基于改进生成对抗网络的虚假数据注入攻击检测方法
2022-03-18夏云舒王勇周林樊汝森
夏云舒,王勇,周林,樊汝森
(1.上海电力大学计算机科学与技术学院,上海市 200120;2.国网上海电力公司青浦供电公司,上海市 201799)
0 引 言
随着智能电网建设的不断推进,传统电力系统与信息控制设备及通信传感网络深度融合,形成电力信息物理系统 (cyber physical system,CPS)。新型能源互联网含有高比例的分布式新能源,是一个大型的电力CPS,能更有效地发挥信息融合带来的优势,但也更容易遭受网络攻击[1]。网络攻击不仅会破坏信息系统的正常功能,还可能传导至物理系统,威胁电力系统的安全运行[2]。虚假数据注入攻击(false data injection attack,FDIA)是一种破坏电网信息完整性的网络攻击,它通过篡改电网量测数据,引起电网误动或拒动,是对电力系统威胁程度较高的攻击方式之一[3]。因此,研究如何提高FDIA检测率对于能源互联网安全运行有重要意义。
传统的FDIA检测方法主要基于状态估计。文献[4]使用自适应卡尔曼滤波对系统内部状态和噪声作出估计;文献[5]在掌握电网局部信息的情况下,针对单节点与多节点攻击场景提出一种基于非线性状态估计的模型;文献[6]提出了一种基于节点时间相关性的短期状态预测方法,通过计算实际得到的量测量与预测得到的量测量的一致性判断是否发生攻击。
随着能源互联网的建设与发展,量测数据的规模日益增长,传统FDIA检测方法逐渐难以应对。近年来,基于人工智能的FDIA 检测方法被提出,如支持向量回归[7]、卷积神经网络[8]、长短期记忆(long short-term memory,LSTM)网络[9]等。这类方法不需要预先获取电力系统的模型参数信息,有强大的计算能力,能够快速、大规模地检测攻击。然而,基于人工智能的FDIA检测方法存在严重的数据不平衡问题。由于FDIA发生的频率低,目前在真实电网中还没有捕获FDIA的实例[10],直接在不平衡的数据集上训练得到的算法性能较差[11],很可能造成误判。
目前解决数据不平衡问题的方法主要基于算法层面和数据层面[12]。前者对传统分类算法进行改进以提高算法对少数类样本的识别能力,如集成学习法、代价敏感法;后者通过数据欠采样、过采样等技术调整样本数据的分布。少类样本合成过采样技术(synthetic minority oversampling technique,SMOTE)通过线性插值在2个少数类样本间合成新的样本[13],是一种经典的数据过采样方法。但在面临不同类型的不平衡数据(如大数据、流数据、高维数据、数值型标签数据)时SMOTE方法还存在一些缺陷[14]。
生成对抗网络(generative adversarial network,GAN)能够学习复杂数据的概率分布并生成人工样本[15-16],已被应用于生成电网中不同类型的数据。文献[17]使用WGAN(Wasserstein GAN)生成电网量测数据,解决由于数据敏感,研究者难以获取真实可信数据的问题;文献[18]通过训练GAN生成FDIA攻击数据,达到在电力市场中获得经济利益的目的;文献[19]使用cGAN(conditional GAN)构建能够逃过电网不良数据检测机制的FDIA;文献[20]训练GAN学习电网正常运行场景下的量测数据分布,以恢复FDIA下电力CPS数据的完整性。
鉴于以上分析,若能训练GAN生成高质量的正常量测数据与FDIA攻击数据,对于解决电力CPS缺少真实数据、数据不平衡导致攻击检测率低等问题具有多重意义。为此,本文首先考虑GAN训练不稳定、模式崩塌等问题对生成数据质量的影响,设计结构更稳定的CTGAN(conditional tabular GAN);其次,考虑接入分布式能源后能源互联网各量测数据间的相互影响,使用Copula函数构建电力系统状态变量间的空间相关性;然后,使用改进的GAN对FDIA数据过采样,提出基于极端随机树(extremely randomized trees,ET)的FDIA检测模型,解决数据不平衡问题。此外,构建数据有效性指标,基于多个分类器的性能评估生成数据所包含的有效信息。最后,通过对比实验对所提方法进行验证。
1 相关技术原理
1.1 原始生成对抗网络
原始生成对抗网络由两个互相博弈的神经网络组成,分别为生成器(generator,G)与判别器(discriminator,D)。生成器负责生成新数据,判别器负责判断生成数据的好坏。在这个零和博弈的过程中,判别器旨在分辨真实数据与生成数据,生成器旨在生成足够真实的数据,使判别器无法准确分辨数据的真假,这2个网络同时训练,直到达到纳什平衡。GAN的目标函数如式(1)所示:
(1)
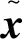
1.2 改进的生成对抗网络
原始GAN在设计之初主要用于生成图像样本,图像的像素值近似服从高斯分布。然而,许多表格类数据(tabular data)不服从高斯分布且存在多模态,直接使用原始GAN会遇到梯度消失、模式崩塌、不收敛等问题。为了增强原始GAN学习表格类数据的能力,并捕捉数据间的相关性,CopulaGAN将CTGAN与Copula函数结合[21-22],使用高斯Copula函数学习数据的概率分布,描述随机变量间的关联,并改进了原始GAN的网络结构和学习步骤。
Copula函数可用于描述随机变量间的非线性相关性,近年来受到广泛关注[23]。设电网量测数据中n维随机变量x=(x1,x2,…,xn),其中xk(k=1,2,…,n)的边缘分布函数为F(xk),令uk=F(uk),故uk为服从[0,1]间均匀分布的随机变量,则联合概率分布函数H(x)与Copula分布函数C(u)(u=(u1,u2,…,un))之间的关系如式(2)所示:
H(x)=H(x1,x2,…,xn)=C(u1,u2,…,un)=C(u)
(2)
对式(2)求导可得到对应的联合概率密度函数,如式(3)所示:
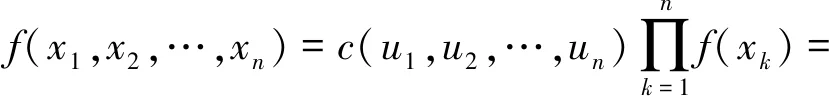
(3)
式中:f(x1,x2,…,xn)为联合概率密度分布;c(u)为n维Copula密度函数,表示相关性结构;f(xk)为xk的边缘概率密度函数。
1.3 极端随机树算法
随机森林(random forest,RF)是一种基于Bagging理论的集成学习算法,它不容易陷入过拟合,对噪声和异常值有较好的容忍性,对高维数据分类问题有良好的可扩展性和并行性[24]。
极端随机树是在随机森林的基础上改进得到的,具有更强的随机性[25]。在构成决策树时,它使用所有的训练样本,保证了训练样本的利用率;在划分节点时,它对分裂阈值设置进一步的随机,保证每颗决策树间的结构差异,减少过拟合。因此,使用极端随机树算法构建攻击检测分类器能够提高少数类样本的利用率,提升模型的泛化能力。
2 基于CopulaGAN的FDIA检测模型
基于CopulaGAN的FDIA检测框架如图1所示,由CopulaGAN模型训练、FDIA攻击检测、模型评估3部分组成。首先,通过CopulaGAN生成器与判别器的对抗训练,得到能够同时生成正常量测数据与攻击数据的数据增强模型;然后,使用该模型对FDIA数据过采样,得到平衡的攻击检测数据集,并使用极端随机树分类器进行攻击检测;最后,使用数据增强模型生成相同数目的正常量测数据与攻击数据,得到一个平衡的数据集。以该数据集为训练集,原始数据集为测试集构建多个分类器,利用分类器在测试集上的性能指标评估CopulaGAN模型生成数据的有效性。

图1 基于CopulaGAN的FDIA检测框架Fig.1 Structure of FDIA detection based on CopulaGAN method
2.1 CopulaGAN模型训练
步骤1:数据预处理。能源互联网作为一个整体,其中各量测值之间相互影响。采用单一GAN难以采集不同数据样本间的联系,生成的训练数据与实际电网数据具有较大差别。因此,通过对原始样本中的随机变量进行概率积分变换,使变换后的样本在服从高斯分布的基础上,仍保持数据间的相关性,根据变换后的样本生成接近真实电网的数据,使训练过程更加精确,具体步骤如下:
1)将原始电力CPS量测数据集分为训练集和测试集。
2)使用高斯Copula函数学习数据的概率分布,描述训练集中的n维随机变量间的关联关系并转换数据。
3)对转换后的数据进行归一化。对于离散值,使用独热编码处理;对于连续值,具体转换策略如下:
(1)使用变分高斯混合模型估计随机变量的模态个数,拟合得到高斯混合分布;
(2)计算数据在每个模态中的概率,得出概率密度函数;
(3)由给定的概率密度函数采样得到模态,并用此模态对数据进行归一化处理。
步骤2:GAN结构设计。首先,为了确保训练过程稳定、收敛快速,引入WGAN-GP(Wasserstein GAN with gradient penalty)[26]中梯度惩罚的概念,把Lipchitz限制作为一个正则项加到Wasserstein损失上,如式(4)所示:
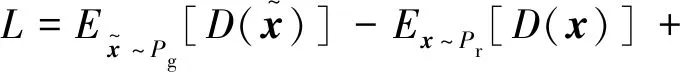
(4)

其次,为了捕获数据之间所有可能的关联关系,使用全连接网络。对于生成器,使用批标准化(batch normalization)和ReLU激活函数,标量值由tanh函数激活,离散值由softmax函数激活;判别器中,在每个隐藏层上使用leaky ReLU函数和dropout方法。此外,使用Adam优化器,设置生成器与判别器的学习率衰减率,衰减率为10-6。并采用打包生成对抗网络(packing GAN,PacGAN)[27]的方法,在将样本传递给判别器之前,将同一类别的n个样本(本文选取n=10)打包,使得判别器能够同时看见多个样本,从一定程度上防止模式崩塌。
步骤3:调整超参数。本文使用基于高斯Copula过程的贝叶斯优化方法[28]寻找GAN模型的最优超参数,设计相似性分数A为优化目标。贝叶斯优化在选择参数时考虑了选择的方向问题,可以缩短寻优时间,减少寻优过程的盲目性,基于Copula过程的贝叶斯优化方法把边缘参数变量变换为均匀分布参数变量,无需考虑参数的边缘分布,简化参数寻优过程。具体步骤如下:
1)对判别器和生成器进行交替对抗训练。
2)每训练得到一个模型,就生成一个包含相同数目正常运行数据和FDIA数据的数据集,并对该数据集进行反归一化处理。
3)使用K-S检验(Kolmogorov-Smirnov test)和KL散度(Kullback-Leibler divergence,KLD)计算数据集与训练集之间数据的相似性,得到相似性分数A。
4)以相似性分数A为目标,寻找模型的超参数。GAN生成的数据与原数据越接近,A越接近于1,以得分最高时获得的超参数作为CopulaGAN模型的最优超参数。
2.2 FDIA攻击检测
CopulaGAN模型捕捉样本间的关联性,生成大量攻击样本,使极端随机树分类器在提升少数类样本训练精度的同时选取更全面的特征来寻找全局最优的分裂属性,增强分类效果。具体步骤如下:
步骤1:数据过采样。使用CopulaGAN模型对训练集的FDIA数据过采样,得到平衡的训练集,用于攻击检测分类器的训练。
步骤2:构建极端随机树分类器。
1)基于CART决策树算法生成基分类器,随机有放回地从攻击检测数据集中抽取所有样本,作为基分类器的训练集。
2)随机地从训练集所有特征中选取m个特征,作为待选择特征库。以基尼指数或信息增益熵选择最优属性进行分裂,且分裂过程不剪枝,对分裂产生的子集进行进一步分裂直到生成一颗决策树。
3)重复2),得到由多颗决策树集成的极端随机树。
4)使用极端随机树识别测试集的量测数据是否被篡改。
步骤3:分类效果评价。使用混淆矩阵呈现分类器的预测结果,二分类算法检测FDIA得到的混淆矩阵如表1所示。

表1 二分类混淆矩阵Table 1 Confusion matrix for binary classification
算法性能的评估指标可通过混淆矩阵计算,如准确率(ηAccuracy)、查准率(ηPrecision)、查全率(ηRecall)以及查准率与查全率的调和平均值F1值(ηF1):
(5)
(6)
(7)
(8)
在检测FDIA时,相比于将正常运行样本预测为FDIA样本的误判情况,将FDIA样本预测为正常运行样本的漏检情况会导致更加严重的后果。因此,在预测结果准确率较高的情况下,算法的查全率越高,检测效果越好。
2.3 数据增强模型评估
CopulaGAN模型能够生成大量的正常运行量测数据和FDIA数据,通过调整模型的超参数可以确保模型生成的数据与原始数据相似,并以相似性分数A表示。然而,生成的数据不仅需要与原始数据有较高的相似性,还需要提供有效信息,使得分类器充分学习样本的特征,提高分类器的性能。
因此,本文设计数据有效性指标评估CopulaGAN模型生成数据的有效性,生成数据包含越多的有效信息,分类器的性能越好,具体步骤如下:
1)假设训练集中正常运行量测数据的样本数为q,使用CopulaGAN模型分别生成q个正常运行数据样本和q个FDIA数据样本作为模型评估的训练集。
2)使用多种经典机器学习算法构建多个攻击检测分类器,在训练集上训练,在原始测试集上测试。
3)以分类器的准确率、F1值为指标评估CopulaGAN模型生成数据所包含的有效信息。
3 算例分析
3.1 数据集描述
本文使用的数据集来源于密西西比州立大学和美国橡树岭国家实验室[29],包含6类不同程度FDIA攻击场景(场景0至5)、1类电力系统正常运行场景(场景6)。攻击者通过改变参数值(如电流、电压、序列分量等)模拟有效故障,使操作员误判电力系统的运行情况并误操作。算例选取这7类场景作为FDIA检测数据集,每条样本中包含4个同步相量量测单元(phasor measurement unit,PMU)量测得到的三相电压幅值、电压相角、电流幅值、电流相角。为保持数据分布的一致性、减少过拟合,按照6∶2∶2的比例使用分层采样法将数据集划分为训练集、验证集和测试集。表2记录了训练集中各类场景的具体情况。实验在Python3.8环境下完成。

表2 训练集中各类场景的具体描述Table 2 Description of the training set
3.2 数据增强模型训练与评估
使用基于高斯Copula过程的贝叶斯优化方法寻找GAN模型的最优超参数,以相似性分数A为优化目标,训练50轮,超参数优化结果如表3所示。

表3 模型超参数优化结果Table 3 Hyperparameters of the model
使用GAN模型分别生成7类场景的数据各3 524条,得到用于模型评估的平衡数据集,该数据集的相似性分数A如表4所示。

表4 生成数据的相似性分数Table 4 Similarity score of synthetic data
由表4可见,调参后,模型生成的正常运行数据得分均在0.85以上,FDIA数据得分均在0.88以上。由此可见,GAN可以作为一种数据增强方法,生成大量与原始数据相似的量测数据。
为了评估GAN数据增强模型,分别基于ET、RF、XGBoost集成学习算法在模型评估数据集上训练多个分类器,根据分类器在原始测试集上的准确率、F1值指标评估合成数据的有效性,结果如图2所示。
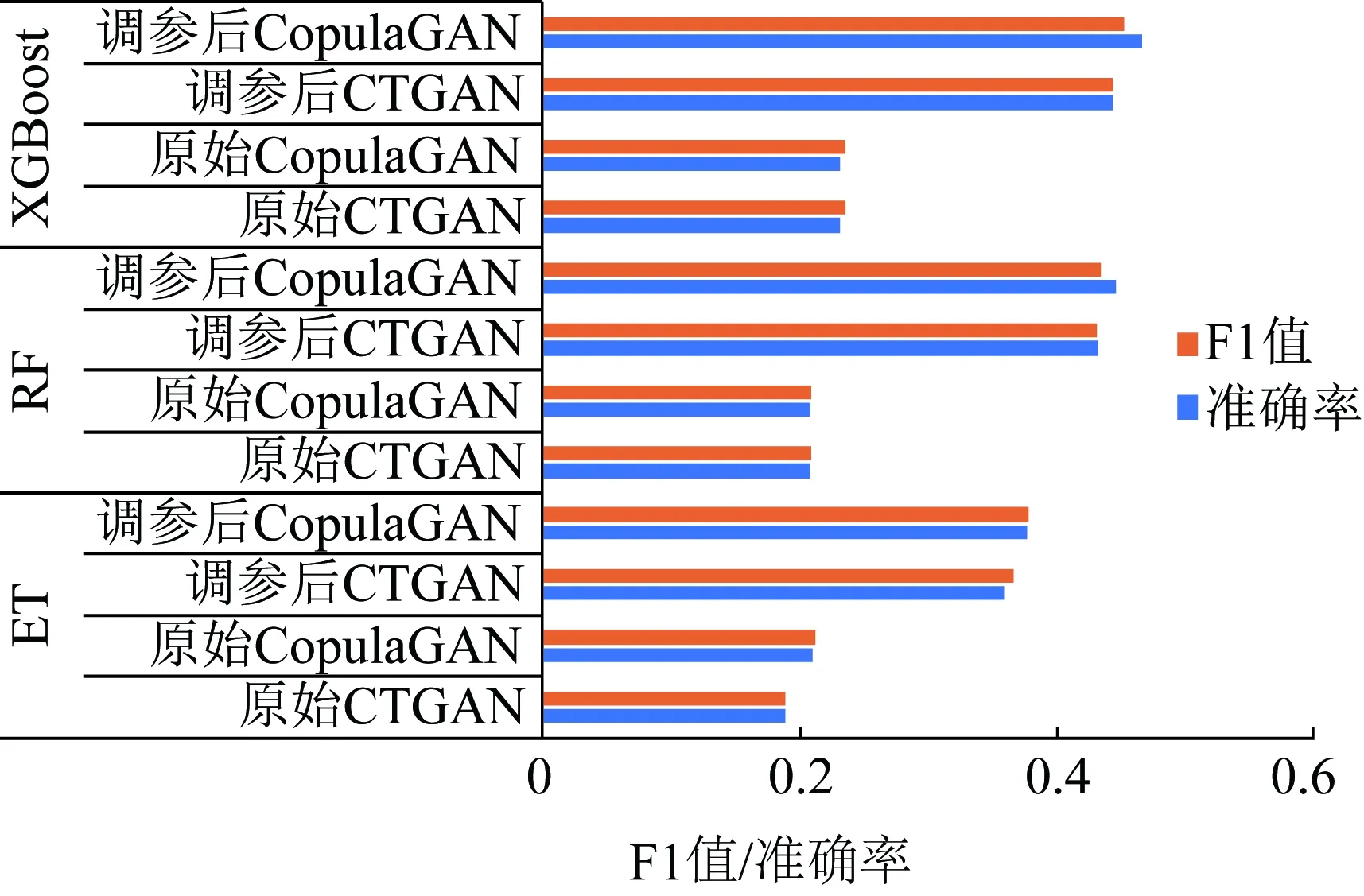
图2 生成数据的有效性评估Fig.2 Effectiveness evaluation of synthetic data
由图2可见,调参后的CopulaGAN提高了每个分类器的性能,这说明GAN模型生成的数据能够在分类器训练时提供有效信息,且CopulaGAN对算法性能的提升效果略高于CTGAN。
3.3 FDIA检测结果对比
在原始数据集上使用ET算法构建攻击检测分类器,与Adaboost、K邻近算法(k-nearest neighbors,KNN)、RF、XGBoost进行对比,算法的准确率如表5所示。

表5 各种算法在原始数据集上的准确率Table 5 Accuracy of algorithms on original dataset
由表5可见,ET算法的准确率达到93%,远高于其他机器学习算法,这是因为在训练的过程中ET算法充分使用了所有的训练样本,且在划分节点时保证了每颗决策树间的结构差异,提高了分类性能。
对FDIA攻击数据进行过采样得到平衡的训练集后,将编号为0至5的6类不同程度的FDIA重新编号为1,编号为6的正常运行数据重新编号为0,如图3所示,得到FDIA检测的混淆矩阵。

图3 FDIA检测混淆矩阵Fig.3 Confusion matrix of FDIA detection
分别使用调参后的GAN模型、随机过采样法(random over-sampling,ROS)、SMOTE方法对原始数据集中的FDIA攻击数据进行过采样得到平衡的训练集,使用ET算法构建攻击检测分类器,得到的准确率、查全率如表6所示。
由表6可见,相对于其他数据过采样方法,CopulaGAN模型提高了ET算法的准确率、查全率,减少了FDIA漏检的次数。本文提出的基于CopulaGAN-ET的检测方法对FDIA的检测率达到98.95%。

表6 各数据过采样方法下ET算法的性能Table 6 Performance of ET algorithm with diffrent oversampling methods
4 结 论
针对新型能源互联网中FDIA攻击检测的数据不平衡问题,本文提出一种基于改进生成对抗网络和极端随机树算法的攻击检测方法。在电力系统攻击数据集上进行实验,得到以下结论:
1)CopulaGAN模型能够合成质量较高的电力CPS正常量测数据与攻击数据,解决了现实中电力量测数据不足的问题。
2)相较于KNN、Adaboost、随机森林等经典机器学习算法,ET算法能够减少攻击检测分类器误判攻击的情况,有效提高FDIA检测的准确率。
3)相较于随机过采样、SMOTE方法,本文数据增强方法能够提高FDIA检测率,减少漏检事件的发生。
4)使用GAN时通常不需要定义规则或约束,便于推广应用于合成电力CPS中各种类型的数据。
未来,除了进一步提升GAN生成数据的精度,还可以研究GAN在新型能源互联网的数据隐私保护、数据压缩中的应用。
