基于YOLOv5 增强模型的口罩佩戴检测方法研究
2022-04-18张乔虹唐朝晖桂卫华
彭 成,张乔虹,唐朝晖,桂卫华
(1.湖南工业大学 计算机学院,湖南 株洲 412007;2.中南大学 自动化学院,长沙 410083)
0 概述
近日,全球多国面临新一轮疫情冲击,且病株变异等情况也为疫情防控增添了更多的不确定风险,在疫情防控常态化的情况下,佩戴口罩是极为有效且经济的防控手段,因此,公共场合的口罩佩戴检测成为一项重要工作。在日常生活中,面对经呼吸道传播的传染性疾病或工厂生产过程中产生的有害颗粒物,佩戴口罩也可保护生命安全,减少危害源的接触,提高安全卫生等级。以人工的方式对活动人员进行监督检测耗时耗力,且近距离接触待检测人员存在一定的安全风险,因此,构建自动监控系统检测活动人员的口罩佩戴情况,对日常防护工作具有重要意义。
人脸口罩佩戴检测属于计算机视觉中的物体检测范畴,在过去的二十年中,物体检测的发展大致可分为2 个阶段,即2014 年以前的传统目标检测以及2014 年以后的基于深度学习的目标检测[1]。随着GPU 和大数据的发展,传统机器学习多阶段才能实现的功能可由深度学习串联完成,输入大量图像、语音和文本信息即可直接进行端到端的训练[2-3],因此,深度学习在物体检测、图像分割等领域展现出远超传统算法的能力。
为了使人脸口罩佩戴监督功能更易获取,口罩检测网络模型的轻量化也是一个必须要考虑的问题。当前经典的物体检测算法大多依赖卷积网络[4-6]进行特征提取,一系列优秀的基础网络(如VGGNet[7]、ResNet[8]、DenseNet[9]等)被提出,但是这些网络计算量往往较大,很难达到实时运行的工业应用要求,于是轻量化网络应运而生。SqueezeNet[10]从网络结构优化出发,先压缩再扩展,使用常见的模型压缩技术,在性能与AlexNet[11]相近的基础上,模型参数仅为AlexNet 的1/50。但该网络仍然采用标准的卷积计算方式,之后的MobileNet[12]采用更加有效的深度可分离卷积,提高了网络速度并进一步促进了卷积神经网络在移动端的应用,同时通过较少的计算量获得了较高的精度。但是在理论上,MobileNet的计算量仍然可以继续降低。ShuffleNet[13]利用组卷积和通道混洗的操作有效降低了点卷积的计算量,实现了更为优越的性能。随着移动设备的进步和应用场景多样化的发展,轻量化网络展现出了更高的工程价值[14]。
针对人脸口罩佩戴检测的精度和速度问题,多位学者进行了各种尝试。文献[15]提出一种基于RetinaNet 的人脸口罩佩戴检测方法,其通过迁移学习并利用预训练的ResNet 模型帮助新模型训练,在验证集上的AP 值达到86.45%。文献[16]基于YOLOv3 网络模型,引入改进的空间金字塔池化结构并优化多尺度预测网络,同时替换损失函数,相较YOLOv3,其准确率提升14.9%。文献[17]基于YOLOv5 网络模型,在原数据集的基础上进行扩充,采用翻转和旋转2 种方式得到30 000 张图片用于训练,最终准确率达到92.4%。
本文提出一种改进的口罩佩戴检测方法。为在模型精度和速度间取得平衡,设计更为轻量化的改进YOLOv5 模型,在几乎不降低模型精度的情况下实现模型压缩并加快推理速度,同时降低对硬件环境的依赖性。针对实际应用场景中由距离摄像头远近不同而导致的一张图片中存在物体尺度面积不平衡的问题,使用YOLOv5 分别进行20×20、40×40、80×80 的多尺度检测,从而提升模型对于小物体的检测性能。
1 基础理论
1.1 YOLOv5 算法原理
YOLO(You Only Look Once)是一个高性能的通用目标检测模型,YOLOv1[18]使用一阶结构完成了分类与目标定位2个任务,随后的YOLOv2[19]与YOLOv3[20]在速度和精度上取得提升,进一步促进了物体检测在工业界的应用,YOLOv4[21]则实现了在一块普通的GPU(1080Ti)上完成模型训练。从YOLOv1至今,YOLO 系列已经发展至YOLOv5,相较YOLOv4,YOLOv5 更加灵活,它提供了4 个大小的版本,分别为YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,4 个版本模型大小与精度依次递增,根据Bottleneck 数目区分,采用了类似EfficienctNet[22]的channel和layer 控制因子来实现版本的变化,在实际应用中,可以根据具体场景的不同来选取合适大小的模型。本文主要实现模型压缩及加速,使其更易应用于资源有限的嵌入式设备,因此,选择YOLOv5s 系列作为基准模型。
YOLOv5 也有着版本迭代更新,目前已更新至v5.0,其中,v3.0、v4.0、v5.0 各有优势,v4.0 与v5.0 中的YOLOv5-P5模型结构相同,v5.0新提出YOLOv5-P6模型,较已有版本,其添加了1个输出层,共计P3、P4、P5和P6这4个输出层,对应下采样幅度分别为8、16、32和64,新增加的检验层有利于检测较大的物体,可以通过更高分辨率的训练获得更高的精度。此外,YOLOv5-P5模型使用PyTorch1.7中新支持的SiLU()激活函数替换了先前版本中使用的LeakyReLU()和HardSwish()激活函数,使得网络中任何一个模块都只使用SiLU 激活函数,并删减了先前版本中BottleneckCSP 的部分Conv 模块。先前版本的BottleneckCSP以及YOLOv5-P5中的改进BottleneckCSP 对比如图1 所示,改进BottleneckCSP也称为C3模块。

图1 BottleneckCSP 和C3 模 块Fig.1 BottleneckCSP and C3 module
可以看到,C3 模块由于消除了每个瓶颈结构中的一个卷积,导致新版YOLOv5-P5 的尺寸都稍小,能够得到更小的模型,且推理速度也有少量提升,对于较大的YOLOv5x,推理时间由6.9 ms 降低至6 ms,即模型越大,从这个变化中受益越大。表1 所示为YOLOv5s各版本的性能比较,可以看到,虽然YOLOv5s-P5 精度较YOLOv5s-3.0 有0.8%的下降,但是速度和参数量都更为优秀,YOLOv5s-P6 虽然精度最高,但是无论是高分辨率的输入还是增加的检测头,都为设备资源分配增加了更大的负担。综合考量,本文最终选择YOLOv5s-P5作为基准实验模型,以其为baseline 进行模型优化。本文中后续出现的YOLOv5 一词,若没有特别说明,均指YOLOv5s-P5。

表1 YOLOv5s 各版本性能分析Table 1 Performance analysis of various versions of YOLOv5s
YOLOv5 由Backbone 与Head 2 个部分组成,Backbone 主要有Focus、C3 以及SPP 模块,Head 包括PANet 以 及Detect 模块。
在Backbone 部分,通过1 个Focus 模块、4 个Conv 模块实现32 倍下采样,其中,Focus 模块将输入数据切分为4 份,每份数据都是相当于2 倍下采样得到的,然后在channel 维度进行拼接,最后再进行卷积操作,Focus 模块减少了卷积的成本,以reshape tensor 实现下采样并增加channel 维度,可以减少FLOPs 并提升速度。
C3 模块参照CSPNet 结构[23],将一个阶段中基础层的特征图分成2 个部分,拆分和合并策略被跨阶段使用,较好地降低了信息集成过程中重复的概率,重复梯度信息的减少,使得YOLOv5 网络能够有更好的学习能力,推理计算也有一定的减少。YOLOv4 中也使用了CSP 模块,但YOLOv5 中做出创新,以有无残差边为区分标准设计2 种CSP 模块,分别为CSP-False 和CSP-True,以shortcut 的取值False 或True 来控制改变。
加入SPP 模块[24]至CSP 模块之后,使用组合的3 个多尺度最大池化层,在几乎没有速度损失的情况下大幅提升了感受野,提取出了最重要的特征,同时也有效降低了直接将图片进行伸缩而导致的图片信息丢失的可能性,进一步提升了模型精度。
在Head 部分,通过将高层特征信息上采样的方式与低层特征信息进行传递融合,实现了自顶向下的信息流动,再通过步长为2 的卷积进行处理,将低层特征与高层特征作Concat 操作,使低层分辨率高的特征容易传到上层,从而实现了PANet[25]操作,更好地将低层特征与高层特征进行优势互补,有效解决了多尺度问题。
YOLOv5 网络结构如图2 所示。

图2 YOLOv5 网络结构Fig.2 Network structure of YOLOv5
1.2 改进的GhostBottleneckCSP
GhostNet 提出了一个创新性的模块Ghost,其通过更少的参数量和计算量生成了更多的特征图[26]。Ghost 的实现分为2 个部分,一个是普通卷积,另一个是具有更少参数量和计算量的线性操作。先通过有限的普通卷积得到一部分特征图,再将所得的特征图通过线性操作生成更多的特征图,最后将2 组特征图在指定维度进行拼接。Ghost 的操作原理如图3 所示。

图3 普通卷积与Ghost 模块的对比Fig.3 Comparison between ordinary convolution and Ghost module
普通卷积层的运算可以表示为:

其中:X∈Rc×h×w代表卷积输入,c指输 入channel 数量,h及w分别指输入特征图的高度和宽度;表示输出n个高度和宽度分别为h′和w′的特征图;ω∈Rc×k×k×n代表进行卷积运算的是c×n个大小为k×k的卷积核;b是偏差项,逐点加至输出特征图的每个小单元。分析可得式(1)运算的FLOPs多达h′×w′×n×c×k×k。而Ghost 结构进行少量的普通卷积运算,采用线性运算高效减少特征冗余,以更少的计算量得到同样多的特征图。由图3(b)可以看出,Ghost 模块的运算可以表示为:
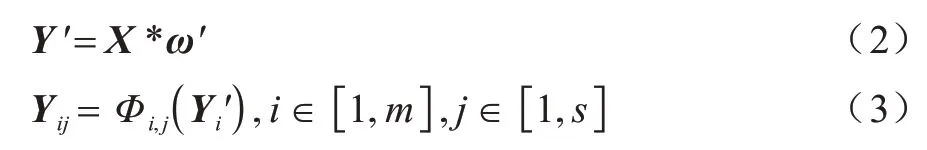
出于提高处理速度的目的,考虑到设备部署时的实用性,相较使用具有不同形状和参数的线性运算,本文全部使用3×3 或5×5 的相同线性运算。设线性运算内核大小为d×d,则可以将Ghost 模块与普通卷积的计算量进行比较,得出Ghost 模块相对普通卷积的提升程度,如下所示:
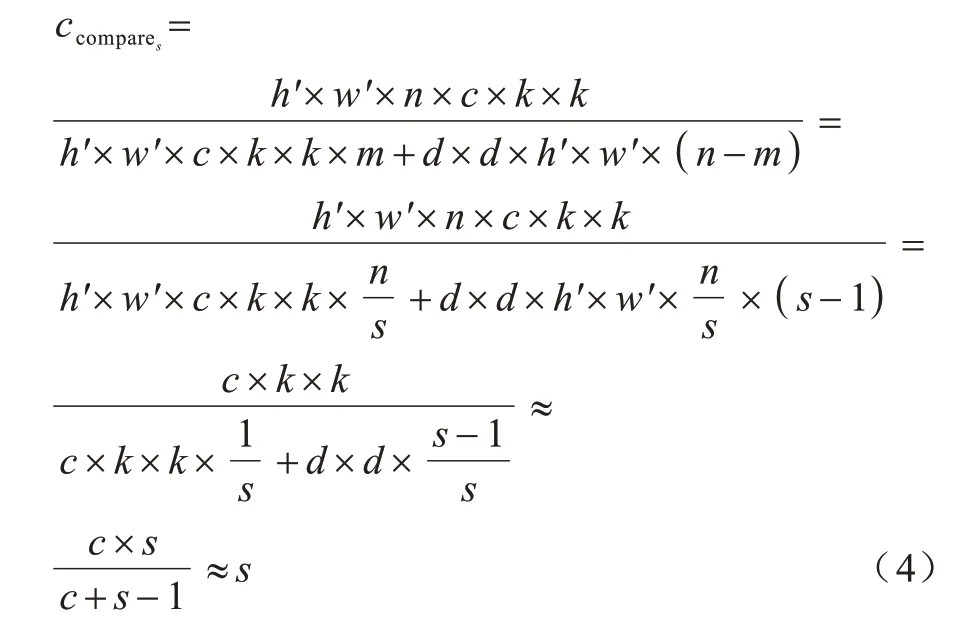
这里的k×k与d×d大小相同,且s≪c,因此,最终化简可以得到普通卷积的计算量近似为Ghost 模块的s倍,参数量计算类似,最终也可以近似化简为s。从理论上可以定量地证明Ghost模块的优越性,因此,以Ghost模块为基础,进而设计GhostBottleneck及GhostBottleneckCSP模块,具体结构如图4所示。

图4 GhostBottleneck 和GhostBottleneckCSP 模块结构Fig.4 GhostBottleneck and GhostBottleneckCSP module structure
图4中的c1与c2分别指输入和输出特征图通道数。在本文中,先使用图4(a)所示的1×1 普通卷积将通道数降至输出通道数的1⁄2,再根据得到的特征图进行大小为5×5 的深度卷积,最后将2 组特征拼接。图4(b)中第1 个Ghost module 先将输出通道数降为目标输出通道数的1⁄2,再由第2 个Ghost module 将通道数恢复至目标输出通道数,并与残差边传来的输入特征图逐点相加进行特征融合。如图4(c)所示,使用GhostBottleneck 替换掉YOLOv5 中所有的Bottleneck模块,与C3 模块形成新的GhostBottleneckCSP,原Bottleneck 由1×1 和3×3 标准卷积组成,新结构通过替换掉原来Bottleneck 中较多的3×3 标准卷积,减少了计算量并压缩了模型。
1.3 ShuffleConv 模块
当前优秀的轻量级网络绝大部分都使用组卷积或深度可分离卷积来降低卷积操作所产生的计算量,但是,为了实现通道间的特征融合,这些网络中使用的1×1 卷积在整个过程中占用较多的计算量,为了缓解这一问题,ShuffleNet[10]提出了通道混洗的概念。在进行组卷积后,使用通道混洗就可以实现组间信息的流通,以更加经济的方式增强特征的表达能力。通道混洗可以通过张量的常规操作来实现,具体过程如图5 所示。

图5 通道混洗的实现过程Fig.5 Realization process of channel shuffle
图5 中的数字是输入通道的编号,使用Reshape操作将通道扩展为两维,并通过Transpose 对扩展出的2 个维度进行置换,通过这个操作能够在不增加计算量的情况下使组卷积通道之间的信息完成融合,最后Flatten 操作将2 个维度复原为原来的初始维度,完成通道混洗。基于以上原理,可以认为一个逐点卷积可以使用一个1×1 组卷积和1 个通道混洗操作组合代替,组卷积与标准卷积相比参数量与计算量有较大减少,且组卷积有类似正则的作用,可以降低过拟合发生的概率。出于这些优点,本文对YOLOv5 中6 个大小为3×3、2 个大小为1×1 的Conv 模块中的普通卷积操作进行改进,将原来的普通卷积更换为组卷积和通道混洗模块,理论上可以实现模型的进一步压缩。
2 YOLOv5 增强网络模型
2.1 YOLOv5 增强网络结构
YOLOv5 具有较好的工程实用性,选择其作为口罩检测模型的基准网络具有可行性。但是,从目前的研究和应用情况来看,YOLOv5 仍可以进行进一步改进。结合1.2 节及1.3 节的内容,得到本文改进后的YOLOv5 网络,其整体结构如表2 所示。

表2 改进的YOLOv5 网络整体结构Table 2 Overall structure of improved YOLOv5 network
在表2 中:第2 列的-1 是指输入来自上一层输出;最后1列的值依次对应该模块的输入通道数、输出通道数、卷积核大小、步长信息;第4列GhostBottleneckCSPn模块中的n代表该模块内GhostBottleneck 的数量。经过计算,改进YOLOv5 模型总计367 层,2 419 191 个参数,计算量为5.5GFLOPs。初始YOLOv5 模型共计7 066 239 个参数,计算量为16.4GFLOPs。两者比较,优化后的模型参数量减少为原来模型的34.24%,计算量减少为原来模型的33.54%,实现了较大程度的模型压缩。
2.2 损失函数
模型损失函数由分类损失(classification loss)、定位损失(localization loss)、目标置信度损失(confidence loss)组成。YOLOv5 使用二元交叉熵损失函数计算类别概率和目标置信度得分的损失,通过实验,本文在GIOU Loss[27]和CIOU Loss[28]之间最终选定效果略好的CIOU Loss 作为bounding box 回归的损失函数。CIOU Loss 计算公式如下:

2.3 本文方法实现
2.3.1 模型训练算法
本文模型训练算法实现过程描述如算法1所示。
算法1模型训练算法
输入人脸口罩数据集图片及标记文件
输出本次训练中性能最佳的检测模型
初始化参数训练epoch 数,学习率,批次大小,输入图片大小,网络模型配置yaml 文件,标签与anchor 的IoU 阈值,损失系数,数据增强系数,标签与anchor 的长宽比阈值
图片预处理调整图片亮度、对比度、饱和度并进行Mosaic 处理
步骤1准备数据,制作数据集并划分训练集和验证集。
步骤2加载数据配置信息及初始化参数,输入数据并对其进行预处理。
步骤3加载网络模型,并对输入图片进行特征提取及物体定位分类。
步骤4随着迭代次数的增加,使用SGD 对网络中各组参数进行更新优化。
步骤5若当前epoch 不是最后一轮,则在验证集上计算当前模型的mAP,若计算得到的模型性能更佳,则更新存储的最佳模型。
步骤6在训练完所设置的迭代数后,获得训练好的最佳性能模型和最近一次训练的模型。
步骤7输出性能最佳的模型。
2.3.2 整体实现流程
本文方法整体实现流程如图6 所示:首先准备数据,进行人脸口罩佩戴图片筛选及标记,制作数据集并随机划分训练集、验证集、测试集;接着按照算法1 进行模型训练,得到性能最佳的人脸口罩佩戴检测模型;之后对测试集数据进行测试,并在测试图片上呈现最终的识别结果,即人脸位置和口罩佩戴状态。
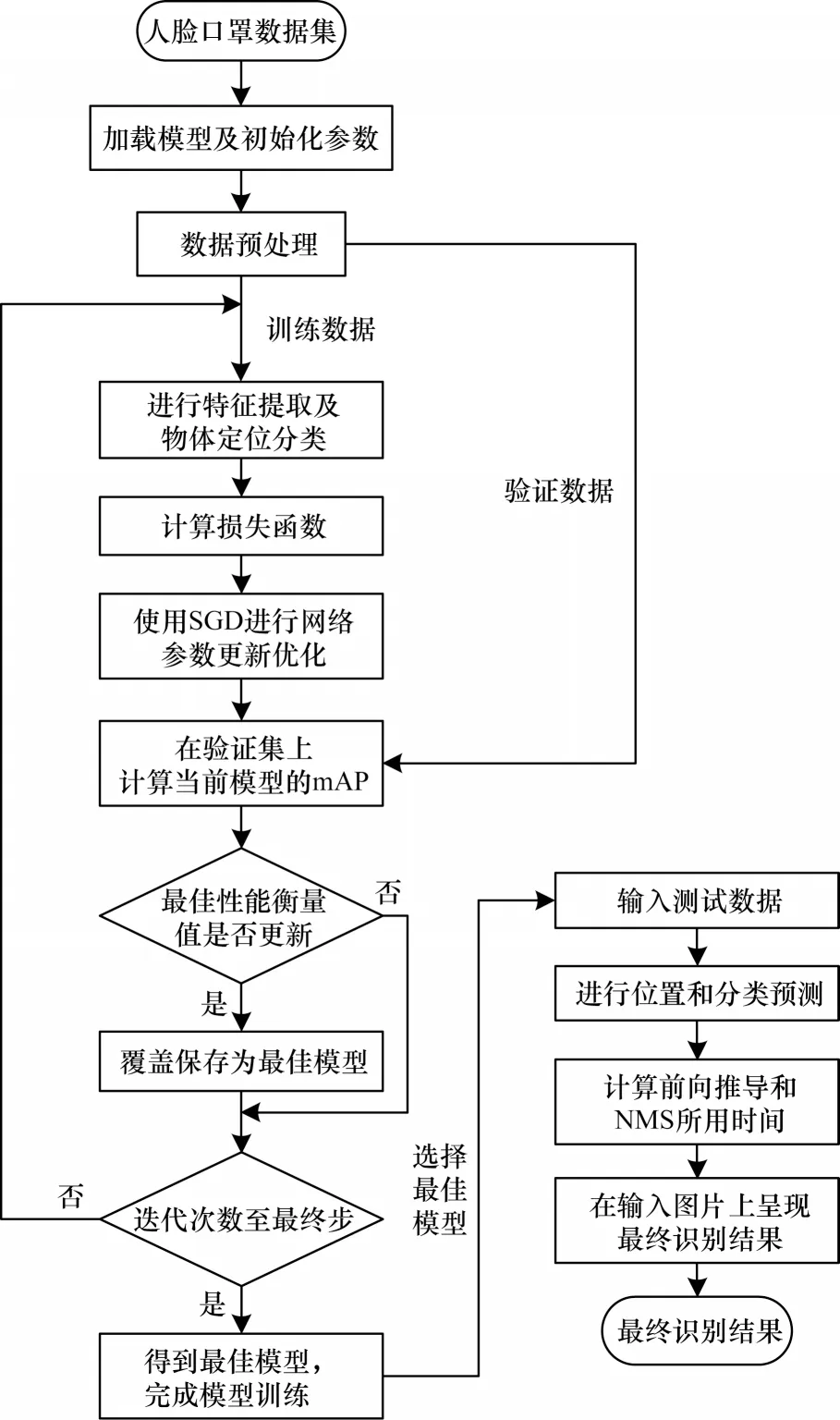
图6 本文方法整体流程Fig.6 Overall process of this method
3 实验及结果分析
3.1 实验环境与数据集介绍
本文实验的机器操作系统版本为Ubuntu 9.3.0-10ubuntu2,CPU 型号为Intel®CoreTMi3-9100F CPU@3.60 GHz,GPU 型号为GeForce RTX 2080 Ti,显存大小为11 GB,内存大小为31 GB。所有模型基于PyTorch 1.8,并使用cuda 10.1 和cudnn 7.6.5 对GPU 进行加速。
实验使用的数据集来自AIZOO 团队整理的开源数据集,该数据集主要从WIDER Face 及MAFA 公开数据集中筛选得到,从中分别选择3 894 张及4 064 张图片,并对其进行二次筛选及扩充,删除错误标签,加入部分ROBOFLOW 开放的口罩数据集,最终得到训练集6 110 张,验证集1 832 张,共计7 942 张图片。将图片预定义为佩戴口罩和未佩戴口罩两类,佩戴口罩标签为face-mask,未佩戴口罩标签为face。
为了避免将捂嘴动作预测为佩戴口罩,实验数据集中加入了嘴巴被手或衣物等其他物品捂住的数据,从而有效过滤了此类干扰。数据集部分图片如图7 所示。

图7 数据集部分图片Fig.7 Partial pictures of dataset
通过对数据集进行分析得到可视化结果如图8 所示:图8(b)中x、y指中心点位置,颜色越深代表该点位置目标框的中心点越集中;图8(c)中width、height 分别代表图片中物体的宽、高。从图8(b)、图8(c)可以看出,数据集物体分布比较均匀,且中小物体占比更大,存在物体间遮挡的情况,符合日常实际应用场景,但数据集存在轻微的类别间样本不平衡问题,该问题将在数据预处理中得到缓解。
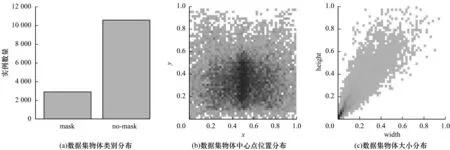
图8 数据集分析结果Fig.8 Dataset analysis results
3.2 数据预处理
3.2.1 数据集标记
实验数据集为PASCAL VOC 格式,但YOLOv5所需为YOLO 格式的txt 标记文件,具体格式为(class_id,x,y,w,h),且都是归一化后的值,因此,需要做相应转换,具体运算规则如下所示:

其中:class_id 为类别的id 编号;xmax、ymax、xmin、ymin分别指VOC 格式的xml 标记文件中相对于图片左上角,标记物体所在位置的左上角坐标及右下角坐标的值。
3.2.2 自适应图片采样
本文所用数据集存在轻微的类间不平衡问题,这也是物体检测中的一个常见问题,模型训练时样本过少的类别的参考性较小,可能会使模型主要关注样本较多的类别,模型参数也主要根据样本多的类别的损失进行调整,最终导致针对少样本类别的检测精度有所下降。
为了解决上述问题,本文采用自适应图片采样策略,根据物体类别的数量占比及每张图片中各类物体的出现频数,生成每张图片的采样权重,再根据图片的采样权重生成采样的索引序列,类别数量和频数与类别权重成反比,若某张图片频数最高的类别的数量占比也较其他类别高,则这张图片被采样的概率就会降低,通过这种采样方式可以有效缓解类间不平衡问题。
3.2.3 anchor 设置
对于目标检测任务,设置合适的anchor直接影响模型的最终表现。合适的anchor 是根据数据集物体大小而确定的,利用预设值anchor,基于shape 阈值对bbox 计算可能的最优召回率。如果召回率大于0.98,则无需优化,直接返回;如果召回率小于0.98,则利用遗传算法与k-means 重新设置anchor。本文模型在人脸口罩数据集上可能的最优召回率为0.997 8,因此,使用YOLOv5 的初始anchor 值[10,13,16,30,33,23]、[30,61,62,45,59,119]和[116,90,156,198,373,326]。
3.2.4 Mosaic 数据增强
本文实验的Mosaic 数据增强参考CutMix[29]:随机选取4 张图片并对其进行随机裁剪、排布和缩放,然后完成拼接,得到的效果如图9 所示。这种方式随机扩充了数据集,特别是随机缩放增加了小目标,使得网络的鲁棒性得到一定提升。经过Mosaic 数据增强后相当于一次性处理了4 张图片,batch size 隐性增加,初始设置的batch size 值无需很大也可以得到一个性能较好的模型,对GPU 性能要求相对降低。
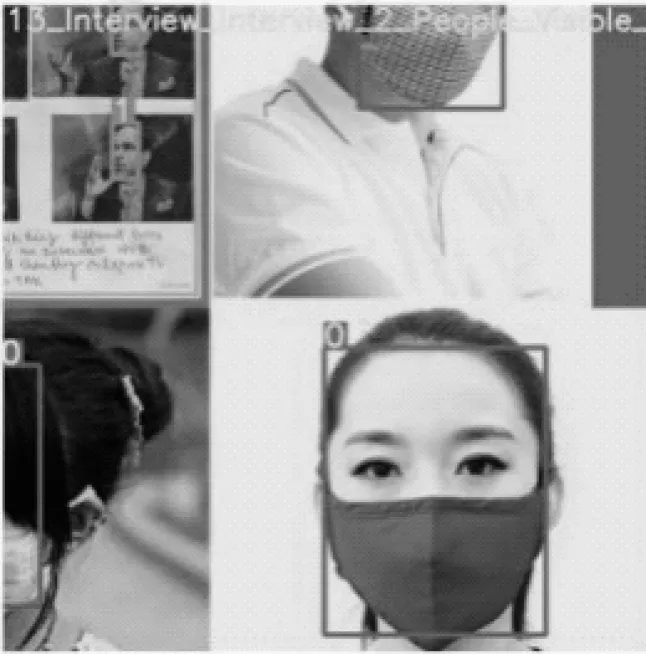
图9 Mosaic 数据增强效果Fig.9 Mosaic data enhancement effect
除此之外,本文还进行了改变亮度、对比度、饱和度等常规数据增强方法,与Mosaic 相结合,在一定程度上有效防止了过拟合问题,能够实现更长时间的训练从而获得更优的模型性能。
3.3 结果分析
本文所有实验中学习率均使用Warmup[30]训练,避免模型训练时初始学习率过高引起模型振荡,以便维持模型的稳定性。在Warmup 阶段,采用一维线性插值对每次迭代的学习率进行更新,bias 层的学习率从0.1下降到基准学习率0.01,其他参数学习率从0 增加到0.01。在Warmup 阶段之后,采用余弦退火算法[31]对学习率进行更新。实验中BN 层、权重weight 层、bais 层的学习率分别为lr0、lr1、lr2,所有实验均训练300 个epoch,batch size 设为32。学习率的变化曲线如图10所示,其中,lr0 和lr1 曲线变化相同。

图10 学习率变化曲线Fig.10 Curve of learning rate
从mAP(0.5)、mAP(0.5∶0.95)、召回率Recall、准确率Precision、平均检测处理时间、参数量、计算量、模型大小这8 个角度对模型性能进行衡量。上述部分评价指标的具体计算公式如下:


其中:TP、FP、FN分别指正确检验框、误检框、漏检框数量;AAP值为P-R 曲线面积,本文采用101 个插值点的计算方法;N指检测类别总数,本文为2;mAP(0.5)指IoU设为0.5 时所有类别的平均AP;mAP(0.5∶0.95)指在不同IoU 阈值下的平均mAP,IoU 取值从0.5 增加到0.95,步长为0.05。平均检测处理时间包括网络推理时间及NMS 处理所花费的时间,模型大小指最终训练结束得到并保存的模型大小。
3.3.1 在人脸口罩数据集上的实验结果
通过消融实验来逐步验证网络结构改变所引起的性能变化,本节3 个实验分别训练YOLOv5、Ghost-YOLOv5、Ghost-YOLOv5-Shuffle 这3 个网络,实验测试结果分别如图11、图12、表3 所示,其中,曲线灰度依次递增分别代表YOLOv5、Ghost-YOLOv5-Shuffle 和Ghost-YOLOv5。

表3 各模型的性能对比结果Table 3 Performance comparison results of each model

图11 各模型在人脸口罩数据集上的实验结果Fig.11 Experimental results of each model on face mask dataset
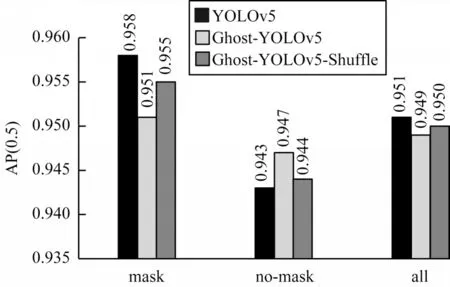
图12 各模型的所有类别AP 值对比Fig.12 Comparison of AP values of all categories of each model
从表3 可以看出,使用GhostBottleneck 替换YOLOv5 中所有的Bottleneck 模块后,模型计算量和参数量分别压缩为原来的63.41%和68.98%,在使用GPU 或CPU 的情况下分别有13.64%和16.37%的速度提升,并且模型大小变为原来的69.34%,但同时,从图11(c)中也可以看出,模型精确度有了明显损失,且波动更为剧烈,这在验证集的类别损失曲线中也有所体现,所幸在训练后期,Ghost-YOLOv5 模型与YOLOv5 之间精确度的差值较初期有所下降,除此之外,从图12 可知,Ghost-YOLOv5 模型最终的所有类别平均AP 较YOLOv5 仅下降0.3%。
在继续将标准卷积替换为ShuffleConv 后,模型计算量和参数量进一步压缩,分别为原来的33.54%和34.24%,在使用GPU 情况下处理时间仍然保持1.9 ms不变,但CPU 速度较YOLOv5 提升了28.25%,模型大小压缩至原来的35.77%。GPU 情况下速度没有提升,原因是在算力足够的GPU 平台上,组卷积虽然降低了运算量和参数量,但是由于内存交换速度的限制,ShuffleConv的瓶颈并非是计算强度,因此,此模块对GPU环境下的影响微乎其微,但当在计算能力有限的CPU平台上,计算速度便会有相当的提升,更适合部署在资源有限的嵌入式设备上。此外,Ghost-YOLOv5-Shuffle在Ghost-YOLOv5 的基础上精度有所提升,从各个衡量标准来看都与YOLOv5 的检测能力更加贴近,且从分类损失曲线来看,在一定程度上证实了组卷积的正则化效果,由图12 可知,Ghost-YOLOv5-Shuffle 的最终mAP(0.5)为0.950,较YOLOv5 的0.951 几乎没有精度下降,且各类间差值都在0.003 范围之内。
YOLOv5 与Ghost-YOLOv5-Shuffle 实际运行效果如图13 所示,每个小图中的左边图片为YOLOv5,右边图片为Ghost-YOLOv5-Shuffle。通过图13 的实际检测效果对比可以看出,改进后的模型在进行非极小物体的识别时与基准模型几乎没有区别,面对分布极为密集的模糊小物体时,基准模型比改进模型略微精确,但改进模型对绝大部分小物体还是能够实现正确识别。

图13 复杂场景下的实际检测效果Fig.13 Actual detection effect in complex scenes
3.3.2 不同网络的对比实验
为了进一步验证本文所提模块及网络的高效性,将其与同类轻量级网络YOLOv3-tiny、YOLOv4-tiny等进行对比,结果如表4所示。其中,实验5、实验6第2列括号中的数字代表模型中前3 个GhostBottleneckCSP 中GhostBottleneck的个数。从表4可以得出:
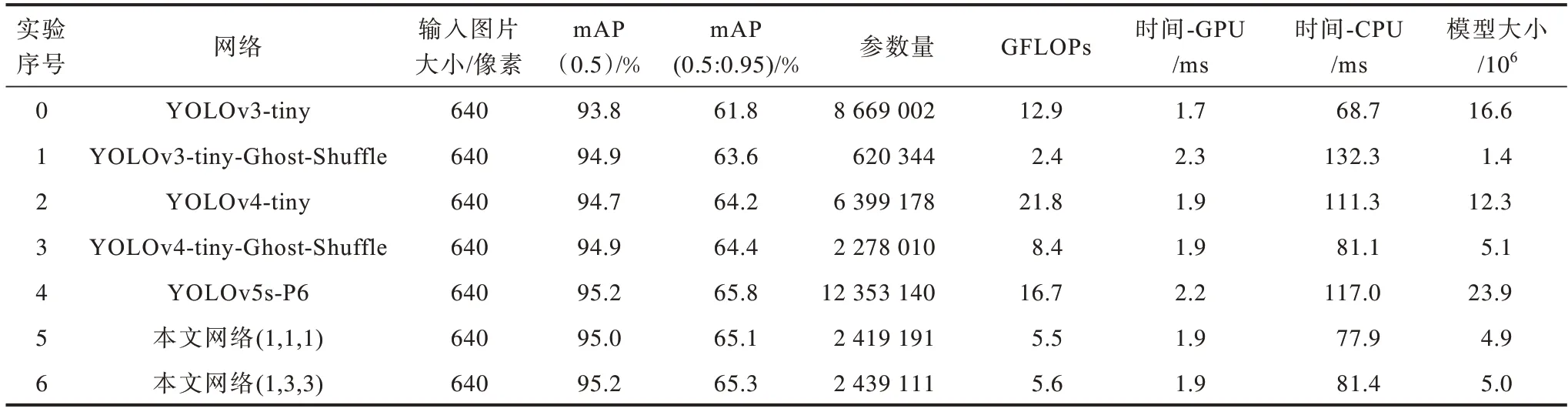
表4 不同网络的性能对比Table 4 Performance comparison of different networks
1)由实验0、实验2、实验4、实验6的对比可以看出,本文模型相较YOLOv3-tiny、YOLOv4-tiny、YOLOv5-P6具有绝对优势,其模型大小分别仅为上述模型的30.12%、40.65%、20.9%,但mAP 明显大于YOLOv3-tiny、YOLOv4-tiny,且与YOLOv5-P6的mAP(0.5)大小相同,即选择本文所提网络结构进行人脸口罩佩戴检测是合理且经济的。
2)通过实验0 和实验1、实验2 和实验3 这两组对比实验可以验证GhostBottleneckCSP 和ShuffleConv 模块在其他网络上的优化通用性,加入GhostBottleneckCSP和ShuffleConv 模块的YOLOv3-tiny 模型大小仅为原模型的8.43%,大量的3×3 和1×1 标准卷积被替换,实现了模型的极限压缩,且由于加入了更加高效的CSP模块,实验1 的精度较原模型也有了明显提升。同理,在YOLOv4-tiny 上做类似替换也能实现模型压缩及精度提升,且在CPU 上的推理速度也提高了27.13%。
3)通过实验5、实验6 可以说明,适当调整GhostBottleneckCSP 中 的GhostBottleneck 数量能够在一定程度上提升模型对小物体的检测能力,在本文所提模型的基础上,将第2个和第3个GhostBottleneckCSP中的GhostBottleneck 数量分别设为1 和3,对应实验2、实验3,更大数量的模型的精度有轻微提升,且对小物体的检测能力更强。在实际应用场景中,可根据任务需要适当调整GhostBottleneck 模块的数量,以达到模型大小与精度之间的平衡,实现更好的检测性能。
4 结束语
本文设计并实现了一种轻量化的YOLOv5 增强网络模型,该模型可以压缩大小并加快推理速度,模型精度得到一定程度的优化,同时极大降低了对硬件环境的依赖性,能够满足实际应用的需求。后续将在移动端进行模型部署,在实际应用场景中验证并完善所提模型,此外,将口罩佩戴特征与其他关联特征相结合,实现实用性更强的安全卫生监督系统,以更好地满足社会与日常生活的实际需求,也是下一步的研究方向。
