机器学习在抑郁症辅助诊断中的应用进展
2022-03-14刁云恒王慧颖董娇朱艺菡邵秋静冯来鹏王长虹
刁云恒,王慧颖,董娇,朱艺菡,邵秋静,冯来鹏,王长虹,4
1.新乡医学院第二附属医院(河南省精神病医院),河南新乡 453002;2.新乡医学院河南省生物精神病学重点实验室,河南新乡 453002;3.新乡医学院第二临床学院,河南新乡 453002;4.河南省心理援助云平台及应用工程研究中心,河南新乡 453002
前言
抑郁症是一种严重影响患者社会功能的常见精神疾病[1]。世界卫生组织调查发现在重大经济负担疾病中抑郁症位列第3 位,预计将在2030年成为第1位[2]。抑郁症症状多样、病程较长、复发率高且治疗效果个体差异大,其检测、诊断经常给临床医生带来挑战,迫切需要客观、准确率高的辅助诊断方法[2]。机器学习是一种分析多维数据的技术,用于构建具有从数据中自动学习能力的系统[3]。研究人员可以利用机器学习技术对复杂的生物信息学数据进行快速且可扩展的分析[4]。在精神健康领域中,研究发现机器学习技术结合精神健康数据可以增进对患者精神状况的了解,进而可以改善患者的预后[5]。机器学习算法分为3类:有监督学习、无监督学习、半监督学习[3]。在有监督学习中,利用带有已知标签的数据构建模型,该模型可以预测新数据的标签,例如基于以往电子邮件的标记将新的电子邮件分类为垃圾邮件[6]。无监督学习利用数学技术对数据进行聚类以提供新的思路,例如网络论坛根据论坛言论自动标记表达的主题[7]。相比之下,半监督学习技术基于已知标签和未知标签数据的组合开发模型[8],由于标记的数据集可能稀少或昂贵,此类技术可通过使用未标记的数据增强监督模型。在使用过程中一般采用多种算法进行建模,确定最适合特定数据集和任务的具体算法。
本文系统性分析了2015年1月至2021年4月间机器学习在抑郁症辅助诊断应用方面的文献,重点关注不同数据背景使用机器学习技术的进展以及潜在的研究方向。首先,概述文献的搜索策略与机器学习在该领域的通用研究流程;然后,以机器学习在不同种类的临床数据上的研究对文献进行总结;最后,探讨现有的研究成果,并提出该领域研究的新思路。
1 文献检索策略与机器学习流程概述
1.1 文献检索策略
本文搜索策略改编自Luo 等[4]的文章。使用关键词“机器学习”、“抑郁症”和“诊断”在数据库进行检索以确定相关文献。初步检索结果为293篇,按标准筛选后剩余75篇(图1)。
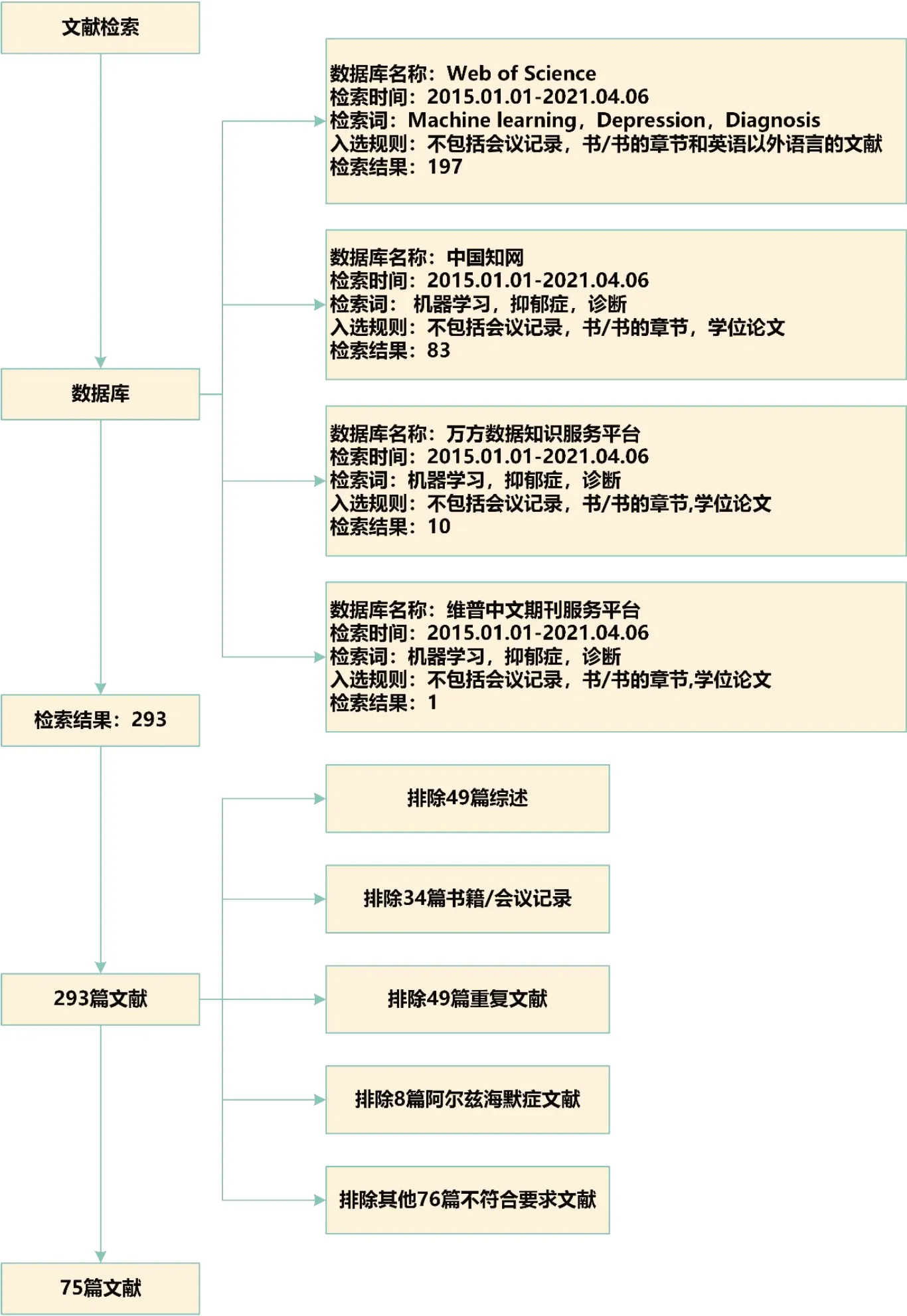
图1 检索流程图Figure 1 Retrieval process
1.2 机器学习流程概述
1.2.1 数据收集本文分析了筛选出的75 篇文章使用的数据,发现机器学习在抑郁症辅助诊断领域使用最多的数据是脑影像数据,其次是电生理数据(图2A)。在脑影像数据中使用最多的特征数据来源是磁共振成像(MRI),这可能是因为MRI 相对于其他脑影像数据,可获得的数据客观且多,且相对于功能性磁共振成像(fMRI)成本较低[9]。在电生理数据中应用最多的特征来源是脑电图(EEG),可能是因为EEG 相对于其他电生理数据,平衡了数据获取难度和数据可信度[10]。
1.2.2 特征工程数据的质量直接决定模型的预测效度和泛化能力[11]。在收集数据完成后,还需要对原始数据进行数据整理,如对缺失值、重复值、离群值进行处理,对数据进行归一化和标准化[12-13]。如果直接使用原始数据,可能会降低模型效度。数据整理后对其进行探索性分析,探索数据中的趋势和关系。根据数据进行特征选择,利用特征之间的关系,选择与因变量关系最为紧密的自变量作为输入特征。最后,对数据集进行分割,创建训练数据集和测试数据集。本文通过统计检索的文献发现,验证模型使用最多的方法是10倍交叉验证和5倍交叉验证(图2B)。
1.2.3 模型选择与训练在检索结果文献中,使用占比最高的机器学习算法是支持向量机(SVM)算法(图2C)。SVM 是建立在统计学习理论VC 维(Vapnik-ChervonenkisDimension)理论和结构风险最小化原理基础上的机器学习方法,它在解决小样本、非线性和高维模式识别问题中表现出许多特有的优势,并在很大程度上克服了“维数灾难”和“过学习”等问题[14]。医学数据集收集难度大,结构化数据少,导致医学数据集的数据量偏小,而SVM 算法恰恰适合小样本数据集,这也是SVM 在医学数据集中使用频次高的原因之一。
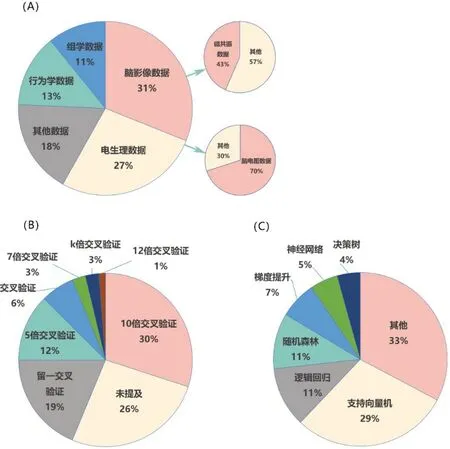
图2 机器学习在抑郁症研究中通用流程Figure 2 General process of machine learning in depression research
1.2.4 模型评估评估一个模型有很多标准,单一标准很难说明模型的优劣。对于分类问题常用评价指标有准确率、平均准确率、对数损失函数、精确率、召回率、曲线下面积(AUC)等,评价回归模型常用指标为均方根差、平均绝对误差、均方误差等。
1.2.5 小结从数据收集、特征工程、模型选择与训练到模型评估,本文总结了机器学习在抑郁症辅助诊断中应用流程(图3),每一步都有多种处理方法,研究需要根据数据特点和研究目的,选择最适合的处理方法。建议在流程中的每一步都要尝试使用多种方法处理,对比不同方法效果,选择最适合研究的方法。

图3 机器学习流程图Figure 3 Flowchart of machine learning
2 机器学习在抑郁症辅助诊断中的应用
2.1 基于脑影像数据的抑郁症辅助诊断
抑郁症的脑影像研究主要分为脑结构、脑功能及脑代谢影像研究。脑功能影像研究主要集中于额叶[15-17]、颞叶[18]、杏仁核[19]、扣带回[20]等处的功能障碍,fMRI 是目前研究脑功能影像的主要工具。近年来,研究者利用抑郁症患者的脑功能影像做了大量研究[21-26]。其中较为典型的是Bhaumik 等[27]基于左侧后扣带回皮质和右侧背外侧前额皮层的特征,利用SVM算法对重度抑郁症患者和健康对照者进行区分,准确率为76.1%;同样是利用SVM 算法,Yan等[28]基于静息状态脑功能网络连接分析数据区分抑郁症患者与健康对照组,准确率达到0.991 3。使用同样的方法,利用不同的特征区分抑郁症准确率大不相同,这提示在抑郁症辅助诊断的研究过程中特征的选取尤为重要。上述研究主要是集中在利用抑郁症患者脑功能影像数据,选择左额叶、颞叶、杏仁核、扣带回等处的功能障碍其中一项或多项作为抑郁症辅助诊断的特征,研究内容差异较小。但是基于抑郁症患者的脑结构影像和脑代谢影像研究却较少,目前关于抑郁症的脑结构影像学研究主要集中于额叶、基底节、扣带回、海马及大脑皮层其他脑区[29],研究工具常为CT 和MRI 等,脑代谢影像数据研究主要集中于海马区,前额叶、前颞叶、扣带回、尾状核等[30],研究工具常为PET、磁共振波谱成像及单光子发射断层成像等。未来的研究者可以尝试使用抑郁症患者的脑结构影像和脑代谢影像数据,仿照前者利用脑功能影像数据进行抑郁症辅助诊断的研究方法,选择适当的特征进行研究。除此之外,脑影像大多以图像为信息的载体,而机器学习中的卷积神经网络算法非常适合图像数据的处理,卷积神经网络相对于传统机器学习算法,具有权值共享、局部区域连接、降采样等特点[31],可以自动提取图像特征进行抑郁症辅助诊断,相对于前者一些研究特定选择一些特征,这种方法更加客观,且可能发现抑郁症更多的脑影像生物标记物。
2.2 基于电生理数据的抑郁症辅助诊断
近年来,除了利用fMRI辅助诊断抑郁症外,电生理数据辅助抑郁症的诊断也得到了大量研究[32-33]。脑电信号具有时间分辨率高、方便易做等特点,深受研究者青睐[34]。相关电生理研究主要包括脑电、心电、皮电、胃电、眼电、体温等[35]。在本文检索结果中发现,脑电信号使用频率最高,包括EEG[36-39]、P300[40]、脑磁图[41-42],其次是眼电数据,包括眼动信号[43-46],心电数据,包括EDA[47]、睡眠时心率[48]。在电生理数据研究中,目前准确率最高的是Acharya等[39]利用深度卷积神经网络构建的模型,该模型利用脑电信号对抑郁进行识别,准确率高达96%。相对于其他关于抑郁症电生理抑郁症辅助诊断的研究,Acharya 等研究准确率高的原因之一可能是因为选用了较为高级的机器学习算法,但是卷积神经网络适合数据量较大的图像数据,提示研究要根据数据类型和数据量选择机器学习算法。眼动数据和睡眠数据是客观指标,相对于传统主观数据具有更高的可信度和说服力。研究者通过眼动数据中的瞳孔大小、注视位置、注视时间等特征,与机器学习算法相结合,建立抑郁症患者预测模型,准确率较高,且数据获取相对成本更低[49]。抑郁症患者多伴有睡眠障碍[50]。研究表明睡眠期间心率异常与神经-心脏调节功能受损有关,这可能为抑郁症的生理睡眠特征提供新的解释[51]。这也提示通过睡眠期间心率变化结合机器学习区分抑郁症患者和健康对照组,是非常新颖且有潜力的一种研究方法。电生理数据在临床上是辅助医生诊断的一个重要指标,通过机器学习与电生理数据结合预测抑郁症患者的准确率来看,脑电数据在机器学习抑郁症辅助诊断中潜力巨大。本文还发现研究者选择合适的新型机器算法构建模型时,性能会高于传统机器学习算法[39],所以选择机器学习算法建模时,除了使用传统机器学习算法之外,也可以尝试使用合适的新型机器学习算法提高模型性能。
2.3 基于组学数据的抑郁症辅助诊断
随着测序技术的不断升级,测序成本逐渐降低,随即而来的是组学数据的增加,组学包括基因组学、转录组学、表观基因组学、蛋白质组学、代谢组学和其他组学(如脂质组学、宏基因组学、糖组学、连接组学、细胞组学,食物组学等)[52]。有研究者尝试使用组学数据构建区分抑郁症患者的模型,如Bhak 团队[53]使用基因组学和转录组学数据构建模型,模型区分抑郁症患者的准确率最高达到92.6%。除了构建区分抑郁症患者模型之外,也有研究者通过机器学习算法筛选生物标志物,如Dipnall 等[54]利用机器学习增强回归算法和逻辑回归算法,在国家健康与营养检查研究(2009-2010)中确定了与抑郁症相关的3 个关键生物标志物,分别是红细胞分布宽度、血糖和总胆红素。 Schultebraucks[55]、Takahashi[56]和Song[57]等利用随机森林和SVM 算法从外周血和代谢物中筛选出预测诊断最佳特征集。通过总结基于组学数据的抑郁症辅助诊断可以发现,机器学习在抑郁症领域应用时,不仅可以建模进行辅助诊断,还可以进行筛选生物标记物,这对于数据量大、数据维度高、序列化的组学数据来说,是一种较为适合的数据分析方法。
2.4 基于行为数据的抑郁症辅助诊断
行为数据,如表情和声音,较其他数据更容易解释。研究者基于视频[58-59]、音频[60]、步态[61]对抑郁症进行诊断,在数据易获取的基础上,模型准确率也较高。研究表明抑郁症患者在行为和语言特征表达上与健康对照显著不同[62-64]。Mastoras 等[65]利用与打字有关的特征区分健康对照和抑郁症患者。Herzog等[66]利用社交媒体上用户生成的文本帖子中提取语言特征,并使用多种机器学习技术(SVM 和逻辑回归)将其分类为健康对照、抑郁和产后抑郁症,该模型用于抑郁症内容识别的准确度为91.7%,而用于产后抑郁症预测的准确度则高达86.9%。除此之外,Razavi 等[67]根据移动设备上拨打和接听电话的时间和发送短信的数量进行区分抑郁症患者,他们发现当特征集中加入包括参与者的年龄和性别时,模型的准确率会提高。这提示样本量大小和准确率有很大关系,模型准确率一般会随着样本量增大而增高。行为数据是临床上评判抑郁症患者的重要辅助指标[62-63]。通常来说抑郁症患者表情较为负面,交流较少[62]。研究者们正是通过抑郁症患者和正常人行为数据的区别,提取特征,对抑郁症患者进行辅助诊断。随着手机和可穿戴设备(如智能手表)的普及,行为数据的收集越来越方便,研究者们可以利用机器学习技术,通过收集特定行为数据,对用户精神状态进行实时评估。
2.5 基于多模态数据的抑郁症辅助诊断
除了使用单一的生理或行为数据辅助抑郁症诊断,也有很多研究尝试使用多模态数据进行诊断[68-72],如使用音频、视频、语言和睡眠数据区分正常人与抑郁症患者[73],F1得分(统计学中用来衡量二分类模型精确度的一种指标,它同时兼顾了分类模型的精确率和召回率)最高达到87.7%,基于表达、声音和语言(文本)的多模态辅助诊断重度抑郁症患者[74-75],F1 得分最高为83.0%。相对于单模态数据,多模态数据具有更多的特征,能够更加全面地描述抑郁症病人的症状表现。机器学习算法能够提取多模态数据更多深层次的特征,建立更加精确的预测模型。但是相对于单模态数据来说,多模态数据的处理更加困难。Mellem 等[76]使用一种高效、数据驱动的特征选择方法,从这些高维数据中识别出最具预测性的特征,这种方法优化了建模,解释了3 个症状领域65%~90%的差异,而没有使用特征选择方法的差异只有22%,这表明适当的特征筛选对模型的精度影响很大。尽管多模态数据的使用较为繁杂,但使用多模态数据是未来机器学习在抑郁症辅助诊断中应用的重要趋势。
3 总结与展望
本文旨在系统性分析2015年1月~2021年4月间关于机器学习应用于抑郁症诊断的文献,总结机器学习方法在临床抑郁症诊断实践中的应用。在抑郁症诊疗领域,机器学习技术主要应用在抑郁症的识别及抑郁症治疗的疗效预测。在研究使用的数据选择方面,研究者大部分是选择脑影像数据与电生理数据做相关的研究,也有少部分研究者开始尝试使用组学数据、行为数据和多模态数据。在机器学习算法的选择方面,目前的研究主要还是基于机器学习传统算法,如SVM、随机森林、决策树、K 近邻算法等。
作为一个新兴领域,本领域的研究尚有不足。首先,机器学习在抑郁症辅助诊断的研究不够全面,从上述系统分析结果来看,机器学习关于抑郁症的预后鲜有研究,未来学者可以尝试这方面的相关研究。其次,机器学习算法的优势没有充分利用。在机器学习辅助诊断应用方面,大部分研究集中在优化模型预测结果的准确率。除了提高模型的性能之外,研究者可以利用机器学习模型的可解释性,对使用的数据进行充分利用,如当使用基因组学数据进行研究时,可以利用机器学习模型进行特征重要度排行,并对排行高的特征进行生物信息学分析,探究其生物功能,并寻找新的作用位点、基因和通路。最后,抑郁症辅助诊断的研究目前大多使用传统机器学习算法。研究者可以尝试使用机器学习的子领域-深度学习算法,如卷积神经网络、循环神经网络、对抗生成网络等。深度学习算法较传统机器学习算法特征提取能力更强,在机器学习模型上表现更好,要在适合自己数据的基础上,选择更加新颖、性能更强的机器学习算法。
在抑郁症辅助诊断领域使用机器学习技术时,还有一些需要面临的挑战。首先,机器学习模型的表现不可避免地受到使用的数据集大小以及质量的影响。其次,机器学习技术需要使用医学数据集,可能会威胁到个人隐私,造成医疗数据泄露以及伦理问题,这需要研究人员、临床医生以及数据主人之间有更多的合作共享和协调数据,以最大限度地发挥模型的效用。