面向配电网故障快速处理的边缘计算单元优化配置方法
2022-03-18潘思宇刘宝柱
潘思宇,刘宝柱
(华北电力大学电气与电子工程学院,北京市 102206)
0 引 言
配电网作为电力系统的“最后一公里”,直接影响用户的用电质量与安全。因此,快速准确的故障处理十分重要。传统配网故障处理中,各感知终端将信息全部上传至主站集中处理并决策。但随着能源互联网建设不断推进,传统集中式故障处理模式已无法满足配网转型发展的要求[1],主要表现在:1)带宽不足,各类监测点、终端数量激增,现有通信带宽已无法支撑海量数据的传输存储需求[2];2)实时性不够,集中式故障处理将数据上传至主站,再请求处理,加之网络问题,系统延迟大,实时性和用电质量下降,还可能引发安全隐患,后果严重[3];3)准确度降低,信息数量大、类型多、传输距离长、速度慢等不稳定因素[4],导致了信息传输中的漏报、误报等问题,严重威胁故障处理准确度。
为此,学者们引入了边缘计算技术。边缘计算是指在靠近物或数据源头的网络边缘侧,就近提供边缘智能服务。将该技术应用于配网中,集中式故障处理转换为在边缘层分布式故障处理,实现系统层面的优化,提高故障处理速度,降低主站通信和计算压力。
现有较多将边缘计算应用于配网中的研究。国家电网有限公司在《配电物联网技术发展白皮书》中提出 “统一硬件平台+边缘操作系统+APP业务应用软件”的边缘层技术架构。文献[5]提出了“云管边端”架构,初步探讨了边缘的定位与发展方向,以配电终端单元(distribution terminal unit,DTU)、馈线远方终端单元(feeder terminal unit,FTU)等为边缘。文献[6]提出基于边缘计算的主动配电网分组传送网(packet transport network,PTN)物理架构模型,将配网分为核心设备、边缘汇聚接入设备及终端边缘设备,以本地能源交换机/汇聚交换机为边缘。还有学者提出主站-电网边缘-用户边缘-配电终端的四层架构,基于稳定连接概念划分边缘,但未明确边缘设备[7]。上述研究大多在架构设计层面做出设想和讨论,边缘计算单元的数目、分布、设备配置类型、配置方法、相关指标的选取方法及量化方法等尚不明确[8]。
基于此,本文首先介绍边缘计算应用于实际配网故障处理的系统架构和工作机制,并为边缘设备选择提供方向。其次,综合考虑电网线路实际物理拓扑结构、通信实时性、通信可靠性、电气可靠性、边缘中心选址、边缘设备选型及相关经济性指标等,将边缘计算单元配置转化为最优分区规划问题,以通信实时性和经济性为目标函数,通信和电气可靠性为约束,结合目标规划、Lingo求解器、Multistart算法等求解最优边缘数。进一步地,基于谱聚类和k-means算法划分边缘管辖范围并确定边缘节点中心位置,结合均衡性、实际要求等修正分区。最后以IEEE 33和IEEE 69节点系统为算例验证本文方法,Matlab/Simulink仿真表明:相较于传统集中式方法,本文方法能够提升故障处理速度3~10倍。
1 应用于配电网故障处理的边缘计算架构
1.1 体系架构
边缘计算是在网络边缘执行计算操作的一种新型计算模型,计算云服务的下行数据和来自于万物互联服务端的上行数据[9-10]。应用于配网中,将故障处理从主站集中式变为边缘层分布式处理,且与主站协同配合,互为后备。但不同于以往的分层分区控制,边缘计算架构的分区是为了保障边缘计算单元的均衡和处理效率,不同分区内故障处理是并行进行且相互独立的,此外每个边缘不仅能实现单一目标函数的计算,更能实现完整的故障处理流程,包括信息收发、数据计算分析、决策和命令等。其体系架构如图1所示,包括感知层、通信网络层、边缘层和云平台层。感知层为各类终端,作用是采集信息上传至边缘和云层,执行命令等;通信网络层为本地和远程通信网,高效可靠地传输信息;边缘层是承担部分主站功能的边缘节点及计算设备,实时快速地处理故障,周期性地将故障记录上传至云层[11],与云层高效协同且受其调度;云层是配电主站,全局性、长周期地分析数据和决策。

图1 边缘计算体系架构Fig.1 Architecture of edge computing
边缘计算实现分布式故障处理的工作策略如图2所示。将边缘及其管辖终端范围视为一个分区,则配网被划分为不同区域。不同边缘计算中心、区内终端与边缘计算中心均通信相连。边缘层可自主控制决策或协商后决策,受主站调度。故障发生时,终端只需上传信息到对应边缘分析计算、决策切除故障。
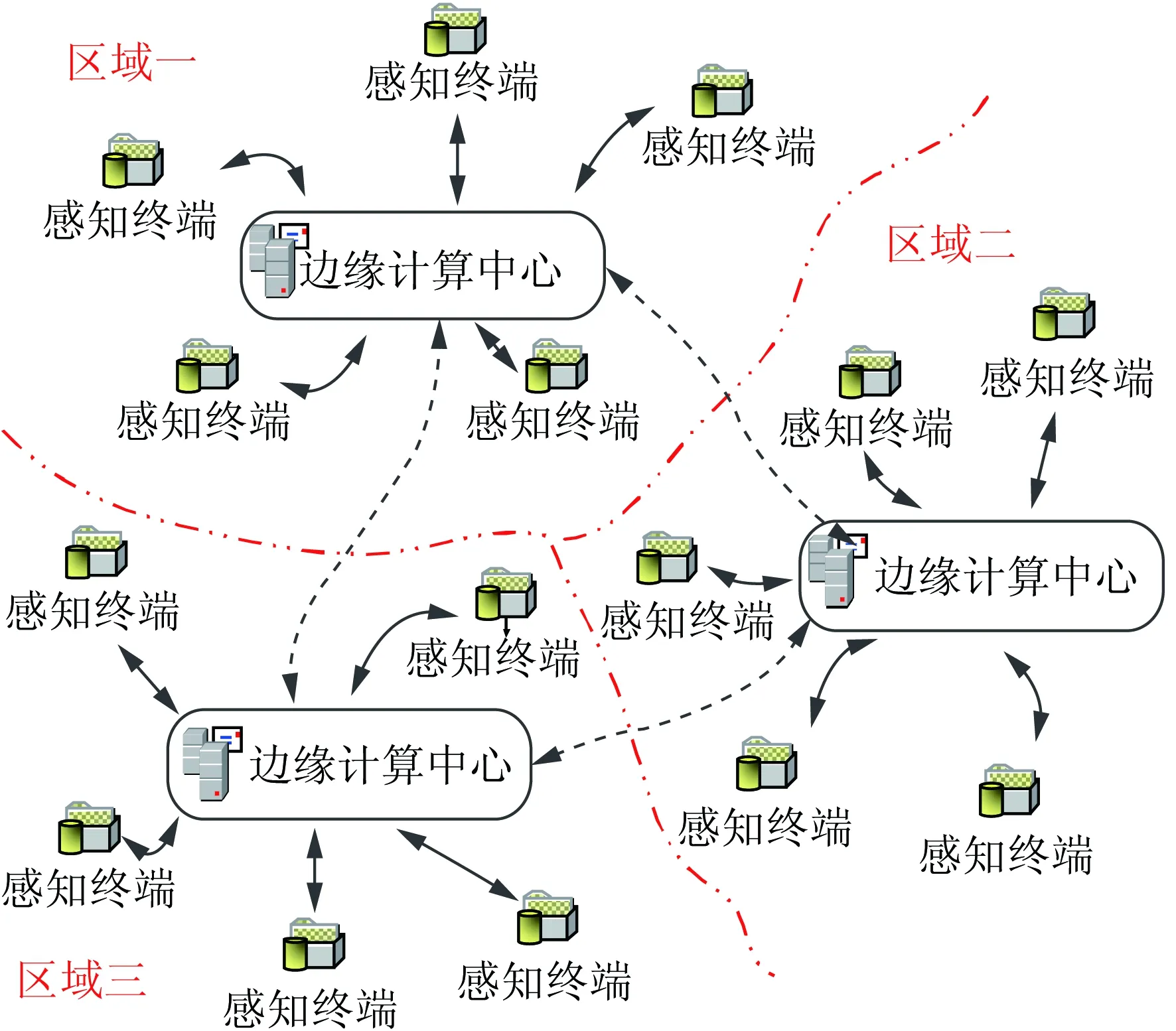
图2 边缘计算工作策略Fig.2 Working strategy of edge computing
此外,主站与边缘计算机制互为备用。为终端设置时延约定,若超过时延终端仍检测到故障信号故障未处理,则判定边缘故障,终端重新上传信息给主站处理。如此主站便作为边缘失效的后备保障。
1.2 边缘计算设备
边缘计算中,终端、云计算等方面的研究都较为成熟,但对于边缘如何充分实现主站数据分析、计算等功能尚不明确,边缘计算设备的选择亟待解决。文献[4]将DTU、FTU等作为边缘计算设备汇聚信息、分析决策。还有研究视DTU、FTU等为终端,选择本地能源交换机、汇聚交换机等汇聚/接入设备为边缘设备[5]。上述设想相差较多,且还未经过实践验证能否满足实际需求。
本文从边缘计算设备所需实现功能入手,即区内自治和区间交互功能。区内自治指管辖范围内,边缘与终端通信并进行计算决策,最终切除故障;区间交互指边缘与边缘、主站间进行故障信息、调度需求等交互。对比考察各类设备性能,未来可以FTU为基础,结合虚拟化技术、容器技术[12]等新兴技术实现终端边缘节点化。此外,可利用机器学习方法建立故障定位、预测等模型特征,边缘层通过存储模型,与实时信息对比相似度即可快速准确地定位和预测故障。这样仅需在原有硬件基础上完善软件技术,实现已有系统向未来边缘计算体系的快速平滑过渡,减少建设成本和周期,相对多地提升系统效益。
2 构造分区数学模型
2.1 配电网边缘计算单元配置方法
应用边缘计算时,合理配置边缘计算单元,快速处理故障是首要任务。不同于大多研究仅在理论层面提出设想,本文结合实际,将终端视为通信节点,将边缘及其管辖的终端视为一个分区,因此边缘计算单元配置转化为最优分区问题,求解边缘数等同于求解分区数,下文均以分区数k表示,划分边缘管辖范围即为分区问题。考虑到边缘计算设备基于实时Linux操作系统等软件进行故障处理,可实现毫秒级以上的信息处理速度,在分区过程中就不再重点考虑这一指标。
首先以通信实时性、经济性为目标函数,以通信、电气可靠性和实际要求作约束,构建数学模型求取最优分区数k(即本章内容)。再利用谱聚类和k-means算法划分边缘管辖范围即分区情况,根据通信实时性、带宽要求、均衡性等修正分区、选择边缘计算中心节点(具体内容在第3节详细介绍)。总体流程如图3所示。
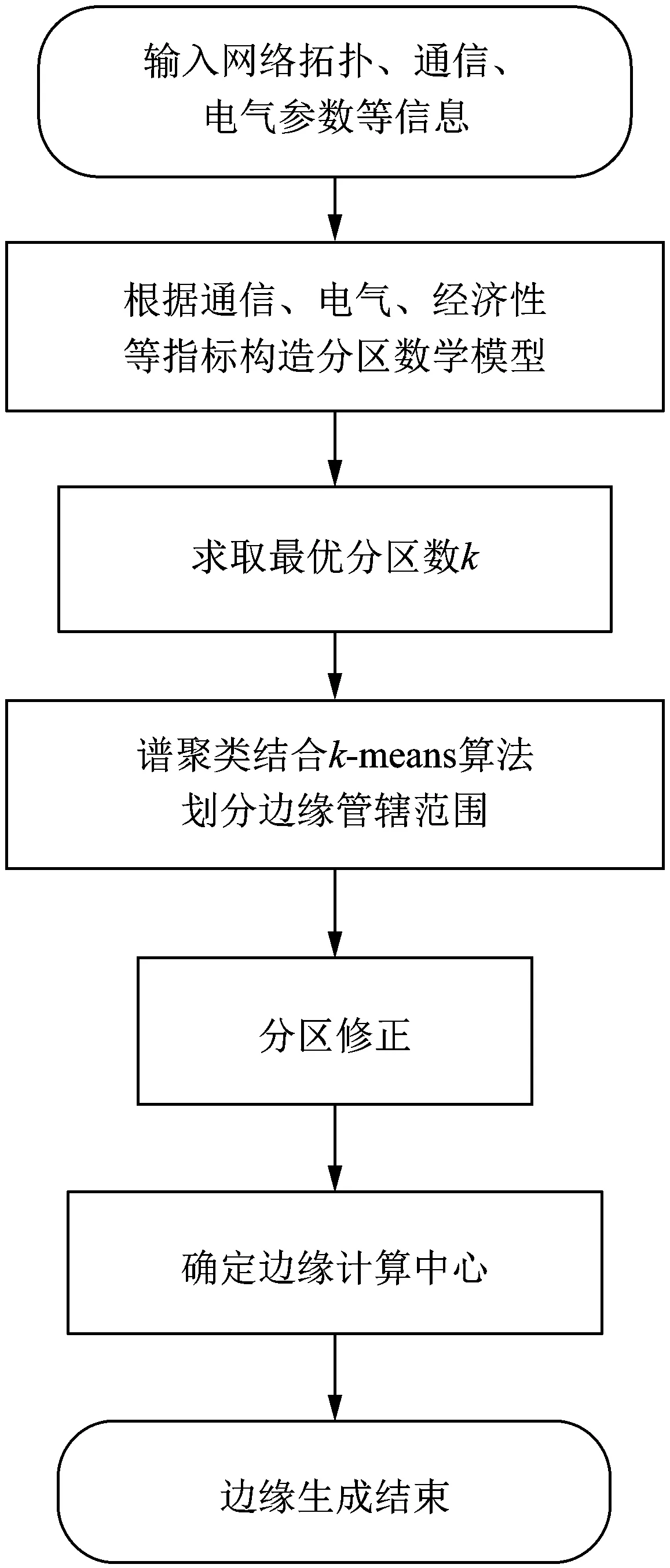
图3 边缘生成流程Fig.3 Edge generation process
2.2 分区评价指标与约束条件
求取最优分区数k时,本文选用通信实时性和经济性指标共同构成目标函数,以通信可靠性和电气可靠性作为约束条件求解。
2.2.1 分区评价指标
1)通信实时性指标。
就边缘层而言,核心任务是快速可靠地切除故障,需考虑通信实时性。分区数k越多,边缘管辖终端数量和范围越小,通信时间越短,通信实时性越好,故障处理速度越快。因此,选取通信时延T为通信实时性指标,可由下式计算[13]:
T=Ts+Tb+Tp+Tr
(1)
(2)
(3)
(4)
式中:Ts为数据发送时间;Tb为数据发送时间间隔,相对较小,一般忽略为0;Tp为数据传输时间;Tr为路由时延;P为数据大小;vn为通信网数据传输速率;L为信道长度;vm为信道数据传输速率;h为路由器数目;λ为数据平均到达速率;μ为路由服务效率。
求最优分区数k时,本文用L表征单个区域内平均通信长度,大致反映区域覆盖半径大小,利用平均的思想,L由式(5)计算:
(5)
(6)
(7)
式中:N为终端总数;¯l为系统内终端连接的平均路径长度;lil为第i个终端连接的第l条路径长度;ri为节点i的连接度;li为第i个终端连接的平均路径长度。
由式(1)—(7)得到通信时延T如式(18)所示:
(8)
2)经济性指标。
考虑通信实时性的同时,还需兼顾增设边缘的经济性。经济成本W可由式(9)计算得到:
W=We+Wn
(9)
式中:We为边缘设备如网关或引入新技术等的投资运维费用;Wn为通信网的建设运维费用。We与分区数k即边缘数目成正比,如式(10)所示:
We=kw
(10)
式中:w为增设一个边缘所需成本。对于Wn,通信信道多沿电力线路架设,规模、数量都与电力线路保持一致,因此电网建设完毕后,其费用固定不变。可得:
W=kw+Wn
(11)
2.2.2 约束条件
1)通信可靠性。
边缘计算提升故障处理速度时,也要确保稳定可靠地传输信息。通信可靠性指标包括丢包率、延时、延时抖动、突发处理能力等。考虑到配网信息上传频繁,为降低成本,语音视频信息极少,因此对延时抖动等要求不高。再结合通信服务质量指标[14],本文选取延时和丢包率指标为通信可靠性约束。
记网关服务效率ρ=λ/μ,延时TS和丢包率Ploss可由式(12)、(13)表示:
(12)
(13)
(14)
式中:Ls是节点缓存队列排队长度;λe是数据实际到达速率;K为节点缓存队列上限,本文取K=λ·CT,CT为最大时延;λa为一个终端上传数据速率;m为跳数;K、CT、λa、m为常数;λ为数据平均到达速率;m为路由服务效率;取μ约等于带宽值常数B;nmax为单个分区内可容纳终端最大个数。
根据实际系统要求¯Ts、¯Ploss及式(12)—(13)可求得ρ和数据平均到达速率λ的取值范围,再由式(14)求得nmax及分区数k的取值范围。
2)电气可靠性。
求分区数k时,也要满足电气可靠性指标。随着k增加,边缘增加,系统各节点故障处理速度与可靠性提高,且多个边缘失效概率低于主站失效概率,可视为停电时间减少。本文选取系统平均停电时间为电气可靠性指标,根据节点原始停电时间数据及边缘失效概率计算系统平均停电时间:tSAIDI=(∑负荷点停电时间×用户数)÷系统总用户数。
2.3 构造分区函数F(k)
首先对通信实时性和经济性指标归一化处理,如式(15)所示,再构建数学模型,如式(16)所示:
(15)
(16)
式中:T′、W′为归一化后的通信和经济性指标;Tmin、Wmax对应分区数k最多时通信时间T的最小值和经济成本W的最大值;Tmax、Wmin分别对应k最小时T的最大值和W的最小值;ω1、ω2为权重系数,对应经济性、通信实时性的重要程度,可根据实际及层次分析法求得;¯Ts、¯Ploss、¯tSAIDI为实际系统要求的数据发送时间、丢包率、平均停电时间。
2.4 求解最优分区数k
最优分区数k即为求解上文非线性模型获得的综合均衡经济性和通信实时性且满足电气、通信可靠性约束的的最优解,文中利用Lingo求解器编程求解,调用Multistart算法求取最优解及变化趋势。可求得理论最优分区数解k0,满足:k
求出理论最优分区数后,可根据实际工程对通信实时性和经济性要求调整k取值。若实际工程看重通信实时性即故障处理速度,可在满足通信、电气可靠性约束的前提下忽略经济性,选择最大k值,满足故障处理速度最快。若更看重经济性,只要求满足基本通信时延即可,可根据实际允许最长时延tm来调整k的取值。令T≤tm得到k≥k1。当k≥k1时,通信时延满足,但经济性随着k增加变差,因此选择k1作为最优分区数解。
3 边缘管辖区域划分
确定分区数后,应划分边缘管辖范围。现有研究对边缘划分方法尚不明确,文献[5-6]以设备代替边缘,并未指出边缘管辖范围,还有学者基于稳定连接概念划分边缘[7],但未讨论如何落实。
为充分考虑配网拓扑结构、地理位置关系及节点连接度等,且尽量使区内终端联系较紧密,距离对应边缘较近,本文选择谱聚类结合k-means算法分区。谱聚类算法性能较优,适用范围广且能在任意形状样本空间实现并收敛,获得全局最优解。
3.1 谱聚类算法
谱聚类对配网Laplace矩阵的特征向量进行聚类实现社团发现。当网络社团结构较明显、分区较简单时,仅根据网络第一小非平凡特征向量或增加特征向量维数如第一和第二小非平凡特征向量,即可分区[15]。但对复杂的配电网远远不够,还需结合k-means算法分区。具体流程如下:
1)根据配网结构求出Laplace矩阵L;
2)求L特征值及特征向量,按照大小排序;
3)若特征值中有一个零特征值判断网路连通进行下一步,若有多个零特征值则根据其特征向量确定节点的分区情况;
4)第一、第二小非平凡特征向量结合k-means算法聚类,划分分区即边缘管辖范围。
3.2 边缘计算中心选择
分区后,需要选择节点作为边缘计算中心,本文主要根据以下原则选择:
1)优先考虑连接度较高、路径关联紧密的枢纽节点;
2)优先考虑位于区域几何地理位置中心的节点,可借鉴谱聚类的聚类中心;
3)优先考虑靠近通信负担重、关键负荷的节点,如更靠近分布式电源或联络开关的节点。
3.3 分区方法灵活性
考虑配网结构灵活多变的特点,对本文分区方法灵活性进行以下讨论。
含分布式电源时,配网增加了发电、储能和输电等任务,通信计算压力更大,且风电等新能源变化迅速且无规律性,故障处理、调度等实时性要求更高,因此更适合本文方法。此外,针对其计算负担重、要求高且十分重要的特点,可选择更靠近分布式电源的节点为边缘节点。
在供电方面,以IEEE 33节点系统开断24、28节点间联络开关为例。首先,原分区方法和通信信道仍可正常通信和处理故障;其次,闭合联络开关重新分区如图4所示,分区结果差别较小,仅23、24节点分区变化;最后,联络开关闭合情况较少,断开联络开关的正常网络状态是主要运行状态,据此选择最合适的分区是较合理的。其他情况如电力线故障或环网等讨论同上,因此本方法具备一定的灵活性。
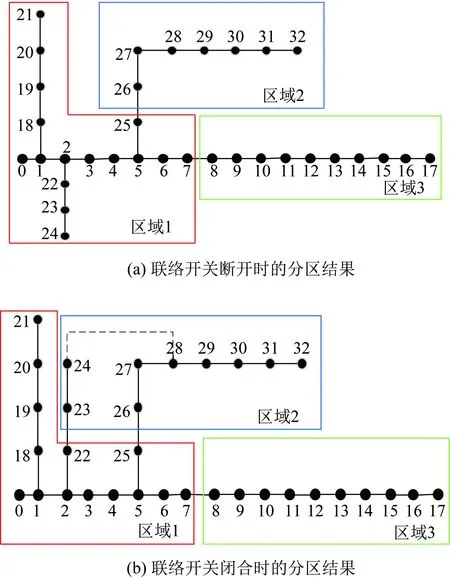
图4 开、断24-28联络开关分区情况对比Fig.4 Zoning comparison when 24-28 liaison switch open and closed
3.4 分区修正
考虑到电网的特殊性和实际情况,本文对分区结果进一步修正,重新规划部分节点。
1)基于通信考虑的分区修正。
首先计算各终端到对应边缘的通信时间,是否满足实际系统允许最长通信时延,不满足则重新规划该节点分区。其次,结合终端通信流量、并发比例等估算通信占用带宽,控制带宽利用率在额定范围内,一般要求小于等于70%。带宽利用率=(∑不同类型终端通信流量×感知终端数量)÷系统带宽。
2)基于分区均衡性的分区修正。
分区规模的均衡性也十分重要。若不同分区终端数目相差大,不同边缘的计算、通信任务也相差较多,计算负担分配失衡,一是会影响后续故障处理的速度;二是会使设备使用寿命相差较大,造成浪费。
本文选用样本标准差S来评价分区方案均衡性,S越小,代表均衡性越好,S可由式(17)计算:
(17)
式中:ni为第i个分区内终端的数目;nave为系统内平均每个分区内的终端数目。
3)基于系统结构的分区修正。
从系统结构出发,尽量使同一馈线上的终端位于同一分区,更便于后续故障处理。此外,从系统经济性出发,可根据实际生产需要中计算精度、速度和重要程度的不同选择不同分区方案。
4 算例分析
4.1 参数设置
本文以IEEE 33节点和IEEE 69节点系统为例,通过Matlab仿真,验证本文方法的可行性并证明方法能够提升故障处理速度。将各终端视为通信节点,为了充分考虑各种情况,假设每条线路上均配有终端,线路长度由已知参数换算得到。通信参数设置为p=200 Byte、vn=155 Mbit/s、vm=5 ms/km、μ=50 Mbit、λ=50 packets/s、Ts≤30 ms、Ploss≤10-6等[14,16-18]。
4.2 分区结果
1)IEEE 33节点系统。
根据2.3节内容将模型用计算机语言写入Lingo求解器,调用Multistart求解程序,经过33次迭代,可得IEEE 33节点系统的理论最优分区数为5。k取5时,F(k)最小,通信实时性与经济性综合最优。结合实际,k≥3即满足系统通信要求和电气、通信可靠性约束,即分区数可以选择3、4、5。考虑经济成本,本文选择经济性最优的分区数为3,将系统划为3个分区。
求解IEEE 33节点系统的Laplace矩阵。再利用谱聚类和k-means算法,得到聚类及分区结果如图5、6所示。图5中红色、绿色、蓝色节点分别对应图6中的同色区域1、2、3。
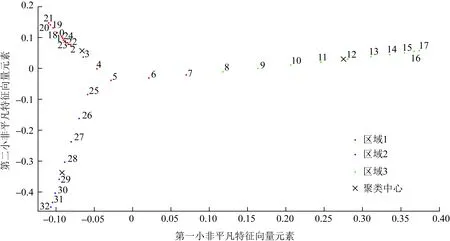
图5 IEEE 33节点系统聚类结果Fig.5 Clustering results of IEEE 33-node system
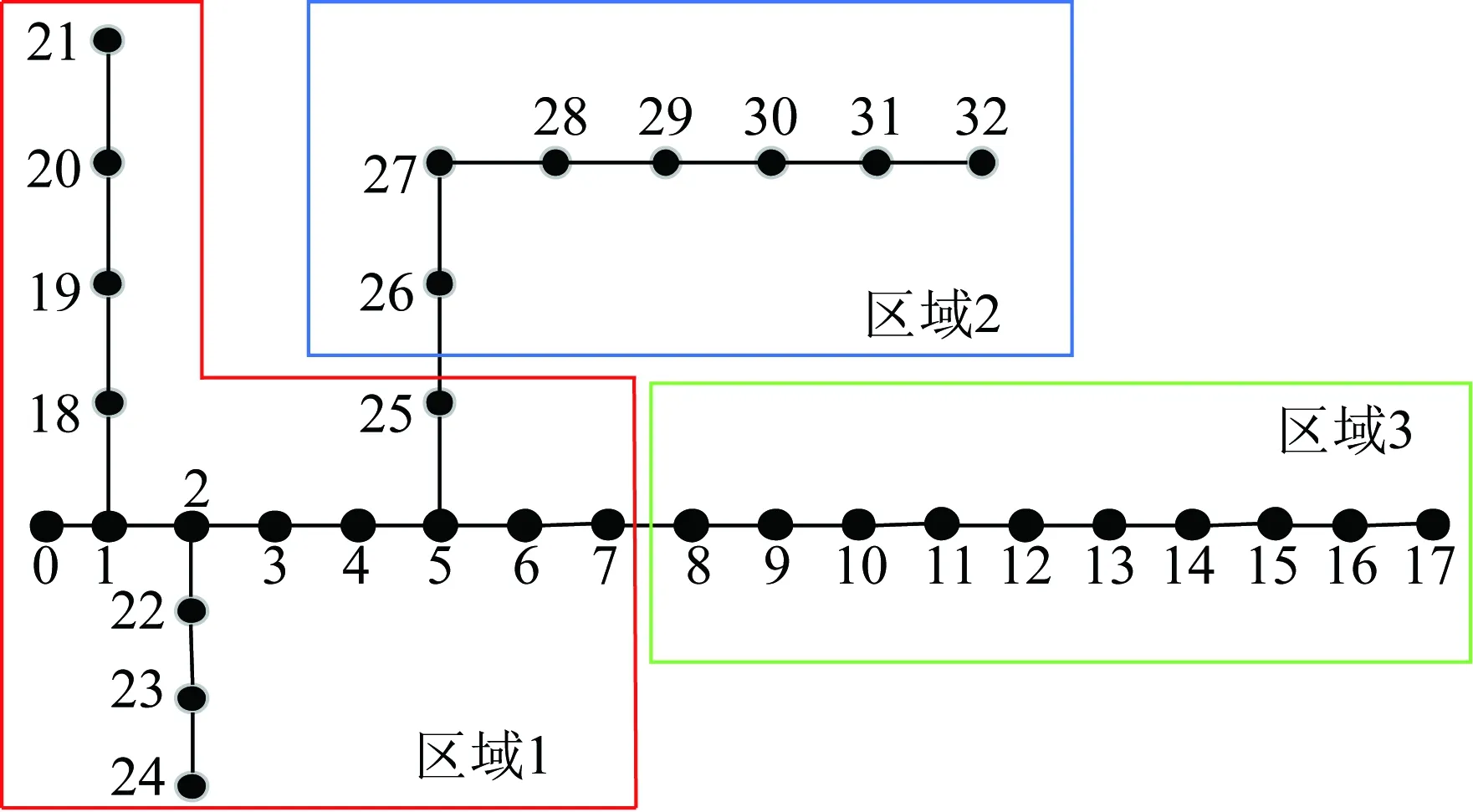
图6 IEEE 33节点系统分区结果(修正前)Fig.6 Zoning results of IEEE 33-node system (before revision)
根据3.4节修正分区结果,如图7所示。由边缘计算中心节点选择原则,选择2、12、28节点为边缘计算中心,即图7中红色节点。

图7 IEEE 33节点系统分区结果(修正后)Fig.7 Zoning results of IEEE 33-node system (after correction)
通信方面,计算区内终端到边缘节点的最长通信时延(2.738 ms)、区内通信业务流量等得到分区结果修正前后均满足系统通信实时性和带宽利用率要求;分区均衡性上,修正后分区终端数目趋向近似,样本标准差S变小、均衡性变好,如表1所示;系统结构上,修正后区域2、3均增加了部分原属于同一条馈线上的终端节点,更利于后续故障处理。

表1 IEEE 33节点系统均衡性Table 1 Balance of IEEE 33-node system
2)IEEE 69节点系统
对IEEE 69节点系统进行上述同样步骤可得其最优分区数为4,聚类及分区结果如图8—10所示。
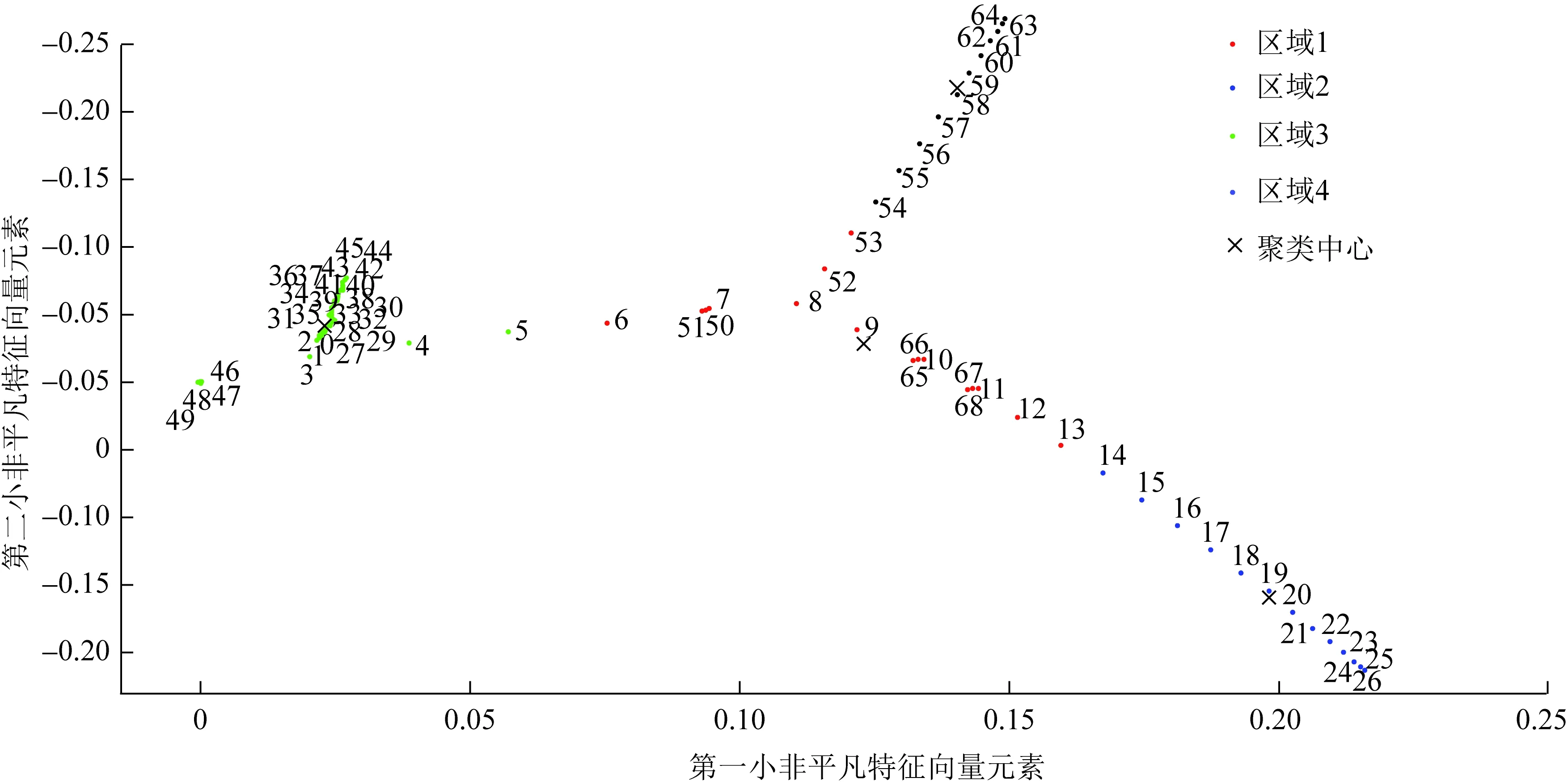
图8 IEEE 69节点系统聚类结果Fig.8 Clustering results of IEEE 69-node system
图10中3号、8号、20号、59号节点为边缘计算中心,对应红色、蓝色、绿色、黑色的四个区域为其管辖范围,区内终端受边缘节点管辖。

图10 IEEE 69节点系统分区结果(修正后)Fig.10 Zoning results of IEEE 69-node system (after revision)
4.3 分区结果验证与分析
为验证对比本文方法与传统集中式故障处理方法,本文利用Matlab/Simulink搭建IEEE 33节点系统、通信系统及混合业务排队论模型,实际仿真了故障处理流程,生成了本文方法和传统方法的故障处理时间和故障波形。
选择0节点模拟集中式故障处理的主站,设置17终端节点所在线路发生BC两相接地短路故障。为分析节点与主站距离不同时,应用本文方法的速度提升效果差异,选择图7中与主站距离较近的区域1和较远的区域3仿真对比。传统模式中,终端将故障信息上传到0节点;本文模式中,区域1(区域3)内终端将数据上传至边缘计算中心2节点(12节点)。
为更明显的对比本文与传统方法,仿真忽略终端采集信息、断路器机械动作及人工检修操作等时间,着重仿真记录各节点从故障发生起上传数据给主站或边缘至处理分析后各终端收到指令、切除故障的通信时间,包括通信时延、计算时延、排队时延等。
为了更精确地仿真,本文重新建模了上述过程中的排队时间。
针对产生排队时间的汇聚节点,首先讨论多类型故障信息流到达速率。假设语音、数据、视频、多媒体4类数据到达时间间隔满足泊松分布,到达速率为li(i=1,2,3,4),到达概率为pi(i=1,2,3,4)。参考自相似业务流排队论、混合业务汇聚流排队论[16,19]等,则故障信息到达速率l满足y阶超指数分布(简记Hy分布),其概率密度函数如下:
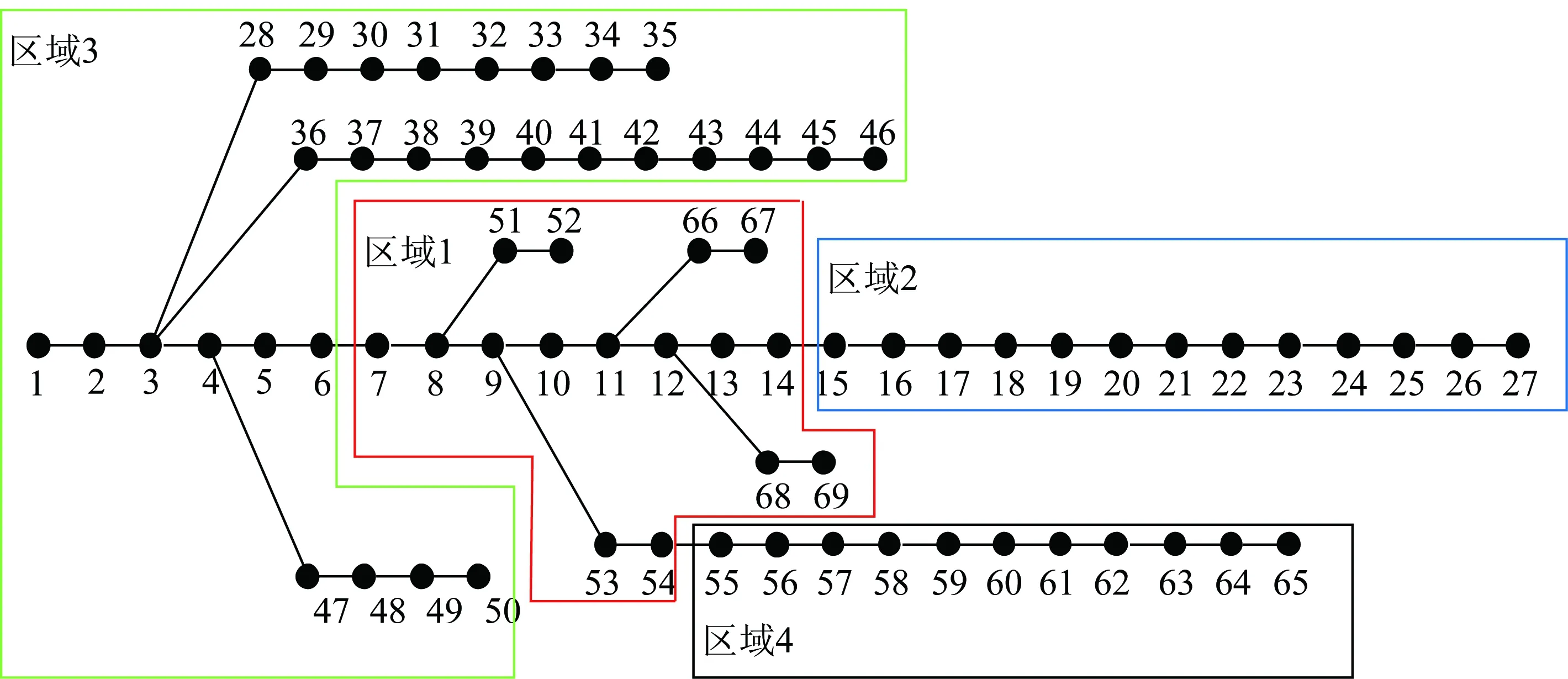
图9 IEEE 69节点系统分区结果(修正前)Fig.9 Zoning results of IEEE 69-node system (before revision)
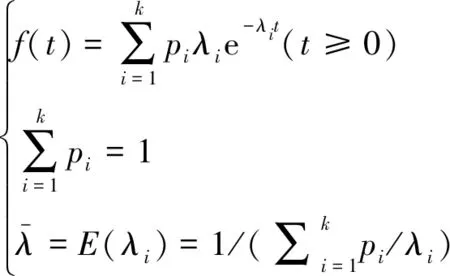
(18)
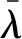
根据排队论原理,汇聚节点按到达次序以速率m转发数据,m服从指数分布。设其缓存排队长度为m,则故障信息排队论模型可记为Hk/m/1/m如下,
(19)
式中:a为到达概率向量,a=[p1、p2、…、pk];e=[1,1,…,1]T;γ=[aRλ(-μT-1)e+∑aRje]-1;R=μ(μI-μea-T)-1;T=diag[-λ1,-λ2,…,-λk]。
根据上述模型即可计算排队时间,假设终端故障信息到达概率都相同,设置λ为80 kbit/s、μ为200 kbit/s、m为80 kbit。
仿真得到故障发生后,两种模式的A相仿真电流电压波形对比如图11所示,时间对比如表2—4所示。

表2 传统模式与本文模式平均排队时间Table 2 Average queuing time of traditional model and the proposed model
图11 A相电流电压波形对比Fig.11 Comparison of A-phase current and voltage waveforms
图11中,横坐标为时间t,纵坐标为A相电流电压幅值,t=1.0s为两相接地短路故障发生时刻。
由图11可以看出,应用本文方法,可以更快速地通信计算并切除故障,停电时间和短路电流电压值更小,对系统的冲击及后续振荡时间与影响也更小。
表3 传统模式与本文模式故障处理总时间(区域1)
Table 3 Total time for fault processing in traditional mode and the proposed mode (area 1) ms

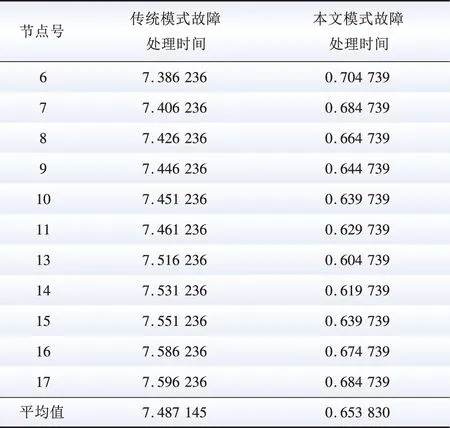
表4 传统模式与本文模式故障处理总时间(区域3)Table 4 Total time for fault processing in traditional mode and the proposed mode (area 3) ms
由表3、表4可知,使用本文方法时,各节点传输数据、排队及故障切除的时间较传统模式大大缩短;区域1处理速度提升近3倍,区域3处理速度提升10倍,即主站距离终端越远、网络规模越大时,时间缩短越多;故障快速处理的同时本文方法满足通信可靠性约束,因此可避免信息漏报误报问题,提升处理准确度。
因此本文方法能够实现边缘计算单元的优化配置,在保障可靠性的前提下实现分布式故障处理,减少通信和计算分析时间,减轻通信带宽和主站压力,进而提升故障处理速度和准确度,且该法在配电主站较远、配电网规模较大时效果更好。
5 结 论
本文提出了一种面向配电网故障快速处理的边缘计算单元优化配置方法,将边缘配置转化为最优分区规划问题,实现了边缘最优数目求解和边缘管辖区域划分。主要结论总结如下:
1)以通信实时性和经济性为目标函数,电气及通信可靠性为约束,结合系统需求求解最优边缘数,再结合谱聚类和k-means算法划分边缘管辖范围并根据通信、均衡性等方面指标修正分区。
2)通过IEEE 33节点、69节点系统算例验证本文配置方法的可行性,结果显示本文方法缓解了配网通信压力,提升了故障处理速度3倍甚至10倍,且配电网规模越大,本文方法效果越好。
3)本文方法还可根据实际工程不同要求灵活调节,并推广应用于其他配电网业务,如用电业务、能效监测、营销运维等。
