基于回归模型的采集数据清洗技术
2022-04-07李洪烈
李洪烈, 夏 栋, 王 倩
(海军航空大学青岛校区,山东 青岛 266000)
0 引言
数据的有效性及其质量是大数据处理的前提[1-3],数据清洗(即数据预处理)是大数据处理的一个重要环节[4]。数据清洗分析“脏数据”的产生原因和存在形式,通过清洗“脏数据”,将原有的不符合要求的数据转化为满足数据质量或应用要求的数据,从而提高数据集的数据质量[5]。数据清洗包括不完整数据的清洗、错误数据的清洗和重复数据的清洗3个主要任务。而对于遥测和数据采集领域,错误数据清洗是数据清洗的主要任务。在遥测和数据采集领域,由于振动、温度以及采集设备因素对采集电路的影响,会出现错误和异常的采集数据[6],被称为孤立值、飞值、野值或者奇异值。采集数据中,野值的存在会使分析结果产生严重错误,因此对采集数据进行清洗的主要任务是对错误数据(即飞值或野值)的清洗。
本文将研究在大规模采集中的野值清洗问题,即在海量的采集数据中对野值进行识别,并通过合适的算法给出野值对应位置的最优估计值。首先提出了一种利用一定采集时间内相邻采集数据(不包含当前数据)的回归值和采集参数变化率给出野值精细识别的方法,然后给出了基于回归模型的数据清洗的完整处理流程,最后利用真实飞行采集数据对本文提出的清洗方法进行了验证。
1 采集数据中的野值及清洗
采集数据中出现明显不同于其他数据的对象值时,该值被称为野值或者孤立值,野值识别是大数据处理的一项重要内容,其重要性体现在以下方面[7]:1) 野值的存在对数据分析的结果会产生非常大的影响; 2) 某些情况下,野值可能是对应领域中感兴趣或者有代表性的潜在知识,野值的深入挖掘分析有时能产生有意义的新知识。
当野值为错误数据时,还需要对野值的真实值进行估计[8-9]。对野值进行数据清洗的方法主要包括两类[10-11]:1) 使用简单规则库(如业务特定规则、常识性规则等)检测、修正数据的错误; 2) 分箱方法通过考察属性值周围的值来平滑属性的值,属性值被分布到一些等深或等宽的“箱”中,按照“箱”中属性值的平均值或中值来替换“箱”中的属性值。
简单规则库野值识别简单、算法速度快,但是规则设置较为宽泛,容易造成部分野值没有被识别出来。分箱识别野值要更准确,但是由于在分箱过程中箱内的内容也包含了野值本身,野值偏离真实值较大时会严重影响野值识别和估计的结果。图1为分别采用简单规则和分箱对某飞机航向原始采集数据进行野值识别的结果。

图1 简单规则和分箱野值识别效果Fig.1 Results of outliers’ identification based on simple rules and separated container
由图1可以看出,在原始采集数据中存在4个野值。简单规则识别出了超出航向角度范围的2个野值,而对于航向范围内的另外2个野值并没有识别出来;分箱识别出了3个野值,但是有1个数据由于受到了临近野值的影响,并没有被识别出来。针对简单规则和分箱的不足,本文将研究一种基于回归模型的数据清洗方法。
2 基于回归模型的精细野值识别
对于采集数据而言,采集到的参数值随时间变化,当前采集数值与前后数据必然有一定的相关性。当前采集值与前后数据相比既存在一定的变化,又必然会将变化速度限定在一定范围内。因此,可以根据当前时刻采样值与附近采样值的偏离程度判断其是否为野值。基于回归模型的野值识别方法以剔除潜在野值后一定时间窗口内采集数据作为参考,对当前采集值是否为野值做出判定。
2.1 野值长度和参考宽度的确定
野值长度Lerr指数据采集中可能连续出现野值的个数,参考宽度Lc指对参数野值做出判断时使用的附近参考数据的个数。单独设置野值长度和参考宽度的目的是将可能为野值的数据从采集数据中剥离,使其不会影响野值的判决过程。野值长度和参考宽度如图2所示,x(k)表示参数的第k个采集数据,M表示最远的参考数据到x(k)的距离。

图2 野值长度和参考宽度示意图Fig.2 Diagram of outliers’ length and referenced data width
野值长度Lerr与采集设备工作频率fs及野值持续时间terr有关,即
Lerr=fs·terr
(1)
该值既不能太大也不能太小,太大会减弱附近数据的关联性,太小则容易影响参考结果,应当根据参数采集实际情况进行理论分析并由工程经验得到。对于野值不连续出现的情况,Lerr=1。
参考宽度Lc指对参数野值做出判断时使用的附近参考采集数据的个数,该值通常可以取为野值长度Lerr的5~10倍。同样,该值也不能取得太大或者太小,太大容易造成对参数值变化过于敏感而将正确值判为野值,太小则不容易识别出野值。
2.2 回归参考值和偏离范围的确定

(2)
(3)
式中,ρ为当前识别位置与参考数据位置的最小偏移量,计算方法为ρ=⎣Lerr/2」,⎣·」为向下取整运算符。
偏离范围指采集参数当前采集时刻的值可能偏离附近值的大小范围,与采集频率、当前时刻偏离参考范围的距离以及采集参数随时间的变化速度有关,其计算方法为
Rx(k)=1/fs·(Lc+Lerr)/2·Vmax
(4)
式中,Vmax为参数最大变化速度。
2.3 动态回归阈值确定及野值精细识别


(5)
(6)

(7)
(8)
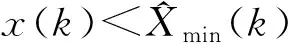
对野值进行识别时可能出现两种错误的判断:1) 将正常数据判为野值,称为误判;2) 将野值判为正常数据,称为漏判。基于回归模型的精细野值识别能够有效降低误判率和漏判率,将误判率和漏判率降低到野值出现概率的10-5以下。
3 基于回归模型的采集数据清洗
数据清洗除了需要对野值进行识别外,还需要对其正确值进行估计。基于回归模型的数据清洗处理流程如图3所示。为了提高野值识别效率,增加了基于简单规则的识别环节,具体步骤包括野值粗识别、野值精细识别、野值回归估计3个环节。

图3 采集数据清洗处理流程Fig.3 Process flow of sampled data cleaning
3.1 基于宽规则的阈值粗识别
基于回归模型的精细野值识别计算复杂,为了提高野值识别的效率,首先通过简单规则识别出明显错误、异常的野值。具体识别方法为:根据所采集参数的性质和常识,设定一个粗略的阈值范围(xmin,xmax),如果采集到的参数值x(k)超出该阈值范围,即x(k)
3.2 基于回归模型的精细识别
经过基于宽规则的阈值粗识别后,明显错误的野值数据被鉴别出来,但是仍然存在着部分比较隐蔽的野值数据没有被处理。为了鉴别出所有的野值数据,可进一步进行基于回归模型的精细野值识别。具体详见第2章,在此不再赘述。
3.3 基于回归平滑的野值估计

(9)

(10)
3.4 数据清洗分析验证
为了验证基于回归模型数据清洗的有效性,按照本文方法对实际采集的一组飞机地速数据进行数据清洗处理。未经清洗处理的原始采集数据如图4所示,由图中可以看出存在多个野值。

图4 未经处理的原始采集数据Fig.4 Unprocessed raw sampled data
数据采集飞机的最大飞行速度极限为1.5倍音速(1836 km/h),因此,基于宽规则粗识别的飞行速度的阈值范围为0~1836 km/h。图4中飞机地速原始数据经过阈值为0~1836 km/h的粗识别所得结果如图5中方框标注所示,可知有2个野值被识别出来,但是仍然有未被识别出的野值存在。野值长度取Lerr=1、参考宽度取Lc=5,再经过基于回归精细模型的精细识别后,被识别出的野值如图5中箭头标注所示。

图5 阈值粗识别和回归精细识别下的地速野值Fig.5 Outliers of ground speed based on coarseand regression-model fine identification
根据两次野值识别的结果和3.3节的估计算法,图4中原始数据经过清洗后的结果如图6所示。

图6 清洗处理后的地速数据Fig.6 Ground speed data after being cleaned
由图6可以看出,清洗处理后的数据随时间平滑变化,原始采集数据中的野值被正确地识别和剔除,并进行了合理的估算。
4 结束语
本文采用阈值粗识别结合回归模型精细识别实现了大数据处理中的数据清洗,对于明显的野值采用阈值粗识别提高识别效率,对于不易发现的野值采用基于回归模型的精细识别方法,避免了潜在野值对识别判决的影响,提高了野值的识别精确度,同时采用回归平滑算法保证了野值估计的准确性。
