基于机器视觉的托盘生产线上原料木板的识别
2022-04-12樊春玲张春堂
滕 腾, 樊春玲, 张春堂
(青岛科技大学 自动化与电子工程学院,山东 青岛 266100)
0 引言
托盘是用于集装、堆放、搬运和运输单元负荷货物的水平平台装置,一般用木材、金属、纤维板制作,便于装卸、搬运单元物资和小数量的物资[1]。木制托盘的托盘生产线设备可以为企业节省人力和物力,因此在市场上被大部分托盘制造厂商所采用[2]。现阶段木制托盘生产线的原料木板上料方式主要为人工上料,工人们需要对原料木板进行分类,并把固定型号的木板放置在对应的位置由钉钉机进行生产操作[3],使用这种方式上料效率不高,并且在上料过程中,上料工人会与钉钉机直接接触,在组装托盘时产生的巨大噪音将会对工人听力造成极大危害。因此需要一种效率高、识别率好的自动化上料方案来代替这种人工上料方式。
在工业生产线上,机器视觉技术的使用大幅度提高了生产线的自动化程度,在避免了工人与生产线的直接接触的同时提高了生产效率[4]。现今的机器视觉技术已经较为成熟,机械制造领域的流水线生产中已经大量使用了基于机器视觉的识别技术,比如部位焊接、缺陷检测、工件装配等。但在木制托盘生产流水线的上料方面,应用很少。因此,该文将机器视觉识别技术应用于木制托盘生产的上料系统中[5],设计一种以原料木板为目标对象的简单有效的图像处理识别算法,并反复试验得到适合工程应用的原料木板识别方案。
1 原料木板识别系统构成
基于机器视觉的托盘生产线原料木板识别系统如图1所示,由工业相机、PC机、PLC、机器人分拣手臂4个部分组成。首先由工业相机完成对原料木板的信息采集并将图片信息传递给PC机,PC机对接收到的图片信息进行图片预处理与图片特征识别并对比预设的数据模型(不同类型的木板尺寸信息)进行识别分类处理,最后将处理后的信息(木板类型、大小和中心坐标)传输给PLC,由PLC控制机械手夹取传送带上的原料木板并放置在钉钉机对应的位置上。在该文中主要研究的是使用PC机的原料木板识别方案,重点研究原料木板的识别算法。
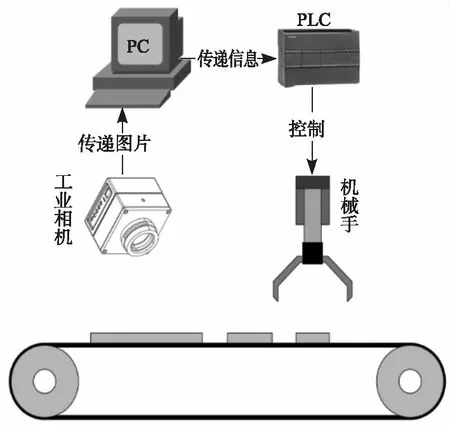
图1 识别系统构成图
2 原料木板识别算法
为了满足托盘生产线的上料操作,该文提出一种对原料木板简单有效的识别算法。算法流程如图2所示,首先对采集到的图片进行图片预处理,去除图中部分噪点的同时分离目标与背景;之后对处理后的图片进行特征点定位与匹配,获取原料木板的特征信息;最后根据获取的特征点信息对原料木板进行识别,获取木板图像坐标后需要进行坐标变换,将图像坐标系转换为世界坐标系[6],同时根据特征点计算特征尺寸构建分类器判断木板类型。为还原实际工况,对原料木板采用两种分布方式进行实验,其中木板相互独立的分布为离散分布,有木板相交情况存在的分布为交错分布,该文中算法演示以较为复杂的交错分布为例。
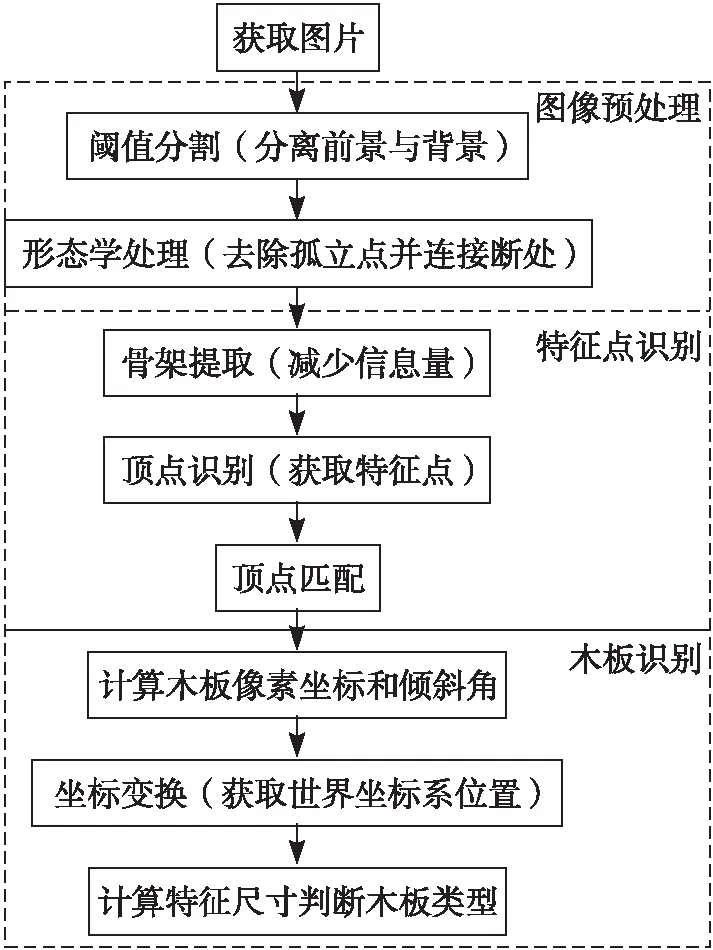
图2 识别算法流程
2.1 图像预处理
预处理主要作用是抑制背景噪声,从而达到提高图像数据信噪比的目的[7]。预处理的效果直接影响了后续木板特征提取的容易与否。
2.1.1 阈值分割
阈值分割是把图像特征从背景中区分出来的技术[8]。阈值分割可以增加图像中前景与背景之间的区分度,减轻后续图像处理的压力,同时降低后续算法的计算量。通过设定不同的阈值,把图像中的像素分为若干类。该文使用OpenCV自带的阈值分割函数Threshold进行分割,将背景像素值设为0,其余像素值设为255。该方法运行效率高,在保证木板轮廓的同时大幅减少了信息量。阈值处理结果如图3(b)所示,不过在阈值分割处理后,少部分木板连接处断裂,同时在图片背景中存在噪点。

图3 阈值处理结果
2.1.2 形态学处理
为了解决经过阈值分割之后部分交错的木板连接处出现断裂,以及在背景区存在噪点的问题,该文采用最简单的形态学运算进行处理。基础形态学运算有膨胀运算和腐蚀运算,这两种运算可以使用自定卷积核将目标区域扩大或者缩小。其他的形态学运算主要由这两种基础运算复合而成。开运算是先腐蚀后膨胀可以去除背景中一些噪点并且不改变总体位置分布和大致形状;闭运算则是先膨胀后腐蚀可以拟合木板中出现的小空洞以及去除与前景木板孤立点[9]。
在该文中,先对阈值分割后的图片依次进行一次形态学开运算和闭运算(图4(a)),既可以去除孤立点、填满木板内部孔洞同时又不改变木板形状与分布;之后需要再进行一次膨胀操作,连接木板上的断裂。处理结果如图4(b)所示,噪点被完整去除并且木板相交处的断裂也消失了。

图4 形态学处理效果图
经过图像预处理,分离目标与背景的同时,降低了背景噪声影响,为下一步原料木板的特征识别提供了方便。
2.2 原料木板特征点的识别
为了保证后续木板分拣操作结果的准确性,必须对木板的特征点进行识别。角点检测技术常常用于对工件进行识别[10~13],但在该文应用场景中的原料木板边缘较为粗糙,这就导致在使用角点检测时会识别出许多无效的角点,因此需要一种针对原料木板的特征识别算法。该文使用的方法是先找到木板的特征点(骨架顶点),再利用特征点完成对原料木板的识别。
2.2.1 原料木板对骨架提取
为了提取特征点,需要对木板进行骨架提取。骨架可以理解成目标物件的中轴,木板的骨架就是长方向上的中轴线。通过骨架提取突出了物体的主体结构,减少了多余信息,根据这些信息可以实现图像上对特征点的定位,比如端点与交叉点[14]。
传统的骨架提取方法在该实验中容易出现分支过多的情况,处理效果不理想[15]。Zhang-Suen细化算法可以让骨架位于木板的中轴线并保证其结构的完整性[16],可以用于该实验。不过该算法为并行迭代算法,从左上和右下两个方向对目标进行细化,比较适用于提取水平或竖直放置的木板,但在大多数情况下,木板都是随意摆放的,这时直接使用Z-S算法进行骨架提取会使骨架接近端点处出现弯折,如果弯折过大,骨架就无法准确反应木板的中轴,通过观察骨架图可以发现在木板不是竖直或者水平的状态下,木板越宽,弯折角度越大。因此,针对这种情况,该文提出改进的Z-S算法,在进行并行细化操作之前减少木板的宽度,从而减小端点附近骨架的弯折角度,使骨架可以更好地反映木板的中轴。改进的Z-S算法流程如下:
(1)获取所有类型原料木板的宽度,进行坐标变换,转换成图像坐标系的像素宽度;
(2)找到所有木板像素宽度中的极小值n;
(3)使用 Opencv的getStructuringElemen函数构建一个size(n/2-1,n/2-1)的结构化元素,在元素的中心设置锚点;
(4)当使用这个结构化元素处理图像内某点时,计算结构化元素覆盖的点里的最小像素值,并将锚点的像素值改为这个最小像素值;
(5)使用这个结构化元素遍历整个图像;
(6)遍历结束后对整个图像使用Z-S算法进行骨架提取[17]。
与Z-S算法处理结果(图5(a))对比,经过改进的Z-S算法处理后(图5(b)),可以看出木板骨架的弯折角度明显减少,可以更好地反映木板中轴,为下一步特征点的识别提供了方便。
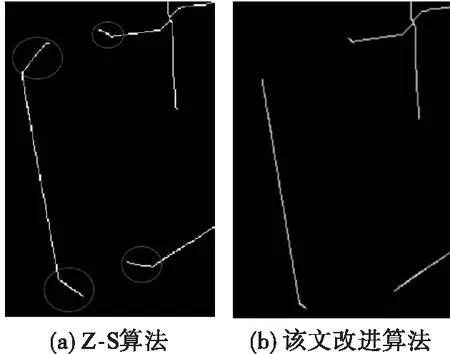
图5 骨架提取效果图
2.2.2 木板骨架顶点定位与匹配
在经过细化处理之后,原料木板变为与之一一对应的骨架细线。由于木板并不全是离散分布的,有些木板相互交错,骨架提取之后的直线也会相互交叉甚至在交叉处发生些许偏折,因此无法直接使用Hough变换来定位直线,但是骨架顶点对于木板的相对位置是固定的。因此可以先找到同一木板上的两个顶点,通过连接它们来定位木板中轴线。分析骨架图片发现骨架总在端部集中于一点,基于此进行顶点定位。具体步骤如下:
如图6所示,构建一个size(3,3)的结构化元素,锚点位置为(1,1)。
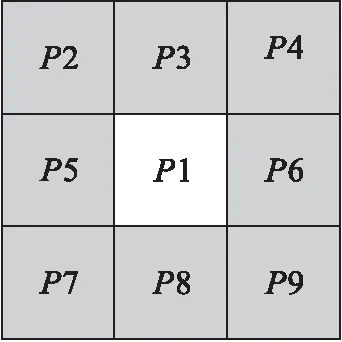
图6 结构化元素
使用这个元素遍历整个图像,若:
P1=255;
P2+P3+P4+P5+P6+P7+P8+P9=255;
这两个条件在某一像素点同时满足,那么该像素点为骨架端点,记下像素点坐标。将所有顶点标记出来的效果如图7所示。
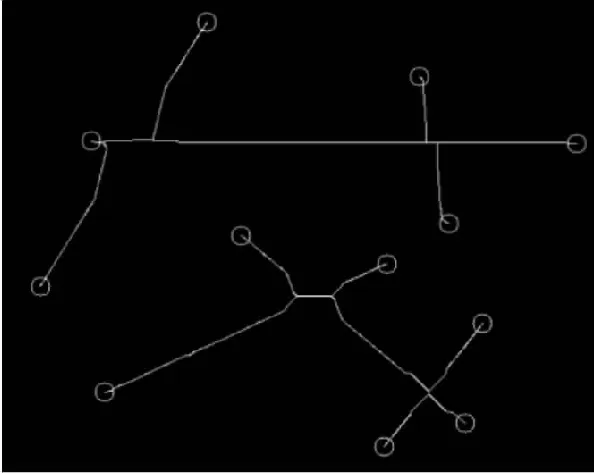
图7 顶点定位效果图
使用这种顶点定位方法可以获得图像中所有骨架的端点坐标,但此时还无法将它们作为特征点使用,因为这些端点是相互孤立,无法确定哪两点在同一条原料木板上。因此需要将同一木板上的两个端点相互匹配。显然,若将同一木板上的两个骨架顶点连线,那么线上所有的点都和这两个特征点属于同一木板。利用这个特点该文提出遍历投影匹配算法,步骤如下:
(1)顶点定位方法找到n个顶点(n为偶数),把所有顶点两两相连作直线,得到(n!/2×(n-2)!)条直线,这些直线可以视作潜在的木板中轴线;
(2)设其中任一条直线上的两点坐标分别为(x1,y1)和(x2,y2),使用两点式获取这些直线的解析式(两点式(y-y2)/(y1-y2)=(x-x2)/x1-x2))。
(3)将这些潜在中轴线的解析式投影到预处理图片中;
(4)遍历在预处理图片中某一条直线解析式上的所有像素,若所有元素的像素值均为255则该直线为中轴线,将包含这两个顶点的潜在中轴线移除。若存在像数值为0的点,则直接把这条潜在中轴线排除;
(5)返回步骤(4)继续尝试其他潜在中轴线,直到所有原料木板都对应两个顶点。
经过匹配算法处理,原本离散的骨架顶点变成可以两两匹配的原料木板特征点,匹配效果如图8所示。
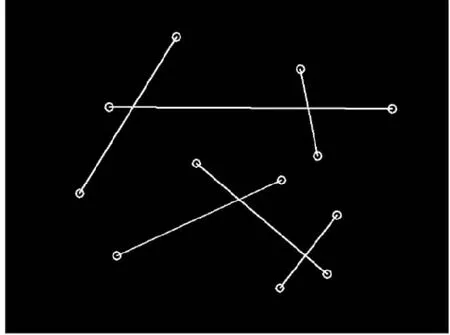
图8 木板特征点匹配结果
2.3 原料木板的识别
完成原料木板特征点的匹配后就可以对木板进行识别,根据特征点位置信息识别木板位置,同时根据实际尺寸构建分类器识别木板类型。
2.3.1 原料木板的位置信息识别
首先根据原料木板的特征点获取木板的像素坐标与偏转角。设两个特征点的坐标分别为(x1,y1)和(x2,y2)如图9所示,则原料木板的位置信息可以表示为:
(1)
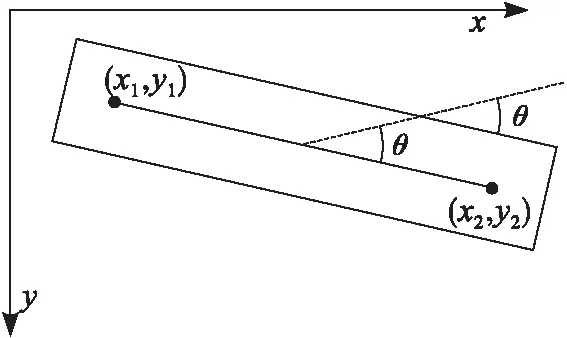
图9 原料木板的位置提取
2.3.2 原料木板类型识别
先通过木板上面的两个特征点计算木板特征尺寸。设两个特征点的坐标为(x1,y1)和(x2,y2),根据距离公式可得两点之间的像素距离为:
(2)
设木板的长度为a,宽度为b,则该木板的理想特征尺寸D:
D=a-(b-1)/2
(3)
该实验木板共有三种类型,按大小从小到大可分为短(梁板)中(辅板)长(边板)三种类型,三种木板的特征尺寸依次增加。根据式(3)计算它们的理想特征尺寸依次为D1、D2、D3。因此可构建分类标准:
(4)
3 实验设置与结果分析
3.1 实验设置
在实际工况下,原料木板按尺寸从大到小的顺序分为长中短三种类型,随意散落于黑色背景的传送带上沿传送带运行方向前进,工业相机拍摄一张图片中约有3到6块原料木板。为模拟实际托盘生产线情况,该文将原料木板放置于黑色背景的平台之上,分为离散分布和交错分布两种工况。该文先用相机采集了50张图片,之后使用调整亮度、旋转、剪切使图片库扩充4倍得到200张图片(包括132张交错分布的木板图片和68张离散分布的木板图片)。
3.2 实验结果与分析
使用该文算法的检测效果如图10所示,图片表明该算法可以准确对原料木板进行定位与类型识别。对所有样本使用该算法进行识别,识别结果如表1所示。使用这套基于机器视觉的原料木板识别算法处理这些图片,离散分布的工况下识别准确率为100%,交错分布的工况下识别准确率为96.5%。本算法在识别成功的情况下可以准确得到木板的类型信息,同时获取的坐标误差不超过5%。实验中有一张图片未识别成功的原因可能是木板叠放过于密集导致无法骨架提取,从而无法对其进行特征识别与定位。不过此情况较为特殊,在实际工作当中较难遇到,后续可通过调整光照与相机设置,对系统进行优化从而防止识别不到的情况出现。实验表明此算法简单有效,并且具有识别时间短,同时系统稳定,能很好地完成原料木板识别任务,满足上料要求,因此该方案能够满足工程实际需求。

图10 检测效果图
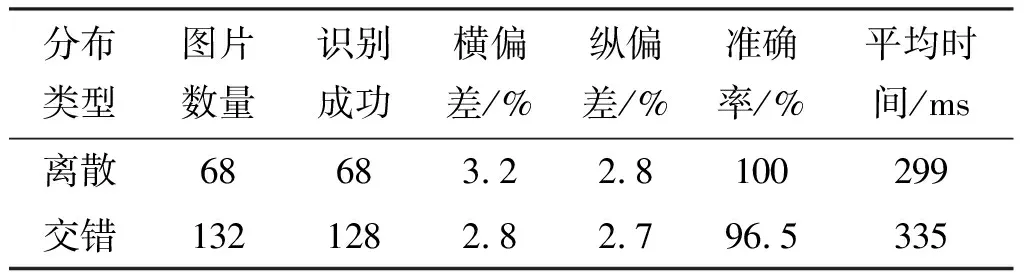
表1 原料木板识别结果
4 结论
该文提出了一种基于机器视觉的原料木板识别算法,使用改进的骨架提取算法减少信息量,采用八邻域算法定位骨架顶点,并将其作为特征点进行匹配,最终实现了对原料木板位置与类型的识别。使用该算法对原料木板图片进行实验,实验结果表明该文提出的识别算法可以对原料木板实现准确快速的识别,识别成功率为96%,识别图片平均用时约为335 ms,同时该算法简单可靠,为托盘生产线的上料环节提供了方法。
