基于生理行为和语言行为双层次特征维度的抑郁情绪识别*
2022-03-16宋锐彪
宋锐彪
(云南师范大学,云南 昆明 650500)
0 引言
随着时代的加速发展,人们所处的社会环境变化多端,学习生活、工作节奏变快,促使压力剧增,精神健康问题日益突出,同时人们对自身的精神健康也越发重视。根据世界卫生组织公布的报告,截至目前,全球抑郁症患者比例高达20.23%,但就诊率不到7%。抑郁症不易察觉,人们意识淡薄,筛查方法缺乏等因素,使得抑郁症的筛查率、就诊率都极低。为了改善这一现状,许多学者都试图将机器与深度学习应用于抑郁症的预测、识别、辅助诊断和后期治疗中[1-3]。有的学者基于自然语言特征进行识别,如刘海鸥等人[4]基于深度学习的在线健康社区抑郁症用户画像开展对抑郁情感进行分类的研究;赵小莉等人[5]基于深度学习对微博文本进行了抑郁症识别,该研究打破传统的患者主动就诊方式,对抑郁症的快速识别和提前预警有重要意义。还有学者从生理行为进行研究,如魏巍等人[6]基于面部深度空时的特征对抑郁症进行识别,毛万登等人[7]基于深度学习从脑电信号对抑郁症患者进行识别研究。
笔者发现,以上研究均是基于深度学习算法利用抑郁症人群的生理行为特征或自然语言特征对抑郁症人群进行识别。其中,利用脑电波特征、面部特征等手段识别的成功率较高,但是识别的形式较为单一,更为重要的是识别时所需数据较为严格,不易普遍筛查。为此,本文提出基于两类抑郁症特征维度的识别方法:结合熵值层次分析对生理行为特征进行识别;基于二次特征词库加强的贝叶斯算法进行自然语言文本识别。
1 本文方法
本文将基于生理行为和语言行为双层次特征维度对抑郁情绪进行识别,即通过对抑郁人群进行生理行为、语言信息两方面的识别达到抑郁情绪识别的目的。本文的主要贡献:第一,完善目前的数学模型,并对抑郁人群进行识别,具体为基于熵值的层次分析法建构对具有抑郁情绪人群的生理特征模型进行识别;第二,基于二次特征词库加强的词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)算法,将特征词向量化输入多项式贝叶斯算法中,从概率角度对抑郁情绪文本进行有效识别,从而判断人群的抑郁情绪。
1.1 生理行为特征——熵值层次分析法
通过查询医疗文献记载、走访精神科医师及翻阅问卷调查资料,笔者发现:当人有抑郁情绪时,其生理的行为特征会发生明显变化,轻则出现失眠、食欲不振、心情低落等情况,重则出现性格孤僻、社交恐惧、厌世、服用药物、自杀等行为。针对这一问题,人们试图通过心理问卷调查等方式来了解自身情况,如抑郁症测试、心理评价等,但这只能帮助初步分析人的心理状况,并笼统地反映自身情况,对于抑郁情绪的具体细致情况的识别效果都是较差的。为改善识别效果,本文通过查询科学的心理问卷填写事实、走访心理医生及查阅医学文献等获得数据,采用聚类的层次分析对抑郁人群的症状进行识别。本文归纳出有关抑郁情绪症状的生理行为特征12个,并通过特征相关分析筛选最终得到7个特征。本文先利用聚类分析的方法对行为特征进行分层,再利用熵值法确定各个特征的权重,由此避免人为主观因素影响层次分析法中的指标权重,从而更为具体地刻画抑郁情绪者的生理行为特征,充分反映各行为特征对评判的影响程度,提高识别效果。文献[8]、文献[9]、文献[10]、文献[11]中均有对熵值法、聚类分析法以及层次分析法的详细介绍,本文不再赘述。熵值层次分析法模型的建立流程见图1。

图1 熵值层次分析法
1.2 语言行为特征——基于二次特征词库加强的TF-IDF 与贝叶斯算法
虽然抑郁情绪者的生理行为特征有着明显的变化,但仅依据生理行为特征就对抑郁症状进行识别的效果还是不尽如人意。文献[12]和文献[13]等研究表明,贝叶斯算法对于文本的分类表现出较好的识别能力。为进一步加强识别效果,本文提出了一类基于抑郁文本语句的多项式贝叶斯识别算法,对抑郁情绪症状做进一步的识别,提高抑郁症状的识别率,即基于二次特征词库加强的TD-IDF 算法对文本语句进行向量化表示,并输入多项式贝叶斯模型中对抑郁情绪语句进行识别。笔者发现,常规的TD-IDF 算法[13]中,在文本特征词的筛选过程中会出现拒接受现象,即错过“低频重要词”和“常规重要词”,这样虽然提高了识别速度,但降低了多项式贝叶斯算法的识别准确率。针对这一问题,本文对TD-IDF 算法采用了建立二次加强的特征词库,有效地提高了该类词的IDF 值,达到提高实验准确率的目的。实验结果表明:通过建立二次加强的特征词库,实验的识别准确率提高了3.2%。
1.2.1 多项式贝叶斯模型
朴素贝叶斯分类器是一种有监督学习算法,对于文本的分类表现出较好的效果[14-15]。它有多项式与伯努利等两种常见模型。其中,多项式模型是一种基于词频的模型,它以单词为粒度,而伯努利模型则是一种基于文档的模型,以文件为粒度[16]的模型。本文采用多项式贝叶斯模型。
本文中的多项式贝叶斯算法为如下3 步:
(1)计算先验概率,公式如下[16]:
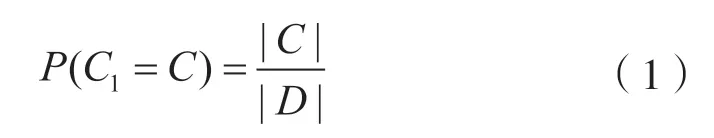
式中:|C|为类别C的文档数量;|D|为所有的文档数量。
(2)计算条件概率,公式如下[16]:
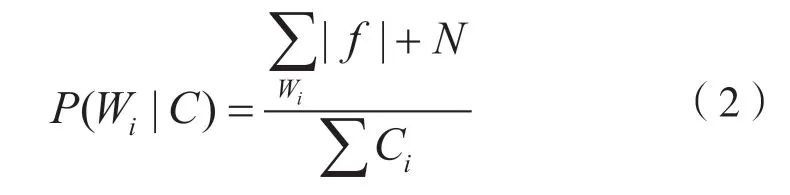
式中:P(Wi|C)为词Wi在类别C的文档中的权重;为词Wi在属于类C的所有文档中出现次数;N为平滑系数,如N=1 为拉普拉斯平滑;∑Ci为C类的所有文档中的词语总数。
(3)先验概率和条件概率的计算均使用最大似然估计,计算出相对频率值,使训练数据出现的概率最大。计算预测概率的公式如下[16]:

1.2.2 TF-IDF 算法
TF-IDF 算法对识别语句中所需的每一个特征词进行刻画,确定其在文本中的重要程度,即该词的重要性与它在某文本中出现的次数正相关,特征词在文本中出现的次数越多,其重要性越大,但同时又与它在总文本集中出现的频率成负相关,特征词在总文本集中出现的次数越多,则该特征词越是不重要的。因此,TF-IDF 值可作为抑郁症文本语句的分类标准,并且TF-IDF 算法还具有避免抑郁情绪文本中的特征词向量维度过高、数据稀疏及计算效率低效等的特点[14]。但是,笔者发现,常规的TF-IDF 算法对于常见特征词、低频重要词等存在拒接受现象。所以,本文中的TF-IDF 算法对抑郁情绪语句文本中的TOP-N 关键词提取时,加入对于识别时所需的重要的二次特征词(人工额外进行二次筛选重要特征词)。最后,采用词袋模型(Bag Of Words,BOW),将文本进行向量表示。
总之,TF-IDF 方法的核心是将文本表示为n个特征词组成的特征词集合,并通过词频和逆向文本频率,反映某个特征词的重要性。
本文通过以下4 个步骤得到特征词的TF-IDF 值:
(1)二次加强特征词库的建立对TF-IDF 算法中出现的对“高频常见词”“低频重要词”不友好的现象进行改善,即通过加入这类特征词与提高该类词的IDF 值来提高该类词在判断时的作用。
(2)计算词频(Term Frequency,TF)。词频是指该词在文本中出现的频率,记为F,计算公式为[17]:
式中:TFij为文件j中的特征词i的词频;Nij为特征词i在文件j中出现的次数;∑Ti为文件j中的所有特征词数量。
(3)计算逆文本频率(Inverse Document Frequency,IDF)。逆文本频率是指文本中的文本总数除以包含该词的文本数记为IDFi,计算公式如下[17]:
式中:IDFi为特征词i在逆文本的词频;|D|为语料库中文本总数;∑ti为包含单词i的所有文本数的分母加1,是为了避免分母为0 即为所有文本不含该词的情况。
(4)实验中的文本的长度不一,会造成识别效果下降,通过文本长度归一化提高识别精度[18],计算公式为:

式中:Li为特征词的长度;Lmax为所有文档中的特征词最大长度。
(5)计算特征词的TF-IDF 值,公式为:

二次特征词库加强下的TF-IDF 贝叶斯算法流程见图2。

图2 TF-IDF 算法流程
2 实验概述
2.1 数据来源
为达到实验研究的效果,本文的数据来源选自微博、微信、星调查等公开平台。主要是通过患有抑郁症的微博用户(如2015 年因抑郁症而去世的用户“走饭”)、现有的抑郁症树洞、网络问卷调查、心理工作站以及走访相关医院心理医生等途径获得的数据。共采集微博平台中具有抑郁情绪的相关用户327 位,7 721 个语句,以及非抑郁症用户287 位,6 921 个语句。发放问卷调查237 份,共得到有效数据214 份。
2.2 实验运行环境
核CPU 为2.70 GHz,16 GB 内存;操作系统为Windows 10,Python 3.9;开发工具为IDLE。
2.3 数据处理
数据处理分为文本数据处理和调查问卷数据处理两类。
2.3.1 文本数据处理
文本数据处理分为以下5 步:
(1)对文本数据进行去隐私化处理,将与个人信息相关的数据进行修改、删除得到6 843 个与抑郁症相关的语句,得到6 402 个非抑郁情绪的语句;
(2)采用Jieba 分词对所得到的3 028 条语句进行分词,得到了2 0645 个词、词组;
(3)去停用词(哈工大版停用词):对日常符号、常见字词进行筛选得到10 078 词,并对筛选后的每一个特征词进行词频统计;
(4)建立二次加强特征词库完善后续特征词库,人工筛选出词频前1 000 个词语。
(5)人工进行检查、增添、删除,最终得到符合本文实验关于抑郁情绪特征语句的识别词库,共计827 个特征词.
2.3.2 调查问卷数据处理
调查问卷数据处理分为以下2 步:
(1)根据心理学中对于抑郁症调查、判断人们是否抑郁的问题中,笔者截取了其中常见的20个抑郁症相关问题,进行科学化的问卷设置。
(2)通过Excel 软件对异常数据进行合理化,如缺失数据、超出正常范围数据进行整改,最终得到206 份问卷数据。
3 实验结果
本文共采集了抑郁情绪相关语句与非抑郁情绪语句共13 245 份,调查问卷数据206 份。从中随机抽查语句文本1 000 份、调查数据60 份作为测试集使用。最终,基于熵值层次分析模型、二次特征词库加强下的TF-IDF 贝叶斯算法对抑郁情绪识别的效果由分类的精确率、召回率和F1 值统计值体现,如表2、表3、表5 所示。其中表1 是采用jieba 分词结果;表2 是未改进TF-IDF 贝叶斯算法识别结果;表3 是本文中改进后的TF-IDF 贝叶斯算法识别结果;表4、表5 是熵值层次分析模型识别结果与一致性检验情况;表6 为熵值层次分析模型权重。

表1 分词筛选后结果

表2 未改进TF-IDF 贝叶斯算法识别结果对比

表3 改进TF-IDF 贝叶斯算法识别结果对比

表4 熵值层次分析模型一致性检验

表5 熵值层次分析模型识别结果对比

表6 熵值层次分析模型
从表格中的结果可见,本文所提的方法有效提高了对抑郁人群特征、抑郁情绪语句的识别效果。
4 结语
本文从生理行为、语言行为两个特征维度,提出利用熵值层次分析识别,以及二次特征词库加强下的TF-IDF贝叶斯识别算法对抑郁情绪进行识别,实验结果显示:在识别速度可接受的情况下,熵值层次分析模型的识别效果可达到83.2%(默认数据正确情况),二次特征词库加强下的TD-IDF 贝叶斯算法识别准确率达到84.9%,相较于未加强模型提高3.2%。然而,需要指出的是,通过对识别错误的语句分析发现,识别错误语句多为消极语句,所以本文采用的模型、算法在文本搜寻和处理、识别精度、维度以及角度方面还有待进一步研究和完善。
