基于问题增强的问题引导图像视觉问答算法*
2022-03-16王玉德任志伟
陈 婷,王玉德,任志伟
(曲阜师范大学,山东 曲阜 273165)
0 引言
视觉问答是以图片和关于图片的自由式、开放式的自然语言作为输入,智能地做出正确回答的过程。Antol 等人首次提出了自由式、开放式可视化问答系统的任务,提出了简单的基线模型[1]。在注意力机制被提出后,Lu 等人提出了协同注意力机制,交替学习图像注意和问题注意[2]。Yang 等人提出一种堆叠注意力机制,通过迭代学习,加强注意力[3]。Fukui 等人提出了多模态紧致双线性池 化(Multimodal Compact Bilinear pooling,MCB)注意力机制,对融合后的图像特征与文本特征进行池化分解[4]。在此基础上,Kim 和Yu 等人提出了多模低秩双线性(Multi-modal Low-rank Bilinear pooling,MLB)模型、多模态分解双线性(Multimodal Factorized Bilinear pooling,MFB)模型、多峰因子化高阶池化(Multi-modal Factorized High-order pooling,MFH)等融合模型[5,7]。Anderson 等人使用更快地区域卷积(Faster Region-Convolutional Neural Network,Faster R-CNN)方法并结合自底向上(bottom-up)的关注提取图像视觉特征[8,9]。Ben-Younes 等人提出多模态塔克融合(Multimodal Tucker Fusion,MUTAN)模型,利用塔克(Tucker)分解的方式对双线性模型的参数张量进行分解[10]。Nguyen 等人提出密集协同注意力模型(Dense symmetric co-attention,DSCA)方法,利用多层密集叠加的协同注意机制[11]。Thome 等人提出双线性超对角线融合(Bilinear Superdiagonal Fusion,BLOCK)模型,其参数张量使用块项分解来构造,优化复杂性和建模能力之间的权衡,并结合密集参数(Compact Parametrization,CP)和Tucker 分解的优势[12]。
当前,在视觉问答任务中加入视觉注意力是常用的优化视觉问答算法的解决方案,但这种方法忽略了问题特征与图像特征之间的推理关系。本文针对上述问题,提出基于增强问题有用信息的问题引导图像注意力机制的视觉图像问答算法。该算法在提取问题特征时加强有效信息,弱化冗余信息,更好地利用问题特征,从而加强图像与问题之间的推理关系,提高视觉问答整体的准确率。
1 视觉问答系统
视觉问答[13]可以看作一个多分类问题,即给定一张图片和图片相关的问题,视觉问答系统通过提取问题特征、图像特征,并通过注意力机制对图像不同区域进行注意力权重计算,然后将问题特征与图像特征进行融合,再将融合后的特征输入神经网络,分类生成推理答案。视觉问答系统的具体流程如图1 所示。
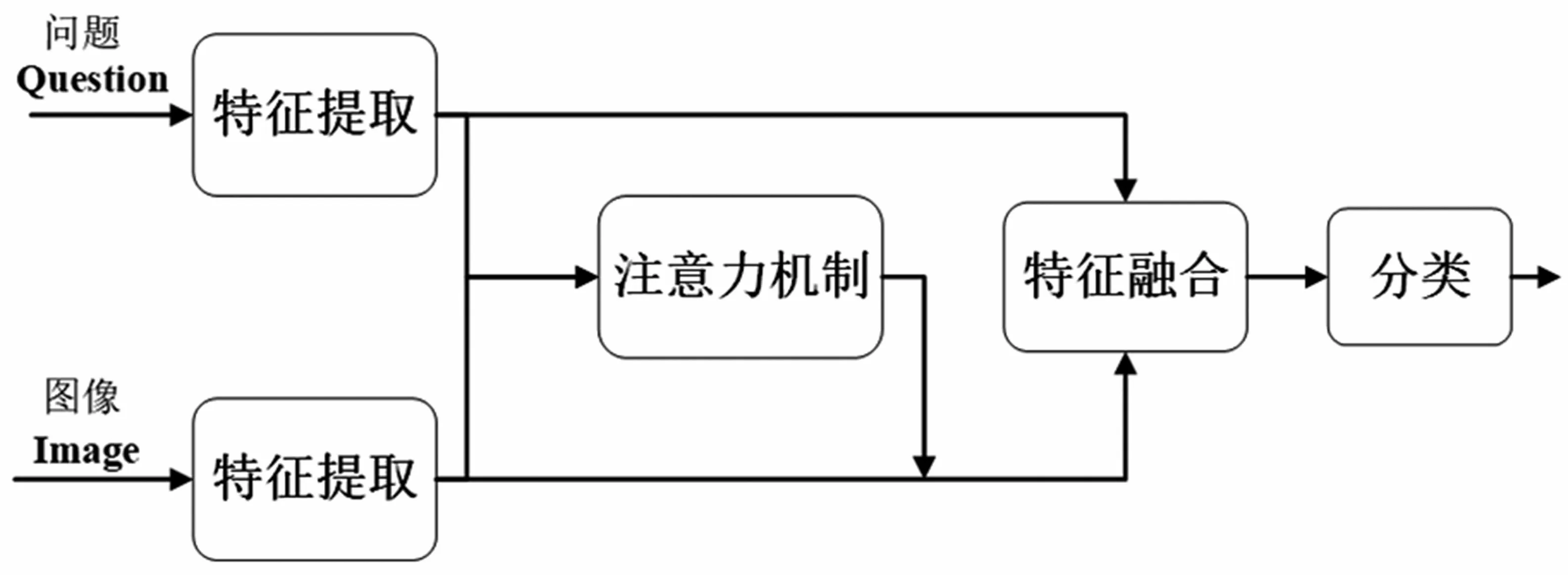
图1 视觉问答系统流程
1.1 问题特征提取
问题特征提取一般使用循环神经网络(Recurrent Neural Network,RNN),常用的网络结构有长短期记忆网络(Long-Short Term Memory,LSTM)[14,15]和门控循环单元(Gated Recurrent Unit,GRU)。
GRU 原理如图2,具体可表示为:

图2 GRU 原理

式中:[]表示两个向量相连;*表示矩阵的乘积;zt和rt分别为更新门和重置门;ht-1为上一时刻隐含层的输出;为当前的候选集;ht为当前隐含层的输出;xt为当前的输入;σ为sigmoid 函数;tanh 为激活函数。
与LSTM 神经网络相比较,GRU 将遗忘门和输入门合成了一个单一的更新门,混合了细胞状态和隐藏状态。
1.2 图像特征提取
图像特征的提取一般使用卷积神经网络(Convolutional Neural Networks,CNN),卷积神经网络由输入层、卷积层、采样层(池化)、全连接层、输出层构成。卷积层的功能是对输入数据进行特征提取;池化层的主要目的是通过降采样的方式,在不影响图像质量的情况下,压缩图片,减少参数;全连接层可以连接所有的特征,将输出值送给分类器。视觉问答任务中常用的卷积神经网络有视觉几何组(Visual Geometry Group,VGG)卷积网络、ResNet 残差神经网络、Faster R-CNN 网络。
1.3 注意力机制
注意力(Attention)机制是聚焦于局部信息的机制,如聚焦图像中的某一个图像区域。随着任务的变化,注意力区域往往会发生变化。从数学形式上看,attention 机制只是简单地对输入量根据重要程度分配不同的加权参数,这一机制模拟了人脑的认知模式,即根据实际需求而将有限的注意力聚焦于事物的关键部分,从而大大提高了神经网络的理解能力。
1.4 评价指标
视觉问答任务的评价指标主要是准确度(Accuracy,A)。对于VQA 数据集,每个问题有10 个答案,当预测答案在人类标注的答案中出现3次及以上,则对单个问题赋予全部得分。如公式(5),准确度越高代表模型对问题回答得越准确,分类能力越好。

式中:#表示预测答案与人类标注答案相同的个数。
2 增强的问题引导图像注意力机制
对于VQA 任务,问题特征的充分利用往往被忽略,针对一个问题,例如“What is the animal in the photo?”人类可以有意识地关注到“what”和“animal”这两个关键词,但是对于机器而言,无法准确判断哪个词才是主要信息;因此,加强关键信息的特征权重,可以有效地对问题特征加以利用。用加强后的问题引导图像,使图像特征更好地和问题特征进行匹配,从而提高视觉问答的准确率。基于问题增强的问题引导图像注意力机制包括问题特征强化、图像特征强化、问题引导。基于问题增强的问题引导图像注意力机制的模型结构如图3所示。
图3 中,FCNet 为非线性连接层,∑指的是加权求和,cat 指的是concat 运算。
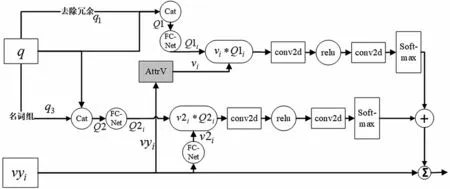
图3 基于问题增强的问题引导图像注意力机制结构
2.1 问题特征强化
从人类认知来讲,一个问题最重要的信息便是疑问词和名词,笔者期望机器能够更关注有用信息,忽略冗余信息,因此考虑将原始问题q中的“a”“an”“the”等冗余词去掉,得到新的问题输入q1,将q1与q进行concat 运算,即将q1与q融合后的特征Q1 经过非线性连接层fq1i得到Q1i:

式中:WN为权重归一化;LN为全连接层。
非线性连接层f将依次经过全连接运算,权重归一化(Weight Normalization,WN),ReLU激活函数。通常的梯度下降法直接将损失函数对权重求导得到梯度,然后以一定学习率,沿着梯度下降的方向更新权重。而WN将每个神经元权重的方向和长度解耦,即把参数权重分为v和g两部分,其中v代表方向,而g代表长度。然后将损失函数分别对这两部分求导,并更新它们的值。同时WN也是用来加速收敛的,通过对权重进行归一化可以抑制梯度,使梯度自稳定。
对于分类来说,笔者期望使类内相似度越小越好,类间相似度越大越好。因此,考虑到对问题进行分类时所有问题中都包含“什么”“怎么样”“在哪里”(“what”“how”“where”)等疑问词,这无疑缩小了不同问题的类间差距,为了解决这一问题,将问题中的疑问词去掉,这样就可以使问题特征最大化地聚焦在名词上。具体地,在q1的基础上去掉所有疑问词,引入新的问题输入q3,将q3与q进行concat 运算得到Q2,经过非线性连接层fq2i得到Q2i,表达式为:
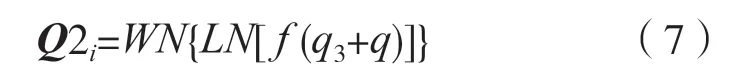
问题特征加强后,有用信息的占比增多,可以对图像起到更好的引导作用,同时增加了VQA 任务的可解释性。
2.2 图像特征强化
CNN 网络输出的图像特征vyi包含了每幅图像的所有目标特征。但是对于一幅图像,其隐含信息十分丰富,例如颜色、形状等特征属性。为了更好地利用图像的这些属性特征,笔者对图像特征进一步处理,如图3 中的AttrV 部分,其具体结构见图4,笔者将vyi经卷积运算依次提取图像特征,得到具有属性特征的vai,并将其送入Softmax 层进行预测。然后,将vai与vyi进行concat 连接。强化后的图像特征可表示为:

图4 AttrV 结构

这里的vi=concat[vyi,vai]。
2.3 问题引导
将图像特征向量vi与问题嵌入Q1i进行相似度计算,问题特征和其引导的图像特征之间匹配度越高,视觉问答系统的准确率也就越高。对经过相似度计算的特征进行卷积运算,提取更丰富的特征,并使用softmax 函数对注意力权重进行归一化,得到与位置相关的标量注意权重a1i,其计算方式为:
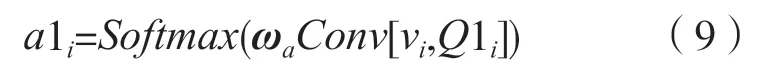
式中:ωa为学习的参数向量;Conv为卷积运算。
为了尽可能地扩大两个不同问题输入的区别,将图像特征在不损失原始特征的情况下经全连接运算得到v2i。
将Q2i和v2i进行与Q1i相同的相似度矩阵计算:
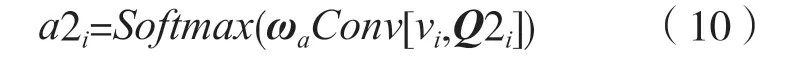
由于q2和q3携带的信息不同,因此得到的注意权重a对图像的注意位置侧重是不同的,为了最大限度注意到所需要的位置信息,将两次的注意权重求和:
轲左手把秦王袖,右手揕其胸,数之曰:“足下负燕日久,贪暴海内,不知厌足。于期无罪而夷其族。轲将海内报仇。今燕王母病,与轲促期。从吾计则生,不从则死。”秦王曰:“今日之事,从子计耳!乞听琴声而死。”召姬人鼓琴,琴声曰:“罗縠单衣,可掣而绝。八尺屏风,可超而越。鹿卢之剑,可负而拔。”轲不解音。秦王从琴声负剑拔之,于是奋袖超屏风而走。轲拔匕首擿之,决秦王,刃入铜柱,火出。秦王还断轲两手。轲因倚柱而笑,箕踞而骂曰:“吾坐轻易,为竖子所欺。燕国之不报,我事之不立哉!”

然后对每张图片的图像特征按照注意力权重ai进行归一化值加权求和,得到注意后的图像特征vl:

3 算法实现步骤
基于问题增强的问题引导图像视觉问答算法主要有问题特征提取、图像特征提取、问题引导图像注意力机制、特征融合和分类预测几个步骤:
(1)问题特征提取。设置候选答案的长度N,使用手套(Glove)词嵌入(Word Embedding)和GRU 的输出得到一个问题嵌入,设置问题的最大长度为n,小于n个单词的问题用零向量补充。将问题词向量通过GRU 神经网络,得到问题特征向量。
(2)图像特征提取。使用自底向上注意(bottom-up)提取的图像特征。
(3)问题引导图像注意力机制。将问题特征q和图像特征vyi分别送入问题引导图像注意力模块,获得带有权重注意力的图像特征vl。
(4)特征融合。将注意后的图像特征vl经过非线性层得到Vl,再将问题特征Q1i与Vl进行点乘运算:

(5)分类预测。将联合嵌入ℎ通过非线性层fℎ,然后通过线性映射wo来预测N个估计答案的分数s:

式中:σ是一个sigmoid 激活函数;wo是学习权重。
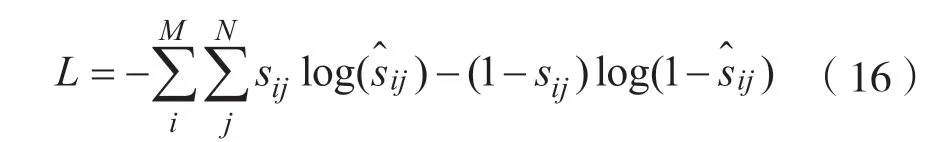
式中:索引i和j分别为M个训练问题和N个候选答案;s为label 中真实答案的准确率;为模型做出回答的准确性。
基于问题增强的问题引导图像视觉问答算法模型如图5。
图5中,FCNet为非线性连接层,FC为全连接层。

图5 模型结构
4 实验结果与分析
实验用11 GB 内存的NVIDIA GeForce GTX 1080Ti显卡,版本为CUDA11.1,Windows 操作系统的搭建基于Anconda3(64-bit)的Python3.6 环境Pytorch1.0。实验在VQA v2.0 训练集、验证集上训练,在testdev 集上测试。
VQA v2.0 数据集包括82 783 张训练图像、40 504 张验证图像、81 434 张测试图像。所有问题集的答案均由人工采集得到,问题-答案组被组织成3种回答类型,即是/否(Yes/No),数字(Number),其他(Other)。每个问题都是由10 个志愿者进行回答,有10 个候选答案,取10 个答案中出现次数最多的答案作为正确答案。
4.1 实验1:验证图像强化和问题强化算法的有效性
实验设置候选答案长度N=3 129,问题的最大长度为n=23,图像维度为2 048 维,使用Adamax优化策略,按阶段设置学习率。设置前4 个epoch学习步长lr=[0.000 5,0.001,0.001 5,0.002],4~10 个epoch 设置lr=[0.002],10 个epoch 后设置lr每2 个epoch 以0.25 的比率衰减,batch size 为256,迭代次数为20。实验结果取同条件下10 次实验结果的平均值,评价指标采用VQA 的准确度指标。实验结果如表1 所示。

表1 问题加强与图像加强在test-dev 上的实验结果 %
图6(a)为未对问题特征增强处理的系统结构图。图6(b)所示结构中,FC 模型加入了去掉冗余特征后的问题输入q1,未对图像特征进行加强处理,直接经过全连接网络输出与问题特征进行相似度矩阵计算。图6(c)所示为QGIA-q1 模型,是在AttrV 基础上,去掉冗余特征后的问题输入q1引导图像特征的系统结构图。
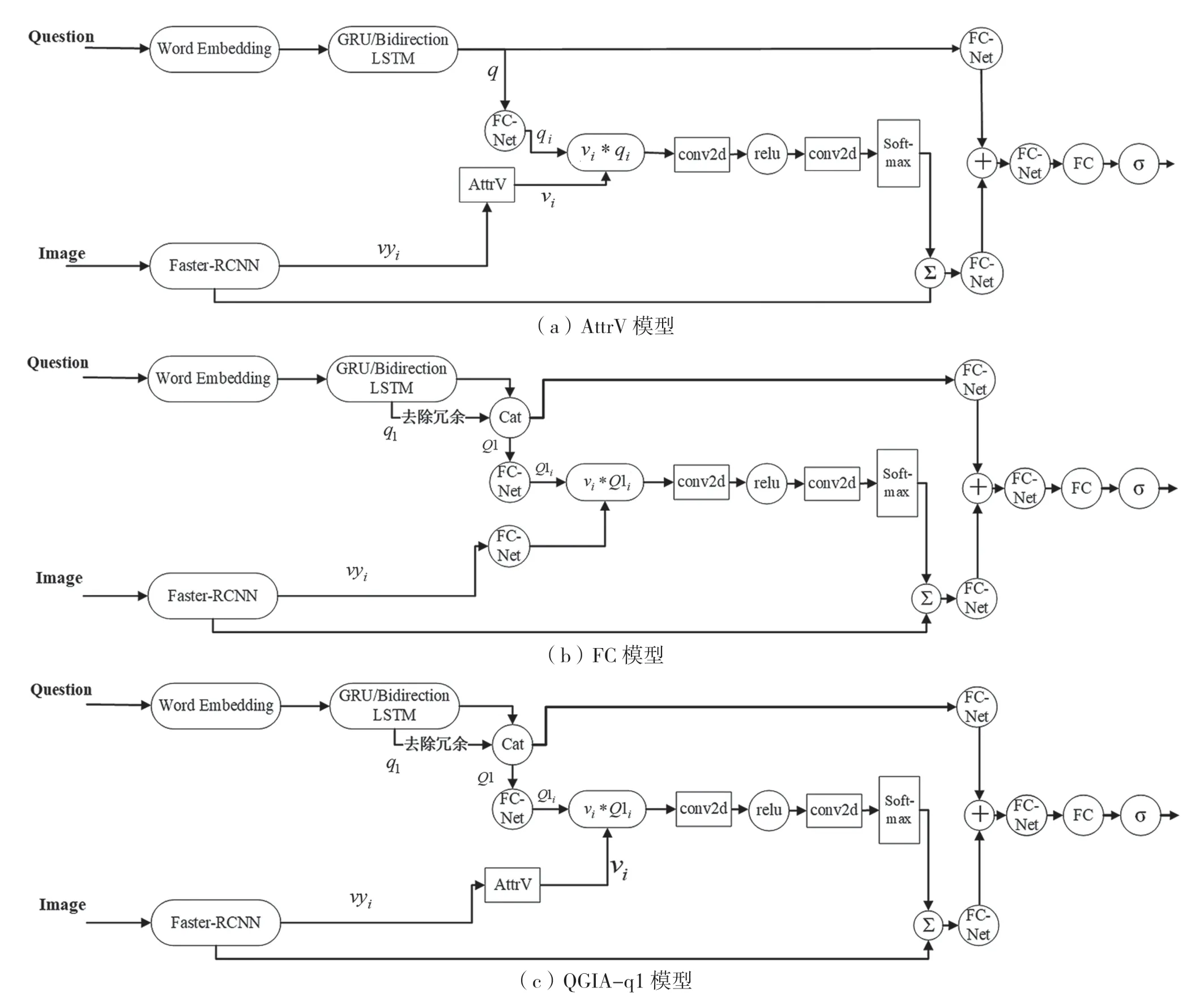
图6 图像强化和问题强化有效性验证模型
从表1 中可看出,对比AttrV 模型和QGIA-q1模型结果,引入问题增强q1后,模型整体准确率提高了0.25%。对比FC 模型和QGIA-q1 模型的实验结果,引入图像增强后,模型整体准确率提高了0.07%。
4.2 实验2:基于问题增强的问题引导注意力机制的算法实验
实验设置同实验1。模型基于相同的数据预处理模式,使用Faster R-CNN 提取特征,在QGIA-q1 模型基础上去掉冗余问题输入q3。
模型实验过程中的损失函数(loss)与训练准确率的变化情况如图7。从图7(a)中可以看出,模型在第16 个epoch 时训练准确率最高,之后趋于平稳。从图7(b)可以看出,损失随着epoch的增加稳步下降,说明模型不存在局部最优的现象。
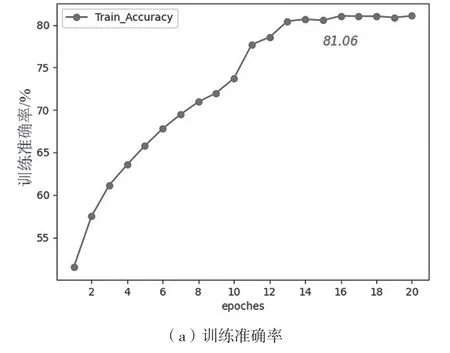
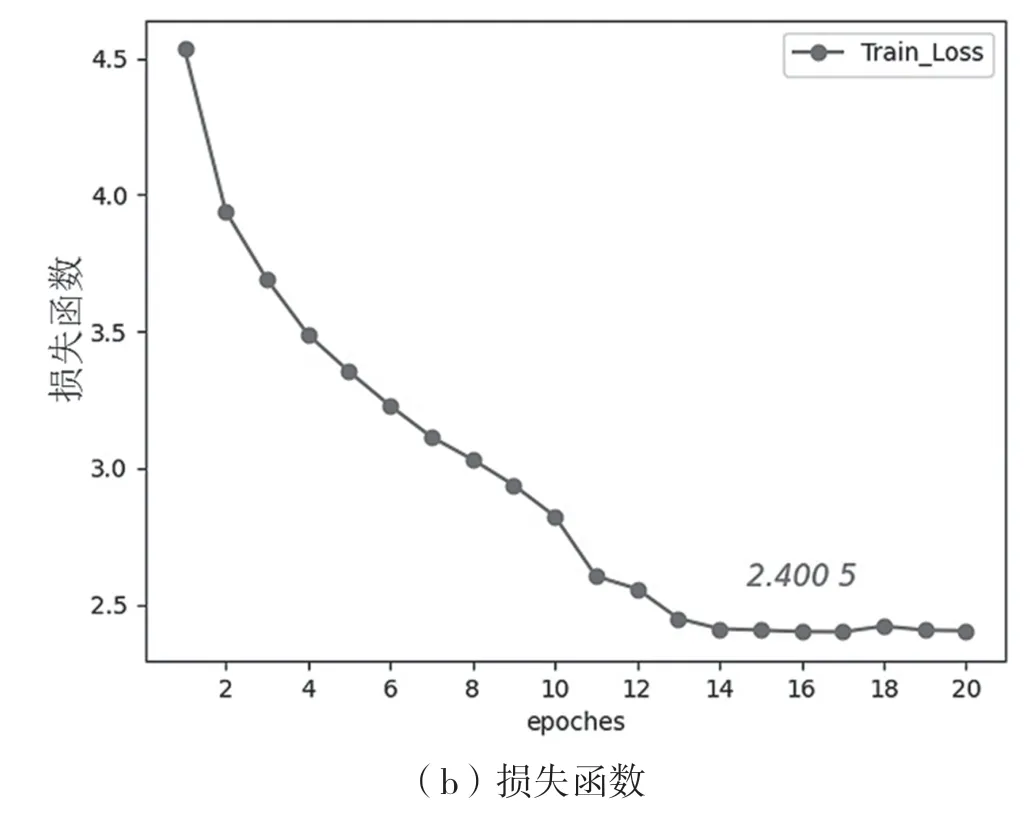
图7 训练准确率与损失函数
实验中,为检验论文提出算法的有效性,将论文提出算法与MFB 模型[6]、bottom-up 模型[8]、MUTAN 模型[10]、MLB 模型[5]、DSCA 模型[11]、BLOCK 模型[12]结果进行对比实验。实验结果如表2。

表2 基于问题增强的问题引导注意力机制模型与其他模型在test-dev 上实验结果的比较 %
从表2 中可以看出,论文提出的模型比MFB等模型高出0.31%~5.69%,对于二元问题(Yes/No)本文模型提升了0.22%~2.01%、Number 类问题提升了0.42%~11.05%,Other 类问题提升了0.36%~7.66%。
部分问答示例如图8 所示。图8(a)和图8(b),无论对于Yes/No 类,还是Number 类,加入问题引导后的模型都能做出准确的回答。但是在图片内容复杂,物体在图像中尺寸较小等情况下,特征提取时无法获得有效的信息,问答准确率比较低。如图8(c)问题“背景中有多少棵树?”,图片中背景复杂,算法不能准确做出回答。

图8 视觉问答实验结果展示
5 结语
针对视觉问答任务中输入图像特征与输入问题特征缺乏推理关系的问题,本文提出了增强问题特征的问题引导图像注意力机制。该机制通过去除冗余问题信息,加强有用的问题信息占比,并将完整的问题信息与强化的问题信息进行融合,通过计算问题特征与图像特征的相似度矩阵,实现问题特征对图像特征的引导作用。模型在VQA V2.0 数据集的Test-dev 上取得了67.89%的准确率。与模型BLOCK 相比,整体准确率提升了0.31%。此外,本文提出的基于问题增强的问题引导图像注意力机制也加强了对视觉问答任务的可解释性,为进一步提高机器视觉问答的准确率提供了理论支持。
