面向自然场景文本检测的FPPMAC 模型*
2022-03-16张习文倪建成
张习文,倪建成,祁 蓉,王 琪
(1.曲阜师范大学 网络空间安全学院,山东 曲阜,273165;2.曲阜师范大学 网络信息中心,山东 曲阜,273165)
0 引言
自然场景文本识别在生活中应用甚广,如自动驾驶、牌照识别、图像检索[1]等,而高效准确的文本定位是识别的前提。近年来,得益于深度学习技术的快速发展,场景文本检测取得了很大的进展,但仍未达到人们对这一任务的预期要求。
现阶段的场景文本检测可分为基于目标检测的方法和基于语义分割的方法,前者通常先定义一系列不同长宽比的锚点(anchors)以适应不同大小的文本区域,而后者则是从像素级别区分文本和非文本区域。
自然场景文本检测与目标检测都是从复杂的背景中识别出相应的目标,但场景文本检测比目标检测面临着更多的挑战,因为除了光照、位置等外在因素,字体、大小等文字本身的特性也给文本检测增加了困难。因此,目标检测方法无法直接应用到文本检测中。经典的目标检测模型如单一探测器(Single Shot Detector,SSD)[2]、反卷积单一探测器(Deconvolutional Single Shot Detector,DSSD)[3]和快速区域卷积神经网络(Faster Region Convolutional Neural Network,Faster R-CNN)[4]等为文本检 测提供了设计思路。Liao 等人提出了基于SSD 的Textboxes[5]模型,将SSD 默认框的长 宽比设置为(1,2,3,5,7,10),并且用1*5 的卷积核替代标准的3*3 卷积核,生成长方形的感受野。为实现定向文本探测,Liao 等人设计了TextBoxes++[6]模型,配置默认 框的长宽比为(1,2,3,5,1/2,1/3,1/5),并将卷积核改为3*5。
上述模型事先设置的锚点(anchors)为矩形,定位弯曲文本时,检测结果中存在大面积的背景区域,不利于后续识别文本,如图1 所示。

图1 用矩形框表示弯曲的文本区域
通过设计对角线调整因子优化回归分支,CAO等人[7]设计了一个简单快速的多方向文本探测算法。利用为每个文本实例提供多个预测的方法,Wang 等人提出的渐进比例扩展网络(Progressive Scale Expansion Network,PSENet)[8]通过渐进比例扩展算法预测完整的文本实例,但该方法过程复杂,检测速度较慢。利用高效准确的文本探测(Efficient and Accurate Scene Text detector,EAST)[9]模型在每一个文本像素上做预测,并使用局部非极大值抑制得到最后的探测结果。继而,Liu 等人基于EAST 构造了快速文本定位器(Fast Oriented Text Spotting,FOTS)[10]模型,虽然在某些公开数据集上得到了很好的效果,但是EAST 和FOTS 在探测长文本时都存在预测不准确的问题。
由此,针对上述方法依然存在的长、弯曲、密集文本检测效果差的问题,本文设计了一个用于检测多方向、任意形状的特征金字塔并行多空洞卷积(Feature Pyramid Network Parallel Multiscale Atrous Convolution,FPPMAC)文本探测模型。提出用循环收缩算法(Cyclic Shrink,CS)多次收缩文本区域,增大文本实例间的距离,更好地区分密集文本。
本文的第一节详细阐述FPPMAC 模型构成,介绍循环收缩算法;第二节介绍实验参数设置、实验结果及其分析;第三节对未来的工作作出展望。
1 检测方法
1.1 FPPMAC 模型
FPPMAC 模型的总体架构如图2 所示,图中的C、C1 表示特征融合操作。该模型利用加入并行多空洞卷 积(Parallel Multiscale Atrous Convolution,PMAC)操作的类特征金字塔(FPN_like)模块,更全面地抽取多 尺度特征。

图2 FPPMAC 模型
1.1.1 特征融合
图3 展示了C1 融合操作,以特征F7的生成为例,F6(40×40)上采样到F2的大小(80×80),接着F2、F6的对应元素相加得到F7。

图3 C1 融合操作
输入图片通过一系列的卷积计算得到4 个不同尺寸的特征图F5、F6、F7、F8,之后归一化到相同大小(的尺寸),再通过C 融合操作得到特征P。不同于C1,C 使用了特征图拼接的融合方式:

式中:Up()n为进行了n倍上采样操作。
1.1.2 PMAC 模块
在自然场景中,文字的大小、占比都是不确定的,为更全面地定位文本,需要将深层和浅层网络提取出的特征结合使用。在FPN 结构中加入由空洞卷积构成的PMAC 模块,可以避免传统深度 神经网络中的连 续池化和下 采样操作对图片的分辨率造成的影响,而且不增加计算成本。
在卷积核的参数中间添加不同数量的0,实现空洞卷积计算。空洞卷积核大小的计算方式为:

式中:k为原始卷积核大小;r为空洞率。
借鉴特征金字塔网络(Feature Pyramid Network,FPN)[11]和空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)[12]的模型架构,本文在FPN 网络中加入PMAC 模块,得到一个FPN_Like结构的网络模型。特征图通过PMAC 时,由4 个不同大小感受野的卷积层同时处理,能够更全面地提取文本特征信息。
图4 展示了PMAC 模块的实现过程。特征F4同时进入4 个不同空洞率的卷积层,在获取4 个不同的特征图之后,再依次经过全局平均池化、线性上采样、特征融合,以及1*1 卷积等操作,得到与特征F4大小相同的特征F5。在图4 中,编号①②③④的参数设置:①1*1 卷积,空洞率为0;②3*3 卷积,空洞率为6;③3*3 卷积,空洞率为12;④3*3 卷积,空洞率为18。
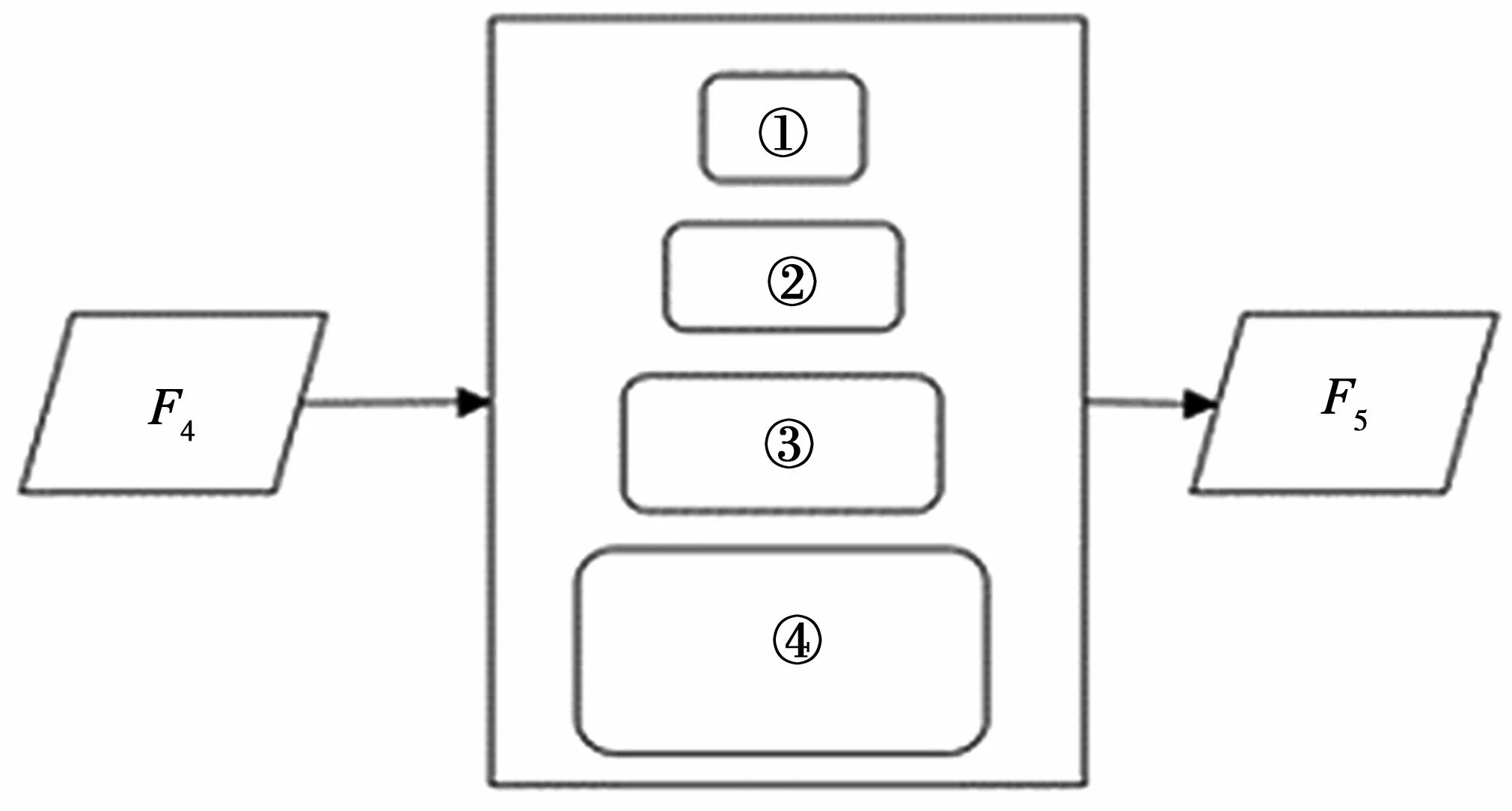
图4 PMAC 模块
1.2 实例收缩与标签生成
将FPPMAC 模型输出的特征P通过1*1 卷积操作得到多个不同尺寸的分割图,即图5 中的P1~Pn。每个Pi都表示一个特定尺寸的分割子图,Pn表示原始文本实例的分割图,P1表示尺寸最小的分割子图。由图5 可见,P1中文本实例(白色部分)间的距离最大,因此用它来区分不同的文本实例。
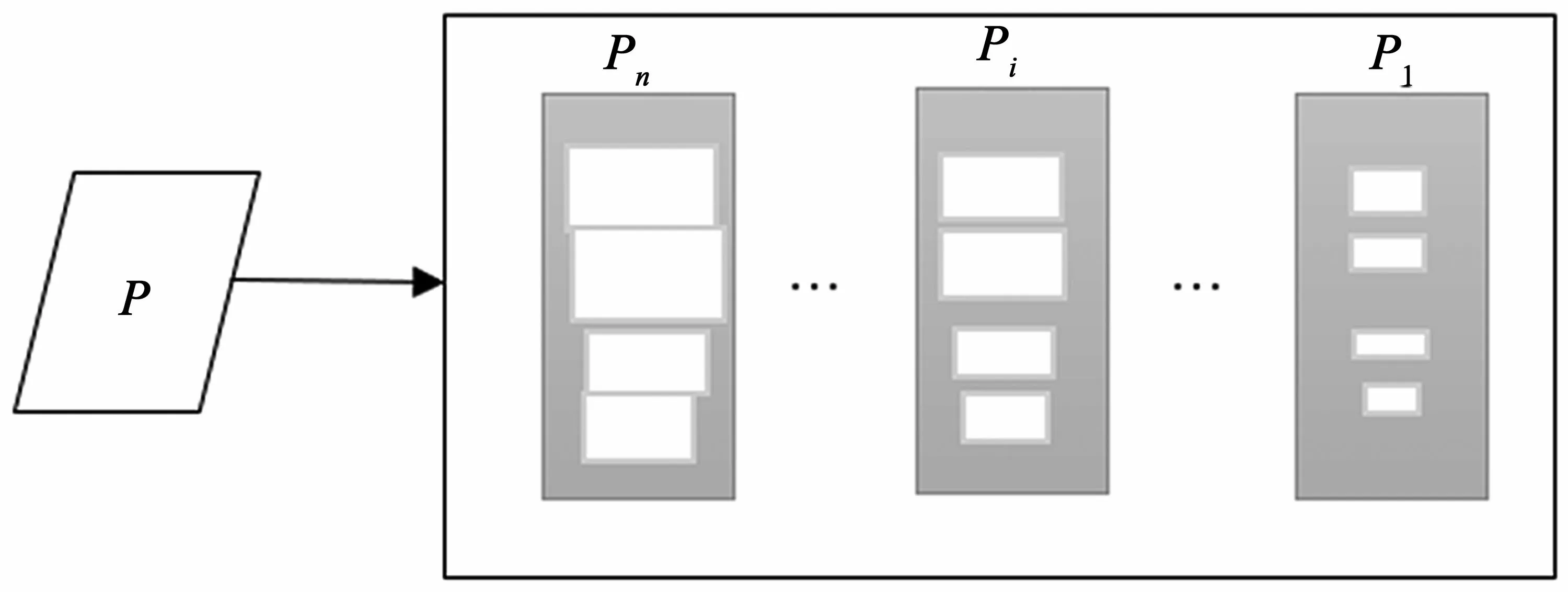
图5 特征分割
本文提出循环收缩算法得到各分割子图的ground truth 以便于训练。

算法1 中的Vatti clipping 算法可以按比例裁剪出与原始多边形保持相同形状的子多边形,A(Si)表示多边形Si的面积,L(Si)表示多边形Si的周长。
在预测阶段,首先用最小的分割子图P1区分不同的文本实例;其次进行循环收缩的逆过程,即从P1开始向外扩展,依次扩展到更大的分割图,直到最大分割图Pn中的像素检索完毕;最后获得最终的文本检测结果。
1.3 损失函数
在自然场景中,由于文 字通常只占很小一部分,容易造成文本区域和非文本区域的失衡问题,从而影响检测效果。为此,在损失函数的定义中,本文结合了Dice 系数和在线硬样本挖掘(Online Hard Example Mining,OHEM)算法[14]平衡文本和非文本区域。
Dice 系数通常用来衡量两个集合的相似性,本文用其表示预测结果和ground truth 之间的相似程度。计算方法为:

式中:Pi,x,y为分割结果Pi中(x,y)位置上的预测值;Gi,x,y为对应位置上的真实值。
为了降低过多背景区域导致的样本不平衡问题对检测结果产生的影响,采用OHEM 方法从背景区域中选取数量为文本区域像素3 倍的像素点进行训练。不妨记OHEM 处理的结果为O,将其应用于Dice 系数,从而得到文本和非文本区域分割的损失函数lC:
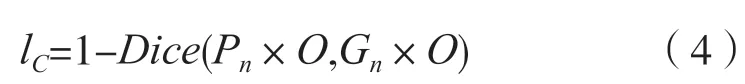
收缩后分割图的损失函数lS用n个分割子图的平均损失表示,计算方式为:

式中:W为Pn内部被忽略的背景区域的像素矩阵。
由此,损失函数L可以定义为:

式中:α、β为平衡因子。
2 实验结果与分析
2.1 实验平台
实验硬件平台:Intel(R)Xeon(R)Gold 6130、NVIDIA Tesla P100,采用GPU 加速。实验软件平台:操作系统为Ubuntu 16.04,CUDA 9.0,python 3.5。实验基于已有的PSENet 框架[8]进行改进。
2.2 数据集
为了充分验证FPPMAC 模型的有效性,本文分别在多方向文本数据集ICDAR2015 和弯曲文本数据集CTW1500 上进行了实验。
2.2.1 ICDAR2015 数据集
该数据集具有文本方向多变、图像模糊且分辨率低的特点,包含1 000 张训练图片、500 张测试图片,以及单词级别的文本实例标记。文本位置用4 个角点定位的四边形表示。
2.2.2 CTW1500 数据集
该数据集包含Open-Image 等互联网资源以及手机拍摄的1 000 张训练图片、500 测试图片,以及单词级别的文本实例标记。该数据集下图片中的文本分布较为密集。为更好地贴合弯曲文本,文本位置用14 个坐标点定位的多边形表示。
2.3 实验参数设置
实验使用网络模型PSENet 作为预训练模型。在ICDAR2015 训练集上微调时,初始学习率为10-4,每200 轮迭代将学习率缩小10 倍,共训练400 轮,每轮批量样本数为8。在CTW1500 训练集上进行实验时,初始学习率为10-3,训练132 轮,每轮批量样本数设为4。
算法1中,最大收缩尺度ms、收缩次数n、最小比例因子m分别设置为20、0.4、7。用多边形定位文本难免会把部分背景区域包含进去,而实验中忽略了分割子图中的背景,即当式(5)中的值大于或等于0.5 时,该像素点的W值为1,否则为0。式(6)中的α和β分别为0.3、0.7。
因ICDAR2015 和CTW1500 数据集的训练集中各包含1 000 张训练图片,样本数较少。为了避免训练过程中出现过拟合现象,每张图片进入模型训练前,首先进行数据增强操作:
(1)随机缩放,缩放因子在[0.5,1.0,2.0,3.0]中随机选取;
(2)随机水平翻转;
(3)随机在-10°到10°之间旋转;
(4)图片尺寸剪裁为640×640;
(5)随机变换图片的亮度和饱和度。
另外,在训练过程中,本文忽略了标签为“#”的文本实例,因为此类标签下的文本非常模糊,即使是人类也难以分辨。
2.4 实验结果及分析
实验结果使用准确率(P),召回率(R)和F分数进行评价。
2.4.1 ICDAR2015 数据集实验结果
在ICDAR2015 数据集上,FPPMAC 模型与EAST、PixelLink 和PSENet 等模型的实验结果如表1 所示。实验复现了PSENet 并得到了与参考文献中相近的结果,其余对照模型数据采信了相应参考文献中的结果。可以看出,FPPMAC 模型的准确率比PSENet、EAST、PixelLink 等方法分别提高了6.99%、4.89%、5.59%;F分数分别超过了PSENet、PixelLink、TextSnake 等方法3.99%、2.29%、1.99%。图6 展示了模型在ICDAR2015 数据集上测试的可视化结果,将检测到的文本区域在原始场景图片下方进行了展示。可见,自然场景图片中的倾斜、密集文本也能被准确定位,这说明本文提出在FPN 结构中加入由空洞卷积层组成的PMAC 模块能有效地提高文本检测能力,而循环收缩算法能有效分割密集文本。

表1 ICDAR2015 数据集实验结果及对比 %

图6 ICDAR2015 数据集上的可视化结果
2.4.2 CTW1500 数据集实验结果
在弯曲文本数据集CTW1500 上,FPPMAC 模型与SegLink、EAST 和PSENet 等模型的实验结果如表2 所示。可见,FPPMAC 模型的准确率最高,达到了89.17%。

表2 CTW1500 数据集实验结果及对比 %
图7 展示了CTW1500 数据集上的测试可视化结果,将检测到的文本区域在原始场景图片下方进行了展示。由图7 可见,自然场景中的密集文本被准确区分,长弯曲文本被用更贴合文本实例的多边形定位,由此解决了基于物体检测方法事先设置anchors 所导致的检测区域包含大量背景的问题。

图7 CTW1500 数据集上的测试可视化结果
由于FPPMAC 模型是在PSENet 模型架构的基础上扩展而得,为公平起见,本文在相同的实验平台上复现了PSENet,并以每秒刷新图片的帧数作为指标进行对比,如表3 所示。可以看出,FPPMAC模型并未使得检测效率下降,即意味着未增加额外的计算成本。

表3 性能比较
3 结语
本文构建了一个FPPMAC 模型,并提出了循环收缩算法,从而能有效检测自然场景下方向多变、形状不规则以及密集分布的文本。在未来的研究中,将进一步研究如何把FPPMAC 模型与文本识别模型结合起来,实现端到端的自然场景文本识别。
