基于情境感知生成对抗网络模型的工程知识推荐方法
2022-04-04王临科蒋祖华牛建民黄咏文李心雨
王临科,蒋祖华+,牛建民,黄咏文,李心雨
(1.上海交通大学 机械与动力工程学院,上海 200240;2.上海船舶工艺研究所,上海 200032;3.上海外高桥造船有限公司,上海 200137;4.东华大学 机械工程学院,上海 201620)
0 引言
在知识经济时代,知识作为企业的重要资产和无形生产要素,对提升企业生产效益、实现企业创新发展至关重要。随着信息技术的快速发展和普及应用,越来越多知识密集型企业开始重视知识管理(Knowledge Management, KM),并搭建知识管理系统(Knowledge Management System, KMS),以建立组织记忆(Organization Memory, OM),实现对企业知识信息的高效储存与重用[1]。KMS通过知识拉取和知识推送协助用户进行知识重用[2]。知识拉取是指用户通过输入检索信息查找所需知识,这是目前用户获取知识的主要途径;而知识推送是指KMS主动将相应的知识在正确的时间推送给所需的用户[3],是一种知识找人的方式。随着KMS中知识的不断积累,用户通过KMS进行知识拉取会遇到知识迷航的问题,难以快速获取所需知识。对此,知识推送能够主动为用户寻找所需知识,有效缓解知识迷航问题,在知识拉取的基础上进一步提升KMS的知识供应能力[3]。传统知识推送方法主要分为基于用户/任务需求[4-7]和基于流程/事件驱动[8-10]两种,前者基于对用户需求[4,5]或任务需求[6-7]的规范化表征进行相应知识的匹配,后者则通过对流程/事件建模[8]或挖掘知识序列模式[9-10]进行知识推送。依赖于知识表示和建模的传统知识推送方法虽然能充分利用领域特征实现较为精准的推送,但由于方法自动化程度低、扩展性差、应用门槛高、知识推送效率低等问题,阻碍了此类技术的发展和应用。对此,自动化程度高、扩展性强,且发展更为成熟的个性化推荐算法为知识推荐提供了新思路[11]。
个性化推荐算法是一种高效的信息过滤工具,能够有效解决信息资源数量成倍增长导致的信息超载问题。通过对用户个人信息、历史行为信息的分析,个性化推荐算法能够学习并预测用户兴趣,进而向用户推荐相应的项目[12]。现有针对个性化推荐算法的研究主要集中于两方面:①如何准确构建用户画像(User Profile);②如何基于用户画像进行推荐。用户画像是用户真实数据的虚拟表示,是基于人口统计学特征、社交关系、行为模式等信息的用户模型,其主要构成要素包含用户的稳定因素(如个人基本背景信息)和可变信息(如用户兴趣偏好信息)[13],其中,对用户兴趣的挖掘是构建用户画像的核心和关键。AMRITKAR等[14]利用用户浏览行为数据和领域知识构建了增强的用户兴趣模型。DHELIM等[15]基于用户—主题异构网络图实现对用户兴趣的协同过滤预测,并通过向用户兴趣模型中引入性格特征来解决新用户冷启动问题。为更全面地挖掘用户兴趣,梁野等[16]构建了变权分层激活扩散模型,利用知识关系网络对用户兴趣进行语义扩展。总之,用户画像就是要利用用户历史行为数据、社交关系网络、语义网络等挖掘用户个人兴趣偏好特征,并将其表征为用户兴趣标签、评分矩阵等形式。基于构建的用户画像,推荐算法的任务是向目标用户推荐其未交互过但可能感兴趣的项目,通常的做法是首先预测目标用户对所有未交互过的项目的兴趣评分,然后根据预测评分排名进行Top-N推荐[17]。对评分的预测常用基于内容相似度计算[18]或基于相似用户进行协同过滤[19]等方法,然而,历史评分数据不足造成的稀疏矩阵问题和无法获取新用户评分数据造成的冷启动问题将使相似度计算失真[20],进而降低推荐准确度。
针对传统推荐算法遇到的稀疏矩阵和冷启动问题,学者们提出了聚类[21]、矩阵分解[22]以及基于深度学习模型[23]等方法。其中,深度学习模型中的深度神经网络(Deep Neural Network, DNN)不仅能够学习用户或项目的潜在特征表示,还能通过学习用户与项目之间复杂的非线性映射关系进行推荐,从而解决稀疏矩阵和冷启动问题[24]。生成对抗网络(Generative Adversarial Network, GAN)是近年来复杂分布上无监督学习最具前景的方法之一,已被应用于多个信息检索与推荐任务中。GAN由生成模型G和判别模型D组成,在基于GAN的推荐算法中,利用G和D的对抗训练能够学习用户的历史评分数据分布,进而根据预测评分排名进行推荐。WANG等[25]提出了信息检索生成对抗网络模型(Information Retrival GAN, IRGAN),基于GAN对抗训练的思想将生成式检索模型和判别式检索模型统一在对抗训练的大框架下,并将该模型应用于Web搜索、物品推荐与问答等任务中。CHAE等[26]提出了协同过滤生成对抗网络模型(Collaborative Filtering GAN, CFGAN),创新性地利用用户评分向量进行协同训练,很好地解决了IRGAN中由于使用离散数据进行训练造成的无法使用梯度下降更新模型的问题,并引入随机负采样技术,以解决由于数据稀疏引发的单类协同过滤问题。KRISHNAN等[27]利用对抗训练策略增强了神经网络协同过滤模型的长尾物品推荐能力。WANG等[28]基于条件生成对抗网络提出一种数据增强模型AugCF,通过对原始评分数据集“足够真实”的扩充来解决稀疏矩阵问题。
随着企业信息化程度的不断提高,信息沉淀与知识积累的速度会不断加快,将自动化程度高且性能优良的推荐算法用于企业知识的智能推荐具有现实意义。然而,知识推荐依赖于知识的表示、推理以及工程语义信息和情境信息[4],要想使推荐算法具有理想的知识推荐性能,还需要使其与领域特征相结合[6]。对此,本文提出一种基于情境感知生成对抗网络模型的工程知识推荐方法(Context-aware GAN-based Knowledge Recommendation, CGKR),将用户情境信息和任务情境信息融入GAN模型的协同训练中,以满足用户在不同任务情境下个性化的知识需求。
1 CGKR方法框架
基于情境感知生成对抗网络模型的知识推荐方法(CGKR)框架和关键技术如图1所示。根据用户对项目的评分进行推荐是推荐算法常用的方式,推荐算法的任务就是利用已有评分数据预测缺失评分数据,并保证用于预测的模型在已有数据上误差最小。CGKR方法即利用数据挖掘手段构造融合情境信息的用户情境评分向量(context rating vector)RC,并将其作为情境感知生成对抗网络模型(Context-awar GAN, CxtGAN)的训练集,通过CxtGAN中生成模型G和判别模型D的对抗训练,使G学得现有用户情境评分向量RC与预测用户评分向量(predicted rating vector)RP之间的映射关系f,最终利用训练后的G进行推荐。CGKR方法的应用主要分为数据挖掘和CxtGAN训练两个阶段,为表述方便,本文分4部分进行介绍。

(1)数据预处理(data pre-processing) 数据挖掘阶段的主要任务是全面探知用户兴趣,利用用户历史浏览行为数据建立用户兴趣模型是推荐领域的常用方法,除此之外,用户对知识的兴趣与其自身背景和面临的工程任务也密切相关[4]。因此,分别对每个用户U的个人信息、近期检索输入信息与历史浏览行为信息进行处理分析,进而分别构造用户情境向量(background context vector)CB(U)、任务情境向量(task context vector)CT(U)与历史评分向量(historical rating vector)RH(U),其中CB(U)和CT(U)可拼接成工程情境向量(context vector)C(U)。
(2)语义激活扩散模型(Semantic Spreading Activation Model, SSAM)RH(U)中已有的少量评分数据能够反映出用户U的部分真实兴趣,但由于信息不对称性和个人知识局限性[29],仍有大量评分数据缺失,导致评分矩阵极其稀疏。因此,充分利用工程语义信息与用户群历史浏览行为数据构建知识相关性网络GI,进而根据激活扩散模型[16](SAM)扩展RH(U)得到语义扩展评分向量(semantic extending vector)RE(U)。
(3)情境感知生成对抗网络模型(CxtGAN) 利用每个用户的CB、CT与RE拼接即可得到情境评分向量RC,虽然通过语义扩展能够缓解稀疏矩阵问题,但由于用户数量远小于知识数量,此时的RC中仍有大量缺失评分数据。为更好地解决稀疏矩阵问题,引入GAN模型,利用所有用户的情境评分向量RC进行协同训练,使G学得所有用户的RC与RP之间的映射关系f,即可利用G进行推荐。
(4)工程知识推荐(Recommend) 由于用户对知识的兴趣在短期内保持相对稳定,可以利用训练过的生成模型G进行推荐。输入目标用户U的情境评分向量RC(U),G输出对应的预测评分向量RP(U),从RP(U)中选取用户U未浏览的评分Top-N项知识文档推荐给用户U。
2 CGKR方法具体实现
2.1 数据预处理
CGKR方法主要通过挖掘用户个人信息和用户历史行为数据探知用户兴趣。企业KMS中集成了人力资源管理系统,其中记录了每名用户的详细个人信息,从中选取可能影响用户知识兴趣的7项信息(如表1)用于构造用户情境向量。

表1 用户个人信息属性
KMS的后台用户日志中记录着所有用户的操作记录,从中整理出用户的检索输入信息与点击浏览行为数据,如表2所示,并将用户浏览行为序列数据表示为向量形式,如式(1)所示:
Rn(U)={(Q,I,ΔT)1st,(Q,I,ΔT)2nd,…,
(Q,I,ΔT)nth}。
(1)
基于现有数据,利用相关自然语言处理技术与数据挖掘方法,完成对用户情境、任务情境的规范化表征与用户兴趣评分的计算。

表2 用户行为记录数据
2.1.1 用户情境规范化表征
用户的年龄、性别、学历、专业信息决定了用户的知识水平与学习能力,而部门、职务、工龄信息能够影响用户的知识兴趣,因此本文选取这7个属性来表征用户情境,采用数字枚举的形式对各个属性值进行编码(如表1),进而将用户情境表征为包含7个元素的向量,如式(2)所示:
(2)
电商领域推荐系统中,用户的隐私保护意识较强,通常不愿意填写太多个人基本信息。但企业KMS中集成了人力资源管理系统和项目管理系统,可以获取每个用户的个人信息,即拼接了用户情境向量CB的情境评分向量RC一定非空,在训练CxtGAN时能够产生相应的梯度,这使得G生成的预测评分向量RP一定非空,进而解决了新用户冷启动问题。
2.1.2 任务情境规范化表征
工程用户的知识兴趣一般与其执行的工程任务和遇到的工程问题高度相关,因此,对用户近期工程任务情境的表征有助于有效探知用户的知识兴趣。当用户遇到问题时,通常会根据自己的认知选取相关的关键词或短语作为检索式进行知识查询,即用户近期的检索式内容能够反映用户的检索意图和知识兴趣,因此,可以利用用户近期的检索式信息表征用户当前的任务情境。
本文采用开源工具包gensim中的Word2Vec模型进行词向量表征,如图2a所示。用所有知识文档作为语料训练Word2Vec模型,输入层x为目标词语的one-hot编码向量,输出层y1,…,yj分别为目标词语的j个上下文词语的one-hot编码向量,训练过程中不断更新隐藏层h的神经元权重。模型训练完成后,将原隐藏层作为输出层,即可将目标词语映射到h-dim维空间。
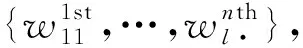

(3)
利用式(3)计算出每个关键词w的重要度,然后从中选出重要度最高的k个关键词{w1,…,wk},并依次用Word2Vec模型映射为k个h-dim维的向量{h1,…,hk},若w不在语料库Corpus中出现,则无法用Word2Vec模型进行映射操作,本文采用[0,1]范围内的随机向量进行代替。最终,拼接{h1,…,hk}得到任务情境向量CT。

2.1.3 基于用户兴趣模型的历史评分向量构造
用户根据需求查找并浏览感兴趣的知识,其浏览行为数据能够反映用户兴趣。考虑到用户兴趣随时间不断变化,过早的浏览行为无法反映用户当前的兴趣,因此,取式(1)中的最近L次浏览数据建立用户兴趣模型,计算用户U对知识文档I的评分,如式(4)所示。
RL(U)={(Q,I,ΔT)n-L+1th,…,(Q,I,ΔT)nth},
(4)
其中:1/(n-k+1)是兴趣的时间衰减因子,|Ikth|为知识文档的文本长度,count(RL(U),I)为RL(U)中I被重复浏览的次数。式(4)利用重复浏览次数和浏览时长作为限定条件[16],若I未在RL(U)中出现,则将评分置为∅,这是因为用户未浏览的评分可能是因为不喜欢,也可能是因为喜欢但还未找到,若I仅在RL(U)中出现一次,且用户浏览时长不超过30 s[9],则将评分置为0,表示用户对该知识不感兴趣,为0的评分数据作为负样本,解决CGKR方法中由于使用稀疏评分向量训练CxtGAN模型造成的单类协同过滤(One-Class Collaborative Filtering, OCCF)问题[26]。利用式(4)计算用户U对所有知识文档的评分,即可构造用户历史评分向量RH(U)。
2.2 语义激活扩散模型
为避免过早的浏览行为数据成为噪声影响评分准确性,式(4)中L的取值不可能过大,使得用户历史评分向量RH中仅有少量的评分数据,进而导致稀疏矩阵问题。考虑到工程领域知识文档间具有一定的关联性,本文引入激活扩散模型(SAM),通过构建的知识相关性网络GI对RH中的初始评分进行扩展,以缓解稀疏矩阵问题。
2.2.1 知识相关性网络
知识相关性网络GI中,节点为知识文档,带权边表示两条知识文档I1和I2间的相关性大小。在计算知识相关性时,同时考虑两条知识文档间的内容相似度和任务相似度。
(1)知识内容相似度计算 对于每个知识文档,依次进行分词、去除停用词、同义词融合等预处理,然后使用TF-IDF(term frequency-inverse document frequency)算法计算每个关键词的权重,即可将知识表征为词向量,如式(5)所示:
(5)

TextSim(I1,I2)=
rel(w1,w2)=
(6)
上式中,Map为根据本课题组另一项工作中的方法[30],从所有知识文档集合D中抽取主题词构建的船舶舾装设计领域主题知识地图GT(如图3),GT中节点为知识主题词,边为节点间的工程语义相似度。MapWeight(w1,w2)为两个主题词在Map中的关联权重。

(2)知识任务相似度计算 知识任务相似度是指两条知识能够解决相似任务的概率。用户在工程任务中遇到问题时,需要浏览知识文档辅助问题解决,而同一个问题通常需要浏览多个知识文档,即用户连续浏览的文档通常能够解决相似工程问题。因此,利用用户群浏览行为序列数据计算知识任务相似度。将未超过30 s的浏览记录剔除,即可计算知识的任务相似度,如式(7)所示:
TaskSim(I1,I2)=
R(Ui)={(I,ΔT)1st,…,(I,ΔT)nth}。
(7)
式中:Ui为所有用户集合U中的任一用户,I1↔I2表示用户Ui连续浏览了两个知识文档。
根据式(6)和式(7)即可计算知识文档I1和I2的知识相关性,如式(8)所示:
Rel(I1,I2)=TextSim(I1,I2)×
TaskSim(I1,I2)。
(8)
利用式(8)算得所有知识文档间的相关性,即可构建知识相关性网络GI。
2.2.2 用户历史评分的语义激活扩散
激活扩散模型(SAM)是用于模拟人类认知机制的网络模型,节点通常为概念主题词,其在知识推荐领域已有应用,但以概念主题词为节点对用户兴趣进行激活扩散很难避免“过专业化”的问题[16],本文直接利用知识文档相关性网络GI对用户历史评分向量RH进行语义扩展。为节约计算资源,仅考虑单层扩散,将RH中已有评分的知识文档看作GI中的初始激活节点,然后向相邻节点扩散,并用式(9)计算用户U对被扩散节点对应知识文档I的兴趣评分。
Rel(I,Ik);
s.t.
F(U,Ik)∈RH(U),F(U,Ik)≠∅,F(U,Ik)≠0
。
(9)
式中:F(U,Ik)表示RH(U)中现有非空且大于零的评分;将Ik设为GI中的初始激活节点,只要在GI中与任一Ik连接,即可被扩散。通过激活扩散后,得到语义扩展评分向量RE(U),进而可以将其与用户情境向量CB(U)和任务情境向量CT(U)拼接得到用户的情境评分向量RC(U)。
2.3 情境感知生成对抗网络模型
由于用户数量通常远小于知识数量,RC中仍有大量缺失评分数据,其中可能包含用户所需知识。传统协同过滤推荐算法通过计算用户和项目的相似度预测这部分缺失评分数据,但算法本身受稀疏矩阵问题影响,推荐效果不佳。对此,作为DNN的一种变体,GAN能够通过从给定的有限数据中学习数据分布进行推荐,有效解决了稀疏矩阵问题,具有良好的推荐性能。因此,引入GAN模型来解决稀疏矩阵问题。GAN由两个神经网络模型组成,即生成模型G和判别模型D,G用于生成伪造样本,D用于估计当前样本为真实样本的概率。在GAN训练过程中,将真实样本和G生成的伪造样本输入D,G需要尽量欺骗D,使D将其生成的伪造样本判别为真,而D则需要尽量将伪造样本判别为假。通过G和D的对抗训练,不断更新神经网络参数,使G学得真实样本数据的概率分布。
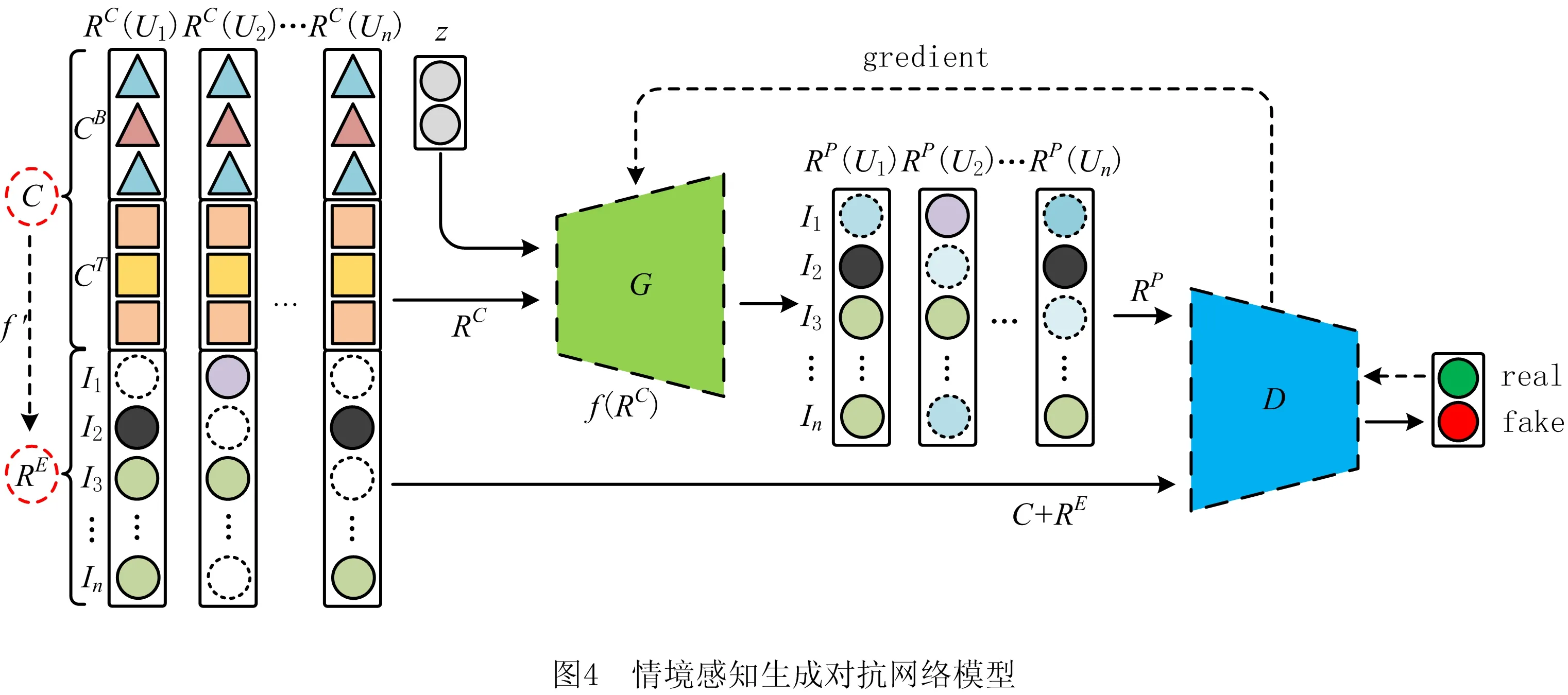
为使GAN更好地应用于工程知识推荐任务中,本文将情境信息加入到GAN的训练过程中。如图4所示,将用户语义扩展评分向量RE与情境向量C(用户情境向量CB和任务情境向量CT)拼接得到RC,并以vector-wise(基于向量)的方式基于RC训练GAN:G以RC和噪声向量z作为输入,学习RC的数据分布,并输出用户对所有项目的预测评分向量RP;D以RP、RE以及情境向量C作为输入,判别输入数据为真的概率,并产生相应的梯度信息以反馈回G。具有特定背景(CB)的用户在特定的任务情境(CT)和历史兴趣(RE)下,通常会有特定的知识兴趣(RP),因此可以认为G的输入向量RC与输出向量RP之间存在某种映射关系RP=f(RC),即从用户背景、任务情境和历史评分到用户当前知识偏好的映射关系。利用所有用户的情境评分向量RC进行协同训练,使G能够学得这种映射关系,进而为目标用户在特定的工程情境下生成个性化的知识推荐。
实际在RC中,情境向量C和用户的语义扩展评分向量RE之间也存在一种映射RE=f′(C),表现为不同RC的数据分布也不同,这种映射关系使得GAN利用所有用户的情境评分向量RC进行协同训练成为可能,其内涵为:基于多个情境评分向量RC进行训练的生成模型G能够学得不同情境C下对应的知识评分向量RE,对于每个知识文档I,只要有至少一个用户评分F(U,I),G即可学得I的评分F(U,I)与对应情境C(U)的映射关系,当再次遇到与C(U)类似的情境,G一定能为I生成对应的评分。
根据图4,生成模型G和判别模型D的损失函数分别如式(10)和式(11)所示:
(10)
log(1-D(RP(U)|C(U))))。
(11)
根据G和D的损失函数,情境感知生成对抗网络模型的训练步骤如算法1所示。
算法1情境感知生成对抗网络模型。
输入:所有用户的情境评分向量RC,生成模型G和判别模型D的神经网络权重参数θ和φ、最小批处理大小MG和MD、学习率μG和μD,G-step,D-step,设定迭代终止次数epochSum;
输出:训练完成的G的参数θ。
1 初始化θ和φ
2 while not reach to epochSum do
3 for G-step do
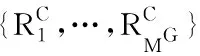
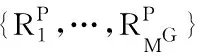
6 更新G的参数θ:θ←θ-μG/MG·∇θJG
7 end for
8 for D-step do
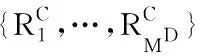

11 更新D的参数φ:φ←φ-μD/MD·∇φJD
12 end for
13 end while
14 return θ
2.4 工程知识推荐
经过算法1训练完成后,生成模型G学得了映射关系RP=f(RC),且由于用户的知识兴趣在短期内保持相对稳定,因此可以利用训练完成的G进行Top-N推荐。例如,对于用户U2,短期内,可认为其个人信息保持不变,即CB(U2)不变;GAN需要先离线训练然后在线推荐,因此在下次训练之前,用户初始评分也保持不变,即RE(U2)不变;而用户会不断地进行检索输入,最新的检索输入能更准确地表征当前任务情境,因此,可以加入U2最新的检索输入,而去除过早的检索输入,并用2.1.2节方法重新构造任务情境向量CT(U2),进而重新拼接RC(U2)作为G的输入,再根据G输出的预测评分向量RP(U2),从中选出U2近期未浏览的预测评分最高的Top-N条知识推荐给U2。RP(U2)是一个稠密向量,即G预测了U2对大多数知识文档的评分,因此,能够从海量知识文档中更准确地挖掘U2的兴趣。
推荐列表的更新可以遵循以下两个规则:
(1)若用户点击了推荐列表中的知识,则依次从预测评分向量RP(U2)中剩下的知识中选出评分最高的知识替换掉被点击的知识。
(2)若用户有新的输入检索信息,则重新构造任务情境向量CT(U2)与情境评分向量RC(U2),将RC(U2)输入G中重新生成预测评分向量RP(U2),根据RP(U2)为U2重新生成推荐。
3 应用案例
3.1 案例背景与数据集
本文拟基于课题组与某船厂的合作项目“舾装智能化设计知识库管理系统”(即KMS)进行实例研究。由于船舶舾装设计任务工作量大、流程繁杂,极依赖于各类标准、规范以及历史经验案例等知识文档的支撑[30],为了提升企业知识资产重用效率,以更好地辅助员工解决工程问题,船厂利用KMS对知识资产进行统一管理,并向KMS用户(即企业员工)提供知识查询和共享等服务。然而,由于企业知识库中知识数量的持续增加引发了知识迷航问题,且用户个人知识面有限,无法通过检索获取到所有相关知识条目。利用推荐算法主动为用户推送合适的知识是提升企业知识重用效率的有效手段,本文CGKR方法即可应用于KMS中,主动挖掘用户兴趣,从而为用户提供优质的知识服务。
为验证CGKR方法的知识推荐效果,从KMS用户日志中整理出13名用户的2 620条检索与浏览记录数据用于挖掘用户兴趣,并获取被这13名用户浏览过的379条知识文档内容,部分数据如表2所示。CGKR方法使用Python 3.7编码,所用开源工具包主要包括:Numpy-1.17.4、Pandas-0.24.2、Torch-1.3.1、Jieba-0.40等,算法在Core-i5、16G-RAM的MacOS-10.15计算机环境下运行。
3.2 模型评估方法
在CxtGAN模型迭代训练过程中,需要持续监控模型的推荐性能,本文采用F1分数和标准化折现累积增益(NDCG)作为模型的评价指标。F1分数是推荐算法最基础的评价指标,用于衡量推荐算法的准确度,兼顾了推荐的查准率和查全率,如式(12)所示:
(12)
式中PUi和RUi分别为针对用户Ui的推荐结果的查准率和查全率,利用式(13)计算:
(13)
式中Rec(Ui)和Real(Ui)分别为针对Ui的知识推荐列表和真实浏览知识列表。在CGKR方法中,从每名用户Ui的行为序列数据Rn(Ui)={(Q,I,ΔT)1st,…,(Q,I,ΔT)nth}中截取RL(Ui)={(Q,I,ΔT)1st,…,(Q,I,ΔT)Lth}用于构造CxtGAN模型的训练数据,截取R0.2L(Ui)={(Q,I,ΔT)L+1th,…,(Q,I,ΔT)1.2Lth}作为Ui真实浏览的知识列表Real(Ui),CxtGAN模型训练完成后为Ui生成推荐列表Rec(Ui),Rec(Ui)中的知识若在Real(Ui)中出现,则为命中。
NDCG能够评估算法的排序性能,如式(14)所示,命中的知识在Rec(Ui)中排序越靠前,NDCG值越大。
(14)
3.3 CGKR方法应用示例
为验证CGKR方法的可行性,将其实际应用于船舶舾装设计领域的Top-5知识推荐任务中,本节简要展示构造用户情境评分向量RC、训练CxtGAN模型并最终向目标用户推荐知识的流程。
3.3.1 用户情境评分向量构造方法
对于用户U,其情境评分向量RC(U)由用户情境向量CB(U)、任务情境向量CT(U)和语义扩展评分向量RE(U)拼接而成,而RE(U)由历史评分向量RH(U)经过语义扩展所得。
(1)用户情境向量(2.1.1节) 根据表1中对用户背景信息属性的编码,将用户的背景信息表征为7维用户情境向量CB(U)(式(2))。
(2)任务情境向量(2.1.2节) 获取用户U最近l条检索输入信息,根据式(3)从中提取出最重要的k个关键词{w1,w2,…,wk},按照图2所示方法进行word embedding操作,分别将k个关键词转化为h-dim维向量{h1,h2,…,hk},拼接{h1,h2,…,hk}即可构造任务情境向量CT(U)。根据经验,本文取l为10,k为5,h-dim为50,则CT为250维向量。
(3)历史评分向量(2.1.3节) 从用户U的浏览行为序列(式(1))中截取近期浏览行为数据RL(U),利用用户兴趣模型(式(4))计算U在L次浏览行为中对浏览过的知识文档的兴趣评分,进而构造用户的历史评分向量RH(U)。
(4)语义扩展评分向量(2.2.2节) 考虑到RH(U)极其稀疏(评分数量不大于L),根据2.2.1节方法构建以知识文档为节点的知识相关性网络GI,然后对RH(U)中现有的真实评分数据进行语义关联扩展(式(9)),以缓解稀疏矩阵问题。将被扩展的知识项目所得评分数据加入RH(U)中,进而得到RE(U)。
将构造的CB(U)、CT(U)和RE(U)拼接即可得到用户情境评分向量RC(U),利用所有用户的情境评分向量即可对CxtGAN进行协同训练。
3.3.2 CxtGAN模型训练方法
在3.3.1节中,对现有用户背景信息以及历史浏览数据进行挖掘得到了13名用户的情境评分向量,本节即利用这13个向量数据,按照算法1训练CxtGAN模型,其中,生成模型G和判别模型D都为4层神经网络,除了用户情境评分向量外,算法1的其他超参数设置如表3所示。

表3 算法1超参数设置
由于本文所用数据量相对较少,而CxtGAN模型又要经过多轮迭代训练,为了防止生成模型G过拟合,在每轮生成模型G的训练中加入噪声向量z(如图4),对输入的情境评分向量RC(U)的数据分布进行轻微扰动,使每次输入的RC(U)都不完全相同。在训练过程中不断保存当前推荐准确度表现最佳(即F1值最高)的生成模型G,当达到设定总迭代次数(即600次)时,训练完成。
3.3.3 模型关键参数L的确定
为使模型推荐性能最优,需进行实验确定关键参数L(即用户近期浏览行为序列RL(U)的长度)。将L值作为实验变量,在不同L值下构建用户情境评分向量,并利用3.3.2节方法训练CxtGAN模型,最终得到CxtGAN模型在不同L值下的性能表现,如图5所示。随着L的增加,两个指标都呈现先不断增加,再趋于平缓甚至轻微下降的趋势,这是由于随着L的增加,RL(U)中包含了更多的用户行为,使得用户兴趣模型能够更准确全面地探知用户兴趣,而若L过大,过早的用户行为会成为噪声数据影响用户兴趣模型的准确性,本文取L=35。

在最优参数L=35下,CxtGAN模型迭代训练过程的学习曲线如图6所示,在迭代训练初期,F1值和NDCG都迅速上升,大约迭代184轮后F1值达到0.491,曲线趋于平缓,用时229 s,NDCG达到0.607,但仍有上升趋势,即算法的排序性能能够继续优化。继续训练,当进行到第395轮时,NDCG达到最高,为0.660,此时F1为0.508。当训练至456轮时,F1值达到最高,为0.520,NDCG略微下降至0.643,此时训练用时561 s,保存此时的生成模型G,用于针对目标用户的知识推荐。

3.3.4 针对目标用户的知识推荐
将U2作为目标用户,利用3.3.3节中保存的生成模型G进行推荐。根据目标用户个人背景信息编码其用户情境向量为CB(U2)=[25,1,4,1,1,1,2]。U2的历史浏览行为数据为R35(U2),如表4所示,目标用户近期偏好于浏览与管系单元内容相关的知识。

表4 目标用户的历史浏览行为数据

续表4
利用式(3)从近期10个用户检索输入信息中提取出5个能表征U2当前任务情境的关键词,分别为:管系、机装、舱柜、管附件、单元,进而利用训练好的Word2Vec模型将其映射为5个50维词向量,并拼接得到用户的任务情境向量CT(U2)。根据式(4)计算U2对R35(U2)中知识的兴趣评分,由于R35(U2)中没有重复浏览的记录,可以得到包含35个非空评分数据的历史评分向量RH(U2),再根据2.2节中的方法扩展RH(U2)得到RE(U2),通过语义扩展,RE(U2)中增加了57个评分数据,缓解了稀疏矩阵问题。将CB(U2)、CT(U2)和RE(U2)拼接得到U2的情境评分向量RC(U2),将RC(U2)输入3.3.2节中训练完成的生成模型G中,使G生成U2的预测评分向量RP(U2),进而可以从U2未浏览的知识条目中选取Top-5条评分最高的知识推荐给U2。
表5展示了U2的知识推荐列表Rec(U2)和真实浏览列表Real(U2)。由Real(U2)可知,在35次历史浏览行为后,U2的兴趣保持相对稳定,即在未来的7次浏览行为中,仍在查找浏览与管系单元相关的知识,如表中黑体表示。在本次推荐中,命中了I145、I362和I294三条知识,F1和NDCG分别为0.5和0.654。

表5 目标用户的知识推荐列表和真实浏览列表
3.4 对比实验
CGKR方法分为数据挖掘和CxtGAN模型训练两个阶段。数据挖掘阶段主要改进为:①构建语义激活扩散模型(SSAM),对用户历史评分向量RH进行语义扩展得到用户语义扩展评分向量RE;②将用户情境(Background Context)信息和任务情境(Task Context)信息引入GAN模型进行知识推荐。模型训练阶段主要改进为基于设定的浏览次数和浏览时长规则主动选取负样本(在式(4)中将未重复浏览且浏览时长少于30 s的文档评分置为0)以优化CFGAN[26]中的随机负样本策略。本节分别对CGKR方法中两个阶段的主要改进效果进行验证。
3.4.1 数据挖掘阶段改进效果验证
为验证语义扩展和情境信息的作用,设计对比算法如下:①基于RH进行推荐的基于用户的协同过滤算法(User-based Collaborative Filtering, UCF);②基于RE进行推荐的协同过滤算法(UCF with SSAM);③在CGKR的基础上去掉语义扩展操作(CGKR without SSAM);④在CGKR的基础上去掉用户情境信息(CGKR w/o BCxt);⑤在CGKR的基础上去掉任务情境信息(CGKR w/o TCxt);⑥在CGKR的基础上同时去掉用户情境信息和任务情境信息(CGKR w/o Cxt)。
对比算法与CGKR方法在Top-5推荐任务中的性能表现如图7所示:
(1)由于未考虑任何领域特征和语义信息,UCF在工程知识推荐任务中表现出了不适应性,推荐准确度(F1=0.281)和算法的排序性能(NDCG=0.169)都为最差。
(2)对比UCF与UCF with SSAM、CGKR w/o SSAM与CGKR的性能表现可知,应用SSAM模型能够使F1和NDCG均有所提升,证明本文利用SSAM模型对用户历史评分进行语义扩展能够更全面地探知用户兴趣,使更多知识文档参与到推荐过程中,进而提升了推荐准确度和算法排序性能。
(3)对比UCF with SSAM和CGKR w/o Cxt可知,虽然引入了GAN模型以解决稀疏矩阵问题,但若忽略情境信息,基于RE进行协同训练的GAN模型学到的也只是不够准确的评分数据分布,其性能表现与传统协同过滤方法相比并无明显优势,甚至F1值下降了0.09。
(4)与CGKR w/o Cxt相比,CGKR方法的F1和NDCG分别提升至0.522和0.643,这是因为CGKR中的CxtGAN模型考虑了用户情境和任务情境信息,通过基于所有用户情景评分向量的协同训练,能够学得情境和评分之间复杂的非线性关系,进而获得较高的推荐准确度和排序性能。
(5)对比CGKR、CGKR w/o BCxt和CGKR w/o TCxt可知,未考虑用户情境时,CGKR w/o BCxt的F1和NDCG分别降至0.449和0.471,而未考虑任务情境时,CGKR w/o TCxt的F1和NDCG则直接降至0.327和0.296,表明相比于用户情境,任务情境对算法性能的影响更大,这是由于任务情境是用户主动输入的信息,更能代表用户的需求和兴趣。

3.4.2 模型训练阶段改进效果验证
为验证本文负样本策略的效果,设计对比算法如下:
(1)在CFGAN[26]的基础上去掉负样本策略(CFGAN w/o n-item),即基于本文用户情境评分向量训练CFGAN,但将式(4)中为0的评分置为空。
(2)采用随机负样本策略的CFGAN,即基于本文构造的用户情境评分向量进行协同训练,将式(4)中为0的评分先置为空,然后从所有为空的评分中随机选择一定比例作为负样本(评分置为0),本实验将该比例设为50%。
图8为两种基于CFGAN模型的对比算法(CFGAN w/o n-item和CFGAN)与本文CxtGAN模型的学习曲线,由图可知:①CFGAN w/o n-item的学习曲线在仅仅迭代大约50步后会出现明显下降的趋势,这是由于未采用负样本策略,导致了单类协同过滤问题,使得模型过早陷入了局部最优;②相比于CFGAN w/o n-item,采用了随机负样本策略的CFGAN的F1和NDCG都有明显提高(最优F1和NDCG分别为0.503和0.534),但CFGAN的学习曲线波动较大,这是因为随机选取负样本产生的偏差影响了训练过程中模型性能的稳定;③相比于CFGAN,CxtGAN的最优F1和NDCG分别提升至0.520和0.660,且训练过程稳定性得到了极大的提升,模型收敛也较快(F1和NDCG的学习曲线分别在迭代184次和297次后趋于稳定),表明本文基于式(4)准确选取负样本能够优化模型训练过程稳定性,使模型更快达到收敛,并能极大地提升模型的排序性能。

以上对比分析表明,本文基于语义激活扩散模型对用户历史评分进行语义扩展能够更全面地探知用户兴趣;而情境感知GAN模型能够有效解决稀疏矩阵问题,在工程知识推荐中表现良好。
4 结束语
针对传统知识推荐算法由于受稀疏矩阵问题影响而准确度不高的问题,本文提出一种基于情境感知生成对抗网络模型的工程知识推荐方法(CGKR)。该方法通过语义激活扩散模型扩展用户评分,并引入了具有情境感知能力的GAN模型,能够有效解决稀疏矩阵和新用户冷启动问题,为工程领域用户提供更优质的知识推荐服务。本文的主要创新点总结如下:
(1)构建了基于知识相关性网络的语义激活扩散模型 不同于传统的以知识主题词为节点的语义网络,本文提出了知识任务相似度的概念,并同时考虑知识内容相似度和任务相似度构建以知识文档为节点的知识相关性网络GI,基于GI构建了语义激活扩散模型(式(9)),进而直接对用户评分进行语义扩展,更全面地探知了用户兴趣,在一定程度上缓解了稀疏矩阵问题。
(2)构造了用户情境向量和任务情境向量 本文分析了用户个人背景信息和当前进行的任务对用户兴趣的影响,然后依托企业KMS中集成的人力资源管理系统,对必要的用户个人信息进行编码,进而构造用户情境向量(式(2)),并定义检索关键词重要度QWI,从用户近期检索输入信息中提取能够表征用户当前任务的关键词(式(3)),进而构造任务情境向量(如图2)。
(3)构建了情境感知GAN模型 引入GAN模型,并利用带有情境信息的评分向量进行协同训练(算法1),进而构建了情境感知GAN模型CxtGAN(如图4)。在CxtGAN模型的协同训练过程中,模型能够学得所有情境评分向量中的数据分布以及情境信息与评分信息之间的映射关系,能够更准确地进行知识推荐。由于CxtGAN通过学习数据概率分布进行推荐,能够有效避免稀疏矩阵引起的相似度计算失真问题。另外,对于没有任何浏览行为的新用户,只要提供部分个人信息,CGKR方法依然能够为其推荐,即解决了新用户冷启动问题。
在本文方法中,除了以上3点主要改进外,仍有不足需要指出:首先,基于用户历史行为进行用户兴趣建模时,不同行为对当前兴趣的影响权重是不同的,相关性越大的历史行为权重越大,而本文设定的规则相对简单(非重复浏览且浏览时长少于30 s即为不喜欢),限制了对用户兴趣探知的进一步精细化;其次由于工程领域的复杂性,导致用户的知识兴趣总是多样化的,而本文未考虑多领域情境下用户兴趣的多样性。对此,可以从两方面扩展本文现有研究:①可以考虑引入深度学习领域的注意力机制,以更精细地探知用户兴趣;②可以将多样性作为知识推荐算法的优化目标,以使推荐结果更全面地覆盖用户兴趣。
