因果推断、科学证据与教育研究 *
——兼论2021 年诺贝尔经济学奖得主的教育研究
2022-03-30黄斌李波
黄 斌 李 波
(1. 南京大学教育研究院,南京 210023;2. 南京财经大学公共管理学院,南京 210023)
一、引言
2021 年10 月11 日,瑞典皇家科学院将诺贝尔经济学奖授予加利福尼亚大学伯克利分校教授戴维·卡德(David Card)、麻省理工学院教授乔舒亚·D 安格里斯特(Joshua D. Angrist)和斯坦福大学教授吉多·W·因本斯(Guido W. Imbens)。在颁奖典礼致辞中,诺贝尔经济学奖评委会主席彼得·弗雷德里克森(Peter Fredriksson)如此评价三位获奖者的学术贡献 “你们的研究表明社会核心问题完全可以通过自然实验得以回答。······你们彻底改变了经济科学中的经验研究。得益于你们的研究,我们回答关键因果问题的能力得到了极大的提升”(Fredriksson,2021)。事实上,这并不是因果方法第一次登上诺奖舞台。2019 年,阿比吉特·班纳吉(Abhijit Banerjee)、埃丝特·迪弗洛(Esther Duflo)和迈克尔·克雷默(Michael Kremer)三位学者就因运用随机对照实验方法为全球脱贫做出的学术贡献而获得诺贝尔经济学奖。社会科学研究实现因果推断有两种方法:随机对照实验(Randomized Controlled Trial,RCT)与自然实验(Nature Experiment)或准实验(Quasi-experiment)。随机对照实验是实现因果分析的“黄金法则”,它通过随机分组形成处理组和控制组之间的数据平衡,由此实现对干预的因果效应的正确识别。随机对照实验源自农业科学,普遍应用于医学与药物研究,班纳吉、迪弗洛和克雷默的学术贡献在于将随机对照实验大规模地应用于社会政策项目与改革成效评估;自然实验或准实验也是以随机对照实验原理为理论基础,但它采用的是非实验性的研究设计,对非实验的观测数据进行“改造”,使之具有与实验数据相类似的平衡特征,并由此获得与随机实验具有同等或相近的因果推断效力的结论。卡德、安格里斯特和因本斯的学术贡献在于他们突破原有的实验研究局限,创新性地发展出基于观测数据的因果推断方法,使因果推断方法在社会科学领域拥有了更广阔的应用空间。
近三十年来,因果推断方法在推动社会科学经验研究发展方面取得了巨大的成功。正如哈佛大学教授加里·金(Gary King)等人指出(King et al., 2021):“在过去几十年里,人们对因果关系的了解比以往的总和还要多。”虽然卡德、安格里斯特和因本斯的主要研究领域是劳动经济学与计量经济学,但鉴于教育对个人劳动参与和收入所具有的重要影响,他们的许多重要研究都与现实教育问题及教育制度变革密切相关,包括教育收益率估计、小班化教学效果、学校投入对学生认知能力发展的影响等。他们在这些方面做出了许多极富创新性的工作,并取得了丰硕的成果,这是教育研究者无法回避,且必须回应的。
探寻事件之间的因果关系是人类不断追求真理的前进动力,决定论与因果律一直是西方哲学研究最重要的内容之一。亚里士多德在其论著《物理学》中便就掌握因果律对于了解自然变化的重要作用进行了充分的阐释:“既然我们的目的是要得到认识,又,我们在明白了每一个事物的‘为什么’(就是说把握了它们的基本原因)之前是不会认为自己已经认识一个事物的,所以很明显,在生与灭的问题以及每一种自然变化的问题上去把握它们的基本原因,以便我们可以用它们来解决我们的每一个问题。”(亚里士多德,1982,p. 37)秉承这一传统,大卫·休谟从经验主义立场出发对因果关系进行考察,他主张“事物的知识应当以因果关系为基础,只有因果关系才能使我们超出感觉和记忆的范围。对于因果关系并不能有先验的认知,只可能借助于经验,而要得出超过经验的任何知识又必须假设因果关系”(休谟,1957,p. 61)。
因果知识很重要,却不易获得。现代人类正身处信息大爆炸的时代,手握各种信息技术利器,可轻易地获取巨量的数据。数据可以告诉我们很多知识,比如它可以告诉我们目前国人的平均收入水平有多高,与之前相比是增加还是减少了,与其他国家相比处于何种水平。这些属于描述性知识。再比如,它还可以告诉我们国人的收入水平会随着个人性别、教育水平、居住地域发生怎样的变化。这属于相关性知识。描述性知识和相关性知识都是非常有益的信息,它们能帮助我们快速了解我们所生活世界的整体状况,但还不够!因为我们不仅希望了解自身所处的物质世界和精神世界是怎样的,更希望了解它为什么会是这样。描述性知识和相关性知识只能回答“是什么”的问题,回答不了“为什么”的因果问题。因果知识对于指导人类社会正常和健康发展是极为必要和重要的,唯有因果知识方可解答“为什么”的问题,为人类下一步的行动提供可信的指引。
“对于因果关系方面的知识来说,数据没有任何发言权” (珀尔和麦肯齐,2019,导言, 第XXIII页)。因果解释只存在于数据之外的人类的想象和逻辑推理之中。事实上,因果推断的思维早已存在于人类意识之中,人们脑中储存了大量的因果知识,正如远古人早就明白在狩猎时团结协作要比单枪匹马能收获更多的猎物,现代人只要早上出门上班发现下雨,就会立刻意识到今天早高峰会大堵车。虽然人类早已掌握并习惯于运用因果思维进行行为决策,随机实验法在100 年前就已经被提出(Fisher & Mackenzie,1923),但人类的因果思维一直未被正式的模型化和数学化,因果推断方法得不到系统的发展,这极大阻碍和限制了因果知识在改善我们人类生活方面的作用的发挥(珀尔和麦肯齐,2019)。
值得庆幸的是,自20 世纪七八十年代以来,经过唐纳德·鲁宾(Donald B. Rubin)、朱迪亚·珀尔(Judea Pearl)、吉多·W·因本斯、乔舒亚·D·安格里斯特等一批学者的努力,包括潜在结果框架(Potential Outcome Framework)与有向无环图(Directed Acyclic Graphs)在内的专门用于因果识别的数学语言和分析框架被系统地建立起来。目前,因果推断方法已被大量地应用到经济学、人工智能、医学、心理学等领域研究中,并正快速向教育学、社会学、政治学等领域渗透。教育学科正处于因果推断方法由经济学向其他社会科学领域扩张的“最前线”,教育科学研究正酝酿着一场因果推断“方法革命”。在以下篇幅中,我们将先从教育研究的人文与科学属性入手,阐明获取因果证据对推动教育科学研究发展的重要意义,再重点介绍2021 年诺贝尔经济学奖得主在教育领域的一些重要研究与发现,最后对当前我国教育因果研究所存在的问题及未来改进方向进行讨论。
二、教育研究的科学属性与因果证据
(一)教育学科的科学属性
关于“教育学是否是科学”一直颇有争议。在日常生活和教育实践中,教育总是给人一种与科学无涉的印象。“人人都是教育家”,对教育问题进行研究、对教育现象进行剖析似乎不需要深奥的专业知识,即便是彻头彻尾的外行人,都能对教育问题、现象或观点评头论足一番(中室牧子,2017)。之所以有此现象,一方面可能是因为教育与我们离得太近,参与教育活动是人类日常生活的一部分,绝大多数人都曾经或正身处于接受教育或施行教育的情境之中;另一方面,教育研究给人一种没有门槛的错觉,它似乎不像讨论其他学科问题那样需要具备高深的知识,只凭借一般经验或观察便可以获得足够的知识用于指导教育实践。教育研究似乎只需描述现象或做价值判断,不需要科学理性,不存在“为什么”的问题,只有“是什么”和“怎么做”的问题。人们习惯于关注教育现象并发表见解,却较少关心教育现象发生的原因,似乎只要把当前所存在的教育问题“痛骂一通”,便完成自己对所有教育本源问题的解构。
公众通常相信自然变化有一般规律,对自然变化规律的研究可诉诸理性与科学,而人的教育行为及结果无规律可循,研究教育只存在伦理与道德上的应然问题,无因果实然研究之必要,因此无须理性与科学。然而,事实并非如此,不是只有自然之物才具有规律性,人类行为及互动以个体的生理为基础,并受制于社会制度、群体行为与道德规范,因此在群体层面上亦会呈现出一定的规律性。
早在18 世纪40 年代至19 世纪中叶欧洲启蒙运动时期,孟德斯鸠、卢梭、亚当·斯密、康德等一批思想家在采用理性精神与科学方法破除传统宗教对人类思想的操控与束缚的同时,便已尝试运用相同的方法建立起“人的科学”,用以形成对人类自身情感与行为的普遍性与规律性的理解和认识(平克,2019, p. 10)。教育研究“天然”具有科学属性:一方面虽然不同个体的主观意识存在差异,生理却存在共性。个体的发展符合生理规律,掌握了这种规律可极大程度地提高教育效率。另一方面,人作为独立的个体虽具有一定的主观能动性,但其生活必须遵从既有的文化、生物演进和社会客观事实,并最终形成规律进而约束着人类的生存与发展活动。因此,社会个体有其独特性和异质性,但作为群体其一定存在着共性和规律(袁振国,2019,2020)。
(二)因果证据与教育科学研究
当前,有不少教育及其他社会科学研究依然延续传统政策研究的风格,偏重于描述教育现象及“说理性”分析,虽然近年来教育量化研究数量与成果不断增多,但研究方法还停留于描述性和相关性阶段,缺乏因果解释力,这极大限制了我们运用经验证据指导教育政策制定的能力(陈云松和范晓光,2010)。因果必定相关,而相关未必因果。正如我们运用爬虫技术可以轻易地从网络获得白菜价格与汽油价格的日常变化数据,并通过相关分析发现二者存在显著的正相关关系,但我们永远不会想到用改变白菜价格的方法来调控汽油价格的走向。相比之下,因果分析能够提供变量间可靠的因果关系信息,决策者利用这一信息可以制定出有效的政策干预工具,改变人群的行为走向及其结果,使其未来的发展与政策预期目标相一致(黄斌等,2017)。因果性是科学证据最重要的特质,大卫·休谟甚至将科学的唯一功用定义为因果性,在他看来,“科学唯一且直接的功用是告诉我们如何从原因来控制和调整未来发生的事件”(Hume,2007, Section VII, Part II, p. 56)。从这一角度看,科学证据即等同于因果证据。
除相关概念外,政策制定者、学者和公众还常将“常识(Common Sense)”与科学或因果证据混为一谈,误将基于个体经验所形成的“常识”等同于科学证据。所谓“常识”是指大多数人普遍认可的观点或知识,但目前在教育领域有多少观点或知识是被多数学者所认可的呢?在笔者所在的教育经济学界,数十年来形成的共识可以说是寥寥无几,学者们在许多重要的具体研究议题上始终存在着巨大的分歧。以增加学校投入能否提高学校教学质量这个看似简单的命题为例,该议题从20 世纪60 年代美国学者科尔曼发布《科尔曼报告》以来,便一直存在争议。有大量研究发现公立学校的绝大多数投入都是无效的,尤其是我们之前认为十分重要的一些物力或货币投入(如基建投入)与教师特征(如教师学历、教龄与性别),对学生学业成绩都不具有显著的影响或只具有微小的影响。这一现象不仅存在于发达国家,发展中国家亦是如此(Glewwe et al.,2011)。
在人类行为互动形成的社会场域中,事件与事件之间的因果关系是复杂的,并且经常随时空和人群发生变化,很难凭借个体的经验或常识就能观察清楚。仅凭借未加科学验证的所谓“常识”进行教育政策决策,面临着极高的犯错风险。常识不能作为科学证据,相反,常识往往是需要进行科学验证的对象。曾经的异端(如日心说),在当下可能是常识;而曾经的常识(如地心说),在当下可能是异端。此外,基于个体经验所形成的常识缺乏客观的价值评判标准,每个个体的教育背景不同,所身处的社会经济环境亦不同,这使得个体经验存在较大差别,你有你的常识,我有我的常识,凭借常识说理常导致“公说公有理,婆说婆有理”的局面。
教育政策的制定需以富含因果关系信息的科学证据作为决策依据。当前,教育因果研究主要集中在教育政策评价领域。对教育政策进行科学评价需要判定政策实施与现实教育结果之间的关系,并量化这种关系的正负方向与大小(袁振国,2017)。然而,除政策外,现实教育结果还受其他许多因素的影响。我们要形成特定政策与现实教育结果之间一一对应的因果关系,就需要通过一定的因果研究设计剥离教育现象之间复杂的干扰因素,揭示特定政策与现实教育结果的因果关系,从而为我们制定对策、改良社会提供依据(辛涛和姜宇,2013;胡咏梅和唐一鹏,2018)。在以往文献中,由于缺少对因果关系的准确定义与判定条件界定,不少政策研究常将只具有相关含义的结论表述为因果结论,这使得不同研究对同一教育政策的量化评价结果不具有可比性。因果推断方法的发展带来了新的量化技术标准,使得不同教育政策研究的质量至少在“相关—因果”这一维度上高下立判。在统一的因果关系分析框架下探求过往不同教育政策的成败原因与得失经验,可帮助我们积累更多有关人类教育行为的有效知识,在科学的客观标准之上取得更多经验证据与社会共识,以减少未来政策重蹈覆辙的可能性。
(三)教育的人文属性与因果研究的兼容
诚然,教育学又不完全只是科学的,它是兼具人文与科学双重属性、集价值和规律为一体的社会科学。教育事关人的终身发展,是人的基本权利,每个个体都有权利接受恰当的教育,这是人类社会在数千年演化过程中形成的“公理”,不证自明!人文关怀理应成为我们制定并实施教育政策、开展教育活动的哲学和伦理基础。然而,人类教育活动带有的主观价值倾向与其客观规律之间关系并不是对立的而是统一的,教育的人文研究与因果科学研究二者并不矛盾,教育研究侧重价值判断未见得就偏离科学,强调科学理性分析亦非无法兼容价值判断。
一方面,教育人文关怀功能的实现需要科学研究与因果证据的支持。人文关怀由单一家庭、群体、民族、阶层与国家向外延展,不仅需要人类基于同情心与同理心形成统一的道德认识,更需要获得这一具有超越性的统一道德认识的能力。正如阿马蒂亚·森在其论著《以自由看待发展》中所阐述的“(自由)应该是一个人选择有理由珍视的生活的实质自由—即可行能力”(森,2002,第62 页)。个人实现其应有权利在很大程度上取决于他功能性活动的质量,而其功能性活动本身就在生理与心理层面上具有一定的自然和社会规律性。掌握含有关人类教育活动规律内容的因果知识对于提升人类在教育方面的“实质性自由”是极为重要的。另一方面,教育研究的人文属性要求研究者需对一些教育“应然”问题抱有强烈的价值倾向与价值判断,而这一倾向与评判的发生本身也内含因果逻辑。尤其是当我们基于效率或公平的价值标准对多种可能的教育政策选项进行取舍时,我们必然要寻求一定的科学因果证据的支持。我们身处在一个资源稀缺的世界,公共教育与其他公共支出之间、公共教育中不同类型投入之间都存在着极为激烈的预算竞争,教育的生产与分配活动始终面临着效率与公平的两难抉择。通过科学的手段探寻人类教育行为的因果规律,可帮助我们在资源有限的条件下以最小的投入获得更多的教育产出并实现更加均衡的教育分配,实现教育效率与公平的共进。
三、诺贝尔经济学奖得主在教育领域的重要研究发现
2021 年诺贝尔经济学奖三位得主中,因本斯的研究偏因果计量技术研发与推广,其与著名统计学家唐纳德·鲁宾(Donald B. Rubin)合著的Casual Inference for Statistics, Social, and Biomedical Sciences被誉为因果方法最经典的教材(Imbens,2015)。相比之下,安格里斯特和卡德的研究偏方法应用,发表文章中有许多涉及教育,尤其是安格里斯特,他绝大部分代表作都与教育有关。以下,我们将对安格里斯特和卡德在教育领域的重要研究与发现进行详细介绍。
(一)教育收益率的因果推断
估计教育收益率是劳动与教育经济学最重要的研究议题。接受更多教育的人拥有更高的工资收入,这几乎是众人皆知的“常识”。然而,接受教育与工资收入之间是否存在因果关系,在学界长期存在争议。个体拥有更高的工资收入,究竟是由于他相较常人接受了更多教育,还是由于他原本就拥有高于常人的天赋能力?也就是说,我们日常观测到的“高教育拥有高收入”现象可能反映的只是二者之间的相关关系而非因果关系。
如以下明瑟方程(Mincer,1974):
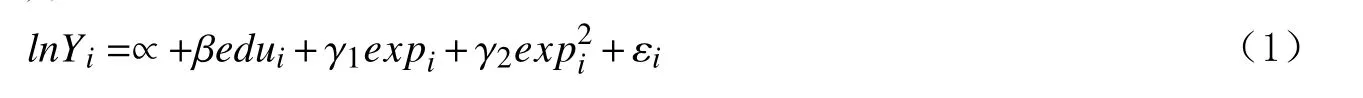
其中,lnYi表示个体i收入的对数值;edui表 示个体i的 受教育年限,估计系数 β即为教育收益率,表示个体受教育年限每增加1 年,其收入增加百分之几;expi和exp2i分别表示个体i的工作经验及其平方项,εi是随机误差项。
可以想象,一个人所受教育会受其天赋能力与家庭背景的影响,而天赋能力与家庭背景又对个人收入具有重要影响,能否有效控制天赋能力与家庭背景的混淆作用对于精确估计教育收益率至关重要。然而,在研究者掌握的数据资料中,天赋能力与家庭背景变量常常因不易测量而被遗漏,如上述明瑟方程(1)就未控制这两个变量,此时个人受教育年限变量由个人天赋能力与家庭背景内生决定,估计系数 β有可能偏估了教育收益率。在遗漏重要变量的条件下,估计系数 β可能只反映个人教育与收入的相关关系,而非因果关系。①解决这一偏估问题的办法主要有以下三种:
一是将个人的智力或认知能力的测验分数作为天赋能力的代理变量,同时控制家庭社会经济背景变量。该方法采用直接控制的方式,其优势在于简明,问题在于智力或认知能力得分可能并不能完全反映个人的真实能力。
二是采用双胞胎样本消去不可观测因素的混淆作用。(同卵)双胞胎继承了相同的父母基因并在同一家庭背景中成长,若他们的收入和教育水平都存在差异,那么收入差异就很可能是由于他们拥有不同的教育水平引起的。该方法存在两方面问题:(1)双胞胎样本过于特殊,其估计结果的代表性存疑;(2)它无法解释为何具有相同基因和家庭背景的双胞胎却在教育与收入水平上存在着差异。在双胞胎样本中,我们常观测到不少拥有相同教育水平的同卵双胞胎在收入上也存在差异,这意味着即便是同卵双胞胎,也未见得是完全同质的,他们可能在偏好、态度、能力和健康等方面存在着差异,遗漏这些变量也会导致教育收益率偏估(Bound & Solon,1999)。
三是采用工具变量法从个人受教育年限变异中剥离出一部分与个人能力、家庭背景及其他异质特征都无关的外生变异,将其用于教育收益率估计。诚然,有效的工具变量需满足一定条件,不是所有变量都适合做工具变量。例如,以往研究常以父母或配偶教育水平作为工具变量,但它可能不是一个好的工具变量,因为有不少有关收入代际流动和婚姻匹配的研究表明,个人收入水平与其父母或配偶的受教育水平显著相关(Becker,1973;Buss,1986)。一种更高明的做法是利用一定的政策冲击构建一个具有随机外生特质的工具变量,安格里斯特就是最早提出并采用这一工具变量设计思路的学者之一。
1991 年,安格里斯特与艾伦·克鲁格(Alan B. Krueger)在Quarterly Journal of Economics合作发表文章Does Compulsory Attendance Affect Schooling of Earnings?。该文巧妙利用义务教育法形成自然实验设计,以出生季度作为工具变量实现对教育收益率的一致估计,堪称教育收益率和工具变量法研究的经典之作。关于义务教育的入学年龄,许多国家都有法律规定。美国各州一般规定到当年12 月31 日前年满6 岁的孩子可以在当年9 月份入学接受义务教育,这一限制会使个体入学年龄产生差异。第四季度出生的孩子入学时年龄较小,而第一季度出生的孩子入学时年龄较大,出生季度不同导致入学年龄的最大差异可以达到近一岁。此外,美国各州对学生结束义务教育的年龄也有严格规定,大部分州要求儿童结束义务教育不得早于16 周岁。学生入学和退学时间的法律限制使得个人出生季节对其受教育年限具有影响。
利用美国1980 年全国普查数据,安格里斯特和克鲁格绘制出人口平均受教育年限随出生年份与季度变化的折线。如图1 所示,折线标识的1、2、3、4 数字分别表示同一年份的第一、二、三、四季度。从该图可以看出,美国人口平均受教育年限随年份总体呈上升趋势,但在同一年内不同季节出生人口的平均受教育年限呈现出一种有规律的起伏变化。在同一年中第三、四季度出生人口的平均受教育年限总是比第一、二季度出生人口的平均受教育年限长,前一年第四季度出生人口的平均受教育年限也总比后一年第一季度出生人口长。
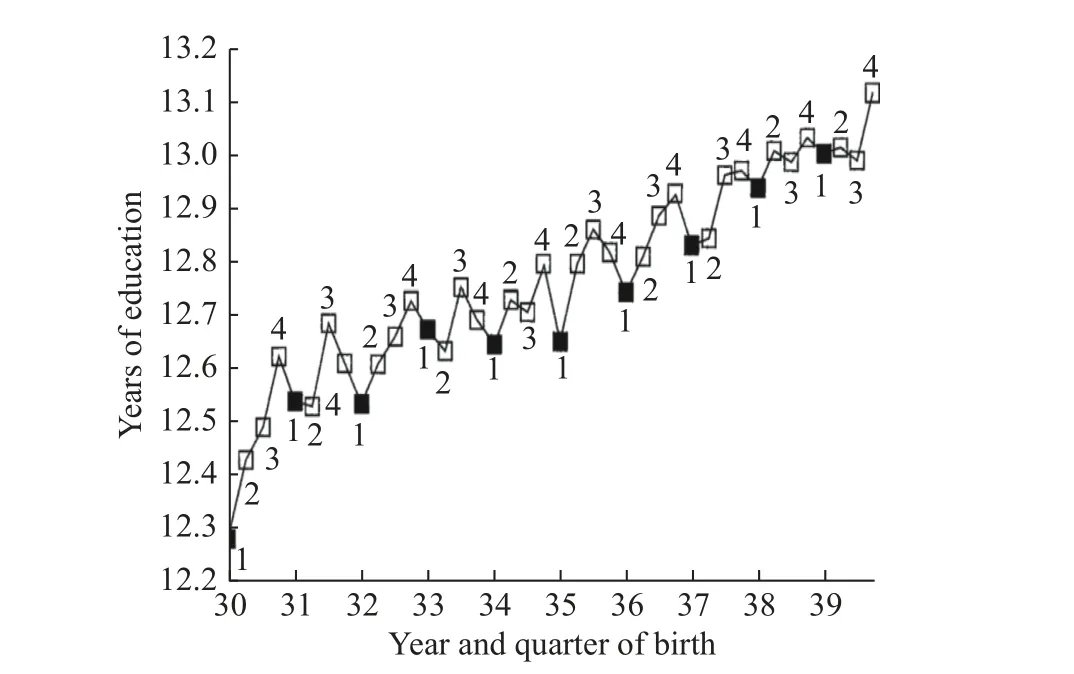
图1 美国人口的出生季度与受教育年限
通常情况下,在哪一季度出生是随机外生的,它与个人家庭背景和天赋能力无关,而图1 表明出生季度对个人受教育年限具有影响。这意味着我们可以利用个人出生季度这个工具变量,从个人受教育年限变异中分离出一部分与个人家庭背景和天赋能力无关的外生变异,并将该变异用于对个人收入的回归估计,形成对教育收益率的一致估计。采用这一思路,安格里斯特和克鲁格估计出1920—1929 年出生的美国男子的教育收益率为10.07%。相比之下,传统的OLS 估计结果为7.01%。工具变量估计结果高于OLS,但二者相差不显著。
这一结果是出乎意料的,因为当模型遗漏重要变量时,教育收益率的OLS 估计值应该是被高估的,采用工具变量法纠偏后的估计结果应当显著不同于OLS 的估计结果。然而,安格里斯特和克鲁格的估计结果却显示二者相差无几。工具变量法估计量的局部特质能解释这一“异常”现象。安格里斯特和克鲁格是利用义务教育法自然实验形成出生季度工具变量,他们所估计得到的教育收益率只代表了那些教育决策会受到义务教育法影响的人群,或者说,只代表了那些教育水平偏低人群的教育收益率,这部分人群学习能力较差且大都来自弱势家庭,属于易受义务教育法影响的“边缘易感”群体。根据边际收益递减原理,这部分人群的教育收益率一般要高于整体劳动力的平均水平,采用出生季度工具变量估计得到的教育收益率高于或接近于OLS 估计结果,就不足为奇了。
(二)班级规模与学业表现的因果推断
小班教学是近年来发达国家推进公立学校教学改革最重要的政策工具之一。小班教学改革既是一个“该如何教学生”的教育问题,更是一个“该不该投入及应如何投入”的财政问题。从财政的角度看,小班教学意味着学校需雇佣更多的教师,由此负担更多的教学和非教学成本,耗资巨大,成本极高,因此研究小班教学,首先要回答小班教学值不值得投入的问题。如果小班教学并不能提升学生的学业成绩,或对学生学业成绩只具有极为有限的影响,那么小班教学就不值得投入了。然而,想精确识别班级规模对学生学业成绩的因果效应是十分困难的,需采用特别的研究设计来解决因果识别过程中的一系列技术性问题(Card & Krueger,1996;李波和黄斌,2020)。
首先,学生的能力可能和其就读班级的规模相关。如果学生就读的学校奉行补偿式教育,将能力较差的学生优先分配到小班进行教学,此时学生能力就与班级规模正相关;相反,如果学校奉行精英教育,学生能力就会与班级规模负相关。其次,学生的家庭背景也可能与其就读班级的规模相关。条件优越的家庭倾向于将孩子送至教学质量更好的学校就读,由此导致学生家庭背景与其就读班级规模呈一定的相关关系。最后,学生就读学校的其他投入也有可能与其就读班级的规模相关。如果学校经费充足,教学条件优良,教师薪资待遇好而师资水平高,并有多余财力支持小班化教学,此时班级规模就与学校其他投入负相关;相反,学校财力原本就不富足,再挤出经费投入小班化教学,这势必会压缩学校其他财力投入,此时班级规模就与学校其他投入正相关。
如何解决以上小班化教学效果的因果识别难题?1999 年,安格里斯特和维克托里·拉维(Victor Lavy)在Quarterly Journal of Economics合作发表论文Using Maimonides’ rule to estimate the effect of class size on scholastic achievement,他们利用以色列政府对中小学班级最大规模的政策限制形成(模糊)断点回归设计,完成对小班化教学效果的一致估计(Angrist & Lavy,1999)。
有关班级规模与教学效果的讨论已有上千年的历史。早在6 世纪,犹太律法经典《塔木德经(Talmud)》就对集体学习圣经的人数规则有过讨论。12 世纪犹太哲学家迈蒙尼提斯(Maimonides)提出研习圣经的师生配比应达到一定标准,如果学生人数达到40 人,就应该增派助教。1969 年,以色列政府直接采用迈蒙尼提斯设立的规则,规定所有公立中小学校最大班额上限为40 人,如果同一年级在校生人数超过40 人,就要拆分为两个班授课。在该规则下,学生接受的是大班教学还是小班教学取决于同年级在校生人数。假定有两所学校A 和B,A 校某一年级在校生为40 人,B 校同一年级在校生为41 人。根据迈蒙尼提斯规则,A 校只开一个班授课,班额为40 人,为大班教学,而B 校要拆分为两个班授课,平均每班学生为20.5 人,为小班教学。也就是说,在校生人数由40 人变化为41 人,仅变化1 人,却使得学校平均班额由40 人下降为20.5 人。在校生人数变化1 人,这只是一种微小的变化,可视为随机的,由此所带来的班额剧烈变化也可视为随机的,它不受前述学生个体特征、家庭背景与学校投入的影响。因此,如果我们从数据中观测到随班级规模发生剧烈变化,学生成绩也发生了较大变化,便可认定班级规模对于学生成绩具有因果效应。
如图2,安格里斯特和拉维运用以色列公办小学数据绘制出年级在校生人数与班级规模、学生平均成绩变化关系图。如图2(a),横坐标是公立小学五年级与四年级在校生人数,纵坐标是各学校班级规模,实线表示根据迈蒙尼提斯规则绘制的班级规模随年级入学人数变化的理论预测线,虚线表示样本中各公立小学班级规模随年级入学人数变化的实际变化线,可以看出这两条线起伏变化高度吻合。图2(b)的横坐标依然是在校生人数,纵坐标变为各校学生的平均阅读成绩,安格里斯特和拉维“惊奇地”发现各校学生平均成绩的变化线同样呈折线变化,并且其变化方向与根据迈蒙尼提斯规则绘制的班级规模理论预测线正好相反,即当年级在校生人数未达到40、80 和120······人这些班级拆分点时,学校班级规模大都呈上升趋势,而此时学生的阅读成绩大都呈下降趋势。相反,一旦年级在校生人数超过这些班级拆分点时,学校班级规模大都呈下降趋势,而此时学生的阅读成绩却大都呈上升趋势。学生成绩与班级规模呈同时且反向的折线跳跃变化,由此可初步判定班级规模应对学生成绩具有一定的因果效应。基于这一研究设计,安格里斯特和拉维运用模糊断点回归估计出缩减班级规模对五年级学生阅读和数学成绩有显著的正效应,对四年级学生阅读成绩有微弱的正效应。

图2 以色列公立小学在校生人数、班级规模与学生成绩
(三)学校投入与学生学业成绩的因果推断
如前所述,在有关增加学校投入能否提高教学质量这一问题上,教育经济学界长期存在着争议。《科尔曼报告》发现美国公立学校投入在提升儿童学业成绩方面起到的作用极为有限(Coleman et al.,1966)。该报告一经发布,便在美国社会与知识界引发激烈的讨论。经济学家埃里克·汉纳谢克(Eric Hanushek)支持《科尔曼报告》的观点,他的系列研究显示学校投入与学生学业成绩确不存在一致性与系统性关系(Hanushek,1986,1989,1997,2003),而以拉里·赫奇斯(Larry V. Hedges)为首的另一批学者同样运用数据分析发现某些学校投入对学生学业成绩在一定程度上是具有显著影响的(Hedges et al.,1994a,1994b;Greenwald et al.,1996a,1996b;Laine et al.,1996)。
关于这一问题之所以有如此大的争议,主要是因为精确识别学校投入与学生学业成绩之间因果关系存在很大的技术困难。学校之间在投入水平上存在很大差异,而学生在不同学校之间的分配也是非随机的。现实中,通常情况是私立学校投入超过公办学校,精英学校投入超过普通学校,而学生择校行为又与其家庭背景和个人能力密切相关(Clark,2010)。因此,在学校投入与学生学业成绩的因果关系识别中,最关键的核心问题是如何构造出一种不同家庭背景与不同能力学生在私立学校与公办学校、精英学校与普通学校之间随机分配的数据条件。
为解决这一问题,安格里斯特与其合作者利用美国宪章学校(Charter School)随机抽签录取学生这一制度形成对此类学校教学效果的因果识别与估计。美国宪章学校是一种特殊的公立学校类型,此类学校同样接受政府财政的资助,但采用比传统公立学校更加灵活、更加自主的学校运营模式。在许多城市,宪章学校改革取得了很好的成效,宪章学校学生的平均成绩普遍高于传统公立学校同类学生。然而,有不少人认为宪章学校学生成绩之所以高,不是因为此类学校教学质量高,而是因为就读宪章学校的学生的学习能力原本就比就读传统公立学校的同类学生强,这些学生的家长也要比传统公立学校的同类学生家长更重视孩子的教育。
为解答这一疑问,安格里斯特等人利用马萨诸塞州林恩市KIPP(宪章)学校通过抽签决定学生入学资格这一随机事件形成工具变量,完成了对宪章学校教学效果的因果推断(Angrist et al.,2012)。按照马萨诸塞州政府规定,若学校每年入学申请人数超过既定的学额数,就要采用随机抽签的方式来分派学额。2005 年,林恩市宪章学校入学申请人数首次超过学额数,开始通过随机抽签决定申请学生的入学资格。学生是否抽中入学资格完全由“老天”决定,这是一个外生的随机变量。然而,获得入学资格的学生未必就读KIPP 学校,有一部分学生可能会放弃KIPP 入学资格而选择就读传统公立学校或私立学校。因此,是否获得入学资格对成绩的影响只是一种“意向性处理效应”(Intent-to-treat Effect,ITT),它不同于学生是否就读KIPP 学校对成绩产生的处理效应。
对此,安格里斯特等人提出,虽然获得入学资格不能直接作为处理变量,但它可以作为工具变量发挥作用。根据样本描述统计,在抽签获得入学资格的学生中有73%就读KIPP 学校,而未获得入学资格的学生中仅有3.5%就读KIPP 学校,这两个比例相差69.5%。安格里斯特等人跟踪了所有向KIPP 学校提交入学申请的学生的数学考试成绩,他们发现获得入学资格学生的数学平均成绩比全州平均成绩低0.003 个标准差,而未获得入学资格学生的数学平均成绩比全州平均成绩低0.358 个标准差,两者相差0.353 个标准差。根据工具变量的Wald 估计量公式:

可以计算出就读KIPP 学校对学生数学成绩的平均处理效应为:0.355/0.695=0.511,表明就读KIPP 学校能使学生平均数学成绩提高大约0.5 标准差。这一结果是在隔绝了学生个人能力、学习动机和家庭背景影响的条件下取得的,表明林恩市KIPP 学校学生成绩优于其他学校同类学生并不是学生和家庭自我选择的结果,KIPP 学校在提升学生学业成绩方面确实取得了显著的成效。
卡德对于学校投入亦有重要的研究发现。卡德对汉纳谢克的“学校投入无用”观点持怀疑态度,他认为将学生学业成绩作为学校教育结果过于短视,应以个人工资收入(而非学业成绩)作为学校教育结果。早在1992 年,卡德与克鲁格便合作发表有关学校投入的文章(Card & Krueger,1992)。他们以美国1980 年全国人口普查数据中于1920—1940 年出生的个体为样本,采用双向固定效应法(Two-way Fixed Effect),在控制个体出生队列与所在州固定效应,以及家庭背景的条件下,就一系列学校投入指标对个人工资收入的影响进行估计,发现有部分学校投入指标(如教师学历、女性教师占比等)对个人工资收入具有显著的正效应。
总的来看,根据已有的因果研究,现实中有大量的学校投入确实是无效的,尤其是一些我们曾以为十分重要的学校投入都对学生学业成绩无显著的因果效应(Glewwe et al.,2011)。为什么如此多的学校投入是无效的呢?一种最具说服力的解释是许多学校将资源都投入到不能有效促进学生认知能力发展的方面。如果这一解释成立,那么接下来我们所面临的将是另一个更重要的命题,即学生的认知能力究竟是如何形成与发展的,它最易受那些外界环境与投入的影响?对于这一问题,认知神经学家与经济学家早已开始进行研究,并取得了许多突破性的成果,有兴趣的读者可参见Heckman(2006)和Nelson & Margaret(2011)。
四、目前我国教育因果研究存在的问题
近年来,我国教育因果推断研究数量不断增多,研究质量亦不断提升,尤其是在义务教育政策领域,国内学者在应用因果推断方法科学评价过往教育政策改革成效方面取得了较丰硕的成果(如孙志军等人,2010;哈巍和余韧哲,2017;Huang et al.,2017;黄斌等人,2019;Ding et al.,2020)。但总体看,当前我国教育因果研究还处于“初级阶段”,国内教育领域从事因果研究的学者数量还不多,量化文献中因果研究数量占比还不高,高质量研究更是少之又少。以下,我们将对制约我国教育因果推断研究发展的若干问题进行讨论。
(一)重量化技术、轻研究设计
有别于传统量化研究,因果推断研究最重要的内核不是统计技术应用,而是准确识别干预分配机制并基于此形成有效的研究设计。要做到这一点,研究者必须对现实教育背景与政策改革有深入的了解,如此才能明白:在我们所研究的微观对象中,哪些对象接受了干预以及接受了怎样的干预;政策干预的分配是不是随机的;如果不是随机分配,处理组与控制组在哪些特征上存在显著差异;这些差异显著特征中有哪些会对因果关系识别产生混淆作用;我们应采用怎样的研究设计实现处理组与控制组的数据平衡,以获得因果关系的无偏估计;高质量的因果推断研究一定是先基于现实政策背景掌握政策干预的对象、内容与分配规则,了解处理组与控制组数据的非平衡表现,再有针对性地采用一定的因果研究设计实现处理组与控制组之间的数据平衡,最后才是运用一定计量技术完成参数估计、统计推断及各种假设检验。
与此相比,目前国内教育因果研究存在“头轻脚重”的问题,即过度重视后期统计技术“套路”的运用,忽视前期干预分配机制识别与研究设计工作。有不少研究花费许多笔墨介绍某一因果推断方法的基本原理、模型构建与估计法,对于真正需要浓墨重彩介绍的政策背景、干预分配机制与因果研究设计等内容,却总是一笔带过,语焉不详;另有一些研究过度追求数据结构与量化方法的复杂性,对形成有效因果识别的一些基础性工作却视而不见。笔者曾评审过一篇文章,该文利用我国农户多年跟踪面板数据,在控制个体固定效应的条件下对农村劳动力(已完成学校教育)的教育收益率进行估计,并宣称利用追踪面板数据进行估计能获得更加一致、稳健的教育收益率估计结果。“理想很美好,现实很骨感”,作者未曾想到既然样本中个体已完成了学校教育,那么在他所追踪的年份中同一个体的受教育年限变量取值必定是不变的,如此如何能通过个体固定效应模型估计出教育收益率呢?
(二)重参数估计、轻证伪检验
因果研究,无论是随机对照实验研究,还是基于可观测数据的准实验研究,其背后都蕴藏着极为严苛的前提假设与适用条件。当前国内有不少研究对各类因果方法的假设检验工作还不够重视。
因果推断研究是以潜在结果框架作为理论基础,此框架要求干预分配应满足非混淆性假设(Unconfoundedness),即个体是否接受干预应独立于其所可能获得的潜在结果。非混淆性假设是形成因果推断的最关键假设,但可惜的是,由于个体的潜在结果总有一方是无法观测到的,因此该假设无法被直接检验,只能采取证伪(Falsification)检验。倍差法的平行趋势检验、工具变量法的独立性检验、断点回归的概率密度检验与断点连续性检验、倾向得分法的数据平衡性检验都属于证伪检验。证伪检验惯用的逻辑是:“根据当前的研究设计所得到的因果结论,事件A 是不可能发生的,如果A 事件发生,即可证明该因果结论是不成立的。”以倍差法的平行趋势检验为例,该检验要求研究者应对干预发生之前处理组和控制组的结果变化趋势进行研判,如果在干预之前这两组的结果变化趋势就已经发生分化,那么在干预期,这两组的结果变化依然发生分化的可能性就非常大,此时控制组结果就不能作为处理组如果不接受干预时的反事实结果,若“强行”使用倍差法,估计得到的处理效应很可能就是有偏的。虽然本质上,证伪检验只能证明谁是“假”因果,不能验明谁是“真”因果,但对于研究者捍卫自身估计结果的因果性与内部有效性来说是极为重要的,不容忽视。
近年来,国内教育学期刊中使用倾向得分法的应用性文章数量激增,但该方法被滥用和错用的问题也最为突出。与其他因果方法相比,倾向得分法有三方面特性:首先,由于匹配变量通常包括若干随时间变化的特征变量,因此理论上实施倾向得分匹配应至少拥有两期跟踪面板数据。研究者使用干预发生前的基期数据进行处理组和控制组匹配操作,而后再使用干预实施后的一期数据进行处理效应估计。如此做的目的在于保证干预实施前处理组和控制组便已经处于数据平衡状态,如同我们在进行随机实验时总是在实验之前就完成处理组和控制组的随机分配。其次,偏估可分为可观测的显性偏估(Overt Bias)和未观测的隐性偏估(Hidden Bias)两大类(Rosenbaum,2002,p. 71)。倾向得分法只能用于纠正显性偏估,无力解决隐性偏估。也就是说,只有在模型中绝大多数偏估可以通过已有数据观测到的条件下,它才能形成对因果关系的正确识别。因此,为尽量减少模型偏估的可能性,实施倾向得分匹配必须要在匹配前后做数据平衡检验,以评估其对显性偏估的纠偏作用,并将匹配法与倍差法或断点回归法配合使用,以解决隐性偏估问题。最后,倾向得分匹配一般要采用一定方法对原样本进行重组,但这一过程包含许多带有浓厚主观色彩的技术操作,如匹配变量的选取、选择模型形式的设定、具体匹配法的选择等,不同的参数和技术组合可能会使匹配后样本的容量与结构发生较大变化,其估计结果亦“飘忽不定”。
对于倾向得分法的上述特性,国内已有研究大都不重视。以一篇刚在教育学刊物发表的文章为例,该文采用倾向得分法对农村劳动力的职业教育收益率进行估计,文中使用的数据是近期某年横截面的调查数据,处理变量为农村劳动力是否接受过正式的职业教育。该文存在一些明显的错误:一是样本中绝大多数处理组个体在调查之前就已经完成了职业教育,这意味着作者是采用干预发生之后的协变量对处理组和控制组进行匹配,所形成的是处理组和控制组在干预之后的数据平衡,严重偏离因果推断的重要假设;二是形成匹配样本后直接通过处理组和控制组均值对比来估计平均处理效应,未配合使用其他因果方法,对明显存在的职业教育收益率隐性偏估问题不做任何文字讨论与检验;三是未对匹配变量的选取和选择模型形式的设定进行检验,刻意降低显著性水平以确保所有匹配变量的平衡检验得以通过。
King & Nielson(2019)指出倾向得分匹配存在严重的模型依赖问题(Model Dependence),他们认为观测数据研究的关键在于破解数据产生的过程,倾向得分匹配正是通过构建和估计选择模型来完成这一破解任务,但可惜的是我们对于现实中观测数据的产生过程知之甚少,这使得我们在使用倾向得分法时带有较大的主观性和随意性。估计结果有赖于模型设定,当有多个模型都能很好地拟合数据并达成数据平衡目标时,研究者自然青睐于那个能产生自己心仪结果的模型,由此量化研究就丧失了客观与科学的品质,沦落为一种单纯为获得参数估计的“技术游戏”。
(三)重效应识别、轻机制分析
教育科学研究的重要使命是揭示教育现象背后的教育运行规律,这就要求研究者不仅要回答“X 对Y 是否具有因果效应”,还需解释该因果效应的发生机制,阐明X 是通过何种途径对Y 发生因果效应的(即“How”问题),以及X 是在何种条件下对Y 发生因果效应的(即“When”问题)。目前国内教育因果研究还主要关注两变量因果关系的识别与估计,对因果关系的发生机制研究得还不够,对于许多重要的教育投入与其结果变量之间的因果关系,我们仅知其然,但不知其所以然。
探究变量间影响机制一般要采用中介效应分析,就X 是否通过Z 或其他变量进而对Y 产生影响进行分析。本质上,中介效应“X→Z→Y”反映的是带有明确作用方向的多变量间因果关系,而当下流行的各种中介效应检验法,无论是早期提出的分步检验法(Baron & Kenny,1986),还是近来流行的自举法检验和条件过程分析法(Hayes,2018),都不是从因果推断的正式分析框架(潜在结果框架)推演出来的,它们只能实现变量间机制的相关分析。然而,国内有大量教育研究将这些方法用于因果中介效应估计。以另一篇刚在教育学刊物发表的文章为例,该文利用省级面板数据就留学教育对我国经济增长的因果影响机制进行回归分析,其中外国直接投资、技术研发与创新为中介变量,所构建中介模型如下:


在模型(3)—(5)中,留学教育规模(edu_os)是处理变量,但各省留学教育规模受多种经济、社会因素的影响,因此它是内生变量。同理,中介变量外国直接投资(FDI)和技术研发与创新(RD)也是内生变量。因此,模型中几乎所有的主要估计系数(a1、 β1、 π1、 π2和 π3)都很可能是偏估的。退一步说,即便模型未遗漏重要变量,不存在任何的隐性偏估,式(3)中的a1也是偏估的,因为它很明显遗漏了中介变量外国直接投资(FDI)和技术研发与创新(RD),而该研究对中介效应的第一步检验便是看估计系数a1是否显著。第一步检验便是错的,之后检验更是错上加错。
事实上,识别因果中介效应“X→Z→Y”要比仅识别两变量因果效应“X→Y”困难得多,亦严苛得多。要实现对因果中介效应的一致估计,既要保证个体是否接受干预与潜在结果、中介变量潜在取值无关,还要保证在给定干预的条件下中介变量取值与潜在结果无关。目前有关因果机制识别与估计方法的研究尚处于探索阶段,具体讨论可参见Imai 等人(2011)。
五、推动我国教育因果研究发展的两点建议
针对上述问题,可从教育量化方法教学改革与教育因果研究创新能力提升两方面提出一些建议。
(一)围绕学生因果思维培养,改革教育量化方法课程体系
当前国内高校教育学相关专业的量化方法教学多以教育统计学为基础课程,该课程大都沿袭心理统计学的教学传统,授课内容以概率与统计初步和心理研究常用方法为主。然而,心理学研究较多采用实验方法,在干预为随机分配的实验数据条件下研究者通过简单的组间均值对比与检验或简单线性回归便可获得因果结论,而相比之下,教育研究(尤其是教育政策研究)所使用的数据多为非实验的观测数据,若照搬心理实验研究惯用方法来判定变量间因果关系,其结果必大谬。
教育量化方法课程的目的是培养学生运用科学思维与方法探究人类学习成长与教育行为规律的能力,而科学思维中最重要的就是因果思维,科学方法中最重要的亦是基于科学实验方法原理形成的因果推断方法,但吊诡的是,目前绝大多数教育量化方法课程都未包含有关因果思维与方法的知识。如此设计课程容易造成学生对量化方法学习目标的“认知偏差”,使学生形成一种“为学习方法而学习方法”的错觉。譬如,学生在学习OLS 线性回归时总是关注如何获得主要解释变量的显著估计结果,对模型中应控制哪些变量却不太关心,这是因为现有方法课程习惯性地把掌握某种统计技术当作教学目标。如果方法课程是以探索变量间因果关系作为教学目标,让学生明白一种结果的产生有多种可能的解释,预设的“因”只是其中一种“备选解释”,如此学生自然会思考应采用怎样的控制策略才能获得较为可靠的因果结论,并关注在控制不同变量的条件下主要解释变量的估计结果会发生怎样的变化,如此学生也就不会产生“只要控制变量不显著,就可以踢出模型”这样的错误认识。
因果推断方法的发展带来的不只是更多新的统计技术,更是量化思维的彻底革新。我国教育学各专业未来应充分借鉴和吸收前沿因果推断思想,围绕强化培养学生科学思维与因果推断能力这一核心目标,对现有的本科与研究生量化方法课程与教学体系进行改革:首先,可考虑在本科阶段单独设置一门“因果思维”课程作为所有教育量化方法课程的前置课程,此课程不讲授任何具体的统计技术,以介绍因果推断的基本知识与社会科学因果推断经典研究为主要内容。也可考虑将这些知识浓缩,放入到“教育统计学”的靠前章节中进行讲解,如美国普林斯顿大学教授、统计学家今井耕介(Kosuke Imai)编著的著名教材Quantitative Social Science: An Introduction中,引言之后的第二章便介绍因果定义及相关方法;其次,可考虑在本科生高年级设置“教育因果推断方法”选修课程,并在研究生低年级设置“教育因果推断方法进阶”必修课程,作为“教育统计学”的后置课程,具体讲解随机对照实验设计与各种常用的准实验方法。
(二)立足我国教育政策实际,提升教育因果研究创新能力
如前所述,正确识别干预分配机制是实现可靠因果分析的前提条件,而要做到这一点,研究者需对现实教育背景与政策有透彻的了解。在因果研究中,事实逻辑永远优先于技术逻辑。一旦研究设计与教育现实不符,无论获得多么漂亮的数据分析结果,亦是无用的,甚至是有害的。
首先,研究者需明白谁为因,谁为果。对于结果变量来说,政策干预是原因,它应是结果变量的前定变量;而对于政策干预来说,控制或匹配变量是原因,它应是干预变量的前定变量。研究者只有对政策实施的历史与现状有足够的了解,才能形成各变量之间在因果链条上的准确时序,才不会犯变量间因果时序颠倒的“低级错误”。
其次,研究者需明晰政策干预的对象、内容和过程。即便是同一政策,在地方落地实施过程亦可能呈现出很大的差别。教育政策的多样化与差异性正是教育政策研究创新的重要来源。譬如,对某一教育事权下放制度改革进行成效评价研究,我们以往常将干预赋值为0 和1,实施该改革的地方赋值为1,未改革的地方赋值为0。而事实上,教育事权概念复杂,它包括多种权力,如教育服务举办权、监督权与调控权等(魏建国,2019),不同省份对不同县区下放的具体事权很可能是不同的,由此导致该政策干预在不同地方实际运行中会产生不同的效力。如何将政策的多样性与差异性用变量间数量变化关系呈现出来,是未来教育因果研究寻求突破与创新的一个重要方向,而要实现这一点,研究者就必须非常了解政策干预在不同地方的实施内容与过程。
最后,研究者需基于教育现实、政策背景和数据结构来挑选因果识别策略。譬如,有效的工具变量需满足第一阶段效应、独立与排他限制三个假设,其中第一阶段效应与独立假设可通过一定方法得到直接或间接的检验,而排他限制假设几乎是不可被检验的,只能依靠事实逻辑进行判定。一个“好”的工具变量可以来自研究者的经验或直觉判断,也可以来自研究者基于理论理解所形成的对变量间内在逻辑的知识构建,无论来自何处,它都必须符合事实逻辑,与教育现实和政策背景不冲突。正如安格里斯特在Instrumental Variables and the Search for Identification一文中所指出的:“在我们看来,好的工具变量常来自对决定自变量取值的经济机制和制度的细致了解。”
(黄斌工作邮箱: huangbin@nju.edu.cn;本文通信作者为李波:libobnu@163.com)
