基于SMOTE与LSTM的核电厂小样本不平衡故障诊断
2022-03-25黄学颖刘永阔单龙飞
黄学颖,刘永阔,单龙飞
哈尔滨工程大学 核科学与技术学院, 黑龙江 哈尔滨 150001
核能作为一种清洁、环保、低耗的能源形式,其自身在事故状态下也存在放射性外逸风险。而核电厂发生放射性泄漏对环境和人员安全会造成很大的影响,因而对核电厂的安全性具有更高要求。为将核电厂发生故障时造成的损失降到最低,在核电厂发生故障时,及时、准确地识别出故障类型及故障位置具有重要意义。国内外学者针对核电厂故障诊断问题做了大量研究。
在国外Lu等[1]利用主成分分析算法等方法开发了一套故障检测和隔离技术,并将其应用于典型压水反应堆中;Deleplace等[2]利用极限梯度提升进行核电厂屏幕清洁器状态监测;Joo等[3]将模糊有向线图进行改进将其应用于Kori-2 核电站稳压器的故障诊断;Dae等[4]将模型推理和验证的人工智能技术应用于核电厂故障诊断系统中,使得故障诊断更加高效;Suryakant等[5]采用卡尔曼滤波器制定故障检测指标和故障特征,将其应用于核电厂传感器时变初始故障检测。在国内熊晋魁等[6]在利用专家知识建立核电厂二回路凝给水故障模型的基础上,引入径向基函数,有效提高了神经网络的诊断准确性和诊断效率;吴国华等[7]利用定性趋势分析与阈值法相结合进行核电厂状态监测,建立符号有向线图进行核电厂二回路故障诊断;熊立红等[8]在核电厂故障诊断系统中引入多级流模型,通过其中信息流、物质流、能量流之间的状态关系准确找出原始故障源位置;孙英杰等[9]采用多变量状态估计和序贯概率比技术,对核电厂冷却剂系统参数变量进行异常判断与预测;朱少民等[10]以蒸汽发生器为研究对象,建立以BP神经网络为主的故障诊断系统,有效地实现了数据的实时采集、在线处理以及故障诊断。
虽然以上方法在数据量充足的条件下进行故障诊断可以得到较好的结果,但在故障数据量很小且正常数据量与故障数据量差异明显,即小样本不平衡情况下很难得到较高的故障准确率。
国内外针对小样本不平衡数据处理也做了大量工作,小样本不平衡数据的核心问题是样本数量过少,导致模型训练难度加大。目前主要通过以下3种方式解决该问题:1)基于数据增强方法,主要思路是利用增强数据来解决目标域数据量不足的现象[11],其中的代表算法包括合成少数类过采样技术(synthetic minority oversampling technique,SMOTE)等;2)基于度量学习方法,通过解决度量数据相似性的问题来解决小样本不平衡问题,典型方法包括匹配网络[12]和关系网络[13]等;3)基于初始化方法,通过优化器的初始化或网络模型优化来解决小样本不平衡问题,典型方法包括记忆增广神经网络[14]、模型未知源学习方式[15]等。
针对以上问题本文拟采用SMOTE与长短期记忆(long short term memory,LSTM)相结合的方法进行核电厂小样本不平衡故障诊断,利用SMOTE扩展训练样本,结合LSTM自动进行特征参数选取的优点,有效提高故障诊断系统在小样本不平衡时故障诊断准确率。
1 核电厂一回路特征参数处理
1.1 特征参数提取
首先采集福清仿真机在100%满功率正常运行状态下的数据,然后插入蒸汽发生器传热管破裂故障、主泵卡轴故障及主蒸汽管道破裂故障,并导出发生上述故障时的故障数据。所有故障类型中包含69种特征参数,绘制4种故障的69种特征参数趋势图,选取其中有利于后续故障诊断的特征参数进行后续处理。以其中的稳压器波动管温度、电加热器热功率为例演示特征参数提取过程。
首先进行核电厂4种状态下、2个状态特征参数趋势图绘制,绘制结果如图1~2所示。
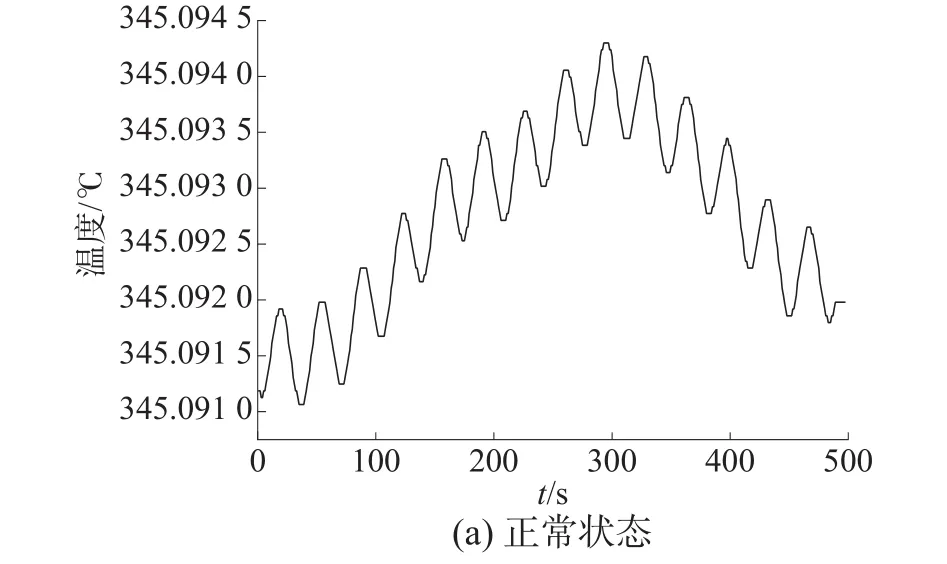

图1 稳压器波动管温度
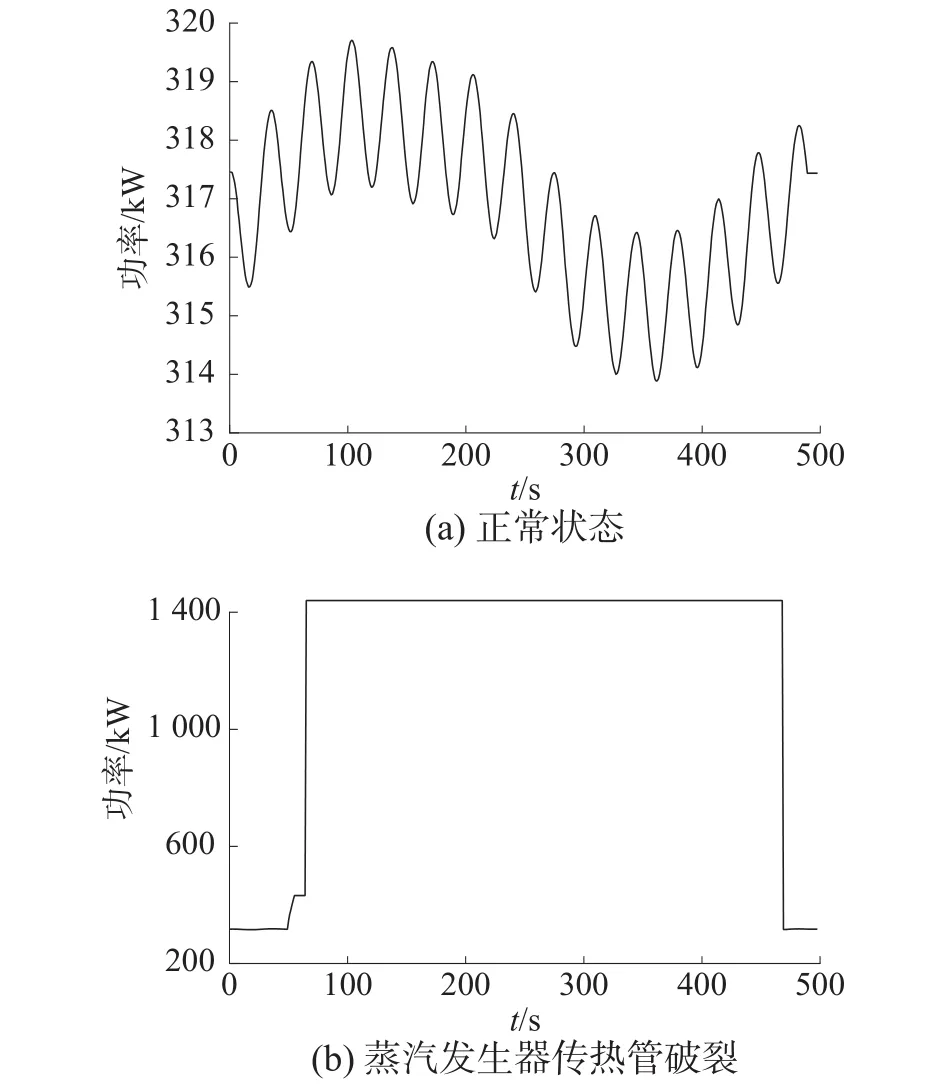
将图1和图2进行对比发现稳压器波动管温度在4种状态下差异性更加明显,而电加热器热功率与稳压器波动管温度相比,电加热器热功率对于后续故障诊断效果并不明显。
图2 电加热器热功率
按照上述原则进行特征参数提取,最终从69种特征参数中选取26种特征参数用于后续故障诊断,分别为稳压器波动管温度、稳压器水位、稳压器压力、稳压器蒸汽空间温度、SG水位、SG二次侧给水流量、SG蒸汽产量、SG出口蒸汽压力、压力容器入口温度、冷却剂压力、冷管段温度、热管段温度、下泄流量、上充流量、下泄管线压力、下泄换热出口温度、上充管线压力、电功率、核功率、安全壳压力、安全壳温度、安全壳地坑水位、喷淋流量、轴封上充流量、下泄换热器壳侧冷却水流量和下泄节点压力。
1.2 SMOTE 算法扩容
为提高后续深度神经网络模型训练效果,使用SMOTE算法进行少数类样本扩容。本文选取正常状态数据250余个、蒸汽发生器传热管破裂故障数据10个、剩余 2种故障状态数据各 30余个,进行SMOTE算法扩容。SMOTE原理图如图3所示。图3中,圆形代表多数样本点,黑色星星代表少数样本点,其中横纵坐标代表样本点包含特征参量,为多维数据,如本文所述模型,样本点为26维数据。

图3 SMOTE 原理
SMOTE算法主要计算过程为:
1)计算少数类样本之间的欧式距离,选取k邻近点。
2)根据不平衡比例设置采样倍率。
3)按照式(1)的方式计算出新的样本点。
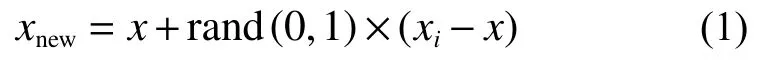
式中:x为小样本参数,xi为小样本相邻相同类型样本参数点。
2 基于 LSTM 的核电厂一回路故障诊断
LSTM深度神经网络是在循环神经网络(recurrent neural networks,RNN)的基础上加以改进,有效地解决了RNN长序列依赖的问题[16−17],LSTM原理如图4所示。图4中ft、it、ot分别为遗忘门、输入门和输出门。
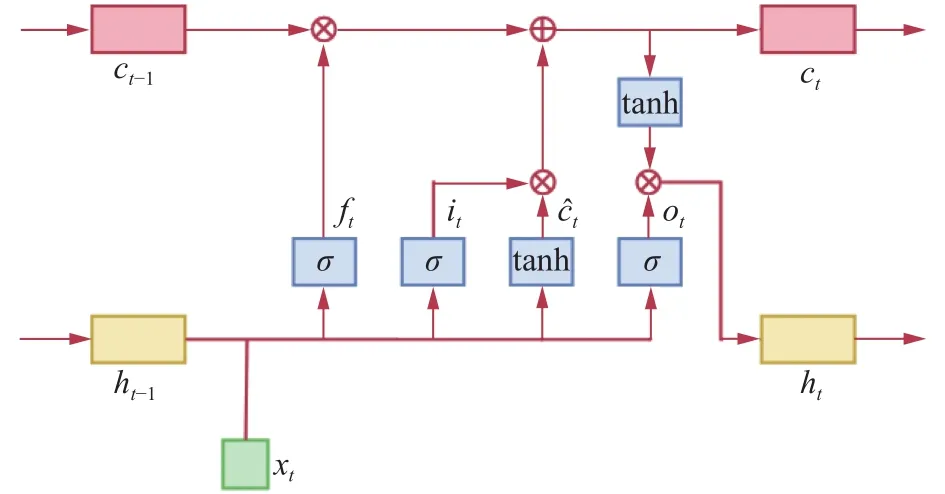
图4 单个时间步长的 LSTM网络结构示意
LSTM通过引入门的结构来解决RNN中的长序列依赖问题,每个门结构包含了1个以sigmoid为激活函数的神经网络结构,sigmoid 输出范围为0~1,可以用来控制信息传递的比例,实现对历史信息的选择性遗忘。由于LSTM门结构的存在使得LSTM深度神经网络可以自动进行特征参数筛选,保留有利于故障诊断的特征参数,筛除对后续故障诊断影响较大的不利特征参数。
输入门用来控制输入值xt的保存比例,输入门的计算方式如式(2)和式(3)所示:

遗忘门主要是用来确定ct−1中多少成分被传递到ct中,其计算公式如式(4):

式中ft为遗忘门的门限,即历史状态ct−1被遗忘的比例。
通过遗忘门和输入门实现状态C的删除和更新,状态ct计算公式如式(5):

输出门用来计算LSTM 隐藏层输出,其数学表达式如式(6)和式(7)所示:
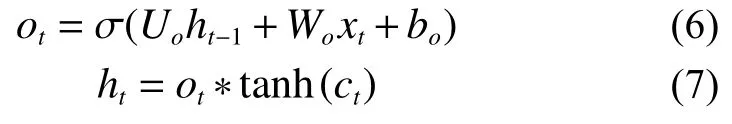
文中LSTM深度神经网络具体训练流程如图5所示。
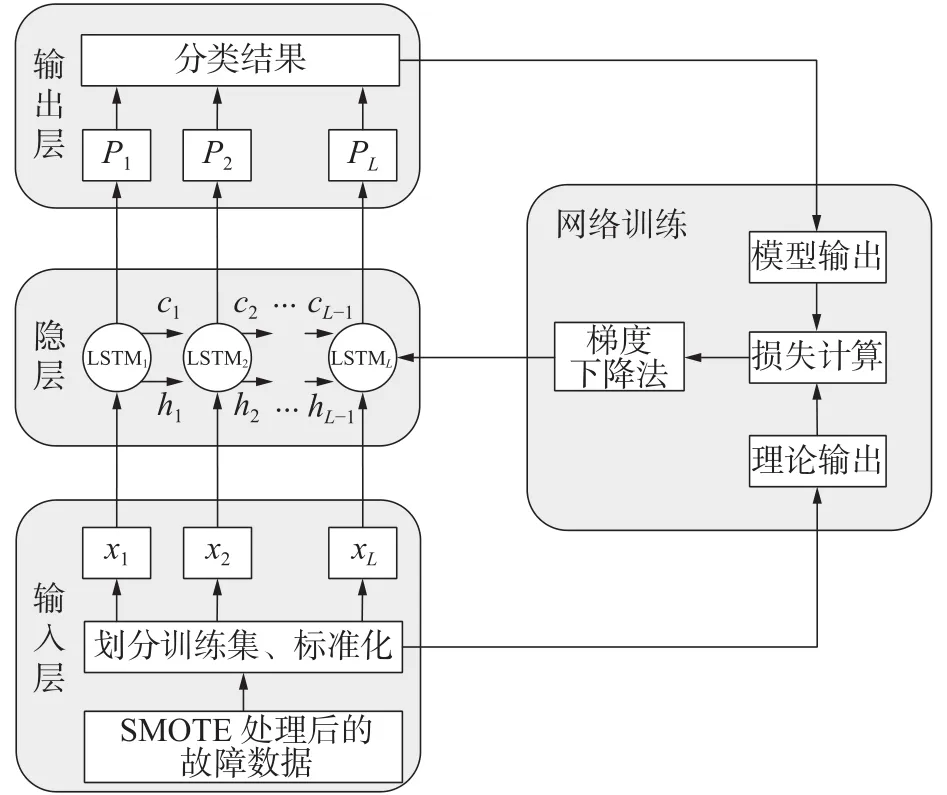
图5 LSTM 网络训练流程
LSTM具体的训练流程为:
1)将进行SMOTE处理之后的故障数据,进行标准化处理。
2)初始化LSTM网络。设置初始权值及最大迭代次数等参数。
3)前向计算。按照上述原理部分内容进行LSTM前项计算。
4)误差反向传播。将模型输出值与理论输出值的均方误差作为误差计算公式,不断通过迭代过程优化模型。
5)训练模型满足预设条件时,停止训练,代入测试集,测试模型故障诊断准确度。
3 结果验证
为验证SMOTE算法与LSTM深度神经网络相结合用于核电厂小样本不平衡故障诊断的准确性,本文将未进行SMOTE处理的数据与进行SMOTE处理的数据进行结果对照,对照结果如表1所示。

表1 SMOTE 扩展效果对比 %
由表1可知在对数据进行SMOTE处理之后,故障诊断准确率大大提高。在未进行SMOTE处理之前由于蒸汽发生器传热管破裂故障数据量较小,且与其他部分故障类型发生故障征兆相似,分类模型训练不充分,因而故障诊断准确率极低,只达到了8.33%。在进行SMOTE处理之后,针对小样本不平衡问题的故障诊断准确率大大提高,且蒸汽发生器传热管破裂故障诊断准确率也由原来的8.33%提升至75%。
4 结论
本文针对核电厂一回路小样本不平衡故障诊断的问题,提出一种SMOTE与LSTM相结合的方法。利用SMOTE算法拓展训练样本,极大地提高了LSTM深度神经网络故障诊断的准确率,并通过实验验证了该方法在样本数量极小以及样本数据量差异极其明显时该方法的可行性。以蒸汽发生器传热管破裂故障为例,在进行SMOTE处理之后,故障诊断准确率由原来的8.33%提高至75%,提升效果显著。
