基于多视图并行的可配置卷积神经网络加速器设计
2022-03-28应三丛
应三丛,彭 铃
(1.四川大学 计算机学院,四川 成都 610065;2.四川大学 视觉合成图形图像技术国防重点学科实验室,四川 成都 610065)
卷积神经网络(convolutional neural network,CNN)的算法模型优化,是提升性能的关键。目前,CNN算法的实现平台主要有中央处理单元(central processing unit,CPU),图形处理单元 (graphic processing unit,GPU)和可编辑逻辑门阵列(filed programmable gated array,FPGA)。GPU虽然并行度高,但能耗和成本也较高;CPU无法实现高效的并行运算,导致模型计算效率低下;而FPGA的可重构、低延时、高吞吐量等特性更适用于人工智能算法加速。但随着CNN算法日趋复杂,基于FPGA的软硬件协同技术被广泛应用。
Meloni和Xue等采用软硬件协同设计方法,其通用处理器是基于ARM(advanced RISC machines)架构,存在定制成本高、灵活性不足等问题。而第五代精简指令集(reduced instruction sets computing,RISC-V)作为当下热门的开源精简指令集架构,是解决上述问题的不二之选。RISC-V指令集由基本指令集和扩展指令集构成,其中,基本指令集是设计RISC-V处理器不可或缺的,扩展指令集则根据用户需求定制。目前,市面上涌现出众多基于RISC-V指令集的开源处理器,伯克利大学设计的Rocket处理器和芯来科技研发的E203处理器深受广大科研工作者推崇。Liao和Yang等选用Rocket处理器实现卷积加速,虽然加速效果明显,但该RISC-V处理器的硬件设计代码是由高级语言转换生成,可读性差,同时,该硬件设计实现于FPGA,会消耗额外的查找表 (look-up-table,LUT)。而E203处理器代码均由人工编写,可读性强且易于理解,该处理器核的功耗和面积与同级ARM Cortex-M核相比极具竞争力。Wu等利用专用协处理器接口去设计扩展指令,从而实现CNN加速和物联网领域多种算法的配置,但其不适用于配置不同模型的卷积、池化、全连接等单元;且未设计片外存储器单元,不适合数据量大的CNN模型。Zhang等采用软硬件协同技术设计CNN加速器,加速效果显著,但该CNN加速器不可配置。Ayat和英伟达的NVDLA主要针对卷积层加速,未结合CNN各个运算单元加速。Ma等结合理论原理,探索卷积层的循环展开方法。Cao设计的CNN加速器在各个运算单元实现了全并行展开,对硬件平台要求较高。
综合以上因素,本文进行了如下研究:第一,扩展协处理器的控制访问接口,实现RISC-V对CNN加速器的参数配置;扩展片外存储器与协处速器的数据访问接口,实现批量数据传输。第二,将卷积层的四重循环展开方法与英伟达NVDLA的并性设计方法相结合,实现多视图部分并行展开,同时该方法可应用于池化和全连接单元。各单元的硬件架构决定寄存器组的设计,由此完成可配置功能。
1 RISC−V处理器
本文的RISC-V处理器是一款变长两级流水线的32位处理器。其中:第1级流水线完成取指功能;第2级流水线实现译码、执行、交付和写回功能。它的系统总线称为内部芯片总线(internal chip bus,ICB))。该总线沿用高级可扩展接口(advanced extensible interface,AXI)的握手机制,仅两个通道,易于控制。
2 基于RISC−V的CNN加速器SoC设计
本文构建的片上系统(system on chip,SoC)如图1所示,系统包括RISC-V处理器、协处理器接口单元、CNN协加速器和片外存储器。

图1 SoC系统框图Fig. 1 Architecture of SoC system
图1中,协处理器接口单元由控制访问接口和数据访问接口构成,分别适用AXI-LITE和AXI-FULL总线。RISC-V处理器作为该SoC的配置管理器,控制CNN加速器的寄存器单元。CNN加速器主要完成寄存器单元的信息解析,然后根据译码信息,实现直接存储访问(direct memory access,DMA)与片外存储器的数据交互,执行卷积层、池化层和全连接层的实时运算。
2.1 高速协处理器接口设计
本文的高速协处理器接口包括协处理器控制访问接口和协处理器数据访问接口,如图2所示。
由于ICB通用性弱,不适合直接连接高速模块,因此,为协处理器扩展高速控制访问接口,完成RISC-V与CNN加速器的控制访问总线的衔接,并使其兼具高速特性。具体实现方式是先利用总线桥将ICB接口转换为适用于控制访问单元的AXI接口(兼容AXI-LITE接口);然后为该桥接单元设计一个专用的异步先入先出(first-in first-out,FIFO)缓冲器,实现硬件加速单元能以高于RISC-V处理器的时钟独立工作。实现框图如图2(a)所示。
图2(b)为协处理器的数据访问接口框图。由于CNN运算的数据量庞大,仅靠片内存储器不仅耗费资源,且无法实现批量传输,因此为其开辟适用AXI-FULL的片外存储接口,以片外存储器来实现数据的高速传输。该接口的突发传输参数包括突发包首地址和数据个数等,单次突发传输的数据个数最大为256。CNN加速器的数据接口由卷积、池化和权重对应的读通道和卷积、池化对应的写通道构成;其中,读通道包括读命令通道和读数据通道。经多路仲裁器轮询仲裁,从3组读命令通道确定存储器的读命令通道,同时根据读命令值,将存储器中待读取的数据分发给CNN加速器对应的读数据通道。而写命令通道、写数据通道和写反馈通道共同构成了写通道。为了提升总线资源的利用率,将写数据的最高位作为写通道数据类型的判断依据,从而实现CNN加速器写命令通道和写数据通道的复用。如果是写命令,则分发给卷积或池化的写命令缓存单元,然后再以轮询仲裁方式发送给存储器的写命令通道,同时存入状态缓存器。对于写数据,先分发给对应的缓存单元;然后,根据写命令值,发送卷积或池化单元的数据到存储器写数据通道;最后,对写响应通道的数据和当前状态缓存器的数据进行判决,以判决器的输出作为存储器写响应通道数据分发的标志。

图2 协处理器高速接口框图Fig. 2 Diagram of coprocessor high-speed interface
2.2 CNN协加速器设计与分析
CNN的基本结构主要包括卷积、池化和全连接层,且各算法层包含多重循环。因此,结合硬件设计的并行思想,采用多视图并行来设计本文的CNN加速器,其中并行展开度为K
,其值可配置为8、16、32。2.2.1 卷积设计与分析
卷积的输入特征图和输出特征图分别表示为I
和O
,权重和偏置分别为W
和B
。3维卷积输出特征图的相关计算公式如下:

H
、
H
、H
分别为输出特征图、输入特征图和权重卷积核的列大小,W
、W
、W
分别为输出特征图、输入特征图和权重卷积核的行大小,P
、
P
为沿行方向和沿列方向的填充行数,S
、S
为沿行方向和沿列方向的滑动步长,x
、y
为 输出特征图的坐标点,m
和n
分别为输出通道和输入通道的参数值,f
为激活函数。本文实现的三重循环并行展开方法,其基本单元由乘累加器和累加器构成,有利于提升模块的资源利用率。以并行度K
实现,此时,三重循环展开可抽象为多个矩阵的并行运算。由于每个视图的基本运算单元最大并行度为32,因此单个视图的并行乘累加阵列个数为32。图3为卷积并行展开示意图,其中,N
/K
和M
/K
分别表示特征矩阵沿输入通道(输入通道长度为N
)和输出通道(输出通道长度为M
),按并行度K
展开的总运算次数(“/”代表的除法运算,若不能整除,则向上取整,即即 「N
/K
」,下同)。为简化硬件设计,对输入特征图的列以并行度K
展开,其运算次数为H
×W
/K
。图3中序号①表示沿输入通道方向的K
个大小为1 ×1的特征矩阵参与卷积运算;序号②表示列长为K
,输入通道长度为K
,大小为1 ×1的特征矩阵参与卷积运算;序号③则是沿输出通道方向,同时进行输出通道长度为K
的序号②运算过程。M
和M
分别表示输入特征图和权重的运算次数。
图3 卷积并行展开示意图Fig. 3 Diagram of convolution parallel expansion
卷积运算的理论计算公式如下:
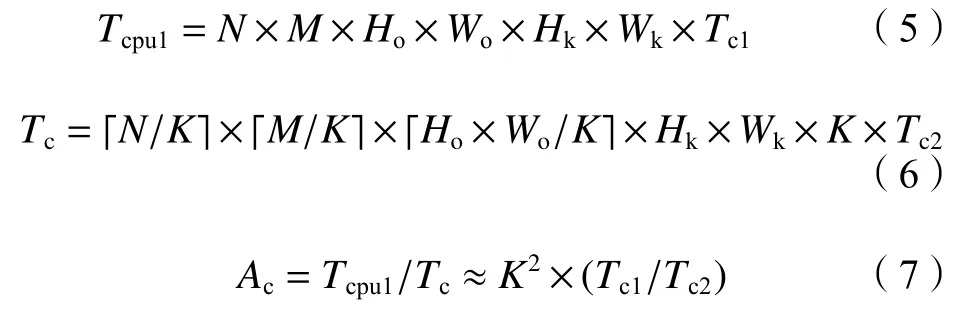
T
和T
分别为CPU和CNN加速器的卷积运算时间,T
和T
分别为CPU和CNN加速器的单次运算时间,A
为卷积加速比。2.2.2 池化设计与分析
类似卷积的并行展开算法,对池化矩阵在输入通道方向上、对输出池化特征图在列方向上分别执行K
并行度展开,同时将池化单元设计为行池化和列池化级联结构。池化设计的相关参数如下:I
和O
分别为池化的输入和输出特征图,N
为池化的通道数,H
、W
分别为池化输入特征图的行大小和列大小,H
、W
分别为池化输出特征图的行大小和列大小,H
、W
为池化窗口的高和宽。池化的并行展开过程如图4所示。针对行池化,其输出特征图大小为H
×W
,因此,行池化的通道参数和特征图列大小的并行展开次数可表示为N
/K
和H
×W
/K
。由于只实现了行运算,因此池化窗口的运算次数为W
×K
,图4中每个矩形框的大小为1×K
。列池化的展开原理类似。M
和M
是行池化和列池化的运算次数。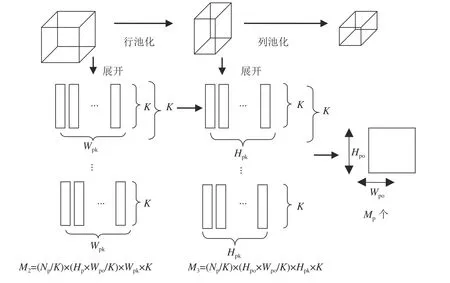
图4 池化并行展开示意图Fig. 4 Diagram of pooling parallel expansion
池化运算时间的理论计算公式如下:

T
为CPU的池化运行总时间,T
和T
分别为行池化耗时和列池化耗时,T
和T
分别为CPU和CNN加速器的单次运算时间,A
为池化加速比。2.2.3 全连接设计与分析
为减少额外的资源消耗,全连接模型可经处理而映射到卷积运算电路。其转换思想是将维度为N
的输入向量I
转换为大小为1 ×1, 输入通道数为N
+1的卷积输入特征图。将偏置矩阵合并到权重矩阵,矩阵权重卷积核大小为1 ×1,输入通道数和输出通道数分别为N
+1和M
。而转换后的输出特征图O
的大小为1 ×1, 输出通道数为M
。按卷积并行展开法,其运算展开过程如图3所示。理论计算公式如下:
T
和T
分别为全连接运算和CPU的总耗时,T
和T
为 两者所对应的单次耗时,A
为两者的加速比。2.3 CNN协加速器设计与实现
通过分析CNN加速器的各运算单元,划分其硬件单元为寄存器组、定点模块、通用运算单元和池化单元。根据设计的硬件电路结构,设计CNN加速器的寄存器组,它由1个系统控制寄存器,33个通用寄存器和26个池化寄存器构成。通过配置寄存器组信息,来完成不同模型在CNN加速器上的部署。其中,通用寄存器组适用于卷积或全连接单元,而系统寄存器决定运算单元开始或结束。
2.3.1 定点量化
根据Hubara等的研究,数据量化对图像任务干扰较小,且对数据参数的精度要求不高,因此为解决CNN主流模型存在的计算量大、存储占用大等问题,本文将32位单精度浮点数处理为16位定点数,这样既可降低数据存储量,又可简化硬件加速器的设计。模型的存储量可降低1倍。
2.3.2 通用运算单元设计与实现
通用运算单元包括通用寄存器组、卷积读DMA、权重读DMA、卷积缓存器、权重缓存器、卷积片上存储器、权重片上存储器、卷积控制单元、乘累加单元、累加单元和激活单元。同时,由于卷积与全连接的运算结构相似,因此,仅设计卷积计算单元来作为通用计算单元,以复用形式实现卷积与全连接运算。
图5展示了通用运算单元的结构,其卷积运算的具体运算流程为:首先,配置系统寄存器,产生系统控制信号,然后,配置卷积运算参数寄存器,确定特征图的行大小、列大小、通道数、卷积核大小等,并产生卷积单元的控制信号。接着,配置卷积的数据访问寄存器参数,如突发包的读地址和读数据长度等,根据这些参数,将卷积和权重数据经DMA从片外存储器写入片上存储器。如此,将所需的运算数据准备好。再根据卷积单元的运算控制信号实现数据的乘累加和累加运算。其中,乘累加单元是由K
路并行乘累加器构成,其值在硬件电路设计中可配置为8、16、32。该运算电路可被复用在3维视图并行实现的CNN加速器中,如最大并行度为32,输入通道为3,则复用该结构1次;输出特征图高为224,复用7次;输出通道为64,复用2次。
图5 通用运算单元结构Fig. 5 Structure of general operation units
对于全连接运算,可通过处理其模型参数,配置通用寄存器组,来实现卷积与全连接模型兼容,同时以运算单元之间的复用来降低硬件资源消耗和设计的复杂度。例如,对全连接结构 4096×1000,按卷积结构处理,可得到结构为 4 096×1×1的卷积输入特征图和结构为4 096×1×1×1的权重特征图,由此将全连接运算转化为卷积运算,实现卷积与全连接结构复用。
经过乘累加和累加单元运算后,根据激活函数寄存器的值,决定该运算结果是否进行激活运算,并将最终结果存入结果缓存器。由于该通用运算单元的输出数据将作为下一运算单元的输入数据,因此按通用寄存器组配置的输出数据地址、数据长度和存储方式等,将结果经卷积写DMA写回片外存储器,并向寄存器返回运算完成标志。
2.3.3 池化运算单元设计与实现
池化运算单元由池化寄存器组、池化读DMA、池化写DMA、池化读缓存器、池化写缓存器、池化控制单元、行池化和列池化组成。其运算结构如图6所示。

图6 池化运算单元结构Fig. 6 Structure of pooling unit
与通用运算单元类似,系统寄存器配置完成后,池化寄存器组开始对池化运算参数寄存器(如输入特征图大小、输出特征图大小、池化窗口大小等)进行配置。接着,池化模式寄存器被配置为最大池化、最小池化或平均池化之一,并产生相应的控制信号,发送给行池化和列池化单元。在完成池化运算参数寄存器配置后,对池化数据参数寄存器进行数据参数值写入。根据这组寄存器提供的读地址、读数据长度、读数据形式(如行或面),从片外存储器读取与之对应的有效数据,并经池化读DMA存入池化读缓存单元,然后执行池化运算。
池化的实际运算单元包括行池化和列池化。其中,行池化的基本运算电路是由最大池化电路、最小池化电路、平均池化电路和3选1多路选择器构成,池化方法控制信号决定行池化的输出数据来源。对于列池化,其输入源于行池化的输出,因此列池化单元可由并行的行池化电路构成。
根据池化运算结构框(图6),列池化的输出结果是池化的最终输出结果。该结果通常作为全连接或卷积的输入数据,因此需要根据池化输出数据参数寄存器,给定输出存储地址、存储大小、行存储参数、面存储参数等,将池化输出结果写回片外存储器的相应单元。
3 实验结果
3.1 FPGA平台验证
使用开发工具Vivado2018对本文的设计进行综合和布局布线,其中RISC-V和CNN协加速器的时钟频率分别为16 MHz和110 MHz。表1列出了CNN协加速器资源消耗情况,CNN协加速器功耗为1.883 W。
表1 CNN协加速器资源消耗
Tab. 1 CNN accelerator resource utilization
资源名称 资源消耗数目/个 资源占用率/%LUT 61 656 20.31 FF 84 115 13.85 BRAM 912 88.54 DSP 1 095 39.11
3.2 CNN协加速器性能
本文在相同测试条件下,分别将卷积、池化和全连接模型部署在CPU、GPU和本文设计的CNN协加速器,获取各自的运算时间、能耗等性能指标。
表2为相同测试模型分别被部署在3个平台(频率2.4 GHz,功耗45 W的英特尔i5-9300处理器;频率1.15 GHz,功耗235 W的英伟达GPU K40M处理器;频率110 MHz,功耗1.883 W的CNN协加速器)的性能指标。测试模型包括3个卷积模型,4个池化模型和3个全连接模型,卷积核大小均为 3 ×3。其中,本文的CNN加速器的卷积算力均值为221 GOPS。表2中的能耗比是GPU与CPU、本文协加速器与CPU的能耗比值;速度比是GPU与CPU、本文协加速器与CPU的运算时间之比。
表2 不同平台不同运算单元性能
Tab. 2 Performance of different kits and different computing units
硬件平台 运算单元运算时间/ms能耗/(W·s)能耗比速度比CPU i5-9th卷积 8 845.760 398.059 1 1池化 112.515 5.063 1 1全连接 11.960 0.538 1 1 GPU Tesla-K40M卷积 0.973 0.229 1 7429 095池化 0.914 0.215 24 123全连接 1.553 0.365 2 8本文协加速器卷积 46.676 0.087 4 554189池化 10.279 0.010 491 11全连接 2.184 0.004 131 6
为了更准确地描述CNN模型的性能,将经典模型VGG16的卷积层部署于CNN协加速器,表3列出了部署VGG16的5个卷积单元组时,本文设计的加速器的性能。表3中,GOP(giga operations)代表十亿次定点运算数,GOPS(giga operations per second)表示每秒执行的十亿次定点运算数。
表3 VGG16卷积单元组性能
Tab. 3 Performance of convolution groups for VGG16 network
硬件平台 卷积组 运算时间/ms运算量 吞吐量本文协加速器第1组 27.14 3.87 GOP142.59 GOPS第2组 27.14 5.55 GOP204.50 GOPS第3组 45.28 9.25 GOP204.28 GOPS第4组 46.35 9.25 GOP199.57 GOPS第5组 16.26 2.31 GOP142.07 GOPS
表4是本文设计的CNN加速器与部分前人工作的对比,从表4中可知,本文设计的CNN加速器的吞吐量为178.6 GOPS,与其他3种加速器相比,吞吐量分别提高94.3 GOPS、44.5 GOPS和55.9 GOPS。
表4 实验对比
Tab. 4 Comparison with previous implementations
平台 FPGA型号时钟频率/MHz运行时间/ms运算量 吞吐量Angel-eye[28]XC7Z020214364.0030.69 GOP84.30 GOPS ALAMO[29] GXA7 100 9.821.46 GOP134.10 GOPS ConvNets加速器[30]XC7Z045125249.5030.70 GOP123.12 GOPS本文协加速器VC707 110162.1730.69 GOP178.60 GOPS
4 结 论
本文基于RISC-V扩展了控制访问接口,用于参数配置,扩展CNN加速器的数据访问接口,完成数据高速传输,然后设计多视图并行的卷积神经网络的协加速器,最后构建包含RISC-V处理器和CNN协加速器的SoC。将CNN模型部署在本文设计的CNN协加速器、CPU、GPU平台,在测试模型和卷积核大小相同情况下,分别对各平台的卷积、池化、全连接单元进行仿真验证。其中,CNN的各运算单元运行在本文设计的CNN加速器的运算速度分别是运行在CPU平台的189倍,11倍和6倍,但明显低于GPU。而对比GPU与本文的加速器的能耗,各运算单元运行在GPU平台的能耗分别是本文设计的CNN加速器的2.6倍,20.5倍和65.5倍。根据表3可知,全连接单元的加速比远小于卷积单元,其原因是全连接单元需经转换才能复用卷积单元结构,而转换生成的卷积输入特征图的行和列大小都为1,这将导致访问外部存储器的带宽降低。
为进一步验证本文设计对具体CNN模型的影响,对VGG16的5组卷积单元进行独立验证,其卷积的运算性能可达178.6 GOPS,与其他的CNN加速器相比,性能得以提升。虽然本文构建的可配置CNN协加速器SoC的加速效果显著,但仅仅是对卷积、池化、全连接单元的单独测试,未进行完整网络的性能分析,下一步将搭建完整的CNN网络模型进行整体性能分析。
