基于YOLO v4的铁道侵限障碍物检测方法研究
2022-03-30刘力苟军年
刘力,苟军年
(兰州交通大学自动化与电气工程学院,甘肃 兰州 730070)
铁路运输因其运量大、成本低的特点,已经成为人民出行和货物运输首选的交通方式之一,随着铁路线路里程的增加和列车行驶速度的提高,铁路行业对列车行驶安全问题的要求也逐渐提高。侵限异物作为列车安全行驶时的潜在威胁,对其检测与识别一直是研究人员所研究的重点,目前主要有非接触式检测和接触式检测两大方法[1]。电网检测法作为非接触式检测方法的代表,是通过判断电网中电流的有无来确定是否存在异物;光纤光栅异物检测系统[2]则对由自然灾害造成的侵限异物有不错的检测效果。虽然接触式检测方法技术成熟,但是由于前期工程量大,安装麻烦,并不适合大量投入使用,还有当检测到异物时如果没有进行及时的人工处置,将会对列车的行驶效率造成影响。基于雷达和图像的非接触式检测方法近年来发展较快,郭双全等[3]提出了一种基于雷达数据的检测方法,但是该方法无法确定被检测物体的种类,有一定局限性;金炳瑞[4]则提出一种基于数字图像处理的异物检测方法,使用不同的方法检测不同的异物,且只考虑了光照情况良好的场景,局限性较大;史红梅等[5]通过机器视觉的方法将异物检测与分类相结合,但检测的实时性还有待提升。由于视频图像信息中包含大量的语义信息,并且通过对视频图像信息的处理,可以获得异物的具体类别和形状信息,基于视频图像的异物检测将会是异物侵限检测领域主要的发展方向。2012 年,AlexNet[6]网络取得了ImageNet 大赛冠军后,深度卷积神经网络凭借自动学习图像特征的特点,在计算机视觉任务中取得了突破性的研究进展,并且在目标检测领域取得了丰硕的应用成果,例如工件缺陷检测[7−8]等任务。目标检测主要研究内容是找出图像中特定的物体,能够准确地进行分类并给出目标的边界框。目标检测作为计算机视觉的基本研究内容之一[9],随着深度学习理论的发展,检测准确性和实时性都得到了显著提升。目前主流的检测网络主要分为单阶段和双阶段网络2种,双阶段网络因将定位和分类分开处理,所以具有较高的检测精度;而单阶段网络则将两者统一起来,在检测速度上取得了巨大突破。精度的提升往往会带来速度的损失,反之则亦然,平衡好这2个指标也是当下所面临的现实问题[10],YOLO v4[11]作为目前主流网络之一,在检测精度和检测速度上表现优良。本文提出一种基于单阶段检测网络YOLO v4的侵限异物检测模型,通过对聚类中心选取算法的改进来获得更具代表性的anchor 尺寸,引入注意力机制来进一步提高检测精度。经过测试,本文所提方法对侵限异物的检测精度和检测速度都取得了不错的效果,具有一定的应用价值。
1 YOLO v4算法
YOLO v4 算法作为典型的端到端网络,其结构相较于Faster R-CNN[12]来说更加简洁直观。它使用预先定义的anchor 来取代Faster R-CNN 中的RPN 网络生成anchor 的方法,网络的检测速度取得了显著的提升。
YOLO v4 继承了YOLO v3[13]的主干结构,在特征提取结构上,不同于YOLO v3 中DarkNet53里面的残差块的连续堆叠,融合了CSPNet 结构,提出了CSPDarkNet53,将堆叠的残差块拆成了2个部分,主干继续进行原来的残差块的堆叠,另一部分则像一个残差边一样,经过少量处理后直接连接到最后,图1(a)为其中一个使用了CSP结构的堆叠残差块,cat 表示在通道维度上进行堆叠的操作;在特征融合的结构中,使用SPP(Spatial Pyr‐amid Pooling)来增加感受野,如图1(b)所示,分别用5个不同尺寸的最大池化进行处理,最大池化的池化核分别为13×13,9×9,5×5 和1×1,用PANet取代了YOLO v3 中的FPN 结构,能够更好地对特征进行融合,先对有效特征由高到低进行融合,再由低到高融合一遍;输出则和YOLO v3 一致,在输入图片尺寸为416×416 时,输出尺度分别为13×13,26×26和52×52。

图1 CSP和SPP结构Fig.1 Sructure of CSP and SPP
对于其中一个anchor,YOLO v4 的损失函数为:
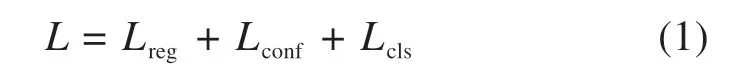
该函数主要由3部分组成,分别是边界框回归损失Lreg,置信度损失Lconf和分类损失Lcls。对于边界框回归损失,YOLO v4 用CIOU 函数取代了传统MSE 函数,能够使预测框(Bounding box)更快地向真实框(Ground truth)逼近;置信度损失函数为交叉熵(Cross entropy)函数,不论该anchor 产生的预测框是否包含物体,都要计算置信度损失;分类损失函数同样是交叉熵函数,当该anchor 负责真实的物体预测时,才会对该anchor 产生的预测框计算分类损失。
2 改进的YOLO v4算法
本文主要是检测和定位侵入列车行驶区域的障碍物,而YOLO v4 是根据公开的数据集来进行设计的,网络的模型结构与anchor 的取值不一定适合本文所研究的对象。通过分析本文的检测数据,对训练集的真实框进行聚类以获得符合目标尺寸的anchor,并引入注意力机制来进一步提升侵限异物检测的准确率。
2.1 anchor的选取
Bounding box 的预测以anchor为基础,其质量的好坏直接影响最终的检测结果。通用的anchor都是在大型数据集上经过聚类得到的,对于特定的检测任务,使用默认的anchor 尺寸,不仅会影响检测的准确度,而且在训练过程中容易出现模型难以收敛的情况。
同YOLO v3 一样,YOLO v4 中默认的anchor也是用K-means算法产生的。对于给定的数据和划分类别数,K-means的主要思想就是使属于同一类的数据到本类聚类中心的距离尽可能小,而不同类的数据到对方聚类中心的距离尽可能大,从而经过迭代确定各类的中心。
最终聚类结果的好坏与初始中心点的选择有很大关系,K-means采用完全随机的方法在所有数据中心选择出初始的聚类中心。由于随机性太大,若产生的初始聚类中心不太理想,可能会使最后的聚类结果陷入局部最优。为了改善随机选取聚类中心所带来的不利影响,本文提出了一种新的聚类中心选取方法,使得每个聚类中心尽可能分散。 对于包含m个样本的数据集D={x1,x2,x3,…,xm},其中每个样本xi是一个n维特征向量,需要聚类的类别数为k,则具体计算流程如下:
1)从数据集D中随机选取一个样本xi作为一个聚类中心;
2) 计算目前确定的所有聚类中心到整个样本点之间的最短欧式距离Dist(•,•),则距离最大的确定为下一个聚类中心;
3) 循环第2 步操作,直到选择出k个聚类中心。
经过对聚类中心选取方法的改进,在4k2_far数据上对本文所提聚类中心选取方法和K-means算法中的中心选取方法进行了对比,结果如图2 所示,图中五角星为选出的初始聚类中心点。可以看出,图2(a)中本文方法所选取的中心都平均分布于每一类当中,而图2(b)中K-means 选取的中心点会因为数据中某几类数据量差距悬殊,随机初始化的聚类中心很难出现在数据量少的类别中。
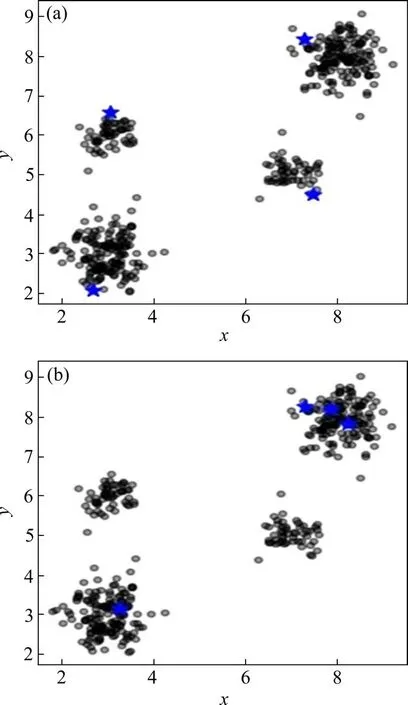
图2 聚类中心选取方法比较Fig.2 Comparison of cluster center selection methods
通过使用优化了初始聚类中心选择的K-means算法对训练集中标注的物体真实框(Ground truth)进行聚类,得到了符合本文要求的anchor 尺寸,分别为(13,31),(22,72),(34,40),(45,130),(62,46),(87,143),(132,291),(220,162)和(327,340),所用数据图片尺寸大都在500~800像素之间。
2.2 注意力机制
当网络达到一定的深度后,相应的语义信息也会更具体,但也会存在一定的冗余的特征[14],选择出对最终预测结果贡献大的特征很有必要。受人类注意力机制的影响而提出的注意力模型广泛应用于计算机视觉任务中,并取得了不错的效果。
SE模块[15](Squeeze-Excitation Module)作为目前应用广泛的注意力模型之一,具有结构简单、易于部署等优点,其结构如图3 所示。SE 模块的主要功能是通过学习对输入的特征赋予不同的权值,最终是对最后预测结果贡献大的特征具有较大的权重。其中的操作过程可以分为对输入特征的挤压和激励。对于尺寸为C*W*H的输入特征,首先在通道(C)维度上对特征图进行全局平均池化(Global Average Pooling,GAP),把输入特征压缩为1*1*C的一维特征;然后以压缩后的特征作为输入,经过一个含有一个隐含层的全连接网络学习不同通道上的权值大小;最后将学习到的权值与输入特征相乘,得到激活后的特征。具体计算过程如式(2)所示:

图3 SE模块Fig.3 SE module
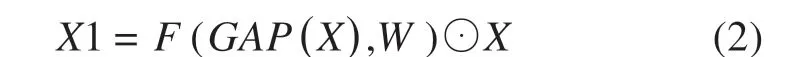
其中,X为输入特征;GAP(•)表示全局平均池化操作;F(•,•)表示全连接操作,将sigmoid 函数作为输出层的激活函数,使学习到的权值分布在0-1之间,代表各个通道的重要程度;⊙表示采用广播机制的乘法,学习到的权值与X中对应通道的所有特征点逐个相乘,最终得到激活后的特征X1。
2.3 改进后的网络结构
在侵限异物的检测任务中,有时因为光照变化、降雨等环境因素的影响,会使有些待检测异物与背景相似度变高,加大了检测难度。为了提高对这类物体的检测精度,对YOLO v4 的结构进行了改变,将SENet加入到网络里面。
改进后的YOLO v4 检测网络如图4 所示,输入图像尺寸为(416,416,3),在第3 个和第4 个CSPResblock 和Conv59 层后面分别插入一个SENet,对特征图赋予不同的权值,选出对检测结果贡献大的特征图,以实现更精确的检测。
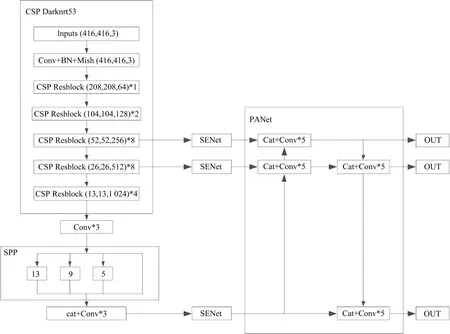
图4 改进后的网络结构Fig.4 Structure of improved network
3 实验
3.1 实验运行环境及数据准备
表1为本文进行实验的主要硬件环境,软件环境主要有ubuntu16.04, pytorch1.2, cuda10.0,opencv-python3.4.2等。

表1 实验硬件环境Table 1 Hardware experiment environment
在实验数据上,由于目前并没有公开的铁路侵限异物数据集,并且考虑到侵限异物的局限性,行人、汽车、自行车和动物(狗)这些也是在异物侵限事件中出现频率最高的,所以选择以行人、汽车、自行车和狗作为本文研究的典型异物来进行实验。训练集主要分为2部分,一部分来自公开的数据集(Pascal voc2007/2012)中与本文研究对象特征相近的数据,另一部分来自课题组所收集整理的数据。测试集数据则是截取了列车行车记录仪和铁道上的监控视频中记录的有侵限异物的图片。训练集共有4 000 张图片,测试集有100 张图片。其中来自Pascal voc2007 与2012 数据集中的各有1 500张,1 000张为自制数据,为了降低因类别不均衡所带来的性能损失,人为的挑选数据图片使得各类别物体样本数量保持相对均衡。测试集中的各个类别也保持相对均衡,平均有60 个物体实例。
3.2 训练过程
输入网络的图像尺寸为(416,416,3),总共训练200 个epoch,batch size 为5,使用Adam(Adaptive Moment Estimation)算法[16]来进行参数的优化,权重衰减系数设置为0.000 5,学习率在前100 个epoch 设为0.001,后100 个epoch 设为0.000 1 来使模型更好的收敛。在训练过程中从训练集里划分400 张图片作为验证集数据,训练集和验证集的loss 曲线如图5 所示,可以看出最终训练集的loss收敛到了0.7,验证集loss则在7左右,检测模型已经收敛。
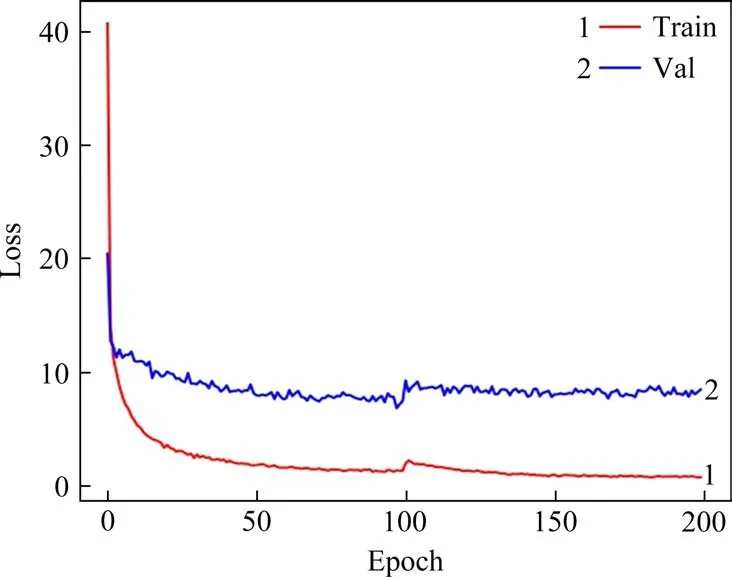
图5 训练集和验证集的loss曲线Fig.5 Loss curve of training set and verification set
3.3 实验结果及对比分析
图6为使用训练好的检测模型对不同的侵限异物进行检测的结果。可以看出,本文方法对大部分的侵限异物具有不错的检测效果,能以较高的置信度准确地检测所要检测的物体,但是在第4幅图中出现了将2 只狗检测为1 只的情况。经过进一步分析,图中2 只狗的所占像素尺寸分别为28×61和58×58,在整个图片中的占比不过3%,属于小目标物体,而且小目标的检测一直是目标检测领域研究的重点与难点,这也是本文所提算法模型进一步优化的方向。

图6 对不同侵限异物的检测结果Fig.6 Detection results of foreign bodies with different invasion limits
为了进一步研究本文所提方法在轨道侵限异物检测方面的有效性,对比了本文所提方法和其他检测方法,包括现有的研究成果和YOLO v4 算法。徐岩等[17]提出了一种基于Faster R-CNN的侵限异物检测方法,具有较好的检测效果。模型的对比实验均是在同一个数据集上训练及测试。
图7 为暗光环境下3 种方法的检测结果对比,共有3个待检测物体实例。暗光环境下成像质量普遍较差,图像中含有一定的噪声,且背光面几乎为黑色,语义信息较弱,从图中可以看出,远处路边的汽车几乎只能看到轮廓。从检测结果来看,本文所提方法与文献[17]的方法都正确地检测出了3个物体,而YOLO v4算法则未能检测出远处的汽车;从预测框的质量来看,本文方法和文献[17]方法的预测框质量对检测目标的包裹性相似,且质量明显高于YOLO v4 算法的预测框,图7(c)中近处车辆的检测框向右的偏移比较大,没有完全框住目标,而中间人的检测框纵向延伸较为明显。

图7 暗光环境下的检测结果对比Fig.7 Comparison of detection results in dark light environment
图8 为3 种方法在遮挡情况下的结果对比,右边中间的人被遮挡面积超过80%,只有头和肩膀露在外面。图8(a)和图8(c)都没有检测出被遮挡的人,只有采用本文方法的图8(b)正确地检测出了被遮挡的人,并且检测框的质量也比较高。

图8 遮挡情况的检测结果对比Fig.8 Comparison of detection results of occlusion
以上实验结果证明,对K-means算法初始聚类中心选取方法的改进,使得最终聚类获得的anchor更具代表性,通过网络计算的检测框也更加符合要求;而注意力机制的加入,提高了对弱特征的关注,网络的检测性能得到了进一步提升。相较于基础的YOLO v4 算法,本文所提方法具有一定的优越性。
平均精度(Average Precision,AP)和平均精度均值(mean Average Precision,mAP)是定量分析一个检测模型性能好坏的常用指标。平均精度用来分析检测模型在每个类别上的检测性能,是评价检测模型的直观评价标准,而平均精度均值则反映了模型在所有类别上的综合性能。
表2列举了本文方法与文献[17]方法和YOLO v4方法进行对比的结果,对比指标主要包括单个类别的平均精度、平均精度均值和视频检测帧率。分析表中数据可知,由于双阶段检测网络Faster RCNN的先天优势,文献[17]在检测精度上处于领先地位,平均精度为92.4%;通过对比采用了以YO‐LO v4 作为基础检测网络的本文方法和YOLO v4网络,本文方法在各个类别上的检测精度都有明显提升,在平均检测精度上提高了5.1%,仅比文献[17]方法低2.2%。对于视频检测帧率这一指标,本文方法和YOLO v4 算法表现出了极大的优势,都在50 fps 以上,大大超过了文献[17]的14 fps,本文方法在视频检测的实时性上表现出了极大的优越性。

表2 不同检测方法间的性能对比Table 2 Performance comparison of different detection methods
综上所述,本文所提出的基于YOLO v4 的检测模型,虽然在检测精度上不如文献[17]的方法,但是相差很小,而且本文方法在检测的实时性上领先于文献[17]的方法,故本文方法有一定的实用性。
4 结论
1) 将YOLOv4 算法应用于铁道侵限异物检测任务之中,对常见的侵限异物类别取得了90.2%的平均检测精度均值和53 fps的检测速度,并且可以同时检测出不同种类的侵限异物。
2) 本文方法通过对聚类中心选取算法的改进来获得更具代表性的anchor 尺寸,加入的注意力模块进一步提高了检测精度。
3)相较于以Faster R-CNN 为基础的检测网络,本文方法在检测精度接近的情况下,检测速度有了极大的提升,实现了实时检测。
