改进YOLOv3 的地面车辆小目标检测*
2022-04-07蒋川虎张东旭
蒋川虎 张东旭 张 超
(北京航天时代光电科技有限公司 北京 100094)
1 引言
随着遥感图像的分辨率不断提高,高分辨率的遥感图像在国民经济领域的应用越来越广泛,而将遥感图像应用于公共交通安全、城市智能交通规划等领域具有很大的研究价值,对遥感图像进行目标检测识别出其中的车辆则是必不可少的一环。
近年来,以卷积神经网络为代表的深度学习在大规模视频/图像目标检测识别方面取得了巨大的成功[1],在遥感图像目标检测中也得到了广泛的应用。然而由于原始大视场遥感图像中存在着大量的车辆小目标,这些小目标通常尺寸小于32*32[2],检测器能够提取到的特征较少,因此难以被检测识别。
目前,基于深度学习的图像目标检测识别主要分为两大类:基于one stage 的检测方法和基于two-stage 检测方法。基于two-stage 的检测方法,例如Fast RCNN[3]、Faster RCNN[4],首先通过Region Proposal 给出可能存在目标的候选区域,然后基于CNN 对候选区域进行识别;基于one-stag的检测方法,例如YOLO[5]、YOLO9000[6]、SSD[7]、YOLOv3[8],将候选框选择和目标识别判别进行统一化处理,使用卷积神经网络对图像进行一次推理直接得到图像中所有物体的位置、所属类别及相应的置信概率,能够极大提升目标检测速度。
鉴于one-stage的检测方法,特别是YOLO系列模型[5~6,8],在检测速度方面独特的优势,本文将基于YOLO 系列模型进行改进,并将其用于遥感图像中车辆小目标的检测识别。
2 YOLO 系列模型
2.1 YOLO基础模型
YOLO 模型将目标检测统一到一个神经网络中,全面推理整幅图像和图像中的所有目标,能够在保持较高精度的同时,保证检测的实时性。
YOLO 模型将图像划分成S×S的网格,如果某目标中心落入一个网格单元中,则该网格单元负责检测该目标。每个网格单元预测B 个bounding box,每个bounding box 包含5 个预测x,y,w,h 和置信度分数c,其中置信度分数反映了模型对边框包含目标的信心,以及模型认为预测的边框的准确程度。另外,每个网格单元还需要预测一组条件类别概率(共C 个),表示在网格单元中包含目标的条件下,目标为某一类别的概率,C 表示目标的类别数。所以每一个网格单元推理最终得到一个B×5+C大小的张量,整幅图像经过YOLO 模型推理后,将被编码为大小为S×S×(B×5+C)的张量。
YOLO 网络模型设计了24 个卷积层和2 个全连接层,通过交替1×1 卷积层减少前序层的特征空间,除最后一层使用线性激活函数外,所有层都使用leaky relu 作为激活函数,网络结构如图1[5]所示。通过优化多部分损失函数进行网络训练,YOLO 的损失函数如式(1)所示。其中,表示目标是否在第i个网格单元中出现,表示第i个网格单元的第j个边界框预测器负责该预测。此外,为了防止模型早期发散,分别设置λcoord和λnoobj参数增加边框预测损失和减少不包含目标的边框的置信度预测损失。
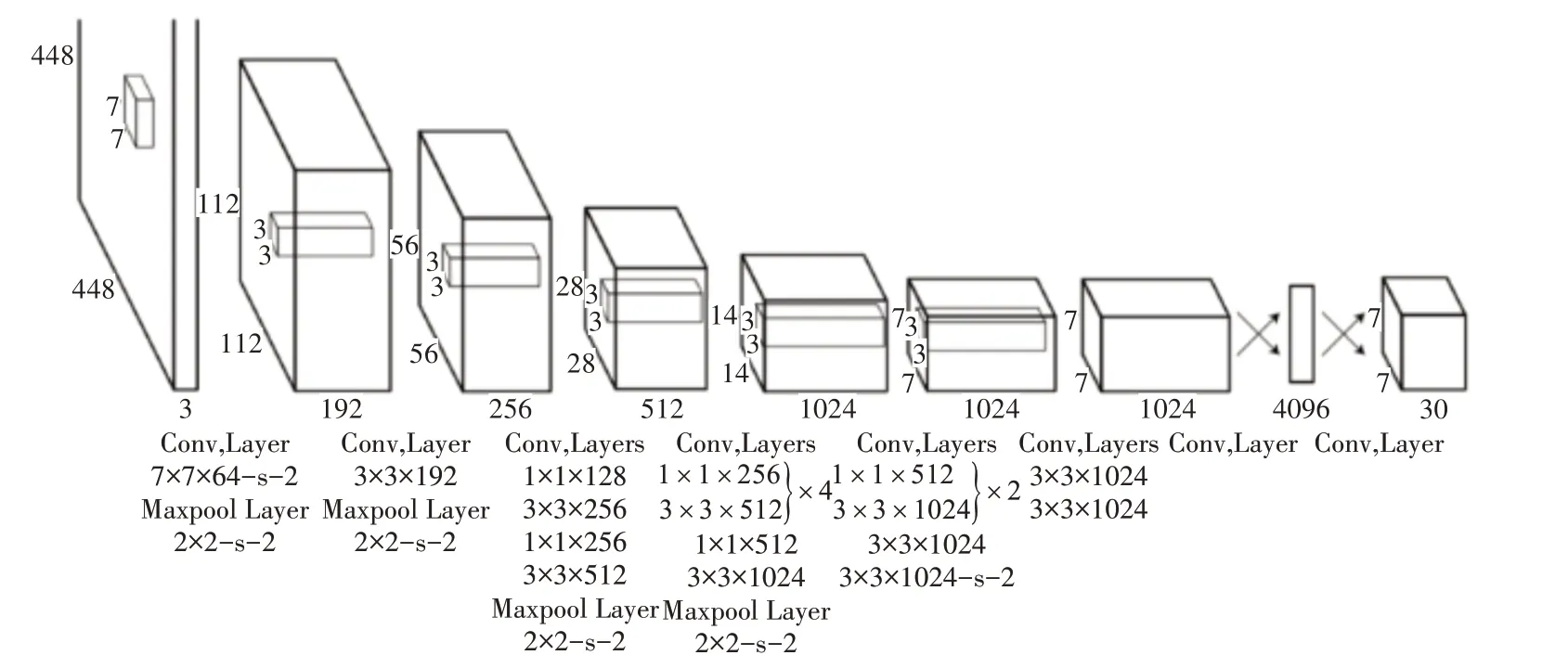
图1 YOLO模型的网络结构
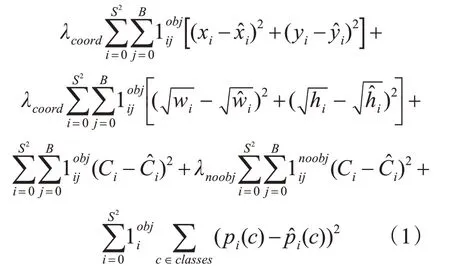
最后,在模型推理阶段,对检测到的S×S×B个bounding box 应用非极大值抑制法,得到最终的检测结果。
2.2 YOLO改进模型
考虑到YOLO 模型定位不准确和召回率低的缺点,Redmon J在YOLO 模型的基础上提出了两个改进版本,即YOLOv2和YOLOv3。
相比于YOLO 基础模型,YOLOv2 模型最大的改变是将躯干网络改为darknet-19,模型完整网络结构如图2所示。
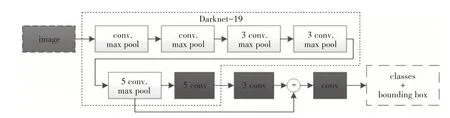
图2 YOLOv2模型完整网络结构
由于YOLOv2 以darknet-19 为特征提取网络,卷积操作减少,加快了检测速度。此外,YOLOv2还加入batch normalization,引入anchor box、多尺度训练等多种手段提升了模型的检测精度和模型的鲁棒性。
YOLOv3 在YOLOv2 的基础上进一步融合一些好的技巧到YOLO 模型中,在保持速度优势的前提下能够提升预测精度,尤其是提升了小目标的检测识别能力。相对于YOLO 之前的版本,YOLOv3 的主要改进有:1)借鉴ResNet 跳远连接的思想,将特征提取网络改为darknet-53;2)使用步长为2 的卷积代替之前版本中的池化层进行下采样;3)利用多尺度特征进行检测;4)在分类层使用Logistics 代替softmax。YOLOv3 模型的完整网络结构如图3 所示。
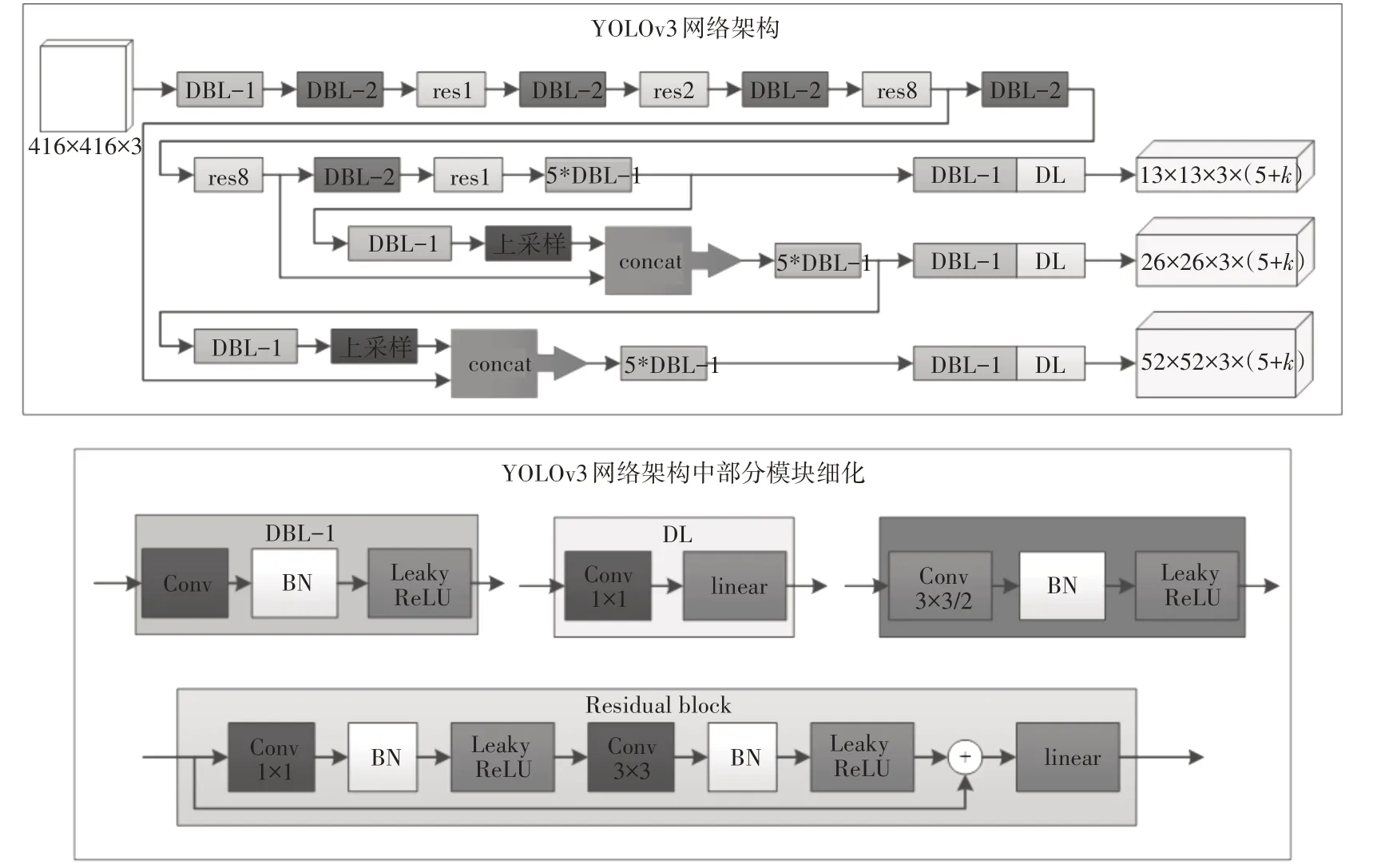
图3 YOLOv3 模型完整网络结构
2.3 改进YOLOv3
YOLOv3 在多个尺度上进行特征图融合的目的是通过高层和低层特征的融合增强小目标特征,从而提升网络的小目标检测能力。从图3 可以看出,多尺度特征图融合过程为:1)使用步长为2 的卷积操作对低层特征图进行下采样;2)通过一系列的卷积操作得到更高层特征图;3)将低层特征图与高层特征图上采样得到的特征图进行融合。虽然通过融合多个尺度上的特征有利于小目标的识别,但是在融合过程中,使用卷积步长为2 的卷积进行下采样容易丢失很多相邻像素点的特征,随着网络的加深,小目标特征丢失越来越严重;此外,对高层特征图进行上采样又容易引入很多噪声。因此,得到的融合特征图对小目标特征的增强不够明显。
针对以上问题,本文将进行以下改进:1)不再进行多尺度特征图的融合,独立地输出各个尺度上的特征图;2)在独立输出的尺度上引入Fisher Xu等[9]提出的dilation 卷积,增大卷积核的覆盖范围,增大网络的感受野;3)在独立输出的尺度上结合Szegedy 提出的Inception-ResNet 结构[10]增大特征提取网络的宽度,提取更好的图像特征。dilation卷积也称为空洞卷积,最初是用来解决pixel-wise输出模型的一种卷积方式,它通过改变卷积核内部间隔来扩大卷积核的感受野,如图4 所示,其中d表示卷积核内部空洞的间隔。图4(a)表示3×3、d=1 的空洞卷积,即常规的卷积核,感受野为3×3。图4(b)表示3×3、d=2 的空洞卷积,卷积核的感受野为7×7。图4(c)表示3×3、d=3 的空洞卷积,卷积核的感受野为11×11。空洞卷积的好处是在不做pooling 或大stride 卷积损失信息的情况下,增大感受野,让每个卷积输出都包含较大范围的信息。
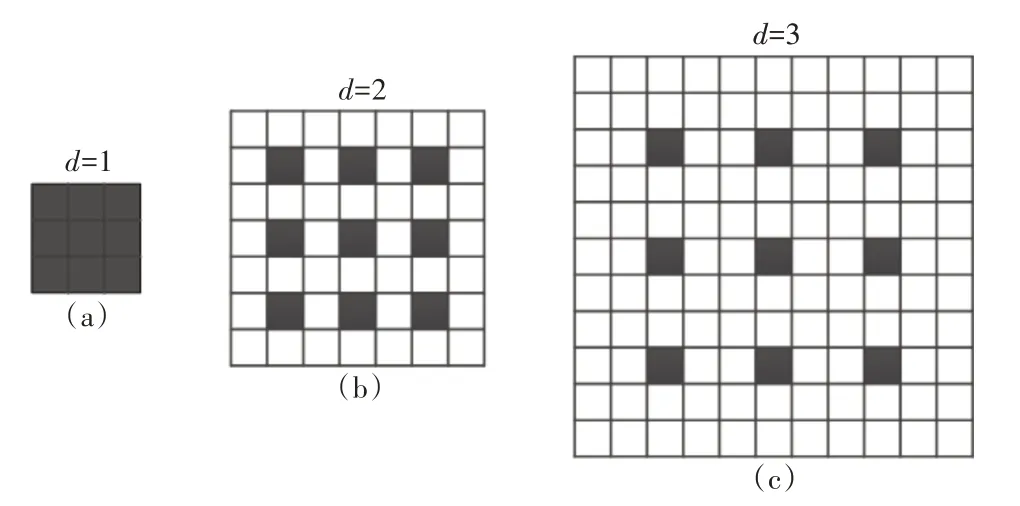
图4 空洞卷积
Inception[11~13]模块基于1×1、3×3、5×5 等不同的卷积运算与池化操作可以获得输入图像的不同信息的理论,对输入的特征图并行地执行多种卷积,并结合所有结果以获得更好的图像特征。ResNet[14]取得巨大成功后,GoogleNet 团队尝试将Residual Learning 的思想应用到Inception 网络中,设计了Inception-ResNet模块,实验结果表明,这种设计确实能够带来性能上的提升。
本文参考Inception-ResNet 结构,在YOLOv3模型每个尺度上的输出引入空洞卷积,设计了空洞Inception-ResNet 模块,后文简称DIRB,如图5 所示。

图5 空洞Inception-ResNet模块
DIRB 将每个尺度上的输出改为多分支结构,每个DIRB的各个分支由不同大小的普通卷积加上空洞卷积构成,然后将多个分支的输出concat到一起共同作用。Inception v2为了解决表征性瓶颈,将卷积核横向扩展,使得网络变得更宽,本文也遵循了这一设计。修改YOLOv3 模型后得到的新模型结构如图6 所示,新的模型仍然沿用YOLO 模型中的损失函数。
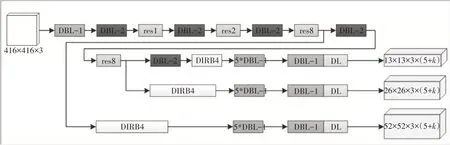
图6 YOLOv3改进后的模型结构
3 仿真验证分析
本文实验在装有Ubuntu 18.04 LTS,搭配Nvidia RTX 2080Ti显卡的计算机上进行,使用的深度学习框架为Tensorflow[15]。
本文基于VEDAI[16]航拍图像对本文模型进行训练和验证。VEDAI 数据集中的图像是从原始大视场图像中分割出来的,分辨率为1024×1024,包含了boat、airplane、各类车辆以及其他混淆对象,数据统计如表1 所示。数据集中还包括了对分辨率为1024×1024 的图像下采样得到的分辨率为512×512的图像。

表1 VEDAI数据集中各类目标的数据统计
本文使用的是1024×1024 的大分辨率图像数据集,将car、vans、pickup 这三种目标归为同一类别,类标号为car,其他类别标号保持不变。从原始数据集中随机选择80%的图像作为训练集,剩余的20%作为测试集。通过旋转图像、增加对比度、调整颜色等方法对数据集进行增强。
对YOLOv3模型和改进YOLOv3模型分别进行训练,训练阶段初始学习率设置为0.001,训练的批次大小设置为32,衰减系数为0.0005,最大迭代次数为50000 次。在训练迭代10000 次后调整为0.01,迭代20000 次后调整为0.001,迭代30000 次后调整为0.0001。
为了对比YOLOv3和本文改进YOLOv3模型的小目标检测能力,用同一测试集(共计200 幅图像,1059 个目标,测试集各类目标数据统计如表2 所示)分别对两个网络进行测试,并分别计算每一类目标的准确率和召回率,结果见表3 和表4。召回率R和检测准确率P的计算公式分别为

表2 测试集中各类目标的数据统计
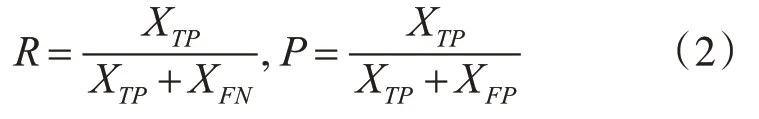
其中,XTP表示正确检测出来的目标,XFN表示没有被检测出来的目标,XFP表示被错误检测出的目标。
对比表3 和表4,相对于原模型,本文改进YOLOv3 模型对车辆小目标(Car)检测的准确率提升了1.07%,召回率提升了6.02%,在整个测试集上的检测准确率提升了1.59%,召回率提升了5.34%。因此,本文改进模型能够有效地提升小目标准确率和召回率,有效解决了地面车辆小目标的漏检问题。

表3 YOLOv3测试结果
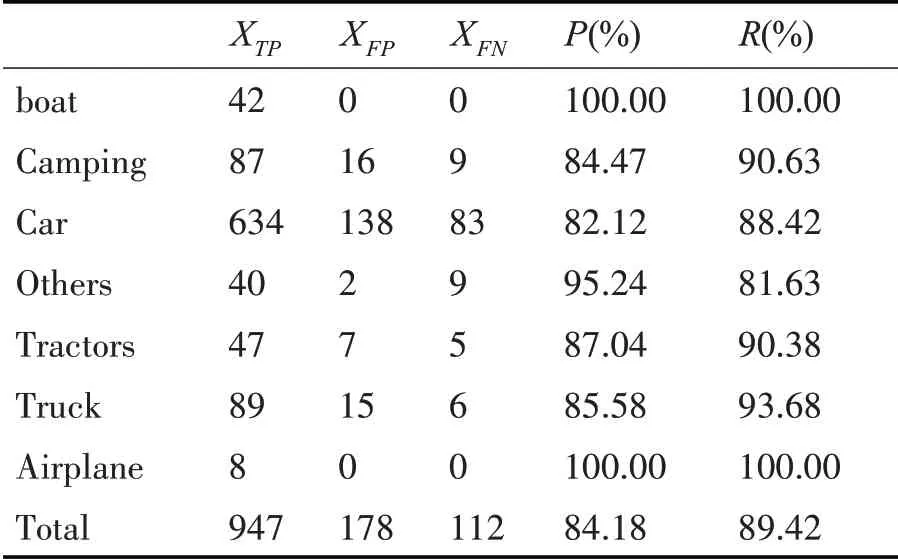
表4 改进YOLOv3测试结果
图7对比了YOLOv3模型和本文模型同时对小目标进行检测的效果,可以发现,图7(b)中YOLOv3 模型进行检测时,左下角的一辆卡车没有被检出,而图7(a)中本文模型没有出现目标漏检的情况。因此,相比于YOLOv3,本文模型能够在保持检测准确率的同时,在一定程度上在提升小目标的检出率。

图7 小目标检测结果对比
4 结语
本文首先分析了遥感图像目标检测的困难和要求,指出了当前算法应用时产生的小目标虚警、漏检和误检问题,并综述了当前的图像目标检测方法。其次,分析了能够在保持较高精度的同时,保证实时性的YOLO 系列模型,基于YOLOv3 模型进行针对性的改进,将多尺度融合输出改为多尺度独立输出,并在每个尺度上引入Dialition 卷积和Inception-ResNet 结构。最后,在VEDAI 数据集上进行模型的训练和验证,实验结果表明,本文模型能够提升小目标检测时的召回率和准确率。
