基于聚合残差网络的加密流量分类方法
2022-04-14李毅聃阮方鸣陈润泽
李毅聃,阮方鸣,陈润泽
(贵州师范大学大数据与计算机科学学院,贵阳 550025)
0 引言
随着网络通信技术的飞速发展,高吞吐量业务的需求大量增长,监测网络安全以及应用程序的行为安全变得越来越困难。而网络流量的准确分类可以在很大程度上解决这一问题,并且对网络流量进行分类的同时可以收集用户使用应用程序的需求和习惯,以便于提升用户体验以及优化监管系统。再加上其对于信息的采集可以进行流量需求预测,以及执行流量工程或服务水平协议校准,这些原因使得网络流量分类成为现代网络空间安全领域的一个重要任务,并且逐渐被互联网服务提供商和网络运营商所关注。
在流量分类这个问题上进行过的研究已经十分丰富。最早使用的基于端口的流量分类方法,是通过流量数据包中的端口号来分类。这种方法在以前的网络环境中是有效且便捷的,然而随着随机端口、端口伪装和临时端口等技术的产生,基于端口号的方法对加密流量分类的准确率一直在下降。之后出现的深度包检测技术(deep packet inspection,DPI),相比之前的方法能更深入读取数据包的载荷,并通过分析七层协议中的应用层信息,从而能够识别各种协议及应用。许多学者对该技术进行了研究,但由于深度包检测技术无法解密与分析目前主流的加密流量,在目前的适用性已大大降低。近几年较多研究集中在使用机器学习方法对流量进行分类,但传统的机器学习方法十分依赖特征选择,还需要人工提取特征,比较费时、费力,也容易出错,再加上分类的准确率并不高,因此目前关于流量分类的研究主要使用深度学习的方法。
1 方法设计
1.1 相关工作
据我们所知,Wang等人首先提出了基于深度学习的流量分类研究,作者提出了使用堆叠式自动编码器(stacked auto encoder,SAE)对网络流量进行分类。该文章实验证明,相比于传统的机器学习流量分类任务,使用深度学习方法不需要人工进行特征的选择,可以大大节省工作量。该文章作者还提出流量的每个字节可以看成是一个像素或一个单词,这个思想在之后给了很多学者启发。但是作者对该文章并没有解释细节,也没有说明具体的数据集。
之后Wang等人提出了一种基于一维卷积神经网络(1D-convolutional neural networks,1DCNN)的端到端加密流量分类方法,以及基于二维卷积神经网络的加密流量分类方法。在基于一维卷积神经网络的实验中使用了端到端的方法,免去了特征抽取等工作,使实验过程更加轻松。这两篇文章沿用了之前文章的思想,即将流量的每个字节看成是一个像素,并取得了不错的效果。在基于二维卷积神经网络的实验中作者选取了每条数据流的前784个字节,然后将其转换为28×28大小的图片输入神经网络进行学习。实验结果证明二维卷积神经网络学习二维空间特征的优势在进行一维加密流量分类时无法发挥,其分类性能相对低于一维卷积神经网络。
Lotfollahi等人提出一种叫深度包的基于深度学习的加密流量分类方法,开发了一个称为深度包(DeepPacket)的框架,其中包含数据预处理和两种深度学习方法。在数据预处理阶段,文章作者删除了域名服务(DNS)段,删除了以太网头,以及给用户数据协议(UDP)的末尾添加0使其与传输控制协议(TCP)具有一样的长度。框架中同时使用了卷积神经网络和叠层自动编码器两种方法。最后得出相比叠层自动编码器网络,1D-CNN能得到更好的分类结果。
本文提出了一种基于聚合残差网络的方法用于端到端加密流量的分类,其端到端的思想减少了工程任务的复杂度,也减少了各层网络中误差的积累。我们设计的ResNeXt-CNN网络模型能同时发挥聚合残差网络和一维卷积神经网络的优势,实现对加密流量的准确分类。
1.2 数据集
本文使用Draper Gil等人的“ICSX VPNnonVPN”数据集进行实验,该文章作者使用了Skype、Facebook等热门软件,并针对不同的流量类型(Streaming、Chat等)分别采集了常规流量和VPN加密传输流量的数据。文献[4]证明了在原始流量被分割为离散单位后,在不同的流量表示类型中使用session(会话)比flow(流)的分类效果更好。其次证明了从协议层的选择上来说,相比于只选择应用层的数据(TCP/IP模型的第4层或ISO/OSI模型的第7层),选择所有协议层的数据分类的效果更好。综上,本文选择了ISCX数据集提供的6种常规流量和6种VPN加密流量,并选取其中所有协议层的数据和使用session的表示类型进行实验,表1为本文实验的数据集描述。
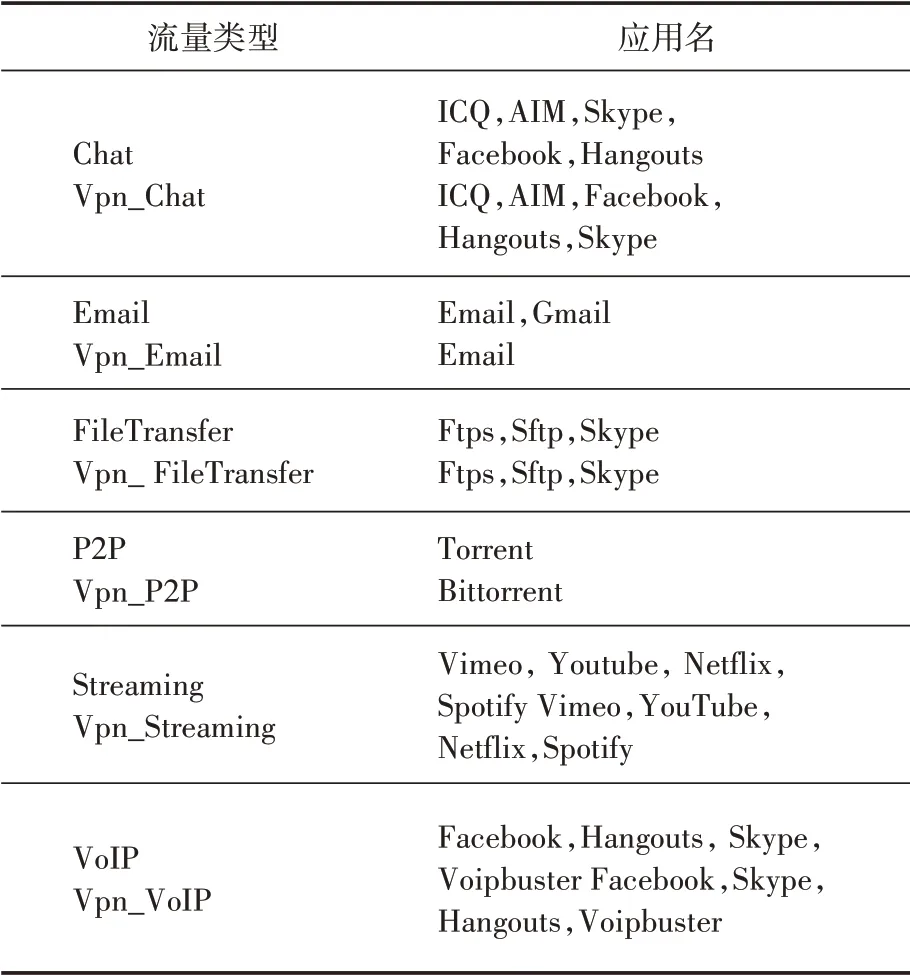
表1 数据集描述
1.3 数据预处理
在进行分类任务前,需要对原始数据预处理来获得标准化数据。本文的数据预处理流程如图1所示。
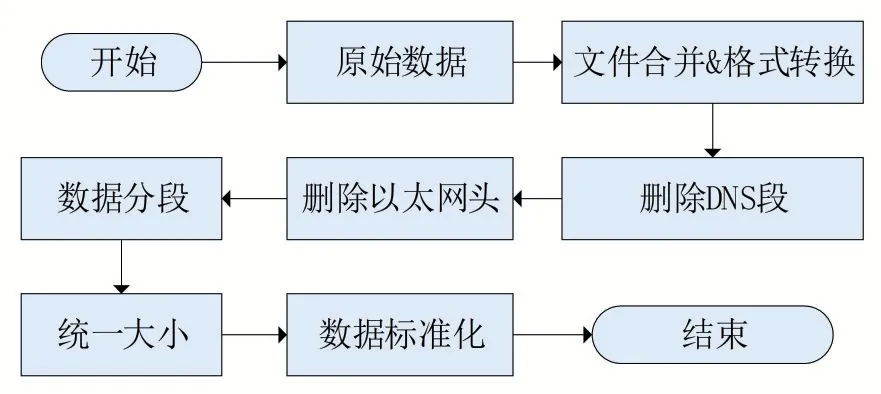
图1 数据预处理流程
ISCX数据集是在数据链路层捕获的pcapng格式文件,我们首先根据不同流量类型将其合并为12类,并转换为pcap格式文件以便于分析和操作。通过分析该流量数据的pcap文件,可以得到每一条数据的结构。我们删除了数据集中存在的一些域名服务(DNS)段,它用来把域名(domain name)和其对应的IP地址(IPaddress)进行转换,也就是对主机名进行解析。但这些字段与流量特征无关,也会占用其他有效信息的空间,因此我们将其从数据集中省略。之后我们删去了以太网头,因为其中包含的MAC(media access control address)地址以及Padding(填充)字段对于分类任务来说没有意义,也会影响模型分类精度。
数据集中不同数据长度的占比,如表所示,长度在1500 B以下的数据占了97.7%,因此为了流量分类任务以及为了方便计算,我们把数据的截断长度定为1521 B,对于长度大于1521 B的数据进行裁剪,对于长度小于1521 B的数据的末尾进行0填充。最后我们把每一条1521 B的数据转换为39×39大小的流量矩阵,再打包为深度学习常用的IDX文件格式。

表2 不同长度数据占比
1.4 模型架构
本文简化并改进了Xie等人提出的聚合残差转换网络(ResNeXt)模型以适应加密流量分类的任务。该网络同时采用了VGGNet的堆叠思想和分组卷积、特征聚合的思想,以及残差网络的跳接思想。该模型在提升准确率的同时大大减少了需要设计的参数数量,提高了模型的泛化能力,还可以防止梯度消失问题。使用的聚合残差模块结构如图2所示。

图2 聚合残差模块结构
本文提出的基于聚合残差的加密流量分类方法,以卷积神经网络的一维卷积层、池化层为基础,同时引入了ResNeXt网络中简化后的模块作为基本的聚合残差网络块构建模型,对12类别的流量进行检测。本文设计的模型ResNeXt-CNN的详细参数见表3。在数据经过预处理进入模型后,首先经过一维卷积神经网络的卷积层进行卷积。为了减少输出大小,降低网络在训练和测试阶段的计算成本,我们在卷积层后添加了一层最大池化层(max pool)。在经过池化层的处理后,数据进入两层聚合残差模块。为使用一维数据进行训练,在聚合残差模块中使用了1×3的卷积层。ResNeXt模块中的计算可表示为:

表3 ResNeXt-CNN模型参数
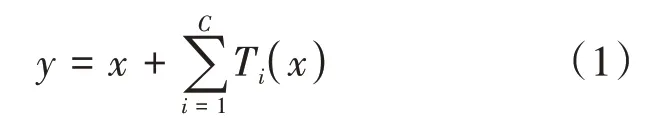
式(1)中代表输入,代表经过一次聚合残差块后的输出,代表基数(cardinality)即分支的数量,本文设置为3,T为相同的拓扑结构。数据在不同分支分别卷积后进行特征融合,再通过直接映射把低层的特征传给高层,再次特征融合。
我们对每一个分支中的第一个1×1的卷积层和1×3的卷积层后都进行了一次批标准化(batch normalization)操作,然后经由ReLU激活后传给下一层。批标准化操作可以使模型的训练过程更有效的进行,加速平稳收敛,这就允许我们使用更高的学习率,并且可以有效防止出现梯度消失或梯度爆炸问题。批标准化可形式化表示为:

上式中x是输入,是输出,是为了数值稳定性添加的一个很小的常数,和是需要学习的参数。(2)式和(3)式是计算出当前batch中每个通道的均值和方差,(4)式是将输入x进行标准化(normalize)得到输出̂,(5)式是将标准化后的数据再扩展和平移。需要学习的参数和的添加是为了让神经网络自动学习和修改。
在经过两轮聚合残差模块、一层最大池化层后,输出数据进入平铺层重组为一维矢量然后馈入全连接层,最后使用Softmax函数进行分类。
2 实验
2.1 实验环境
本文实验的配置如下:操作系统为Win⁃dows10家庭版,显卡为NVIDIA GeForce GTX 1060,处理器为Intel Core i5-8300 H,内存为16 G,并使用了Tensorflow框架以及keras库。在实验过程中选取了数据集的90%作为训练集,10%作为测试集进行测试。本文使用交叉熵作为损失函数,使用自适应矩估计(adaptive moment estimation,Adam)优化器,学习率设置为0.0001。
2.2 评价指标
我们使用准确率(Accuracy),精确率(Preci⁃sion),召回率(Recall)和F1(F1-score)四个指标来评估我们提出的模型和方法,它们在统计分类任务中被广泛使用。上述指标的计算公式如下:
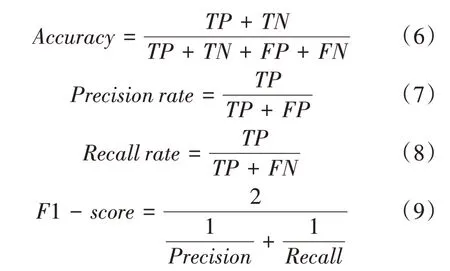
准确率代表了方法的整体效果,表示预测出的流量类别有多准确,衡量的是识别系统的准确性。召回率代表有多少正确的条目被识别,测量识别系统的召回率。1-则同时考虑了精确率和召回率,对识别精度进行综合评价。在公式中的,,,分别代表如下意思:(true positive)代表属于类,并被正确预测为类的样本;(true negative)代表不属于类,并被正确预测为不属于类的样本;(false positive)代表不属于类,但被错误预测为类的样本;(false negative)代表属于类,但被错误预测为不属于类的样本。
2.3 结果分析与对比
为了对比实验,本文使用了1D-CNN模型对同样预处理后的数据进行分类。在实验结果方面,本文将分别使用1D-CNN和ResNeXt-CNN的模型,与Zou等人提出的CNN+LSTM的模型,以及Lotfollahi等人提出的深度包中的SAE模型做对比。
由于在上述的SAE模型和CNN-LSTM模型中作者并没有使用全部评价指标,因此在一些评价指标上不做对比。从总体准确率来看(见表4),本文使用的模型对“ICSX VPN-nonVPN”数据集具有更好的分类效果。之后本文分别根据精确率、召回率和1在三个模型中作出对比。

表4 方法准确度对比
由图3—图5可知本文使用的ResNeXt-CNN模型在分类精确率、召回率和1分数上相比另外两种模型都有显著的提升。从在分类的精确度上看,虽然在VPN_VoIP类别上使用本文方法识别的精确率略低于1D-CNN和SAE方法,在其他11种流量类型上识别的精确率均高于另外两种方法,特别是在Chat、Email、Streaming、VoIP和VPN_Chat上,比1D-CNN模型分别提升了4%、16%、8%、5%和11%,比SAE模型分别提升了4%、2%、13%、35%和1%。
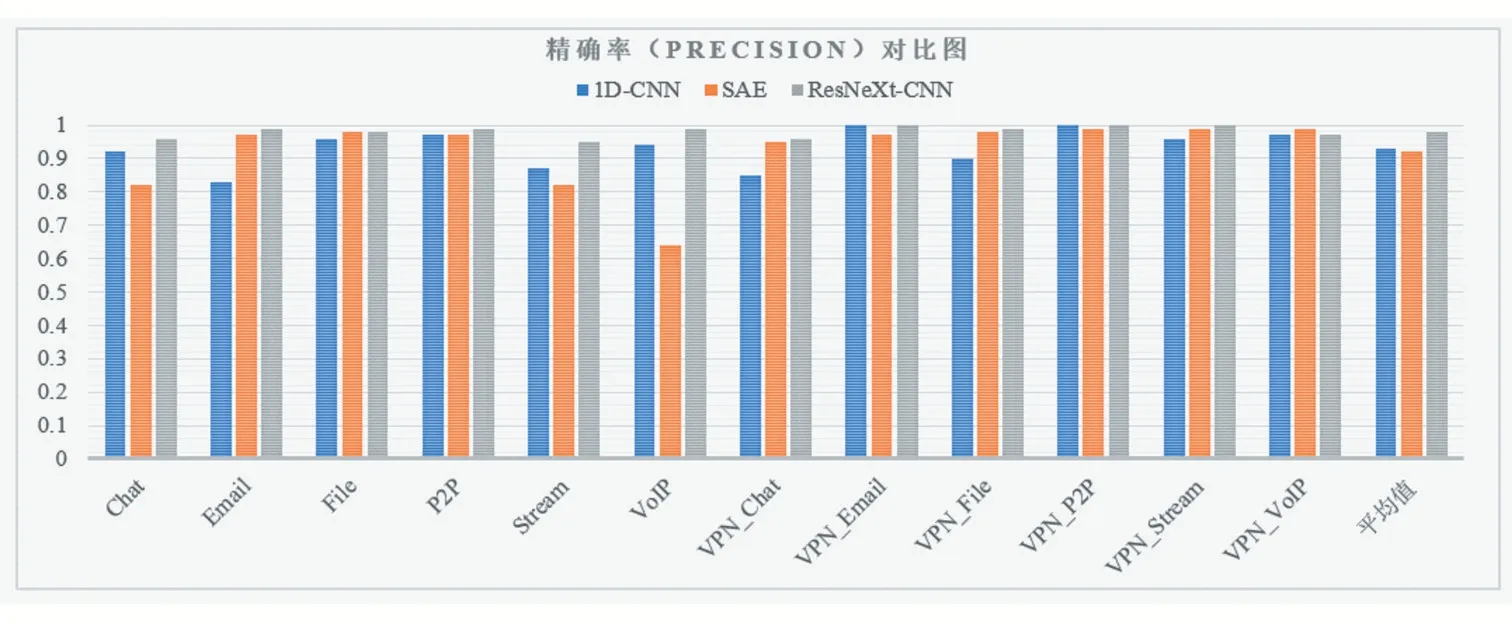
图3 1D-CNN,SAE和ResNeXt-CNN的精确率对比

图5 1D-CNN,SAE和ResNeXt-CNN的F1-score对比
在召回率方面,虽然在File transfer、P2P、VPN_Email和VPN_Streaming四种流量上都略低于1D-CNN和SAE方法,但只降低了1%~3%,而在Chat、VoIP和Streaming上的提升是明显的,对比1D-CNN方法分别提升了27%、10%和3%,对比SAE方法分别提升了30%、8%和6%。
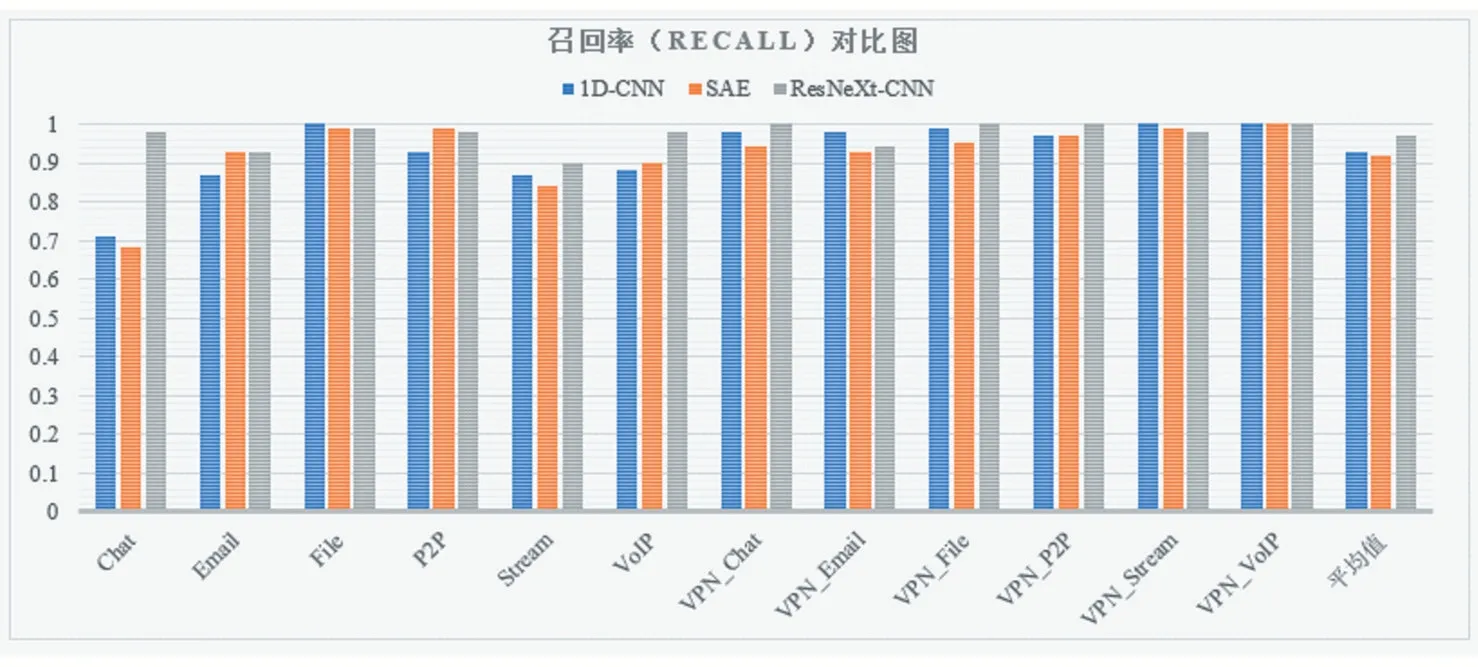
图4 1D-CNN,SAE和ResNeXt-CNN的召回率对比
从1分数上来看,对比1D-CNN和SAE模型,在Chat、Email、Streaming、VoIP和VPN_Chat这五类流量上的识别效果提升最大。本文模型相比1D-CNN和SAE模型,在Chat类上的1得分分别提升了17%和23%,在Email类上提升了11%和1%,在Streaming类上提升了6%和10%,在VoIP类上提升了7%和23%,在VPN_Chat类上提升了7%和4%。
3 结语
在本文中,我们提出了一种基于聚合残差网络的加密流量分类方法,其发挥了ResNeXt模块的提高准确率、防止梯度消失等特点,并充分利用了一维卷积神经网络在处理一维序列数据时的优势,进一步提高了对加密流量识别的准确率。在未来的工作中,我们将采集真实的互联网流量作为模型的输入数据,并研究真实流量数据中报头、协议和有效载荷部分的改变对深度学习模型性能的影响,同时继续改进流量分类方法以适应真实的互联网环境。
