基于注意力机制子网络的时空跌倒检测算法
2022-04-07师后勤齐宇霄
谢 辉,师后勤,齐宇霄,陈 瑞,童 莹
(南京工程学院信息与通信工程学院,江苏 南京 211167)
0 引 言
跌倒事件是公共安全的最大风险之一,尤其是对老年人。有研究表明,在65岁以上的老年人中有1/3的人每年至少经历一次跌倒,其中约8%的跌倒会导致严重伤害。世界卫生组织的2020年报告中,与跌倒有关的死亡率为6%[1]。因此,跌倒成为造成老年人身体伤害甚至死亡的主要原因,也引起了人们对跌倒检测和预警系统的关注。
目前,跌倒检测系统有基于可穿戴设备的[1-2]和基于成像传感器的[3-4]这2种。前者采用倾斜传感器、加速度计、陀螺仪等可穿戴传感器,可以随身携带,实现全天候监测,在跌倒事件检测方面取得了良好的性能。但是,可穿戴设备比较适合室内环境,在室外或拥挤的场景中不太适合。基于成像传感器的跌倒检测系统依赖于摄像机、深度传感器和红外传感器等成像设备,这种方法及其数据集主要对拥有昂贵设备的室内场景中摔倒事件进行检测。
针对室外复杂场景下的跌倒检测,本文提出一种基于注意力机制子网络的时空坠落检测算法,该算法的总体框架如图1所示。首先,采用基于YOLO v3的多尺度特征融合方法提取图像空间特征。然后,采用卡尔曼滤波和匈牙利算法对目标行人进行跟踪,运用数据增强和重检测提高检测精度,同时加入注意力机制子网络提高被遮挡行人的识别率。最后,使用滑动窗口存储特征映射和SVM分类器重新检测跌倒事件。

图1 本文算法框架
1 相关工作
基于计算机视觉的跌倒检测自动识别系统使用各种图像处理技术进行人体形状特征分析和运动分析来检测摔倒事件。此类方法具有成本低廉、受物理干扰小、可以用于同时检测多个事件的优点,因此受到了越来越广泛的关注。
目前,基于深度学习的目标检测算法主要分为2大类,分别是基于候选区域(Two-stage)和基于回归(One-stage)这2类[5]。其中,基于候选区域的算法首次提出是在2014年Girshick等人[6]提出的R-CNN,该方法需要先生成候选框,然后再对候选框内部进行目标检测,因此检测速度相对较慢;Wu等人[7]提出了一种改进的基于Mask R-CNN的方法,该方法提高了少样本下的检测性能。而基于回归的算法则是直接在特征图上产生物体的位置和类别概率,典型算法有2016年Redmon等人[8]提出的YOLO(You Only Look Once)算法和Liu等人[9]提出的SSD(Single Shot MultiBox Detector)算法,随后在此基础上又继续优化的算法包括YOLO v3[10]和RSSD[11]。基于回归的算法虽然时效性好,检测速度快,但存在准确率低、对小尺度目标容易漏判的问题[12]。并且上述算法均在良好的环境下进行测试得到较好结果,而现实环境更为复杂,常常有多尺度目标、光照变换、遮挡等问题影响检测。为此,邵慧翔等人[13]提出了一种融合更浅层的特征与深层特征的改进YOLO v3算法以应对小目标的检测,而刘丽等人[14]在YOLO v3网络中引入SPP(Spatial Pyramid Pooling)层提高对遮挡行人的检测准确率。但目前仍然缺少一种方法可以同时解决复杂环境下光照变化、遮挡和尺度变化等多个问题。随着目标检测算法精度和速度的不断提高,目标跟踪算法也更加倾向于基于目标检测结果的跟踪方法。在文献[15]中提出的Deepsort跟踪方法可以实现实时在线跟踪。当目标在多帧中被遮挡或漏检时,同一目标的运动轨迹将被中断,形成新的运动轨迹,因此Chen等人[16]提出了一种用于遮挡的堆叠LSTM(Long Short-Term Memory)跟踪方法。Yao等人[17]提出了一种结合孪生网络和回归网络的跟踪方法,以应对不同尺度的目标跟踪。Doan等人[18]提出了一种结合YOLO v4和Deepsort进行车辆实时检测的自适应模型。
2 基于注意力机制子网络的时空跌倒检测算法
从图1的算法框架图可以看出,本文算法包括3个模块:行人检测模块、目标跟踪模块和跌倒判断模块。其中,行人检测模块基于传统的YOLO v3网络对视频帧中的行人进行检测,并采用多尺度特征提取以适应目标的尺度变化。同时加入了注意力机制子网络克服行人被遮挡物遮挡的影响。目标跟踪模块采用卡尔曼滤波和匈牙利算法,以较低的计算成本完成跟踪任务。跌倒判断模块综合考虑滑动窗口和SVM分类器的结果,以便更准确地输出最终的跌倒事件预测。
2.1 行人检测模块
目前许多行人检测算法被提出使用,其中YOLO v3因其速度快,使用最广泛。它预测每个边界框(tx,ty,tw,th)的4个协调值。设Pw为边界框宽度,Ph为高度,根据图像左上角的偏移(cx,cy),预测的下一个边界框可以被表示为:
(1)
YOLO v3的结构如图2所示。YOLO v3包含特征提取和目标检测2个部分。特征提取部分使用了Darknet-53和Resnet网络。与传统的CNN网络结构[19]不同的是,Darknet-53去掉了常用的池化(pooling)层和全连接(fully connected)层,在卷积层之后再加上Leaky-ReLU激活函数,并且在激活函数的输入中采用无偏置,可以简化模型,减小卷积核的维数和参数,增强模型的特征提取能力,提高行人检测的及时性和灵敏度。

图2 YOLO v3网络结构
针对低分辨率拥挤小目标的检测,采用多尺度预测方法。检测部分用于对3种不同尺度的特征图进行预测,分别为52、26和13。根据网络的多尺度特征,对网络中不同感受域的卷积层进行改进,作为单独的输出用于分类计算,进而使得网络可以根据物体groundtruth的实际大小调整该感受野卷积层的priorbox,计算边界框之间的交并比为:
(2)
其中,area(A)为原边界框区域面积,area(B)为候选框区域面积。如果两者重叠程度越高,则结果越趋向于1,以此求出最佳的匹配图像边界框。最后,检测框的大小可以根据行人与摄像头的距离变化引起的不同大小进行调整。
YOLO v3以损失函数估算真实框和预测框间的距离,并在不断训练后减少两者间的差距从而得到提高模型鲁棒性的作用。YOLO v3的损失可以分为位置损失、置信度损失、分类损失,可表示为:
Loss=lxy+lwh+lcls+lconf
(3)
其中,lxy、lwh、lcls、lconf分别表示目标物体的中心点误差、长宽误差、置信度误差和预测类别误差。其中,前两者为位置损失采用误差平方和损失函数,而后两者则采用二元价差熵损失函数。
2.2 目标跟踪模块

图3 注意力机制子网络结构
为了进一步提高算法的遮挡处理能力,本文引入空间注意力机制子网络,增加行人关键部位(如头部、躯干、脚等)的特征权重,使跟踪器聚焦于这些关键部位,从而避免背景遮挡等干扰信息的影响。注意力机制子网络需要先利用固定大小为26×26的窗口,在静止的416×416图像上以奇数行从左到右、偶数行从右到左的滑动方式分割成16个子图像;再利用CNN对这些子图像进行特征提取,得到一系列的特征序列;最后利用如图3所示的注意力子网络识别身体部位并回归一个注意向量,并对这些特征序列进行加权。
当特征提取后,将图像序列转成特征序列,表示为x(t)(t=1,2,…,N),作为注意力机制的输入。图3中,当特征序列输入注意力机制子网络后经过2个卷积层来识别身体部位,通过学习映射函数F将注意矢量θ回归输出为:
(4)
其中,θt的大小表示为x(i)是行人身体部位特征的可能性,用θt对特征序列中的元素x(i)进行加权,得到加权后的特征序列X(i)(i=1,2,…,N)为:
X(i)=x(i)⊙θi,i=1,2,…,N
(5)
通过注意力机制子网络不断学习,更新注意力机制子网络的参数,优化公式(4)中的权重θt,最终将结果输入到目标跟踪模块,从而提高被遮挡行人的检测跟踪效率。

(6)

然后,采用匈牙利算法计算视频帧的帧间相关性,使用目标预测框和检测框的IoU作为匈牙利算法的权值来计算帧间相似性矩阵,从而实现目标匹配和跟踪。在匈牙利算法中,采用检测框与预测框之间的马氏距离d1来表示运动目标的关联度,即:
(7)
其中,dj为第j个检测框,yi表示为第i个预测目标位置,Si是第j个检测位罝与平均跟踪位罝之间的协方差矩阵。马氏距离保留了空间域分布的结果,为了更好地描述表观特征的关联度程度,进一步计算第i个轨迹和第j个轨迹的最小余弦距离d2,即:
(8)
式中对每一个检测框dj,计算一个表面特征描述子rj,且|rj|=1,Ri中保存了每个轨道中最近100帧的外观描述符。综合考虑马氏距离和余弦距离,得到决策信息Ci,j为:
Ci,j=λd1(i,j)+(1-λ)d2(i,j)
(9)
其中,λ为超参数,用于调整不同马氏距离d1和余弦距离d2的权重。决策信息(最终计算结果)Ci,j越小,表明检测目标与跟踪目标的相关性越大。马氏距离测量对短期预测和匹配有良好的效果,而余弦距离这种表观信息对长时间的丢失轨迹能更有效地度量,提高了算法对目标丢失和障碍物的鲁棒性。
2.3 跌倒判断模块
根据行人目标检测和跟踪结果,跌倒判断模块主要完成目标区域中行人是否跌倒的二分类工作。通常,行人站立时,其边界框的长宽比小于等于0.4;在行人跌倒的瞬间,边界框的长宽比会突然增加到0.7~1.2左右,且偏转角度会低于一定阈值(本文设定此阈值为37°),垂直方向瞬时加速度增加,且明显大于下蹲、弯腰等动作。本文综合考虑边界框的长宽比、偏转角度和垂直方向瞬时加速度3个特征因素(或特征值)进行跌倒判断,这3个因素不仅具有较强的独立性,符合综合判断的条件,还可避免因选择的特征向量过多导致特征向量空间维度更高、分类器设计复杂、系统实时性更差。
对于特征值的求解,根据跟踪模块,可以得到每帧上跟踪框的长度H、宽度W、左上方点(xL,yL)以及右下方点(xR,yR)。那么每帧跟踪框的长宽比ρ为:
ρ=W/H
(10)
每帧跟踪框的质心(xP,yP)为:
(11)
再根据质心求解出每帧目标框偏转角度为:
(12)
如果相邻2帧的质心为(xPi,yPi),(xPi+1,yPi+1)那么第i+1帧的目标垂直方向的运动速度vi+1为:
(13)
其中,t表示为2图像帧的时间间隔,那么此时的加速度ai+1为:
(14)
由于传统跌倒判断算法仅考虑单帧图像的特征值,而跌倒行为是一个连续动作,所以本文采用滑动窗口得到连续多帧图像特征的变化值。具体实现时,本文先在一个固定大小的滑动窗口中存放第1帧的特征值,随着时间的增加,后续帧的特征值不断进入容器,待容器填满后,新进入的特征值在滑动窗口末尾加入,最左侧数据随之移除。

图4 滑动窗口示意图
如图4所示,设置滑动窗口固定长度为M,对于帧序列{P1,P2,…,Pt,…},初始时滑动窗口内为{P1,P2,…,PM},经过t帧后窗口序列为{Pt+1,Pt+2,…,Pt+M}。本文窗口大小设置为跌倒行为的周期,由于跌倒过程大约在0.5 s~0.8 s之间,实验视频的帧率为20帧/秒,经过多次测试比对最终将滑动窗口大小固定为15,其中滑动窗口Pi中存放从人体运动目标中获得的特征,包括人体长宽比、偏转角度以及垂直方向瞬时加速度。
根据滑动窗口内的特征值构建支持向量机分类器(SVM)[20-21]进行跌倒检测,判别行人是否跌倒。训练过程是将大量跌倒样本特征数据和非跌倒样本特征数据放进SVM中,通过训练这些样本得到跌倒分类器。由于本文方案中提取的多种特征融合的特征向量是一个线性不可分的问题,所以选取高斯核函数作为核函数将特征投射到高维空间,即:
(15)
其中,γ属于超参且大于0。相较于多项式核函数、字符串核函数等而言,公式(15)需要调的参数较少,可以提高有效性,减少运算复杂度。
3 实验结果及分析
3.1 训练模型
为了减小光照和尺度变换的影响,本文通过随机改变光照、图像大小、角度等步骤来扩展测试数据集。相应地调整原标签集,扩展训练集。实验结果表明,该网络对光照和阴影变化具有较强的鲁棒性,能够很好地检测小目标。

图5 损失曲线
图5为在coco数据集训练800次后通过可视化工具tensorboard查看的训练过程中损失值的收敛曲线。从图5可以看出,在训练开始时,损失值迅速下降。随着迭代次数的增加,曲线基本上趋于稳定。

图6 AP图
图6为模型的AP(Average Precision)图。AP是精确度(Precision)和召回率(Recall)的结合。如图6所示,从曲线下的面积可以看出,召回率随着准确率的降低而增加。通过速率不断增加,不断的测试找到彼此的平衡。精确度和召回率公式为:
(16)
(17)
其中,TP(True Positives)是被正确归类为阳性的样本数,FP(False Positives)是被错误归类为阳性的样本数,FN(False Negatives)是被错误归类为阴性的样本数。
3.2 实验结果
本文分别在Cityperson数据集、Montreal fall视频数据集和自建数据集上评估本文的检测器,实验结果分别如图7~图12所示。
图7为在Cityperson数据集行人检测结果。在图7中存在行人相互遮挡、行人被路标汽车遮挡以及不同光照、尺度下的情况。从结果可看出,在行人检测上本文方法可以有效克服行人被部分遮挡的情况,并对明暗环境以及行人不同尺度的情况具有一定的鲁棒性。
图8为在Montreal fall视频数据集上的对于行人跌倒的检测结果。在图8中分别有3种不同方式角度的典型跌倒情况,本文方法都能够准确在图像右上方自动标注出检测到行人跌倒事件发生。

图7 Cityperson数据集上的部分测试结果

图8 Montreal fall视频数据集上的部分测试结果

图9 室内光照变化下的测试结果

图10 室外遮挡情况下的测试结果

图11 室外尺度变化下的测试结果

图12 干扰实验的测试结果
图9~图12展示了自建数据集中在真实复杂场景下的部分典型测试结果。本文分别在图9中设置了室内高光照以及遮挡物存在的场景,在图10中设置了室外树木遮挡的场景,在图11中设置了从近到远4个尺度下的行人情况以及在图12中设置了行人站立、半蹲、弯腰和蹲下的4种干扰情况。在上述图中,本文方法能够有效克服强光环境的干扰,并能在部分身体被遮挡时持续跟踪,但当身体关键部位大面积遮挡时效果仍然不佳,此外对于不同尺度的行人本文方法可以有效调整跟踪框的大小,提高跌倒判断的准确性,并且本文的跌倒判断算法对于蹲下、弯腰等干扰情况的误判性低。表1为本文方法与文献[22-24]中的算法进行比较的结果。综合考虑了准确性、误判性和漏判性等指标,结果表明本文方法具有更高的综合准确性以及可行性。
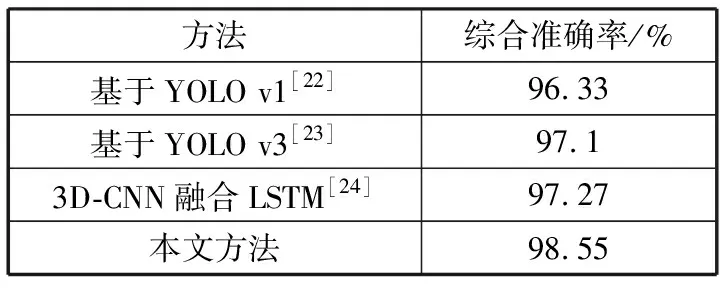
表1 实验结果比较
4 结束语
本文提出了一种基于深度学习的复杂环境跌倒事件检测方法。本文的研究有2个方面工作:1)在模型中引入了注意力机制子网络来克服遮挡物的影响;2)在跌倒跟踪模块中提出了使用滑动窗口检测连续多帧图像中行人跌倒情况的思想,有效提高准确性。此外,本文方法能够克服室外光照变换以及行人尺度变换的干扰,通过进行各种实验,验证了所提出的方法对于室外复杂环境下的跌倒检测具有较高的鲁棒性,也具有将其用于室外环境的监视系统的可能性。
