终端区飞行轨迹聚类分析及异常轨迹识别
2022-04-06王志森张召悦冯朝辉崔哲
王志森,张召悦*,冯朝辉,崔哲
(1.中国民航大学空中交通管理学院,天津 300300;2.中国民航大学安全科学与工程学院,天津 300300)
近年来,空中交通流量快速增长,以往的空域扇区的划分不能满足现有的空中交通流量的需要,因此,导致航空器实际进场飞行轨迹偏离标准航线,并增加管制员的工作负荷。以自动相关监视广播(automatic dependent surveillance-broadcast,ADS-B)终端区飞行轨迹数据为基础,可以获取进离场盛行交通流的分布信息,优化空域扇区的划分和标准进离场程序设计,帮助管制员优化进离场程序,从而达到提高空域利用率[1]和保障空中交通安全[2]的目的。
航空器的飞行轨迹包含了空中交通流时空分布规律、管制员意图等重要空中交通信息。飞行轨迹聚类是一种通过划分航空器飞行轨迹,达到类内相似,类与类之间相异的一种方法。以飞行轨迹聚类分析为基础,为掌握飞行轨迹的时空分布规律提供支撑,从而达到制订相应的空中交通管理规则、识别盛行交通流等目的。可以将轨迹聚类方法分为两大类,一种方法是将航空器的飞行轨迹简化为线段后进行聚类,以此降低轨迹聚类的难度[3-5]。另一种则是通过构建相似度矩阵来实现对轨迹的聚类[6-11]。但由于地形、环境等的影响,ADS-B数据存在解析过程的错误、飞行轨迹点缺失、航空器运行速度不同等问题。因此原始数据中存在着大量的干扰飞行轨迹,而上述两种方法,对数据都有着比较高的要求,需要对原始数据进行一定的处理。基于密度空间聚类(density-based spatial clustering of applications with noise,DBSCAN)方法[8-10]可以在聚类过程中标记噪声点,从而优化聚类效果,但仅能针对低纬度数据点操作,不能对线段、向量等进行聚类。赵元棣等[11]对飞行轨迹进行重采样后降维,从而对航空器飞行轨迹应用基于点的聚类方法,但其忽略了飞行轨迹的高维表示并不是线性排列。王莉莉等[12]针对飞行轨迹聚类效果易受离群点干扰的问题,选取航空器的航向和高度变化率进行飞行轨迹的模式识别。Tan等[13]则通过完善数据预处理的过程,实现聚类效果的提升。为解决数据质量较差和空中交通流之间差异较小的问题,Dong等[14]通过深度自编码器完成对轨迹的重构与异常轨迹检测。
现针对航空器飞行轨迹聚类普遍数据预处理和计算复杂的问题,通过DBSCAN算法简化轨迹数据的预处理并剔除轨迹中干扰轨迹。首先,采用重采样技术降低飞行轨迹的数据规模,并在重采样过程中提取原始航迹点作为重采样点代替线性插值避免产生新的点,破坏飞行轨迹的原始结构;其次,通过核主成分分析法(kernel principal component analysis,KPCA)对飞行轨迹数据降维处理,尽可能分离不同类别的飞行轨迹;最后,通过DBSCAN剔除数据中的干扰飞行轨迹完成聚类并提取异常轨迹。
1 数据重采样
通过对飞行轨迹重采样可以在保存飞行轨迹结构特征的条件下,有效缩减每条飞行轨迹包含的航迹点个数,从而减少计算量,提升了计算速度。同时,对均匀参数化法[11]进行改进,使得重采样后,所有的飞行轨迹包含的航迹点个数一致,为利用KPCA降维提供必要条件。
若某条飞行轨迹包含n个点,则以(p1,p2,…,pn)表示该飞行轨迹,点pi包含其三维信息,即(xi,yi,zi)。如式(1)所示,对所有点累加弦长作为参数,使飞行轨迹上所有点落在区间(0,1)内。当对飞行轨迹进行重采样时,为保证飞行轨迹的准确起止位置,故不对飞行轨迹的第一个和最后一个飞行轨迹点进行重采样,而是直接编入到重采样后的数据中。
因此使用改进的均匀参数化法[11]对飞行轨迹进行重采样,从而避免线性插值产生的点破坏原有轨迹结构特征。
(1)

(2)

图1 重采样与原飞行轨迹对比
2 基于KPCA的飞行轨迹降维方法
基于密度的聚类方法对于高维数据的处理上往往不尽如人意,故在轨迹进行聚类之前,对轨迹降维。首先,将每条轨迹整理成3m维向量,即把每条飞行轨迹视为3m维空间的一个点。但维数过高会在聚类过程中导致维数灾难,为避免在聚类过程中发生维数灾难,KPCA对数据进行降维。
通过KPCA对所有轨迹归纳其的前c个主成分,设存在s条轨迹,每条轨迹包含3m个点,则轨迹集合T为一个s×3m的矩阵。轨迹集合T以[x1x2x2…xmy1y2…ymz1z2…zm]形式进行排列,即
T=(T1,T2,…,Ts)=[Tij]s×3m=
(3)
为了使同一类别的点分布相近,不同类的点尽可能互相远离,将高斯函数作为KPCA的核函数进行降维。KPCA运算步骤如下。
步骤1对矩阵T标准化。
(4)
步骤2计算核矩阵。
(5)
步骤3中心化核矩阵。
K*=K-unitK-Kunit+unitKunit
(6)
步骤4求解K*特征值,并降序排列,λ1≥λ2≥…≥λ3m,取前c个特征值对应向量V,V=(V1V2…Vk)。
步骤5得到Xnew。
Xnew=K*V
(7)
式(7)中:Xnew为航空器轨迹集合的前c个主成分。
分别以c=2、3为例,对飞行轨迹进行核主成分分析,每个数据点代表一条轨迹,如图2所示。

图2 不同c值时KPCA结果
c=3时,数据点集的分布则更加立体,类与类之间的差异也更加明显,故选择c=3作为主成分个数。
通过KPCA可以将非线性高维数据进行降维,尽可能使同类点之间分布更密集,不同类点之间更加稀疏,并保留了数据特征信息。因此数据点之间的关系即代表了飞行轨迹之间关系。同时根据图中信息得到,轨迹点的分布密集地围绕在几个中心点,并以辐射状发散,这也与终端区航空器按照标准程序进场的实际情况相吻合。
3 基于DBSCAN的轨迹聚类方法
由于各终端区进场程序间差别较大,且实际的航空器飞行轨迹与标准的进离场程序存在着较大的偏差,因此很难提前确定聚类数目,且飞行轨迹数据中包含较多由错误轨迹构成的噪声点。DBSCAN可以对数据中噪声点剔除并确定聚类个数。因此使用DBSCAN对降维后的轨迹数据聚类。
DBSCAN是一种基于密度的聚类算法,相较于其他聚类方法,DBSCAN具有高效处理噪声点、聚类效率高、并发现任意形状空间簇类的优点。
DBSCAN通过持续搜索核心点,不断建立新簇,并不断对簇进行合并直到簇与簇之间密度不可达为止的过程。其算法如表 1所示。

表1 DBSCAN算法
在对飞行轨迹数据集降维后,通过DBSCAN算法对降维后的数据集进行聚类和噪声点的识别。为确保聚类质量和噪声点剔除的准确性,经过分析,Eps为0.01,Minpts为7,并对数据集聚类,聚类结果如图3所示。
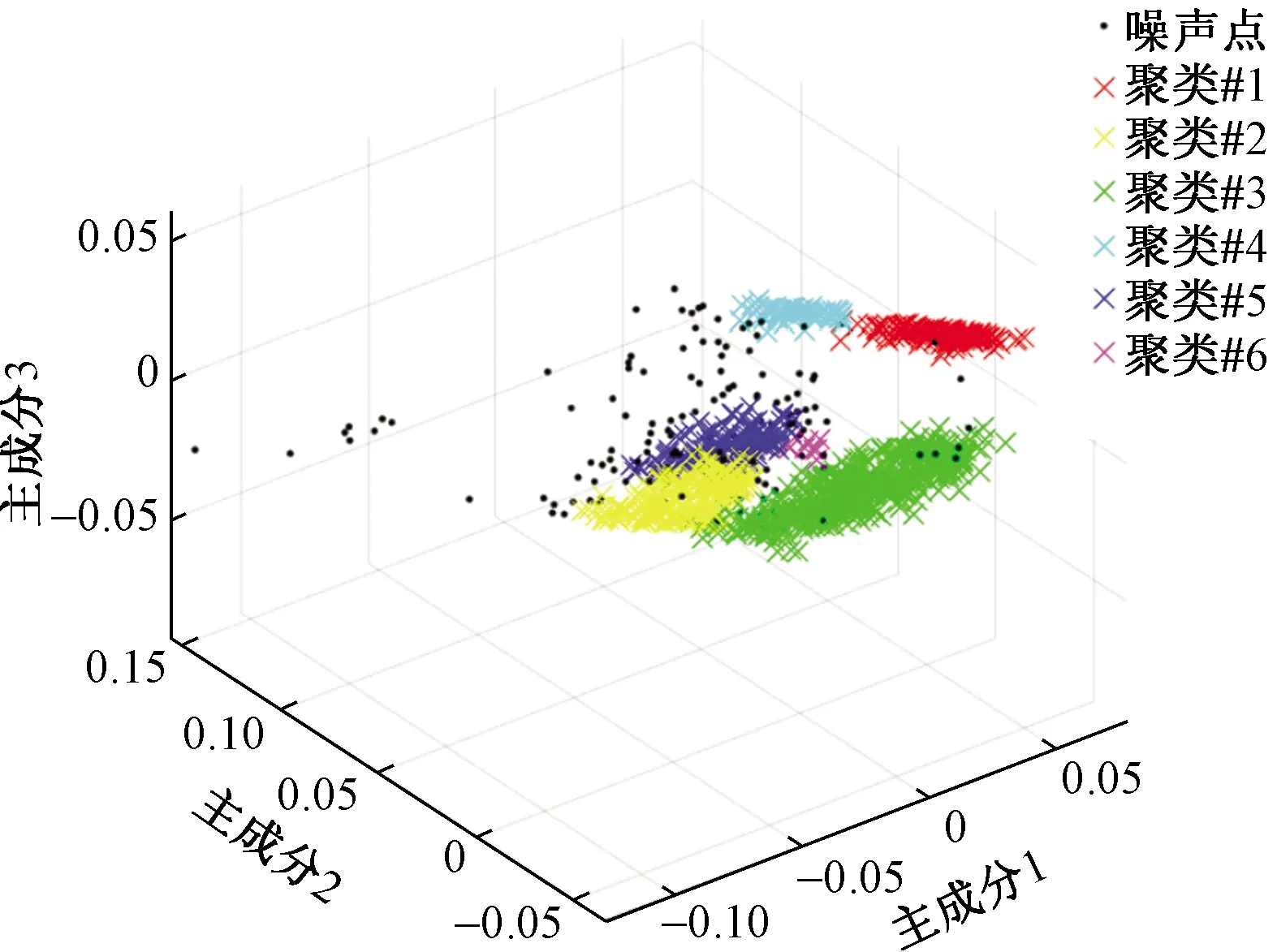
图3 KPCA(Gaussion)聚类结果
4 实例分析与对比
以某终端区4 d内共1 243条进场飞行轨迹为例,应用MATLAB软件进行编程,从全部数据处理到整个聚类完成,仅耗时9.38 s。实验环境为3.20 GHz CPU,8 GB内存的笔记本。在整个聚类过程中共涉及5个参数的设置:重采样后点的个数m;核函数中参数σ;核主成分个数为k;DBSCAN中存在两个参数Eps和Minpts。
4.1 实验分析
4.1.1 聚类结果及异常轨迹提取
图4是对轨迹进行KPCA方法降维后的聚类结果图。图4中,点代表一条轨迹,其中线条的颜色代表其所属的类。红色类别包含飞行轨迹135条,黄色类别包含飞行轨迹226条,绿色类别包含飞行轨迹531条,青色类别包含飞行轨迹58条,蓝色类别包含飞行轨迹146条,粉色类别包含飞行轨迹8条,与噪声点相对应的飞行轨迹139条。
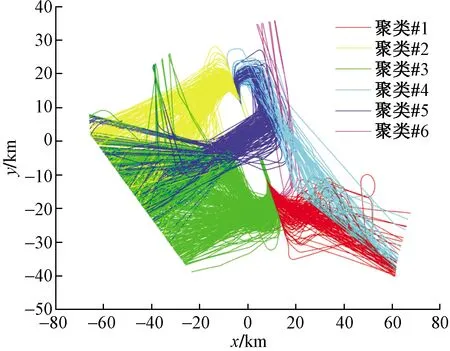
图4 飞行轨迹聚类结果
其中粉色类别的飞行轨迹仅有8条,且该轨迹飞行结构特征与其他轨迹存在显著差异,此类轨迹的产生是由于管制员采取雷达引导方式导致其进场轨迹偏离标准进场航线,因此将粉色类别作为异常轨迹。
4.1.2 噪声点分析
所使用的ADS-B数据,仅是剔除了飞越轨迹的原始轨迹,因此数据集T中包含很多由于地形、环境、设备解析等问题造成的不完整轨迹、地面运行轨迹等干扰轨迹。干扰轨迹的存在会对聚类效果造成不利影响,但针对问题轨迹的剔除和不完整轨迹进行补点费时费力,利用DBSCAN算法中识别噪声点的特点对干扰轨迹进行识别,并对噪声点进行分析。
首先,对原始轨迹进行处理,提取出缺点轨迹162条,ADS-B设备解析问题导致的干扰轨迹7条。如图5所示。

图5 轨迹对比
对以高斯函数为核函数的KPCA进行聚类(图3),产生了169个噪声点,其中噪声点包含全部因ADS-B设备解析问题导致的干扰轨迹,对于轨迹缺点问题,在不进行补点的情况下,噪声点中包含了25条,其余缺点轨迹加入到正常轨迹的聚类中(图4),并未产生明显不利影响。
4.2 参数分析
4.2.1 Eps的影响
在通过DBSCAN方法进行聚类时,需要对Eps和Minpts进行设置,不同的参数设置对应不同的聚类结果。如表 2所示,可以看出,随着Eps减小,聚类类别数目增加。如图 6所示,随着Eps增大,噪声点数目减小,聚类类别减少。因此,数据集中,各点的实际分布情况是确定Eps的重要因素。

图6 不同Eps聚类结果

表2 Eps的影响
4.2.2 Minpts的影响
Eps和Minpts都会对聚类结果造成影响,如表3所示,Minpts在固定Eps的条件下,对数值变化并不敏感。如图 7所示,随着Minpts增大,噪声点数目增加,在具体结果上表现出对规模较小的类别不能有效识别、对规模较大的类别划分更加精确的特点。

图7 不同Minpts聚类结果

表3 Minpts的影响
4.3 聚类结果对比
4.3.1 与meanshift聚类结果对比
meanshift算法与DBSCAN同属于基于密度的聚类方法,相较于DBSCAN算法,meanshift算法只需要设置一个参数,但meanshift算法的聚类质量受起始点选择的影响较大,聚类质量不稳定,且无法识别噪声点,因此使用meanshift算法进行聚类需要较高的数据质量。meanshift聚类结果如图8所示。

图8 meanshift聚类结果
与图4相比,由于没有对轨迹数据进行预处理,存在过多的干扰轨迹从而使meanshift聚类结果相对杂乱,不能很好识别轨迹所属的类。
4.3.2 不同核函数聚类结果对比
常见的核函数可分为4种:线性核函数、多项式核函数、径向基函数(radial basis function,RBF)核函数和Sigmod核函数。因多项式核函数种类繁多,且需要进行较多的参数选择并对参数敏感性较大,故不在此进行详细讨论。
(1)采用RBF核函数。RBF中包含多种核函数,除了高斯核函数,常用的还有指数核函数和拉普拉斯核函数。以指数核为例,结果如图9所示。与图4的DBSCAN飞行轨迹以高斯核函数为核函数聚类结果相比,以指数核函数为核函数不能很好地区分同一跑道入口的两类轨迹(绿色类别的飞行轨迹)。

图9 指数核聚类结果
(2)以Sigmod为核函数。其结果如图10所示。虽然以Sigmod作为核函数,可以较好地剔除噪声点,但不能很好地区分同一跑道入口的两类轨迹(绿色类别的飞行轨迹)。

图10 Sigmod核聚类结果
4.3.3 多类别识别
通过上述对比,不难看出,该机场存在5个主要交通流,但通过参数调节,将更多轨迹判定为噪声点,可以获得更加细致的航空器进场轨迹的类别,如图11所示,图4中的绿色类别可以再次划分为4个类别,黄色类别可以再次划分为2个类别。

图11 聚类结果
通过实验证明,应用KPCA和DBSCAN算法对飞行轨迹聚类,可以在实现对交通流更精细划分的同时,DBSCAN中自行筛除噪声点的特点保证聚类的质量,为聚类结果最终的应用提供了更多的可能。
5 结论
从终端区飞行轨迹非线性特征的角度和剔除异常轨迹影响的角度出发,重采样简化飞行轨迹数据规模,针对终端区飞行轨迹特征,利用非线性降维方法对飞行轨迹高维数据进行降维,并通过DBSCAN算法完成聚类及异常轨迹的识别。实验结果证明,该聚类方法可以得到高质量的聚类结果,相较于其他聚类方法,可以消除错误轨迹的不良影响,保证聚类质量。未来的研究工作包括结合飞机性能的数据特征子集的选取、飞行轨迹质量评估等,并在此基础上进行空中交通分析。
