基于神经网络的CFB锅炉灰渣含碳量预测
2022-04-06王树宇刘林涛董瑀非
陈 斌,王树宇,刘林涛,朱 伟,董瑀非
(1.桐乡泰爱斯环保能源有限公司,浙江 嘉兴 314500;2.能源清洁利用国家重点实验室(浙江大学),杭州 310027)
0 引言
CFB(循环流化床)锅炉采用工业化程度最高的洁净煤技术,燃烧效率高,NOX等污染物排放低,燃料适应性广(可掺烧污泥、垃圾等非煤炭燃料)[1],目前在我国热电厂中广泛应用。一方面,由于对入炉煤煤质要求不高,CFB 锅炉的燃煤多为灰分较高、水分较大的难燃煤种(如无烟煤或烟煤等),燃用此类燃煤时往往会增加锅炉灰渣量,且灰渣中的可燃物含量也会增多[2];另一方面,国内热电厂技术力量和运行水平相对较为薄弱,在日常运行中存在锅炉性能浪费的现象。能够获取实时的锅炉效率,对于指导锅炉运行调整、获得更佳的经济效益有非常重要的意义[3],而飞灰含碳量和炉渣含碳量是影响锅炉效率的重要数据指标之一。
目前国内热电厂多采用人工检测法、光学检测法等方法进行飞灰含碳量的检测,在线监测多采用灼烧法在线监测装置,但此类方法存在准确度不够和滞后性严重的问题[4]。图1为国内某发电厂的飞灰含碳量在线监测装置测得的数据与试验实测值对比,可以看出存在较大误差。目前国内外对炉渣含碳量在线监测的关注较少,几乎没有相关设备装置用以在线实时测量炉渣含碳量,一般均为人工取渣后进行化验。炉渣由于其排渣过程时间较长,且一般需经烘干研磨后再进行含碳量化验,相较于飞灰滞后性更严重。

图1 国内发某电厂飞灰含碳量在线监测数据与实测值对比
因此,对锅炉飞灰和炉渣含碳量的软测量方法得到了广泛关注,尤其是神经网络方面的研究取得了长足的进展[5]。崔锐[6]等利用灰色关联法对飞灰含碳量影响因素的相关性进行计算,提出了基于L-M(Levenberg-Marquardt)算法优化BP(反向传播)神经网络数据融合技术的飞灰含碳量预测方法;周昊[7]等基于热态锅炉试验数据建立并训练BP神经网络模型,用于预测大型电厂锅炉飞灰含碳量;朱琎琦[8]建立了基于L-M 算法改进的BP-ANN(反向传播人工神经网络)预测模型,包含一个用于预测飞灰含碳量的母模型和三个确定影响母模型的煤质参数偏差的子模型;王月兰[9]等利用减法聚类算法自适应确定初始模糊规则和结构参数,利用最小二乘估计算法和误差反向传播算法构成的混合算法对模糊神经网络的参数进行学习,最终得到飞灰含碳量的模型构建。
本文以我国现有主要动力用煤的燃烧特性数据库及现场试验数据为基础,首先构建以水分、挥发分和发热量等煤质参数为输入参数的神经网络子模型,计算得到表征煤粉燃尽难易程度的煤粉燃尽特性指数。然后以煤粉燃尽特性指数与锅炉运行负荷和炉膛出口氧量作为输入参数,构建计算灰渣平均含碳量的神经网络模型。通过灰渣平均含碳量神经网络模型计算得到灰渣平均含碳量的预测值,可直接用于热电厂的锅炉效率在线性能计算,方便热电厂更好地掌握锅炉的运行状况和经济性指标,提高锅炉运行情况,降低生产成本[10]。
1 CFB锅炉飞灰和炉渣含碳量的影响因素
飞灰和炉渣含碳量受多种因素影响,如煤质、锅炉负荷、锅炉流化风与播煤风的配比等,在神经网络建模过程中,输入参数的选择是否合适对神经网络预测结果的优劣有直接的影响。
1.1 入炉煤煤质
入炉煤的灰分、水分、硫分、挥发分以及低位发热量等因素均会影响灰渣含碳量。灰分和水分会在炉膛内吸收热量,降低炉膛内温度,导致煤粉无法充分燃烧,使飞灰中的含碳量升高。灰分残留物在燃烧过程中会将部分煤粉包裹在内形成炉渣,使炉渣中的含碳量升高[11]。硫分一般不直接影响灰渣中的含碳量,但硫分与煤的煤化程度直接相关,硫分越高,煤的煤化程度越低,更容易燃烧且更易完全燃烧。一般来说,挥发分越高煤粉越容易燃烧,反之则不易完全燃烧,增加灰渣中的可燃物含量。低位发热量表征煤的好坏程度,低位发热量高的煤含碳量相对更高,水分含量相对更低,所以也会对灰渣含碳量产生影响。
1.2 锅炉运行负荷
锅炉运行负荷直接影响炉膛床层温度、流化风和播煤风的风量、给煤量等运行参数[12],这些运行参数会直接或间接地影响煤粉在炉膛内的燃烧情况,而锅炉运行负荷与这些运行参数之间的数据关系相对稳定,可将运行负荷看作众多锅炉运行参数的一个综合值。锅炉运行负荷一般存在一个最佳区间,在此区间内煤粉燃烧较为充分,灰渣含碳量相对较低,过高或过低的锅炉运行负荷都会影响煤粉的燃烧情况。
1.3 炉膛出口氧量
炉膛氧量直接影响煤粉在炉膛内燃烧状况,合适的氧量是保证煤粉在炉膛内燃烧充分的必要条件,氧量过低会导致煤粉无法充分燃烧,氧量过高一般是风量过大,风量过大会导致煤粉在炉膛内停留时间变短,煤粉同样无法充分燃烧[13]。有研究证明炉膛出口氧量会明显影响飞灰、炉渣含碳量和机械未完全燃烧损失值,而且存在最佳炉膛出口氧量[14]。
2 神经网络建模
2.1 BP神经网络
BP神经网络是一种模拟人类大脑结构和思维方式的神经网络,是人工神经网络中使用最广泛也是最重要的模型之一。人工神经网络由大量模拟生物神经元的人工神经元广泛互连而成,这些人工神经元组成了BP 神经网络中广义的输入层、隐藏层和输出层[15]。不同种类的数据通过输入层传递到隐藏层,在隐藏层中进行数据的加工处理,再通过输出层输出结果,神经网络中每层的每个神经单元都有各自的权重值,BP神经网络根据计算输出结果与期望值的误差以梯度下降的方式反向逐层修正各神经单元的权值直到输入层,完成一次迭代。通过多次迭代后将各层各神经元权值调整到合适范围,使输出的结果与期望值的误差符合预期效果或达到设置的学习次数时完成训练[16]。
2.2 煤质燃尽特性指数神经网络模型
2.2.1 输入参数与输出参数确定
由于国内大部分热电厂入炉煤的化验单仅有空气干燥基(以下简称“空干基”)成分数据,出于方便考虑,选择空干基水分Mad、空干基灰分Aad、干燥无灰基挥发分Vdaf、空干基弹筒发热量Qb,ad、弹筒洗液含硫量Sb,ad(在煤质低位发热量大于14.6 MJ/kg 时,默认Sb,ad等于空干基全硫分St,ad)作为输入参数。
煤的燃尽特性指数BR是由煤粉热重试验得到的TGA(热重分析)曲线计算出来用以表征煤的燃尽特性的指标[17],其值与燃尽特性优劣程度的对应关系见表1。相比各种煤质参数,燃尽特性指数BR从热重试验TGA曲线计算获得,能更好地反映煤粉的燃尽程度。因此,本文选择燃尽特性指数作为输出参数,同时作为后续灰渣平均含碳量神经网络建模的输入参数之一。

表1 燃尽特性指数与燃尽程度的对应关系
2.2.2 神经网络中间量确定
神经网络训练数据来源为某实验室燃煤特性数据库,经筛选后共计400组数据,由于数据总量偏小,训练参数集囊括所有数据,随机选取其中40 组测试数据集。经不断调试神经网络模型后,最终确定计算效果较好的数据设置模型。首先对输入参数进行归一化处理,归一化后的范围为[-1,1],设置输入层节点数、各隐藏层节点数和输出层节点数分别为5、5、1;隐藏层设置为3层,各层传递函数分别为logsig、logsig、tansig,采用梯度下降法训练;设置最大迭代次数为1 000,学习速率0.02,训练目标最小误差为10-7,设置训练停止条件为达到最大迭代次数或达到泛化要求(连续6次迭代后误差不下降)。
2.2.3 神经网络训练结果
神经网络建模计算后得到测试集的预测值与期望值以及两者误差如图2 所示,测试集的MAE(平均绝对误差)为0.343 2%,MSE(均方误差)为2.245 8%,RMSE(均方根误差)为1.498 6%。神经网络训练过程中的相关性分析如图3所示,期望值与输出值的相关性较好。

图2 煤质燃尽特性指数神经网络测试集期望值与预测值分布

图3 煤质燃尽特性指数神经网络的相关性分析
2.3 灰渣平均含碳量神经网络建模
2.3.1 输入参数与输出参数确定
飞灰和炉渣含碳量受运行方式影响较大,本文选取对燃烧情况影响较大的锅炉主要运行参数锅炉负荷和炉膛出口氧量,以及上文中通过建立神经网络模型拟合得到的煤质燃尽特性指数作为输入参数。
输出参数确定为灰渣平均含碳量,灰渣平均含碳量由飞灰含碳量、飞灰系数、炉渣含碳量、炉渣系数计算得到,是反平衡锅炉效率计算法中的一个中间过程量,具体计算公式见式(1)。灰渣平均含碳量可以较好地综合表征飞灰和炉渣的含碳量,而且减少了一个神经网络预测输出参数,从而减小了神经网络预测计算的误差。
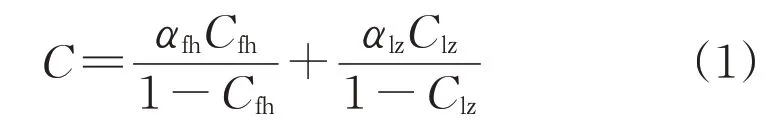
式中:C为灰渣平均含碳量;αfh为飞灰系数;αlz为炉渣系数;Cfh为飞灰含碳量;Clz为炉渣含碳量。
2.3.2 神经网络中间量确定
设置灰渣平均含碳量神经网络模型输入层节点数、各隐藏层节点数和输出层节点数分别为3、4、1;隐藏层设置为3 层,各层传递函数分别为tansig、tansig、tansig,采用梯度下降法训练;设置最大迭代次数为1 000,学习速率0.01,训练目标最小误差为10-7,设置训练停止条件为达到最大迭代次数或达到泛化要求(连续6 次迭代后误差不下降)。
2.3.3 神经网络训练结果
训练后灰渣平均含碳量神经网络的测试集MAE为0.974 7、MSE 为1.504 9、RMSE 为1.226 7。神经网络建模计算后得到测试集的预测值与期望值以及两者误差如图4所示,神经网络训练过程中的相关性如图5所示,可以看出神经网络模型整体训练效果较好。

图4 灰渣平均含碳量神经网络测试集期望值与预测值分布

图5 灰渣平均含碳量神经网络的相关性分析
3 神经网络模型计算结果验证分析
3.1 使用子模型计算结果分析
选择某热电厂的部分锅炉现场性能试验数据代入用以预测煤质燃尽特性指数的神经网络子模型和用以预测灰渣平均含碳量的神经网络母模型进行计算,验证本文中神经网络模型的实际适用性和准确度。某热电厂的几台CFB 锅炉型号均一致,采用单锅筒横置式、单炉膛、自然循环、全悬吊结构、全钢架π型布置,具体锅炉参数设计值见表2。

表2 某热电厂CFB锅炉的设计值
将真实的试验数据先代入煤质燃尽特性指数神经网络模型,获得煤质燃尽特性指数。再通过灰渣平均含碳量神经网络模型计算得到灰渣平均含碳量预测值,与试验获得的灰渣平均含碳量真实值进行对比,如图6所示。灰渣平均含碳量真实值与预测值的MAE为0.84%。

图6 灰渣平均含碳量真实值与预测值对比
将灰渣平均含碳量真实值替换为预测值,得到用灰渣平均含碳量预测值计算的锅炉效率预测值,锅炉效率真实值与预测值的对比如图7 所示,两者的MAE为0.15%。

图7 锅炉效率真实值与预测值对比
3.2 不使用子模型计算结果分析
为了验证煤质燃尽特性指数对灰渣平均含碳量预测值的影响,建立一个直接将各煤质参数作为输入参数的神经网络模型,不使用煤质燃尽特性指数作为中间量,输入参数分别为锅炉负荷、炉膛出口氧量、空干基水分Mad、空干基灰分Aad、干燥无灰基挥发分Vdaf、空干基弹筒发热量Qb,ad、弹筒洗液含硫量Sb,ad,输出参数仍为灰渣平均含碳量。经不断调整神经网络参数完成训练后测试集的MAE 为1.038 0、MSE 为2.183 6、RMSE 为1.477 7。
代入现场试验数据计算得到灰渣平均含碳量预测值与真实值的MAE为1.29%,代入计算得到锅炉效率预测值与真实值的MAE为0.23%。
对比分析使用子模型和不使用子模型的计算结果,数据如表3所示。两个模型的MAE仅相差0.063 3,MSE相差0.678 7,可以认为两个模型训练效果较为接近。但是两个神经网络最后算得的灰渣平均含碳量相差0.45%,代入计算得到的锅炉效率相差0.08%,存在明显差距。通过两个神经网络模型计算结果对比分析可以认为,使用煤质燃尽特性指数神经网络子模型进行灰渣平均含碳量预测计算相较于不使用子模型直接预测计算准确度更高,误差更小。两种情况的灰渣平均含碳量、锅炉效率预测值与真实值对比如图8、图9所示。

表3 使用子模型和不使用子模型计算灰渣含碳量结果对比

图8 两种情况的灰渣平均含碳量预测值与真实值对比
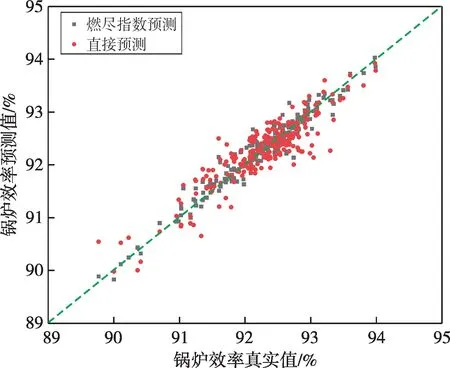
图9 两种情况的锅炉效率预测值与真实值对比
4 结语
1)本文分别建立用以预测煤质燃尽特性指数的神经网络子模型和用以预测灰渣平均含碳量的神经网络母模型,用煤质燃尽特性指数表征入炉煤综合煤质质量,用灰渣平均含碳量代替飞灰含碳量与炉渣含碳量作为输出参数,尽量减少误差。
2)本文中的神经网络训练效果较好,煤质燃尽特性指数神经网络经训练后测试集的MAE 为0.343 2、MSE为2.245 8、RMSE为1.498 6;灰渣平均含碳量神经网络经训练后测试集MAE 为0.974 7、MSE为1.504 9、RMSE为1.226 7。
3)用某热电厂现场试验获得的数据验证神经网络模型,经两个神经网络模型计算后得到灰渣平均含碳量预测值与真实值的MAE为0.84%,用灰渣平均含碳量预测值计算得到的锅炉效率预测值与真实值的MAE 为0.15%,具有较好的泛化性,但仍具优化空间。
4)使用煤质燃尽特性指数子模型进行预测相较于不使用子模型计算得到的灰渣平均含碳量的偏差为0.45%,代入计算得到锅炉效率的偏差为0.08%,证明使用子模型能够有效减小误差。
