基于Bi-LSTM 的医学文本分词模型*
2022-03-16邵党国黄初升贺建峰易三莉
邵党国,黄初升,马 磊,贺建峰,易三莉
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引言
近年来随着信息技术在中国的蓬勃发展,针对医疗机构的信息系统已经得到广泛推广,医疗机构在引入信息系统后,积累了大量的中文医学文本数据[1]。目前医疗机构的信息系统中的医学文本主要以医学影像报告、病理报告、电子病历等形式存在,大多是以自然语言的形式进行记录和保存的,而将这些文本中的相关信息提取出来并加以利用,对医疗行业的发展有着巨大的意义[2]。
汉字是构成中文最基本的单位,在中文中汉字与汉字之间紧密排列,而相比于单个的汉字,词才是表征中文语义最精确的单位,但是中文中并没有明确的标记将一段话中的前后两词进行分隔,而中文分词的目的就是将中文文本基于某些标准划分为能够表征精确语义的词构成的序列[3]。
在中文的自然语言处理任务中,中文分词大都作为第一步的工作,分词的效果会直接影响后续的实体识别、语义分析、机器翻译、信息检索等自然语言处理相关工作的结果[4]。然而无论是传统的机器学习的分词方法还是基于深度学习的分词方法,其效果依赖于大规模的训练数据[5],目前中文分词领域开放的数据集大多为通用的分词数据集,其在各领域的分词任务上效果并不好。由于医学领域具有极强的专业性,获取大量的标记的中文医学领域的训练数据比较困难,所以传统架构的中文分词方法暂时还无法在医学领域分词上实现期望的结果。
针对以上问题,笔者提出了一种基于双向长短期记忆网络(Bi-directional Long-Short Term Memory,Bi-LSTM)的分词模型。通过引入开放的分词语料生成的预训练模型,与中文医学领域的分词预训练模型进行融合,构建出这种全新的分词模型。该模型在仅使用少量的中文医学领域标记数据的同时,获得了较好的分词效果。
1 相关工作
目前无论是传统的机器学习模型还是基于神经网络的深度学习模型,大部分中文分词的思想都是将中文分词问题视为对单个汉字字符的序列标注问题[6]。此外,在深度学习进入大众视野之前,就已有学者对中文分词任务进行了大量的研究。
1.1 传统的中文分词机器学习模型
传统的基于机器学习的中文分词模型分为基于字标注的学习和基于词特征的学习两大类[7]。基于字标注学习的方法始于Xue 等人[8]的研究,该工作通过使用位置标签(tag)来代表一个字在词中的位置,表达该字所携带的切分信息,从而将分词任务转化为字所在词中位置的序列标注学习任务。Low等人[9]继续完善了这一思想,将严格的串标注学习应用于分词。2004 年,Peng 等人[10]将条件随机场(Conditional Random Fields,CRF)引入中文分词学习,自此,CRF 的多个变种在深度学习时代之前成为了标准分词模型的主要构成部分。基于词特征的分词方法主要通过半条件随机场(semi-Markov Conditional Random Fields,semi-CRF)来实现,与CRF 不同,semi-CRF 通过将其特征函数定义在序列数据的某个段落上来捕捉词特征信息。Andrew[11]第一次将半条件随机场semi-CRF引入分词任务中,但是其性能却不甚理想。虽然后续仍有学者对其进行改善,但是考虑到semi-CRF 的训练相比标准的CRF 更耗时,并且也没有明显的优势,因此基于词特征的分词在后续的分词研究中并未成为主流。
1.2 基于深度学习的神经网络分词模型
随着深度学习在自然语言处理中不断取得突破,越来越多的研究人员也开始探索将其用于中文分词任务中。Zheng 等人[12]在2013 年首次使用深度学习技术解决中文分词任务,验证了深度学习模型应用到中文分词任务上的可行性。Chen 等人[13]基于长短期记忆网络(Long Short-Term Memory,LSTM)模型特有的记忆性,将其引入分词模型中来解决中文分词问题,充分发挥了该模型在长序列任务处理上的优势,获得了较好的分词效果。2016年,Yao 等人[14]提出了使用Bi-LSTM 模型完成中文分词任务,获得了非常不错的效果。
1.3 分词任务的标注方法
分词任务的标注需要体现汉字在一个词中具体的位置信息,针对中文分词任务,目前主流的标注法主要有2 词位标注法、4 词位标注法和6 词位标注法。这3 种方法的定义如表1 所示。

表1 中文分词标注方法
1.4 跨领域分词
随着计算机技术以及深度学习模型的发展,中文分词任务在准确率上有了明显的提升,但是中文分词任务面临着新的问题:未登录词的影响仍然存在,专业名词的识别失误在跨领域分词中尤为明显[15]。2018 年,Ma 等人[16]探讨了在Bi-LSTM 模型的基础上预训练字向量、Dropout 和调整超参数以达到最先进结果,实验证明最新的分词模型的错误大多由注释不一致问题或者词汇不足造成,并且也几乎无法通过调整模型结构来降低犯错的概率,因此使用外部词典或知识库非常重要。Zhang 等人[17]提出在神经网络的基础上结合字典进行分词,该方法可以解决对应领域词汇稀少引起的问题,并且当模型需要应用于不同领域时仅需添加额外的领域词典,其他参数可保持不变。
2 本文方法
本文提出的分词模型结构如图1 所示,由通用分词模型训练、模型测试和领域分词模型训练3 个部分构成。通用分词模型训练部分和领域分词模型训练部分,统称为模型训练部分,分别使用两种数据集在相同的模型结构下进行训练,得到对应的通用分词模型和领域分词模型。模型测试部分,对领域测试集分别使用两种模型对测试集进行标签预测,然后对两种模型得到的标签概率按权重比例λ进行权重组合,得到组合后新的标签概率,最后经过标签预测层,得到最后分词的结果。
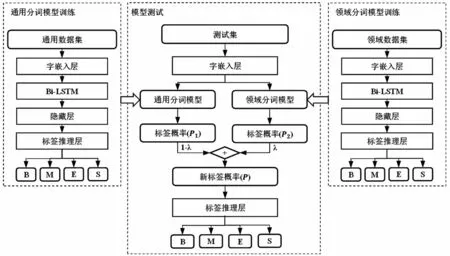
图1 本文模型框架
2.1 模型训练部分
本方法中需要同时准备一个通用分词模型以及一个领域分词模型,两者使用相同结构的Bi-LSTM分词模型进行训练,区别主要在于通用分词模型由通用数据集训练而来,领域分词模型则由领域数据集训练而来。
2.1.1 基于Bi-LSTM 的中文分词模型架构
基于Bi-LSTM 的中文分词模型主要由字嵌入层、神经网络层和标签推理层3 部分组成。具体架构如图2 所示。

图2 基于Bi-LSTM 的中文分词架构
2.1.2 字嵌入
使用深度学习模型进行自然语言处理相关任务,首先需要将输入的文本转化为向量,因为只有经过文本向量化,输入的文本才能变成计算机能够识别和理解的信息。文本向量化的方法主要有独热表示(one-hot representation)和分布式表示(distribute representation)两种。前者是用一个长向量来表示一个字或者词,向量的长度词典的大小相等,每个词对应的向量的分量只有一项为1,其他均为0,1的位置对应该字在词典中的位置。这种表示方法生成的词向量维度太高且数据过于稀疏,并且不能很好地反映词与词之间的相似性。
分布式表示[18]是将每一个词映射成相同长度的短向量,在所有词对应向量形成的向量空间中,每一个向量即为该空间中的一个点,两个词在这个空间中的“距离”就体现出了它们之间的语义相似性。该表示方法通常又称字嵌入(Embedding)。目前已有充足的研究证明,在自然语言处理领域,对神经网络训练之前将文本进行字嵌入操作,可以明显地提升训练的效果。
2.1.3 Bi-LSTM
循环神经网络(Recurrent Neural Network,RNN)是一种特殊的神经网络,其结构特点就是其神经元会在时序上传递信息,因此RNN 在序列数据的处理上有比较大的优势。由Hochreiter 等人[19]首先提出的LSTM 是一种改进的RNN 模型,通过其特有的结构,解决了传统RNN 在较长序列下容易出现的梯度消失和梯度爆炸等问题。LSTM 与传统RNN 的区别主要在于神经元内部结构不同,其神经元结构如图3 所示。
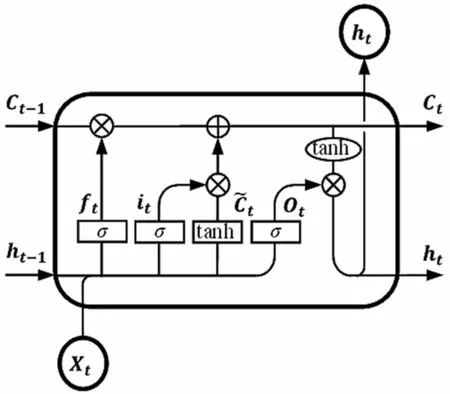
图3 LSTM 神经元结构
(1)细胞状态
图3 中穿过神经元顶部的水平线即代表细胞状态,细胞状态穿过了LSTM 链上的所有神经元,并且只有一些小的线性操作作用其上,因此整个链的信息在传递过程中可以保持相对稳定。
(2)遗忘门
遗忘门决定细胞状态在该神经元中丢弃的信息。遗忘门的输入为上一时刻的隐层状态ht-1和当前时刻的输入xt,遗忘门的输出用于决定上一时刻的隐层状态中需要被遗忘的信息。遗忘门门控状态ft的表达式为:

式中:σ为Sigmoid 激活函数;Wf为ft的权重矩阵;bf为ft的偏置。
(3)输入门
在本时刻需要在细胞状态中存入的信息是由输入门决定的,其包括输入门的门控状态it和候选值向量,具体的表达式为:

式中:Wi为it的权重矩阵;bi为it的偏置;WC为的权重矩阵;bC为的偏置。
在信息经过输入门后,细胞状态在本时刻的神经元中也随之更新完毕:
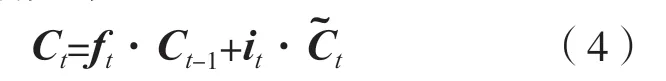
式中:Ct为本时刻的细胞状态;Ct-1为上一时刻的细胞状态。
(4)输出门
输出门决定细胞的输出。输出门的输入也是上一时刻的隐层状态ht-1和当前时刻的输入xt,在通过Sigmoid 层后得到输出门的门控状态Ot,Ot与经过tanh 函数处理更新后的细胞状态Ct相乘,结果即为本时刻神经元的输出,同时该输出又会作为隐层状态输入下一时刻的神经元中,具体的表达式为:

式中:WO为Ot的权重矩阵;bO为Ot的偏置;ht为隐层状态。
Bi-LSTM 神经网络[20]由两个结构相同、传播方向相反的LSTM 网络组成,这两个网络分别称为前向层和后向层。与LSTM 相比,Bi-LSTM 在继承其诸多优点的同时,还能同时在正方向和反方向上捕捉序列的信息,其具体结构如图4 所示。图4 中ib、ob、if、of分别代表后向层和前向层的输入和输出,wb和wf分别代表后向层和前向层神经元之间传递的信息,即隐藏状态和细胞状态。
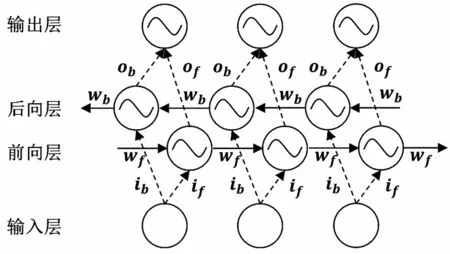
图4 Bi-LSTM 结构
Bi-LSTM 的最终输出由前向层和后向层的对应节点共同决定,其公式为:

式中:hft和hbt分别为前向层和后向层的输出;yt为Bi-LSTM 的最终输出;fft、ift、Oft,fbt、ibt、Obt分别为前向层和后向层遗忘层、输入层、输出层的门控状态;分别为前向层和后向层的候选值向量;Cft-1、Cbt-1分别为前向层和后向层上一时刻的细胞状态。
2.2 模型测试部分
2.2.1 标签概率权重组合
将测试集进行字嵌入操作后分别输入至通用分词模型和领域分词模型中,输出的结果即为两种模型对分词结果对应的标签的概率预测。对两种模型得到的标签概率进行权重组合,得到组合后新的标签概率。
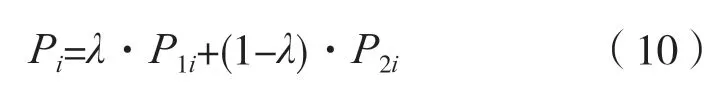
式中:P1i为使用领域数据训练模型预测该汉字标签为i的概率;P2i为通用数据模型预测该汉字标签为i的标签概率;λ为领域数据模型预测的权重比。
2.2.2 Viterbi 算法
维特比算法(Viterbi Algorithm)是动态规划算法中的一种,用于快速求解最佳路径的问题。笔者在标签预测层引入维特比算法对汉字对应的标签进行预测[21]。对于权重组合后的标签概率,笔者要寻找一条隐含状态序列,用它去生成指定的观测序列,使得这个观测序列的概率最大。计算最大路径的概率公式为:

δt(i)表示在时刻t,结束于隐藏状态i,同时满足观测序列(o1,o2,o3,…,ot)的最大路径概率。其递推公式为:
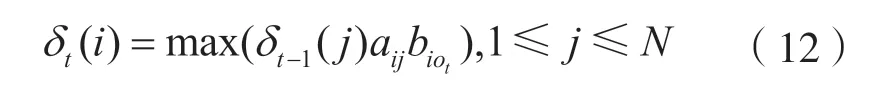
式中:aij为状态i到j的转移概率;biot为状态ot的观察概率。
笔者按照维特比算法中的思路从δ1(i)开始起步,一步一步推导至δt(i),求得最大的概率,同时在递推的过程中,在每一个时间点t都记录好上一个时间点t-1 的隐含状态,即可获得最优的隐含状态序列。
笔者在模型测试的标签预测层利用维特比算法,对各汉字的标签进行计算得到各汉字所属标签的最终概率,将最大概率的标签作为预测标签,从而完成中文分词。
3 实验及分析
3.1 实验数据
本次实验中通用数据集来自SIGHAN 第二届国际中文分词大赛(SIGHAN The Second International Chinese Word Segmentation Bakeoff)的微软研究院(Microsoft Research,MSR)语料。中文医学领域数据(Chinese Medical Corpus,CMC)语料来自“‘万创杯’中医药天池大数据竞赛——中药说明书实体识别挑战”所提供的训练集,其中包括1 000 条药物说明书,以及对应的实体标注。将数据集中的实体内容提取作为领域词典,使用jieba 分词导入自定义词典的功能导入领域词典后对其进行分词。最后通过人工对分词结果进行检查,得到一个标准的中文医学语料。随机抽取该语料中的70%作为领域分词模型的训练集,剩下的作为测试集。数据详情如表2 所示。
通过对企业的经营活动进行有效监督,内部审计能够帮助企业预防风险,降低损失。从企业的价值方面来看,如果企业使用内部审计花费的成本小于能够预防或减少的损失的价值时,企业的价值就能增加,即内部审计带来的直接价值。同时,内部审计的存在对其他部门和企业的经营管理人员都会起到一定的震慑作用,无论内部审计是否发生问题,企业内部都不得不努力地改善工作的秩序和效率,提升绩效,也能够带动企业价值的增加,成为一种内部审计带来的间接价值。由此可见,内部审计既是企业改善治理效果的有效途径,同时也是增加企业价值的有效方法。

表2 实验数据统计
所有的数据集的标注方法均为4 词位标注法。表3 为两种数据集中的标注示例。

表3 4 词位标注样例
3.2 实验设置
本文实验软件环境为python 3.6,模型基于pytorch1.8.0 深度学习框架和numpy、pandas、sklearn等第三方库。使用torch.nn.Embedding 模块对数据集进行字嵌入操作。其他参数和设置如表4 所示。

表4 该处填入表的名称
3.3 评价指标
本实验使用F1 值作为主要评价指标,同时使用精确率(Precision rate,P)、召回率(Recall rate,R)作为参考,其计算方式为:

式中:A表示正确分词的单词的数量;B表示分词总数;C表示标准分词集中的词数。
3.4 实验设计
3.4.1 模型预训练
本实验涉及两个预训练模型,分别使用两种数据集在相同结构的Bi_LSTM 模型下训练获得。
(1)通用分词模型:使用MSR 数据集作为训练集获得的MSR_Bi_LSTM 模型。
(2)领域分词模型:使用CMC 数据集的训练集获得的CMC_Bi_LSTM 模型。
权重比例λ用于调节MSR_Bi_LSTM 和CMC_Bi_LSTM 的预测结果之间的权重。图5 展示了选择不同λ得到的对应分词实验的F1 值。虽然在不同的迭代次数下得到最好实验结果的λ值有所不同,但是在迭代30 轮的训练模型下,当λ=0.8 时取得了最好的效果。表5 为迭代30 轮的分词模型在不同λ下的预测结果,此词的准确率、召回率和F1 值,分别为95.49%,95.44%和95.46%。因此将λ固定为0.8 来进行后续的实验。

图5 不同权重比在不同迭代数下的F1 值
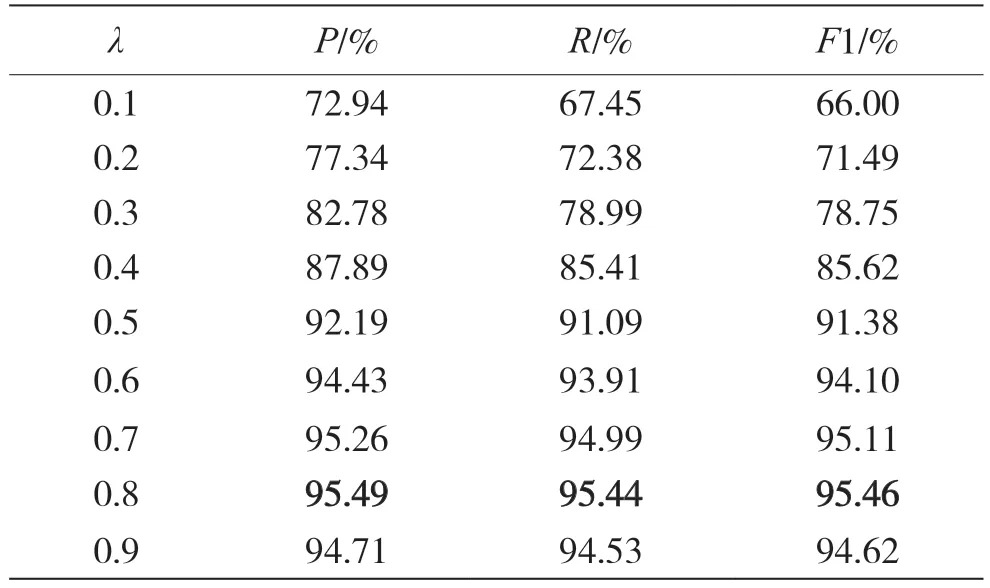
表5 不同权重比对应的实验结果
3.4.3 标签转移概率矩阵的确定
本实验中标签推理层使用维特比算法进行标签预测,需要对标签转移概率进行确定。对于本文所选的标注方法,其标签转移的可能性仅存在SS、SB,BM、BE,MM、ME,ES、EB 几种情况。在上文实验中均采用等概率形式的标签转移概率进行实验,即所有转移概率设为0.5。然而等概率形式的标签转移概率并不一定能使实验效果最好。
在本实验中,通过采用固定其他3 个标签的转移概率,变换当前标签的转移概率进行实验来确定当前标签的最佳标签转移概率。表6 和表7 为最后得到的最优标签转移概率矩阵以及对应的实验结果。可以看出,使用最优转移概率所取得的实验结果要优于使用等概率的实验结果。

表6 最优标签转移概率矩阵

表7 最优标签转移概率实验结果
3.5 对比实验
为验证本文所提模型的有效性,本文分别选择MSR 数据集、CMC 数据集以及将两者合并的MSR&CMC 数据集使用BiLSTM-CRF 模型进行实验作为对比。在确保模型参数一致的情况下,记录的实验结果如表8 所示。
根据表8 的实验结果可知,分词模型MSR_BiLSTM-CRF 在跨领域的分词任务上效果并不好,并且对比CMC_BiLSTM-CRF 与MSR&CMC_BiLSTM-CRF 的实验结果可知,在医学领域的分词任务中,通过并入其他领域的训练数据对训练集进行扩充,可略微提升最后的分词效果。本文所提出的模型相比以上的分词模型在准确率、召回率和F1 值上均获得了最优的结果。

表8 实验结果对比 %
表9 列举了测试集中3 个例句在对比实验中的结果。从分词结果上可看出,传统的跨领域的分词模型MSR_BiLSTM-CRF 在中文医学领域上表现很差,对于未登录词没办法生成正确的分词结果,例如例1 中将“失血性休克”切分为“失/血性/休克”。

表9 实验结果示例
使用中文医学领域训练集训练所得的分词模型CMC_BiLSTM-CRF,能够更加正确地切分出该领域的专业词汇,但是由于训练集样本较小,在测试时还是会出现如例2 中将“升高血压”切分为“升/高血压”的情况。将两种数据集合并后训练得出的MSR&CMC_BiLSTM-CRF 模型也获得了不错的切分结果,但是由于两个数据集数据量的悬殊,在出现歧义的句子中的分词结果会偏向于数据量较大的数据集中的样本,如例3中的“可抑制氢化可的松……”被切分为了“可抑/制氢/化可的松/……”,本文模型由于能够通过权值λ来控制两个数据集所训练的模型对预测结果的影响,所以能有效地避免该问题。
综上所述,在小样本的中文医学领域的分词任务上,利用本文提出的分词模型,通过引入跨领域的通用分词模型,能够有效地弥补因为训练样本不足而导致分词结果较差的问题。在调整标签转移概率以及权值等参数后获得的最优结果,相比传统的BiLSTM-CRF 分词模型,在正确率、召回率和F1值上均有显著提升。
4 结论
针对医学领域的中文分词问题,本文提出了一种分别将通用数据集以及医学领域数据集进行模型训练,再将训练所得模型结合形成的全新分词模型。实验结果证明,该模型能充分发挥两种模型在各自领域的优势,提升分词的效果。在仅有少量医学领域标注数据的前提下,该模型相比传统的分词方法在分词效果上有比较显著的提升。
由于条件所限,本文并未将工作重心放在模型选择上,在实验的参数设置、最优转移概率的选择上也比较粗糙。在下一步的研究中,笔者计划引入预训练的词向量,以门控循环单元(Gated Recurrent Unit,GRU)、有序神经元长短时记忆神经网络(Ordered Neurons Long Short-Term Memory,ONLSTM)等LSTM 变种单元,对模型进行优化,同时针对实验中的参数的优化做进一步的探索。
