基于Rasch模型的网络教育学位英语考试试题质量分析
——以北京地区为例
2022-03-24刘勇李俊平
刘勇,李俊平
(北京邮电大学 网络教育学院,北京 100088)
一、引 言
随着互联网的出现和普及,成人学历教育极大缓解了原有困扰成人教育的工学矛盾,提高了国民的学历层次与专业素养,为社会培养了数量庞大的应用型人才[1]。网络教育属于成人学历教育的一种,其灵活的学习方式非常适合工作繁忙、学习时间不固定的成人学习者。教育部最新发布的《各级各类学历教育学生情况》显示,截至2020年6月,全国网络本专科高等教育在校生(web-based undergraduates)数量已达850余万[2]。网络教育作为国家高等教育的重要组成部分,为解决在岗人员的学历教育和继续教育问题作出了重要贡献。
英语教育作为网络教育的重要组成部分,旨在帮助学生树立世界眼光,培养学生的国际意识,提升学生的人文素养。在针对网络教育学生进行的英语能力测试中,成人本科学士学位英语统一考试(adult higher education bachelor’s degree in English test,简称学位英语考试)是其中一项重要的测试。成人本科学士学位英语考试用于检测地区成人教育系列中非外语专业学生的英语水平,为提高成人本科毕业生学士学位质量提供了重要保障。学位英语考试每年举行两次,非英语专业学生只有通过此考试,才有资格获得本科学士学位证书。因此,为了获得学位,学生非常希望通过这一考试。然而,由于网络教育学生多是成年人,其英语水平普遍较低,这一考试的通过率并不高。以北京地区为例, 2018 年北京地区成人本科学士学位英语考试的通过率仅为20%左右[3]。因此,有必要对学位英语考试试题进行分析,从中了解成人学生的英语学习能力以及试题质量情况,进而为提高学位英语考试试题质量提供量化依据,使学位英语考试更具有效性、公平性和准确性。
二、研究概述
教育测评是教学过程的重要环节,必须对测评工具的质量进行严格把关。测评工具一旦出现问题,测评结果必将缺乏全面性和准确性,也会使教育公平受到破坏。目前,国内对教育测评的分析以经典测量理论(classical testing theory, CTT)为主。研究者普遍认为,CTT具有诸如样本依赖、信度不够准确、忽视具体试题反应等局限[4],这导致基于CTT的测评分析不能较好地反映学生真实水平与测评工具质量。项目反应理论(item response theory, IRT)的出现和发展很大程度上弥补了CTT的不足,其以项目特征曲线与潜在特质为理论框架,依据强假设,通过数学模型来解释被试对测评项目的反应与其潜在水平之间的关系[5],为如今的教育与心理测量提供了坚实有力的数据支撑。IRT的作用尤其体现在对于考试进行测量评价的领域[6]。相较于CTT,IRT的优势集中表现在以下三个方面:一是对被试能力的估计独立于特定测验项目,即对同一批被试而言,在测试项目数量及内容产生变化时,所测量到的被试能力不变;二是项目参数估计独立于被试样本,即面对不同的被试群体,同一份测试项目的参数保持不变,被试答对特定试题的概率仅仅与其本身能力有关,与测试项目的变化无关;三是IRT中被试能力参数与项目难度参数标尺一致,即针对已知能力参数的被试与已知难度参数的项目时,可以较为准确地预估该被试在该项目上的答对概率,反过来说就是能够选择最适合被试的试题进行测试[7]。
丹麦数学家Rasch[8]提出的Rasch模型是IRT中被研究者较为广泛应用的数学模型,常用于心理与教育测量领域的分析。Rasch模型通过精确分析学生在每一道题上的作答反应,对试题的难度水平与学生的能力水平进行估计,并将难度水平与能力水平放在统一等距量尺上进行比较,量尺之间的单位距离具有相同的意义,可以精确分析测验试题难度分布、考生能力分布、试题难度水平与考生能力情况之间的关系等。对于被试而言,在特定项目中能力高的被试答对的概率必然比能力低的被试答对的概率大。因此,Rasch模型实质上是一个概率模型,模型公式如下:
(1)
式中:θn表示被试n的能力值;bi表示具体试题i的难度值;Pni是一个能力为θ的被试n,其在难度值为b的项目i上的正确作答概率。由Rasch模型公式可以明显看出,某被试在某道题上的正确作答概率仅由被试能力值与试题难度值的差值决定,当被试能力值与试题难度值相等时,正确作答概率刚好为50%。对于特定试题而言,被试正确作答概率仅由其能力决定,这也解释了Rasch模型的基本假设。
关于Rasch模型的研究可以分为以下两个方向:一是关于Rasch模型参数估计、模型拓展等数学理论模型构建方向,二是运用Rasch模型进行实践统计探索研究。其中,大量研究着眼于某个测量工具的质量分析,例如张迪[9]对八年级数学学业测试卷试题进行Rasch模型分析,章建石[10]对新高考背景下英语试卷进行分析。国内运用Rasch模型进行英语测试工具分析既包括对小型日常测试、课堂考试等的分析,也包括对大学英语四六级、英语专业四级考试等大型正式考试的分析[11]。经过众多研究的验证,Rasch模型在教育测评工具分析领域应用较为广泛,但是缺乏涉及成人学历教育的测评工具质量分析,尤其是尚未见到网络教育学位英语考试质量分析方面的相关研究。
笔者拟结合网络教育学位英语考试、学习者以及测试过程的特点,基于Rasch模型分析网络教育学位英语测试工具质量及学习者情况,以期拓宽Rasch模型在教育测评中的应用领域,也为网络教育学位英语考试的发展与完善提供理论及数据支撑。
三、结果与分析
(一)数据来源
选取2018年北京地区成人本科学士学位英语统一考试试题中第一部分词汇与语法(Part I-Vocabulary and Structure)的试题进行质量分析。学位英语考试一般都会包括三种题型:一是词汇与语法,二是阅读理解,三是完形填空,题型设计上以客观题为主。其中,词汇与语法部分主要考核学生对词汇、短语及语法结构的理解与运用能力,是对学生英语知识与能力基础的考量。词汇与语法是后续阅读理解和完形填空部分的基础,对这一部分试题进行质量分析,其结果能够反映试题的整体质量情况。因此,本研究将词将汇与语法这部分试题作为研究对象进行分析。
2018年北京地区成人本科学士学位英语考试试卷中的词汇与语法部分共30道题,均为单项选择题,要求考生从每题4个选项中选出唯一正确答案。试题采用“0”“1”计分制:“0”代表考生在该题上答错,“1”代表答对。笔者选取参与此次考试的266名学生的答题结果,采用Winsteps 3.72.3软件进行处理与分析。
(二)单维性假设与分析
单维性假设是Rasch模型的前提假设条件之一,是指只有一种潜在特质在决定性影响被试的答题反应,其余潜在特质对测试结果的影响可以被忽略。在一般测试中,组织者希望整套试卷只包含一个维度,即试卷测量被试的一个心理或能力特征,从而符合单维性检验。一般采用主成分分析法(principle components analysis,PCA)的解释率百分比来检验测评工具的单维性表现[12]。
词汇与语法部分的试题考查被试对英语词汇与语法的理解与运用能力。如果单维性假设检验成立,即可证明该套试题是针对被试的英语词汇与语法的理解与应用能力的考查,符合试卷的考查目标;否则,测试组织者需要对整套试题进行综合分析,针对特定项目进行进一步的修正与完善。
图1是通过运行Winsteps 3.72.3软件,在输出列表中选择item:dimensionality后生成的项目标准残差对比情况的截图。其中,横坐标ITEM MEASURE表示试题难度区间,纵坐标CONTRAST LOADING表示因子载荷,30个大小写字母分别对应30道试题。因子载荷为该试题与其他潜在测试影响因素的相关系数,其值在-0.5~0.5的范围内表示试题单维性较好,超出该范围则表示本次测试受到其他潜在的非英语能力影响因素的影响。由图1可知,30道试题的因子载荷全部在-0.5~0.5的范围内,说明本次测试的测量符合单维性,能够反映被测试学生的真实水平。因此,本套试题客观题部分总体上符合Rasch单维性假设,可以使用模型进行分析。
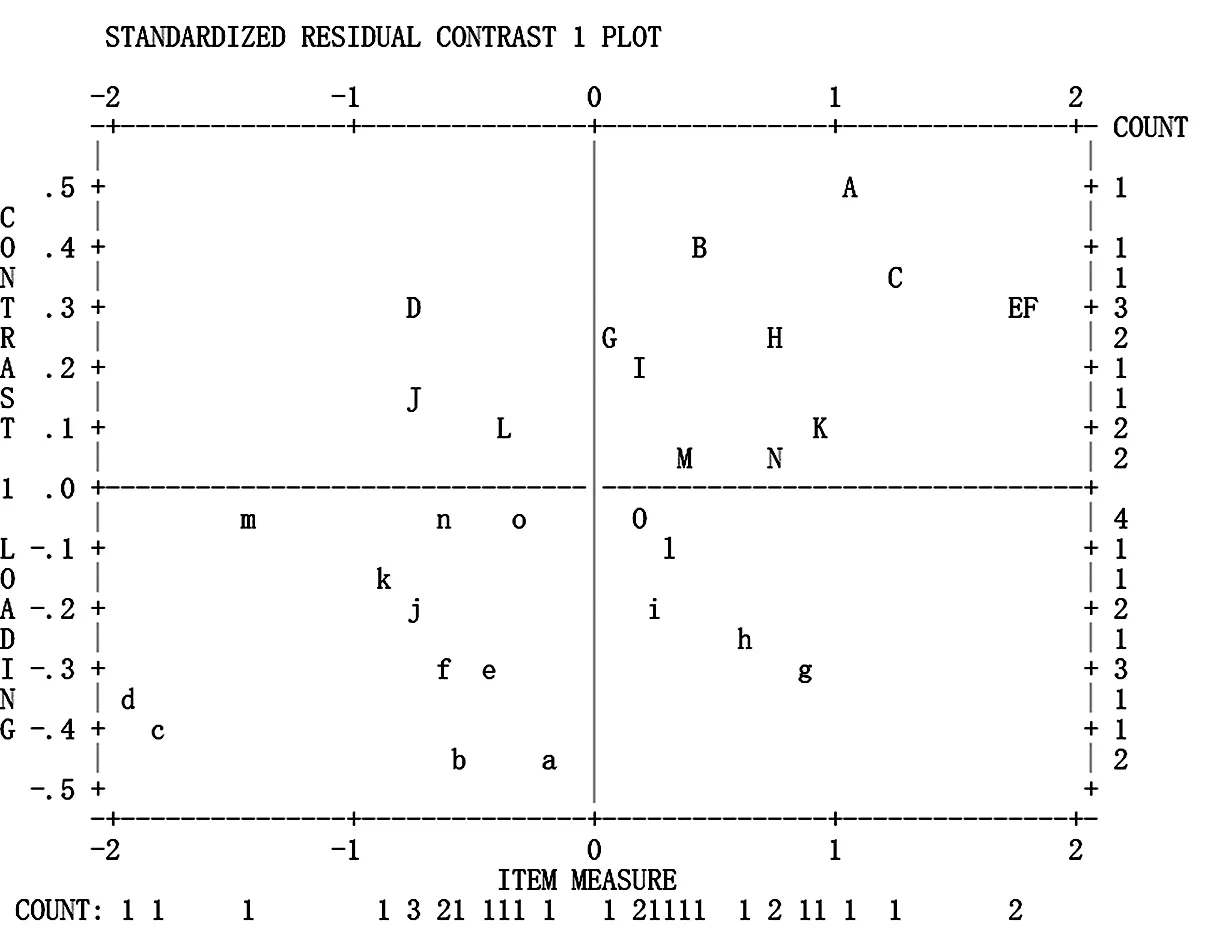
图1 项目标准残差对比
(三)试卷难度与学生能力水平分析
在进行试卷的试题质量分析之前,需要对试题整体难度分布与学生整体水平分布进行比较,分析试题能否较好地考查所有学生的能力水平,一般使用Rasch模型中的怀特图(item-person map,或称Wright map)进行比较和分析。Rasch指出,Rasch模型可以通过对原始数据进行对数转换,将被试的能力与试题的难度参数化[13],从而计算出被试的能力值与试题的难度值,并将其放置在同一个等距量表,即洛基量尺(logit scale)上进行比较,从而直观比较被试与被试间、被试与试题间、试题与试题间的差异,同时可以依据被试能力预测其在未实施试题中的表现。

图2 试题一学生关系怀特图
图2是通过运行Winsteps 3.72.3软件,在输出列表中选择item:map后生成的试题—学生关系怀特图的截图,从中可以看出学生能力水平与试题难度水平之间的关系。中间竖线为logit刻度尺,M代表均值,S代表与均值相差一个标准误的位置,T表示与均值相差两个标准误的位置。刻度尺左侧为学生能力水平分布,每个“#”代表6名被试,学生间的距离间隔表示学生间的水平差异;刻度尺右侧是试题难度水平分布,数字代表题目编号,试题间的距离间隔代表试题难度差异。怀特图自下而上,学生能力增高,试题难度增大。怀特图将试题分布均值设置为0,负分数代表试题比平均水平容易,正分数代表试题比平均水平难。总体来说,怀特图可以反映测评工具对于目标被试群体的适切度。
由图2可知,学生能力水平分布在-1.87~4.98个logit单位之间,跨度约为6.85个logit单位。学生的能力范围跨度较大,但仍主要集中在均值周围。试题的难度分布在-1.94~1.72个logit单位之间,跨度约为3.66个logit单位。编号为4238,4248,4236的题目难度较小,绝大部分被试的能力水平都超过这三道题的难度水平,对这三道题都能正确作答。总体来看,学生平均能力水平比试题平均难度水平高约0.5个logit单位,说明学生能力水平高于本次测试的试题难度水平。此外,观察图2还发现,怀特图中的试题分布出现了空白间隙,表明在对应水平范围内没有对应难度水平的题目相匹配,部分学生的能力水平未被准确测量。
从试题难度与学生水平的关系来看,试题难度均集中于中部,有相对较简单的题目,但缺乏高难度试题。试题难度可以对中等能力水平的学生作出较为准确的估计,但无法对高能力水平学生作出估计。从整体来看,学生能力水平高于本次测试试题的难度水平,即缺乏相应难度的试题对高水平学生进行区分。
四、试题拟合与误差分析
Rasch模型可以通过拟合度分析检验被试对于试题的作答情况与模型的预期相吻合的程度,即所收集到的实证数据必须满足模型规定的标准和结构,只有在相符的情况下,才能实现客观测量,后续分析得到的结果才具有实际价值。Wright等[14]曾指出,测评工具设计者应当利用拟合度指标来排查异常的试题和个体,找出可能造成影响的其他因素。在Rasch分析中,评估数据和模型的拟合程度通常采用两个指标,即加权的均方拟合统计量(information-weighted mean square fit statistic,简称Infit MnSq)和未加权的均方拟合统计量(unweighted mean square fit statistic,简称Outfit MnSq),这两个指标的理想值均为1。 Infit MnSq和Outfit MnSq值越接近1,说明数据与Rasch模型的拟合越理想。本研究中采用Linacre (2013)的标准,认为Infit MnSq和Outfit MnSq值在0.5~1.5之间时,数据和模型拟合较好。如果Infit MnSq和Outfit MnSq值大于1.5,则表明学生在作答题目时受到其他非考查目标因素的影响,例如猜测、抄袭等因素,导致作答方式与模型设定的方式不一致,即数据与模型不拟合;如果Infit MnSq和Outfit MnSq值小于0.5,则表明学生的作答结果差异太小或者题目不能区分学生之间能力水平的差异,即数据与模型过度拟合。
Bond等[15]认为,在Rasch模型分析中需要谨慎使用拟合指标,可以采用MnSq和ZSTD 值(standardized as a z-score,即Infit标准化Z值)共同考量试题与被试的拟合情况。当数据指标在模型拟合中出现不拟合和过度拟合的情况时,一般以Infit MnSq为准[16]。ZSTD 值为MnSq标准化的指标。若ZSTD 值大于2,表明能力高和能力低的个体在该题得分比例比模型预期的小,即能力高和能力低的个体都答对或答错;若ZSTD 值小于-2,表明个体在该题的得分比例比模型预期的大,即该题对能力高的被试过于简单,而对能力低的被试过于困难。本研究将Infit MnSq和Outfit MnSq值以及ZSTD 值结合起来作为拟合指标进行探讨分析。
图3是通过运行Winsteps 3.72.3软件,在输出列表中选择item:fit order后生成的试题拟合情况表的截图。由图3可知,Infit MnSq值在0.84~1.17之间,全部处于可接受范围内;Outfit MnSq在0.58~1.43之间,全部处于可接受范围内;ZSTD 值大部分处于-2~2之间,说明数据与模型的拟合较好,能够满足模型规定的标准和结构,在逐项分析具体的试题质量时,分析得到的结果具有实际价值,能够发现试题的潜在问题。
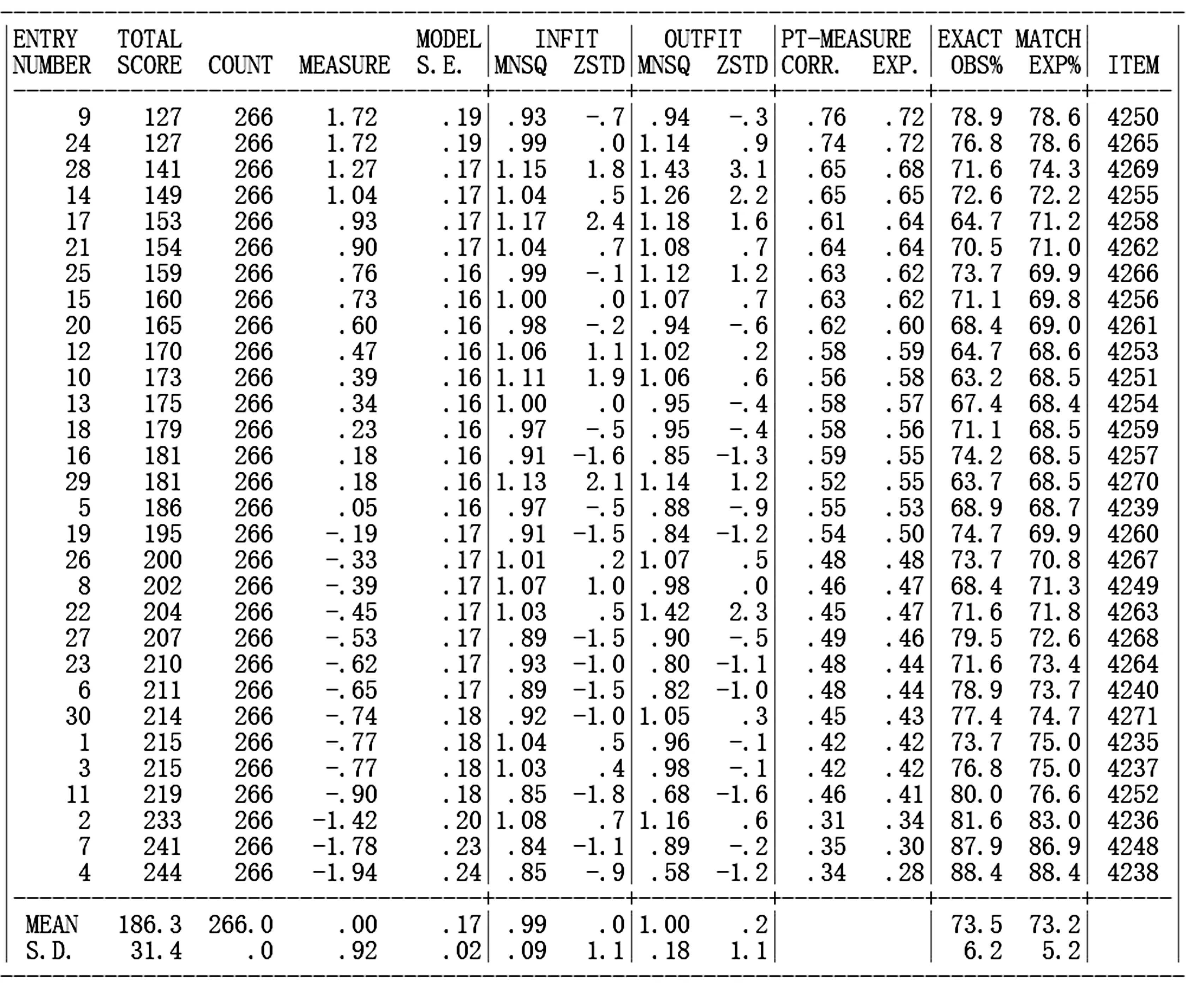
图3 试题拟合情况表截图
图3中的MODEL S.E.为Rasch模型标准误,表示依据题目的测量结果对学生能力进行估计时,估计结果的准确性。本研究中所有试题的标准误平均为0.17,结合图1分析可知,学生的能力水平高于题目的难度水平,试题在区分学生能力水平时存在一定误差,未能很好地区分高能力水平的学生。PT-MEASUR CORR(point-measure correlation)表示题总相关系数,即在测量学生能力时,某一道题的分值预期与测试总分之间的相关性,反映题目的区分效果,可接受范围为0~1。本研究中的题总相关系数在0.34~0.76之间,全部落在可接受范围内,说明整体上每道题目与测试的测量目标一致,且每道题都能够根据其对应难度区分出不同能力水平的学生,即区分度良好。EXACT MATCH表示观测数据与模型预测的匹配度。如果观测数据与模型预测的匹配度小于其期望值(OBS% 气泡图可以形象直观地展示试题的拟合度指标与难度估计的标准误差,有助于研究者快速确认质量相对较差的题目。气泡的大小表示误差的大小,气泡越大表示标准误差越大,气泡越小表示标准误差越小,测量结果越准确。当样本量在30~300之间时,ZSTD 值需要在-2~2的可接受范围内[17]。图4是通过运行Winsteps 3.72.3软件,在plots输出列表中选择bubble chart后生成的气泡图的截图。 图4 气泡图 图4中横坐标表示拟合指标Infit MnSq的ZSTD值,纵坐标表示试题难度值。由气泡图可知,所有题目的难度范围均在-1.94~1.72个logit之间。大多数气泡是重叠在一起的,难度集中于-1~1个logit单位间,说明大多数试题难度相近,高难度题目较少,中低难度的试题较多。ZSTD 值在-1.8~2.4之间,表示整体上试题与模型的拟合度较好,但有个别题目需要改进,如编号为4258和4270的题目。所有试题的标准误差偏大,试题间相差不大,说明整套试题对于学生能力的考查出现了一定偏差,其中气泡较大试题的编号分别是4236,4248和4238。 结合气泡图与试题拟合指标可知,编号为4250的试题是难度最高的题目,答出该题的学生人数较少,误差较大。编号为4236,4248和4238的试题是相对简单的题目,也是标准误差最大的题目,表明这些题目未能区分对应水平学生的能力,需要进一步完善修正。结合怀特图分析可知,试题误差整体偏大的原因是试题难度水平与学生能力水平匹配度不够,不能够做到区分不同能力水平的学生,但是考虑到一套试卷中加入不同难度的题目有利于区分出不同能力水平的学生,在进一步修订试题时,不能粗暴删减题目,而应该根据学生情况与考试要求作进一步修正。 成人学历教育英语课程考试的目的是划分出已经达到基础英语水平的学生。因此,在制定试卷时,应该侧重对学生英语基础知识的考查,试题难度不宜过高。图5和图6是通过运行Winsteps 3.72.3软件,在输出列表中选择summary statistics后生成的本次测试的试题及学生拟合总体情况的截图。图5为本次测试的试题统计量描述,MEASURE一列显示,试题平均难度(MEAN)为0,标准误差(S.D.)为0.92。试题难度值最大(MAX)为1.72,最小(MIN)为-1.94。图6中MEASURE一列显示,学生的平均能力值(MEAN)为0.51,标准误差(S.D.)为1.18,学生能力值最高(MAX)为3.73,最低(MIN)为-1.87。结合图5和图6以及怀特图分析可知,试题平均难度值为0,学生平均能力值为0.51,即本次测试的总体难度水平低于学生的能力水平,学生容易在测试中取得较好的成绩。 图5 试题拟合总体情况 综上所述,该次测试总体上能够反映学生真实英语能力水平,难度编排偏向简单,试题拟合较好,能够获得预期的测验效果。考虑到本次测试是成人高等学历教育英语测试,属于过关性测试,目的是检测学生是否达到要求的英语水平,在此基础上检测学生的真实能力水平,因此,试卷总体偏向简单化,缺乏难度大的题目是可以接受的。此外,仍有几个问题需要改进,即:个别题目的单维性指标接近临界值,意味着这些题目在测试学生英语能力的同时,也会受到其他因素影响;少数题目的拟合程度需要提升,如编号为4269和4238的题目。 本研究使用Rasch模型对成人高等学历教育英语考试部分试题进行质量分析,结果表明,Rasch模型能够很好地评估测试质量与被试情况。由Rasch模型的分析结果可知,本研究所选用试卷符合单维性,即试题仅受到被试英语词汇与语法相关能力的影响,整套试题能够涵盖大部分被试的水平,试题信度高,试题的模型拟合度好,能够测量出学生的真实英语水平。成人学历教育学位英语考试旨在测量学生的基础英语能力水平是否过关,不应包含难度水平较高的试题,而应集中于难度水平中等偏基础的试题,但在此基础上也应反映中高能力水平学生的真实能力,建议增加少量高难度水平的试题。 Rasch模型具有精确分析相同测验的不同考生之间能力水平的特性,据此应进一步对测验内容进行调整优化,形成具有针对性且完整的测验。受到成人高等学历教育考试所面向考生知识和能力水平以及时间、精力、考试态度等因素的影响,从考试数据来看,有部分考生没能完成测验。本研究仅采用能够完成全部试题的考生数据,因此,没有对未完成测试考生的能力水平进行分析,分析结果存在一定偏差。据此建议考试过程中应督促考生按照真实能力水平作答,且完整作答。 成人高等教育学历英语考试作为成人继续教育中的关键考试,需真实评估学生英语水平。同时,科技进步为成人继续教育提供了极大的便利,使用Rasch模型可以为检验和改进测验的准确、完整评价提供数据支撑。记录学习者不同阶段的知识水平并进行有针对性的辅导,可以帮助教师实现个性化教学。此外,可以依据拟合度挑选出质量优秀的题目,为优质题库建设积累素材。 本研究仍存在一些局限性:一是试题类型只涉及“0”“1”计分制的客观题;二是题目数量较少,虽然题目数量满足分析要求,但会使分析误差加大。未来的研究工作将从这些方面入手,进一步扩展测量模型,最终使研究结果具有更广泛的适用性。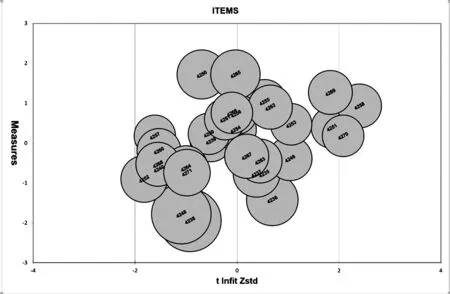
五、试题与学生能力

六、结论与建议
