基于“聚类-过采样”方法的肿瘤免疫亚型分类研究
2022-04-14田夫蓉白新宇
田夫蓉,白新宇
(贵州师范大学大数据与计算机科学学院,贵阳 550000)
0 引言
近年来,我国肿瘤的发病率和死亡率不断走高,有效的筛查技术较少,诊断水平不高使得肿瘤在早期不能被及时发现,现已成为世界上死亡率最高的疾病之一。如果能够提高早诊率、正确识别癌症的类型,将有助于提高癌症的治愈率。为了更好地研究癌症的病发,部分科学家转向对肿瘤的免疫亚型研究。肿瘤的免疫亚型分类一直都是“癌症基因组学”研究的重要课题之一。对肿瘤免疫亚型的精准分类,将对肿瘤的早期诊断、预测与后期疗效评价等多个方面起到重要作用。
解决肿瘤免疫亚型的分类问题,目前使用最多的方式是将基因测序数据与机器学习算法相结合来进行分类。肿瘤免疫亚型数据集(也称为“样本集”)存在样本不平衡的问题,直接在原样本集上进行分类会导致效果不理想。针对样本分布不均衡问题,提出了一种新样本合成方法,来平衡各类别的数量分布。首次将该方法应用在肿瘤免疫亚型分类问题中,增加分类中少数类样本的数量,实现样本均衡。
1 相关工作
随着大数据时代的到来,样本类别分布不均衡的分类问题在疾病监测、欺诈侦查等领域均受到了广泛关注,这类问题的主要特征是不同类别间的样本数量规模差异较大。Weiss通过多次分类实验,明确指出样本不平衡的样本集会使分类结果不佳。医疗领域中,对少数类的误分可能造成严重的损失。因此,保证样本集中各类别数量均衡,可以使分类器分类性能得到显著的提高。传统的分类算法在处理不平衡样本分类问题上效果表现较差,其主要原因是,在分类模型的训练过程中,样本的不平衡分布会导致不同类别的样本被使用的机会不均等。如:多数类(样本数量较多的一类)被使用的机会较多。而少数类(样本数量较少的一类)被使用的机会较少。这将使得分类器对多数类样本特征更敏感,所以面对新样本时,更容易将其划分为样本数量较多的一类。
解决样本分布不平衡分类问题的方法,可分为降采样法和过采样法。降采样通过减少多数类样本数量,在原始数据集上创建平衡子集。文献[10]中指出,增加训练集的数据量可以在一定程度可以减少错误率。因此,在小样本的分类问题中,降采样方法很少使用。过采样通过增加少数类样本来保证各类别样本的规模相近,常用于样本规模较小的分类任务中。常用的过采样方法包括随机采样法、SMOTE(synthetic minority oversampling technique)、Borderline-SMOTE和ADASYN。
最简单处理样本不均衡问题的方法是随机采样。随机采样方法虽然可以均衡样本,但也存在一些问题。比如,过采样只是简单地对少数类样本进行复制,扩大了样本数据的规模,增加了模型的训练复杂度,严重的会造成过拟合。SMOTE选择少数类样本作为种子,找到离种子最近的个样本S,并为每个S赋予随机权重,将S加权求和得到新的伪样本。SMOTE为原始数据集引入了新的样本,但是该方法需要人工选择超参数。由于未考虑S样本类别信息,容易使得新生成的伪样本中包含其他类别样本的特征。Border-line SMOTE是对SMOTE方法的一种改进,该算法使用各类别交汇边界上的少数类样本来合成新样本,从而改善样本各类别分布混淆的问题。ADASYN对SMOTE的采样过程进行改进,采用一种自适应机制决定每个少数类样本需要合成多少伪样本,但该方法受离群点的影响较大。
Hulse在文献[15]中指出,在样本类别分布不平衡的分类问题中,类内的样本分布也会影响最终的分类结果,且少数类内部样本分布越不平衡,对分类结果的影响就越大。
以上方法仅考虑了类间样本数量不平衡的问题,并未涉及少数类内部分布对分类结果的影响。本文提出了一种利用少数类的核心特征来合成新样本的方法,用于解决类间样本规模不平衡问题和少数类内部分布不均衡问题。为了方便描述,将该方法简记为“聚类-过采样法”(clustering minority over-sampling technique,CMOT)。
2 研究方法
为了解决肿瘤免疫亚型样本分布不均匀的问题,使用CMOT法产生少数类的伪样本,来保证六种肿瘤免疫亚型样本数量规模相近,并通过使用随机森林分类器来验证该过采样方法的有效性。
2.1 数据来源
癌症基因图谱(the cancer genome atlas,TCGA)计划是美国国家癌症研究所和美国人类基因组研究所共同监督的一个项目,同时TCGA也是目前最大的癌症基因信息数据库之一。本实验使用的数据集源于TCGA平台,由Veste⁃inn Thorsson针对TCGA平台33种癌症样本进行研究,结合6种分子平台数据来计算160种免疫特征间的相关系数,通过聚类分析最终得到5个免疫表达特征。根据这五种免疫表达特征,将所有非血液肿瘤聚类分为6种免疫亚型(伤口愈合型、IFN-γ主导型、炎症型,淋巴细胞殆尽型、免疫静默型和TGF-β主导型)。为了方便描述将六种免疫类型记为:C1、C2、C3、C4、C5、C6,六种免疫类型的数量分布如表1所示。

表1 六种免疫类型数量统计
2.2 聚类方法选择
聚类是按照某种特定标准把样本集分割成不同类簇的一种方法,是搭建一个正确数据模型的重要步骤。为了保证少数类内部样本分布更加均衡,本文使用聚类的方法将少数类划分为几个小的类簇,找到代表类簇核心特征的聚类中心点,将聚类中心点加权求和产生新的伪样本来增加少数类的样本数量。在同一数据集上,不同的聚类方法有不同的表现。因此,以TGF-β主导型肿瘤样本集为例,通过使用六种常见的聚类方法(Agglomerative Clustering、KMeans、DBSCA、Birch、Spectral Clustering、Mean shift)进行聚类,选择适用于该样本集的聚类方法。
图1为六种聚类方法在C6样本集上的聚类结果。观察可知,使用DBSCA、Birch、Spec⁃tral Clustering、Mean Shift等方法进行聚类,聚类结果均出现不同程度的不平衡情况。Agglom⁃erative Clustering和KMeans方法聚类效果相对较好,但Agglomerative Clustering方法中出现了类簇边界混淆的情况(如图中绿色类簇穿插到了黄色类簇与蓝色类簇之间)。因此,最终选择KMeans方法的进行聚类,该方法可以保证每个小的类簇规模相近,且类簇间的分布相互独立。

图1 六种方法的聚类结果对比
2.3 K值选择
KMeans是一种较为常见的聚类方法,因为其简单实用的特性被广泛地应用于数据挖掘领域,但这种方法需要人为确定聚类的个数。实际上,我们希望能够找到一些可行值的估计方法。但是,值的选择一般基于经验和多次试验结果。因此,我们尝试用不同的值进行聚类,以轮廓系数(silhouette coefficient)作为评价指标来度量聚类结果的优劣,轮廓系数公式如(1)所示。

其中()是样本到同簇其他点距离的平均值,体现了同一类簇的凝聚度。()是样本到其他类簇样本的平均距离,代表了各个类簇间的分离程度。所以,轮廓系数值越大,表示聚类结果的类内凝聚度越强、各类簇间的分散程度越大、聚类的总体效果越好。
图2展示了值取3,4,5,6的聚类效果和轮廓系数。以值取3的结果为例,右侧图是聚类的可视化结果,左图的横轴表示当前的值对应的轮廓系数,纵轴表示聚类标签,每个标签的面积体现了该类簇所占比例。观察可知,当聚类个数为3和4的时候,轮廓系数值最大。但当聚类个数为4的时候,各个类簇的数量分布更加均衡,所以本实验值定为4。

图2 选取不同K值的轮廓系数和聚类结果对比
2.4 CMOT
CMOT方法通过聚类的方式找到类簇核心特征,并对核心特征点加权求和得到新的伪样本。这是一种通过合成伪样本,来增加样本点的方法,其主要优点是可以合成独立于原始样本集的新样本,可用于提升分类模型的泛化性。下面详细叙述CMOT方法步骤:
(1)通过KMeans聚类方法,将少数类聚类为四个小的类簇并找到聚类中心点,如图3(a)所示,红色“×”表示该类簇的核心特征。
(2)由(1)中的聚类中心点,结合公式(3)加权组合生成新的伪样本,来扩充少数类的样本数量(其中w表示为第个聚类中心分配的权重,(0,1)表示0~1之间的一个随机数,[]表示第个聚类中心点,为新生成的少数类样本)。

(3)重复执行(2),直到少数类样本数量和多数类样本规模相近为止。
图3为CMOT在C6样本集上的表现,(a)(b)两图展示了采样前后各类别的分布情况,新生成的伪样本不仅在每个类簇上分布均衡,而且很好的保证了少数类中样本的原始分布。
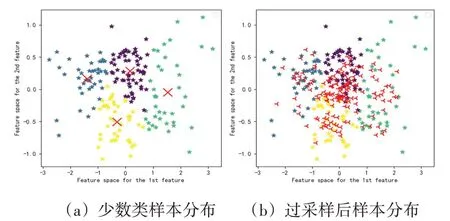
图3 CMOT采样前后对比
由于新样本是由聚类中心点加权求和产生的,通过该方法合成的样本不会有离群点出现。因此,在一定程度上减少了类内数据不平衡的现象。
3 分析讨论
3.1 评价指标
(1)Micro。Micro是一项宏观的评价指标,通过统计总体数据来计算,即把所有的类的TruePositive(TP)除以所有类别的TP与False⁃Positive(FP)的加和。因此Micro方法下的pre⁃cision和recall都等于accuracy。

(2)Macro。Macro是一项微观的评价指标,通过统计各个类别数据来计算,即把分别求出每一个类别的precision再求其算数平均。公式(4)中为总类别数。

(3)Weighted。Weighted是一项综合的评价指标,Macro算法是对各类的precision和取算术平均,Weighted算法是对Macro算法的一种改进,Weighted算法以每个类别的占比为权重,重新计算得到加权precision。

其中,表示正样本被正确的预测为正;表示正样本被错误的预测为负;表示负样本被错误的预测为正;表示负样本被正确的预测为负。
3.2 实验结果
本实验所使用的样本集公开于Github。实验中将原始样本集按照训练集比测试集为4∶1的比例进行划分。为了保证实验效果的真实性,仅对训练集样本使用CMOT方法进行过采样,用于模型训练,其余部分用于模型测试。过采样后训练集中各类别数量分布如表2所示。为了增加分类器的泛化能力、节省训练时间、平衡数据误差,本实验选择以随机森林作为分类器,表2中的每一个指标的取值均是五次重复试验得到的平均结果。

表2 训练集过采样后免疫亚型的数量分布
表3为使用多种过采样方法进行分类的结果对比,分别采用随机采样法、SMOTE、Borderline-SMOTE、CMOTE等四种方法并使用随机森林算法做分类器,由图4可以看出,与未经过过采样的结果对比,CMOT对分类的性能提升最大,Borderline-SMOTE和SMOTE次之,随机采样性能提升效果最差。
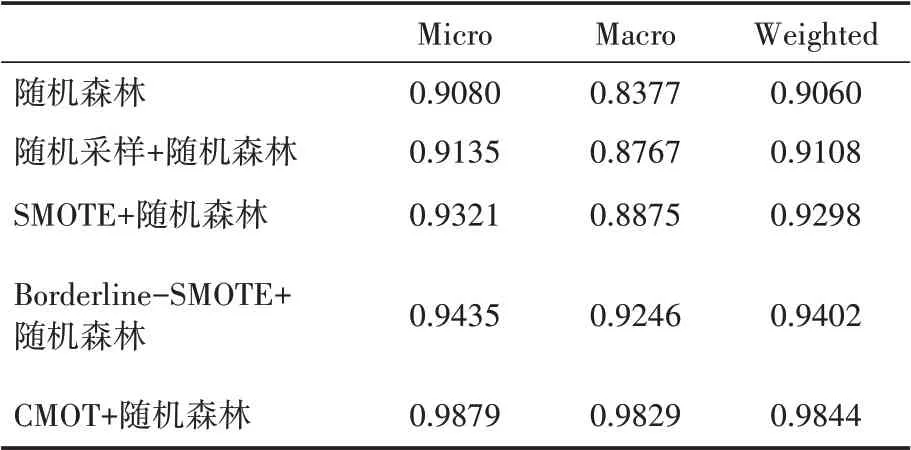
表3 基于过采样分类结果对比

图4 多种采样方法分类结果对比
该结果表明:COMT采样法,在肿瘤免疫亚型分类任务中具有更好的表现。究其原因,总结为两点:①本文提出的CMOT方法,增加了少数类样本数量,实现了训练集类间样本数量均衡。②使用CMOT方法生成的伪样本,既保留了原始样本的重要特征,也合成了新的特征,增加了训练集样本的多样性。
4 结语
针对样本不平衡的肿瘤免疫亚型分类问题,本文提出了一种合成伪样本的方法,通过向少数类中增加伪样本,使得训练集中各类别样本量更加均衡,同时也使得肿瘤免疫亚型分类的准确率大幅提高。但本文的研究工作还可以从以下两个方面探究:①本实验的样本数量较少,因此选择的过采样的方法使得数据达到平衡,面对数据规模较大的数据集,可能需要寻找更好方法来进行下采样。②本实验提出的方法在解决肿瘤免疫亚型分类问题取得了较好的效果,但未在其他领域进行验证,因此可考虑将其用于不同任务中。
