加性频域分解的生成对抗网络语音去混响
2022-03-28全海燕郑志清
全海燕,王 涛,郑志清
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
混响是一种常见的自然现象,适度混响能使声音更加饱满立体,但过度混响则有损声音质量,降低可懂度。混响是由声源语音与房间冲激响应(room impulse response, RIR)在时域上卷积产生的,因此,其在时、频域上都存在较高的相关性,这种高相关性在很大程度上制约了现有去混响方法的性能。
深度学习为语音去混响指出了新的研究方向。目前,基于深度学习的去混响方法主要使用频谱映射和时频(time-frequency, T-F)掩蔽两种原理。Han等通过构建多隐藏层的神经网络将混响语音幅度谱与声源语音幅度谱相映射,能有效抑制混响干扰,但这种映射方式受浅层网络结构和损失函数的影响很难获得更精确的声源语音幅度谱。Williamson、Wang等通过T-F掩蔽的方式,利用深度神经网络(deep neural networks, DNN)训练混响语音幅度谱实、虚部的复数理想比值掩码,再与混响语音频谱相乘来获得声源语音,能提升去混响语音的可懂度,但对于相关性较高的部分仍无法有效抑制混响。Wang等利用DNN对多麦克风复合频谱进行映射,会比使用单个通道有明显的改进,但这种方式在实际应用场景中耗费较多硬件资源。由于DNN特征提取能力有限,Ernst等利用全卷积神经网络(fully convolutional network, FCN)来对混响语音频谱进行特征提取,学习到更多声源语音特征,有助于频谱的重构,然而卷积网络也没有去相关的能力。此外,Zhao、Wang等将图形处理中重要的注意力机制应用于去混响处理,在训练过程中能对频带信息间的相关性进行建模,提升模型对声源语音幅度谱的映射能力,该方法虽考虑到相关性的问题,但其可解释性较差。Wu等通过优化语音帧中的帧移位大小和DNN输入的声学上下文窗口大小来获得较好的去混响效果,该方法对于未知混响时间有较好的适用性,但也没有从数据角度上去解决相关性问题。刘斌等采用的联合长短时记忆递归神经网络对混响语音的对数功率谱进行映射,虽能学习上下文的关联,但仍然是对网络模型进行改变。因此,对于降低数据本身层面的相关性研究还较少,这也是制约后续神经网络特征提取性能提升的重要因素。
基于上述问题,本文提出了一种加性频域分解模型的生成对抗网络(GAN) 语音去混响算法。首先,以预先降低混响语音数据本身的相关性为目的,在数据处理阶段引入对数运算,将声源语音与RIR在频域中的乘性关系转换为加性关系,从而实现加性分解;然后,采用GAN对混响中的高维特征分布进行学习,使GAN输出RIR的对数幅度谱估计,再通过简单的减法运算,可有效提高去混响语音的整体质量。
1 加性频域分解模型的去混响原理
1.1 混响数学模型
声音经天花板、墙壁等反射吸收,其幅度和相位产生变化,最后直达声音与反射声音叠加形成混响,其生成过程为:

s
(t
)为声源语音,h
(t
)为RIR,n
(t
)为加性噪声,y
(t
)为混响语音,t
为总采样时间,τ为卷积过程中中间时刻,“*”表示线性卷积,T
为RIR的长度。由于主要研究混响问题,因此忽略加性噪声的影响,式(1)可简化为:

h
(t
)主要受混响时间(reverberation time, RT)影响,RT表示声源停止发声后,声压衰减60 dB所需要的时间,一般在200~1 000 ms内。后文出现的混响时间均为RT,RT与房间墙面衰减系数和房间大小等因素有关,其数学公式为:
A
为 总吸声量,其中,S
为各墙面面积,α为各墙面吸声系数;V
为房间体积;“·”为乘法运算。图1为采用镜像源模型(image-source model,ISM)模拟得到的RIR示意图。

图1 房间冲激响应样例Fig. 1 Example of RIR
图1展示了镜面反射原理模拟声音在房间内的反射轨迹和能量衰减过程。图1中,幅值为1处为直达路径响应,其余各处幅值因能量衰减而逐渐减小。
1.2 加性频域分解去混响模型
基于T-F掩蔽的语音去混响方法通过混响语音的幅度谱值乘以掩蔽估计值来得到去混响语音幅度谱。采用短时傅里叶变换(short-time Fourier transform, STFT)将式(2)转换到频域上为:

H
(t
,f
)≠0。进一步变换式(4)可得:
Y
(t
,f
)、S
(t
,f
)、G
(t
,f
)分别为混响语音短时幅度谱、声源语音短时幅度谱和RIR短时幅度谱倒数(或称为RIR增益),t
、f
分别为帧数和频点。 在T-F掩蔽中,掩蔽估计值与混响语音幅度谱相乘正好符合式(5)在频域下的去混响原理。因此,在混响处理过程中计算掩蔽估计值就等同于计算RIR增益,物理意义相当于获得一个RIR逆滤波器,从而实现去相关,但受算法限制,并不能精确获得RIR增益。受加性噪声启发,对式(4)做对数运算,从而进行加性分解,变换如下:
进一步变换式(6)可得:

式中, 对等式两边各信号的短时幅度谱做对数运算,从而分别提取出各信号对应的短时对数幅度谱。式(7)的物理意义是利用同态处理进行解相关,将复杂的乘性关系转换为加性关系,不仅能降低整个算法复杂度,更能直接提供弱相关性的数据便于后续网络进行特征提取。
2 加性频域分解模型的语音去混响
2.1 生成对抗网络去混响框架
加性频域分解下的去混响框架如图2所示。图2中,主要包含数据预处理、GAN训练、语音重构3部分。其中:在取对数操作后,采用sigmoid函数将短时对数幅度谱数据归一化到[0,1],此操作能进一步消除奇异值对整体数据的影响。在取指数前,需先采用sigmoid反函数对输出数据逆处理,然后结合混响语音相位谱进行短时傅里叶逆变换(inverse short-time Fourier transform, ISTFT),得到去混响语音。

图2 加性频域分解下的去混响原理框图Fig. 2 Block diagram of dereverberation under additive frequency domain decomposition
2.2 深度全卷积生成对抗网络去混响原理
本文采用FCN来构建GAN中的生成模型(G)和判别模型(D)的网络结构,整体系统模型如图3所示。

图3 深度全卷积生成对抗网络语音去混响结构图Fig. 3 Structure diagram of speech dereverberation based on deep full convolutional GAN
图3中,G网络由卷积和反卷积两部分构成。卷积阶段采用多个卷积层逐层提取混响语音对数幅度谱的高维特征;反卷积阶段则利用多个反卷积层对高维特征进行恢复。但网络引入了跳跃连接结构,因此,每层输入不仅来源于上层输出,还包含卷积阶段对应的各层输出,该结构能提供更多的细节信息。每层输出前均采用带泄漏修正线性单元(leakyReLU)作为激活函数,最后一层输出采用Tanh激活函数,将估计值映射到[-1,1]。其G网络结构如图4所示。
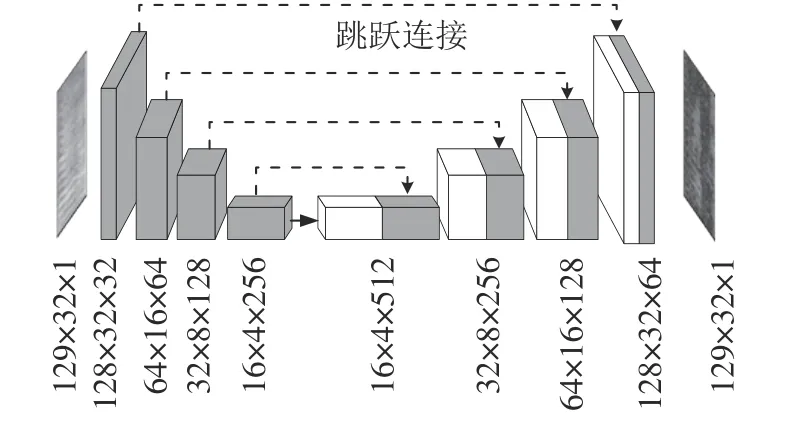
图4 生成模型(G)结构图Fig. 4 Architecture of G
D为一个二分类网络,与G的卷积阶段类似,差异在于其最后一层采用全连接层,并使用sigmoid作为输出层激活函数。此外,为提升整个系统训练的稳定性,在输入前添加了一些噪声z
来提高D的训练难度,有利于克服D学习能力太强而抑制G学习的矛盾。2.3 对抗损失函数
对抗损失函数是决定网络性能好坏的关键,用于描述G和D之间的博弈过程。由于原始GAN采用的交叉熵损失函数在实际使用中会出现训练不稳定等问题,因此,采用Mao等提出的最小二乘损失函数作为本文方法的损失函数,结合式(7),令=lgS
(t
,f
),=lgY
(t
,f
),得:
P
为数据分布,E为在P
下误差的期望,G
(·)和D
(·) 分 别为G网络和D网络的函数,z
为服从正态分布N(0,1)的随机噪声矩阵。此外,由于GAN训练难度高,极难训练出稳定模型,所以,在损失函数V
(G
)中引入L1正则项来防止过拟合并加快网络收敛,由超参数λ控制,计算生成数据与目标数据差的绝对值。Ernst等也验证了添加L1正则项的有效性。则式(9)修改为:
2.4 具体算法
加性频域分解下的去混响算法中主要包含前期的加性分解和后期的网络训练两部分。具体伪代码为:
算 法
加性频域分解下的去混响算法输入:混响语音y
(t
)、 声源语音s
(t
)、 最大迭代次数N
;输出:去混响语音s
˜(t
);1. 计算混响语音短时幅度谱和相位谱:(Y
(t
,f
),φ
(t
,f
))←STFT(y
(t
));2. 计算声源语音短时幅度谱:S
(t
,f
)←STFT(s
(t
));3. 根据式(6)进行加性分解:←lg(Y
(t
,f
));←lg(S
(t
,f
));4. for epoch=1 toN
do5.根据式(7)转换得:←-G
();6.根据式(8)更新D的网络参数:
7.根据式(10)更新G的网络参数:
8. end for
9.(t
,f
)←10;10. 重构去混响语音:s
˜(t
)←ISTFT(~S
(t
,f
),φ
(t
,f
))。算法中,∇和 ∇分别为对G和D的网络参数θ和θ进行梯度更新,STFT和ISTFT对应短时傅里叶变换函数及其逆变换函数,、分别为混响语音和声源语音的对数幅度谱,φ
为混响语音的相位谱,为去混响语音幅度谱。实际训练时,步骤6、7交叉训练,即更新D参数时,固定G参数不变;更新G参数时,固定D参数不变。3 仿真实验及结果分析
3.1 数据集和评价指标
本文采用Aishell中文语音数据集进行仿真实验。该数据集总时长178 h,共400个说话人,每人大约讲350句话。首先选取500句语音作为训练数据,由数据集中随机选取10人(男女各半),每人各50句话构成。同时为验证本文方法的泛化能力,构建两类测试语音:一类是从训练语音的10人中每人分别提取10句话(与训练语音不重叠)构成100句同源测试语音;另一类是从数据集中重新选取10位说话人,每人10句话构成100句非同源测试语音。然后分别与200、400、600、800 ms混响时间下的RIR卷积获得训练和测试数据集(包括同源测试集和非同源测试集)。
选取3种语音评价指标:1)语音质量感知评估(perceptual evaluation of speech quality, PESQ),指计算语音的感知质量,其值越大越好;2)短时客观可懂度(short-time objective intelligibility, STOI),指计算语音的可懂度,其值在[0,1]之间,越大则表示可懂度越高;3)对数谱距离(log-spectral distance,LSD),指计算语音的频谱差距,其值越小谱失真越小,频谱质量就越高。
3.2 实验设置
训练前,对训练集和测试集采用8 kHz下采样,降低网络复杂度和计算量。分帧时,采用Hamming窗,帧长为32 ms,帧移为8 ms,并对每帧信号进行256点的STFT;再取以10为底的对数获得短时对数幅度谱;最后采用sigmoid函数将数据映射到[0,1]。语谱图分割时,每32帧为一个输入,则输入尺寸为129×32,各输入之间重叠22帧。
表1为采用ISM模型获得不同RT下RIR的房间参数设置,根据式(3)计算出对应的RT为200、400、600、800 ms。GAN中G的网络参数设置如表2所示,D同G的卷积阶段网络设置类似。
表1 不同RT下的房间参数设置
Tab. 1 Setting of room parameters under different RT
RT60/ms 房间尺寸/(m×m×m)墙面吸声系数(前后左右下上)200(1.62×2.22×2.00)(0.5,1.2,1.5)(1.0,1.5,1.5)[0.19 0.19 0.19 0.19 0.45 0.35]声源坐标/(m,m,m)麦克风坐标/(m,m,m)400(3.73×5.79×3.40)(1.0,2.2,1.5)(2.0,4.5,2.0)600(6.11×7.24×5.20)(2.8,3.5,1.5)(4.2,6.5,2.5)800(7.72×8.10×7.60)(3.0,4.0,1.5)(5.0,7.0,2.5)
表2 G中各网络参数设置
Tab. 2 Setting of network parameters in G
(反)卷积层 卷积核数量 卷积核大小 步长 特征图大小卷积层_1 32 2×1 (1,1) 128×32卷积层_2 64 3×3 (2,2) 64×16卷积层_3 128 3×3 (2,2) 32×8卷积层_4 256 3×3 (2,2) 16×4反卷积层_5 256 3×3 (2,2) 16×4反卷积层_6 128 3×3 (2,2) 32×8反卷积层_7 64 3×3 (2,2) 64×16反卷积层_8 32 3×3 (2,2) 128×32反卷积层_9 1 2×1 (1,1) 129×32
训练时,采用RMSprop优化算法,训练批次设置为50,批处理大小为32,G的学习速率为0.001,D的学习速率为0.000 1。此外,为使得L1正则项与G的损失函数在同一个数量级上,将式(10)中超参数λ设置为500,这是经多次实验后确定的最优取值。若λ太小,网络仍容易发生过拟合;若λ太大,损失值集中在L1上,忽略D对G的反馈作用。
在对比实验中,选取基于DNN的乘性频域分解去混响方法、基于FCN的乘性频域分解去混响方法,同时再构建基于GAN的乘性频域分解去混响方法。DNN方法中,将每7帧的频谱作为一个网络输入,帧间重叠4帧,输入层和输出层都为903(即129×7)个节点,3个隐藏层都具有1 024个节点,输出层采用Tanh激活函数,其余各层采用ReLU激活函数,其他参数同本文方法设置一致。FCN方法中,网络结构和参数设置同本文GAN方法中的G网络相同。 GAN方法也与本文方法网络结构和参数设置相同。用于乘性频域分解下方法训练的数据是未取对数前的短时幅度谱数据。此外,为进一步验证加性频域分解算法的优势,额外构建在加性频域分解下的DNN和FCN的去混响对比方法,其网络结构和参数与乘性频域下的方法设置一致。
3.3 实验结果和分析
表3给出同源测试集在RT为200、400、600、800 ms下6种方法的去混响评价指标得分情况。
表3 同源测试集的 PESQ、STOI、LSD评价得分
Tab. 3 Objective PESQ, STOI, LSD scores of homologous test sets
RT60/ms同源测试集的PESQ评价得分 同源测试集的STOI评价得分 同源测试集的LSD评价得分乘性频域分解 加性频域分解 本文方法乘性频域分解 加性频域分解 本文方法DNN FCN GAN DNN FCN DNN FCN GAN DNN FCN DNN FCN GAN DNN FCN乘性频域分解 加性频域分解 本文方法2002.592.832.85 2.86 3.073.17 0.860.870.87 0.90 0.920.93 0.940.860.85 0.79 0.750.75 4002.322.502.54 2.54 2.792.83 0.810.820.83 0.85 0.890.90 0.990.900.88 0.87 0.820.81 6002.132.332.34 2.33 2.612.63 0.760.790.79 0.80 0.870.88 1.050.940.94 0.93 0.870.87 8002.032.172.18 2.13 2.372.40 0.680.720.71 0.72 0.790.80 1.141.051.05 1.05 1.000.99
由表3可见:随着RT增大, 6种方法下的评价得分都逐渐降低,但加性频域下的DNN和FCN方法和本文方法的各评价得分均优于乘性频域下各方法的得分,其中,PESQ和STOI分值提升都在10%左右,LSD分值也下降了约10%。原因在于:乘性频域分解类似于T-F掩蔽,而混响语音在时频上相关性较强,因此网络对特征的提取受限;而经加性分解后的频谱数据相关性降低,因此得到的RIR对数幅度谱估计与混响语音数据之间的独立性更强。进一步观察DNN、FCN和GAN方法下的去混响评价得分可知:无论在乘性频域还是加性频域下,DNN的去混响性能要明显差于FCN和GAN两种方法。这是由于DNN的特征提取能力较弱,只能感知全局特征,且参数庞大;而采用卷积方式的FCN和GAN能更好地学习较小的局部特征,训练参数也更少。此外,FCN和GAN的评价得分差距主要体现在PESQ得分上,STOI和LSD得分无明显差距,说明GAN能进一步提升语音的整体感知质量,这主要是因为GAN的对抗学习能学习数据分布多样性,而不再直接依赖损失函数。以损失函数值为目标的模型,只能以输出值与目标值的数学距离作为误差来源;而GAN是计算输出值与目标值的样本分布差异,因此,不再局限于数学距离。上述分析可知,本文方法相较于对比方法有更优的去混响能力,能进一步提升去混响语音的整体质量。
为进一步验证本文方法在不同说话人的混响语音上的泛化能力,表4给出了非同源测试集在加性频域分解下的DNN、FCN方法和本文方法的PESQ、STOI和LSD评价指标得分情况。通过表4可以清晰看出,3种方法的在PESQ、STOI和LSD评价指标得分从高到低依次为本文方法评价指标得分、加性频域分解下的FCN方法评价指标得分、加性频域分解下的DNN方法评价指标得分,这与同源测试集中得分具有相同的变化趋势。通过表4对比表3中加性频域分解及本文方法的评分结果可知,虽然非同源测试集3种方法下的整体得分低于同源测试集下的得分,但从分值来看仍表现出较好的去混响效果。
表4 非同源测试集的 PESQ、STOI、LSD评价得分
Tab. 4 Objective PESQ, STOI, LSD scores of non-homologous test sets
RT60/ms非同源测试集的PESQ评价得分 非同源测试集的STOI评价得分 非同源测试集的LSD评价得分加性频域分解 本文方法 加性频域分解 本文方法 加性频域分解 本文方法DNN FCN DNN FCN DNN FCN 200 2.38 2.56 2.63 0.87 0.91 0.92 0.81 0.77 0.77 400 2.10 2.34 2.41 0.82 0.87 0.89 0.92 0.85 0.84 600 1.94 2.22 2.24 0.78 0.85 0.86 0.97 0.91 0.90 800 1.80 2.05 2.07 0.77 0.81 0.81 1.07 1.00 0.99
图5展示了本文方法在 PESQ、STOI、LSD 3种评价指标下同源测试集与非同源测试集的得分差值曲线。
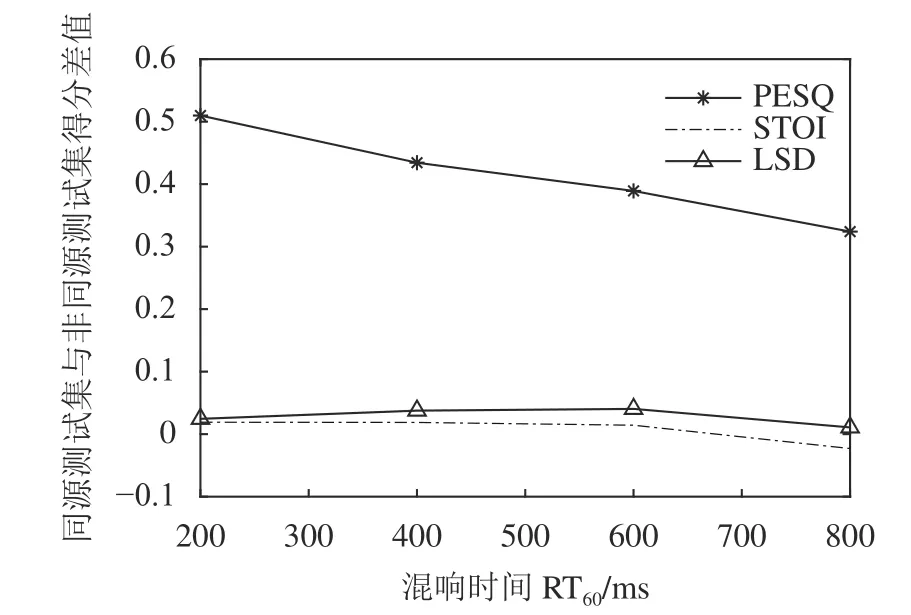
图5 同源测试集与非同源测试集的得分差Fig. 5 Score difference between homologous and non-homologous test sets
由图5可知:PESQ得分差值曲线变化明显,说明非同源测试集在感知质量上的恢复要弱于同源测试集,这主要因为神经网络在训练时额外学习了说话人的个性特征,导致训练好的网络对同源说话人的语音更加敏感,得分较高。而STOI和LSD得分差值曲线变化平缓,说明对于非同源测试集,本文方法对混响语音的可懂度和频谱质量也具有很好的提升。
为从频谱细节中更直观地观察去混响语音质量,图6展示了RT为600 ms的一句混响语音经5种对比方法和本文方法去混响后的语谱图。由图6可知:所有方法在低频部分对混响干扰都有较好的抑制作用(如左下方矩形框部分),而在高频部分中就存在明显差距。图6(d)、(f)、(h)中,这3种方法对小矩形框中高频部分恢复更好,尤其是本文方法对高频部分混响干扰的抑制更显著,使得细节信息恢复更好,框中的声纹恢复更加平滑清晰,更接近于声源频谱。

图6 5种对比方法和本文方法下的测试语音语谱图Fig. 6 Test speech spectrograms of five comparison methods and proposed method
为验证本文算法的实际去混响性能,从真实环境下录制一段混响语音进行测试,声源语音由一名男性发声,在空间大小为2.0 m×1.4 m×3.0 m的房间内录制。图7分别为实测混响语音与使用4种RT(RT为200、400、600、800 ms)下已训练好的本文方法去混响模型的测试语音的语谱图。4种RT都进行测试是由于无法知道实测环境的混响时间。
由图7可见:本文方法在低频成份上能较好地抑制混响干扰(图7(b)~(e)的左下方矩形框);本文方法在RT= 600 ms下对语音高频成分(小矩形框部分)有一定恢复作用,在RT= 800 ms下对语音高频成分(小矩形框部分)恢复作用较明显。但受实际环境和噪声等因素干扰,本文方法获得的去混响语音在自然度上存在部分失真。

图7 4种RT60下的本文方法去混响测试语音语谱图Fig. 7 Speech spectrograms of proposed method dereverberation test under four RT60
4 结 论
传统的基于深度学习的语音去混响方法一般是在乘性频域下来实现的,但是这种方式下的神经网络学习的特征数据仍存在较强相关性。为从数据本身上降低相关性,本文提出了一种基于加性频域分解的生成对抗网络语音去混响算法,通过非线性对数运算,将混响语音的频谱相乘调制转换为频谱相加调制,进而使数据中包含的特征独立性更强,更有利于GAN对混响特征数据进行抑制。本文算法是根据混响语音的产生机制,通过简单的数学变化来实现混响语音的解相关,且各变量都有对应物理含义,避免了设计更加复杂的神经网络去从高相关性数据中提取特征。实验结果也表明本文方法可以更好地抑制混响干扰,在不同混响时间下得到的去混响语音质量都有进一步提高,且在实测语音上也有一定的去混响效果。但因对数的饱和效应,高频部分仍存在结构信息损失,说明加性频域分解对于高频成分仍有不足,这也是下一步需要重点研究的问题。
