融合语义增强的中文短文本分类方法研究*
2022-04-07潘袁湘牛新征
潘袁湘 黄 林 牛新征
(1.电子科技大学信息与软件工程学院 成都 610000)(2.国网四川省电力公司信息通信公司 成都 610015)(3.电子科技大学计算机科学与工程学院 成都 610000)
1 引言
网络上的微博等短文本具有内容短,语义依赖性强的特点,如何对短文本进行高效准确的分类是自然语言处理领域的学者们探索的热点。
中文短文本分类的本质是提取已知类型标签的短文本特征,预测未知的待分类文本的归属类型。目前,短文本分类的主要方法有朴素贝叶斯[1]、支持向量机[2~3]以及神经网络[4~5]等。本文采用前沿的深度神经网络来研究中文短文本分类。
相较于传统的语言模型,基于神经网络的语言模型具有有效共享上下文语义信息的特点,模型泛化能力强。例如word2vec[6]、glove[7]等模型可以学习到良好的向量表示作为特征,以便用于后续的分类任务。但word2vec 无法使一词多义的问题得以解决。基于该现状,Peters[8]等提出了一种高级新型语言模型(Embeddings from Language Models,ELMo),该模型生成的词向量既可以对词汇语法与语义进行表征,又可以随语境进行多义词动态变换。2018 年12 月,Google[9]提出的Bert(Bidirectional Encoder Representations from Transformers)语言模型可以捕捉更深层次的语义信息,其突破了多项自然语言处理任务,有力地推动了自然语言模型的发展。
人工神经网络分类法因其学习能力强的优点,在实际分类任务中得以广泛应用。针对循环神经网络(Recurrent Neural Network,RNN)存在“梯度消失”或“梯度爆炸”[10]的问题,Hochreiter[11]等认为长短期记忆网络(Long Short-Term Memory,LSTM),通过引入“门控”机制改善了上述问题。Cho K[12]等改进了LSTM 的结构,形成“双门控”的门控循环单元(Gated Recurrent Unit,GRU)。Wang[13]等提出构建双向LSTM 网络模型提取文本序列化的上下文信息,并引入注意力机制强化重要的文本特征表达,使短文本分类性能得到进一步提升。
论文从改善传统词向量语义表达问题和从特征稀疏的短文本中提取重要特征的问题着手,提出融合语义增强的短文本分类方法。该方法使用预训练语言模型Bert进行语义向量增强,同时在双向GRU 的基础上引入多头注意力机制获取短文本内部依赖关系。经验证,本文提出的方法改善了短文本语义表达的问题,使短文本的分类精确率得到提升。
2 相关工作
2.1 语言模型Bert
Bert 语言模型是由多个Transformer 的Encoder部分进行叠加组合而成的高级新型网络。Transformer 的Encoder 能够一次性双向读取完整的文本序列信息。这个特征使得模型能够基于单词的粒度进行上下文语义学习。在训练语言模型时,Bert为了克服一种固有地限制语境学习的方向性的挑战,创新性提出Masked LM[9]和Next Sentence Prediction[9]的无监督预测任务来预训练Bert。
2.2 双向门控循环单元Bi-GRU
双向门控循环单元网络(Bidirectional Gated Recurrent Unit,Bi-GRU)[14]是GRU 的一种双向结构,相较于GRU,Bi-GRU 结构能更好地捕捉双向语义依赖。它当前时间步的隐状态信息由前后两个时间步共同决定。隐状态输出的公式如式(1)所示:

其中,表示前向传播隐状态,表示后向传播隐状态。
2.3 多头注意力机制
不同于普通注意力机制,Google 团队提出了多头注意力机制[15](MultiHead Attention)。
多头注意力机制通过“复制”和“拆分”自注意力机制的权重矩阵,形成新的加权计算模式,以便学习到多个不同子空间的语义信息。公式如下所示:

3 融合语义增强的中文短文本分类方法
为解决中文短文本特征稀疏和上下文依赖性强的问题,以有效提高短文本分类准确率,论文提出了融合语义增强的中文短文本分类模型。模型结构由语义向量表示层、特征抽取层和输出层组成。首先将预处理后的短文本通过Bert 预训练语言模型生成的语义向量。然后输入到Bi-GRU 神经网络中并结合多头注意力机制提取文本全局特征。最后进行多分类输出。
3.1 语义向量表示层
语义向量表示层是文本输入的第一层,采用预训练语言模型Bert进行短文本语义向量表示。
以“股票的突破形态股票”为例。输入表示流程图如图1 所示。首先按照“[CLS]股票的突破
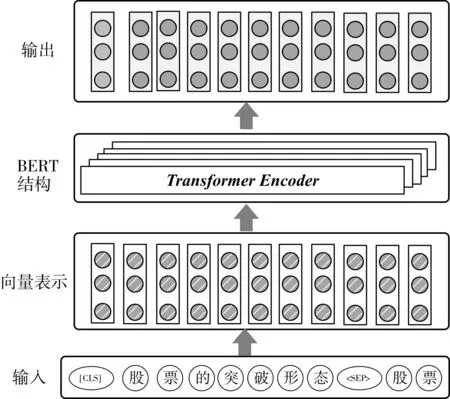
图1 输入表示层流程图
3.2 融合语义增强的特征抽取层
特征抽取层将Bert 预训练语言模型生成的语义向量输送到Bi-GRU 网络中,同时结合多头注意力机制提取文本全局特征。特征抽取层的结构示意图如图2所示。
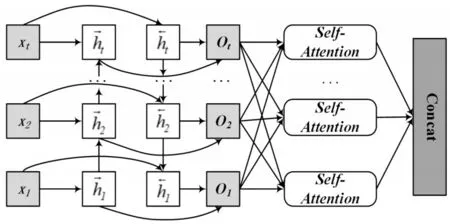
图2 特征提取结构示意图
Bi-GRU网络结构的“双门”可以控制时序信息的记忆程度,不但使其保留全局时序的最优特征,而且又可以充分提取当前时间步的前后时间步的隐状态信息。因此本文构建了Bi-GRU 网络以充分提取短文本上下文语义信息。
输入单元为Bert 预训练语言模型生成的语义向量集合,即X={x1,x2,…xi,…,xt},其中,xi(i=1,2,…,t)表示字向量。隐藏层包含前后两个方向的传播层。本文使用h→t表示前向传播隐状态,h←t表示后向传播隐状态。
论文采用数量大小为h 的隐藏单元构建网络。在进行网络前向推断过程中,已知小批量输入为xt,上一个时间步隐状态为ht-1。Bi-GRU 网络的内部子结构GRU 在时间步t时,通过式(4)和式(5)计算重置门和更新门的状态。
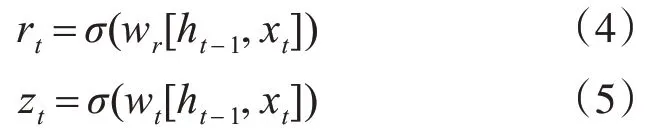
其中,wr和wt为权重参数,σ为激活函数,其取值范围在0~1之间。
候选隐状态的作用是辅助控制当前时间步t的隐状态的计算,计算公式如式(6)所示:
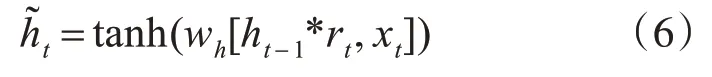
其中,wh为权重参数,tanh 为激活函数,其取值范围在-1~1之间。
至此,通过式(7)可计算出前向单元的隐状态输出。
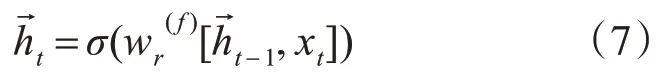
通过式(8)可计算出后向单元的隐状态输出。
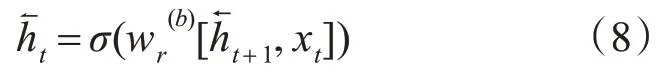
综上,当前时间步t 的前后隐状态输出拼接组成了综合隐状态输出,其公式如式(9)所示:

由Bi-GRU 网络中进一步得到融合语义的向量集合O={o1,o2,…,oi,…,ot},其中,oi(i=1,2,…,t)表示语义特征向量。此时,论文采用多头注意力机制在获取强化语义的同时并进行权重调整。
多头注意力机制是由N 个自注意力机制堆叠而成,如图3 所示。通过“复制”和“拆分”自注意力机制的权重矩阵,构成了多头注意力机制的计算模式,如式(10)所示,这使得学习到多个不同子空间的语义信息。

图3 MultiHead-Attention更新权重计算
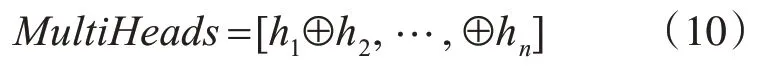
自注意力机制堆叠复制了8 次,形成了8 头自注意力机制。通过平分这8 个Attention 形成了词向量,然后通过矩阵交互计算,从而得到了多头注意力的权值。
3.3 输出层
输出层对每个样本所属的标签进行概率统计预测。在分类问题中,输出层常用Softmax 层映射为条件概率。将输入的样本划分为类别j的概率公式如式(11)所示:
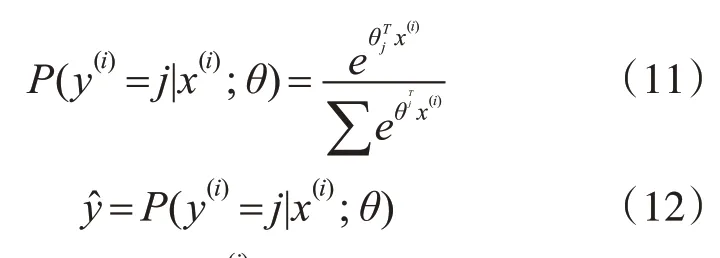
x(i)表示训练样本,y(i)∈{1,2,…,k}表示标签,ŷ则表示其预测值。
4 实验
4.1 数据集
实验数据来自今日头条公开新闻数据集。数据集由38 万余篇中文新闻文本标题组成,其中包含房产、军事、股票等总共15 个主题类别。本文选取其中的子集进行实验,每个类别选取5000 条数据,按照8∶1∶1 的比例进行训练集、测试集和验证集的划分。
4.2 实验结果与分析
实验采用精确率(Precision,P)、召回率(Recall,R)和F1 值(F1-Measure,F)作为标准的评价指标[16]。实验环境为Linux Ubuntu16.04系统,显卡型号GTX1070,实验中涉及到的算法均采用Python3.6 编写以及Tensorflow1.12 深度学习框架实现。
本实验将目前在短文本分类任务中优秀的算法[9,14]作为基准算法,与本论文算法在相同数据集上进行两组对比实验。
1)第一组实验
为验证Bert 预训练语言模型生成的语义向量比Word2Vec 的表征能力强,以使得分类准确率更高。将Word2Vec-GRU 及其改进模型与Bert-BiGRU模型进行第一组分类实验。
本组实验相关参数设置如下。
模型训练的超参数包括:学习率lr 为0.001,隐层单元数hidden_units 为128,批处理量batch_size为32,网络节点丢弃率dropout 为0.25。具体实验结果记录表如表1所示。
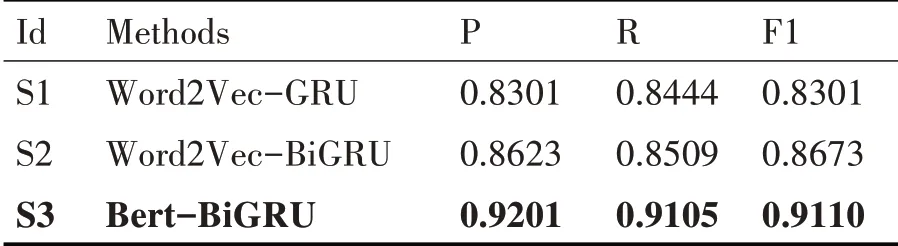
表1 实验结果记录表
2)第二组实验
为验证本论文提出的模型比主流的引入传统向量表示或者引入注意力机制的神经网络分类模型的准确率高,本论文进行第二组分类实验。
本组实验的模型超参数设置为学习率lr 为0.0005,隐层单元数hidden_units 为128,批处理量batch_size为32,网络节点丢弃率dropout为0.1。具体实验结果记录表如表2所示。
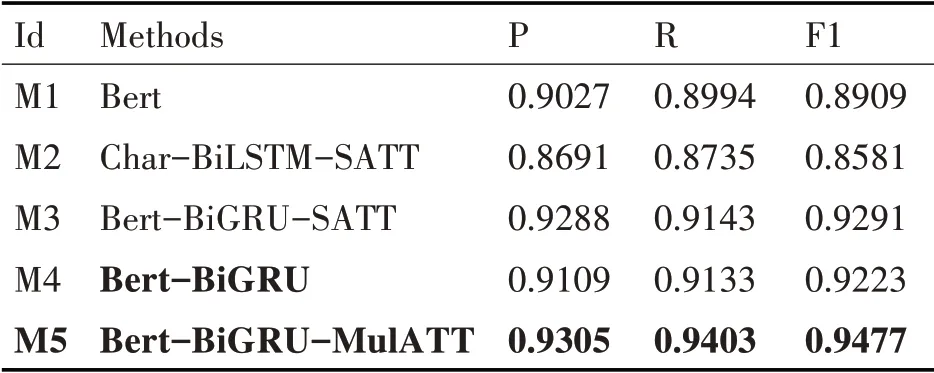
表2 实验结果记录表
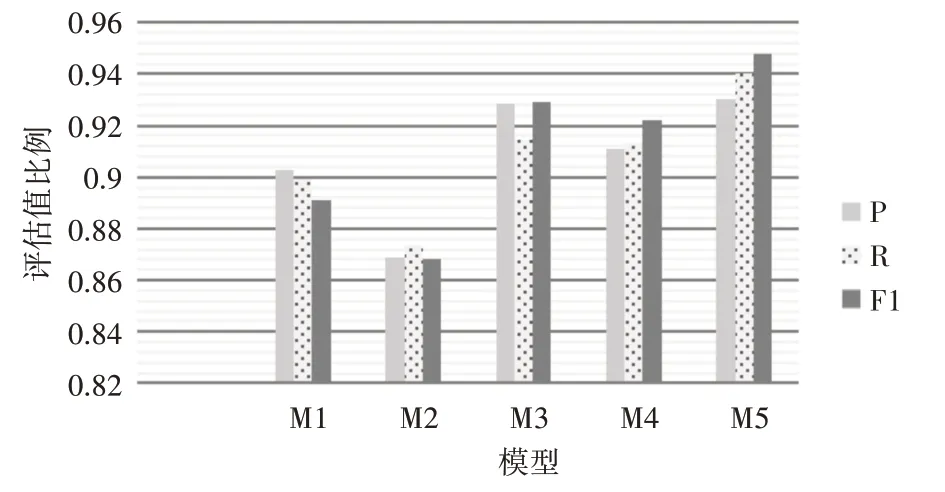
图4 实验二分类效果对比图
本论文进行了两组对比实验,具体分析如下。
由实验一的结果记录表可知,通过对比引入Word2Vec 的S1、S2 两个方法和引入Bert 的S3 方法的实验结果,发现S3方法相较S2方法的精确率、召回率和F1 值分别提升了5.78%、5.96%、4.37%。说明了加入Bert 生成的向量表示法能表达丰富的上下文语义信息,有利于后续分类准确率的提高。
由实验二的结果记录表可知,通过对比M1、M2 和M3 方法,发现Bert无论在语义向量表征能力上还是分类准确率上均表现优越。通过对比M3和M5 方法的结果,发现引入多头注意力机制比自注意力机制的分类效果更显著。
通过对比实验一分类准确率最高的S3(M4)与本论文提出M5方法的实验结果发现,模型精确率、召回率和F1 值分别提升了1.96%、2.7%、2.54%,证明本论文提出的方法在Bert-BiGRU 的基础上,利用多头注意力机制能充分捕捉到局部关键特征,进一步增强短文本上下文语境。综上两组实验可以证明本论文提出的融合语义增强的短文本分类方法的优越性。
5 结语
针对中文短文本具有内容特征稀疏,上下文依赖程度强的问题,结合目前主流的基于词向量的双向循环神经网络的优点,提出融合语义增强的中文短文本分类方法进一步改善分类效果。该方法引入Bert生成融合字、文本以及位置向量的语义向量作为训练文本的词表征。采用Bi-GRU 网络提取上下文关系特征,并通过多头注意力机制调整权值强化重要特征表达。实验结果表明该方法应用于短文本分类问题的准确性和优越性。
