基于ECA-SSD模型的汽车零件缺陷检测
2022-04-07金文倩彭露露朱媛媛王笑梅
金文倩,彭露露,朱媛媛,王笑梅
(上海师范大学计算机科学与技术系,上海 200234)
0 引 言
汽车零件通常有表面损伤、生锈、毛刺颗粒、加工异常、污渍、亮斑等多种缺陷,对于汽车零件来说,微小的缺陷可能会造成巨大的安全隐患。零件缺陷问题不容小视。
深度学习在图像处理上有着广泛的应用,如在图像分类、目标检测、图像分割等方面。Lecun等人[1]于1998年提出的LeNet网络结构是深度学习最初的网络原型。基于深度学习的目标检测分为2种,一种是基于候选区域的Two-Stage模型,例如Fast-RCNN(Fast Region-based Convolutional Neural Networks)[2]、Faster-RCNN(Faster Region-based Convolutional Neural Networks)[3]等。另一种是基于回归方法的One-Stage模型,此类模型基于anchors直接进行分类以及边界框的调整,例如SSD(Single Shot MultiBox Detector)[4]、YOLO(You Only Look Once)[5]等。
Two-Stage模型由于只在一个特征层上预测,而该特征层是经过很多层卷积后所得到的,已经被抽样到了一个很高的层次。抽样的层次越高,则意味着细节的信息保留的越少,所以Two-Stage模型对于小目标的检测效果差。同时由于这类模型通常都很大,所以检测速度也会比较慢。
在One-Stage模型检测方面,Lin等人[6]利用深度卷积结构中的多尺度金字塔结构来构建有少量额外成本的特征金字塔Feature Pyramid Networks(FPN),由于图像中可能同时存在不同大小尺寸的目标,不同的目标意味着具有不同的特征,特征金字塔可利用浅层特征将简单目标区分开来;利用深层特征将复杂目标划分开来。Fu等人[7]提出的DSSD反卷积单发检测器,在反卷积层上将Residual-101[8]与SSD相结合,提高了小目标检测的准确率。Biswas等人[9]将SSD与MobileNet相结合,利用SSD可处理不同大小形状目标的特点以及MobileNet快速轻量的特点,实现了模型的改进与优化。
为了满足工业生产上的实时性以及准确性的要求,本文在One-Stage的SSD模型的基础上,结合深度可分离结构、线性瓶颈倒残差结构以及有效通道注意力ECA模块,构建了一种同时具有检测精度及速度的目标缺陷检测ECA-SSD模型。模型在大幅度降低SSD复杂度的同时,通过增加少量的参数以保证检测的速度和准确度,并通过有效注意力机制ECA模块使网络在获取图像时能够更加集中注意在目标上,增强特征,从而忽略背景所带来的影响和干扰。实验结果表明,本文提出的算法相比于其他算法,模型小、检测速度快且准确度高。同时为了检验模型的普适性,本文还使用公开的COCO128数据集进行实验,实验结果表明,模型在其他数据集上的多目标检测也有很好的检测效果,能够满足实际工业需求。
1 算法基础
1.1 SSD模型
SSD是一种常见的One-Stage目标检测算法,相比于Two-Stage的模型,它去掉了获取候选框的步骤,采用了Anchors机制,以输入图像中的每个点为中心获取不同尺度和不同长宽比的采样,直接回归目标的类别和位置。对不同尺度的特征图用SSD进行预测,则可以适配不同大小的目标。
1.1.1 SSD网络结构
SSD模型的网络结构如图1所示。SSD网络本质上是将VGG-16[10]的最后2个全连接层改成了卷积层并增加了4个卷积层来构造的结构。首先将输入图像缩放为300×300的通道为3的RGB图像,然后经过VGG-16的网络结构直到Conv5_3,在VGG-16结构中的Conv4_3中输出SSD的第1个预测特征层,大小为38×38。在VGG-16的第2个全连接层输出第2个预测特征层,大小为19×19。随后经过4个大小不同的卷积核得到大小依次为10×10、5×5、3×3以及1×1的预测特征层。

图1 SSD网络结构图
通过上述模型结构,SSD可以得到6个不同尺度的特征层,以此来预测大小不同的目标。前面的特征图卷积次数少,抽象程度低,细节保留的较多,常用来预测小的目标,靠后的特征图则用来预测较大的目标。
1.1.2 SSD目标检测过程
SSD模型在获取不同尺度的特征图中都设置了一系列大小固定的默认框,默认框Sk的计算公式为:
(1)

SSD的2个样本选取原则为,一是每个真实框匹配与其IOU值最大的默认框;另一个是当默认框与真实框的IOU值大于阈值0.5,则判定其为正样本。原则上说,非正样本都是负样本,但是由于正样本的数量较少,这样易导致数据不平衡等问题,所以对非正样本采用困难负例挖掘方法[11],计算其最大置信度误差,置信度误差值越大说明将其预测为目标的概率越大,按照1∶3的比例来选取正负样本。
确定了训练样本之后,则是对算法进行损失计算。SSD算法的损失包含类别的置信度损失和定位回归损失,并将两者进行加权求和,损失函数L具体为:
(2)
其中,Lconf表示置信度损失,Lloc表示定位损失,N为匹配到的正样本个数,x表示匹配结果,c和l分别表示预测结果的置信度和位置信息,g是真实框,α默认为1,用于调整置信度损失和定位损失之间的比例。
置信度损失Lconf计算公式为:
(3)
(4)
定位回归损失Lloc只针对正样本,k表示类别,Lloc具体的计算公式为:
(5)

(6)
(7)
(8)
(9)
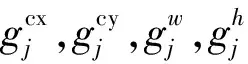
smoothL1损失函数的计算公式为:
(10)
1.2 深度可分离卷积
传统的卷积神经网络内存需求大且运算量大,相比于传统的卷积神经网络,深度可分离卷积[12]在准确率小幅度降低的前提下参数却只有VGG-16的1/32。
深度可分离卷积结构如图2所示,由Depthwise(DW)和Pointwise(PW)这2个部分结合起来,用来提取特征图。

图2 深度可分离卷积结构
传统卷积中的每个卷积核的深度都与其输入特征的深度是相同的,输出特征矩阵的深度则为卷积核的个数。而DW卷积的每个卷积核都只负责输入特征矩阵的1个层进行卷积计算,即一张通道数为3的RGB图像对应有3个卷积核,每个卷积核的深度为1,同样卷积核的个数为输出特征矩阵的深度,则通道数也是3。
PW卷积与传统卷积一样,卷积核的尺寸为1×1×C,C为上一层的通道数。
深度可分离卷积的参数是由DW卷积和PW卷积2个部分相加所得,将传统卷积与深度可分离卷积的计算量进行对比,具体计算为:
(11)
其中,Din为输入通道数,Dout为输出通道数,K为卷积核大小,Win为输入矩阵大小。由于输出通道数一般都较大,所以式(11)中的第1项可以忽略不计,而第2项的大小则取决于卷积核的大小,按照最小的3×3的卷积核来计算,可以明显得知,深度可分离卷积的计算量仅仅只是传统卷积计算量的1/9,这样不仅可以大大地加快网络的检测速度,同时对精度几乎没有太大的影响。
本文使用深度可分离卷积替换SSD模型中的VGG-16的结构,在仅仅增加少量参数的情况下,大大减少了模型参数的运算量,使得模型的运算速度得到显著的提升,同时又不降低检测的准确度。
1.3 线性瓶颈倒残差结构
传统残差结构[13]与倒残差结构的对比如图3所示。传统的残差是先进行1×1的卷积进行降维操作,然后是3×3的卷积,最后经过1×1的卷积升维还原。由于中间的3×3卷积计算量太大,所以需要降通道以减少计算量,这就导致了传统残差结构是如图3(a)所示的两边宽中间窄的沙漏形。

(a) 传统的残差结构

(b) 线性瓶颈倒残差结构图3 残差结构与倒残差结构对比
现在将计算量大的3×3卷积变成了计算量大大减少的DW卷积,所以可以适当增加通道来改善效果。倒残差结构[14]顾名思义就是与传统残差结构相反,先通过1×1卷积来升维,将低维空间映射到高维空间,再经过DW卷积,最后经过1×1卷积降维还原。这样倒残差结构就呈现出如图3(b)所示的两边窄中间宽的形状,从而在提升效果的同时不增加计算量。
一般在卷积之后都会有一个ReLU非线性激活函数,但是由于从高维向低维转换,使用ReLU激活函数可能会造成信息丢失或破坏。所以不再使用ReLU激活函数而是使用线性激活函数。前面卷积部分的ReLU激活函数也改成了ReLU6激活函数。
ReLU6激活函数的计算公式为:
y=ReLU(x)=min(max(x,0),6)
(12)
从公式中可以知道,ReLU6激活函数的前半部分与ReLU一样,当输入值小于0时置0,输入值为0~6时,不做改变,当到达上限6以及超过6的时候,则置6,这样很好地避免了ReLU的不设限而导致的激活值非常大所带来的精度损失。
由于已经使用深度可分离卷积来替换VGG结构,使得模型计算量减少,通过使用倒残差结构,适当地增加通道提高检测效果。同时使用线性激活函数避免非线性激活函数可能会造成的信息损失。
1.4 ECANet
注意力机制[15-16]是利用神经网络找到输入的特征哪一部分更有用。通过改变不同的权重,让神经网络模型在做特定的事时注意到它需要注意到的地方。通道注意力分为硬注意力和软注意力,软注意力中又可以分为空间域注意力[17]、通道域注意力[18]和混合域注意力[19]等。
SENet是最常见的通道域注意力机制,主要步骤为:挤压、激励、注意。如图4(a)所示,即先对每个通道单独进行全局平均化,然后使用2个非线性的全连接层(Fc层),再使用一个sigmoid函数生成通道权值,2个Fc层是为了捕获非线性的跨通道交互,同时进行降维。降维操作将通道特征从一个高维空间映射到一个低维空间,然后再映射回来,这个操作可以降低模型的复杂程度,但是同时也阻断了权重和通道之间产生直接的对应关系。
ECANet[20]是基于SENet的一个扩展和改进,避免了降维,以一种高效率的方式来实现跨通道交流,引入极小的参数和计算量能够带来明显的增益。ECANet在没有降维的通道进行全局平均池化之后,通过考虑每个通道以及其k个邻居来捕获跨通道交互信息。
从图4(b)可以看出,ECA在经过全局平均池化之后得到一个1×1×C的特征图,计算得到自适应的卷积核大小k,k指的是局部跨通道交流的覆盖范围,即会有多少个邻居参与到单个通道的注意力预测当中去,交互覆盖率(卷积核大小)与通道维数成正比。通过大小为k的快速1D卷积可以得到每个通道的权重。

(a) Squeeze-and-Excitation Networks(SENet)结构

(b) Efficient Channel Attention (ECANet)结构图4 SENet与ECANet结构对比图
关于k值的确定,在不同的网络结构以及不同数量的卷积模块中,可以通过手动调节最优的覆盖范围,但是通过手动调节会导致大量算力资源的消耗。由于卷积核大小k和通道维数C成正比可知,k和C存在映射关系。且通道维数一般是2的指数,映射关系如式(13):
C=φ(k)=2γ×k-b
(13)
为了使通道数较大的层可以进行更多的跨通道交互,一维卷积的卷积核大小可通过一个函数来自适应,卷积核大小k的计算公式为:
(14)
其中,|t|odd表示t最近的奇数个邻居,γ设为2,b设为1。根据上述非线性映射关系可知,高维通道的交流更长远,而低维通道的交流则会短一些。
本文添加ECA高效通道注意力模块,在避免降维的同时能够使模型将注意力放在图像的目标上,而忽略背景所带来的影响和干扰,由此来提高模型的检测准确率。
2 算法框架
基于ECA-SSD深度可分离卷积的汽车零部件缺陷检测算法的结构框架如图5所示。首先将图像缩放到300×300,输入到以深度可分离卷积为backbone的SSD网络中,经过倒残差结构以及相应的卷积操作后,依次得到了38×38、19×19、10×10、5×5、3×3、1×1这6个不同尺寸的预测特征图,将这6个特征图层分别经过ECA高效通道注意力模块,对各个特征层的不同通道按照重要程度分配不同权重之后将其送入到SSD的检测层来预测边界框的位置和对象的类别。最后再经过非极大值抑制NMS[21]来消除冗余边界框,得到最终的检测结果。
ECA-SSD算法的功能流程如图6所示。将输入的300×300的RGB图像经过1×1的PW卷积进行扩张,经过ReLU6激活函数,随后是3×3的DW卷积提取特征,再经过ReLU6激活函数,之后是1×1的PW卷积,但是这个卷积之后使用的是线性激活函数,而非ReLU激活函数,线性激活函数避免非线性激活函数可能会造成的信息损失。将卷积得到的6个不同大小的特征图层经过全局平均池化之后输入到ECA有效通道注意力中,经过激活和特征加权,给每个特征图不同的关注程度,减少网络收敛所需时间。最后送入到SSD的检测器中进行类别和定位的检测。

图5 基于ECA-SSD深度可分离的缺陷检测算法框架
3 实验与结果分析
3.1 实验环境与数据集
本次实验的硬件环境用的显卡为NVIDIA-SMI,GPU版本为CUDA 10.1,Python 3.6.9,深度学习框架为PyTorch1.7.0。
实验数据选用的是来自上汽提供的汽车衔铁外观缺陷中最常见的外壁缺陷,其中包含560张图片,使用labelimg对数据集进行VOC[22]格式的标注,将数据集中的图片按8:2的比例划分训练集与测试集。
3.2 实验结果及分析
ECA-SSD模型进行批训练的部分结果如图7所示。在单类型的缺陷检测中,外壁缺陷能够被非常准确的检测出来,漏检率低。缺陷形态多为细长型和微小型,基于ECA-SSD模型的目标缺陷检测的效果精确,验证了改进算法的有效性。
目标检测模型的评价指标有很多,本次实验选择的是Precision准确率和Recall召回率。ECA-SSD模型的Recall和Precision的变化曲线如图8所示,准确率为89.9%,召回率为97%。说明模型对于正样本的识别率高,分类效果好。

图7 ECA-SSD模型缺陷检测结果

(a) 缺陷检测准确率

(b) 缺陷检测召回率图8 ECA-SSD模型的Precision和Recall变化曲线
在机器学习领域,混淆矩阵(confusion matrix)[23]是将算法性能进行可视化呈现的一种特定矩阵,其中行表示实际类别,列表示预测值。如图9为本文模型缺陷检测的混淆矩阵,对于外壁缺陷damage的检测准确率为93%,误检或漏检率为7%,背景被100%检测成功。

图9 缺陷检测混淆矩阵
图10为ECA-SSD模型在400 epoch(训练周期)内损失值loss的变化曲线。在训练初期,模型的损失值迅速降到较小值,在训练后期,损失值逐渐降低并收敛,稳定在0.02~0.04之间。
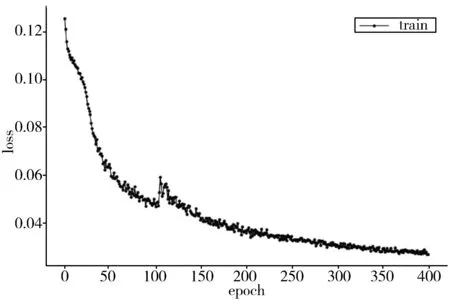
图10 ECA-SSD模型loss变化曲线
为了验证本文提出的ECA-SSD算法的性能,本文除了对实验结果进行了分析,还与其他不同模型做了对比实验。为了保证实验的公平性以及准确性,每组实验的网络模型均设置相同的训练参数。输入图像都缩放为300×300的大小,迭代4000次,批次为32,初始学习率为1e-3,GAMMA:0.1,动量为0.9,权重衰减为0.0005。对比实验的评价指标为3项,分别为mAP、模型大小与速度。
对比实验分别训练了VGG-SSD、MobileNetV2-SSD、SE-SSD、YOLO v3以及本文所提出的ECA-SSD模型。实验结果如表1所示。
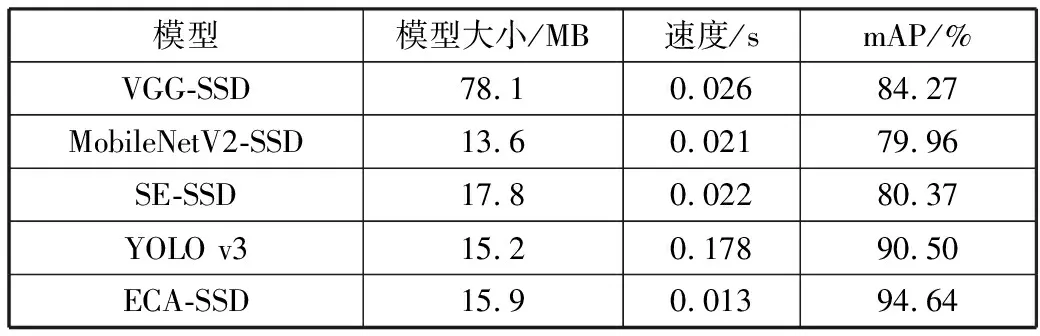
表1 各个模型对比实验结果
由表1可知,VGG-SSD模型在准确率和速度上都有着不错的性能,但是模型较大,不符合现代化工业轻便的要求。将SSD中的VGG结构替换成了轻便型的MobileNetV2结构可以明显地发现模型的大小有了巨大的改变,速度也有所提高,但是准确率却也在下降。将通道注意力SENet模块添加到MobileNetV2-SSD模型中,使模型在检测时将注意力集中在图像的重点目标中,减少背景所带来的干扰,模型的大小有所增大,同时检测的准确率也有提高,但是提高的程度不明显,且速度也有所降低。YOLO v3检测的准确率较高,模型也较小,但是检测的速度相比于其他模型较慢。本文中的ECANet是对SENet的改进,在避免降维的同时保证了对于图像中目标的注意力,减少了背景的影响。从结果可以看出,本文模型较小,且速度相对于其他模型有明显地提升,准确率也有了很大提高。对于汽车零件的缺陷检测在工业上有着速度和精度的要求,同样算法模型过大也不利于实际操作,本文提出的ECA-SSD模型在有着轻量级模型的特征同时也能保证检测的速度和精度。

(a) VGG-SSD检测结果

(b) MobileNetV2-SSD检测结果

(c) YOLO v3检测结果

(d) ECA-SSD检测结果图11 缺陷检测结果对比
图11是使用VGG-SSD模型、MobileNetV2-SSD模型、YOLO v3模型和本文的ECA-SSD模型对同一张缺陷图片进行检测得到的结果。明显地看出,图11(a)中的VGG-SSD模型和图11(b)中的MobileNetV2-SSD模型都有部分缺陷没有检测到,检测的结果不太理想。图11(c)中的YOLO v3模型对所有缺陷都能进行有效的检测,图11(d)中模型不仅将缺陷全部识别,同时检测的准确率也很高。

图12 ECA-SSD模型在COCO数据集上的检测结果
为了验证本文提出的算法的普适性,本文还使用微软提供的公开数据集COCO数据集来训练模型,COCO数据集中有80个类别。图12为模型在COCO数据集上的检测结果,图片中的目标都能够进行很好的识别,说明改进算法不仅在零件外壁缺陷数据集上是有效的,在其他开源数据集上进行多目标的检测也是能够很好实现。
通常,Recall值是递增的,正例被判为正例的数量越来越多,但是这并非严格意义上的递增。准确率的总体趋势是在递减的,正例被判为正例变多,同时负例被判为正例的数量也在变多。P-R曲线下的面积,叫做AP(Average Precision),N个分类类别得到N条P-R曲线和N个AP。图13为ECA-SSD模型对COCO128数据集的检测P-R曲线变化。其中深灰粗曲线表示模型对于数据集中80种类别的平均精度AP,浅灰色细曲线表示80种类别中每一种类别的平均精度AP,P-R曲线下的面积越大说明AP值越高,则表示对这个类别的检测精度越高。可以看出图片中大多数曲线集中对角线上方,这样曲线下的面积较大,精确度较高。说明ECA-SSD模型对于COCO128数据集中的大多数类别能够进行较好的识别,对于少部分类别的检测效果不佳。
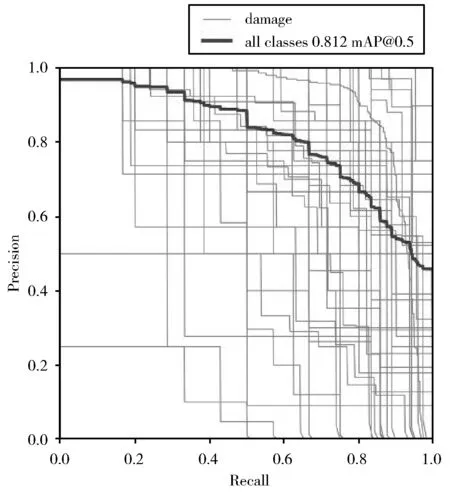
图13 ECA-SSD模型在COCO数据集上的P-R曲线
ECA-SSD模型对于COCO128数据集中的80种分类的检测混淆矩阵如图14所示。混淆矩阵的特点是将所有的正确预测结果都体现在对角线上,可以很清楚地看出图14中的对角线的颜色很明显,说明检测的正确率高,错误的检测在对角线外,颜色浅且少。

图14 COCO数据集的混淆矩阵
在相同的实验条件下,将ECA-SSD模型在COCO数据集上的识别检测情况与VGG-SSD、MobileNetV2-SSD、SE-SSD、YOLO v3模型进行对比。如表2所示,ECA-SSD模型的大小较小,检测精度较高,且检测速度相比于其他模型更加优越,比初始的VGG-SSD模型速度提升了将近10倍。说明ECA-SSD模型在其他数据集上也具有良好的检测效果。

表2 各个模型在COCO128数据集中的对比实验结果
4 结束语
现代汽车工业的零部件缺陷检测对于实时性和鲁棒性有着很高的要求。为此,本文基于回归的One-Stage目标检测模型SSD为网络基础,利用基于深度可分离卷积以及线性瓶颈倒残差结构,并引入ECANet有效通道注意力机制模块,提出了一种ECA-SSD目标检测模型。本文的主要工作总结如下:
1)将SSD中的VGG结构用深度可分离结构进行替换,相比于原来卷积神经网络,深度可分离卷积对内存的需求量小,同时能够有效地减少模型的计算量,提高检测速度。
2)为了提高检测的准确度,加入线性瓶颈倒残差结构。通过适当地增加通道数,同时使用线性激活函数,减少信息丢失与破坏。
3)为了突出目标的特征信息,忽略背景的干扰,在目标检测之前引入了有效通道注意力ECA模块,按照特征的重要程度进行权值分配,能够更有效地检测目标,提高精度,降低漏检率。
4)利用该模型对某企业提供的汽车零件外壁缺陷进行了检测和验证,取得了良好的结果。实验结果表明,模型大小仅15.9 MB,mAP为94.64%,检测每张图片时间为0.013 s,满足了汽车工业上的速度和精度的需求。对比实验表明,ECA-SSD模型在模型大小、检测精度以及速度上都具有一定的优越性。
5)验证模型的普适性以及多分类检测的效果,将ECA-SSD模型用于COCO128数据集的目标检测实验,实验结果表明本文模型具有良好的实时性、准确性以及鲁棒性,能够满足实际应用的需求。
