基于关联规则的大坝变形性态预判模型
2022-04-15李俊,王康,张群
李 俊,王 康,张 群
(中国电建集团西北勘测设计研究院有限公司,西安 710065)
0 前 言
大坝变形监测是大坝安全监控的重要组成部分,建立精确的大坝变形预测模型对实现大坝安全状态预警及诊断分析有着重要意义。近年来,机器学习算法在大坝变形预测中的成果广泛应用于大坝安全监控领域,大都取得了较好的效果。范新宇等[1]运用BP 神经网络模型对某库区高边坡进行变形预测分析,应用效果良好;何明等[2]建立了基于最小二乘支持向量机的大坝变形预测模型,获得了较高的预测精度。但是,由于大坝变形过程具有高度非线性、动态性,且受多种因素相互影响等特点,导致支持向量机模型很难确定合适的核函数,神经网络模型容易过学习等问题[3-5]。
关联规则是一种重要的数据挖掘手段[6],是形如X→Y的蕴涵式,即事件由X推导出Y的简称。其中,X和Y分别称为关联规则的前端和后端,同时该事件有两个基本属性,即支持度和置信度。Apriori是一种经典的关联规则算法,用于挖掘大数据中潜在的事物联系。该算法采用自底向上的遍历思想逐级挖掘,以确保关联规则的准确性。周发超等[7]针对经典Apriori算法执行效率低的缺点,引进TID标识码使得算法效率大大提高;李汉巨等[8]广泛收集自然灾害数据,并利用改进的关联规则算法从中挖掘出自然灾害事件的关联规则,实现对自然灾害事件的预测。
本文以大坝实测数据为基础,将大坝变形影响因子(上游水位、温度等)作为关联规则的前端,大坝变形量为后端,利用Apriori算法进行关联规则的挖掘,建立关联规则库,然后将产生的关联规则用于建立大坝变形预判模型,实现大坝变形的准确预测,为分析大坝的运行性态奠定基础。
1 大坝变形关联规则库的构建
1.1 关联规则前端的选取
为了将关联规则用于大坝变形性态预判,对于形如X→Y蕴涵式,其后端Y必须是变形量,其前端X应为大坝变形的影响因子。根据经典的大坝变形统计模型[9]:
(1)
公式(1)中:Hi为上游水深的i次方;Ti为测点前i天每天的坝体温度平均值;θ为蓄水初期到目前的天数除以100。
由于H、H2、H3、H4之间有确定性关系,所以关联规则挖掘时仅选择H作为影响因子;Ti表示测点前i天的坝体温度平均值,选取测点当天和前3、10、30、60 d的坝体温度平均值作为影响因子;关于时效变形,采用不断更新挖掘数据的方法,保证关联规则库的新陈代谢,可以最大程度地消除时效变形的影响。最终确定关联规则的前端为6个影响因子:H、T、T3、T10、T30、T60,考虑到温度影响因子过多使得预测难度增加的原因,关联规则的前端要求可以降低为:H和至少任意3个温度影响因子。
1.2 影响因子与变形量的关联度
关联度在数学上是指两函数相似的程度,是表征两个事物之间的关联程度[10]。本文以影响因子与大坝变形量间的关联度为权重指标,建立大坝变形性态关联规则。上游水位H、温度T、前i天平均温度 ,Ti(i=3,10,30,60)与变形量D之间的关联度:
假设有m组监测数据,构成的影响因子矩阵i:
(2)
公式(2)中:i1j,i2j,i3j,i4j,i5j,i6j(j=1,2,…,m)分别表示6个影响因子序列。
变形量矩阵d:
d=(d1d2…dm)
(3)
首先对影响因子矩阵i和变形量矩阵d进行归一化处理,得到无量纲矩阵I和D。则关联系数可按下式计算:
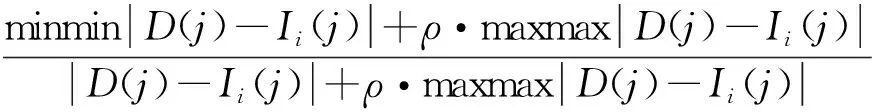
(i=1,2,…,6)
(4)
公式(4)中:ρ为分辨系数,通常取0.5。
关联系数的均值即为影响因子与变形量之间的关联度:
(5)
1.3 大坝变形关联规则的挖掘
Apriori是一种常用的关联规则挖掘算法。在算法执行前,用户应先设定2个阈值:最小支持度和最小置信度。支持度是指该规则在数据库中出现的次数或频率,置信度是指该规则在数据库中的准确性。所有支持度大于最小支持度的项集称为频繁项集,置信度大于最小置信度的关联规则称为强关联规则。
首先挖掘实测数据中的频繁项集,然后将频繁项集推导成关联规则。利用Apriori算法产生频繁项集过程主要分为连接和剪枝两步。首先,将包含i个变量的项集称为i项集,将包含i个变量的频繁项集称为i频繁项集,扫描所有实测资料,产生候选i项集,根据最小支持度,产生1-频繁项集。然后由1-频繁项集自连接产生2-项集,对2-项集剪枝处理,即剔除2-项集里面有非空子集是非频繁项集的项,再根据最小支持度,产生2-频繁项集。重复以上步骤,直到得出所有频繁项集。然后将得到的频繁项集推理成关联规则,以4-频繁项集(H,T,T3,D)为例,其中:H事件为当天上游水位取值在区间[a,b]内;T事件为测点当天温度取值在区间[c,d]内;T3事件为测点前3 d温度均值在区间[e,f]内,D事件为测点当天变形取值在区间[g,h]内。则可推理出关联规则:
H、T、T3→D
则该关联规则的支持度和置信度分别为[5]:
Support(H、T、T3→D) =P((H、T、T3)∪D)
(6)
confidence(H、T、T3→D) =P((H、T、T3)|D)
(7)
该关联规则可以表述为:当上游水位H、当天温度T、前3d平均温度T3分别在区间[a,b]、[c,d]、[e,f]内时,变形量有P((H、T、T3)∪D) 的可能性出现在区间[g,h]内,且这种情况出现的频率为P((H、T、T3)|D) 。
1.4 Apriori算法的改进
在对监测数据进行关联规则挖掘前,用户需要设定2个重要的阈值,即最小支持度和最小置信度。然而在利用关联规则进行大坝变形量的预测时,关联规则的前端包含影响因子的数量并不是固定的,如果按照常规方法,将最小支持度和最小置信度设置成定值,那么会导致影响因子数量较少时,预测精度偏低。鉴于此,本文提出基于关联度的融合支持度和融合置信度的概念,用于提高关联规则的预测精度。
单个影响因子与变形量之间的关联度可按公式(5)计算得到,那么n个影响因子的融合关联度可表示为:
(8)
设定当全部6个影响因子为前端时初始最小支持度和初始最小置信度为Sup6和Conf6,那么任意n个影响因子作为关联规则的前端时,相应的融合最小支持度Supn和融合最小置信度Confn为:
(9)
(10)
在对不同影响因子进行关联规则挖掘时,采用相应的融合最小支持度和融合最小置信度作为Apriori算法的最小支持度和最小置信度,以改善关联规则的预测性能。
2 大坝安全变形性态预判模型
2.1 大坝变形性态指标的拟定
根据大坝上某一点的变形监测资料统计分析,以该点变形量的历史最大值σmax为基础,结合标准正态分布,确定大坝变形性态的临界值系数。
(11)
公式(11)中:临界值σi的系数拟定思路为:第一、二、三、四临界值由标准正态分布密度函数横轴分别在(-∞,2.5]、(-∞,2]、(-∞,1.5]、(-∞,1]范围内面积所对应的大坝变形处于安全状态的概率,如图1。
4个临界值系数将大坝变形划分为5种性态,即非常稳定、稳定、基本稳定、异常、失常。同时,对于上游水位、温度也采用相同的临界值系数进行区间划分。
2.2 大坝变形性态预判模型
将用关联度改进的融合支持度和融合置信度作为Apriori算法挖掘时的最小支持度和最小置信度,对不同类型的关联规则前端进行挖掘,然后将产生的强关联规则用于预测,建立预判模型。具体实现过程如图2,主要步骤如下:
(1) 将监测数据离散化处理。Apriori算法不具备处理连续型数据的能力,因此在进行关联规则挖掘前,应先将变形量和影响因子的取值根据上述4个临界值系数划分为5个区间,用区间编号代替变形量和影响因子的具体值;
(2) 计算影响因子与变形量之间的关联度。关联度的计算方法可按公式(4)和公式(5)计算;
(3) 计算不同关联规则前端对应的融合最小支持度和融合最小置信度。本文选取6个影响因子,其中包含5个温度影响因子,若从这个5个温度影响因子中随机选取至少3个,共有16种不同的组合。给定包含全部影响因子的融合最小支持度Sup6和融合最小置信度Conf6,可按公式(8)、(9)和公式(10),分别计算各不同组合关联规则前端的融合最小支持度和融合最小置信度;
(4) 关联规则挖掘。对不同的关联规则前端,利用Apriori算法对离散化的监测数据在融合最小支持度和融合最小置信度2个阈值下进行关联规则的挖掘,将挖掘出来的关联规则构成关联规则库,用于大坝变形性态预判;
(5) 利用准确关联规则预判。本模型在预测时,关联规则前端的部分影响因子(如H、T)需要根据水文和天气预报来确定。因受制于水文及天气预报精度的影响,本模型仅对未来3 d的大坝变形进行预测。如H(2)、T(4)、T3(3)、T30(3)→D(2)的关联规则,当H、T、T3、T30分别处在区间2、4、3、3时,我们可以推断大坝变形量D处于区间2,大坝变形处于稳定状态,并同时给出预测可信度,即这条关联规则的置信度;
(6) 利用近似关联规则预判。真正进行预测时,会发现有时候前端影响因子所处的区间组合超出关联规则库的检索范围。此时,应采用与之所处区间最相近的关联规则进行预测,利用近似关联规则预测需符合以下要求:① 近似关联规则的前端应尽可能包含更多的影响因子;② 近似关联规则前端影响因子所处区间的性态级别应不低于影响因子实际处所区间;③ 近似关联规则前端单个影响因子所处区间的性态级别最多不超过实际所处区间1级;④ 近似关联规则前端最多只能包含2个近似影响因子;⑤ 若在以上近似条件下仍然没有可用关联规则,应特别指出;
(7) 模型评价。将模型预测结果与实际监测数据对比,分别计算未来1、2、3 d的预测准确度。
3 工程实例
本文以某双支墩大头坝第四坝段坝顶水平位移(PL4)为预测对象。本文选取2018年1月1日至2020年11月16日共计1051组数据用于关联度的计算和关联规则的挖掘,测点变形量和影响因子过程线如图3所示。由于该工程坝型的特殊性,关于气温因子的选择需做如下讨论:该工程共有3处气温测点,分别为坝上气温、坝下气温和垛内气温。参考文献[9]中指出,对于有坝体内部温度监测仪器的,应优先选择坝体内部温度作为影响因子。虽然垛内气温不能完全代表坝体温度,但可以用考虑滞后效应的垛内气温来表征坝体温度,所以本案例中选用垛内气温作为影响因子。
3.1 关联度计算
利用公式(5)计算影响因子H、T、T3、T10、T30、T60与变形量D的关联度分别为0.5852、0.5473、0.5512、0.553、0.5629、0.5759。
3.2 融合最小支持度和融合最小置信度计算
经过反复试验并结合工程实际,本文初步确定当全部6个影响因子为前端时初始最小支持度和初始最小置信度为Sup6=2和Conf6=0.6,利用公式(9)和公式(10)分别计算不同关联规则前端的融合最小支持度和融合最小置信度,结果见表1。
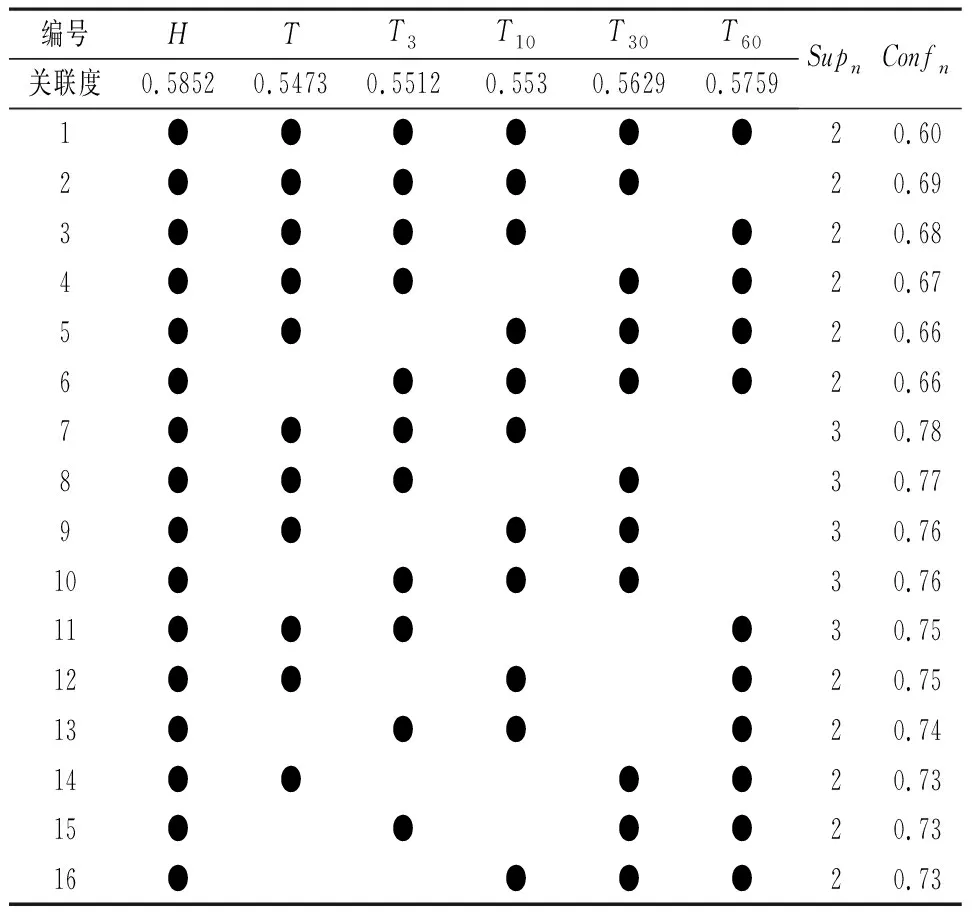
表1 不同关联规则前端的融合最小支持度和融合最小置信度
3.3 关联规则的挖掘
将影响因子组成的16种不同关联规则前端和变形量作为Apriori算法的输入矩阵,然后输入相对应的融合最小支持度和融合最小置信度进行关联规则的挖掘,共挖掘出307条有用关联规则。
3.4 利用(近似)关联规则预测及评价
考虑到绝大多数时间大坝都处于较安全状态,无法较为全面地利用关联规则,所以本文选取1 a当中变形量较大的5—9月份的监测数据作为检验集进行模型精度检验。本文选取2020年5月16日至9月15日共计123组数据进行预测,将预测结果与实测值绘制成热点如图4所示,图中横坐标表示检验集时间轴,纵坐标为3种不同预测方式和实测值下的测点变形性态,颜色越深,表示测点变形所处的形态等级越高,预警级别也越高。此图可以较为直观地表现出测点的变形性态等级和预测结果对比。
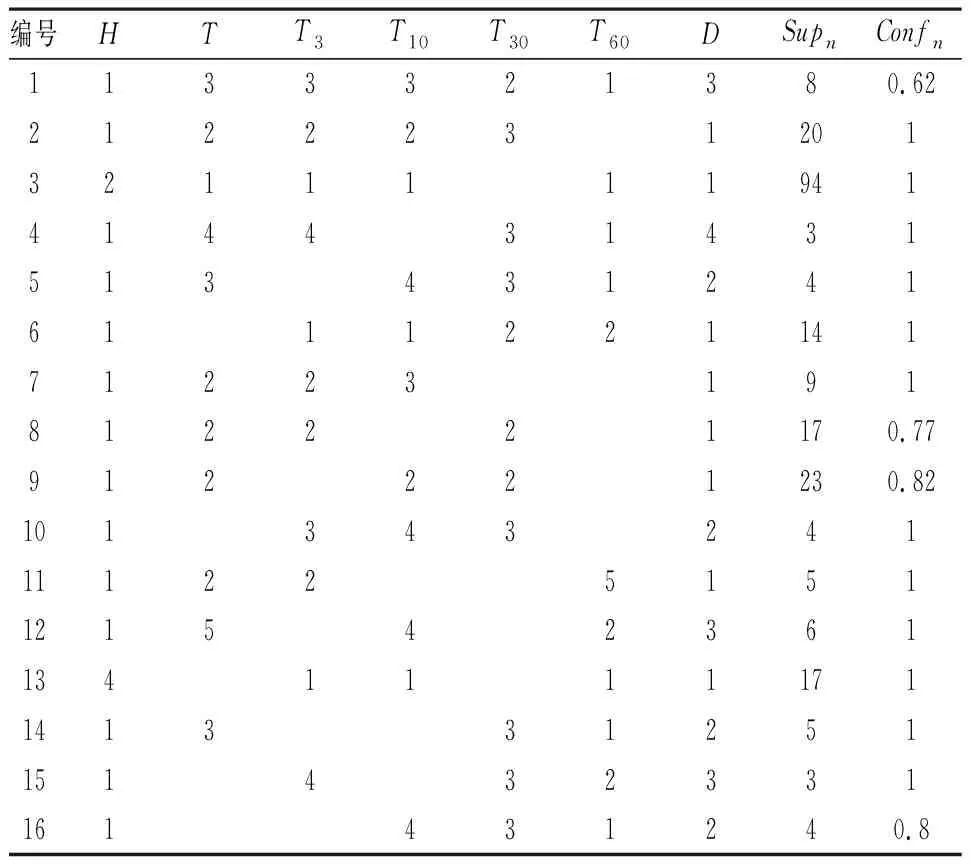
表2 关联规则库(部分)
从图4可以看出提前越长时间预测,预测结果出错率越高。将上述3组预测出错结果汇总见表3,从该出错明细表可以看出,该模型具有较好的预测精度,预测结果较为理想。
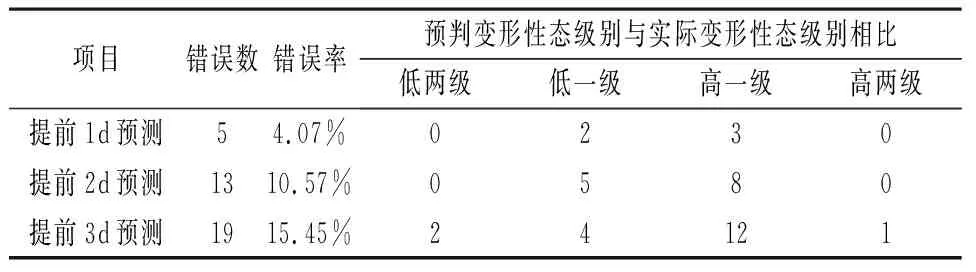
表3 预测结果出错明细
4 结 论
本文所建立的模型是基于Apriori算法对监测资料进行关联规则的挖掘,并用关联度改进算法中的2个关键阈值,同时提出利用近似关联规则预测的基本要求,以实现大坝变形的预测。形成结论如下:
(1) 模型根据经典的统计模型选定影响因子作为关联规则的前端,并用关联度对传统Apriori算法进行改进,具有很强的理论基础,可靠性较高。
(2) 由于Apriori算法从数据层面出发,进行深度挖掘,即使模型在影响因子、阈值选择方面出现一定的不精确,挖掘出来的关联规则仍然满足最小支持度和最小置信度的要求,所以挖掘出来的关联规则还是具有一定的可靠性,模型容错率很高。
(3) 将本模型应用到某双支墩大头坝,获得了较高的预测精度,从上述关联规则预测及评价中可以看出,当利用关联规则提前1 d预测时,出错率仅为4.07%,大坝变形性态误差级别不超过一级,且在高危变形性态时间段内没有出现预判错误,说明将其应用于大坝变形预测是可行、有效的。
