基于效益自适应的虚拟云资源计算研究
2022-03-16黄金凤
黄金凤
(福建船政交通职业学院,福建 福州 350007)
0 引言
现有的云数据中心环境主要是由物理服务器组成。近年来,由于“互联网+”和大数据等各类技术的推广而产生的海量数据,加剧了云数据中心环境的负载。这对云环境中的物理计算资源响应度而言无疑是一个严峻的挑战。虚拟服务器节点计算资源被业界视为解决该问题的最佳途径之一,也就是一个物理服务器节点可根据云端用户提请的任务请求规模在某一时刻为该任务释放虚拟计算资源。为使云环境中的虚拟计算资源更高效地服务于云用户任务请求,遗传算法成为研究热点。诸如,杜艳明等[1]构思了一种基于业务优先级的云任务调度算法,该算法旨在充分利用遗传算法优质基因选择的思路,为不同优先级的云任务适配最合适的虚拟资源节点,以开展基于QoS约束的海量数据云计算,但并未提及云任务的时间代价控制思路。为解决该问题,郑迎凤等[2]设计了一种基于时效的云任务分配算法,该算法通过优化遗传算法迭代效率,降低迭代计算频率,同时设计最小化云任务计算在时间上的目标函数,来缩短云任务的执行时间,然而却忽略了云环境中不同的虚拟服务器节点,因个体差异可能导致任务在接受云计算后的反馈时间也存在差异性。针对此不足,侯松[3]提出了一种基于双层约束的遗传算法(IGA),该算法在交叉变异环节引入测算因子,为云用户任务引入多云环境。通过调度多个虚拟资源节点来平衡云系统负载并降低云任务的执行时间,但依旧未顾及单个虚拟服务器节点计算资源在特定时间内响应该云任务而引发的损耗问题。显然相关主流研究在基于遗传算法优势的基础上,即便做出了改进也仅是片面地解决了云任务计算的时效性和资源的均衡性,甚至针对收敛过早的情形也未展开相关探讨,这难以实质性地提高云计算提供商的效益。为此本文在经典的遗传算法基础上提出一种基于效益的虚拟云计算研究(PVC)。
1 效益模型
为使效益最大化,云数据中心通常将待计算的云业务分化成多个彼此无关的子模块,并使虚拟服务器上的虚拟计算[4]资源分别映射至各个子模块,待各子模块经过虚拟计算响应后再整体输出虚拟云计算值。然而,云数据中心环境内各物理服务器计算性能的差异特征所引发的虚拟计算资源差异化,导致了云数据中心受理子模块的云计算时间成本不一。并且基于差异特征的虚拟服务器在特定时间内通过映射其虚拟资源来计算一个子模块所引发的损耗代价也不尽相同。显然,云计算提供商获取良好收益的思想是使虚拟服务器为多个不相关的子模块同时提供虚拟计算资源。
将t和p分别表示虚拟服务器v执行子模块m所需的时间成本和损耗代价,将pv表征为v的个体成本,则损耗代价记为
p=tpv.
(1)
假设云端用户向云数据中心环境提请的云业务规模为K,云业务的子模块规模为x,第c个云业务中的子模块m的数据长度为Lcm,虚拟服务器规模为y,第v个虚拟服务器所能提供的虚拟计算能力为Cv,于是有1≤m≤x、1≤v≤y。进而求得时间成本的值为
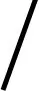
(2)
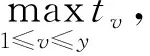
(3)
假设虚拟服务器承载云业务的成本为pvt,可得云用户提请的云业务待响应代价为
(4)
2 云计算方案构建
对于云计算提供商而言,效益最大化才是其投资的最大目标。因遗传[5]算法具有普适性评估、优胜劣汰、交叉变异等优势,使得该算法在部署海量任务的云计算时,可在云系统能耗、云资源博弈、云带宽配置[6]等方面表现出良好成效。但即便如此,遗传算法依然因其固有的某些缺陷使其应用在复杂的云任务计算中无法发挥应有的优化作用。诸如,传统意义上的遗传算法对于初代染色体的序列依赖度较高,以致于收敛太早搜索成效太低。显然这样的情形并不利于云计算提供商精确地测评云计算执行时间成本和损耗代价等事务性指标。基于此,本文研究一种基于云任务受理成本和时间约束的高效益云计算方案,整个方案流程如图1所示。
首先随机创建一个规模为N的种群,通过为每一个个体开展普适性评估来提取出位列所有种群前5%的优质个体遗传到后代继续用作种群,同时设计轮询机制对剩余的95%个体开展择优选用。然后让两个随机个体执行交叉,从而获得全新的子代个体种群。在此期间优质个体将被保留,劣质个体将被淘汰。最后通过设计变异适应函数来评估个体的普适性。此举旨在预防优质个体发生劣变。
云数据中心环境创建g个染色体。每个染色体的长度为x,即云任务的子模块规模。根据前文描述,每个子模块将由虚拟服务器为其映射一个虚拟计算资源。于是本次编/解码环节的设计便是基于虚拟计算资源和待计算的云任务之间一种关于映射关系的编/解码设计。染色体的基因参量不超过虚拟资源规模y。比如,虚拟服务器为染色体3、2、4、5、3、4、1、3、5、2、1、2、3映射五个虚拟计算资源。则五个虚拟计算资源节点所映射的子模块分别为v1={7,11}、v2={2,10,12}、v3={1,5,8,13}、v4={3,6}、v5={4,9}。不难统计出五个虚拟服务器的虚拟计算资源所要计算的云任务数量分别是2、3、4、2、2。
为从根源上提升后代遗传基因质量,算法需引入普适性指标,从初代开始评估最适合用作继承的个体。由于本研究目标在于提升云计算服务提供商的效益,故将待计算的云业务受理时长和受理代价作为普适性的目标函数。受理云业务计算的损耗代价普适性目标函数值和种群个体损耗代价成反比。这一过程表示如下:
(5)
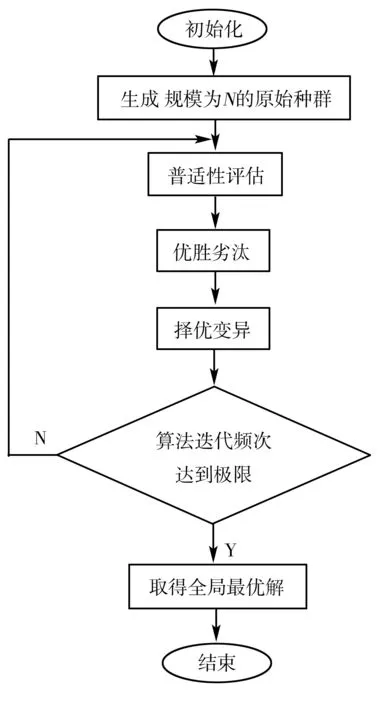
图1 高效益云计算方案流程
倘若云数据中心受理云业务的时间成本较低,则损耗代价普适性目标值越大;倘若云数据中心受理云业务的时间成本太高,则目标值Aα越小。因此,损耗代价普适性目标值和云业务受理时长息息相关。令云数据中心受理云业务的最大时长为TH,则受理云业务计算的时间成本普适性目标函数记作:
(6)
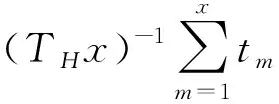
同理,当云数据中心受理该云业务时间成本越低,该方案所对应的时间成本普适性目标值Aα越大;反之,若该受理方案对应的Aα值越小,意味着该方案值并非全局最优解。
但由于算法在遗传后期的迭代计算中会使个种群个体逐渐趋于一致。这样的情形容易引发所求解仅局限于某一个局部范围内,若推广到云数据中心将导致该解在整个云数据中心环境下缺乏普适性。为避免该情形定义差异化因子d作为遗传后期的个体区分。根据前文所述,云业务的子模块数据长度即为基因长度,记作n。基因方差记作:
Δz=Jmz-Jvz,
(7)
其中,Jmz和Jvz表示位于相同位置的两个基因的值。
则有
(8)
由于云计算服务提供商的效益是基于时间成本和损耗代价的约束来实现,同时为了避免优质个体的偶然性对全局事件的影响,首先淘汰普适性参量较大的前3‰个体,然后将紧随其后的5%个体选作次代种群个体,再采用轮询算法筛选余下的个体。鉴于部分染色体基因在优胜劣汰环节遭遇不可避免的舍弃,并由此引发种群粒子规模的频繁波动,算法在部署前需选用一些普适性较为贴近的个体作为补充以保持种群个体规模相对稳定。将所筛选出来的个体和交叉变异后的个体组建出一代新的个体种群。

(9)
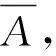
(10)
3 云计算实施方案
根据前文云业务部署步骤,以效益为目标实施云计算时,应由云数据中心环境产生初代粒子个体并开展个体普适性评估,随后启动优胜劣汰执行交叉变异最终收敛出一个全局最佳值。据此思路,云计算实施步骤如下:
4 实验分析与论证
4.1 实验设置
部署遗传算法时,首先要将种群规模初始化为N=45。云数据中心服务器将所要受理的云业务划分为1 500个子模块,即x=1 500个。并为其映射15个虚拟计算资源,即y=15。迭代计算频次上限至200次。其次,交叉和变异环节中的各参量初始化为o1=30×10-1,o2=3,o3=3×10-2,o4=3×10-2,pth=2×10-2。为凸显本文所研究PVC算法的先进性,本次选用前文所述的IGA算法作为对比。通过考察两个算法受理云业务计算的时间成本和损耗[10]代价来验证PVC算法方案的科学性。
4.2 实验结果分析
图2所示曲线为两种改进型遗传算法在受理云用户提请的云业务计算时所产生的损耗代价情况。整个云业务被划分成1 500个子任务模块,分别由IGA算法和PVC算法来受理。两种算法在迭代计算初始所产生的资源损耗代价较为接近。随着迭代频次递增两种算法下的损耗代价均有不同程度下降。但由于PVC算法引入了损耗代价普适性函数用于评估个体值在全局范围内的适应性,并且在交叉变异环节进一步优化了继承的基因,这恰好是IGA算法所不具备的优势。故随着迭代频次逐渐增加,PVC算法下的云资源损耗代价曲线降幅赶超IGA的降幅。至此,PVC算法表现出了相对优势。
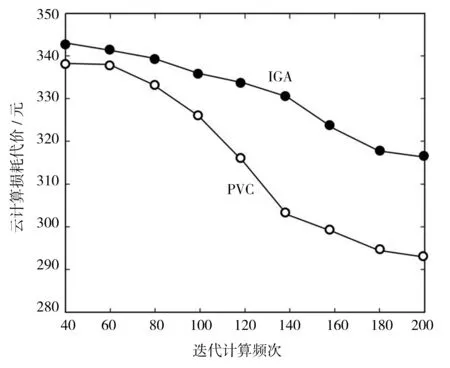
图2 受理云业务计算的损耗代价
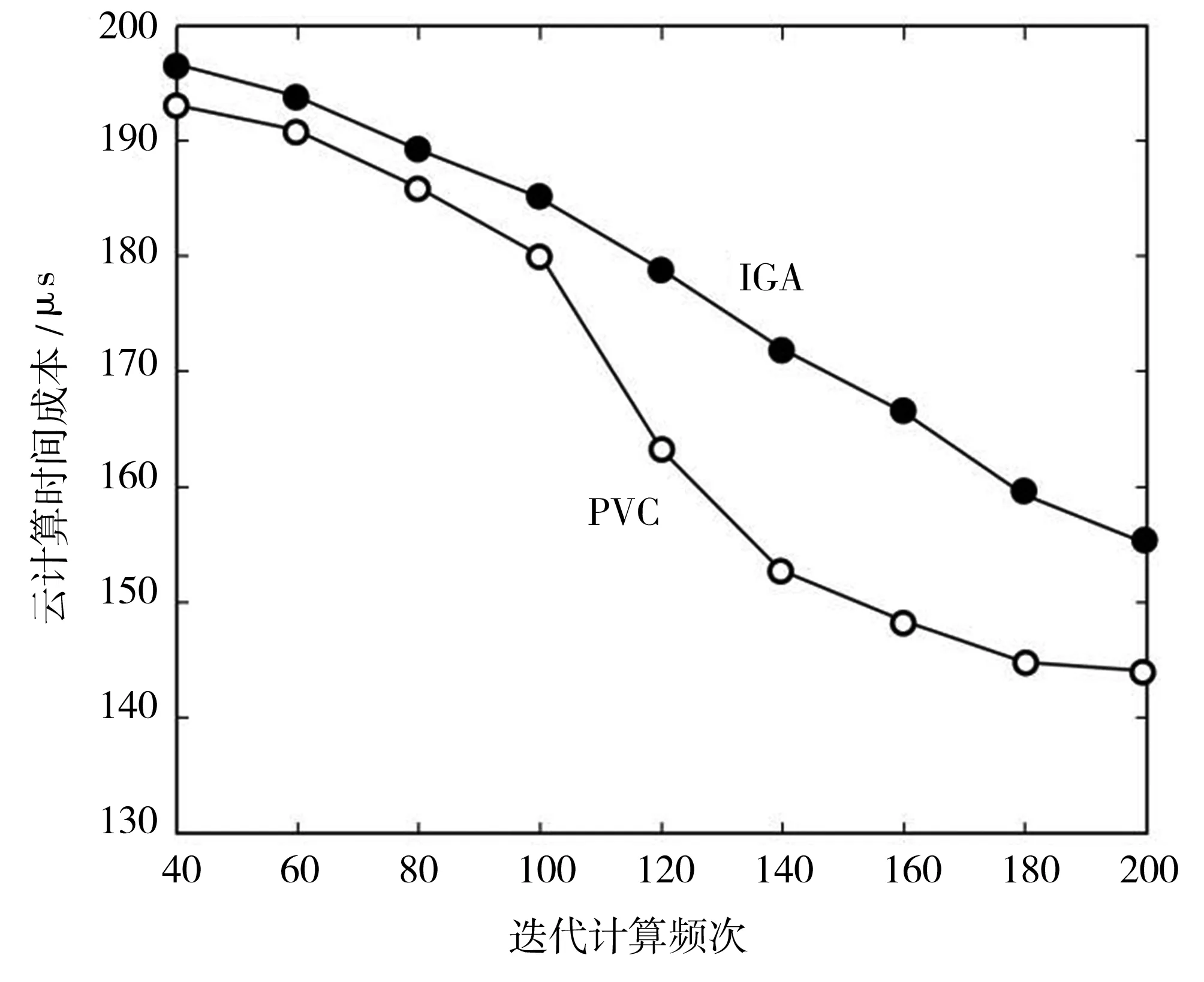
图3 受理云业务计算的时间成本
图3所示曲线为两种改进型遗传算法在受理云用户提请的云业务计算时所需的时间成本情况。由图中曲线不难看出,两种算法在对云环境中的1 500个子任务开展虚拟云计算所消耗的时间成本各不相同。总体而言,算法的时间成本均和迭代计算频次成反比。这是由于两个算法都是基于遗传算法思想演进而来。遗传算法思想是通过迭代计算方式不断进化出优质后代收敛出较好的值,从而降低算法后续计算的复杂度。从图中曲线可以看出,受理业务的云计算初期两种算法的时间成本相差无几。但随着云计算频次的增加,两种基于遗传算法的优势均得到明显体现,所产生的时间成本均显著下降。相比之下,本文研究的PVC算法在实施云业务计算时更好地做到了对时间成本的把控。究其原因是PVC算法针对种群个体单独设计了时间成本普适性评估函数。同时,PVC算法在交叉变异环节再次开展优质个体基因的评测,为后续收敛速度和精度均奠定了良好的基础,该设计理念正是IGA算法所欠缺的。故本组测试论证了PVC算法的相对优势。
5 结语
本文围绕云数据中心环境开展云业务计算时引发的计算时间和计算代价问题提出一种新型云计算方案,根据该方案设计的普适性评估机制、优胜劣汰机制和择优变异机制均在一定程度上提升了子代个体的遗传质量。从实验数据不难看出,子代个体的普适性函数值具有良好的全局性,同时云环境下大量子任务的虚拟云计算指标也验证了本文算法方案的优势。这些良好的表现使得本文算法在部署海量业务的虚拟云计算时,可有效地降低云数据中心的损耗代价,压缩云计算时间成本,这无疑可为云计算服务提供商带来可观的效益。
