基于非局部注意力和局部特征的车辆重识别算法
2022-04-07万冬厚张德贤邓淼磊
万冬厚,张德贤,邓淼磊
(1.河南工业大学信息科学与工程学院,河南 郑州 450001; 2.河南省粮食信息处理国际联合实验室,河南 郑州 450001)
0 引 言
智慧城市与智慧交通的相关技术近些年来飞速发展,车辆管理是智慧交通的重要一环,所以车辆重识别技术也是智慧交通的重要技术之一。车辆重识别是图像检索的子领域,目的是在不同摄像头拍摄的不同场景中检索同一辆车。车辆重识别由于受到光线因素、场景变换、拍摄角度等因素影响,从而导致重识别过程中存在高类内相似度的问题。图1为同一辆车在不同角度的对比,很难分辨出这是不是同一辆车。这一问题受到国内外学者的广泛关注,诸多学者已经开始着手解决这一问题。

图1 同一车辆在不同角度拍摄的图片
传统的车辆重识别方法使用车辆图像的固有属性进行特征提取,从图片中提取那些最有表现力的特征,例如图片的边缘、角点等特征。文献[1-4]都是用外观描述子的方法提取车辆查询集与匹配集的特征。Feris等人[5]使用车辆的色彩与车型等信息,与数据库中车辆的色彩与车型等信息进行比较,这种方法将车辆重识别任务转化成了车辆属性匹配的问题。Zheng等人[6]使用SIFT与BOW结合的方法来描述车辆特征。首先使用SIFT算子发现图片中不会轻易改变的点作为特征,然后使用贝叶斯融合方法转化已经得到的特征。文献[7]将车辆的图片切割成条状分块,使用切割后的条状图片块作为车辆特征进行对比,这种图像特征处理方法能够更好地进行特征对齐。车辆重识别的核心在于获得车辆独一无二的特征,如果仅仅选取车辆的色彩等属性作为特征,并不能够将车辆区分开来。所以Koestinger等人[8]使用了HSV、RGB直方图与LBP纹路特征融合的方法,这种方法将纹路以及色彩等特征融合,之后使用PCA降维获得描述因子。Liu等人[9]融合了色彩纹路以及车辆的语义信息,极大地扩展了车辆的描述特征。
传统的图像特征提取方式都具备各自的特点,但是都具有相同的缺点:泛化能力弱、在特定的场景有效、只能用于特定的任务、特征一旦更换任务场景其效果就会变得很差。主要表现于:1)特征描述方法只针对特定的任务有效,无法在更换场景时进行相应的调整,例如直方图特征值仅仅对于图像分类任务奏效,对于图像的语义分割任务无效;2)传统的特征描述方法仅侧重于图像的某些方面的特征,例如方向梯度直方图HOG侧重于图像的边缘信息,SIFT特征侧重于图像的某些局部外观兴趣点,局部二值模式特征LBP侧重于图像的纹理特征,因此传统方法泛化能力较差。
卷积神经网络提取的图像特征具有良好的泛化能力,因此在重识别领域、目标检测、语义分割等诸多领域拥有良好的效果。目前主流的车辆重识别方法使用卷积神经网络。许多车辆重识别的研究都是关注于全局特征,也就是使用深层的卷积神经网络提取整幅图片的特征向量进行图像检索。有些研究开始关注于局部特征的提取,常用的局部特征提取的方法有关键点定位、区域分割等。Wang等人[10]提出了一种使用关键点定位和使用关键点进行区域分割的方法。该方法首先将车辆的图像标注20个关键点,从图像中获取目标车辆的多个分割结果,然后使用卷积神经网络对多个区域的分割结果提取车辆的关键特征,将这些关键特征与卷积神经网络提取整幅图像的全局特征融合,最后与要检索的图像进行特征向量的对比。Meng等人[11]提出了一种从不同方向解析视点的网络。这个网络有2个分支,第1个分支是全局分支。全局分支使用ResNet50[12]提取车辆的特征图,特征图经过全局平均池化[13]后生成2048维的特征,这2048维的特征分别被送入到三元组损失和全连接层,经全连接层的特征最终被送入到交叉熵损失中。第2个分支则使用U-Net[14]将车辆从前方、后方、侧方、上方4个方向分割,这4个方向一般都是视觉可见方向。分割后的特征与全局相乘获得对齐的特征,然后使用注意力机制给这4个可见部分以不同的权重。这4个特征被聚合到一起后被送入到三元组损失中,推理阶段全局特征与4个视点的特征直接相加。
无论是基于局部特征的车辆重识别方法还是基于全局特征的车辆重识别方法都是使用度量学习的方法,度量学习又称作相似度学习,如今在人脸识别、行人重识别、车辆重识别领域主流的方法都是使用度量学习的方法。度量学习的目的是使得同类图像特征的距离小于不同类别图像特征的距离。使用卷积神经网络提取图片的特征,然后使用度量学习损失函数来使得同类的图像特征距离小于不同类别图像特征的距离。Zheng等人[15]提出了大规模车辆重识别数据集VehicleNet,这个数据集的训练集有31805辆汽车的434440张图片。VehicleNet数据集是经CityFlow[16]与VehicleID、VeRi776混合而成。作者的模型使用了较为简单的结构,在骨干网络SE-ResNet后接全局平均池化和一个512维的全连接层、Batch Normalization[17]层以及1个用于分类的全连接层。作者提出了非常有效的二阶学习理论,也就是第1阶段使用大规模数据集VehicleNet训练网络参数,第2阶段在目标数据集CityFlow上进行训练,同时更换第1阶段的最后一层的线性分类网络并减小学习率微调模型参数。最终二阶学习取得了不错的效果,其中mAP与CMC-1均有较大提升。在CVPR2020 AICity Challenge中,作者在上述模型的基础上又使用了MaskRCNN[18]裁剪汽车图片、模型集成、查询膨胀、Re-ranking[19]等一系列技术处理来提升成绩,最终达到了第1名的成绩。
上述基于深度学习的方法中,大多数方法只关注图像的全局特征,缺乏对全局特征与局部特征的融合能力。全局特征过分关注车辆的全局信息,而忽略了局部有分辨力的特征。所以全局特征在在区分视觉上相似度较高的不同车辆时效果会较差。局部特征通常是包含许多细节信息的有分辨力的特征,例如车辆挡风玻璃的挂饰、车辆前方的纸巾盒等都是可以区分相似车辆的细粒度特征,所以车辆重识别需要融合粗粒度的全局特征与细粒度的局部特征来提高车辆重识别的精度。因此,本文构建一种融合局部特征与全局特征的多分支车辆重识别网络。受到文献[20]的启发,本文在多分支网络的基础上构建一种非局部注意力与多分支特征融合学习的车辆重识别网络。其中竖直通道组的结构如图2所示。

图2 竖直通道组的结构
1 模型描述
本文提出一种非局部语义特征与多尺度特征的车辆重识别模型。首先,使用ResNet50作为骨干网络,并在骨干网络中构建非局部注意力,增强骨干网络提取车辆的语义特征的能力。然后,在骨干网络后有5个局部分支学习车辆的细粒度局部特征。最后将这5个局部分支的特征与全局特征进行融合,得到局部-全局特征。使用这些局部-全局特征对比车辆之间的欧氏距离,从而得到车辆的id信息,相似度排行较高的属于同一id。
1.1 非局部注意力
本文在骨干网络中构建了非局部注意力层。非局部注意力层的架构如图3所示。受到文献[20]的启发,本文模型的非局部注意力层的计算公式为:
(1)

图3 非局部注意力
图3中g、θ、φ是公式(1)中提到的g、θ、φ。C、H、W分别表示特征图的通道数量、高和宽。C′是缩减后的通道容量。⊗表示矩阵相乘操作,图中最上面的⊕表示元素求和,也就是公式(2)所表示的内容,将原来的特征xi与经过注意力机制计算后的特征Wzyi相加。Wz指的是图中⊗左边的特征图,yi指的是⊗右边的特征图。
式(1)中i指的是输出层在位置i处的输出,j指的是特征图中除了i位置之外的其他位置。x是输入的特征图,y是输出的特征图,y与x有同样的维度大小。∑∀jeθ(xi)Tφ(xj)是成对函数,用来计算位置i和位置j之间的相似性。成对函数将xi和xj映射到高斯空间来计算2个位置特征图的相似度。最终,∑∀jeθ(xi)Tφ(xj)的输出将会是位置i处的特征图与其他所有位置的特征图的相似度权值加权和。g(xj)的表达式为g(xj)=Wgxj,g(xj)表示对输入的特征图xj进行映射变换,Wg表示可学习的权重矩阵。最终的非局部注意力模块可以表示为:
Zi=Wzyi+xi
(2)
其中,yi为式(1)中定义的公式,Wz为学习的权重矩阵,+表示按元素相加,Wzyi+xi表示将非局部注意力前的特征图直接加到非局部注意力处理后的特征图后面。这样做可以保证在原有的语义特征的基础上捕获任意2个位置远程依赖,而不是仅仅依赖于相邻点,相当于使用了一个与特征图同样大小的卷积核来进行卷积,可以捕获全局的语义信息。
1.2 非局部注意力5个分支网络架构
整个非局部注意力5个分支网络的结构见图4,其中骨干网络使用ResNet50,中间层加入了非局部注意力层。RBs表示残差模块,GMP表示全局最大池化,GAP表示全局平均池化,BN代表Batch Normalization层,FC代表全连接层。
整个架构的主干网络是ResNet50,非局部注意力模块被加入到主干网络中,用于捕获特征图中大范围依赖,而不是仅仅依赖于邻接的特征图。在ResNet50的conv5_3层后,特征图将被复制为3个主干特征图分支,送入到3个独立的分支网络中,每个特征图在经过分支网络处理后的通道维度都是2048维。首先,将第1个主干分支的特征图复制1份,称之为全局特征,将全局特征送入到后面的分支网络中。其次,再复制1份特征图,特征图从竖直角度被切分为4块,这4块就是从竖直角度分割的局部特征,送入后面的网络中提取车辆图像的竖直分块的细粒度特征。最后,又复制1份特征图,特征图从通道层面分为4个通道组。同样,第2个主干分支也被分为3个小分支,首先复制主干特征图,将全局特征送入到后面的网络中,其次,再复制1份第2个主干分支特征图,将特征图从水平方向切分为4组,这4组分割后的特征图是车辆图像的水平方向的局部特征,送入后续网络中提取车辆图像水平方向的细粒度特征。最后,再复制1份特征图,将特征图从通道方向分为4组。前2个主干分支被分组后,共计有18个组,这18个组会被送入到全局最大池化层中。全局分支用来提取全局粗粒度特征。竖直与水平分组可以提取车辆图像局部的细粒度的特征,并且增强模型对局部特征的学习能力,不同的通道分组用来学习多样的语义特征。
第3个主干的特征图分支,叫做通道竖直分组。竖直通道组的图像可见图2,竖直通道组可以提取车辆图像不同维度的语义信息,增强模型的语义提取能力。首先,特征图会从水平方向分为2个通道组,然后2个通道组又会从竖直方向被分为4个通道组。这4个分组会被送入到4个全局平均池化层。通道组竖直分支将通道组分为4个局部的分组,用来提取车辆图像细粒度的语义特征。

图4 非局部注意力5个分支网络结构
5个分支的结构可见图4,竖直角度分割的4个特征块构成第1个分支,第1个通道分组构成第2个分支,水平角度分割的4个局部特征图构成第3个分支,第2个通道分组构成第4个分支,竖直通道组构成第5个分支。这5个分支分别提取车辆图像的横向特征、通道组特征、纵向特征和不同维度的语义特征,然后与全局特征进行融合,从而实现细粒度特征与粗粒度特征融合,提升车辆重识别的检索精度。
上面提到的22个分支被送入到1×1的卷积层,用来统一维度,将所有的特征分支都统一到256维,降维之后的特征会被送入到BN(Batch Normalization)层,加速模型的收敛。上面提到的2个全局分支将会被送入到Triplet Loss[21]中进行度量学习,其余的20个局部分支将会被送入到全连接层,之后被送入到Softmax Loss中进行分类学习。在推理阶段,所有的22个特征分支在经过BN层后,会concatenated成一个1维向量,和其他的向量对比欧氏距离,判断是否是同一辆车。
1.3 损失函数
本文提出的模型使用了Softmax Loss和Triplet Loss结合的损失函数,这样可以提升模型的判别能力。2种损失函数在训练阶段使用。Triplet Loss用于车辆个体间的精细分类,拉大anchor特征与负例特征的距离,拉近正例特征与anchor特征间的距离。Softmax Loss则用来加速训练的收敛,提升训练过程的稳定性。在1个batch中,Softmax Loss公式表示为:
(3)

在1个batch中,Triplet Loss的损失函数为:
(4)

最终,总的损失函数为:
(5)
其中,Nsoftmax和Ntriplet分别代表使用交叉熵损失函数和三元组损失函数训练分支的总数。本文提出的模型中,Nsoftmax=22、Ntriplet=2,因为本文的全连接分支有22个,全局分支有2个。ω是交叉熵损失函数三元组损失函数的平衡参数。
2 实验验证
在实验验证阶段,本文使用VeRi-776公开的车辆重识别数据集对本文提出的模型进行实验验证。本文提出的模型使用Pytorch深度学习框架进行实现,实验环境是装有2块32 GB显存的Tesla V100显卡的高性能服务器。
2.1 数据集和评价指标
VeRi-776数据集是使用真实场景中的20个道路监控摄像头拍摄的776辆汽车的51035张图片构成。车辆类型包括小汽车、渣土车、公交车等常见车型。该数据集分为训练集,查询集和测试集。训练集由576辆车辆的37778张图像构成,查询集有1678张图片,测试集有11579张图片。在测试过程中,使用查询集的图像对测试集的图像进行检索和排序,将最接近的具有相同id的车辆按照欧氏距离进行排序。
在检索和重识别任务中,使用最广泛的指标是rank-k(前k击中率)和平均精度(mean Average Precision, mAP)[22]来评价模型的性能的好坏。本文也使用这2种指标来对本文提出的模型进行验证。
每个检索图片的平均精度(AP)可表示为:
(6)
其中,n指的是测试集的样本总数,Ng为标注的数量,P(k)是第k个匹配结果处的精度,g(k)是指示器,如果第k个匹配结果是正确的,则其值为1,否则为0。
上述的AP可以评判算法在某个类别上的效果好坏,而对所有的类别计算AP的平均值就可以得到mAP:
(7)
其中,Q是查询集的样本数。由于mAP评估指标同时考虑了算法的精准率与召回率,所以是一种比较全面的评估方法。
评估指标rank-k表示对于所有的待检测车辆的图像,将匹配图像库中的图像依次按照相似度排序,看排序结果的前k张图像是否有检索正确的,计算公式为:
(8)
其中,m表示待检索车辆图像总数,对第i张图像,其检索结果按照相似度排序后,前k个图片中有与被检测图片同id时si,k=1,否则si,k=0,通过计算rank-k值可以绘制累计匹配(Cumulative Matching Characteristics, CMC)曲线[23],该曲线可以比较好地反映模型的性能。
2.2 实验参数设置
本文提出的模型实现与训练使用Pytorch深度学习编程框架,训练的硬件使用带有双Nvidia Tesla V100显卡,CPU是Intel Xeon E5-2640的高性能主机。每个batch的图片数量是32,每个batch中有8个id,每个id的车辆会有4张照片被采样,共计迭代1000个epoch。输入图片的大小是384×384,模型的骨干网络是ResNet50,为了能够提取更多的细节,ResNet50最后一层conv5_1的步长被设置为1。初始的学习率被设置为4×10-4,在经过500个epoch后,模型的损失下降不再明显,学习率每隔100个epoch下降为原来的0.1倍。模型训练过程中使用了随机翻转、随机擦除、随机裁剪等数据增强策略来提升模型的鲁棒性。
2.3 实验结果与分析
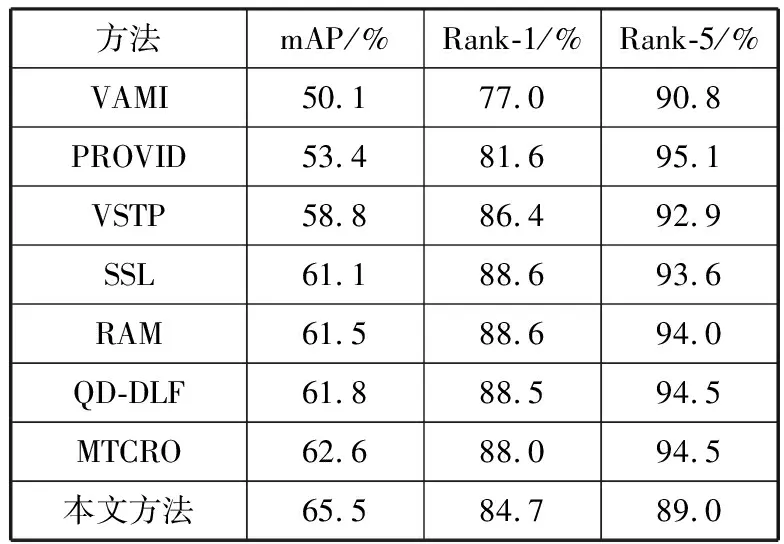
表1 不同车辆重识别算法结果对比
本文提出的方法与近年来精度较高的算法对比见表1。VAMI[24]模型为了解决车辆在不同的角度拍摄造成重识别精度低的问题,提出了一种多角度学习的方法。首先将车辆的单角度图片输入到网络提取特征,然后利用跨视图排序损失训练其他视图特征,从而得到该车其他视图的特征。使用网络生成的特征与实际摄像头拍摄的图像再提取出的特征有很大不同,所以最终的效果一般。PROVID[25]与VSTP[26]都是多模态检索模型,他们将车辆的图片以及图片相关的时间与空间信息编码输入模型,这样做可以在一定程度上提升车辆检索的精度,未能将时空特征与图像特征正确融合导致了这2个模型未能达到较好的效果。SSL[27]模型的主要创新点是使用生成对抗网络来生成车辆重识别样本,从而提升车辆重识别训练集的数量,而且SSL模型的训练过程使用了半监督的学习方法。SSL模型使用了对抗生成网络训练增加了算法的时间复杂度且准确率提升不高。RAM[28]模型是一种区域感知的算法,用4个分支构成整个车辆重识别的模型,4个分支过分关注局部细节特征,对车辆整体特征的感知能力过低。QD-DLF[29]提取车辆图像在水平、垂直、对角线和反对角线方向的特征,最后这几个方法的特征被进行归一化并且连接到一起。该方法仅仅考虑这4个方法的特征,而没有考虑局部等细节特征。MTCRO[30]提出了一种多任务学习方法并且构建了一种新的排序方法。本文提出的模型不仅提取了车辆的全局特征,还提取了车辆的局部细粒度特征,并且使用非局部注意力使得局部的特征能够捕获全局的特征。实验结果表明,本文模型在VeRI-776数据集中比其他所有模型的精度都高。最终本文中提出的模型的可视化结果见图5。图5中第1列为待识别图片,第2列到第11列是按照相似度排序从高到低排序的10张图片。第1行和第2行都是10个结果均匹配正确。第3行中最后1张图片匹配错误,第4行中第7张图片匹配错误。

图5 本文提出的车辆重识别模型推理结果可视化
表2是本文提出的算法在VeRI-776数据集上的剥离实验结果。No-atten方法表明是去掉了非局部注意力模块后的实验结果,从表2可以看出mAP降低了1.29个百分点,这表明了非局部注意力的有效性。No-hori和No-vert分别表示将图4中的5个分支中的第1个分支和第3个分支分别剥离掉,分别剥离这2个分支后,mAP相对于本文方法分别下降了1.57个百分点和3.51个百分点,这表明了2个局部特征分支是有效的。

表2 剥离实验结果对比
3 结束语
本文提出了一种基于非局部注意力的车辆重识别算法,使得重识别的精度在一定程度上得到提升。使用ResNet50提取车辆全局特征,非局部注意力提取车辆图像的全局语义特征,通道分组从不同的角度提取图像的语义特征,局部分支与全局分支分别提取车辆全局特征和局部细粒度特征,有效地提高了车辆重识别模型的车辆检索精度。
