基于交路接续规律的动车组运营里程预测算法
2022-04-04贾丹龙高畅霞
贾丹龙,刘 峰+,张 宁,张 春,高畅霞,郝 伟,3
(1.北京交通大学 计算机与信息技术学院,北京 100044;2.北京交通大学 高速铁路网络管理教育部工程研究中心,北京 100044;3.中车青岛四方机车车辆股份有限公司 信息技术部,山东 青岛 266011)
0 引言
随着我国高铁建设规模的扩大,营业里程的上升[1],为保障运营安全,动车组的高级修次数也将愈加频繁。高级修流程耗时较长,且工艺复杂,目前能够承担动车组高级修任务的检修地的检修能力相比于动车组的数量显得较为有限。由于全年铁路客流分布不均衡,动车组运用具有一定随机性,如果不加以调整,动车组的入修在时间分布上常常出现高峰期与低谷期,导致了检修资源利用率低下、动车组检修停运时间过长等问题的出现[2-3]。为了在满足动车组运用需求、遵守检修规程[4]的前提下,合理并充分利用有限的检修资源,需要提前为动车组制定高级修计划。
高级修计划是动车组运用与检修管理工作的重要组成部分,是动车组检修计划的重要组成部分。近年来,一些专家学者对动车组高级修计划的优化方法进行了探讨和研究,旨在全局范围内找到最优方案的同时,提高编制高级修计划的效率。文献[5-6]以动车组日均走行公里和年平均开行天数为关键参数,提出一种动车组年度高级检修量预测方法。文献[7]考虑了客流分布不均对部件可靠度及维护经济性的影响,提出了客流分布不均影响下的动车组部件动态维护调整策略。文献[8]基于高级修计划的编制流程与实际约束条件,构建了0-1整数规划模型,并设计了相应的粒子群求解策略。文献[9]针对动车组高级修问题,通过设立状态函数构建了0-1整数非线性规划模型,并利用模拟退火算法进行求解。文献[10]基于状态函数、时空网络和多目标规划理论研究了多种高级修计划优化方法,并结合具体案例进行了实证研究。文献[11]通过构建时间—状态网络将动车组高级修送修问题转化为网络上的路径选择问题,并构建了相应的数学规划模型与求解策略。文献[12-14]针对动车组高级修车间工艺流程进行了优化研究。文献[15]研究了检修计划优化的3大核心子问题并构建了各个阶段的模型。文献[16-17]深入研究了单一部件和多部件的维修策略。文献[18]构建了动车组运用与检修计划综合优化的0-1整数规划模型,从不同角度形成了动车组运用与检修计划的综合优化方法。文献[19]在保证所有动车组都能及时检修的约束条件下,结合动车组预防性检修制度,对为动车组提前1~3天安排检修作业的问题进行了优化研究。文献[20]以减少动车组空车送检次数为目标,在考虑检修修程、检修基地布局以及检修能力等约束条件下,构建了基于交路互换的动车组检修计划优化模型。
上述高级修计划优化的研究在实际中暂未得到应用,实际工作中高级修计划编制是依据人工经验借助Excel表格完成的,编制效率较低且对人依赖性过大,难以得到最优方案。高级修计划编制首先要确定动车组送修日期,目前,无论是上述文献中对高级修计划的优化研究,还是实际采用的人工编制方式,都以动车组运行里程为动车组送修时机的主要决定依据,但尚未有一种成熟的里程预测方法。
我国动车组投入使用已有数年,期间积累了许多宝贵的历史开行数据,本文利用这些动车组的历史开行数据,提出一种基于交路接续规律的动车组运营里程预测算法模型,根据列车执行交路的接续关系以及停靠站点的接续关系,实现列车每次执行交路后的里程增长情况预测,对于确定动车组的送修日期、为后续高级修计划的编制具有积极的作用。
1 问题描述
编制高级修计划必须遵循目前高铁动车组的检修规程,首先需要根据里程周期和时间周期中的先到者确定列车送修日期,而我国高速铁路运行繁忙,列车往往在达到时间周期之前就已经达到里程周期。因此,动车组运营里程预测是实现动车组送修日期预测的关键,对于检修计划的制定具有基础性的作用,是检修计划决策的基本依据之一。
截至目前,国内暂未有成熟的动车组运营里程预测方法,实际工作中采用同一动车组两次相邻二级修之间的日均里程进行预测(简称日均里程法),但是该方法的预测准确率并不可靠,当列车的运行里程分布不均衡时难以达到理想效果。目前,预测动车组的较长期的运行里程具有相当大的难度,其原因如下:
(1)随着我国高速铁路的建设,动车组的数量及运行总里程每年都在不断增加。
(2)每列动车组的运行区域和交路也依据实际运输需求经常调整。
(3)全年客流量存在高峰期与低谷期,从时间上看动车组运用规律分布并不均衡。
也正是由于上述原因,现有的基于人工经验或日均里程的里程预测方法较难达到理想的预测效果。针对上述问题,有必要提出一种能不受动车组交路动态变化影响的运营里程预测方法。
2 算法模型设计
本文将同一动车组在一天内执行的所有车次的有序集合定义为交路,算法模型以动车组历史开行数据为基础,基本设计思路如下:
(1)历史开行数据预处理,并为每一条数据生成合适的时间权重;
(2)充分分析动车组列车交路接续规律,结合数据时间权重,构建交路转移概率矩阵,同时考虑到矩阵中可能出现新交路的情况,对交路转移概率矩阵进行修正和优化;
(3)在交路转移概率矩阵的基础上进行交路随机转移预测,并为整个预测过程设置一定重复次数,以消除偶然性,体现统计规律。
上述设计思路对应本章3个小节,依次为数据处理、交路执行规律提取和交路随机转移预测,最终得到一组交路预测结果,根据交路与里程数一一对应的关系可以得到未来动车组的里程增长情况,从而实现动车组运营里程预测。
本章使用的部分符号下标定义如表1所示。

表1 算法模型中涉及到的符号定义

续表1
2.1 数据处理
在实际的铁路日常工作过程中,各动车组在完成各自的开行任务后会同步记录,形成动车组的原始历史开行数据集。
2.1.1 数据预处理要求
考虑到不同数据集的格式存在差异,仅对处理前的原始数据集和处理后的开行数据集提出以下要求:
要求1数据完整。原始数据集在处理前应当至少具有“交路”、“开行日期”、“交路始发站”、“交路终到站”和“交路里程数”5个字段,且要求动车组所有正常运营的交路执行记录都包括在该数据集中。
要求2数据充足。原始数据集中的动车组交路执行记录数量至少是要预测的交路执行次数的3倍。
要求3日期有序。原始数据集经过处理后得到开行数据集D,其中di与di+1的日期可以不连续,但要求di+1中的“开行日期”字段大于di。
要求4日期唯一。开行数据集D中,di与di+1的日期可以不连续,但要求每一个日期都只有唯一的一条数据。
要求5无干扰数据。开行数据集D中,要求di中的“交路”字段中包含的所有车次中至少有一个车次为正常运营车次。
经过预处理后,得到的开行数据集D如表2所示,表中:r表示交路的车次组合,l表示该交路对应的里程长度,s表示停靠站。
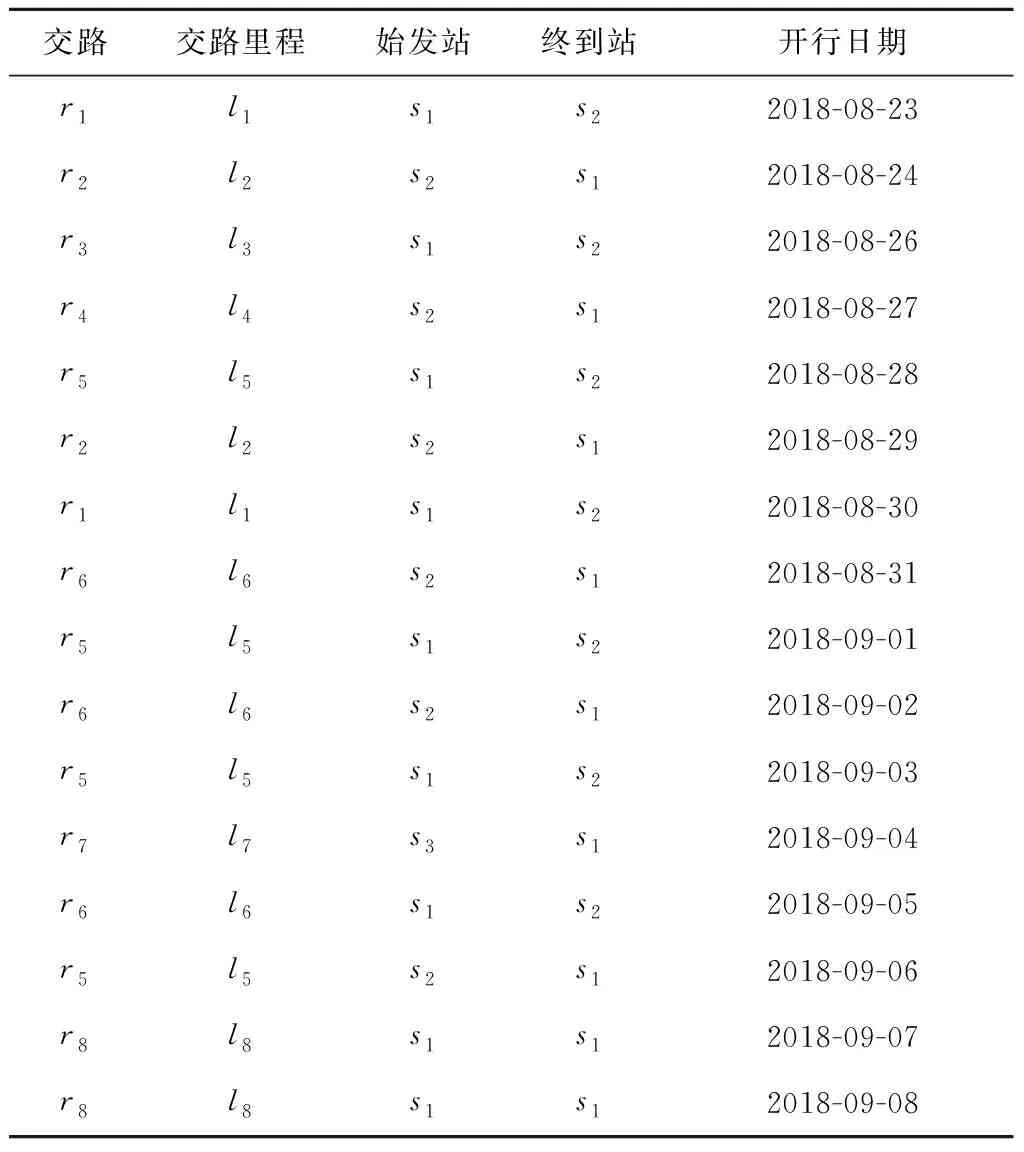
表2 某动车组的部分历史开行数据
2.1.2 生成时间权重集
随着我国高铁建设规模的扩大,列车开行计划也会做相应的调整,交路更替也会频繁出现,以满足不断增长的客流量需求。因此,动车组的历史数据中的交路执行记录是具有时效性的,记录日期越新的数据记录,对未来预测的参考价值越高。
处理完历史数据后,为每一条数据di加上时间权重wi以体现不同数据的参考价值。从整体上来看,动车组运用规律呈阶段式变化,类似于分段函数,为了算法执行效率,本文仅设置两个分段参数:tworst和tbest,分别划分出历史数据没有参考价值和最有参考价值的日期范围。另外,对于记录日期位于tworst和tbest之间的数据,采用sigmoid函数作为参考价值的变化曲线。数据时间权重的计算公式如式(1)所示,其中k是最佳时间权重系数,与tworst和tbest一样都采用迭代逼近的方法找到最优值,
(1)
数据时间权重的计算步骤如下:
步骤1设置tworst、tbest和k的迭代范围以及迭代步长,并将开行数据集D按照合适比例划分为训练集和验证集。
步骤2迭代3个参数的所有组合,根据式(1)计算临时时间权重集W′,并根据2.2节与2.3节中的步骤,对训练集数据进行预热性预测,将得到的预测结果集与验证集比较,按照式(5)计算准确率,并与全局最佳准确率进行比较并更新,保留最优的一种参数组合。重复步骤2,直到迭代结束。
步骤3取出全局最佳准确率对应的tworst、tbest和k,根据式(1)为开行数据集D中的每一条数据di计算权重wi,并加入时间权重集W。
2.2 交路执行规律提取
动车组交路是一定数量的列车车次有序接续的车次集合,是动车组分配每日开行任务的最小单元,直接决定了动车组的每日运营里程增长量。目前,我国动车组的运营以固定运行区段的方式为主,动车组每日可担当的交路直接受限于其之前担当过的交路,即交路之间存在一定的接续限制关系,在已知动车组上一次担当的交路任务的情况下,其下一次可能执行的交路将被限制在一个有限的交路集合中。
从表2中展示的部分历史数据中可以发现,动车组执行交路存在某种固定的接续规律,如交路r1的接续交路有r2、r6,交路r6的接续交路只有r5,这种交路接续的规律随着历史数据日期范围的扩大将更加明显。另外,动车组的停靠站之间也存在接续关系,本文定义动车组上一次开行任务的终到站与相邻下一次开行任务的始发站为接续站点,如表2中站点s1的接续站点只有s1自身,s2的接续站点有s1与s3。由于动车组在安排每日开行任务时与当前所在停靠站往往密切相关,每条交路都有各自的始发站与终到站,因此站点接续关系已经隐含于交路接续关系中。
要实现交路接续的预测,除了需要已知上述的交路接续限制关系,还需要明确如何从可接续交路的集合之中做出选择,因此,要从历史数据中提取的交路执行规律,除上述的交路接续限制关系外,还有可接续的交路被选择的可能性。这种可能性在历史数据中也有体现,同样以表2为例,交路r1的可接续交路有r2和r6,且在该表范围内接续交路选择r2的情况有一次,选择r6的情况也有一次,在不考虑数据时间权重的情况下,可以明确该动车组在担当交路r1后,下一次选择r2或r6作为接续交路的可能性均为50%。在此基础上,按照得到的概率值进行随机预测,就可以确定接续交路的具体选择。
交路执行规律提取是整个算法模型中最重要的过程,经过这一步骤之后将得到3个数据集,分别为站点接续关系集S、交路转移频次矩阵F以及交路转移概率矩阵M,其中交路转移概率矩阵M是交路转移预测的核心,其他两者都服务于矩阵M的生成和优化。
2.2.1 生成站点接续关系集
当开行数据集中最后一条数据中出现新交路时(如表2中的交路r8),该交路在历史数据中不存在可接续的交路。针对这种情况,本文将交路接续的要求降级为站点接续的要求,依据站点接续关系集S,为新交路寻找满足站点接续的交路。该集合可通过以下步骤计算得到:
步骤1遍历开行数据集D,取出第i条数据di的终到站sk1,和第i+1条数据di+1的始发站sk2。
步骤2从S中取sk1的站点接续关系子集Ssk1,将sk2加入到Ssk1之中。
步骤3重复步骤1和步骤2,直到遍历结束。
2.2.2 生成交路转移频次矩阵
交路转移频次矩阵记录的是开行数据集D中交路ri转移到交路rj的总加权次数fri,rj,如表3所示,其主要作用是计算和修正交路转移概率矩阵。在计算交路转移频次矩阵时,需要结合时间权重集W,具体步骤如下:
步骤1遍历开行数据集D,取出第i条数据di和第i+1条数据di+1,得到接续起点交路ri和接续终点交路ri+1。
步骤2从交路转移频次矩阵F中取出元素fri,ri+1,从时间权重集W中取出di+1所对应的时间权重wi+1,令fri,ri+1自增一倍的wi+1后放回F。
步骤3重复步骤1和步骤2,直到遍历结束。
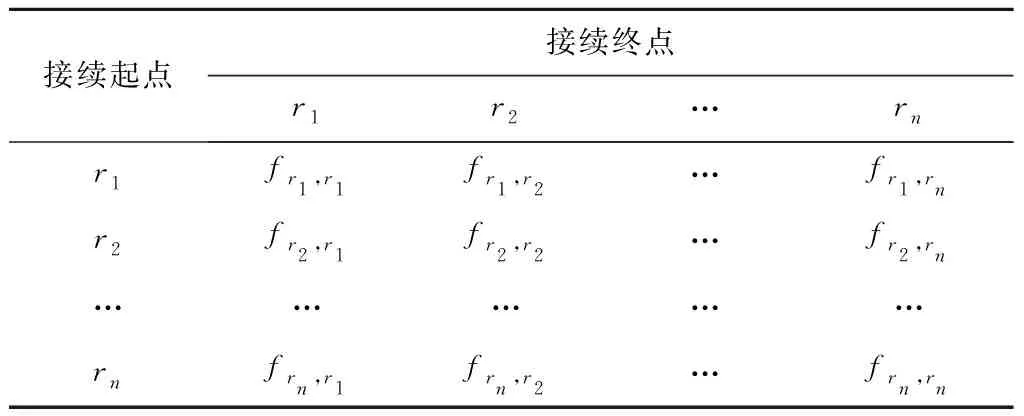
表3 交路转移次数矩阵结构示意表
2.2.3 生成交路转移概率矩阵
交路转移概率矩阵包含当前动车组的交路接续规律,是2.3节中交路预测的直接依据,其结构类似于交路转移频次矩阵,如表4所示,但元素表达的含义不同,M中的元素mri,rj是一个概率值,可由式(2)计算得到:
(2)

表4 交路转移概率矩阵结构示意表
生成交路转移概率矩阵主要经过矩阵初始化和矩阵修正两个过程。其中矩阵初始化指的是根据交路转移频次矩阵F中的转移频次数值计算出转移概率,逐步填充转移概率矩阵,概率矩阵的初始化步骤如下:
步骤1遍历交路转移频次矩阵的每一个元素fri,rj,根据式(2)计算相应的mri,rj并填入M。
步骤2重复进行步骤1直至交路转移频次矩阵遍历结束。
步骤1设新交路rk的始发站为sz,获得与sz接续的站点集合Ssz,若Ssz非空集,进入步骤2,否则进入步骤3。
步骤2Ssz非空集说明站点接续的要求能够被满足,将以Ssz中的站点为始发站的所有交路放入集合Rsz,作为新交路的可接续交路集,设rl∈Rsz,根据式(3)计算得到各条交路的转移概率,
(3)
步骤3Ssz非空集说明站点接续的要求无法被满足,此时将要求站点接续的限制解除,令交路根据历史出现频次自由转移。设rl∈R,将所有历史上出现过的交路作为可接续交路处理,以各条交路的历史出现总频次作为其转移概率的计算依据,根据式(4)计算得到各条交路的转移概率
(4)

2.3 交路随机转移预测
交路转移概率矩阵之中的每一个矩阵行Mri记录的是在当前执行交路为ri时,接下来可能执行的交路有哪些,以及执行该条交路的概率是多少。为了让所有交路的转移概率都参与到预测中,本文采用交路随机转移的预测方法,并通过一定次数的重复预测来消除随机预测可能出现的偶然性,取出重复结果中的累计里程数最接近平均值的一组结果作为最终结果。交路转移预测的具体步骤如下:
步骤1初始化设置交路转移次数为n1,交路预测重复次数为n2以及随机数空间最大值为n3。获取交路转移概率矩阵M。
步骤2检查当前重复预测次数是否达到n2次,若是则进入步骤6;否则将开行数据集D中执行日期最新的交路设为当前所在交路rcur,然后新建一个交路预测结果集,并增加一次当前重复预测次数后进入步骤3。
步骤3将交路rcur作为转移起点交路,获取交路转移概率矩阵行Mrcur,在0~n3的随机数空间中为Mrcur中的每一个非0概率所对应的交路rj分配一段长度为n3×mrcur,rj的概率空间。
步骤4在0~n3的随机数空间内生成一个随机数,若该随机数落在交路ri的概率空间内,则认为该次随机预测的结果是交路rcur转移到了rk,将rk加入交路预测结果集,并将rcur更新为rk,随后增加一次交路已转移的次数。
步骤5检查交路已转移的次数是否达到n1次,若满足,则将该n1次交路的组合作为一次交路预测结果保存并返回步骤2,否则回到步骤3。
步骤6取出n2组交路预测结果的平均累计里程,将累计里程数最接近该平均累计里程的一组结果作为最终的交路预测结果输出。
经过以上步骤可以得到当前动车组的一组交路预测结果,需要注意的是交路预测结果之中的记录是以每次交路执行为单位而非日期,因此还需要从历史开行数据集中保留交路预测的起始日期。
3 实验结果分析
实验采用2016年初~2019年末国内多个铁路局的动车组开行数据作为历史数据集,涵盖了各类车型,并从中随机抽取了15列数据记录量在1 000条及以上的动车组历史开行数据作为输入数据,分别进行里程预测,其中将每列车最新的300条数据作为验证集,剩余数据作为训练集,用于迭代最优时间权重参数以及提取统计规律。
实验过程中首先对日均里程法的预测准确率进行计算,由于本文算法模型是以交路执行次数为自变量,实际生产中动车组两次二级修之间执行交路次数大概在30次左右,因此实验中采用历史数据集中的最新30条开行数据的平均里程数作为预测的平均里程数,乘以预测的次数300后与验证集中的300条数据的累计里程总数进行对比计算,得到的准确率记录于表8中的日均里程法准确率一列,计算公式如下:
P=1-
(5)
根据第2章中的方法和步骤,进行本文算法模型的预测准确率验证。本次实验将时间权重式(1)中的参数tbest的迭代范围设置为185天~545天,并以30天为迭代步长;将参数tworst的迭代范围设置为740天~1 100天,迭代步长设置为30天;将时间权重系数k的迭代范围设置为0~8,迭代步长设置为0.2。最终得到了15列动车组的参数最佳组合如表5所示,将其中的参数组合结合式(1)后可以为每一条历史开行数据计算时间权重wi,随后可以依次计算得到每列车的交路转移概率矩阵,此处仍以列车T1为例,列车T1建立得到的矩阵共有96条不同的交路,即矩阵规模为96×96。为了方便展示,以表6的形式展示了该矩阵的部分内容,并省略了每一行中概率为0的列,表6中的符号与表7中的符号互相对应。
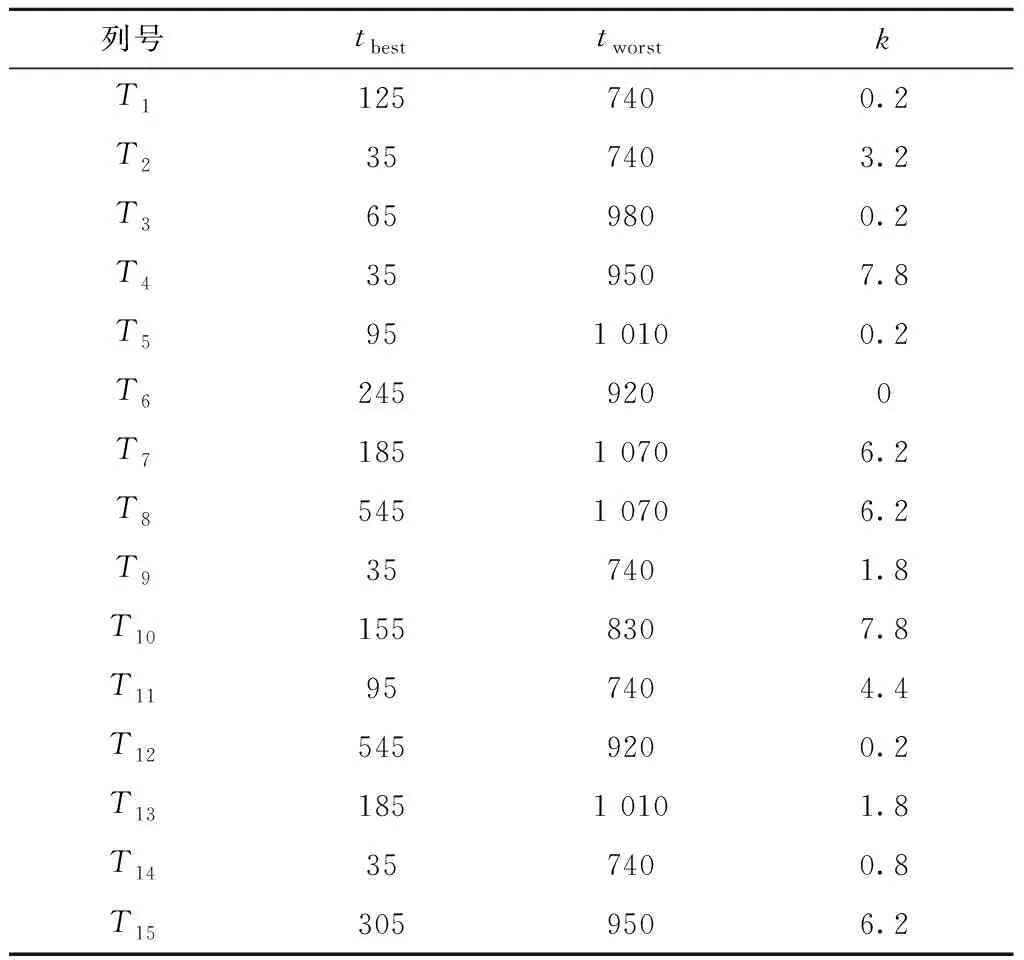
表5 时间权重的3个参数最佳组合

表6 列车T1的交路转移概率矩阵部分展示

续表6
执行算法后,为每列车生成记录未来执行的300次交路的预测结果集,表7展示了列车T1的部分预测结果,其中rn代表在预测结果集中出现的第n条不同的交路,sm代表在预测结果集中出现的第m个不同的停靠站。

表7 列车T1采用本文算法模型的部分预测结果

续表7
通过交路与里程的一一对应关系可以得到列车运营里程的增长情况,也可计算各列车的预测准确率,并记录于表8中的带权重准确率一列中,计算公式如下:
(6)
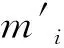
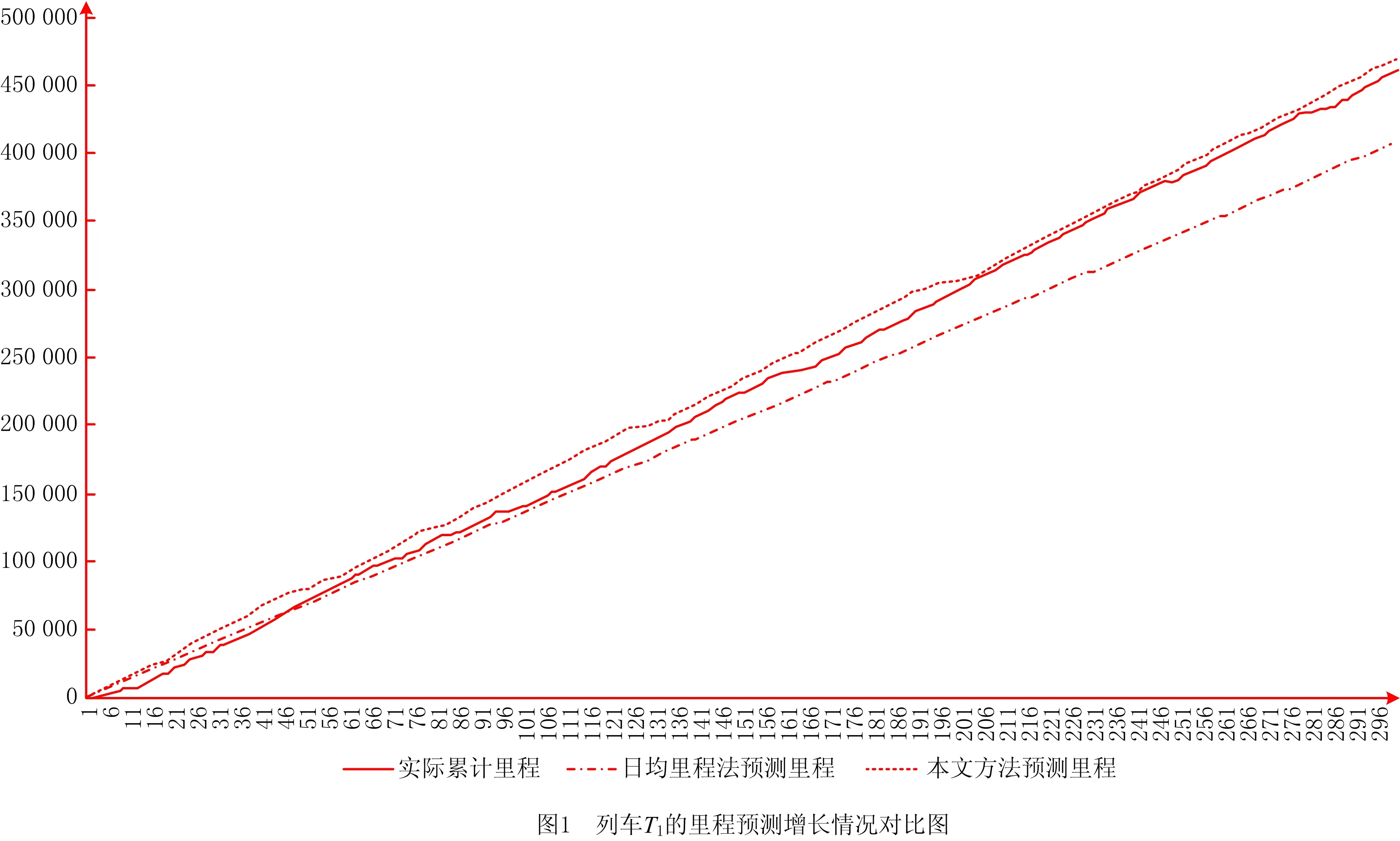
为了说明时间权重对预测准确率的积极作用,在本文算法模型的基础之上去除了时间权重的计算部分,即令各条数据的时间权重wi恒等于1,再进行相同的预测步骤,得到交路预测结果集,预测准确率的计算同式(6),预测结果记录于表8的无权重准确率一列中,并在图1中展示了列车T1的累积里程随开行次数增长的对比图。
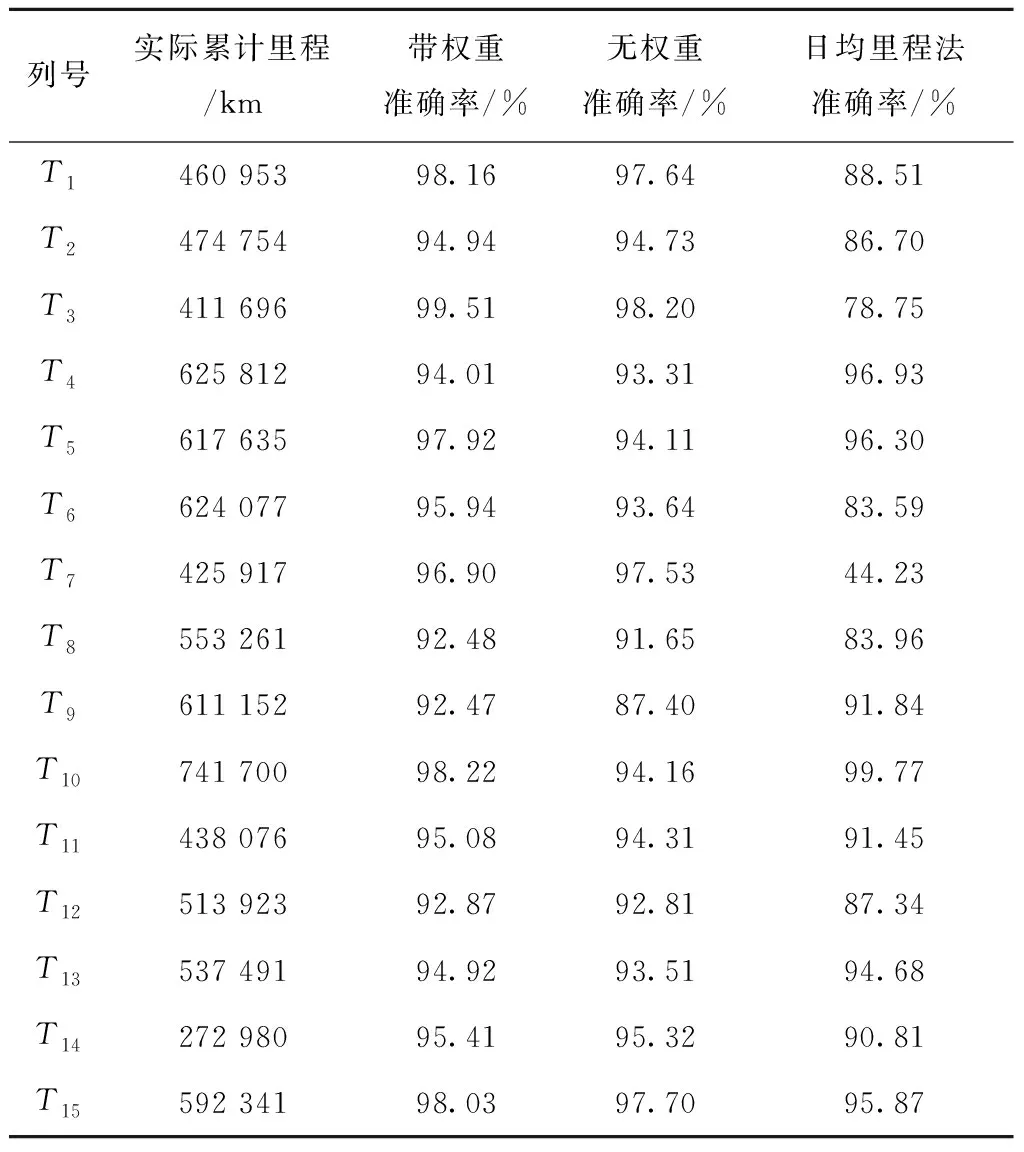
表8 预测300次交路的预测准确率对比
通过对表8中的带权重准确率与旧方法准确率的对比,可以发现本文算法模型具有以下3个优点。
(1)预测准确率高 本文提出的算法模型的预测准确率全部维持在92%以上,部分结果甚至能达到99%的准确率,而日均里程法只有少数几列车能够达到90%以上的准确率。
(2)预测性能稳定 日均里程法对不同列车预测后得到的预测准确率波动范围较大,列车T7的预测准确率只有44.23%,导致预测结果不可靠。而本文提出的算法模型对不同列车的预测准确率范围在92.47%~99.51%,预测结果稳定可靠。
(3)预测结果动态变化 本文提出的算法模型可以具体预测到每列车每次执行开行任务后的里程增长,能够体现动车组里程增长的动态变化情况。
尽管有以上优点,但实际上本文算法模型的表现并不总能优于日均里程法,比如列车T4、T5、T9、T10、T13和T15,两种方法得到的预测准确率差距很小,甚至日均里程法略优于本文方法。这些列车在所选日期时段内每日执行交路的里程数分布比较均匀,此时在预测里程增长方面本文的算法模型将不具备优势。另外,通过对表8中带权重准确率和无权重准确率的对比,可以发现加入本文提出的时间权重后,预测准确率有一定提升。由于不同列车的交路更新规律不同,时间权重带来的提升也并不一致,可见时间权重起到了一些积极的作用。
从整体上来看,本文提出的算法模型的性能明显优于日均里程法,尤其是预测准确率的稳定性方面有显著提高,对于动车组运营里程的预测有积极的意义。
4 结束语
本文在各列动车组的历史开行数据基础之上,给出了数据的处理方法,并将时间权重与历史数据中的交路接续情况相结合,形成交路转移概率矩阵,同时给出了出现新交路情况下矩阵的修正方法,并设计了交路随机转移的基本步骤。最后通过实验分析与对比,说明了该方法的预测准确性和稳定性。但本文只是预测了动车组未来连续执行一定次数交路后的里程增长情况,若要实现以日期为自变量的里程预测,还需要考虑动车组停车的情况,包括检修、库停和热备等,这也是未来的研究方向。
