结合自注意力特征过滤分类器和双分支GAN的面部表情识别
2022-04-06邹海锋
程 艳 蔡 壮 吴 刚 罗 品 邹海锋
研究表明, 55%的人类情绪表达是通过面部表情传达的[1].表情在人类的日常交际中起到重要作用.面部表情识别作为计算机视觉领域的一个重要研究方向,广泛应用于医疗诊断[2]、智能教学系统[3]、人机交互[4]、驾驶员疲劳检测[5]等领域.早期的面部表情识别任务主要使用基于手工特征的方法.随着深度学习的发展,基于深度神经网络的方法逐渐取代基于手工特征的方法.
基于手工特征的方法包括图像预处理、特征提取、分类器构建等过程,可分为基于几何的方法和基于外观的方法.基于几何的方法提取基于形状变化的面部特征信息[6].Lanitis等[7]提出利用人的眼睛、鼻子和嘴巴的关键位置点计算脸部的运动情况,用于分析面部表达的表情.Tian等[8]开发自动面部分析系统,提取面部特征的详细参数描述,识别面部动作编码系统(Facial Action Coding System,FACS)中的动作单元(Action Unit, AU).局部特征描述符主要包括Gabor滤波器[9]、局部二值模式(Local Binary Pattern, LBP)[10]及各种变体,如局部弧形模式(Local Arc Pattern, LAP)[11].然而,基于手工特征方法的识别结果依赖于手工特征的设计,这些手工特征的设计依赖于大量的先验知识和丰富的经验,大多为特定应用设计的,泛化能力不强,在应用中需人工调整参数,这无疑增加识别难度,并且容易丢失面部表情特征的关键信息[12].
由于卷积神经网络(Convolutional Neural Net-work, CNN)[13]等深度学习模型以端到端的方式自动学习特征,在特征提取上性能较优,因此基于深度神经网络的方法近来广泛应用于面部表情识别任务中.该类方法有效克服基于手工特征方法的缺点,大幅提升识别效果[14].Zhang等[15]为了减轻个人属性对面部表情识别结果的影响,提出IACNN(Identity-Aware CNN),实现身份不变的面部表情识别.Li等[16]针对真实环境中面部表情识别的遮挡问题,提出pACNN(Patch-Based CNN)和gACNN(Global-Local-Based CNN),在真实遮挡和合成遮挡数据集上的实验表明,2种方法都提高遮挡人脸和非遮挡人脸识别的准确率.Zhao等[17]提出MA-Net(Global Multi-scale and Local Attention Network),用于面部表情识别.
但基于CNN的面部表情识别方法从表情中提取的特征容易与其它的面部属性混合,如姿势和外观的变化,影响特征提取的质量,在分类不同的表情时辨别性不强,不利于面部表情识别.针对此问题,Xie等[18]提出基于TDGAN(Two-Branch Disentangled Generative Adversarial Network)的面部表情识别模型,通过双分支分解生成对抗网络(Generative Ad-versarial Network, GAN),将表情从表情图像迁移到面部图像,实现从其它的面部属性分离表情,生成具有辨别性的表情表示.该模型包括一个生成器和两个判别器,但该模型生成器使用CNN提取表情特征.CNN提取的特征值表示每个空间位置检测到的局部特征,由于CNN的局部聚合、归纳偏差,特征值具有有限的感受野,CNN提取的特征容易混入噪声[19],全连接层作为分类器会将这些噪声输入分类器中,对最终的识别结果有一定的影响.TDGAN在参数学习时提出双重图像一致性损失(Dual Image Consistency Loss),使用原图像和重构图像的整体像素计算重构误差[20],当图像整体发生细微变化和局部巨大变化时,计算的差值可能相差无几,这将导致有些生成的图像发生局部表情崩塌现象,即在重要的局部区域(如眼睛)存在缺陷而实际的重构误差并不大.
针对上述不足,本文提出结合自注意力特征过滤分类器和双分支GAN的面部表情识别方法(Fa-cial Expression Recognition Combining Self-Attention Feature Filtering Classifier and Two-Branch GAN, TGAN-AFFC).首先,使用双分支GAN学习辨别性的表情表示,并提出自注意力[21]特征过滤分类器(Self-Attention Feature Filtering Classifier, AFFC)作为表情的分类模块.AFFC使用级联的LayerNorm和ReLU将低激活单元归零,保留高激活单元,生成多级特征,使用自注意力融合输出多级特征的预测结果,在一定程度上消除表情特征中混入的噪声对识别结果的影响,提高识别的准确率.然后,提出基于滑动模块的双重图像一致性损失,监督模型学习具有辨别性的表情表示,减少生成图像表情崩塌现象的发生.在4个公开的面部表情数据集上的实验表明,TGAN-AFFC具有较优的识别效果.
1 结合自注意力特征过滤分类器和双分支GAN的面部表情识别方法
1.1 网络结构
结合自注意力特征过滤分类器和双分支GAN的面部表情识别方法(TGAN-AFFC)框架如图1 所示.

图1 TGAN-AFFC框图Fig.1 Flow chart of TGAN-AFFC
TGAN-AFFC包括两部分:双分支GAN和自注意力特征过滤分类器(AFFC).双分支GAN使用TDGAN[18]提出的双分支分解GAN结构.
TGAN-AFFC同时输入一幅人脸图像If和一幅表情图像Ie.根据GAN的原理,TGAN-AFFC的双分支GAN由生成器和判别器组成.生成器是编码器-解码器结构,由面部编码器Ef、表情编码器Ee、嵌入模块和解码器Dg构成,用于将表情从表情图像的人脸迁移到人脸图像的人脸上,使表情编码器学习具有辨别性的表情表示.判别器是双分支结构,由面部判别器Df和表情判别器De构成,用于评估输入的图像.在表情编码器后,接入AFFC,输入表情编码器学习的表情表示,识别结果作为面部表情识别任务的结果.
1.2 双分支生成对抗网络
受TDGAN[18]工作的启发,TGAN-AFFC的双分支GAN使用TDGAN提出的双分支分解GAN结构,网络参数也相同.双分支GAN由生成器和判别器组成,生成器由面部编码器、表情编码器、嵌入模块和解码器组成,判别器是双分支结构,由面部判别器和表情判别器构成.面部编码器、表情编码器、面部判别器和表情判别器具有相同的特征提取网络,由具有Inception[22]结构的CNN构建,嵌入模块由具有残差块的CNN构建,解码器由反卷积层构建.生成器的目标是通过将表情图像的表情从一张人脸迁移到另一张人脸,学习具有辨别性的表情表示.
双分支GAN输入图像对为{(If,yf),(Ie,ye)},其中,If为输入的人脸图像,Ie为输入的表情图像,yf、ye分别为相应的身份和表情的独热编码标签.将输入图像对输入面部编码器Ef和表情编码器Ee中,输出特征表示为
df=Ef(If),de=Ee(Ie),
其中,df为人脸图像的面部特征,de为表情图像的表情特征.通过嵌入模块融合面部特征df和表情特征de,得到融合后的特征:
dfuse=Emb(con(df,de,dn)),
其中,Emb(·)为嵌入模块,con(x,y,z)为按通道拼接,dn为噪声向量.
融合后的特征dfuse经过解码器Dg生成图像,表示为
Ig=Dg(dfuse)=G(If,Ie,dn),
其中G(x)为整个生成器.
在理想情况下,生成图像Ig应保持和输入人脸图像If相同的面部外观,保持和输入表情图像Ie相同的表情.为了评估生成图像是否满足期望,设计表情判别器De和面部判别器Df,分别判断输入图像的表情和身份.表情判别器De(x)∈Rke,面部判别器Df(x)∈Rkf+1,其中,ke为表情的类别数,kf为人脸数据集的标签数量.面部判别器中额外类的作用是区分输入图像是来自于真实样本还是生成图像.当训练模型时,所有生成图像都将被标记为kf+1类,这使得生成器生成符合人脸数据集分布的图像.
1.3 自注意力特征过滤分类器
使用CNN提取的特征值表示每个空间位置检测的局部特征,由于CNN的局部聚合、归纳偏差,特征值具有有限的感受野,提取的特征容易混入噪声[19],全连接层作为分类器会将这些噪声输入分类器中,对最终的识别结果产生一定影响.受集成方法的启发,Seo等[19]提出FFC(Feature Filtering Cla-
ssifier),由级联的LayerNorm和ReLU、共享的全连接层组成.对于输入特征F0,经过多个LayerNorm和ReLU,生成多级特征,经共享全连接层,生成多级特征的预测结果,最终平均集成多级特征的预测结果,得到最终的预测结果.
输入共享全连接层的多级特征具有不同的语义内容,平均集成平等对待每个预测结果,未考虑多级特征的预测结果对最终预测结果的不同贡献.为了更好地融合多级特征的预测结果并得到最终表情的预测结果,本文结合自注意力机制[21],提出自注意力特征过滤分类器(AFFC),在表情编码器后使用该分类器.AFFC由级联的LayerNorm和ReLU、共享的全连接层和自注意力融合模块组成.
表情编码器学习的辨别性表情表示de输入AFFC,经过L个LayerNorm和ReLU组成的简单特征过滤分类器,将低激活单元归零并保留高激活单元,生成多级特征F0,F1,…,FL.由于操作只使用特征的均值和标准差进行平移和缩放,因此保留每个通道的语义信息.多级特征送入由全连接层构成的共享分类器中,得到每个特征的预测结果Pi.简单特征过滤分类器表示如下:
Fi=ReLU(LN(F)i-1)),Pi=Cls(Fi),
其中,LN为LayerNorm,Cls(x)为全连接层共享分类器.
为了更好地融合多级特征的预测结果,得到最终表情的预测结果,使用自注意力机制[21]学习每个特征预测结果对最终表情预测结果的权重.在自注意力融合模块中,输入多级特征组合的向量矩阵:
F=[F0,F1,…,FL]∈RD×L.
首先,将向量矩阵F进行线性变换,映射到3个不同的子空间,得到3个向量矩阵:
Q=WqF∈RDk×L,K=WkF∈RDk×L,V=WvF∈RDv×L,
其中,Wq∈RDk×D为查询矩阵,Wk∈RDk×D为键矩阵,Wv∈RDv×D为值矩阵.然后计算注意力值:
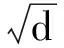
最终,将学习的注意力值attention与多级特征的输出结果矩阵P=[P0,P1,…,PL]的元素相乘,得到最终的表情预测结果:
其中i对应第i个特征.
1.4 模型学习
1.4.1 判别器的参数学习
GAN的训练是先训练判别器,再训练生成器,两者交替迭代.面部判别器的总体损失函数为:
Lf=E(If,yf)~pf[lnDf(If)]+E(Ig,yg)~pg[lnDf(Ig)],
(1)
其中,pf为人脸图像的数据分布,pg为生成图像的数据分布,yg为生成图像的身份标签.在模型的训练中,生成图像仅被送入面部判别器中.通过最大化式(1)优化面部判别器Df.
表情判别器的总体损失函数表示如下:
Le=E(Ie,ye)~pe[lnDe(Ie)],
(2)
其中pe为表情图像的数据分布.通过最大化式(2)优化表情判别器De.
1.4.2 生成器的参数学习
生成器的损失函数包括3部分:分类损失、感知损失、基于滑动模块的双重图像一致性损失.
1)生成器的分类损失.生成器的目标是能生成欺骗2个判别器的图像.生成器的分类损失为:
LC=-{λGfE(Ig,yf)~pg[lnDf(Ig)]+λGeE(Ig,ye)~pg[lnDe(Ig)]},
其中,λGf、λGe为超参数,平衡面部判别器的损失和表情判别器的损失.
2)生成器的感知损失.为了保持输入人脸图像的语义内容不变,引入感知损失,测量2个图像之间的语义内容差异,感知损失定义为
其中,λpf为超参数,df为人脸图像在面部判别器的特征,d(g,f)=Df(Ig),为生成图像在面部判别器的特征.
3)基于滑动模块的双重图像一致性损失.为了更好地监督TGAN-AFFC的训练,提出基于滑动模块的双重图像一致性损失,通过滑动窗口的滑动,逐步计算每个滑动窗口内的像素差值,再对所有滑动窗口中的像素差值取平均.基于滑动模块的双重图像一致性损失过程如图2所示.
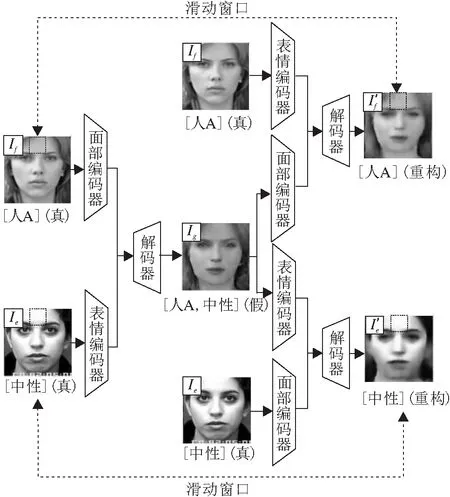
图2 基于滑动模块的双重图像一致性损失流程图Fig.2 Flow chart of dual image consistency loss based on slid module

LD=
其中,λD为超参数,n为滑动窗口的总数.
综上所述,生成器总的损失函数为:
LG=LC+LD+LP.
1.4.3 AFFC的参数学习
TGAN-AFFC通过双分支GAN将表情从一张人脸迁移到另一张人脸,学习具有辨别性的表情表示,识别不同的面部表情.具体地,在优化双分支GAN的同时,使用交叉熵损失函数训练AFFC.AFFC的损失函数为:
2 实验及结果分析
2.1 实验数据集
本文在如下4个公开的面部表情数据集上进行实验.
1)CK+数据集[23].包含从123名对象收集的593个图像序列,每个序列的表情都是从中性表情到峰值表情,只有309个序列被标记成6种典型表情(愤怒、厌恶、恐惧、快乐、悲伤、惊讶)之一.挑选每个序列的最后三帧构建训练集和测试集.此外,每个选定序列的第1帧都被收集为中性表情.实验总共涉及1 236幅面部表情图像.
2)RAF-DB数据集[24].实验中只使用具有基本表情(包括6种典型表情和中性表情)的图像进行实验,其中12 271幅图像作为训练数据,3 068幅图像作为测试数据.
3)BAUM-2i数据集[25].包含不同条件下的面部表情,使用8种表情标签(6种典型的表情+中性+鄙视)进行标记.实验中仅使用7种表情(6种典型表情+中性表情)标记的数据进行实验,共涉及998幅面部表情图像.
4)TFEID数据集(http://bml.ym.edu.tw/tfeid).从40名受试者(20名男性和20名女性)中采集面部表情图像,每位受试者采集8种面部表情(6种典型表情+中性+蔑视).实验中使用6种典型表情和中性表情的面部表情数据,共涉及580幅图像.
2.2 实验设置
本文实验选择PyTorch 1.8.0作为深度学习环境,训练机器使用GeForce RTX 3060.
为了完成表情的迁移任务,面部编码器分支输入的图像应是被身份标注的图像.因此,选择CASIA-
WebFace数据集[26]作为面部编码器分支的输入.TGAN-AFCC的主要任务是表情识别而不是人脸识别,所以只使用CASIA-WebFace数据集上前10个类别的图像作为面部编码器分支的输入,选择的人脸图像共包含1 021幅图像.在模型的训练过程中,一幅面部图像和一幅表情图像分别从CASIA-WebFace数据集和表情数据集中随机采样,两幅图像构成模型输入的图像对.
在数据的预处理阶段,首先通过MTCNN(Multi-
task Cascaded CNN)[27]检测输入图像的脸部区域,获得输入图像的关键点坐标.根据关键点的坐标进行脸部的校正和裁剪,将图像裁剪为140×140×1.在训练阶段,采用随机裁剪和水平翻转的方式进行数据集扩充,随机裁剪后图像大小为128×128×1.为了与其它方法公平对比,在CK+、BAUM-2i、TFEID数据集上进行十折交叉验证实验;在RAF-DB数据集上,使用预先划分好的训练集和测试集进行训练和评估.对于超参数,设置λGf=0.2、λGe=0.8、λpf=1、λD=1.优化器使用自适应矩估计(Adaptive Moment Estimation, Adam)优化器.相对RAF-DB数据集,CK+、BAUM-2i、TFEID数据集数据量相对较少,为了模型训练,在具有287 401幅训练数据的AffectNet数据集[28]上进行预训练.
2.3 对比实验
2.3.1 实验室条件下的实验结果
在实验室受控条件下的CK+、TFEID数据集上进行实验.选择如下对比方法:LAP、IACNN、pACN-
N、TDGAN、PHOG(Pyramid of Histogram of Gradi-
ents)-LBP、Boosting-POOF(Boosting Part Based One-
vs-One Feature)、DeRL(De-expression Residue Lear-
ning)、REC(Self-Organizing Network for Facial Ex-
pression Recognition from Radial Encoded Contours)、LMBP(Local Mean Binary Pattern)、MPC(Meta Pro-
bability Codes)、LGBPHS(Local Gabor Binary Pa-
ttern Histogram Sequence)、CNN-Base,其中CNN-
Base为TGAN-AFFC的表情判别器.
TGAN-AFFC在2个数据集上的混淆矩阵如图3所示.在混淆矩阵中,当所有输入都在受控的环境下捕获时,TGAN-AFFC性能较优.此外,从CK+数据集上的混淆矩阵中可见,在所有7个表情类别中,伤心表情的识别率最低,为89%,近11%的伤心表情归类为中性表情.这是因为在CK+数据集上,部分伤心表情的图像和中性表情的图像在面部区域具有一些相似动作,如嘴巴紧闭、眉毛舒展.所以在网络学习过程中,对于相似度很高的伤心表情和中性表情,学习特征更倾向于中性表情.在TFEID数据集上的混淆矩阵可见,在所有7个表情类别中,厌恶表情的识别率最低,为88%,近12%的厌恶表情归类为中性表情.原因在于:厌恶表情和中性表情在局部的面部区域具有一些类似的面部变化,如嘴巴紧闭.所以在训练过程中,对于相似度很高的厌恶表情和中性表情,训练学习的特征更倾向于中性类别.

(a)CK+

(b)TFEID图3 TGAN-AFFC在CK+、TFEID数据集上的混淆矩阵Fig.3 Confusion matrices of TGAN-AFFC on CK+ and TFEID datasets
各方法在CK+数据集上的准确率如下:CNN-
Base为92.68%,IACNN[15]为94.37%,PHOG-LBP[29]
为94.63%,Boosting-POOF[30]为95.70%,pACNN[16]为
97.03%,DeRL[31]为97.30%,TDGAN[18]为97.53%,TGAN-AFFC为98.49%.
各方法在TFEID数据集上的准确率如下:REC[32]为85.45%,LMBP[33]为90.49%,MPC[34]为92.54%,LGBPHS[35]为93.66%,LAP[11]为95.15%,CNN-Base为96.07%,TDGAN[18]为97.20%,TGAN-AFFC为98.26%.
各方法上的文献序号表示结果引自此文献.
相比TDGAN,在CK+、TFEID数据集上,TGAN-
AFFC的准确率分别提升0.96%和1.06%.原因在于:1)TGAN-AFFC使用基于滑动模块的双重图像一致性损失,能在有局部变化时更准确地计算差值,避免脸部局部区域变化时损失变化不大的情况,使生成器学习具有辨别性的表情表示;2)自注意力特征过滤分类器生成特征的多个版本,使用自注意力融合模块融合多个特征的预测结果,在一定程度上消除特征中混入的噪声,提高表情识别的准确率.相比传统的手工特征方法(LAP、PHOG-LBP、Boosting-
POOF、REC、LMBP、MPC、LGBPHS),TGAN-AFFC在2个数据集上都取得更好的分类效果,这表明神经网络模型在面部表情识别任务上具有更优识别效果.同时,相比基于神经网络的方法(IACNN、pACN-
N、TDGAN、DeRL),基于GAN构建的TGAN-AFFC取得更优效果,在CK+数据集上比DeRL(97.30%)提高1.19%,在TFEID数据集上比CNN-Base(96.07%)提高2.19%.这表明通过GAN,生成器学习的表情表示比基于CNN学习的表情表示更有辨别性.
2.3.2 不受约束条件下的实验结果
为了验证TGAN-AFFC在不受约束条件下的性能,在RAF-DB、BAUM-2i数据集上进行实验.选择如下对比方法:gACNN、MA-Net、TDGAN、DLP-CNN
(Deep Locality-Preserving CNN)、Boosting-POOF、LAP、LPQ(Local Phase Quantization)、3DFM(3D Face Modeling Approach for In-the-Wild Facial Expression Recognition on Image Datasets)、WLD(Multi-scale Weber Local Descriptor)、LMP(Local Monotonic Pattern)、SLPM(Soft Locality Preserving Map)、CNN-
Base.
TGAN-AFFC在RAF-DB、BAUM-2i数据集上的混淆矩阵如图4所示.由图可见,TGAN-AFFC在识别快乐表情时性能最优,在2个数据集上的准确率都超过90%,然而,对厌恶表情和害怕表情不敏感.一方面厌恶表情和害怕表情的样本数量最少:在RAF-DB数据集上,厌恶表情和害怕表情分别只占5.71%、2.31%,而快乐表情占38.83%;在BAUM-2i数据集上,厌恶表情和害怕表情分别占5.11%、6.81%,而快乐表情占24.84%.当面对不同表情类别样本量如此巨大的差距时,很难从不同的表情中平等学习,导致对厌恶表情和害怕表情学习的特征较少.另一方面,选择的面部编码器分支输入的数据集为CASIA-WebFace数据集,该数据集上样本大部分是笑脸,很少有厌恶表情和害怕表情的人脸.由于TGAN-AFFC可从面部数据集和表情数据集中学习,所以TGAN-AFFC能学习更多关于快乐的知识,相比厌恶表情和害怕表情,对快乐表情的识别能力更强.

(c)RAF-DB
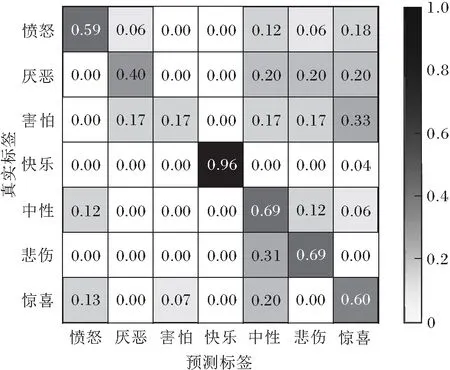
(d)BAUM-2i图4 TGAN-AFFC在RAF-DB、BAUM-2i数据集上的混淆 矩阵Fig.4 Confusion matrices of TGAN-AFFC on datasets RAF-DB and BAUM-2i
各方法在RAF-DB数据集上的准确率如下:Boosting-POOF[30]为73.19%,DLP-CNN[24]为74.20%,CNN-Base为82.92%, TDGAN[18]为83.09%, gA-
CNN[16]为85.07%,TGAN-AFFC为85.21%, 3DF-
M[36]为86.10%,MA-Net[17]为88.40%.
各方法在BAUM-2i数据集上的准确率如下:WLD[37]为54.97%,LMP[38]为57.43%,LAP[35]为58.32%,LPQ[35]为58.99%,CNN-Base为61.46%,SLPM[39]为63.84%,TDGAN[18]为65.76%,TGAN-
AFFC为67.71%.
各方法上的文献序号表示结果引自该文献.
在不受约束条件下,面部表情识别任务因姿态和背景等变化多样而更具有挑战性.在RAF-DB数据集上,3DFM、MA-Net实现较高的准确率,这是因为3DFM、MA-Net的网络架构深于TGAN-AFFC,使方法具有更强大的特征学习能力以处理更复杂的场景.相比TDGAN,TGAN-AFFC在RAF-DB、BAUM-2i数据集上分别提高2.12%、1.95%.这是因为TDG-
AN使用全连接层作为分类器,生成器提取的特征具有一定的噪声,会对最终的识别结果造成影响.TGAN-AFFC使用自注意力特征过滤分类器,使用多个LayerNorm和ReLU生成多级特征,采用自注意力融合输出预测结果,能在一定程度上消除噪声的影响,提高识别率.同时,使用滑动模块计算重构损失,减少表情崩塌图像的生成,通过GAN,生成器学习更有辨别性的表情表示.
2.3.3 自注意力特征过滤分类器的消融实验
为了评估自注意力特征过滤分类器的效果,将TGAN-AFFC与TGAN、TGAN-FFC进行消融实验,结果如表1所示,表中TGAN使用全连接作为分类器,TGAN-FFC使用FFC作为表情分类器.
由表1可知,相比TGAN,TGAN-FFC的准确率在4个数据集上都有所提高,表明FFC通过级联的LayerNorm和ReLU,将低激活单元归零并保留高激活单元,能在一定程度上消除噪声对实验结果的影响,提高识别效果.相比TGAN-FFC,TGAN-AFFC的识别率在4个数据集上都有所提高,表明通过自注意力机制融合多级特征的预测结果,能取得更优效果,验证特征过滤器中引入自注意力机制的有效性.
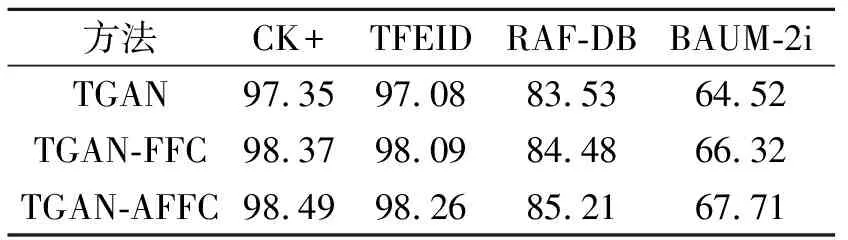
表1 AFFC的消融实验结果
2.4 超参数选取
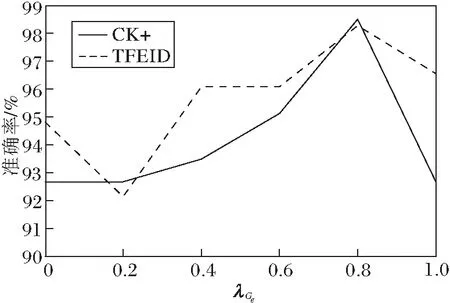
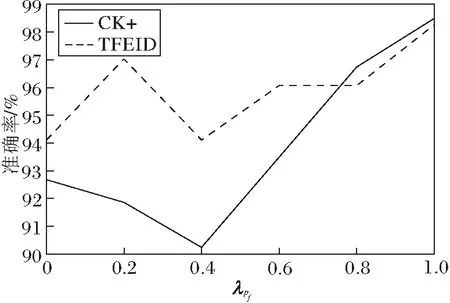
下面通过4组实验研究超参数λGf、λGe、λpf、λD对最终表情识别结果的影响.第1组实验固定λGe=0.8,λpf=1,λD=1,λGf从0变化到1,结果如图5(a)所示.当λGf=0.2时,获得最高准确率.第2组实验固定λGf=0.2,λpf=1,λD=1,λGe从0变化到1,结果如图5(b)所示.当λGe=0.8时,获得最高准确率.第3组实验固定λGf=0.2,λGe=0.8,λD=1,λpf从0变化到1,结果如图5(c)所示.当λpf=1时,获得最高准确率.第4组实验固定λGf=0.2,λGe=0.8,λpf=1,λD从0变化到1,实验结果如图5(d)所示.当λD=1时,获得最高准确率.
由图5可观察到,TGAN-AFFC的准确率随着4个超参数的改变而改变,但不是规律性的变化,原因在于GAN容易发生模式崩溃现象,超参数的改变会影响方法训练效果.

(a)λGf
(b)λGe
(c)λpf

(d)λD图5 超参数改变时TGAN-AFFC在2个数据集上的变化 曲线Fig.5 Curves of accuracy versus different hyperparameters on 2 datasets
2.5 基于滑动模块的双重图像一致性损失
为了评估滑动模块计算重构损失的效果,TD-GAN和TGAN-AFFC在4个数据集上的生成图像如图6所示.由图可看出,相比未使用滑动模块计算重构损失的TDGAN,TGAN-AFFC可避免生成局部表情崩塌的图像.在TFEID、BAUM-2i数据集的图像上,可明显观察到TDGAN生成图像在鼻子、嘴巴区域存在明显畸变,而使用滑动模块计算重构损失的TGAN-AFFC生成图像比TDGAN正常,在姿态变化的条件下,TGAN-AFFC生成图像只出现轻微的畸变.原因在于基于滑动模块的双重图像一致性损失更关注面部的局部区域,能生成更好的图像,在一定程度上表明引入滑动模块计算重构损失可有效避免生成图像的局部表情崩塌现象的发生,验证滑动模块的有效性.

(a)人脸(a)Faces

(b)表情(b)Expressions

(c)TDGAN生成图像(c)Images generated by TDGAN

(d)TGAN-AFFC生成图像(d)Images generated by TGAN-AFFC图6 TDGAN和TGAN-AFFC的生成图像Fig.6 Images generated by TDGAN and TGAN-AFFC
3 结 束 语
本文提出结合自注意力特征过滤分类器和双分支GAN的面部表情识别方法(TGAN-AFFC).使用双分支GAN学习辨别性的表情表示,并提出自注意力特征过滤分类器作为表情的分类模块,有效融合多级特征的识别结果,在一定程度上消除表情表示中的噪声对识别结果的影响,提高表情识别的准确率.提出基于滑动模块的双重图像一致性损失,通过滑动窗口计算损失,更好地监督模型学习具有辨别性的表情表示.在不同数据集上的对比实验验证方法性能.虽然TGAN-AFFC在4个公开的数据集上具有良好的表现,但在真实环境中的应用还有待研究,下一步将围绕该方法的实用性展开深入研究.
