学术论文审稿效用研究
——以国际会议ICLR同行评议为例
2022-04-11赵昕航孙曰君张春博高成锴
■赵昕航 丁 堃 孙曰君 张春博 林 原 高成锴
大连理工大学,辽宁省大连市甘井子区凌工路2号 116024
2020年初,教育部、科技部印发《关于规范高等学校SCI论文相关指标使用 树立正确评价导向的若干意见》、科技部印发《关于破除科技评价中“唯论文”不良导向的若干措施(试行)》,学术评价问题再次成为领域的研究热点。学者们在定量评价方法和定性评价方法中不断盘桓,意图发现最合适的评价方法。其中,同行评议是学术论文出版过程中很重要的科学防线。
尽管同行评议是目前无法替代的一种评价手段,但学术界对同行评议的批评从未停止[1],对同行评议本身的批评大多围绕在同行评议的公平性、一致性以及有效性上[2]。在高水平期刊中,传统同行评议专家承担着守门人的责任,但是由于同行评议具有较强的主观性,审稿意见并非总是正确的[3]。本文主要研究审稿意见的效用问题。“效用”意为效力和作用,在学术领域内的应用来源于叶继元提出的“全评价”体系,他将原有评价中的定性与定量两种维度重新分为形式、内容和效用三大维度[4],为学术界提供了很好的思路,也给本研究一定的启发。
随着论文及相应同行评议数量不断增多,像以往一样采用人工分析同行评议内容,由此得到审稿结果的方式无疑大大增加了编委和编辑的工作量。在此情况下,开放科学运动以及计算机领域的发展使得人工智能辅助同行评议过程成为可能,其中OpenReview网站提供了大量计算机领域会议的同行评议信息。为了能够更有效地探索审稿文本,本文选择其中最权威的人工智能顶级会议——国际表征学习会议(International Conference on Learning Representations,ICLR)的审稿文本作为研究样本,以尽可能避免由非高水平会议或期刊中存在的审稿专家非小同行、没有时间或者消极懈怠等导致的部分审稿意见过于简单、笼统,缺乏建设性等问题[5]。本文所使用的ICLR同行评议文本数据常被用于计算机领域以及科技管理领域的分析中。计算机领域研究主要分为使用情感分析手段[6]或观点挖掘手段[7]分析同行评议文本,科技管理领域中已有将同行评议文本应用于论文质量评价的研究[8]。在科技期刊界,目前人工智能辅助同行评议的应用按照功能可分为投稿审查、审稿人推荐和学术影响力预测三类[9],但对辅助编委会和编辑评议的研究成果较少,而这又是很重要的研究话题。
基于此,本文将使用表示学习与深度学习方法,将审稿文本作为最主要的研究数据,在文本中分析其所包含的审稿行为特征,确定审稿文本是否有助于审稿结果的制定,以此构建审稿效用度智能识别模型。再通过所收集的审稿专家经验评估和审稿专家对自己本次审稿行为进行评估的信息进行辅助分析。智能分析方法的应用不仅可以辅助期刊编委和编辑进行评议与决定,还可以对识别结果进行分析,以获得更多有关同行评议的经验,在减少编委和编辑工作量的同时,对经验进行归纳总结,以健全完善期刊界的同行评议机制。
本文首先定义审稿效用的概念,明确研究的对象与方法并进行实验设计;其次,对审稿效用度智能识别模型识别出的结果结合审稿专家评估分数进行分析,并利用中式英语特征推断中国审稿专家撰写审稿文本的情况;然后,基于以上研究,提出帮助论文提高审稿效用的对策建议;最后对本文提出的研究方法进行总结,并指出其在科技期刊界的应用意义。
1 研究设计
1.1 审稿效用的定义
在正式给出“审稿效用”定义之前,首先要明确本研究分析的审稿意见文本为审稿专家的最终意见,这是因为论文的评审一般是作者、审稿专家和发文平台(期刊或会议)反复交互的过程,但最终只能将审稿意见及其审稿结果呈现出来,而之前的交互过程及其信息很难获得。本研究的数据来源于ICLR,ICLR在收到投稿后,会将符合规范的论文分配给2~5个审稿专家,每个审稿专家会提出初步意见。该意见在后续讨论期间可能根据论文的变动以及其他审稿专家的意见而修改,最终由会议委员会根据审稿专家最终意见综合做出论文录用与否的决定(1)对于期刊而言,会议委员会或领域主席的决定相当于期刊编委会或主编的决定。。鉴于评审过程交互信息的难以获得性和最终评审意见(包括评审专家和会议委员会的评审意见及结果)的可获得性,将后者作为本研究的对象文本。
在本研究中,将审稿效用定义为评审专家最终审稿文本对论文最终录用结果的作用,而这种效用可以用“审稿效用度”来度量。具体来说,本研究选用会议委员会最终的决定来探索构建审稿效用度智能识别方法的模型,由于仅考虑识别最终的审稿文本在决定审稿结果的阶段是否具有审稿效用,因而在本研究中将审稿效用简化抽象为审稿专家的决定与论文录用结果一致性的二值问题。首先将审稿专家评分1(Reject)和3(Weak Reject)定义为0(拒绝),6(Weak Accept)和8(Accept)定义为1(接受)。而会议委员会决定录用论文,论文最终被录用的状态为1;论文被拒收,则状态为0。如果审稿专家对于论文的最终评审意见(录用/拒收)与最终论文发表结果一致,则认为审稿专家最终意见有作用,审稿效用度为1;如果不一致,则认为审稿专家最终意见不影响最终录用结果,因此审稿效用度为0。审稿效用度的计算公式为
E=1-|A-B|
(1)
式中:E为审稿效用度;A为会议委员会最终决定的论文录用结果;B为审稿专家最终推荐分数。
1.2 研究对象与方法
1.2.1 研究对象
本研究的实证依托于公开评审的ICLR,ICLR近几年将投稿论文信息、审稿文本与审稿评估信息全部公开,有利于学界更详细、全面地分析同行评议。首先爬取OpenReview网站上ICLR 2020年官方发布的全部同行评议信息(包含普通审稿专家审稿文本与会议委员会评议文本),得到7775篇普通审稿专家的审稿文本与2213篇领域主席的评议文本。然后将普通审稿专家的意见与领域主席的意见相匹配,去除没有最终接收/拒绝意见的审稿文本(往往是由作者撤稿导致的),得到6721篇审稿文本。
同时,收集6721篇审稿文本对应的审稿专家自我评估信息。评估信息主要包含两个方面:审稿经验评估(Experience Assessment)与本次审稿评估(Review Assessment)。审稿经验评估对应的评估得分0~3分别对应审稿专家在该领域的学术水平(从我对该领域不太了解、我已经阅读了该领域众多论文、我在该领域发表过一两篇论文到我在该领域常年发表论文,程度逐渐加深),而本次审稿评估分为3个方面:论文阅读的深入程度(Thorough in Paper Reading,以下简称“阅读程度”)、推导和理论的正确性检验程度(Checking Correctness of Derivation and Theory,以下简称“DT检查程度”)以及实验正确性检验程度(Checking Correctness of Experiments,以下简称“实验检查程度”),分数0~3代表程度从低到高。
1.2.2 研究方法
本研究提出一种审稿效用度智能识别方法,该方法主要使用TextRank-BERT框架对审稿文本进行效用度评估,该框架可以判断英文计算机领域审稿文本的审稿效用度。BERT(Bidirectional Encoder Representation from Transformers)[10]是由谷歌团队于2018年提出的预训练语言模型,该模型可以在自然语言处理各大任务上达到最优成绩。BERT采用Transformer语言模型[11],该模型的结构为编码器-解码器,采用注意力机制[12](Attention)挖掘输入和输出之间的关系。BERT的预训练目标函数采用遮蔽语言模型(Masked Language Model),即先随机遮蔽一些词语,再在预训练过程中对其进行预测,这样可学习到能够融合两个不同方向文本的表征。BERT模型在预训练时通过学习大量语料获得了丰富的信息,只需要微调便可以应用于下游任务上。本研究通过微调BERT模型学习审稿文本中所蕴含的影响论文录用结果的特征,并利用线性层、增加注意力机制以及CNN(卷积神经网络)模型三种方式对特征进行处理,以完成审稿效用度二分类任务,在训练时通过已经标注好的标签不断调整模型的学习策略,以提高模型学习特征的能力。经过统计发现,绝大多数审稿文本非常详细具体,虽然能够全面地帮助作者修改论文,但是并不利于所设计模型从中学习决定论文是否录用的信息,同时大部分审稿文本的长度远超BERT输入512词的限制。因此,本研究利用TextRank算法[13]抽取审稿文本摘要,将审稿专家的核心表达抽取出来,用作BERT模型的输入。TextRank是一种无监督抽取式摘要的经典算法,目前其抽取关键信息的有效性已经在各个领域得到了充分证明。TextRank算法利用一篇文档内部词语间的共现信息抽取关键词,从一个给定的文本中抽取出该文本的关键词、关键词组,并使用抽取式自动文摘方法抽取出该文本的关键句。
1.3 实验设计
本研究首先利用(1)式计算出审稿文本效用度作为各审稿文本的标签。得到审稿效用度为1的审稿文本共5080篇(75.58%),审稿效用度为0的审稿文本共1641篇(24.42%),并将它们作为基本数据。在构建数据集前,为了确定审稿文本长度是否会影响审稿效用度,使用Point-Biserial相关系数[14]对全部真实数据的审稿效用度(二值变量)与审稿文本长度(连续变量)进行相关性分析,得到相关系数为0.0925,P值为2.916×10-14。因此本研究认为在目前的大量数据样本中审稿文本长度和审稿效用度的相关性非常小,可忽略不计。
审稿效用度分类任务使用的数据集包含4个部分,为了解决数据不平衡问题,对审稿效用度为0的审稿文本进行数据增广操作,数据集构造方法如表1所示。

表1 数据集构造方法
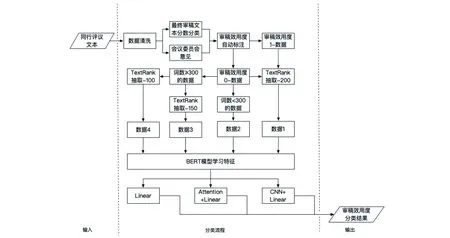
图1 审稿效用度智能识别方法的流程
数据1~4组成了整个用于TextRank-BERT框架学习的数据集,共9220条数据,其中审稿效用度为1的数据共5080条,审稿效用度为0的数据共4140条,基本保持正负比例平衡。本研究划分到训练集的数据共8000条,验证集数据共720条,测试集数据共500条。首先通过BERT模型学习训练集中包含的与审稿效用度有关的特征,并采用3种方式对审稿文本所反映的审稿效用度进行预测,然后通过验证集进行调整,最后在测试集上进行测试。审稿效用度智能识别方法的流程见图1。
2 结果与分析
2.1 实验结果
本实验通过微调三组BERT模型10个epoch对数据集进行审稿效用度的二分类任务。第一组使用普通BERT模型,第二组使用BERT-Attention模型,第三组使用BERT-CNN模型。同时增加两组对比实验:一组不使用TextRank处理数据,直接使用BERT模型的实验(BERT(-));另一组将基本数据扩增至9220条,然后使用BERT模型进行实验(BERT)。使用精确率、召回率和F1值作为评价指标,其中F1值为最终评价指标[15]。经过实验得到五组模型的结果如表2所示。通过表2结果可以发现,数据是影响结果的最主要因素,而在数据量及正负样本比例基本相同的情况下,通过TextRank算法[13]抽取关键信息,利用BERT模型[10]标记文本中对审稿效用有贡献的相关特征,以便能准确判别审稿效用度。在原有线性层的基础上添加注意力机制,让模型将注意力放在更重要的特征上能够提升模型的识别效果。同时,使用CNN对审稿效用度进行分类,可以得到更加显著的效果。

表2 模型实验结果
2.2 数据基本分析
经统计,文本长度主要集中在1~1000词,共6499篇,而长度为1001~4000词的文本仅222篇,约占全部数据的3.3%。审稿文本是结合论文具体信息撰写的,因此长短不一是正常现象。将1~1000词按照100为区间单位进行等间距分割统计,结果如图2所示。由图2可知,文本长度为201~300词的同行评议文本数量最多。当审稿文本长度为1~100词时,审稿效用度为0的审稿文本所占比例为32.79%,而整体审稿效用度为0的比例为24.42%。虽然在整体上审稿效用度与审稿文本长度没有太大的相关性,但根据分析结果,字数极少的审稿文本更倾向于缺乏对论文录用决策的有益贡献,一篇审稿文本若是包含应有的意见元素,则文本长度便不会很短。

图2 审稿文本长度的区间统计描述
正面审稿意见与负面审稿意见对应的审稿效用度数量如图3所示。由图3可知,负面意见的效用度更高。也就是说,“审稿专家评分为1和3,即不推荐录用”时该稿件被拒收的概率(93.12%)要高于“审稿专家评分为6和8,即推荐录用”时该稿件被录用的概率(56.69%)。这说明审稿专家在给出负面审稿意见时往往拥有合理拒稿原因,证明了审稿专家在对论文提出批评时大多非常谨慎。

图3 负面及正面审稿意见对应的审稿效用度
被拒绝或录用的论文的审稿效用度如图4所示。可以看到,同行评议结果与论文最终结果不一致,产生学术异议时,在被拒绝的论文中,审稿文本效用度为0的文本占比更高,为43.16%,而被录用的论文中审稿文本效用度为0的文本占比为13.09%。这可能是由论文质量一般时,审稿专家对其的评价角度不一致导致的,也可能是由部分审稿专家对该领域并不是特别熟悉,不能辨别论文的真实水平导致的。这时候就体现出多位审稿专家的优势,编委会可以通过分析多位审稿专家撰写的评审意见给出最终决策。

图4 拒绝/录用意见对应的审稿效用度
本研究对审稿效用度为0和1的审稿专家评分进行了统计,结果见表3。由表3可知,处于拒绝或录用意见临界状态的论文数量最多。在以前的研究中发现,审稿专家更倾向于肯定优秀的论文,否定水平较低或是与会议主题不相符的论文,而对于水平中等的论文不能做出很好的判断[6]。审稿效用度为0的审稿专家评分为3或6的论文数量占审稿效用度为0的论文总量的85.68%,而审稿效用度为1的审稿专家评分为3或6的论文数量占审稿效用度为1的论文总量的69.86%,在一定程度上验证了以上结论。同时表明审稿专家需要深化学术造诣,磨练对论文把关的能力,从而提出建设性意见。

表3 不同审稿效用度下各审稿专家评分对应的论文数量
2.3 识别样例
利用审稿效用度智能识别方法可有效识别出审稿文本的审稿效用度,审稿效用度为1的部分审稿文本样例如表4所示,审稿效用度为0的审稿文本与其他审稿文本观点对比样例如表5所示。由表4可知:该审稿专家首先表述对论文内容的理解;其次审稿专家对论文进行整体评价,在该论文中,审稿专家认可作者的核心观点,但也提出该论文仍需一定的改进,此部分最能体现审稿专家的学术造诣,即能否对论文水平做出整体判断;然后审稿专家指出论文的优缺点以及存疑之处,这部分的提出可以让作者及公众理解审稿专家做出判断的具体原因,同时所提出的缺点也是作者需要改进的地方;最后,审稿专家指出论文存在的失误,从细节上帮助作者完善论文。经过对比发现,该篇论文的其他审稿专家的观点以及领域主席的观点与该审稿文本的观点基本一致,证实了该审稿文本对于论文录用结果是有益的。

表4 审稿效用度为1的文本样例1(审稿专家评分为6)
表5所示为同一篇论文在不同审稿文本中的观点对比样例。审稿效用度为0的审稿文本表达了对该篇论文的赞同,关注到了论文优秀的一面,但是却忽视了论文致命的一点:有非常相似的论文已经发表,即该论文的原创性和新颖性受到质疑,以及该论文在对比实验中证明自己提出模型的有效性时,进行了无效的比较。所提出方法有效地识别出该篇审稿效用度为0的审稿文本,此种情况可以有效辅助编委和编辑做出正确决定,同时也可以提醒相应的审稿专家提高自己对领域的熟悉度与学术水平。

表5 审稿效用度为0的文本样例1
利用所提出方法还能识别出一些看似经验不足,但仍非常有效的审稿意见,如表6所示。根据以往的研究,审稿专家在审稿讨论阶段修改自己的意见往往是因为本人意见与其他审稿专家意见存在差距[16]。而该审稿专家坚持自己的观点,并没有根据其他两位审稿专家的高分意见修改自己的意见,体现出较高的审稿素养。正是因为审稿专家在自己所研究的领域拥有丰富的经验,他才能准确地判断出该论文所研究的问题是否属于本领域的研究内容。

表6 审稿效用度为1的文本样例2
同时,本研究在对审稿效用度为0的审稿文本进行分析时还发现,通过公开评审,公众会质疑不负责任的审稿专家,如表7所示。因此,除了将审稿专家的审稿文本与其他专家和会议委员会的意见进行对比,公众也是审稿文本是否具有效用的见证群体。通过专家们的对照监督和公众监督两种方式,可以督促审稿专家以更负责的心态撰写审稿文本,因此可以产生更公正的学术评价结果。

表7 审稿效用度为0的文本样例2
2.4 审稿专家经验评估以及审稿评估分析
经统计,审稿效用度为0和1的文本对应的各项审稿专家自我评估指标的基本情况见表8。由表8可知,大部分审稿专家是对领域比较熟悉的学者,这些专家能够深入地阅读论文,并有能力检查论文中数学推导、理论以及实验是否正确、充分。在审稿效用度为0的文本对应的审稿专家中,刚刚入门的学者最多,而审稿效用度为1的文本对应的审稿专家中,已经能够在领域内发表一两篇论文的学者最多。因此,在指定审稿专家进行审稿前,需要了解审稿专家的资历,只有对所属领域充分了解的专家才能给出正确的评价结果。但现实情况是,大量涌现的稿件导致了高水平审稿专家的不足,因此利用人工智能辅助同行评议是必要的,也是未来发展的方向。
为了探索审稿经验评估和本次审稿评估与审稿效用度之间的相关性,本研究使用随机森林方法挖掘各指标对于审稿效用度的贡献程度,将审稿评估值作为特征用于预测审稿效用度。由于随机森林方法每次抽取的子集不一样,产生结果不一样,因此取5次结果的平均值作为特征重要性的最终结果(表9)。根据最终结果,与审稿效用度相关性最弱的指标为DT检查程度,即审稿专家对推导和理论的检查不如其他3个评估指标重要;与审稿效用度最相关的指标为审稿经验评估,审稿专家的学术造诣是其文本审稿效用的最重要的影响因素,在其他3个指标相同的情况下,在该领域能长期发表多篇论文的审稿专家往往更能熟知论文水平,给出更有见地的审稿意见。而审稿专家是否能够深入阅读论文、检查实验结果的正确性也是非常重要的影响因素。整体看来,这3个指标与审稿效用度的相关性都很强,也证明了ICLR选择的对审稿专家的评估指标抓住了关键要点。
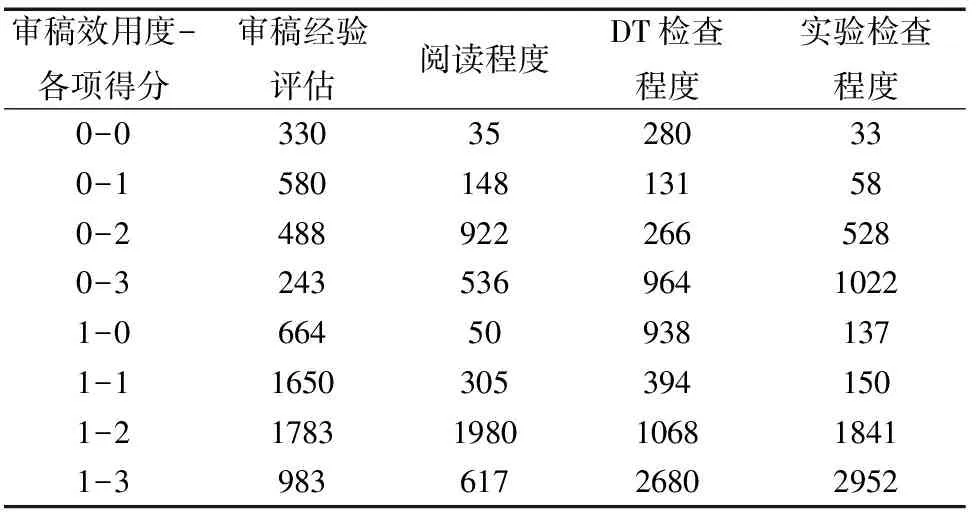
表8 不同审稿效用度对应的评估指标情况

表9 随机森林方法的特征重要性实验结果
2.5 中国审稿专家所撰写的审稿文本的审稿效用度
由于同行评议中审稿专家是匿名状态,无法获知审稿专家的国籍。张明阳等[17]通过计算审稿文本向量与中式语法向量之间的欧氏距离来判别中国审稿专家的写作风格。本研究受此启发,决定利用中式英语作为切入点,探索哪些审稿文本属于中国审稿专家。此外,本研究在中式英语的基础上增加了非中式英语作为对比数据,让模型同时学习中式英语特征与非中式英语特征。为了避免模型学习时受到相似内容的干扰,本研究没有选取ICLR论文的摘要,而是选择中英文期刊作为实验数据来源。
在期刊选择上,由于ICLR是人工智能领域的顶级会议,因此本研究在选择期刊时将领域定位为人工智能,且选取中国计算机学会推荐的高质量期刊,最终选择的期刊为《模式识别与人工智能》与ArtificialIntelligence。在时间选择上,虽然会议论文从审稿到发表的时间相较于期刊更短,但本研究忽略较为相近的时间因素,由于使用的是ICLR 2020的数据,因此对于期刊,也使用2020年对应的论文作为数据来源。《模式识别与人工智能》2020年的载文量为109篇,ArtificialIntelligence2020年的载文量为87篇。在摘要数据选择上,选择《模式识别与人工智能》刊载论文的英文摘要作为中式英语数据源,非中式英语首先去除ArtificialIntelligence中文作者及外国机构中第一作者疑似中国人的论文,然后将其他论文的英文摘要作为非中式英语数据源。在实验粒度的选择上,由于中式英语通过句子即可被发现,不需要结合段落中的上下文信息,因此本研究将摘要按照句子粒度进行切割,得到中式英语688句,非中式英语661句,共1349句。以句子为粒度将中式英语标注为1,非中式英语标注为0。
为了初步对中国审稿专家进行探索,本研究从5080篇审稿效用度为1的审稿文本中随机抽取75篇文本,从1641篇审稿效用度为0的审稿文本中随机抽取25篇文本,以基本保证与原同行评议数据中审稿效用度为0和1的文本比例类似。将这100篇审稿文本拆分成句子,从75篇审稿效用度为1的审稿文本中每篇文本随机抽取1句,同理,在其余25篇文本中随机抽取25句,最终得到100句实验数据。由于支持向量机(Support Vector Machines,SVM)模型在区分英式英语和美式英语实验上具有较高的准确率[18],本研究使用SVM模型判别这100句是否为中式英语时,首先将已标注的1349句作为实验数据集,按照8…2的比例将它们划分到训练集与测试集,使用TF-IDF作为特征权重。最终模型在测试集上的准确率可达96.30%,将100句同行评议句输入已训练好的SVM模型进行预测,得到中式英语数量及占比结果见表10。ICLR 2020年审稿效用度为1和0的审稿文本所占比例基本相等,说明目前大部分中国专家的水平处于国际平均水平,所撰写的审稿文本不会毫无效用,但也没有达到国际顶尖审稿水平。未来中国审稿专家评审论文时需要更谨慎,充分利用自己的专业知识,避免主观臆断,优化我国学术论文的评议环境。

表10 识别出的中式英语数量及占比
3 提高审稿效用的建议与措施
(1) 对于审稿专家。审稿专家应该提升自身学术素养,用良好、认真、专业的态度对待审稿,提高自己的审稿水平,撰写丰富且客观的审稿意见。对于自己撰写的审稿效用度被识别为0的审稿文本,及时发现问题所在,汲取经验,更加谨慎地对待下次审稿。积极与期刊或会议进行沟通,必要时参加期刊或会议主办机构组织的审稿培训会议。
(2) 对于期刊编委和编辑。首先,严格把控审稿专家的资历,要选择与期刊或会议水平相符的审稿专家,这是因为对领域了解得不够深入的专家很难给出准确的评价意见,不仅会导致同行评议结果不科学,还会影响期刊或会议的水平。其次,在外审前,学术编辑应该认真进行论文的初步审阅,将审阅合格的论文提交给审稿专家评审,这可帮助审稿专家节省时间,并且给出良好的反馈结果。再次,外审结束后收到审稿文本时应该加强对论文审稿意见乃至论文本身的理解,尤其关注文本极短、模棱两可的意见,防止做出不科学的决策,损害学术界的健康,同时让科学的论文成果及时发表,以帮助相关领域进步。最后,认可审稿专家的表现,与审稿专家进行良好的互动,建立健全专家审稿激励机制和监督机制。
(3) 对于中文学术论文。目前同行评议常被诟病,包括是否掺杂人情因素等,而开放审稿文本可在一定程度上缓解相关问题。开放评审在国外的有效推行及相关研究的有益性已经为中国学术界提供了有益的思路,未来通过借鉴国外先进的经验,健全同行评议机制,建立中国自己的开放同行评议平台,并在此基础上建立起更有效的学术评价体系,让我国的科研成果能够在更透明、更科学的环境中得到准确的评价与应用。
(4) 对于人工智能方法的应用。现在各行各业都在尝试利用人工智能技术对本领域进行提升,使用人工智能技术可以有效地对大数据进行处理,利用高效的机器智能检测辅助人工进行更有效的决策,在同行评议领域也已经有相关的应用研究,除了本研究提出的方法,未来应该有更多智能辅助模型,通过在海量文本数据中进行学习,更好地对同行评议中的特征进行分析,提高决策的效率并提升决策的科学性。
4 结语
本研究提出一种使用TextRank-BERT框架的审稿效用度智能识别方法,该方法在构建时利用TextRank算法抽取审稿文本中的重要观点,使用BERT模型对审稿文本进行识别,利用审稿专家最终评分与编委会录用决定来计算审稿效用度标签。经过在ICLR 2020年数据上的微调,该模型最终能够准确地识别审稿文本的审稿效用度,对审稿文本进行评估。本研究在对审稿文本的审稿效用度进行分析的基础上结合专家审稿的评估信息,客观地对同行评议进行评价与监管。
采用智能方法处理同行评议是目前的研究热点,通过智能方法辅助同行评议能够促进同行评议的发展。所提出的审稿效用度智能识别方法主要应用于审稿机制中,利用本文方法,可以辅助编委和编辑更有效地挑选稿件,实现编委和编辑与审稿专家的良性互动,完善审稿机制。本文方法通过在终审阶段预测外审专家返回意见的审稿效用度,结合审稿专家推荐录用或拒绝的意见来帮助编委和编辑综合评价投稿水平,以降低编委和编辑的工作量。本文方法通过对多个审稿文本进行识别,帮助编委和编辑过滤审稿效用度低的同行评议内容,即过滤低质量的同行评议内容,进而帮助编委和编辑通过检阅高质量的审稿意见得出合理的评审结果,以此提高编委和编辑决策的科学性。利用本文方法还可以通过编委和审稿专家之间的良性互动来健全同行评议机制,编委和编辑通过将异常的审稿文本反馈给审稿专家,帮助审稿专家不断提升审稿能力。
本研究也存在一定的不足,如对中国审稿专家所撰写的审稿文本审稿效用度进行分析的部分,是利用中式英语进行推测的方式,与现实存在一定差距。如果未来能够开放审稿专家信息,才能在研究中利用真实数据刻画中国审稿专家的特征。同时,本文只使用了2020年的数据,未来通过合理地使用大量数据,则可以使模型拥有更好的智能识别效果。
