基于互信息法的智能化运维系统入侵检测Spark实现
2022-03-23葛军凯张秀峰史令彬徐海宁
葛军凯,李 震,张秀峰,史令彬,徐海宁,韩 磊
(1.国网舟山供电公司,浙江 舟山 316000;2.哈尔滨工程大学机电工程学院,黑龙江 哈尔滨 150001)
0 引言
当前,网络应用技术与数据传输技术都获得了快速发展,人们逐渐进入大数据时代。尤其是随着智能化运维系统的不断推广,产生了大量数据,也因此形成了持续增加的数据维度。这就要求使用新的特征选择方式来满足高维度数据的需求[1-4]。现阶段,已有学者采用特征选择技术处理大规模数据,不过依然还有一定缺陷需要克服。在处理高维数据时,还需进一步开发更加高效的分布式特征选择技术[5-6]。
入侵检测是指对可能发生的未授权访问数据、操作信息与系统运行错误、不可靠、无法使用情况进行检测[7-8]。这属于主动防御的模式。入侵检测技正逐渐成为继防火墙防御之后的又一项关键防御技术。该方法从计算机网络关键节点进行参数收集,在保证网络正常运行的条件下,判断是否存在恶意攻击的情况,以此达到保护网络内部与外部环境的作用[9]。目前,已有许多研究人员针对大数据运行环境开发出了相应的机器学习库。Spark在内存中具备较强的计算性能,可以实现快速迭代的作用。这使得建立在Spark平台的开发算法被广泛应用于业界。虽然可以通过Spark平台实现机器学习算法与大数据分布处理相结合的技术,但将Spark与特征选择算法进行结合的文献报道则较少[10]。
1 本文方法
1.1 互信息算法
信息度量是指接收方在信息发送时已获得的信息数量,是通过预测学习的信息和分类输出特征实施关联来实现的。互信息(mutual information,MI)已成为信息论的一项重要信息度量,代表1个随机变量所包含的关于另一变量的信息量。
互信息计算式为:
I(A|B)=H(A)-H(A|B)=
(1)
式中:A与B为2个随机变量;p(a,b)为A与B组成的联合概率分布;p(a)与p(b)依次对应a与b边缘概率分布函数;H为特征当前集合。
MI可通过A、B、C这3个随机变量表示:
I(A,B|C)=H(A|C)-H(A|B,C)=
(2)
式中:C为第三个随机变量;p(c)为C的边缘概率分布函数;p(a,c)、p(b,c)与p(a,b,c)为联合概率分布。
互信息特征选择方法也属于Filter方法,需根据定量指标选择Filter特征。这使其成为一项相关性指标。通过评价此类特征相关性,可完成特征排序,同时选出相关性最大的要素。此外,对特征进行选择时,也可以选择更复杂的标准来实现特征排序,判断其冗余度是否比另一特征更大。以下是以互信息标准进行判断后丢弃的冗余特征。
(3)
式中:β为权重因子。
将惩罚比例加入冗余,其比例由所选特征和候选特征共同决定。
1.2 Spark实现
所有输入特征X和Y的相关性(即MI值)可以使用Spark计算框架中的broadcast功能计算。Spark实现计算相关性伪代码如下。
输入:DcRDD 的元组[index,(block,vector)],设置特征的数量。
输出:所有特征的MI值。
①ycol←Dc.lookup(yind)。
②bycol←broadcast(ycol)广播 Y的索引。
③counter←broadcast(getMaxByFeature(Dc)广播。
④H←getHistograns(Dc,yind,bycol,null,null)得到直方图。
⑤joint←getProportions(H,ni)计算联合概率分布。
⑥marginal←getProportions(aggregateByRow(joint),ni)计算边际概率。
⑦return(computeMutualInfo(H,yind,null)返回MI值。
2 试验设计及验证分析
UNSW-NB15数据集的单条记录总共含有49个特征。各特征对应的属性存在较大差异。由于特征数值变化较明显,需对数据作归一化处理,使不同维度特征值被限定在合适范围内,从而确保小范围特征不会被大范围特征所“覆盖”。
基于支持向量机(support vector machine,SVM)算法的入侵检测结果如表1所示。
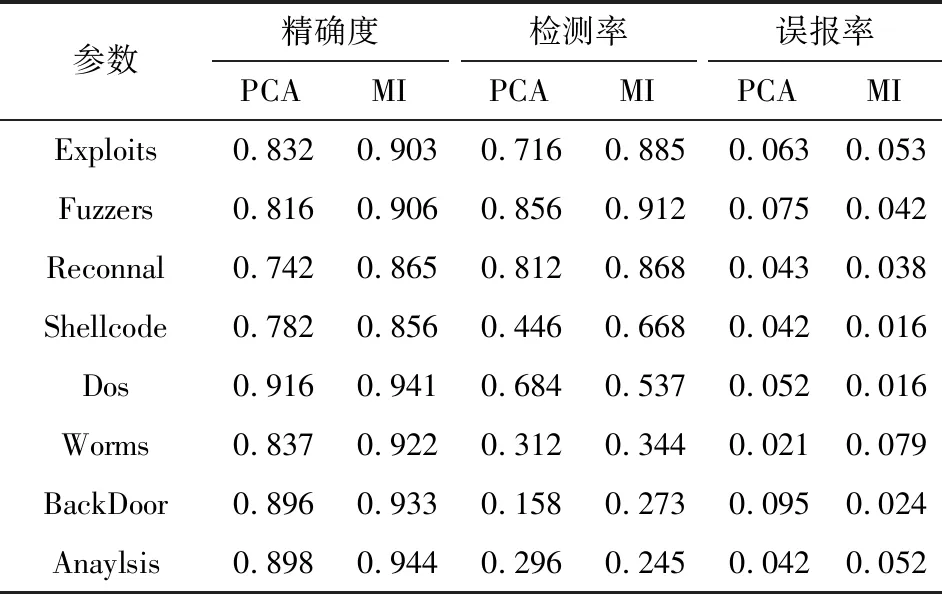
表1 基于SVM算法的入侵检测结果Tab.1 Intrusion detection results based on SVM algorithm
以Spark平台进行试验设计并完成测试。本试验采用HDFS存储数据集。为各个HDFS与Spark都设置一个主控制节点,以Hadoop的NameNode进行HDFS与DataNode控制。通过Spark主执行器实现对从节点的控制功能。Spark选择HDFS存储文件数据。
首先,把数据集分成训练集与测试集共两类。本试验将数据集的70%作为训练集,剩余30%作为测试集。然后,分别以主成分分析(principle component analysis,PCA)、MI算法在相同Spark平台上开展测试,并比较本文设计的分布式互信息算法;同时,依次选择不同类型的机器学习分类方法开展入侵检测。最后,选择具备高精度、误报率低的评价方法对本试验结果进行了评价。
试验以UNSW-NB15数据集作为测试对象。数据集总共包含了2 642 520条数据,依次对8种攻击参数实施检测。基于NaïveBayes算法和决策树算法的入侵检测结果分别如表2与表3所示。
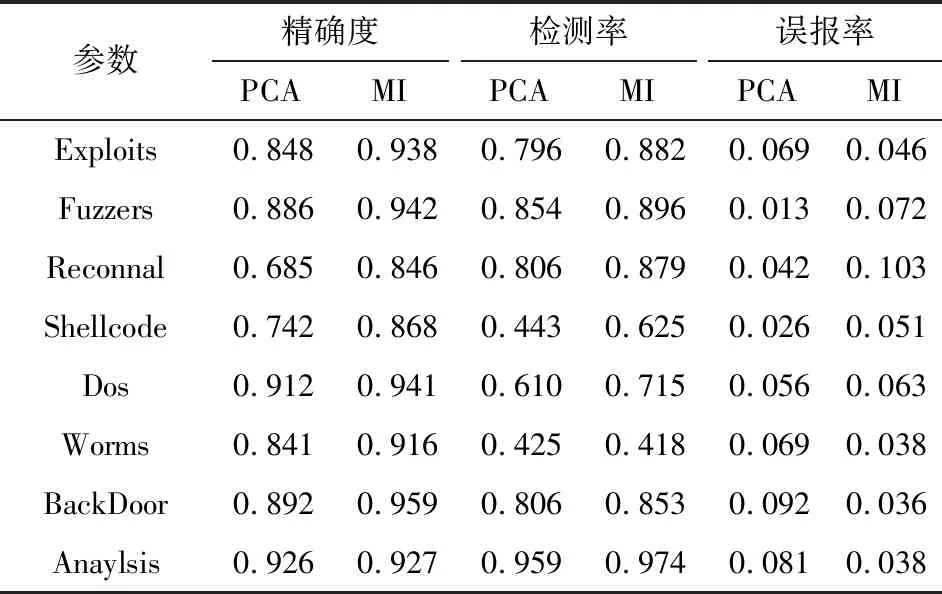
参数精确度PCAMI检测率PCAMI误报率PCAMIExploits0.8480.9380.7960.8820.0690.046Fuzzers0.8860.9420.8540.8960.0130.072Reconnal0.6850.8460.8060.8790.0420.103Shellcode0.7420.8680.4430.6250.0260.051Dos0.9120.9410.6100.7150.0560.063Worms0.8410.9160.4250.4180.0690.038BackDoor0.8920.9590.8060.8530.0920.036Anaylsis0.9260.9270.9590.9740.0810.038

表3 基于决策树算法的入侵检测结果Tab.3 Intrusion detection results based on decision tree algorithm
对测试数据进行分析可知,相对于PCA算法,MI算法可以获得更高的特征提取精度,提升了检测率,降低了误报率。因为Worms与Shellcode这2类攻击占总体攻击的比例很低,因此3种算法都表现出了对Worms与Shellcode的低检测率。对于总体攻击类型中占比最大的Generic类型,各算法都具备较高精确度与检测率。通过比较3种算法可知,决策树算法表现出了比其他2种算法更高的精确度。
PCA和MI的运行时间对比如表4所示。由表4可知,虽然MI具备较高精度,但也因此消耗较长时间。这是由于在Spark计算框架内构建分布式模型时需使用大量map与partition操作,从而在大量数据下形成了高达近万个分区,需要消耗大量时间。

表4 PCA和MI的运行时间对比Tab.4 Comparison of PCA and MI runtimes /min
运行时间与数据量的关系如图1所示。
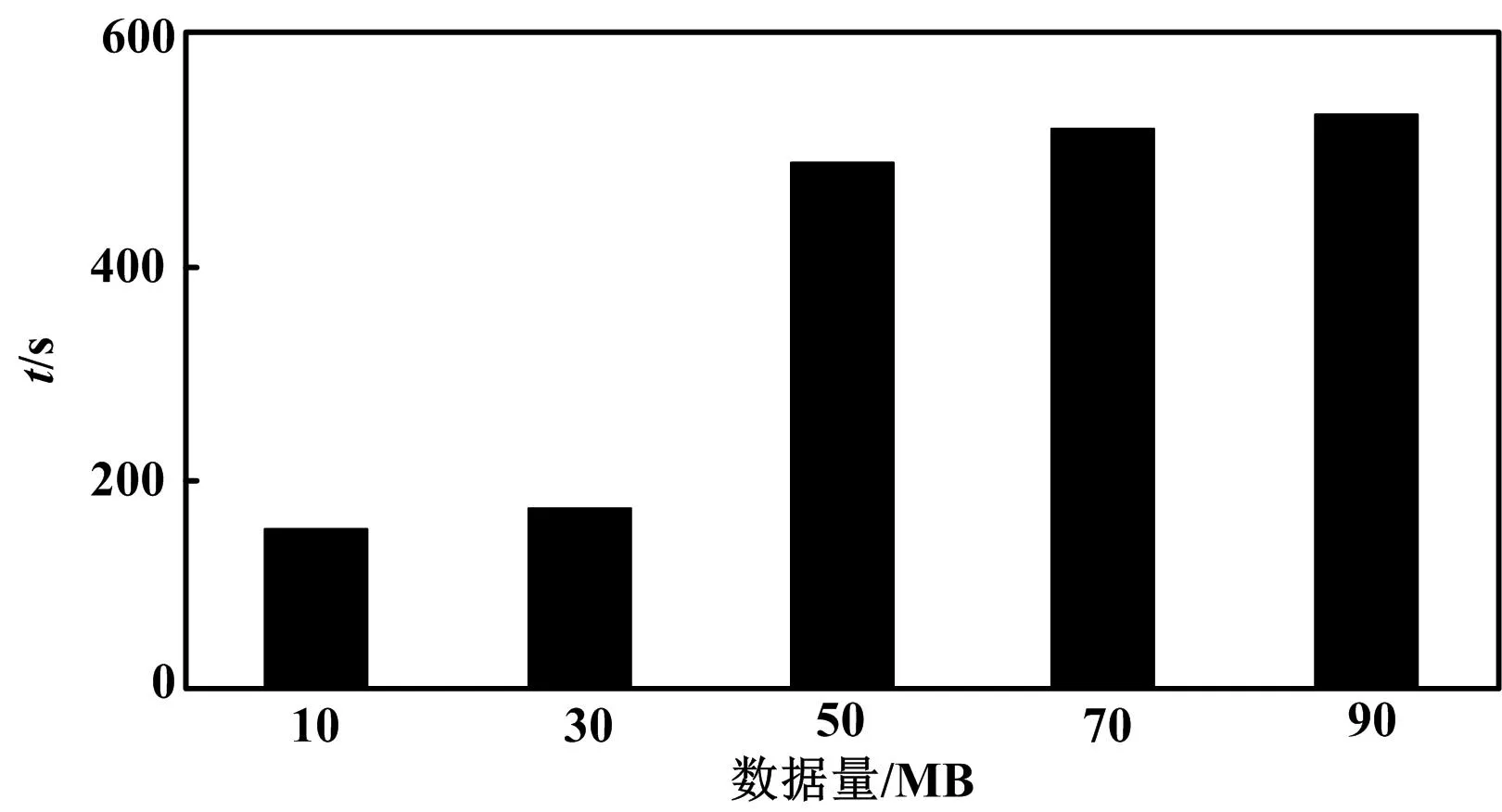
图1 运行时间与数据量的关系Fig.1 Relationship between running time and data volume
从图1中可以看出,随着数据量的增加,形成的运行时间消耗越多,尤其是在数据量30 MB之后增加明显。这是因为较多的数据量会增加模型分析的难度,甚至影响汽化能力。
3 结论
本文选取UNSW-NB15数据集,以Spark平台进行试验设计并完成测试,通过Spark主执行器实现对从节点的控制功能。相对于PCA算法,MI算法可以获得更高的特征提取精度,检测率也明显提升,降低了误报率。虽然MI算法具备较高精度,但也因此消耗较长时间。当数据量快速增加后,分布式模型表现出了更短的入侵检测时间。
