利用深度学习的施工人员安全隐患行为诊断控制方法
2022-03-30王生云赵吉龙虎晓敏马少军拓媛媛
王生云,赵吉龙,虎晓敏,马少军,拓媛媛,胡 军,包 超
(1.宁夏农垦建设有限公司,银川 750000; 2.宁夏建设投资集团有限公司,银川 750000;3.宁夏大学 土木与水利工程学院,银川 750000)
0 引言
在建筑行业,工人的行为是造成工作场所事故和伤害的主要原因之一。大约80%~90%的事故与工人的不安全动作和行为密切相关[1-3]。先前的研究也表明,基于行为的技术(例如,反馈、目标设定和工人参与)可以显着提高安全性能[4-7]。为此,一种基于行为的方法已成为安全研究的趋势,旨在观察、分析和改变工人的行为。具体来说,该方法包括制定与安全相关的关键行为清单,观察工人并统计所定义行为的频率,通过反馈改善他们的行为,并通过观察到的数据不断提高安全性[8-9]。在过程中,观察员了解导致事故的不安全行为和姿势,观察自己和同事的行为,并提供对观察结果的反馈。工人的行为可以通过听取对自己的反馈得到显着改善,观察者也倾向于在观察和讨论同事的过程中改善自己的行为[10]。在这方面,观察是作为行为修改和管理改进的初步数据的最重要的单元[11-12]。传统的行为测量方法虽然很重要,但在应用于建筑项目时存在以下局限性:1)测量过程中所涉及的任务费时费力[13];2)需要大量的样本以避免偏差[14-15];3)观察和报告需要工人的积极参与[16-17]。
基于计算机视觉的行为监控系统,可以自动捕捉工人的动作并识别工人的不安全行为。现有的动作捕捉解决方案主要分为机械、磁性、光学和基于视觉的系统。前三种可能比基于视觉的系统提供更准确的结果,但需要在人体上安装传感器或标记来进行运动跟踪。在施工中,这种要求造成了一个严重的障碍,因为附加的设备会干扰工人的行动。因此,可以认为基于视觉的方法最适合施工应用。由于其在实用、经济、可视化和快速数据收集方面的潜力,基于视觉的方法已被用于施工,像生产力管理、进度监控 、质量管理、资源跟踪和安全性。特别是,文献[18]以及文献[19]分别提出对工人进行姿势分析和运动分类,以分析施工作业的生产率。在安全管理方面,本文探讨了一种微观层面的运动跟踪与识别方法来识别工人的不安全行为。该系统从现场视频中提取三维人体骨骼运动模型,并利用运动数据识别工人的不安全动作。通过这种方式,三维骨骼模型还可能通过跟踪人体关节和人体部位轨迹之间的角度来实现工人姿势的人机工程学分析(例如,背部角度),这是人机工程学分析的主要输入。
本文探讨了基于行为安全管理中的观察过程及其挑战。为了解决这些挑战,我们提出通过深度学习的方式对建筑施工现场工人的不安全行为进行诊断控制,引入了一个基于视觉的监控框架,并通过实验研究调查其实用性。在此基础上,讨论了基于视觉的监测方法的贡献和局限性,以验证其在建筑工人行为测量中的适用性。
1 基于CNN-LSTM的行为识别模型
本部分的主要内容是针对通过人体骨架图来提供表征视频内人体姿态以及运动变化对应的模态信息进行介绍,且针对骨架图的提取途径进行全面介绍,进一步提出使用数据拟合能力以及模型泛化能力更强的卷积神经网络来代替现阶段使用的网络,对CNN-LSTM模型具有的时序建模能力进行优化。
单帧输入图仅能够对人体行为对应的空间特征进行表征,另外还需要针对多帧输入图时序完成建模的过程,从而全面地将行为失控信息进行反映。所以此次研究决定使用择CNN-LSTM模型来实现骨架图序列的失控信息建模,同时利用选择更佳的CNN对辨别性更为理想的空间特征进行提取,由此全面优化CNN-LSTM行为识别模型所具有的识别性能,通过图1对基本框架进行描述。
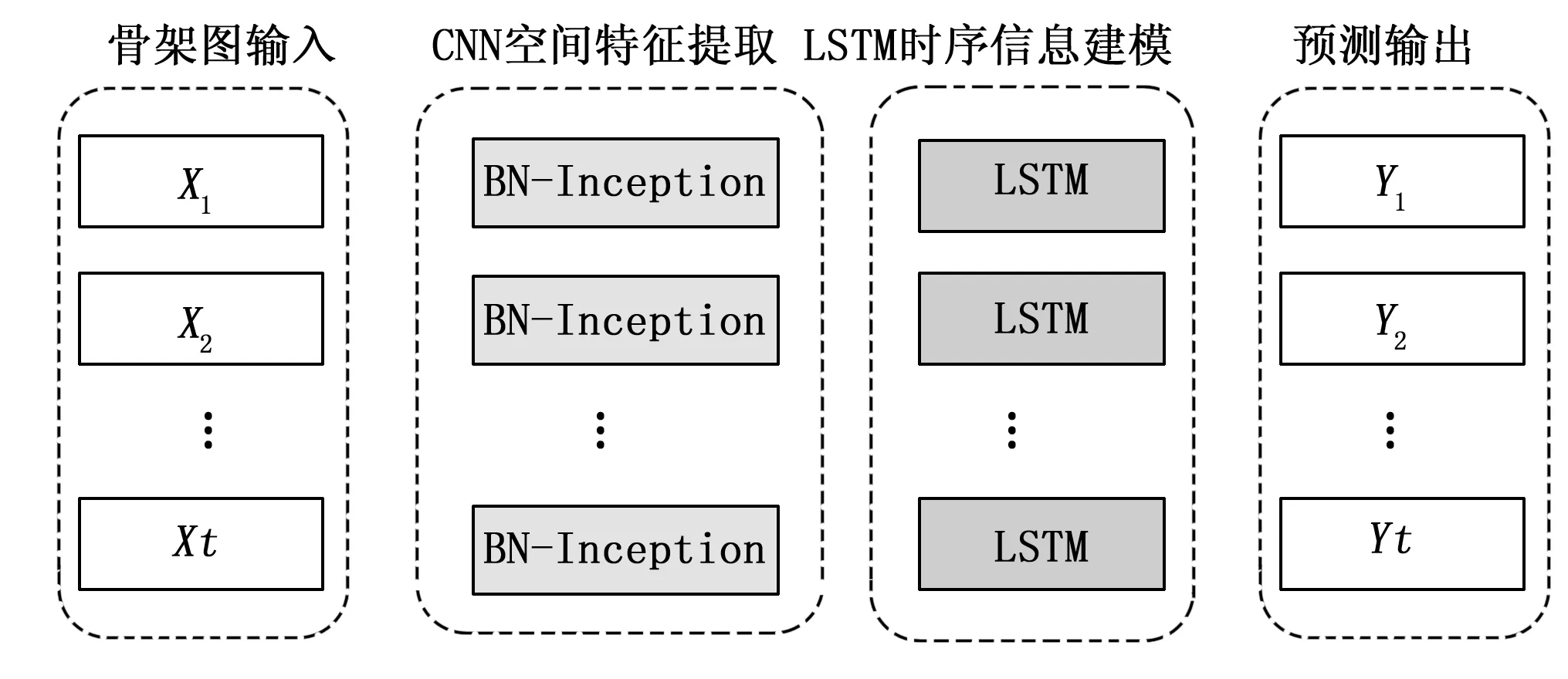
图1 基于骨架图的CNN-LSTM模型
第一步BN-Inception训练提取视频中所有帧内包含的空间结构信息,对现阶段使用的CNN-LSTM模型具有的空间特征提取能力进行加强,进一步全面优化CNN-LSTM行为识别模型的性能。随后通过借助长短时记忆网络(LSTM)针对所有视频中的全部帧时序信息完成建模过程,且模型的最终输出结果为LSTM在最后时刻的预测输出Yt。
1.1 人体骨架图提取
对事故统计进行分类能够得到两种伤害类别:1)来自身体外部的物理冲击所导致的伤害;2)因为身体本身存在不良姿态以及动作,在长时间的反复累积之下所导致的人体工学伤害。对这两类伤害继续分类,还能够分为若干类子伤害,并且致死率以及非致死率能够对各个类型的子伤害以及疾病频率、轻重缓急进行反映[20-21]。基于对频率以及严重程度的综合考虑,以子类别为依据对施工过程中的主要姿势以及运动进行识别,且通过本文所提及的以视觉为基础的监测系统完成跟踪以及检测。这里需要强调的是,能够针对清单作出修改,对特定的工作地点进行反映,比如利用特定的劳动力以及工作场所的具体特点来描述[22]。
从本阶段出发,能够对工人产生不安全行动可能性较大的范围以及有关活动进行识别。针对事故作出的统计数据以及记录能够为危险工作场所以及有待重点监测的活动提供有力的制成。所以,此步骤可以为摄像头的安置、对行为进行监测与分析提供科学的指导。比如,跌落于脚手架以及梯子上的情况在总体中的占比分别等于18%、16%;所以,此类设备附近的位置就是最需要安装摄像头的区域,以避免事故的发生率升高。同时,根据相关统计数据可知,砖石工人的背部受伤率始终居高不下,跟其他各种类型的建筑工人相比都能够超过16倍。由此可见监测的重点是哪些区域,由此避免部分明确、高发伤害的类型出现。
从运动捕捉领域来说,通常是通过单目摄像机以及多目摄像机这两种摄像机针对人体关节对应的三维位置进行估计。此次研究以三维摄像机为核心,此类摄像机能够对三维骨骼进行提取以及简化处理,将其转化为二维姿态来完成估计。三维摄像机的结构为一个摄像机中存在的两个镜头,能够基于不同的角度在同一时间内完成两个视频的制作流程。利用三维摄像机或联合使用两个摄像机进行拍摄得到的两个视频,一个的基本用途是对人体关节于二维图像列上的位置进行估算,另一个的基本用途是搜集三维重建的参考数据。由此利用计算过程求出深度信息,对估计的二维身体关节进行转换,使其转化为三维坐标,由此获取三维骨骼模型。
针对视频来说,基于二维图像对身体关节的具体位置进行估计,从而获取二维骨骼模型。针对人体关节展开估计通常能够使用两种方法,即自上而下或者自下而上,前者主要是在观察得到的图像上映射身体模型,从而实现对关节位置的估计,后者是基于图像对身体部位进行检测,随后再适当调整期位置,提升对人体的适应度。然而自上而下的方法不适用于存在遮挡的情况下,一般要在第一帧进行手动初始化,所以此次研究选择使用自下向上的方式。
通过利用梯度方向直方图(HOG, histogram of oriented gradients)描述符基于二维图像中对身体部位进行检测,同时应用部位混合模型对身体部位间存在的关系进行推断;此类方法能够提供较为迅速且准确的结果,并且能够为目标人群的不同外观以及遮挡等多种问题提供解决方案。以检测身体部位为目的,确定一组训练图像以后,通过图2给出的身体骨骼模型完成手动注释的过程。以骨骼模型为基础,对训练图像内包含的身体关节进行标记,得出的数据集可以对身体部位于测试数据集内的具体位置进行估计。从此过程来看,多个旋转以及缩短的训练数据集能够对姿势估计中存在的问题进行解决,比如自由度过高、因为身体尺寸以及形状存在差异进而造成四肢外观、服装以及视角产生变化。不包括位置信息在内,二维图像中的固定身体部位所属类型也能够被识别并进行储存,用于三维骨架模型的构建。所以,集群代表特定身体部位形成的集合,同时以集群为基础对身体部位的分类进行标记。再通过派生类型标签进一步构建得到一个完整的监督数据集,同时对灵活的不见混模型进行学习,给身体关节分配正确的ID。最终输出的结果为三维骨架模型,并对和身体关节进行关联的ID分配。
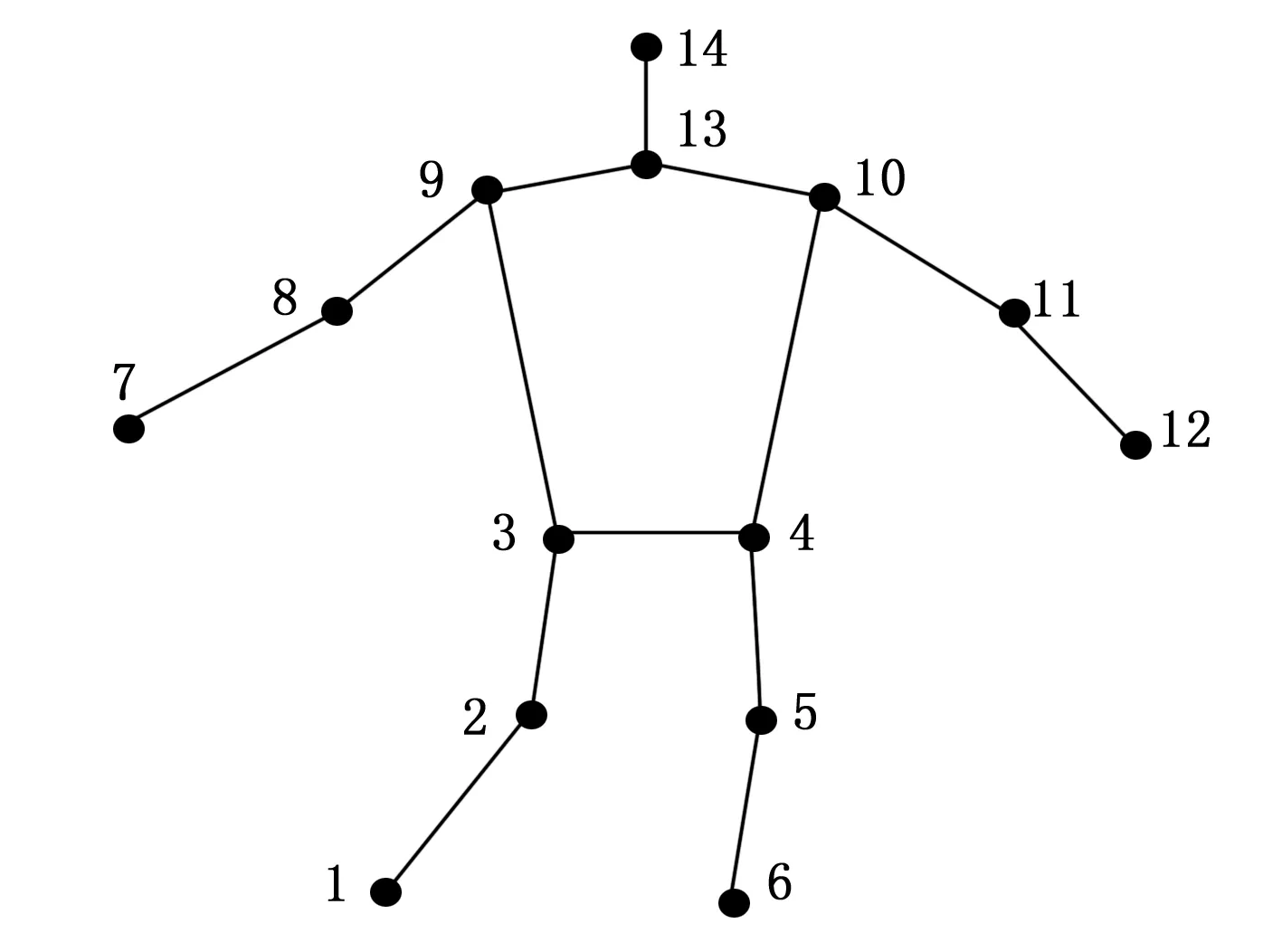
图2 用于身体关节估计的身体骨骼模型(注:数字代表身体部位的数字 ID)
1.2 基于BN-Inception的卷积神经网络空间特征提取
训练深度神经网络具有极高的复杂性,原因是训练中的各层输入分布都会随着上一层参数的变化产生共同变化。由此便要求学习速率降低且对参数进行更加细致的初始化处理,必须减小网络的训练速度,同时会造成训练饱和非线性模型的难度提升。以攻克这一困难,相关研究人员Sergey Ioffe提出了Batch Normalization(BN),也就是批量标准化的方法,该方法的中心思想为降低内部相关变量,对深度网格的训练提供加速动力,由此能够解决许多不科学的初始化问题。将标准化纳入模型结构,同时针对所有训练对应的mini-batch展开标准化流程。BN能够提供更为理想的学习速率以及更为简便的初始化参数。
BN-Inception结构具有的特点为所有卷积层后都有添加的BN层以及ReLU层。BN层的功能是Batch Normalization,ReLU的功能是用于实现归一化。通过图3针对BN-Inception的整体结构进行描述。BN-Inception实质上是基于Inception的优化,一方面添加BN层,降低内部相关变量的转移,从而使得网络的各层输入都能够归一化至随机正态分布,另一方面通过对VGG网络进行借鉴使用2个3*3的卷积核将Inception模块内存在的5*5卷积核进行替换,不仅能够降低参数数量,还能够提升网络的计算效率。
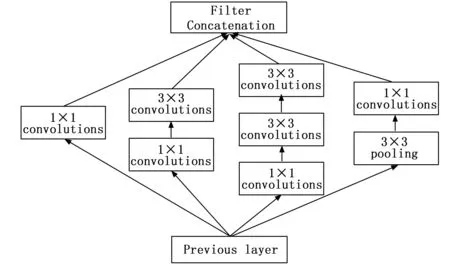
图3 BN-Inception结构
1.3 基于LSTM的骨架图时序关系建模
此次研究通过CNN对所有帧骨架图含有的空间信息进行提取以及存储。视频中的行为信息涵盖了帧内视觉空间以及帧间时序信息,仅对CNN加以利用来处理骨架图不能针对视频内所有帧间信息的变化完成时序的建模过程,特别是对于时间跨度相对更大的视频,必须借助于空间关系基于时间序列中的变化对各类行为进行鉴别,所以基于对骨架空间信息进行提取,还要进一步对视频帧序列间存在的时序关系进行训练以及学习。
在视频帧骨架图序列中按照等间隔的方式累计抽取16帧,作为全视频的代表。通过利用经过训练的BN-Inception网络对视频帧骨架图具有的空间特征进行提取,以时间顺序为依据输入LSTM,再利用数据集原本具有的帧级标签对LSTM的网络误差以及更新网络参数进行计算,CNN-LSTM最终得出的结果就是LSTM最终输出的行为类别预测值,进而用其对分类性能进行评价。
传统使用的循环神经网络在进行反向传播的过程中,传递一层就必须将梯度与上一次的权值矩阵W进行相乘,即传递n层,继续向下传递的梯度必须与W的n次方相乘,若W>1、W<1时,梯度完成了n层传递后可能无限趋近于0,也可能无限趋近于无穷,也就是说梯度不存在或者爆炸了,这种情况下网络无法沿着向下的方向持续对权重进行更新,所以循环神经网络无法对时间跨度过长的时序信息进行解决,也就是“长时依赖”问题。通过式(1)对循环神经网络神经单元输入输出计算进行表示。
(1)
这里,ht所指代的是当前时刻,也可以指代当前序列t所对应的神经元输出结果,W所指代的是神经元权值矩阵,ht-1所指代的是前一时刻,也可以指代前一序列t-1对应的神经输出结果,xt所指代的是t时刻网络数据输入,tanh所指代的是激活函数。
2 实验
LSTM所使用的为隐藏单元的单层神经元结构,累计数目为512个,输入为利用BN-Inception提取得到1 024维空间特征向量。初始学习率设置为0.001,再以训练情况为依据展开衰减的过程。将训练周期设置为10个epoch。在实验进行时,对采集得到的数据集进行分组,分为各不相同的多个训练以及测试视频,网络训练需要100个视频,性能测试需要150个视频。
2.1 数据采集
在实验室环境中,分别使用商用动作捕捉系统(VICON)和3D摄像机(JVC 3D Everio Camcorder)来收集爬梯运动模板并做视频记录;在VICON的情况下,围绕表演者的8个摄像头跟踪连接到身体关节的反射标记,因此表演者或梯子的遮挡可以最小化。 另一方面,视频样本是用距离表演者约5米的三维摄像机记录的。
基于相似性度量进行运动检测,计算视频中不安全动作如表1所示。其中,真阳性(TP)除以真阴性(TP)与假阴性(FN)之和的召回率为88%;TP除以TP与假阳性(FP)之和的精密度为88%;例如,TP表示检测到不安全动作正在进行,FN表示没有检测到不安全动作正在进行,FP表示没有检测到不安全动作,实际上不安全动作已经开始发生。其中,Recall表示运动识别算法检测到视频中88%的不安全动作,Precision表示在检测到的动作中,88%的动作被算法正确检测到。实验结果表明,本文提出的运动识别方法在使用预定义模板检测和计算不安全动作时,能够很好地处理现场数据。此外,误差可能主要来自对身体关节位置的不准确估计,特别是手臂和手,这在姿势估计结果的分析中得到了证实。

表1 一个检测的结果
2.2 实验结果与分析
此次研究提出视频帧输入所需要的空间提取器选择为BN-Inception,且和文献[23]中所应用的Alex Net以及主流的VGG16[24]进行对比。文献[25]选定的输入视频帧的空间特征提取器为Alex Net,此次研究选定的输入视频帧的空间特征提取器为BN-Inception,模型整体具备更为理想的空间提取能力。在确定使用BN-Inception前,本文将Alex Net、BN-Inception以及VGG16进行了性能方面的对比。所有CNN对应的网络模型参数皆为通过Image Net大型图片分类数据集的训练而得到的,所有网格训练都具备一个epoch。
通过图4对三类不同的CNN模型训练一个epoch对应的训练误差值(train loss)变化进行描述,trainloss值越低,说明模型输入预测值、训练集标签对应的真实值越趋于相等。基于有限的迭代次数,BN-InceptionAlex Net与VGG16相比具有更高的收敛速度以及更强的稳定性。
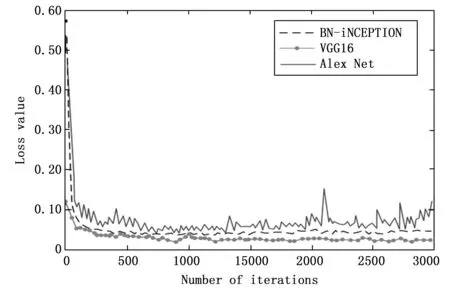
图4 三种CNN模型训练loss值变化
通过图5对三类CNN模型的测试过程对应的准确率进行描述。由图可知,3个网络都能够在经过1 000次上下的迭代后达到较为理想的准确率,其中BN-Inception完成1 200此迭代后准确率基本能够维持不变,约为88%,比其他两类模型高;VGG16经过1 000次迭代后,准确率呈现出降低的趋势,基本保持在82%上下,存在小幅度波动;Alex Net经过1 000此迭代后,也开始出现轻微波动。
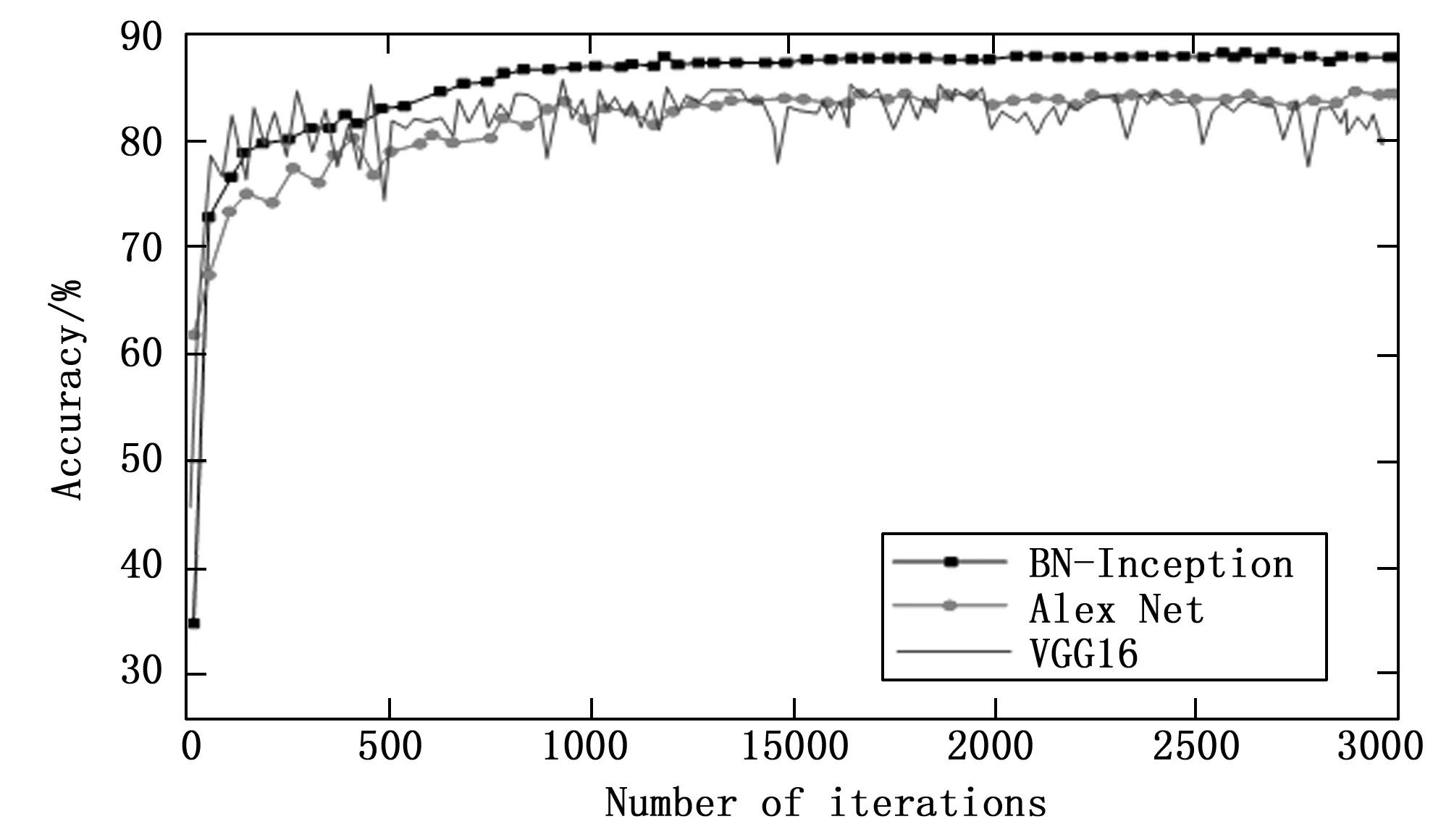
图5 三种CNN模型测试准确率变化
现阶段已有的针对骨架图行为识别开展的研究大多数通过LSTM来完成骨架序列时序关系的建模过程,文献[26]便提出了一种较为经典的以LSTM为基础的骨架行为识别模型,能够利用正则化对共现关节点集合进行定义为表征行为对应的特征,此次研究针对文献[26]中提出的LSTM方法和此次选定的CNN-LSTM模型展开了细致的对比。因为此次研究应用的UCF101本身尚未完成骨架图的信息标注,仅利用定向梯度直方图(HOG)对人体骨架对应的位置以及姿态进行估计,文献[26]所应用的CMU数据集包括了对3D人体关节点以及骨架移动的标注,所以确定选择采集到的数据集中存在的骨架信息进一步提取准确度较高的15类行为视频展开对比实验。
所有视频采用的帧数均为16帧,在CNN-LSTM模型中输入包含骨架信息的视频,在文献[26]所使用的识别系统中输入含有骨架信息的矩阵,并展开分别的训练以及测试过程,通过表2对两者的测试准确率进行总结。通过结果能够得出,CNN-LSTM模型的准确率能够拿到88.67%,与文献[26]中所提及的LSTM模型相比具有显著的优势。

表2 不同骨架模型性能对比
实验结果表明,该框架能够很好地从视频中提取三维骨架,并能够利用运动模板检测不安全动作。考虑到人类观察者在监视工人行为上所花费的时间和精力,所提出的框架可能有助于持续和自动地监视工人,提供反馈,并管理他们的行为,以安全的方式执行工作。
3 结束语
在这项研究中,提出了一种利用深度学习的建筑施工现场工人不安全行为诊断控制方法。从现场视频重建包含运动信息的三维人体骨架模型,并用于检测数据中预定义的不安全行为。对于工人行为的观察,基于视觉的监测不需要大量额外的时间或成本,因此提供了一种收集行为数据的方法,用于实践中的安全管理。考虑到人类观察者必须花费在工人行为监控上的时间和精力,提出的框架可能有助于持续自动监测工人,提供反馈,并管理他们的行为,以安全的方式执行工作。
在未来的研究中将需要进行实地研究,以评估框架对实际施工环境的适用性,包括各种活动、运动和遮挡,为归档数据收集提供详细的指南。然而,运动识别的性能依赖于从视频中提取的三维骨骼的准确性。在这方面,二维姿态估计和三维骨骼重建的性能需要深入验证。例如,骨骼模型中存储的旋转角度可以与商业动作捕捉系统(如Kinect)进行比较,Kinect的性能也需要提前验证才能作为地面真实。在这种情况下,由于特殊的防护服和标记的要求,VICON可能不适合进行角度验证,这可能会影响基于视觉的运动捕捉的准确性。
通过验证,我们可以研究遮挡对三维姿态估计的影响程度,找到提高其精度的研究方向。深入的验证将有助于确认所提出的框架可以应用于其他类型的不安全行为。因此,我们未来的工作将包括三维骨骼模型的深入验证,并将测试各种类型的动作,姿态估计误差会显著降低动作检测的准确性。
