基于非线性堆叠双向网络的端到端声纹识别
2022-04-07王芷悦
王芷悦,崔 琳,2
(1.西安工程大学电子信息学院,陕西 西安 710699; 2.西北工业大学航海学院,陕西 西安 710072)
0 引 言
声纹识别又称说话人识别,是生物识别技术的一种,它是通过对比不同语音的深度特征来达到区分说话人的目的。相较于其他需要接触采集的生物识别方式,声纹识别获取样本方式更多样,被采集者接受度更高。声纹识别在刑事侦查、国防监听、金融证券、生活加密等领域都有重要的应用。
在深度学习进入声纹识别领域之前,传统方法中最有效的是利用高斯混合模型-通用背景模型(Gaussian Mixture Model-Universal Background Model,GMM-UBM)[1-2]进行声纹识别,但是此方法过程繁琐,整体性差。随着深度学习的发展,神经网络在多个方面表现优异,声纹识别领域也开始引入深度学习的方法。由谷歌提出的d-vector模型[3]首次建立了深层神经网络(Deep Neural Networks, DNN)下的声纹识别系统,后来又发展出基于三维卷积神经网络(3D Convolutional Neural Networks, 3D-CNN)的说话人识别模型[4]和基于时延神经网络(Time-Delay Neural Network, TDNN)的x-vector模型[5]等各种模型。以上几种方法是端到端声纹识别的雏形,近几年,端到端模型[6-7]愈发引起研究人员的重视。百度提出基于残差网络(Residual Convolution Neural Network, ResCNN)的端到端声纹识别模型[8],此外还有从神经网络的隐藏层提取帧级别说话人深度嵌入的方法[9],用于建立端到端的说话人识别模型。这些模型充分发挥神经网络的优势,一次性完成深度特征提取与分类,过程简洁、整体性强、便于优化,且结果较好。
主干网络的选择对于端到端声纹识别模型来说非常关键,常见的卷积神经网络(Convolutional Neural Networks, CNN)[10-11]虽擅长提取数据的深层特征,但在处理时序数据方面仍有短板。循环神经网络(Recurrent Neural Network, RNN)[12-13]擅于处理序列信号,具有信息持久性,所以常被用来处理具有时间连续性的语音信号。虽然RNN擅长处理时序信号但是存在梯度爆炸或梯度消失的问题,且传统RNN无法实现对长序列的记忆。后来长短时记忆网络(Long Short-Term Memory, LSTM)[14-15]被提出,它改变了传统RNN网络的内部结构,避免梯度在传递过程中的大量连乘,使网络只对有价值的信息进行记忆,解决了RNN梯度消失与无法处理长序列任务的问题。文献[16]构建了一种LSTM-RNN模型,研究不同语音特征和不同信噪比情况下的文本无关的说话人识别。
对于语音信号,前一帧与后一帧同样地反映着说话人的音色特征。因此,对于主干网络而言全面处理时序信息的能力至关重要。双向长短时记忆网络(Bidirectional Long Short-Term Memory, BLSTM)[17]是由前向和后向LSTM结合而成,它能够获得更多的时序信息从而得到相对LSTM更细粒度的分类结果。要使网络模型的特征提取能力进一步加强,就要改变原始网络结构。堆叠网络(stacked network)[18]是由多层神经网络层叠而成,它能够获得更深层次的数据特征信息从而得到更精确的识别结果。但是如果网络在外部没有非线性激活层,这就使网络缺少非线性表达能力从而缺少应对复杂问题的能力。此问题本文通过堆叠多层的非线性层来解决。
综合上述研究,针对语音信号独特的数据特征,同时为得到过程简洁、整体性强且具有时序全面性与非线性的高精度识别模型,本文提出一种以非线性堆叠双向LSTM(Nonlinear Stacked Bidirectional Long Short-Term Memory, NSB-LSTM)为主干网络的文本无关端到端声纹识别模型。
1 端到端声纹识别模型
1.1 主干网络
本文所构建的NSB-LSTM主干网络,通过多层BLSTM与非线性层的叠加,逐层提取语音信号的深层次特征。其中LSTM是一种改进的循环神经网络,它改造了传统RNN隐藏单元的内部结构,加入“门”和细胞状态的理念,使网络能够有选择地记忆和遗忘。BLSTM结合前向LSTM与后向LSTM,能够双向提取数据序列的特征信息。在t时刻,前向和后向2个网络会同时处理网络的输入信息,能更全面地提取时序信号的深度特征,为时序性强的语音信号问题提供更好的识别结果。其网络结构如图1所示。

图1 BLSTM结构示意图

(1)
(2)
(3)
其中,W表示权重矩阵,b表示偏置向量。
对于SB-LSTM网络,其网络结构如图2所示。它的独特之处在于下一层的网络可以重新组合前一层网络学习到的内容,即它能够在更高级别建立新的时序数据特征。如图2所示,第1层网络接收输入数据并进行特征提取后的输出,被当作第2层网络的输入数据,继续进行深度特征计算。

图2 SB-LSTM结构示意图
本文主干网络中所加非线性层通过激活函数实现。在深度学习发展初期,传统S型非线性饱和激活函数sigmoid和tanh函数得到了广泛的应用[19],但是它们有梯度弥散的问题[20-21]。为解决这一问题,修正线性单元(Rectified Linear Units, ReLU)[22]作为激活函数的方法被提出。由于ReLU函数容易发生神经元坏死的情况[23],因而Leaky ReLU激活函数[24]被提出。由式(4)可以看出,Leaky ReLU在负半轴添加一个线性参数a,使梯度不再限定为0,所以能有效缓解神经元死亡的问题,本文选择使用此激活函数来实现非线性层。
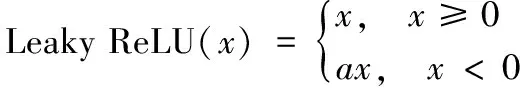
(4)
其中,a为常数。
1.2 基于NSB-LSTM的端到端声纹识别
本文所提端到端声纹识别模型主要组成部分为:输入原始数据预处理过程、将语音信号转化为高维向量的特征提取和计算声学特征深度嵌入的神经网络。图3为本文所提方法的总体流程。

图3 本文所提方法的总体流程
其中声音信号预处理主要包括预加重、分帧、加窗过程,目的是为其后的特征提取过程做数据准备。声学特征提取技术发展较早,梅尔倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)与滤波器组(Filter bank, Fbank)是其中最常用的2种。相对于MFCC特征,Fbank的信息相关性更高且更类似于人耳处理音频的方式,本文使用此特征作为神经网络的输入。其主要过程为,将预处理后的语音信号经过快速傅里叶变换,再经过Mel滤波器组计算Mel频率,最后取对数得到Fbank特征。
神经网络是整个声纹识别模型的关键部分,主干网络是将输入的特征向量计算成语音深度嵌入的工具,识别过程就是通过对比不同深度特征的距离来确定是否为同一说话人,本文针对语音信号的特点在主干网络部分做出新的改进。加深神经网络深度通常能够获得更好的识别结果,SB-LSTM由多层BLSTM堆叠而成,比单层网络有更高的拟合度,它能更深入且全面地提取时序信号的深度特征。本文利用此优势,将其引入声纹识别领域,用来处理时序性较强的语音信号。同时为了增加网络的非线性表达能力,使网络更好地处理复杂问题,增加模型识别精度,在SB-LSTM网络基础上加入多层非线性层,构建具有时序全面性与非线性的NSB-LSTM主干网络。
本文所构建NSB-LSTM主干网络的具体结构如下:首先为序列输入层,将提取出的FBank特征向量进行维度变换,变为符合神经网络输入的大小。然后是多层的BLSTM网络,双向处理接收数据,经过多层网络计算数据的深层特征。再者为多层非线性层,在网络中添加非线性表达能力。最后为一层全连接层,目的是对网络处理后的数据做维度变换。经过神经网络计算得到说话人特征的深度嵌入后,使用交叉熵损失函数结合softmax分类器对比不同语音的深度嵌入,得到说话人识别结果。
2 实 验
2.1 实验数据集
本文采用TIMIT数据集进行模型的训练和测试。该数据集由麻省理工学院、斯坦福研究院、德州仪器共同构建。数据集包含来自美国8个不同州的630位说话者,每人10句话,总计6300个句子,说话者中约有70%的男性,大多数为成年白人。音频文件录制环境为安静的室内,数据集的语音采样频率为16 kHz,比特位数为16 bits。在本文实验中将数据集以9:1划分训练集和测试集,即567个说话人数据用于训练,63个说话人数据用于测试。进行数据预处理时设置帧长和帧移分别为512、160,汉明窗大小为400。预处理后的数据通过40个梅尔滤波器,得到40维的Fbank特征作为神经网络的输入。
2.2 参数设置与评价指标
本文实验在Windows 64位操作系统上进行,采用Pytorch深度学习框架。进行模型训练时使用SGD优化器,学习率设置为0.01,整个训练过程共经历500轮迭代。
本文采用损失值(Loss)和测试时的等错误率(Equal Error Rate, EER)作为评价指标。损失值表示模型判定结果与实际标签的偏差,损失的具体数值由损失函数计算得到,本文使用交叉熵损失函数计算损失值。损失值的大小可作为衡量模型好坏的参考,损失值越小模型预测越准确。等错误率是错误拒绝率(False Rejection Rate, FRR)与错误接受率(False Acceptance Rate, FAR)相等时的值,等错误率越小就说明2种错误率同时越低,即声纹识别模型性能越好。
2.3 实验结果
2.3.1 模型参数选择
本文构建NSB-LSTM为网络主干的声纹识别模型,其中BLSTM的堆叠层数、每层隐藏节点数与非线性层数是网络的重要参数,对网络性能有着不可忽视的影响。对于SB-LSTM而言,层数越多,网络越深,理论上对说话人的识别能力也就越强,但是层数深意味着计算资源的大量消耗,并且在实际应用中,层数越多不一定得到的结果就越准确。因此需要首先构建基于SB-LSTM的声纹识别模型,通过实验得到最高性能的网络结构,从而与非线性层组合。
将SB-LSTM层数分别设置为1、3、5,将每层的隐藏节点数分别设置为256、512、768,一共9种组合方式。图4是9种不同模型的实验结果,从图中可看出SB-LSTM的网络层数从1层增加到3层时,不同隐藏节点数的网络对应的EER都有所下降,但当网络层数为5层时,等错误率大幅上升。此实验结果表明,层数为1时,网络过浅造成学习能力不足,层数为5时,对于声纹识别来说网络过深造成过拟合。从图4可以看出,不同隐藏节点在层数为3时所对应的模型效果是最好的,因此本文选择层数为3的SB-LSTM网络与非线性层结合进行后续实验。

图4 不同参数的SB-LSTM识别结果
将3层的SB-LSTM与不同层数的非线性激活层组合进行实验,得到最佳的参数组合。对于隐藏节点数则分别设为256、521、768,将非线性层数分别设为1、2、3、4,得到12种组合。图5是不同模型的实验结果,从图中可以看出,非线性层数从1增加到3时,各隐藏节点数对应模型的EER均逐渐下降,其中层数为3和隐藏节点数为768的模型表现最好,非线性层数增加到4时,模型性能变差。对比图4与图5可以看出,加入非线性层的NSB-LSTM模型在各个隐藏节点不同的情况下,性能均优于SB-LSTM模型。图5实验结果表明在非线性层数为3时,模型的非线性表达能力最好,因此本文将NSB-LSTM堆叠层数设置为3、隐藏节点数设置为768、非线性层数设置为3进行后续模型对比实验。

图5 不同参数的NSB-LSTM识别结果
2.3.2 模型性能对比
为增加LSTM的时序全面性与非线性,本文提出了NSB-LSTM网络,为验证本文所构建模型的有效性,将本文所提的NSB-LSTM2模型与RNN、GRU、LSTM、BLSTM、NSB-LSTM1(ReLU)这5种模型进行对比,除网络结构不同外,其他实验参数设置均相同。
图6是5种不同模型训练过程中的损失值变化曲线。在本文实验中,基于RNN模型的损失值变化范围与其他模型损失值范围差距较大,故将RNN的损失值变化排除在曲线图之外,这一实验结果也验证了传统循环神经网络无法很好地进行识别工作。对于其他5种模型,从图6可以看出,双向LSTM网络收敛后的损失值小于非双向网络,而增加非线性层的堆叠双向LSTM收敛后的损失值最小,收敛速度也相对最快。

图6 损失值变化曲线
模型最后一次迭代的损失值与等错误率的实验结果如表1所示。从表1可看出,基于RNN网络的模型表现最差,其他改进模型在损失值与等错误率方面均有较大提升,其中本文所提模型表现最好。本文模型相比GRU模型、LSTM模型和BLSTM模型,在损失值方面分别下降约0.8、0.76、0.34,在等错误率方面分别下降比例约为38%、36%、28%。将非线性层为ReLU函数的NSB-LSTM1模型作为对比项时,可以看出本文所使用的Leaky ReLU函数在性能上有所提升。综合以上实验结果可得出本文所提模型具有更好的识别效果和更强的模型性能,同时也验证了本文所提方法的有效性。

表1 不同网络结构性能对比
3 结束语
本文提出了一个具有时序全面性与非线性的NSB-LSTM网络作为声纹识别主干网络,通过实验找出网络模型的最佳参数,在实验中验证了本文所提模型性能优于LSTM模型、GRU等其他模型。本文构建的端到端声纹识别模型解决了传统方法过程繁琐的问题,并且针对语音信号特点在原有网络结构基础上提出新的改进策略,得到高性能的声纹识别模型,为提取语音深度特征提供了新的方法。
