基于人眼视点图的特征融合小目标检测算法
2022-04-07魏文晓刘洁瑜
魏文晓, 刘洁瑜, 沈 强, 李 成
(火箭军工程大学导弹工程学院, 陕西 西安 710025)
0 引 言
目标检测是计算机视觉领域的一个重要课题,广泛应用于各行各业。传统基于人工特征的检测算法鲁棒性、通用性都比较差,而目前基于深度学习的目标检测算法则有更好的性能。基于深度学习的检测算法主要分为双阶段目标检测算法和单阶段目标检测算法,双阶段目标检测算法虽然相较多类别单阶检测器(single shot multibox detection, SSD)等单阶段算法精度高,但其运行速度慢,难以满足实际场景中实时性的要求。目标检测领域中,小目标具有分辨率低、信息少等问题,导致小目标特征表达能力不足,检测过程中漏检、错检现象严重。因此,针对小目标检测精度不足问题,近年来国内外许多学者对小目标检测问题提出了不同的改进方案,大多通过融合获取含有充分信息的特征层分类回归进行算法的改进。朱明明等基于快速区域卷积神经网络(faster region convolutional neural network, Faster-RCNN)通过特征融合和软判决非极大值抑制(soft non-maximum suppression, Soft-NMS)改进小目标检测精度,但是由于Faster-RCNN为双阶段检测算法,实时性较差。朱敏超等基于特征融合SSD (feature fusion SSD, FSSD)算法将不同特征图进行融合,通过利用表征能力更强的浅层特征图检测小目标,但该算法引入过多的浅层特征,算法快速性降低过多,实时性较差。郑浦等基于SSD算法通过金字塔特征融合思想,对每个通道进行权重分配,增加了算法的泛化能力,但该算法并未充分利用表征能力更强的浅层特征。汪能等基于SSD算法通过多尺度融合、增加卷积层深度,获取更充分的具有表征能力的浅层特征,但该算法并未对融合信息进行筛选。因此,选择生成更有表征能力的特征层是小目标检测领域的研究核心。同时由于目标检测算法中负样本多,背景所占图片比例大,如何突显目标所在位置的像素也是提升精度的重要研究方向之一。文献[14-15]对人眼视点图的研究表明人眼的感受野是视网膜上呈现图像的偏心度的函数,与偏心度呈正相关,距离视网膜上物体的中心越近,感受野的尺度越小,因此人眼在观察物体时能够形成所关注部分清晰,周围模糊的视觉感受,同时对所观察物体位置上的微小偏移也能够较清晰地进行判断。故构造类似人眼视点图的感受野有助于目标检测精度的提升。
基于以上分析,本文以典型的SSD算法为基础,针对小目标信息少、分辨率低等特点,采用不同扩张率的空洞卷积构建具有类似人眼感受野的空洞卷积金字塔模块,扩大浅层特征图感受野,提升模型对目标所在位置像素的学习。同时,利用特征金字塔网络(feature pyramid network, FPN)思想和长短时记忆(long-short term memory, LSTM)网络的记忆思想,建立特征金字塔融合模块,生成具有更佳表征能力的新特征层进行分类回归。利用包含20个类别的VOC 2007数据集进行验证,本文算法可以在保证检测速度的前提下提升检测精度
1 SSD网络结构分析
SSD算法借鉴了Faster-RCNN中的锚框和YOLO(you only look once)算法单阶段检测思想,在检测精度、速度上都有较好效果。SSD网络结构如图1所示,基础网络通过VGG(visual geometry group)网络进行特征提取获取一个特征层,附加网络中增加4层级联卷积层获取5个特征层,网络输入通道数为3通道,从左至右生成6个特征图: Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2及Pool11,尺寸大小分别为 38×38、19×19、10×10、5×5、3×3、1×1,通道数分别为 512、1 024、512、256、256、256。不同大小的特征图有利于检测尺度差别较大的目标,浅层较大的特征层有利于检测图片中尺寸较小的目标,尺寸较小的特征层则负责检测尺寸较大的目标。最后将6个特征层对应的检测框进行合并,通过非极大值抑制(non-maximum suppression,NMS)得到最终结果。

图1 SSD网络结构图Fig.1 SSD network structure
传统SSD算法在特征图中每一个网格单元设置不同比例的先验框,以先验框为基准计算偏差预测目标位置,降低模型的训练难度。但SSD算法在浅层特征层上检测精度低,且6个特征层在同一水平上检测,导致算法提取位置信息、细节信息和全局语义信息的能力下降,因此小目标检测精度较低。故增加细节特征、合并上下文信息、提高浅层特征信息的利用率是提高小目标检测精度的重要途径。
2 改进的SSD网络结构
卷积神经网络中浅层特征层包含大量细节信息,但SSD算法基础网络的浅层特征层对应的感受野大小仅为92×92,并不能覆盖全图的感受野,包含的语义信息和特征信息不丰富,造成大量小目标漏检、错检。为此扩大VGG网络输出的Conv4_3特征层的感受野,改善浅层特征图感受野小的不足。Conv9_2、Conv10_2、Pool11 3个特征层所对应的感受野覆盖全图,分别为356×356、485×485、612×612,而Conv7、Conv8_2两个特征层的感受野大小为260×260、292×292,提取出的特征缺乏全局性,因此融合Conv9_2、Conv10_2、Pool11 3个特征层中丰富的位置信息、语义信息,增加细粒度信息,生成新的Conv7′、Conv8_2′。
改进的SSD网络结构如图2所示。基础网络输出的浅层特征图通过构建的空洞卷积空间金字塔模块扩大感受野,附加网络中的5个特征层通过建立的特征金字塔融合模块提升细粒度信息,利用上下文信息对目标进行分类回归。
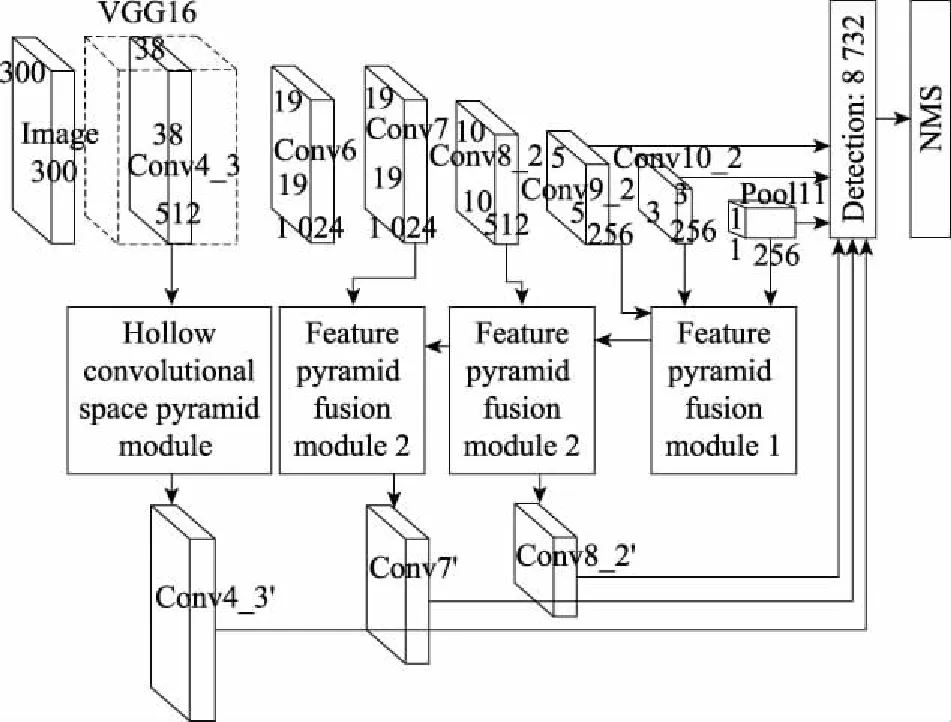
图2 改进的SSD网络结构图Fig.2 Improved SSD network structure
2.1 空洞卷积空间金字塔模块设计
目前的深度学习模型,通常将感受野与特征图上常规采样的网络设置为相同大小,会导致网络鲁棒性不强。Inception考虑了多种大小的感受野,并通过不同卷积内核的多分支卷积神经网络来实现。其改进方式在目标检测(两阶段检测算法)中和分类任务中获得了非常好的效果。但Inception结构中所有的内核都是在同一中心采样的。可变形卷积根据物体的大小和形状来自适应地调整感受野的空间分布,采样网格非常灵活,但并未考虑感受野偏心率的影响,认为像素对输出做出的贡献相同,未强调重要信息。神经科学方面的发现表明,在人类视觉皮层中,群体感受野的大小在视网膜视点图中是与偏心率呈正相关的函数,随着偏心率的增加而增加。因此,本文根据人眼观察物体时的视网膜视点图的感受野设计空洞卷积空间金字塔模块,观察目标时,人眼视网膜视点图如图3(a)所示,V1、V3、hV4分别代表眼睛在不同视角观察时的群体感受野,总体呈现随偏心率的增加感受野尺度逐渐增加的趋势,越靠近目标中心感受野越小,这样的感受野有助于突出显示靠近中心区域的像素,并提高位置预测时较小空间偏移的敏感度。因此构造类似人眼感受野的特征层更有利于提升检测精度,提高对小目标的位置预测。故在SSD算法的基础上增加空洞卷积空间金字塔模块,如图3(b)所示,通过融合不同扩张率空洞卷积下的特征层构造出如图3(a)所示的人眼感受野。

图3 特征层感受野结构图Fig.3 Structure diagram of characteristic layer receptive field
将基础网络输出的Conv4_3特征层经过不同扩张率的空洞卷积进行融合,构造出与人眼视点图类似的感受野,既增加了特征层对应的感受野大小,又突出强调特征层中的重要特征信息。根据图3(b)所示空洞卷积空间金字塔模块的思想,本文改进的空洞卷积空间金字塔模块结构图如图4所示,其中空洞卷积的扩张率分别选用1、3、5,对3个分支的特征层串联融合。首先在每个分支中采用1×1卷积层组成的瓶颈结构,以减少加上×卷积层后特征图的通道数。其次,为加深结构的非线性,减少参数和计算量,采用两个堆叠的3×3卷积层代替5×5的卷积层,并使用一个1×3和一个3×1的卷积层来代替原始的3×3的卷积层,最终生成新的特征层Conv4_3′。

图4 空洞卷积空间金字塔结构图Fig.4 Structure of hollow convolutional spatial pyramid
2.2 特征金字塔融合模块设计
图2中特征金字塔融合模块一主要是对深层特征中的全局语义信息和位置信息进行特征融合,借鉴特征金字塔的融合思想,对3个特征层建立自上而下的横向链接,通过反卷积对深层特征信息进行融合构造。同时,通过1×1卷积整合不同维度信息,减少反卷积之后的通道数,增加网络结构的非线性和特征层的表征能力。如图5所示,生成的新模块的特征层的表达式为
=(()+)+
(1)
式中:、分别为Pool11、Conv10_2的特征层;为Conv9_2的特征层;为通过反卷积层、1×1卷积层、归一化层和激活层的总函数,其中反卷积层和1×1卷积层共享参数,减少计算量。
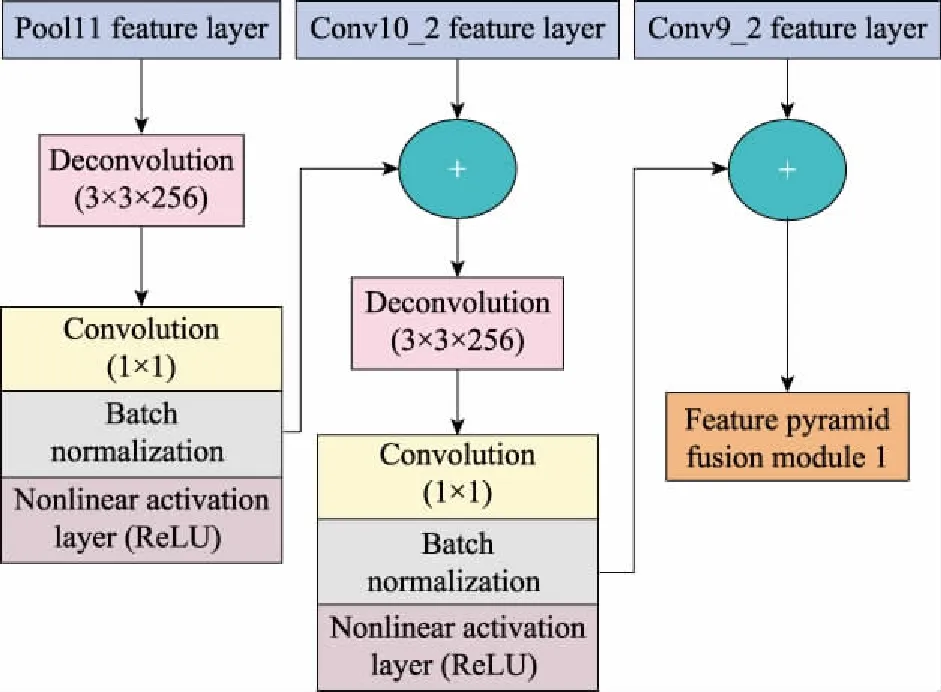
图5 模块一结构图Fig.5 Structure of module 1
为丰富Conv8_2特征层的位置信息、语义信息以及细粒度信息,将模块一中新生成的特征层与Conv8_2通过模块二进行融合。由于模块一新生成的特征层主要包含全局信息和位置信息,而仅有部分信息对检测有利。同时,Conv7和Conv8_2两个特征层尺寸相对较大,反卷积过程中易受噪声干扰,因此模块二引入LSTM的门控思想,对输出的特征图信息进行筛选,滤除无效信息。门控结构采用sigmoid函数生成激励信号,对特征信息进行选择性的滤除后将有效信息进行融合,0表示信息完全滤除,1表示信息完全接收。
模块二的结构图如图6所示。将模块一的特征层经过反卷积、卷积、批标准化、激活层后与Conv8_2层的特征层通过sigmoid函数进行特征融合,将融合后的特征层与Conv8_2比较,为选择出更有代表性的特征层,选择数组较大的组合作为新的特征层Conv8_2′。

图6 模块二结构图Fig.6 Structure of module 2
3 实验结果与分析
3.1 实验平台与数据
小目标在目标检测中定义为绝对小目标和相对小目标两类,绝对小目标是指目标像素小于32×32,相对小目标指目标尺寸小于原图尺寸的10%。为验证本文算法的性能,本文在PASCAL VOC2007的数据集上进行训练评估。VOC2007数据集包括不同尺寸大小的20个分类,总共9 964张图片。其中,根据小目标定义数据集中的各个类别小目标所含数量如表1所示。

表1 PASCAL VOC2007数据集中小目标含量Table 1 Small target content in PASCAL VOC2007 data set
实验在Ubuntu16.04系统的Pytorch框架下运行,并使用CUDA9.0和cuDNN7.1来加速训练。计算机搭载的CPU为Corei7-8700k,显卡为NVIDIA GTX1080Ti,内存为32 G。训练过程中输入图片大小为300×300,batch size设置为16。优化器采用传统的随机梯度下降法(stochastic gradient descent with warm restarts, SGDR),初始学习率设置为0.001,动量值为0.9,权值衰减值设为0.000 1。
3.2 实验结果分析
为验证本文算法性能的有效性,设计了3个实验:① 与经典主流算法的对比实验,主要分析本文算法与经典SSD算法在训练模型、检测精度上的提升;② 消融实验,主要验证本文算法改进模块的必要性;③ 与改进小目标检测算法的对比实验,主要与基于SSD算法改进的小目标检测算法的精度对比,验证算法在精度上的提升。
3.2.1 与经典主流算法对比实验
为验证本文算法有效性,在训练过程中对不同算法的损失函数进行可视化,对比损失值的大小和下降趋势,检测改进算法的模型收敛效果。
SSD算法和本文算法在VOC 2007数据集上训练的损失曲线如图7所示,红色为SSD算法的损失函数曲线图,蓝色为改进算法损失曲线图。从对比图中可以清晰地看出,本文算法损失函数中的损失值比SSD算法的更低。除此之外,本文算法在改变学习率之后损失函数有明显下降趋势,说明本文改进算法模型收敛效果更好,具有更好的识别度和鲁棒性。

图7 损失函数曲线对比图Fig.7 Comparison of loss function curve
目标检测精度在测试集上的评价指标,通常采用平均准确率均值(mean average precision, mAP),计算公式如下:

(2)

(3)

(4)

(5)
式中:表示正确识别目标的数量;表示将背景错误识别成目标的数量;表示目标未被正确识别的数量;+表示识别目标的总数;+表示目标的总数量;AP为第个类别检测的平均准确率;为数据集包含的类别总数;mAP为所有类别检测平均准确率的均值,表示模型在多个类别上的综合性能。
本文采取mAP为检测精度的评价标准,训练时使用VOC 2007的训练集和验证集,测试集采用VOC 2007的测试集。本文算法与其他算法平均检测精度的结果对比如表2所示,本文算法相比于SSD算法提高了3.7%,与目前精度较高的Faster-RCNN双阶段检测算法的精度相比提高了1.8%。

表2 PASCAL VOC 2007测试数据集的检测精度Table 2 Detection accuracy of PASCAL VOC 2007 test data set %
在算法速度上,本文选用每秒传输帧数(frames per second, FPS)作为评价指标。该算法引入空洞卷积空间金字塔模块和特征金字塔融合模块,两个模块扩大了特征层的感受野,增加了特征层之间的联系,因此与原算法相比参数所需内存增加了80 MB,模型复杂度增加了35.9%,运行速度FPS下降为65帧/s,较SSD算法的71.4帧/s下降了6.4帧/s,但仍大幅度领先于双阶段算法。
表2的检测结果表明本文算法在所有类别中的检测结果都高于SSD算法,且在包含小目标较多的plant、tv类别上,检测精度高于Faster RCNN算法。在bottle、chair、bird 3个小目标的类别上本文算法虽检测精度超出SSD算法,但由于数据集中该类目标的周围环境相对比较复杂,并未超出双阶段检测算法的精度。
3.2.2 消融实验
为进一步分析本文所提网络结构对检测的影响,分别对空洞卷积空间金字塔模块和特征金字塔融合模块进行了实验验证,如表3所示,其中√表示在原有算法基础上加入了不同的模块,—表示检测时没有加入。空洞卷积空间金字塔模块为算法提供了1.2%的精度提升,表明增加浅层特征层的感受野可以有效提升检测精度。特征融合金字塔模块中的模块二在未加入门控思想时由于未对全局信息进行筛选而导致检测精度下降,加入门控思想后检测精度提升了0.7%。

表3 不同模块效果对比表Table 3 Comparison of the effects of different modules
3.2.3 与改进的小目标检测算法对比实验
为与文献[12]中提出的Bi-SSD算法对比,本文算法将实验数据集的训练集设置为VOC 2007+2012的训练集,测试集设置为VOC 2007的测试集,与Bi-SSD算法的对比结果如表4所示,虽然总体检测精度仅提高了0.8%,但在bottle、plant、tv等小目标较多的类别上检测精度提升较明显。另外,与YOLOv3相比,本文算法在输入图片大小为300×300时的检测精度相同,但在输入图片大小为512×512时检测精度相较于YOLOv3提升了2.1%。
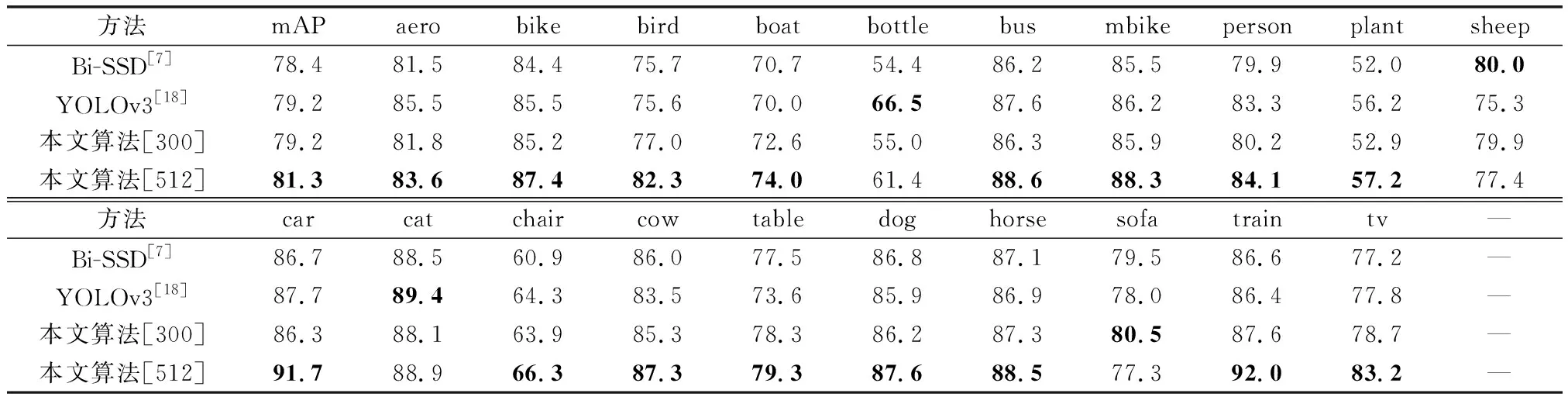
表4 小目标检测算法平均检测精度对比Table 4 Comparison of mean detection accuracy of small target detection algorithms %
图8是SSD模型与本文算法在VOC数据集上得到的检测结果对比图,其中图8(a)为输入原图,图8(b)为本文算法的检测效果图,图8(c)为SSD算法的检测效果图。本文算法相较于SSD算法减少了漏检率和错检率,提升了整体目标的检测精度。另外,如第一、二、六行图片所示,针对遮挡物体本文算法有较好的检测结果。


图8 测试图片的结果对比图Fig.8 Results comparison chart of test data
4 结 论
本文设计的基于人眼视点图的小目标检测算法主要通过人眼视点图的思想扩大浅层特征层感受野,同时通过特征金字塔融合的方法改善了SSD算法不同特征层在同一水平上检测回归的问题,提升了全局语义信息的提取率,从两方面的改进提升了检测精度。在VOC 2007数据集上进行验证,结果表明,本文算法的检测精度相较于SSD算法提升了3.7%,相较于Faster-RCNN提升了1.8%。但SSD算法的锚框设置在针对不同数据集时有非常大的局限性,且在数据集背景较为复杂时检测精度不够理想,因此如何改善锚框的设置及提升复杂背景下的目标检测精度是将目标检测算法应用到实际的重要研究方向。
