基于区间和灰色关联度的云制造服务匹配方法
2022-04-04马仁杰
马仁杰,陈 军,郭 钢+
(1.重庆大学 汽车工程学院,重庆 400044;2.后勤工程学院 军事供油工程系,重庆 400000)
0 引言
随着21世纪第四次工业革命的到来,制造业得到了高度重视,我国也提出了“中国制造2025”发展计划。云制造利用云计算、大数据、物联网等先进技术将制造资源和能力虚拟化,构建制造服务云平台,实现统一智能化管理[1]。在制造资源集聚后,云制造环境中存在多样化服务,而根据客户需求为客户精准匹配与推荐云制造服务极为重要。
目前,国内外学者已经对云制造服务的匹配推荐展开了大量研究。李慧芳等[2]考虑了服务的类别、状态、功能信息和服务质量(Quality of Service, QoS),基于概念相似度对服务进行了综合匹配;杜易洲等[3]着眼于需求描述方面,采用资源描述框架对制造需求和服务进行表述;AL-FAIFI等[4]提出一种混合多准则决策方法,从智能数据中评估和排序云服务提供商;XUE等[5]提出一种基于计算实验的评价框架来验证服务匹配策略性能;SIMEONE等[6]同时针对多个服务方和需求方,用深度神经网络为客户提供决策推荐;文献[7-9]则均运用了遗传算法进行服务优选。
上述研究均为云制造服务匹配推荐方法提供了参考,由于云制造服务的多样性、属性值的波动性以及需求方的个性化需求,总体的匹配呈现出不确定性,目前常用模糊模型处理该类不确定性问题。文献[10]采用基于直觉模糊集的综合加权方法;文献[11]采用双重犹豫模糊集进行制造商和供应商双边匹配;文献[12]构建了模糊层次分析法和加权总和乘积评估的综合决策模型来评价云服务;文献[13]在粗糙集理论中引入了用户后悔理论;文献[14-16]均采用区间数模型和遗传算法进行服务匹配选择;文献[17]和文献[18]都基于灰色关联分析对服务进行综合评价并选择。
在匹配推荐阶段,上述方法都可以在QoS方面提供决策支持,但少有文献能结合客户的实际需求与实际服务属性值的不确定性形成综合模型。
本文构建了综合的云制造服务匹配推荐模型,依次对服务资源类型、服务资源描述、服务资源QoS进行匹配,其中,QoS匹配考虑了属性的不确定性和需求方偏好,采用了区间数和灰色关联度的方法,最后,本文考虑了用户反馈,形成了匹配闭环。
1 云制造服务模式
1.1 云制造服务平台运行模式
云制造服务和需求的匹配依赖于云服务平台,该平台聚合了各类需求和服务,包含服务方、需求方、运营方3种角色。需求方在平台上发布需求或检索服务,服务方在平台上提供服务,运营方负责平台运营,最终实现在云服务平台上需求方和服务方完成服务资源匹配、选择评价、谈判交易、支付结算等制造资源全过程服务活动。
1.2 云制造信息资源管理模式
在云制造服务平台中,需要对用户信息及各项资源进行管理,以便将信息形式化描述后进行匹配推荐。如图1所示为云制造信息资源管理模式,首先利用分词处理器、同义词字典、语义本体结构树等工具进行需求解析,利用Web服务资源框架(Web Service Resource Framework, WSRF)对资源进行标准化、松耦合、高透明的封装并集成,进而形成需求云和制造云[19]。然后通过映射管理工具将需求云映射到相关度最大的制造云内,从而匹配相应制造资源。
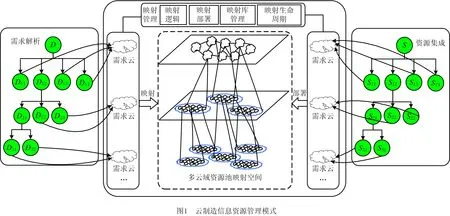
2 云制造服务资源匹配模型
封装后的云制造服务资源有各种属性信息,反映了不同云制造服务的不同特征,为了满足需求方的个性化需求,需要对各类信息进行匹配推荐,基于区间和灰色关联度的云制造服务资源综合匹配推荐模型如图2所示。
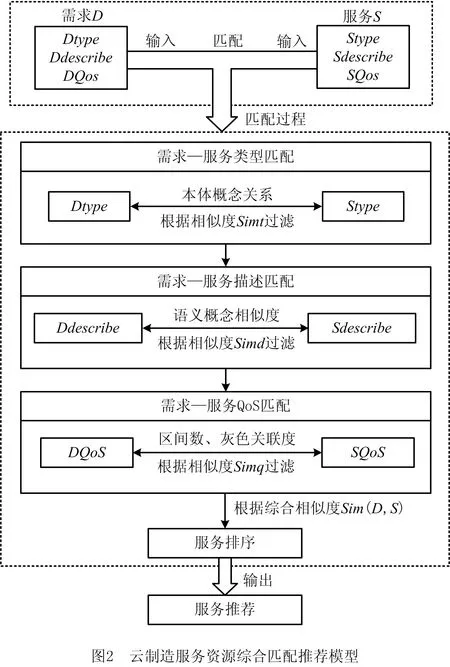
定义服务方提供的服务资源是一个四元组S=(Sbasic,Stype,Sdescribe,SQoS),分别代表提供服务资源的基本信息(如名称、地址等)、类型(如设备、物料、人力等)、描述信息、服务质量(如时间、价格、信誉度等)。类似地,定义需求方的需求是一个四元组D=(Dbasic,Dtype,Ddescribe,DQoS)。具体匹配过程为分别对服务资源类型、描述信息、QoS信息计算相似度Simt、Simd、Simq,每一步需要滤除相似度低的服务,并采用上一步过滤后的剩余服务集合作为输入进行计算,最终用加权方法计算综合相似度Sim(D,S),并做出排序推荐。
3 云制造服务资源匹配算法
3.1 服务资源类型匹配
首先根据需求解析情况,按照资本资源、物料资源、设备资源、技术资源、人力资源、软件资源、物流资源、用户信息资源进行分类,具体细分参考文献[19]。服务本体中概念有5种关系,如图3所示。
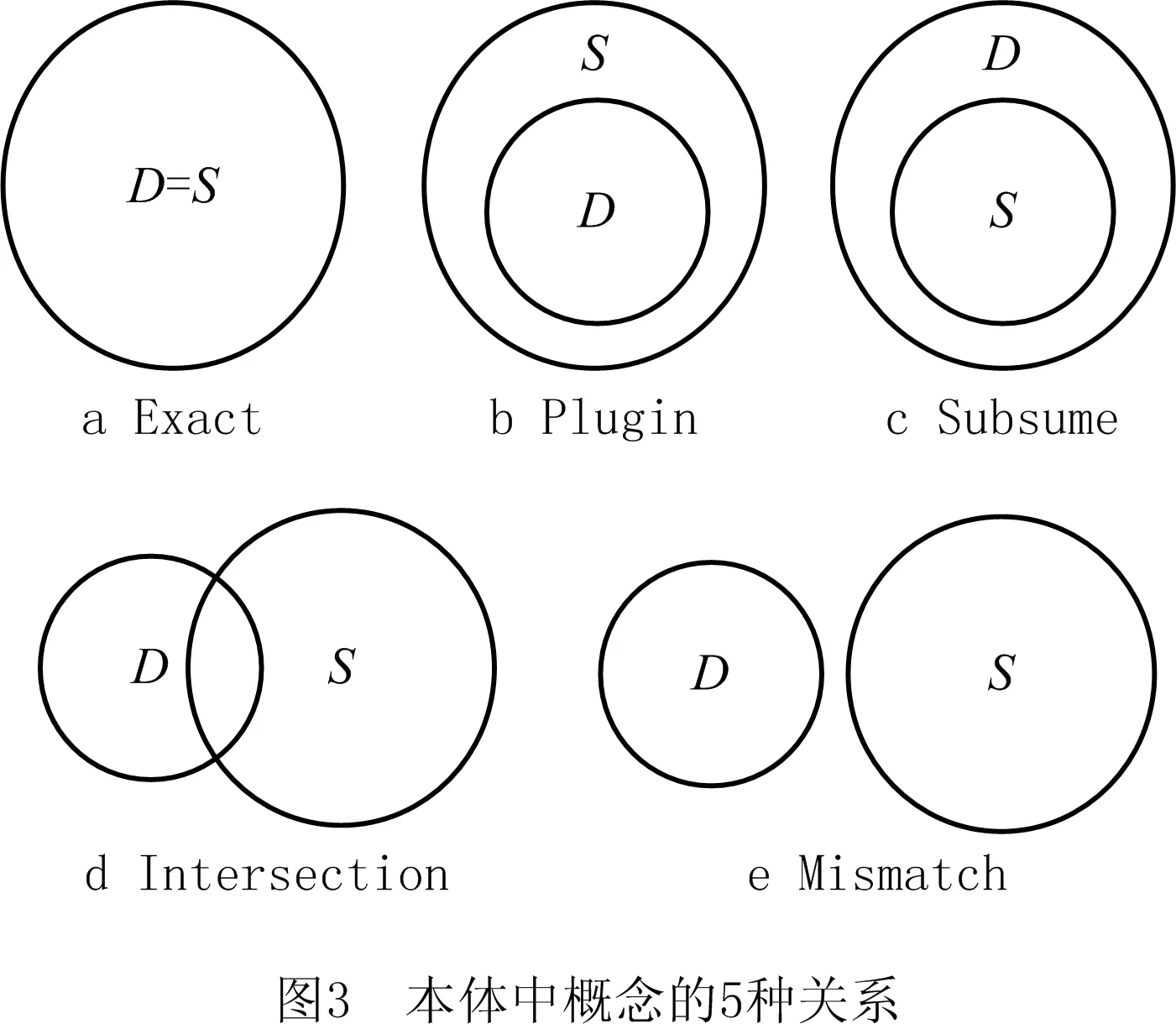
可以利用这5种关系对服务资源类型进行匹配,由此可计算服务资源类型匹配相似度Simt:
Simt=
(1)
当Dtype和Stype为Mismatch关系时,该服务不能满足需求方的需求,因此,在该步骤将该类匹配即Simt=0的服务滤除,并将剩余服务交由下一步的服务资源描述匹配。
3.2 服务资源描述匹配
服务资源描述匹配是对需求名称、具体描述等的匹配,在此之前,需要对需求和服务这类自然语言信息进行解析,通常是对信息进行分词处理得到关键词后,再进行语义或关键词的匹配,如文献[20]通过构建检索关键词规范化模块、分词处理器提取分词、同义词字典规范化关键词对自然语言信息进行解析。常用的分词方法有基于词典的分词方法、基于统计的分词方法、基于理解的分词方法、词典与统计相结合的分词方法[21]。基于词典的分词方法如正向最大匹配算法、逆向最大匹配算法、N-最短路径分词法等具有分词速度快、效率高、容易实现的优点;基于统计的分词方法如N元语言模型、互现信息模型等具有分词更准确的优点,因此可根据实际需求选取方法或将二者进行结合[21]。解析完成后,本文参考文献[2]的语义概念相似度匹配方法对解析后的形式化表达关键词进行匹配,其思想是利用本体结构树将语义距离转化为概念相似度,进而计算出描述匹配相似度Simd。限于篇幅,本文不再赘述相关计算过程。
对集合Ddescribe内的每一个元素,依次计算其与Sdescribe内的每一个对应概念元素的语义概念相似度,并取最大相似度Simmax,若本体结构树中存在对应概念元素且Simmax=0,则滤除该服务,如此遍历Ddescribe内的每一个元素,则服务资源描述匹配相似度
(2)
再滤除Simd小于设定值的服务,将过滤后剩余的服务交由下一步的QoS匹配。
3.3 服务资源QoS匹配
服务资源QoS匹配实质上是多属性决策过程,QoS属性有多种,属性值量纲不一且存在波动,区间数通过用区间表示数,展现一个闭区间上所有实数集合,因此可以用区间数来体现属性值的波动不确定性,从而使属性信息更真实。此外,传统的逼近理想解排序法(TOPSIS)和欧氏距离的应用仅能反映数据曲线的位置关系,但不能反映数据序列的态势变化,因此可以引入灰色关联分析方法,以数据序列的几何相似度即数据曲线相似度来衡量序列之间的关联度,如果方案与理想方案的灰色关联度越大,就可认为方案越接近理想方案[22]。此时,若引入需求方主观偏好代替理想方案,匹配结果将更贴近用户的真实需求偏好。因此本文采用基于区间数和灰色关联度的决策方法,考虑了属性值波动情况和需求方偏好,使匹配结果最大程度地反映真实情况。
步骤1构建QoS客观偏好矩阵。
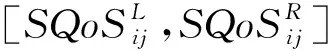
(3)
该矩阵可以看作是基于服务方QoS属性值的客观偏好矩阵,反映了客观情况下的QoS情况。
步骤2对客观偏好矩阵规范化。
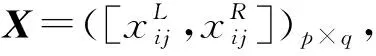
对于效益型属性:
i=1,2,…,p;j=1,2,…,q。
(4)
对于成本型属性:
i=1,2,…,p;j=1,2,…,q。
(5)
步骤3构建QoS主观偏好矩阵。
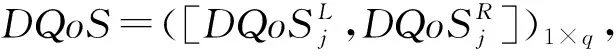
(6)
步骤4建立灰色关联系数矩阵。
灰色关联系数计算如下:
(7)
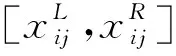
步骤5建立优化模型并求解权重。
第i个服务的QoS匹配相似度计算模型如下:
(8)
考虑到应使Simq尽可能大,即灰色关联度尽可能大,由此可建立多目标规划模型:
(9)
由于各服务方案公平竞争,不存在任何偏好关系,可将多目标优化模型转化成单目标优化模型:
(10)
解上述单目标优化模型,可以得到不同QoS的权重ωj。
步骤6计算QoS匹配相似度。
将步骤5得到的所有权重ωj代入式(8),求得每个服务加权后的灰色关联度,即QoS匹配相似度Simq。滤除小于设定值的服务,再将过滤后剩余的服务交由下一步的服务资源匹配综合相似度计算。
3.4 服务资源匹配综合相似度计算
计算得到服务资源类型匹配相似度Simt、描述匹配相似度Simd、QoS匹配相似度Simq后,需要根据式(11)计算服务资源匹配综合相似度Sim(D,S):
Sim(D,S)=α×Simt+β×Simd+γ×Simq。
(11)
式中α、β、γ为综合匹配的权重系数,需满足α+β+γ=1,且α≥0,β≥0,γ≥0。
综上,根据求出的剩余服务的综合匹配相似度Sim(D,S)大小,对服务进行降序排序,并将排序后的服务输出给需求方,作为服务推荐。
3.5 用户反馈调整
用户反馈是需求与服务匹配推荐环节中闭环控制重要的一环,在本文匹配推荐方法的QoS方面,根据调整内容可分为主观QoS反馈和客观QoS反馈。
(1)主观QoS反馈
主观QoS反馈是指在需求方得到推荐结果且未选择所需服务时,对排序结果的进一步反馈调整优化。若需求方对排序结果不满,可通过调整3.3节中步骤3的QoS主观偏好矩阵或对应权重重新优化排序。此外,需求方也可以对推荐后得到的服务某一QoS值降序排序,从而进一步优化排序结果。
(2)客观QoS反馈
客观QoS反馈是指需求方已经选择了目标云制造服务且服务使用完成后需求方提供的反馈,体现了用户对服务的满意度,主要是对服务客观QoS值的反馈调整。设对于某一服务的某个可评价客观QoS共有t个需求方做出评价反馈,分别对应客观QoS反馈值FBQoS1,FBQoS2,…,FBQoSt,则此时该服务的该项Qos值应更新为:
(12)
由此通过主观和客观QoS反馈机制对服务QoS实行闭环实时调整,同时考虑需求方的满意度,使其具有时效性。
4 算例验证
为了说明该云制造服务匹配推荐算法模型的合理性和有效性,以发动机相关的2 000个云制造服务为例进行验证。
假设需求方的需求是一个三元组,即D=({Dtype:成品},{Ddescribe:活塞销,低碳钢,数量,硬度,表面粗糙度},{DQoS:时间,价格,鲁棒性,信誉度}),设需求方对不同QoS的权重集合W={[0.2,0.3] [0.2,0.3] [0.2,0.3] [0.2,0.3]},需求方对类型、描述、QoS匹配的权重分别为α=0.3,β=0.4,γ=0.3,为便于比较,此处假设需求方的主观偏好矩阵为Y=[[1.0,1.0] [1.0,1.0] [1.0,1.0] [1.0,1.0]]。
设服务方提供的服务有2 000个,部分信息如表1所示。
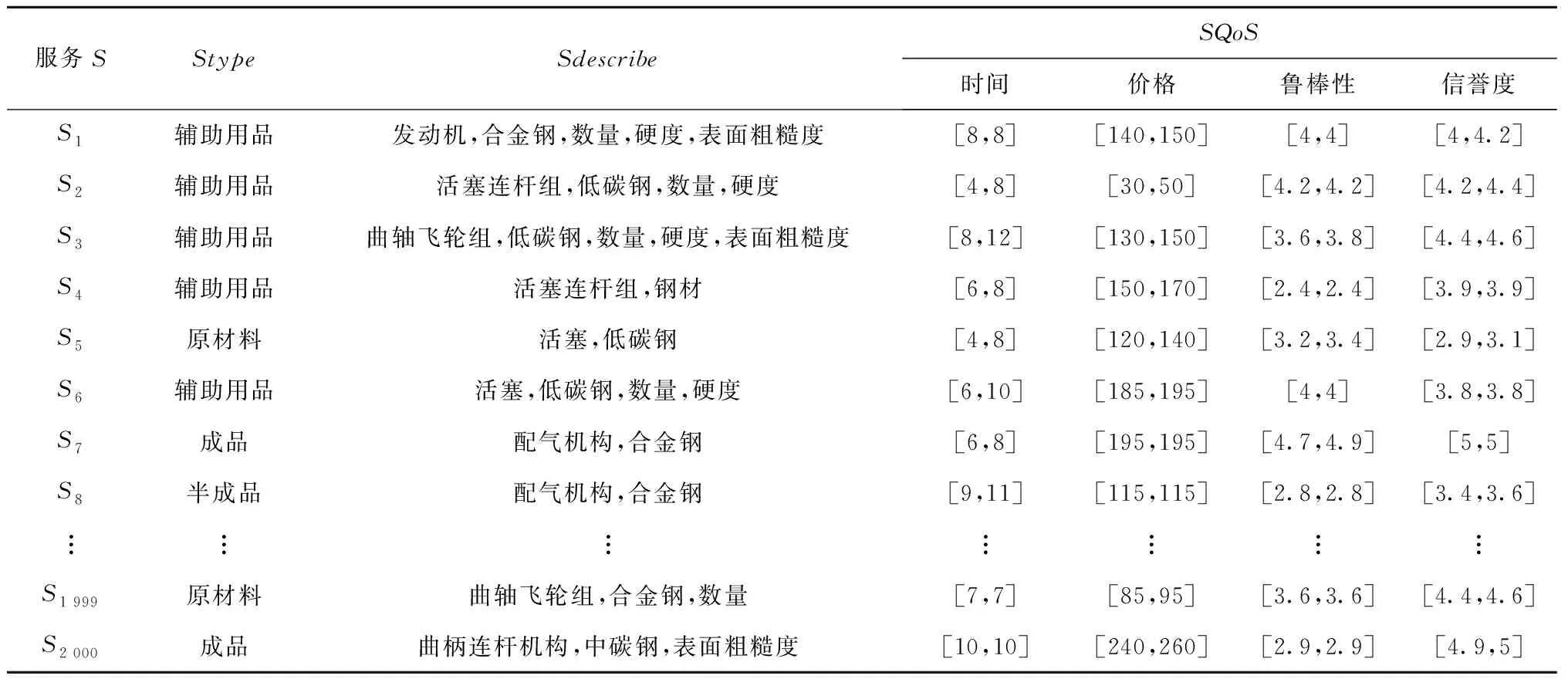
表1 服务方所提供服务的属性信息
步骤1服务资源类型匹配。
根据图3和式(1)计算服务类型匹配相似度Simt,由于Dtype为成品,与Stype的成品为Exact关系,与物料资源为Plugin关系,故Simt=1;而成品与原材料、辅助用品、半成品均为Mismatch关系,故Simt=0。然后滤除计算结果为0的服务,并将剩余的881个服务组成的服务集合作为步骤2描述匹配的初始服务集合。
步骤2服务资源描述匹配。
本文参考文献[1]给出的发动机本体结构树,根据文献[2]的方法计算得到发动机语义概念相似度,如表2所示。同理可得材料信息语义概念相似度,数量、硬度和表面粗糙度则采用布尔值进行计算。
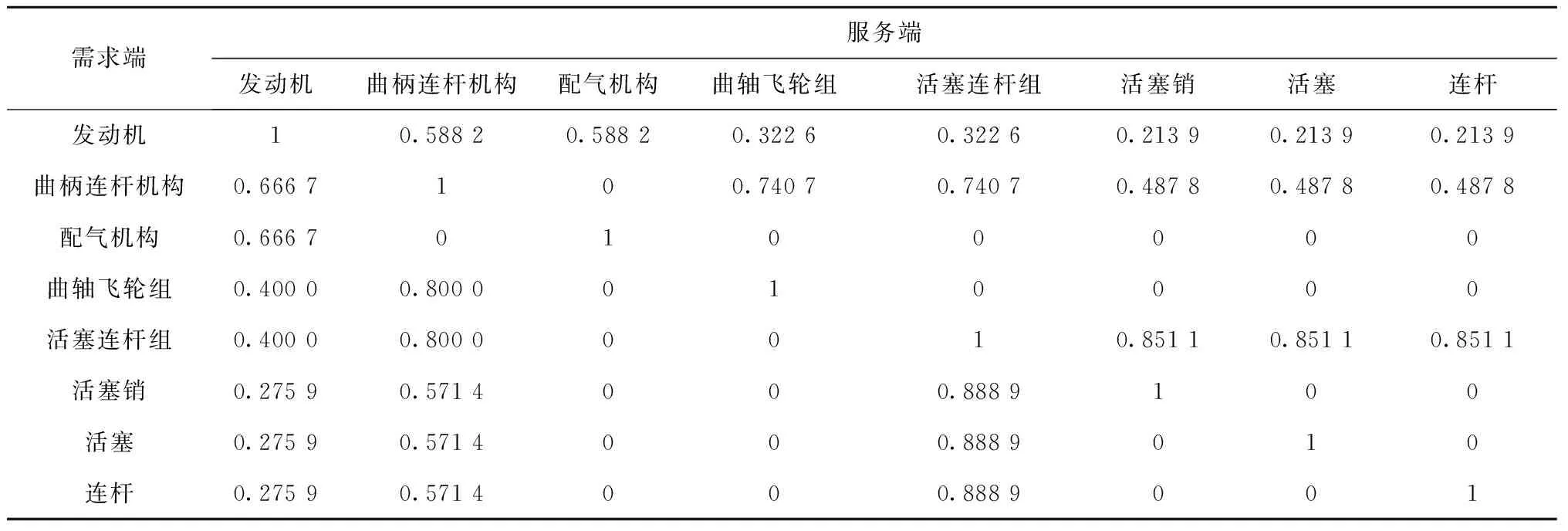
表2 发动机语义概念相似度相关数据
最终由式(2)计算得到Simd,假设描述匹配相似度设定值为0.6,滤除小于0.6的服务,并将剩余的201个服务组成的服务集合作为下一步QoS匹配的初始服务集合。
步骤3服务资源QoS匹配。
对201个服务的QoS属性按照3.3节的步骤计算QoS匹配相似度,最终求得单目标优化模型的权重为ω1=0.2,ω2=0.2,ω3=0.3,ω4=0.3,并得到服务的Simq值。设QoS匹配相似度设定值为0.6,滤除小于0.6的服务,并将剩余的62个服务组成的服务集合作为下一步综合相似度计算的初始服务集合。
步骤4服务资源匹配综合相似度计算。
根据式(11)计算综合相似度,计算得到上述62个服务的综合相似度,如表3所示。对该62个服务进行降序排序后得到返回的服务资源集合为{S1 030,S388,S120,S1 899,S1 761,S1 930,S1 591,S992,…,S752,S1 325,S1 418},并将该集合作为输出推荐给需求方。

表3 综合相似度计算结果

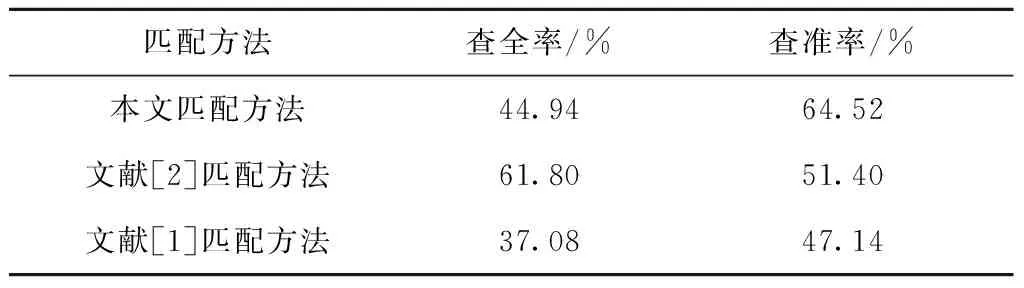
表4 不同算法服务匹配推荐结果比较
通常情况下,查准率越高,查全率就越低,文献[2]由于并未对QoS匹配结果进行筛选,导致其所得服务较多,故其查全率较高,而实际情况下其查全率和查准率会更低。文献[1]由于采用了聚类的方法,容易将一些顾客能接受的处于聚类边缘的服务误分类,导致其查全率和查准率较差。因此,综合比较来看,实际情况下本文匹配方法的查全率和查准率相对较高。
云制造环境下的服务数量存在变化,因此,本文还分析了不同服务数量情况下的查准率和查全率,并与文献[1]和文献[2]进行了对比,结果如图4和图5所示。
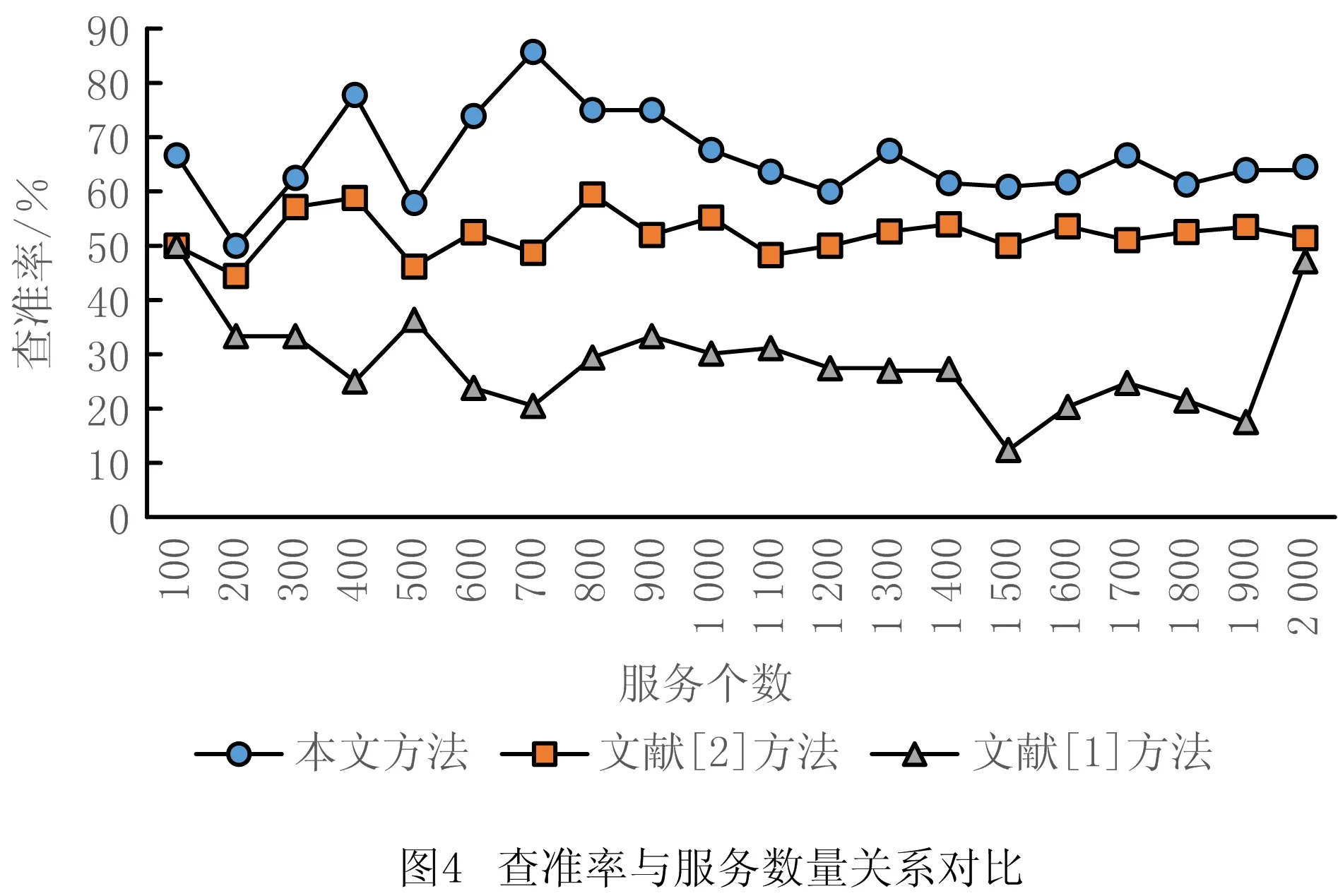
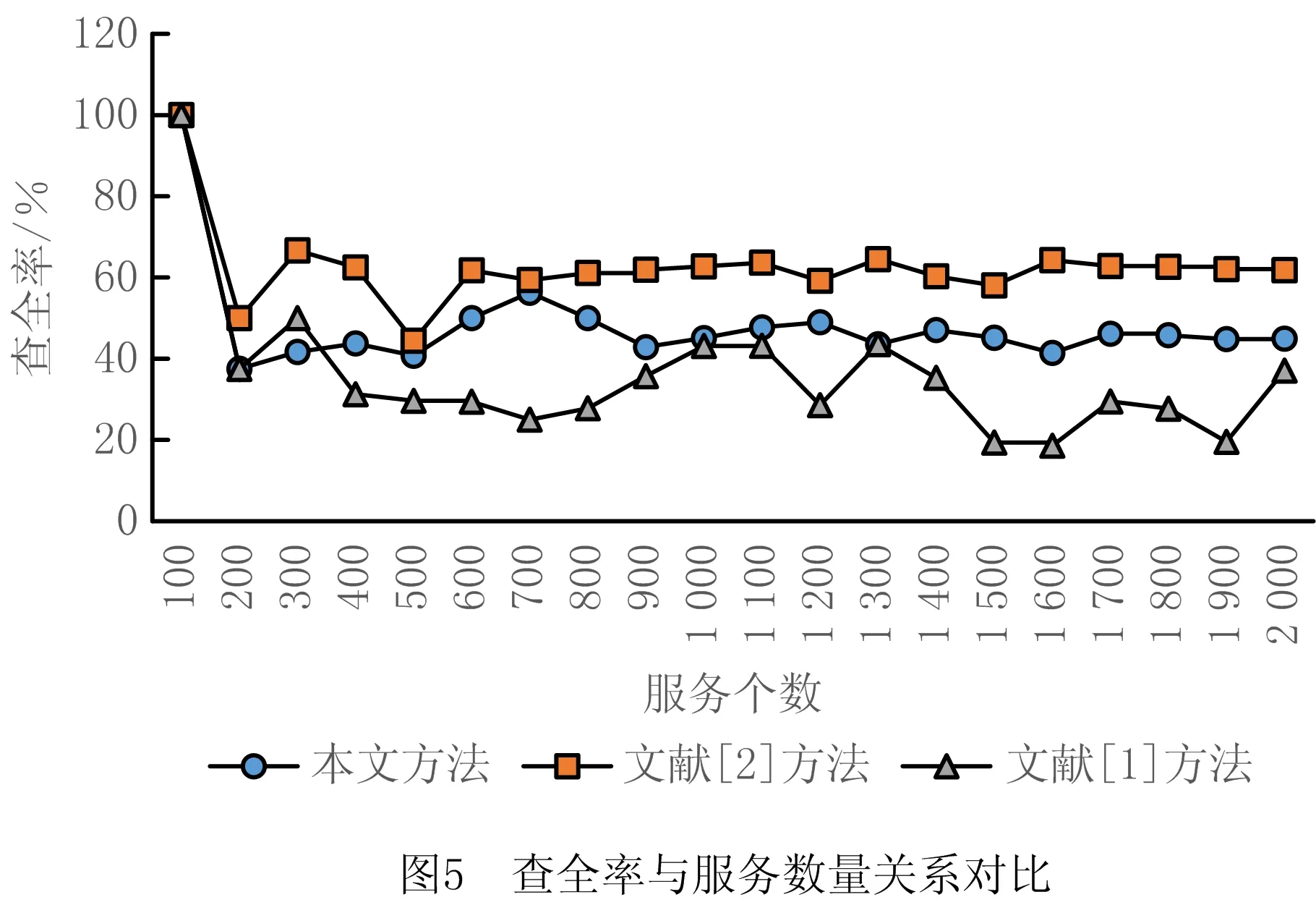
可以看出,在不同服务数量情况下,本文匹配方法的查准率普遍高于文献[1]和文献[2]的方法,查全率和文献[2]差别不大,但优于文献[1]。此外,文献[1]的波动较大,而本文随着服务数量的增加,查准率和查全率趋于平稳,更符合云制造情况下的海量数据情形。
此外,用户可以根据自身需求选择主观偏好矩阵Y和权重,并进行QoS反馈调整,从而避免筛选得到某些用虚假信息或非正常价格产品博人眼球的服务,因此,本文匹配方法允许需求方通过设定区间喜好滤除这类某一方面过于极端化的服务,使需求方更好地选择综合最优的服务。
综上所述,本文基于区间和灰色关联度的云制造服务资源综合匹配推荐方法有效,且相对其他文献查全率和查准率得到了改善。此外,区间数表示更能彰显实际情况的不确定性,引入的需求方主观偏好能使推荐结果符合需求方真实需求,以达到选择综合最优的目的。
5 结束语
本文考虑了实际情况下云制造服务需求方的个性化需求和服务属性值的不确定性,介绍了云制造服务模式和匹配推荐模型,提出了一种基于区间和灰色关联度的云制造服务资源综合匹配推荐方法。该方法总体上分为服务资源类型匹配、描述匹配、QoS匹配、综合相似度计算、用户反馈调整5个步骤。其中,服务资源类型、描述、QoS匹配步骤需要对服务进行过滤,滤除不满足设定值的服务,并将剩余服务交由下一步骤。最后,通过算例验证说明了本文算法的有效性,并通过对比实验显示了本文算法准确率高、稳定性好,且能反映实际情况下需求方的个性化需求,同时考虑了服务属性值的波动不确定性和匹配的闭环控制。本文之后的工作首先将在QoS评价指标中开展,着重研究QoS指标的选取;然后再对QoS匹配算法进行深入研究,考虑在QoS匹配中引入三角模糊数或隶属度函数,以求改进现有算法;最后考虑将整个云制造服务资源匹配算法应用到实际的云制造服务平台中,探讨其在实际应用中的可行性与实用性。
