基于主动学习的非平衡支持向量机分类方法
2022-04-14崔丽娜
崔丽娜
(长治幼儿师范高等专科学校信息技术教学部,长治 046000)
0 引言
随着大数据时代的到来,数据已经成为一种重要的战略性资源,数据工程领域呈现出一种“6V”特性,即容量大(Volume)、种类多(Variety)、速度快(Velocity)、可变性(Variabil⁃ity)、真实性(Veracity)、价值密度低(Value),这种“6V”特性又决定了大数据本身特有的复杂性,非平衡数据就是一类最典型的复杂数据。现实世界中存在大量非平衡数据问题,例如在信用卡交易欺诈的检测中,更关心欺诈用户的识别,但非法的欺诈交易只是偶尔发生,大部分记录都是正常交易;再如在患者肿瘤情况的检测中,肿瘤呈阳性的比例要远少于肿瘤呈阴性的比例,但在检测中需要准确发现严重的阳性肿瘤患者,以进行及时的治疗;此外,非平衡分类问题在雷达图像监测、金融贷款管理、企业破产预测、电信设备故障检测、文本分类、垃圾邮件过滤等实际领域中都非常常见。
目前,针对非平衡问题的理论及应用领域,已经提出了多种解决非平衡分类问题的机器学习方法,支持向量机作为一种典型的机器学习模型,也在非平衡数据问题中得到了较为成功的应用。目前,支持向量机处理非平衡数据分类问题大体上包含三种思路:一是对训练数据的重采样,对大量的多数类样本进行下采样,对稀少的少数类样本进行上采样,通过这种方法达到数据的近似平衡分布,提高分类的性能;二是对数据集进行偏置性的权值设置,即通过对少数类样本与多数类样本设置不同的权值,以使得重要的少数正类样本尽可能强制分类正确;三是通过抽样得到初始超平面之后,通过一定的启发式规则调整分类超平面使其逼近最优分类超平面,提高对少数类数据的识别效率。
虽然这些方法可以提高支持向量机处理非平衡分类问题的性能,但都存在一些局限。基于采样策略的SVM非平衡分类方法尽管使得数据分布趋于平衡,但下采样可能会将包含重要信息的数据丢弃,而上采样会增加训练的开销,导致原本学习效率就不高的SVM效率进一步降低,此外由于强行无根据地进行人为的训练样本分布改变,导致了实际参与训练样本的分布与测试集样本不再符合机器学习中训练样本与测试样本独立同分布的大前提,得到的结果缺乏可信性和可解释性;基于权值调整策略的SVM非平衡分类方法虽然通过对不同类样本设置不同的权值,使得少数类样本在分类过程中错分的概率减小,一定程度上提高了正类样本分类的准确率,但其权值设置没有统一的理论依据,不同的数据、不同的情况可能需要设置的权值分布就不同,因此,这种方法中权值设置时一个瓶颈问题,同时也缺乏相应理论支撑;基于超平面调整的SVM非平衡分类方法往往是在得到初始分类超平面之后,根据一定的启发式规则进行超平面的一次性调整,调整超平面的方向和幅度也一般都是通过实验测试进行,缺乏相应理论和依据,实验结果缺乏可再生性和可解释性。
针对传统SVM无法有效处理非平衡数据分类的问题,本文结合主动学习具有很好的人机交互作用的特点,提出一种新的非平衡SVM分类方法,该方法先将多数的负类样本进行划分并采样,再与正类样本合并训练得到初始分类器,在此基础上根据负类剩余样本集中样本到分类器的距离,逐次选择主动学习中的关键信息样本加入到负类训练样本集中,同时删除负类训练样本集中相对次要的非关键信息样本,始终保持训练集样本分布的平衡,有效提高SVM对于非平衡数据分类的泛化性能。
1 非平衡SVM分类与主动学习
1.1 非平衡SVM分类及分析
传统的SVM在处理非平衡数据的分类问题中,经训练得到的分类超平面总是向少数类样本偏斜,使少数正类样本被错误归类,失去了对重要正类样本的识别能力。本文以在二分类问题为例,假设样本有横轴和纵轴两个特征,且在这二维特征上均符合正太分布,分别以(-1,-1)与(+1,+1)为中心构造两类样本,其中正类样本和负类样本的规模分别取(500,500)、(100,900)、(50,950)、(20,980)和(10,990)这5种从平衡到不平衡的情况,然后采用传统SVM在这种二分类样本上进行训练,图1和图2分别为线性核和高斯核在两类不同非平衡性的样本上得到的分类超平面。图1表明,随着正负类样本集不平衡程度的增加,分类超平面更加偏向少数类样本,当正类样本和负类样本比例偏差达到一定程度时(如图中的50:950),两类数据无法分开,即SVM已经无法得到分类超平面。从图2可以看出,虽然随着样本不平衡性的增加,分类超平面一直都可以得到,但学习得到的分类超平面明显偏向于少数正类样本的分布区域,即对重要的少数正类样本缺乏识别性能。
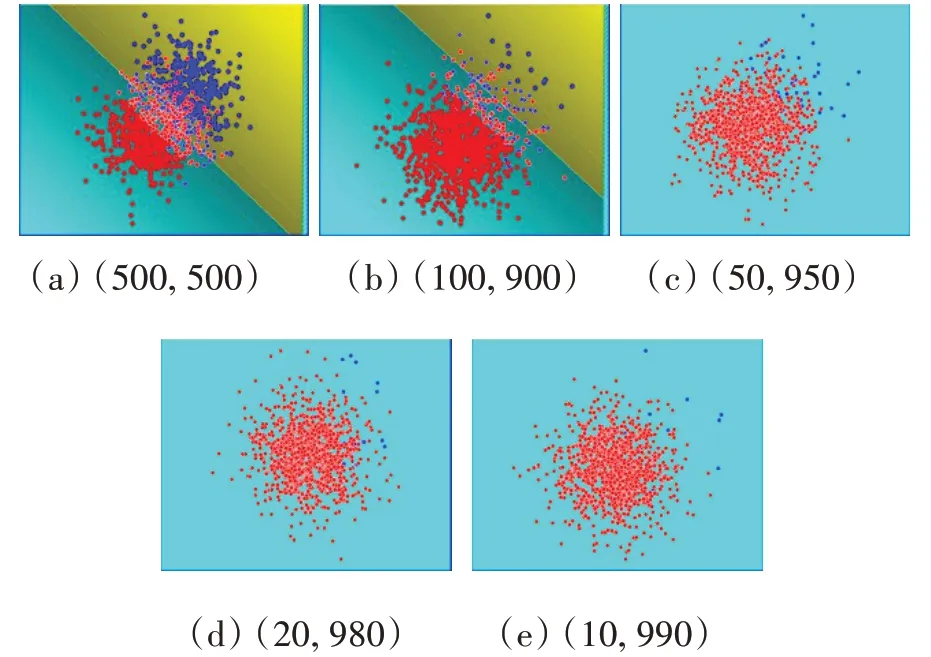
图1 基于线性核SVM的非平衡数据分类面(正类,负类)

图2 基于高斯核SVM的分类面(正类,负类)
1.2 主动学习
主动学习(active learning,AL)是一种应用于解决大规模机器学习问题的典型策略,已经在图像处理、语音识别、信息提取、计算生物学等许多领域得到实际应用。主动学习的本质就是构建一种关键信息样本选择的启发式规则,根据该规则主动地选择训练样本中对于学习任务最为重要的关键信息样本加入训练集来参与训练,并通过循环迭代得到最终的机器学习结果。在主动学习过程中,由于只有少量的关键信息样本参与训练,因此训练集规模较小,噪声样本影响较少,学习效率较高。由于支持向量机是一类小样本学习器,其虽然泛化性能较好,但其由于要构造核矩阵并进行运算,训练时间复杂度为(),其中为样本规模,因此当训练集样本规模较大时,无法进行高效学习。
目前,针对SVM无法处理大规模复杂数据学习的问题,已经结合主动学习方法,提出了一些基于主动学习的SVM改进学习算法,如Tong等选取距离超平面最近的样本作为重要信息样本参与训练,提高了SVM的学习效率,使SVM的近似超平面可以尽快地收敛于最优超平面,并将其应用于文本分类的实际问题;Schohn等认为当前分类器中不易识别的样本是最重要的,利用这些样本来构造信息样本集,设计出Uncertainty Sampling等采样方法提取重要信息样本。尽管这些主动SVM分类方法通过构建启发式的关键信息样本提取规则,提取含有重要分类信息的样本加入训练集迭代主动学习,提高了学习效率。但这些方法都是针对平衡数据分类问题的,对于非平衡数据的分类问题并不能使用。因此,如何结合主动学习模型,抽取非平衡分类问题中更有价值的信息样本,以提高传统SVM处理非平衡数据的分类性能是一个值得研究的问题。
2 基于主动学习的非平衡SVM分类方法
本文结合主动学习的思想,提出一种基于主动学习的针对非平衡数据分类的SVM改进分类方法。该方法首先将规模较大的负类样本划分为与正类样本个数一致的簇,计算出每个簇中心作为负类训练样本集,将其与正类样本合并训练,得到初始分类超平面。由于对SVM最优分类超平面起决定作用的样本往往分布在超平面附近,越远离分类超平面的样本越无关,因此在剩余的大规模负类样本集中根据样本到近似超平面的距离,选择主动学习的关键信息样本(即距离当前分类超平面最近的负类样本),同时删除负类训练样本集中距离超平面最远的样本,以始终保持SVM训练样本中不同类别样本分布的平衡性,有效提高SVM对于非平衡数据分类的泛化性能。

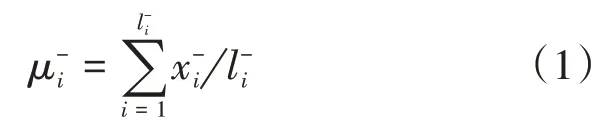


根据负类剩余样本集中每个样本到超平面的距离,即可选择主动学习当中需要加入的关键信息样本和需要删除的非关键信息样本,二者的选择方式见如式(3)、式(4):
关键信息样本:
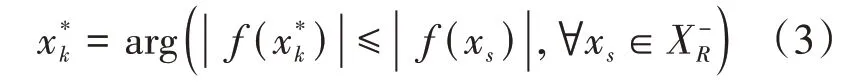
非关键信息样本:
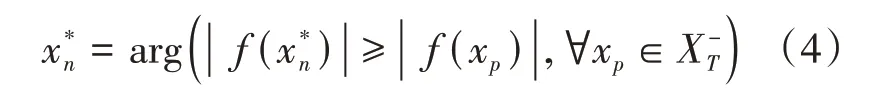

基于主动学习的非平衡SVM分类算法
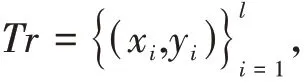


(4)使用新训练集训练SVM模型,得到分类器,并测试其分类性能。
(5)根据式(2)计算负类剩余样本集中样本到分类超平面的距离,并根据式(3)从负类剩余样本集中选择关键信息样本,并对负类训练样本集和负类剩余样本集进行更新,更新方法如下:

(6)根据式(2)计算负类训练样本集中样本到分类超平面的距离,并根据式(4)从负类训练样本集中选择非关键信息样本,并对负类训练样本集和负类剩余样本集进行更新,更新方法如下:

(7)得到更新后的负类训练样本集与正类样本集合并构成新的训练样本集,转到(4)继续迭代执行,直到迭代次数达到要求为止。
(8)输出整个过程中得到的一系列分类器及一系列评测值。
(9)算法结束。
为验证ISVM_AL方法的有效性,实验中将该方法与标准SVM基于聚类的非平衡SVM(ISVM_C)分类方法进行对比研究。ISVM_C算法如下。
基于聚类的非平衡SVM分类算法



(4)使用新训练集训练SVM模型,得到分类器,并测试其一系列评测指标。
(5)算法结束。
3 实验结果及分析
3.1 实验数据集
为验证ISVM_AL分类算法的性能,本文分别在人工构造的非平衡数据集和多个典型的非平衡UCI数据集上都进行了测试。人工构造的非平衡数据集呈正态分布,正类和负类分别以(+1,+1)和(-1,-1)为中心,以(1 0,0 1)为协方差矩阵,构造训练集中负类样本与正类样本的比例为500∶500、900∶100和980∶20。测试集也同样方法构造,但数量规模扩大10倍,图3所示为构造的训练集样本分布情况;标准非平衡UCI数据集如表1所示,这些数据集可从网站http://www.ics.uci.edu/~mlearn上下载,为提高实验的测试准确性,在UCI数据集上采用五折交叉验证的方式,即将数据集五等分,其中一份作为测试集,剩余的四份合并作为训练集,实验中取五次实验的均值作为统计结果。实验中,将ISVM_AL方法与标准支持向量机(SVM)和基于聚类的非平衡SVM分类方法(ISVM_C)进行了对比。
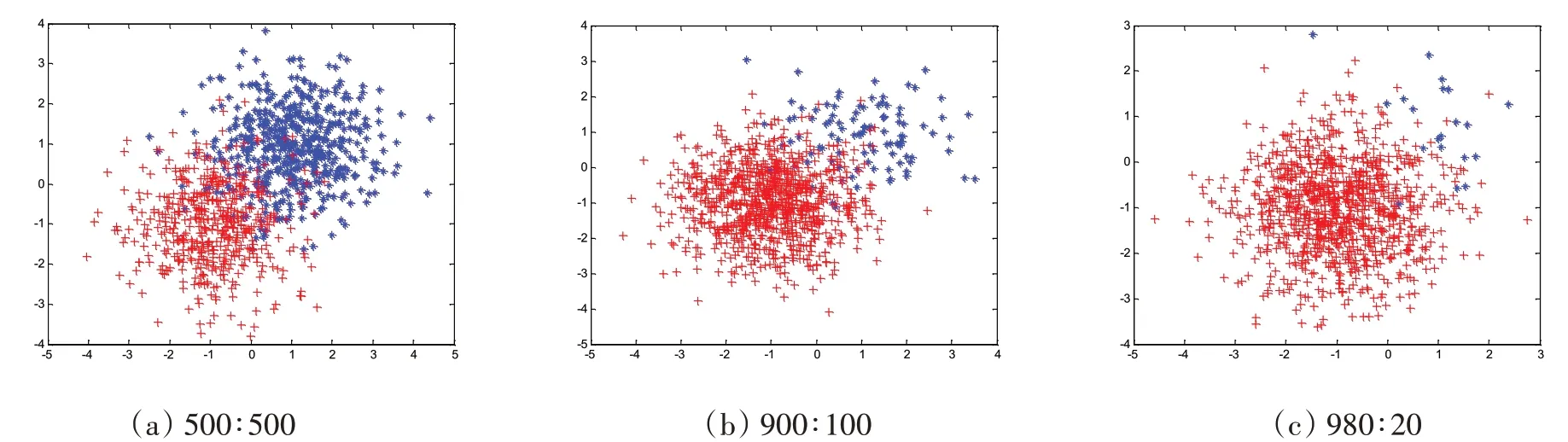
图3 正态分布数据集

表1 实验采用的UCI数据集
3.2 实验评测指标
为有效衡量所提出的基于主动学习的非平衡SVM分类方法的性能,本文在多种不同的非平衡分类指标上进行了全方位的测试。涉及到的测试指标如下:
(1)准确率()。用于测算所有测试样本中算法预测正确的比例:

(2)召回率()。用于测算实际正类样本中被正确预测的比例:
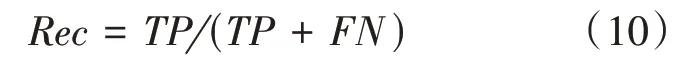
(3)特效性()。用于测算实际负类样本中被正确预测的比例:

(4)值。该指标综合衡量正类和负类样本的分类准确率,具体如下:
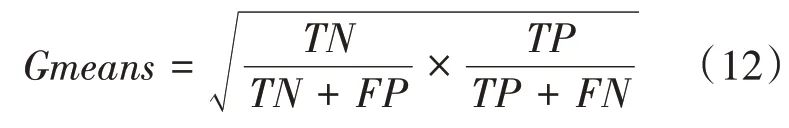
各评价指标涉及到的变量意义如表2所示。

表2 相关变量的意义
3.3 正态分布数据集实验结果及分析
对于人工构造的正态分布数据集,三个数据集的差异主要体现在不同类别的平衡度上,由于数据集分布简单,所以三种方法当中均直接采用线性核进行训练测试,由于模型选择不是本文重点考虑的问题,所以三种模型的惩罚参数均取默认值1。经三种方法训练测试,得到的实验结果见表3,实验中ISVM_AL方法的迭代步数默认取15。

表3 正态分布数据集上的实验结果
从表3可以看出,对于类型分布平衡的数据,三种方法得到的结果完全一致,这是由于当类别完全平衡时,本文所提出的ISVM_AL方法和对照的基于聚类的ISVM_C方法都退化为简单的SVM方法,因此得到的结果完全一致;而对于(b)组非平衡分布数据,SVM方法对正类样本分类效果较差,因而导致其对应的和值都比较低,尽管基于聚类的ISVM_C对于正类样本分类效果较好,但其在分对正类样本的同时也导致了大量的负类的错分样本,因此其对应的值和值都不高,而本文提出的ISVM_AL方法一方面采用聚类方法达到了不同类别之间样本的平衡,对于正类样本得到了较好的分类准确率,同时采用了基于关键样本提取的负类样本选择更新方法,负类样本的错分率也较低,因此其对应的的值和值都较好;此外,在另一组类别差异度更大的数据集上,SVM完全无法进行分类,即将全部的正类样本都错误地识别为负类,而ISVM_C方法尽管取得了较好的正类分类正确率,但负类样本的错分率非常高,而本文提出的ISVM_AL方法在提高正类样本分类正确率的同时,同时负类样本的错分率也较低,在综合反映正负类样本分类正确率的指标上,与ISVM_C相比,ISVM_AL提高了15%以上。
3.4 标准数据集实验结果及分析
对于标准数据集,三种模型的惩罚参数均取默认值1,由于这四个标准数据集均不是线性可分的,因此都采用高斯核进行训练测试,核参数为默认值,即取特征数的倒数。经三种方法训练测试,实验得到的各测试指标值如图4所示,实验中ISVM_AL方法的迭代步数默认取15。

图4 标准数据集上的测试结果对比
由于标准SVM和ISVM_C两种方法并不涉及模型参数,因此在图4中,SVM和ISVM_C两种方法得到的结果并不随着参数变化而变化,而对于本文提出的ISVM_AL方法,其性能随着迭代过程的改变而改变,且初始状态下,也是对负类样本进行了与正类样本规模相等的信息抽取,这一点与ISVM_C方法完全一致,因此其初始值和ISVM_C方法是相等的。但随着算法迭代次数的增加,ISVM_AL方法对于正类样本依然保持了较好的分类正确率,同时对于负类样本的分类正确率有了明显的提高,从而有效提高了分类的精度值和值,这充分说明本文提出的ISVM_AL方法一方面有效提取了负类样本的重要信息,保持了不同类样本的规模平衡,提高了正类样本的分类性能,同时通过主动学习的方法有效地抽取了负类样本集中重要的信息样本加入训练,从而在不影响正类样本分类的情形下,也有效提高了负类样本的分类性能,在不同类样本的分类效果之间得到了有效的折中。另外,为了进一步直观地观测分类效果,本文给出了数据集Thyroid上采用标准ISVM_C和ISVM_AL(迭代次数为10)的分类超平面(如图5所示)。从图中可以看出,在分类超平面边界附近,本文提出的ISVM_AL方法聚集了更多包含重要信息的负类样本。
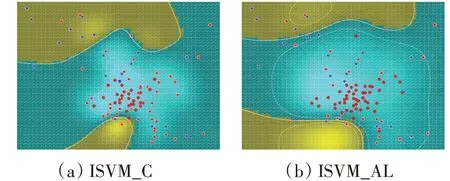
图5 ISVM_C和ISVM_AL得到的分类超平面
综上所述,本文提出的基于主动学习的非平衡SVM分类方法通过对负类样本进行压缩替换,保证了不同类样本规模的平衡性,提高了对于非平衡问题中正类样本的分类正确率,同时采用主动学习方法有效提取负类样本中的关键信息样本,删除非关键信息样本,在保持样本分布平衡的同时又保留了重要信息,从而在不同类样本的分类性能之间得到了较好的折中。
4 结语
针对传统非平衡支持向量机处理非平衡数据分类问题时无法有效平衡正负类样本分类性能而导致泛化性能差的问题,本文结合主动学习的思想,提出一种新的非平衡SVM的分类方法ISVM_AL。该方法先对多数类样本划分采样,并与正类样本结合构成平衡的训练集并初始分类器,然后采用主动学习方式从负类剩余样本集中选择关键信息样本逐次加入到负类训练样本集,同时删除负类训练样本集中相对次要的非关键信息样本,从而始终保持负类训练样本集与正类训练集样本规模的平衡性,提高了SVM对于非平衡数据分类任务不同类样本的分类性能。
