基于语义分割实现的SAR图像舰船目标检测
2022-04-07句彦伟
陈 冬, 句彦伟
(南京电子技术研究所, 江苏 南京 210013)
0 引 言
合成孔径雷达(synthetic aperture radar, SAR)属于微波遥感方式中的一种,具有全天时、全天候工作的特点,能够捕获目标散射特性,在军事上、民事上均具有非常广泛的运用。而传统的SAR图像处理流程包括:相干斑抑制、目标检测、目标分割以及特征提取和识别等。
目标检测是其中一个极其重要的环节,其包含变化检测与特定目标检测。舰船目标检测即是其中一类特定的检测任务,军事上可以探查军舰情况,民事上可以用于航海监测等。传统的舰船目标检测主要有:恒虚警率法(constant false alarm rate, CFAR)、尾迹检测法、模板匹配法等。
深度学习在自然图像上取得巨大成功的同时带动了SAR领域中的智能解译。当前基于深度学习实现的SAR图像相干斑抑制、目标检测与目标识别等方法层出不穷,其中又涉及小样本学习、生成对抗网络等方法。而针对检测问题,当前诸多方法均是自然图像领域算法的迁移,对SAR图像中小目标检测问题做出了模型调整,其中很大一部分缺少对SAR图像本身特点的考虑。
深度学习的检测方法可分为双阶段检测和单阶段检测,其各具非常鲜明的特点。双阶段以区域卷积神经网络(regions with convolutional neural network, R-CNN)系列为主,具有非常高的检测精度和召回率,适用于复杂和实时性要求低的场景中。Faster R-CNN更是实现了双阶段方法的端到端训练,并取得了非常好的效果。在此基础之上,Cascade R-CNN与Mask R-CNN被提出,得到了广泛使用。2017年Li等人首先提出了SSDD数据集并测试了Faster R-CNN在该数据集上的性能,之后其他改进及优化的双阶段模型不断被提出。
相较于双阶段的大量候选框产生的问题,以单次多盒检测(single shot multibox detector, SSD)系列和“你只看一次”(you only look once, YOLO)系列为主的单阶段检测具有非常高的检测速度。抛弃候选框产生过程带来好处的同时在精度上却有所下降,使得单阶段方法更加适用于相对简单以及实时性要求比较高的场景。YOLOv4方法更是融合多种方法优点于一体,在实时性以及效果上取得了一个较好的平衡。
由于双阶段和单阶段检测中存在的锚框问题成为了实时性的又一大桎梏,2019年起诸多无锚框的方法开始兴起。基于无锚框的方法可以舍弃锚框的概念,在实时性上进一步提高,并逐渐设计出新的解码过程。CenterNet即是先寻找目标的中心点再基于中心点进行边框的回归。而Nicolas更是将Transformer引入检测中,提出了名为DETR的检测网络,对CNN提取出的特征和相应的位置编码进行处理,通过询问式的序列输入进行解码。
以上如此复杂的检测解码过程并不适用于SAR图像舰船目标检测。深度学习目标检测的概念是定位与分类一体化,其对应于雷达检测识别一体化。而当前已公布数据集SSDD、SAR-Ship-Dataset以及HRSID均不具备识别的条件,使得研究方法更加专注于定位问题。此外,多数舰船目标图像中不存在复杂背景,只是海面,因此图像中大部分是“黑色区域”。此时锚框的引入必然造成大量的算力冗余,耗费资源且没有明显的收益。如何进行高效的解码成为了当前SAR图像智能检测的一大问题。
本文重新思考已有检测方法并在其基础上,针对SAR图像本身特点,提出使用语义分割来实现检测、分割一体化。实验结果证明,基于语义分割实现的SAR图像舰船检测方法具有更好的性能。
本文的主要创新点如下:
(1) 提出了通过语义分割的方式实现SAR图像舰船目标检测、分割一体化,将检测问题转化为分割问题,避免了复杂的检测网络解码过程。
(2) 基于语义分割网络的编解码形式提出了UNet-S的网络结构,能够有效地提取特征和实现目标的检测与分割。
(3) 针对背景与目标样本不均衡问题,引入了Dice Loss损失,结合交叉熵损失构建本文的损失函数,实验结果证明效果提升显著。
1 方法介绍
1.1 语义分割与SAR图像舰船目标检测
1.1.1 语义分割
在计算机视觉(computer vision, CV)中,语义分割是一个非常重要的领域。图像分割通常可以表述为具有语义标签的像素分类问题(语义分割)或单个对象的分割问题(实例分割)。语义分割的结果通常是逐像素分类的类别(如人、车等),其在二维视觉和三维视觉中均具有极其重要的运用,并广泛运用于自动驾驶、医学图像诊断、人机交互、增强现实等领域中。
随着深度学习的快速发展,语义分割也取得了非常大的进步。全卷积神经网络(fully convolutional neural network, FCN)采用常见的特征提取网络如VGG作为编码器,并采用反卷积层实现上采样恢复分辨率作为解码器,首次实现了语义分割端到端训练。在医学图像分割领域中取得巨大成功的UNet网络结构是当前主要采用结构的代表,其基于FCN拓展和修改而来。其他语义分割的模型稳步增多,如SegNet、DeepLab系列等。但UNet模型仍具有非常好的分割效果,曾在ISBI电子显微镜下细胞图像的分割比赛中,以较大的优势领先,获得了冠军。本文即是基于UNet的网络编解码结构并进行部分改进提出了UNet-S网络来实现SAR图像舰船目标分割与检测。
1.1.2 SAR图像舰船目标检测
SAR图像舰船目标检测不同于CV领域中的目标检测任务。后者通常涉及到定位与分类,而当前前者只涉及到定位问题。此外,诸多深度学习网络用于检测的解码部分极为复杂,涉及到检测框回归、置信度以及分类网络。基于锚框的方法通常还需要进行非极大值抑制(non-maximum suppression, NMS),对检测出的诸多重复框进行筛选。
从某种意义上来说,SAR图像舰船目标检测可不看作是检测问题而认为是二分类问题,关注点在于区分目标和背景。通过当前的神经网络有效地区分背景和目标,即可比较好地实现舰船目标检测问题。在该思路上,本文提出基于语义分割的方法来实现SAR图像舰船目标检测,即逐像素进行舰船目标和背景的分类。该方法能在完成检测的同时,获取舰船目标的分割掩膜,便于后续的识别研究等。
1.2 舰船目标语义分割实现
1.2.1 改进型UNet-S语义分割网络
UNet网络结构本身具有非常好的语义分割效果,而本文此处对UNet网络结构做出了部分修改以适应性地运用于SAR图像中,采用的网络结构如图1所示。

图1 本文UNet-S网络结构Fig.1 The proposed UNet-S network architecture
输入大小统一为800×800×3的形式,而输出对应为800×800×2的大小(其具体的解码过程可参考第1.2.2节)。
UNet网络由一个收缩路径和一个对称扩张路径组成。收缩路径即下采样过程,用于获取上下文信息;而对称扩张路径即上采样过程,融合提取的上下文信息用于精确定位。
本文的模型对UNet中多尺度信息融合的方式进行了保留。整体网络结构同样采用16倍下采样的方式,相比较于原UNet网络,本文UNet-S的设计方案以常见的VGG16网络为特征编码网络。通过该特征提取网络可在训练过程中加载预训练模型,进行固化训练,并在迭代一定次数之后进行微调,能够有效地加快模型收敛速度、提高模型的性能。
解码部分采用双线性上采样来提高分辨率并结合浅层网络中提取的特征来获取丰富的上下文信息,为逐像素预测过程提供更加丰富的空间信息。最后使用1×1大小的卷积进行通道数的调整,使其满足语义分割的类别数。
1.2.2 语义分割解码过程
基于深度学习的检测方法通常会对提取的特征结合空间位置进行解码,将提取的特征转换为检测框、置信度和类别,之后需对重复的检测框进行非极大值抑制等操作。本文采用语义分割的方式,逐像素区分背景和舰船目标,在获得分类结果之后对舰船目标的预测区域进行提取即可实现检测,因此避免了复杂的检测解码过程。
而基于语义分割的解码过程是在目标分类任务上的扩充。此处认为检测是逐像素二分类任务,最终的预测结果为两层800×800大小且经过Softmax激活之后的对应位置概率值。通过该方式即可完成SAR图像舰船目标语义分割任务,再对获取的连通域进行提取,可获得每个连通域的坐标框以及目标大小。
图2为网络预测结果、对应的生成掩膜以及转化为检测的结果。通过该方式实现的舰船目标检测,一方面避免了诸多基于“过冗余”方法实现的检测方法中带来的算力大量消耗、设计锚框等问题;另一方面将检测转化为分割问题,使得舰船目标检测中多尺度特性转化为前景与背景类别不均衡问题,同时能够获取分割之后目标的具体信息,便于之后的识别研究等。
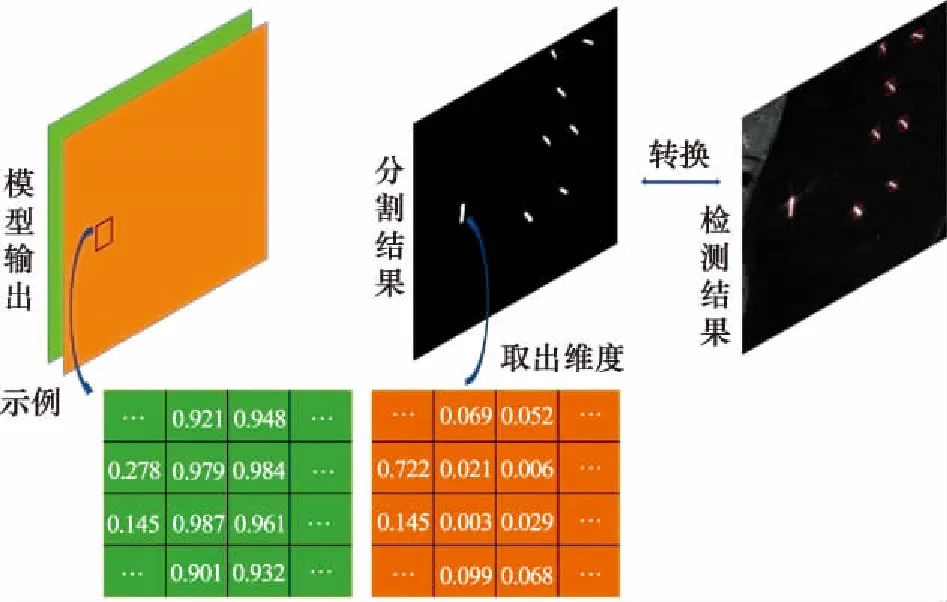
图2 解码实现过程Fig.2 Decoding implementation process
1.2.3 损失函数
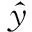
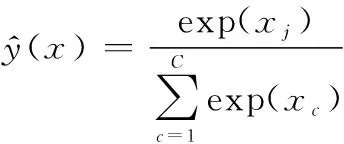
(1)
式中:是总类别数;为第个类别对应的CNN输出结果。此时,像素交叉熵损失为

(2)
最终的分割交叉熵损失为
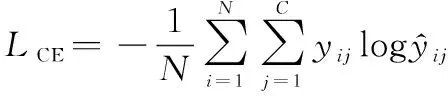
(3)
式中:为像素数。该损失函数形式归根到底是逐像素单独评估交叉熵损失再取均值,即可认为每个像素对于最终模型的贡献是均衡的。但本文存在一个样本不均衡的问题:舰船目标与背景具有很大的失调关系。经统计得出,训练数据中背景与舰船目标出现的频率分别为0996和0004。如何有效地区分背景与目标,避免造成误判尤其重要。
因此,本文在交叉熵损失基础之上采用Dice Loss损失来缓解样本不均衡的情况。Dice Loss损失最早于VNet中使用,用于解决医学图像中前景与背景极其不均衡的问题,后被广泛引用并扩充至其他语义分割任务中。该损失函数采用的思想是直接对指标进行优化而不是通过不同目标权重比来解决不均衡问题,其来源于评价指标Dice系数。不妨设样本和,则
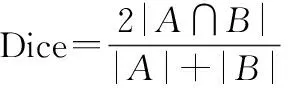
(4)
式中:|∩|表示的是交集个数;||和||分别表示其元素个数。Dice系数是一个集合相似度度量函数,取值范围在0到1之间。在分割评价中,预测结果与标签重合度越高,Dice值越大,而将其引用作为损失函数优化可采用如下形式:
=1-Dice
(5)
本文Dice损失最终形式:
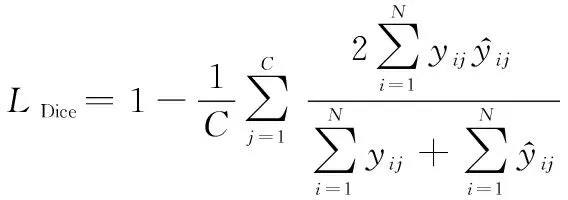
(6)
综上,本文采用的损失函数为
=+
(7)
2 实验验证
本文采用的实验框架是Pytorch深度学习框架,实验计算机硬件配置为GTX 1080Ti,显存为11 G,内存为32 GB。实验过程中,总迭代次数设置为150次。其中,前50次加载预训练模型进行固化训练;后100次对模型进行微调,所有参数均进行更新。
本文使用分割与检测两种评价指标,从多方面对检测以及分割所得的结果进行比较,能够凸显采用方法的优越性。此外,为了与基于深度学习的检测方法相比较,本文选用单阶段检测YOLOv4方法以及双阶段检测算法Faster R-CNN(ResNet50)作为参照基准。
2.1 实验数据
当前公布且用于深度学习训练的SAR图像舰船目标检测数据并不是很多,典型代表有海军航空大学的SSDD、中国科学院的SAR-Ship-Dataset以及电子科学技术大学的HRSID数据集等。
相比较于其他数据集,HRSID数据集数据量适中,单图像虽较大,但具有比较高的分辨率,且其涵盖多目标、多尺度以及强干扰等情况的舰船目标。此外,该数据集还进行了统一划分,具有一个二阶段检测方法的对照基准,且对舰船目标进行了实例分割的标注。在该数据集基础上,本文对标注结果进行调整,进一步生成语义分割标注结果,用于实验验证。
2.2 评价指标
由于本文通过分割的方式来实现SAR图像舰船目标检测,因此具有分割特性且具有检测特性,可通过两种不同的方式对实验结果进行评价分析。
从语义分割的角度进行分析,本文选取了均交并比(mean intersection over union, MIoU)和平均像素准确率(mean pixel accuracy, MPA)作为评价指标。假设包含背景共有+1个类别,表示类别为的像素被预测为类别为的数目,则就表示TP(true positives),与分别表示为FP(false positives)与FN(false negatives)。则MIoU和MPA的计算方式分别如下:

(8)
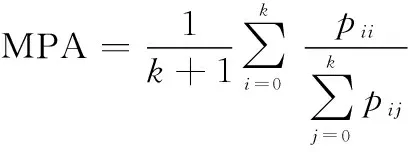
(9)
MIoU是计算真实值和预测值之间的交集与并集之比,先计算出每一类的交并比(intersection over union, IoU),再对多类IoU求和之后的结果进行平均得到最终的全局评价指标。而MPA计算的是每一类正确判别的像素比例,再同样对所有类别求其平均值,是从像素角度进行的评价。
从检测的角度进行分析,本文选取COCO数据集中的平均精度和平均召回率等作为评价指标。此外,本文还考虑了模型大小等问题,并从其他角度对结果进行比较分析。
2.3 实验结果
本文方法的语义分割指标如表1所示,实验采用的模型即是本文在UNet基础上进行修改并适应的调整应用于SAR图像中的UNet-S。不同损失函数对应的结果对比如表1所示。

表1 语义分割评价指标Table 1 Semantic segmentation evaluation indicators
其中,总计是背景和舰船目标分割结果的平均值,CE指的是是否使用交叉熵损失函数,Dice代表是否使用Dice Loss损失。从表1中对比可看出,训练过程中使用Dice Loss能够有效地提升语义分割效果。虽在背景上分割结果相近,但对于舰船目标分割效果提升显著,MPA更达到了7.3%的差距。表2和表3反映的是检测评价指标,其中Dice代表是否使用Dice Loss损失;而AP代表的是准确度,下标数字代表的是不同阈值情况,下标s、m和l对应小目标、中目标和大目标情况。
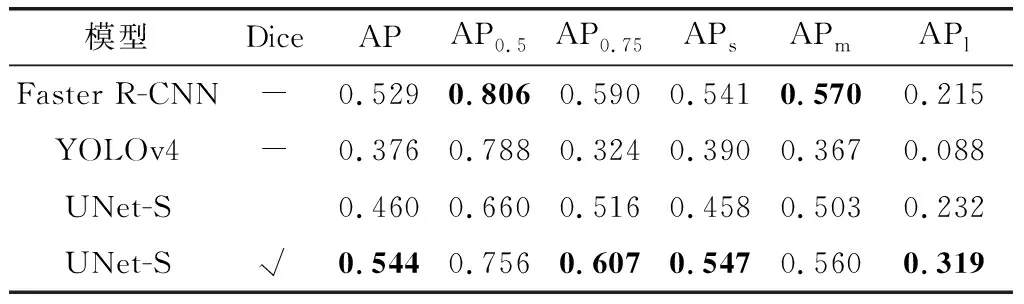
表2 不同模型的平均精度指标Table 2 Average precision indicators of different models
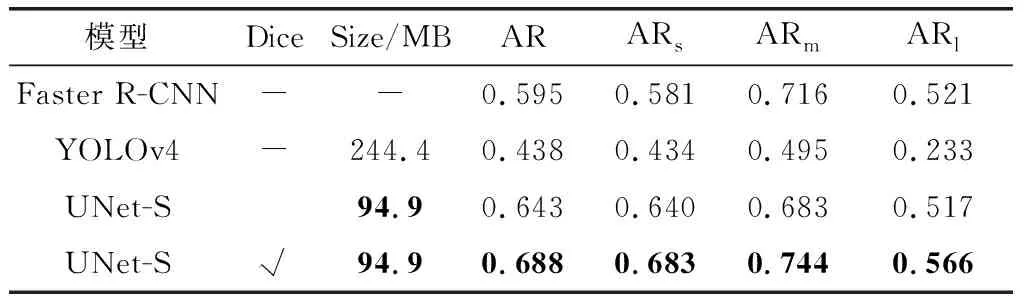
表3 不同模型的平均召回率指标Table 3 Average recall rate indicators of different models
对比可知,本文方法在精度指标AP上超出单阶段检测优秀算法YOLOv4和双阶段典型算法Faster R-CNN(采用的骨干网络为ResNet50),且无论目标大小都有极高的精度。表3中AR指的是平均召回率,同样超出YOLOv4和Faster R-CNN,最高达到33.3%的差距,可见本文所用算法的优越性。
图3展示了本文方法的部分预测结果,其中图3(a)对应的是真实标注框,图3(b)对应的是本文方法的预测结果,图3(c)是语义分割过程中预测的掩膜。可以看出,无论是大目标还是小目标、复杂背景与简单背景还是稀疏情况与稠密情况下,本文方法都能得到一个很好的检测与分割效果。

图3 UNet-S的检测结果Fig.3 Detection results of UNet-S
2.4 对比分析
表2和表3反映了本文方法的优越性,这可归因于UNet-S对于舰船目标尺度不敏感的特性。其将检测问题转化为语义分割问题,逐像素判断舰船目标和背景。因此不利于检测方法的舰船目标多尺度特性与小目标检测在此处转化为目标和背景的不均衡问题。通过Dice Loss损失函数可有所缓解,整体效果提升巨大。
与此同时,从表3中的模型大小可以发现,UNet-S参数量仅为94.9 M,而YOLOv4参数量为244.4 M。其他如双阶段检测算法HRSDNet检测效果虽好,但模型大小更达到728.2M。相对而言,本文UNet-S模型的参数量较小。
图4展示的是本文方法与YOLOv4的检测框对比情况,其中绿色框代表的是真实标注框,红色框对应的是本文UNet-S的预测结果而黄色框是YOLOv4的检测结果。从图4(a)中可以看出,本文方法的预测框与真实标注的结果基本相重合,预测的结果相对于真实框偏移极小。而图4(b)中YOLOv4的检测结果相对而言偏移较大。

图4 预测框结果对比Fig.4 Result comparisons of predicted bounding boxes
图5展示的是复杂背景下和多尺度目标下,UNet-S和YOLOv4算法的检测结果,其中标注框颜色与前文所述一致。YOLOv4在该场景中漏检两个目标且预测框偏移较大,而本文算法则完整地检测出所有目标,预测框整体偏移较小。这再次说明通过语义分割的方式能够在SAR图像上达到很好的检测与分割效果。

图5 复杂背景下检测对比Fig.5 Detection comparisons under complex backgrounds
3 结束语
在诸多公开数据集的引导下,当前已有许多深度学习的检测方法用于SAR图像中完成舰船目标检测等任务。但就其自身特点来说,均属于迁移类方法,缺乏了对其任务自身的考量。当前SAR图像舰船目标检测只涉及定位而不涉及分类问题,且锚框等设计思路在SAR图像中容易造成冗余、算力浪费情况。此外,数据集本身的噪声影响、多尺度特性以及目标背景不均衡问题等均对检测产生极大的负面影响。
不同于当前已有思路,本文将SAR图像舰船检测问题认为是二分类问题,通过语义分割的方法实现了SAR图像舰船目标检测分割一体化。本文避免了复杂的检测网络解码问题以及将舰船目标多尺度不易检测特性转化为目标和背景判别问题,通过引入Dice Loss损失函数进行优化,在分割的同时实现了舰船目标检测。实验结果表明,本文方法在评价指标上均取得了大幅提升。
本文所有实验结果均基于UNet语义分割实现,并对其进行了部分改进,提出了UNet-S网络以适用于SAR图像中。下一步工作将考虑如何进一步提升检测与分割的效果以及追求更加高效的性能。
