LaRED[31]数据集上进行实验测评。LaRED 数据集共有27 种基础手势,含242 900 张图片。27 种基础手势如图6 所示,每个基础手势取3 个朝向,分别为基础手势、基础手势绕X 轴旋转90°、基础手势绕X/Y 轴各旋转90°的手势。从数据集中选取部分手势如图7 所示。

图6 LaRED 数据集类别Fig.6 Classification of LaRED date set

图7 LaRED 数据集的部分数据Fig.7 Partial data of LaRED date set
原始数据集是按帧采集的连续序列,相邻帧图片近似,故每15 帧取一张图片,对数据集进行筛选,并只利用数据中的RGB 信息。其中,训练集含12 955 张图片,测试集含3 239 张图片。对于处理好的图片采取RGB 的方式输入,去均值后,送到后续网络中进行分类。
3.2 注意力机制ACAM 实验分析
本文首先在不同网络模型上验证所提注意力机制的适用性,然后在MobileNetV2 网络的基础上添加不同注意力机制,并与本文所提注意力机制进行对比,以综合验证ACAM 的有效性。选取网络ResNet-18[32]、ShuffleNetV2[33]、MobileNetV2 进行对比,实验结果如表2 所示。
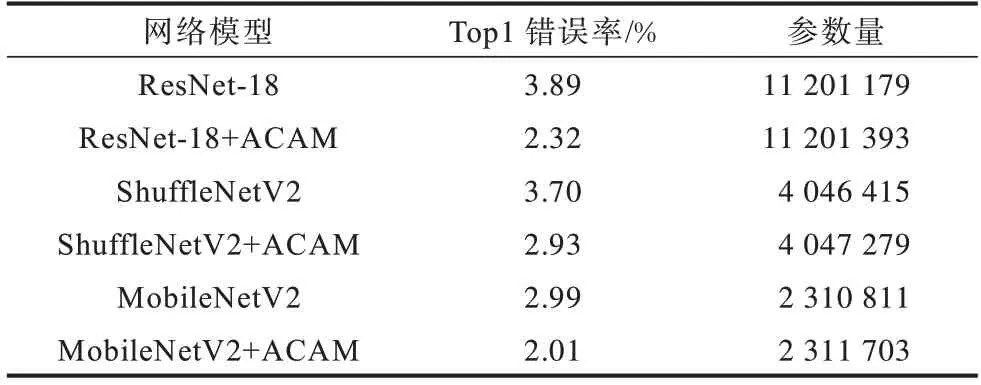
表2 ACAM 在不同网络模型上的结果对比Table 2 Comparison of ACAM results on different worknet models
从表2 可知,本文所提ACAM 虽然仅引入较少参数,但在不同网络模型的准确率上均有1个百分点左右的提升,证明了ACAM 的适用性。ACAM 在ResNet-18网络上的错误率降低了1.57个百分点,参数量增加214;在ShuffleNetV2网络上错误率降低0.77个百分点,参数量增加864;在MobileNetV2 网络上错误率降低0.98 个百分点,参数量增加892。
对比3 种不同网络及加入ACAM 的表现,MobileNetV2 不管从Top1 错误率还是参数量上均有明显优势。从Top1 错误率看,MobileNetV2+ACAM 的Top1 错误率比ResNet-18 降低了0.31 个百分点,比ShuffleNetV2+ACAM 降低0.92 个百分点。从参数量上看,MobileNetV2+ACAM 参数量仅为RestNet-18 的20.64%,为ShuffleNetV2+ACAM 的57.18%。综合以上考虑,选择在MobileNetV2 基础上进行实验。
为验证ACAM 的有效性,以MobileNetV2 为例,在BAM、CBAM、ECA 上与ACAM 进行对比,实验结果如表3 所示。由表3 可知,在MobileNetV2 上,不同注意力模型对于手势识别效果均有贡献。与MobileNetV2基础网络相比,MobileNetV2+BAM 的参数量增加了157 400,在MobileNetV2参数量的基础上增加了6.81%;MobileNetV2+CBAM 的参数量增加了60 286,在MobileNetV2 参数量的基础上增加了2.61%;MobileNetV2+ECA 参数量仅增加了59,增加参数量相对MobileNetV2 参数量可忽略不计。本文所提ACAM与MobileNetV2 结合后参数量为2 311 703,与MobileNetV2 的参数量相比增加了892,相当于在MobileNetV2 参数量的基础上增加3.86×10-4。在不考虑错误率情况下,通过引入参数量进行比较,BAM 引入参数量最多,CBAM 次之,ACAM 和ECA 引入参数量相对较少。综合Top1 错误率和模型参数量两个衡量标准考虑,本文所提ACAM 结果更优。
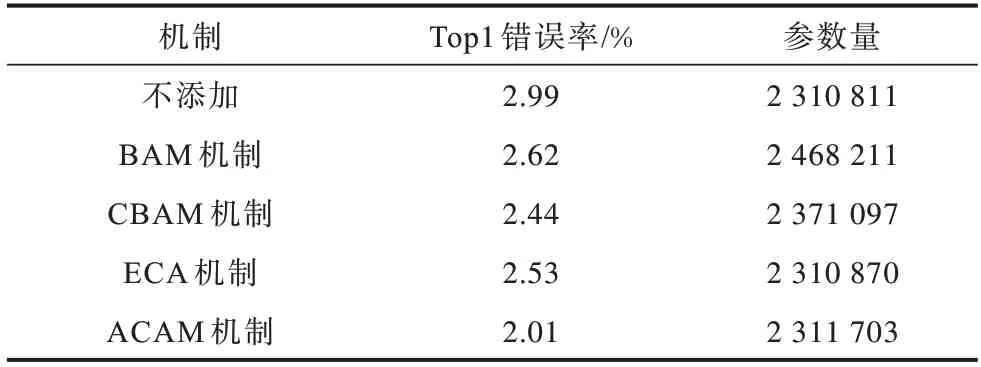
表3 不同注意力机制在MobileNetV2 网络上的结果对比Table 3 Comparison of results of different attention mechanisms on MobileNetV2 network
3.3 改进网络实验分析
将本文提出的注意力机制与特征融合模块加入MobileNetV2 中,并对MobileNetV2 进行修改,mobilenetv2 为直接在MobileNetV2 上修改后的网络,实验结果如表4 所示,其中“×”表示未添加,“√”表示添加。

表4 ACAM 机制与CFP特征融合模块对网络性能的影响Table 4 Influence of ACAM mechanism and CFP feature fusion module on network performance
由表4 可知,在MobileNetV2 基础上进行删减后,mobilenetv2 的参数量减少了900 480,相当于MobileNetV2 参数量的38.97%。mobilenetv2 在减少参数量的同时准确率提升,Top1错误率减少0.3个百分点,这说明删减后的网络更适合手势识别。在MobileNetV2和mobilenetv2 上添加CFP 和ACAM,添加CFP 后两种不同的网络MobileNetV2+CFP 和mobilenetv2+CFP Top1 的错误率均降低1 个百分点左右,但参数量大幅上升,相较原基础网络,参数量分别增加了58.96%、19.27%。添 加ACAM 后,mobilenetv2+ACAM 相 较MobileNetV2+ACAM Top1 错误率更低,在参数量更少的情况下,Top1 错误率降低0.53 个百分点。通过上述分析可知,CFP、ACAM 对手势识别任务有效。将CFP和ACAM 加 入MobileNetV2 和mobilenetv2 中,形 成R-MobileNetV2和r-mobilenetv2。其中R-MobileNetV2以未经删减的MobileNetV2 为基础,r-mobilenetv2 以删减后的MobileNetV2 为基础。最终R-MobileNetV2 相对MobileNetV2的Top1错误率降低了1.26个百分点,参数量相对MobileNetV2增加了59.00%,达到了3 674 263。r-mobilenetv2 相对mobilenetv2 Top1 的错误率降低了1.52 个百分点,参数量相对mobilenetv2 增加了11.79%,达到1 682 849;相对R-MobileNetV2 Top1 的错误率降低了0.56 个百分点,参数量仅为R-MobileNetV2 的45.80%;相对MobileNetV2 Top1的错误率降低了1.82个百分点,达到1.17%,参数量仅为MobileNetV2 的72.83%。以上实验结果充分验证了CFP、ACAM 及r-mobilenetv2 的有效性。
此外,在r-mobilenetv2 网络中,选取测试集数据制作混淆矩阵,结果如图8 所示。由图8 可知,r-mobilenetv2 对27 种手势的预测基本完全正确,在手势识别中有着优异的表现。

图8 r-mobilenetv2 算法的混淆矩阵Fig.8 Confusion matrix of r-mobilenetv2 algorithm
4 结束语
为有效提取特征,解决特征表征不足的问题及提高手势识别精度,本文结合注意力机制和特征融合,提出一种轻量级网络静态手势识别算法r-mobilenetv2。通过结合空间注意力和通道注意力模型,得到一种自适应卷积注意力机制,针对高级语义特征含有的分类信息不完全问题,构建分类特征金字塔,并通过实验验证自适应卷积注意力机制及分类特征金字塔的有效性。实验结果表明,r-mobilenetv2 算法的准确率达98.83%,与MobileNetV2 算法相比,其参数量及Top1 的错误率分别降低了27.20%、1.82 个百分点。下一步将从损失函数、卷积方式入手对网络的适应性及实时性进行改进,提高网络识别精度及泛化性能。
