基于TrAdaBoost算法的近红外光谱模型传递研究
2022-03-14刘翠玲徐金阳孙晓荣张善哲昝佳睿
刘翠玲 徐金阳 孙晓荣 张善哲 昝佳睿
(1.北京工商大学人工智能学院, 北京 100048; 2.北京工商大学食品安全大数据技术北京市重点实验室, 北京 100048)
0 引言
随着近红外(Near infrared,NIR)光谱学的发展,近红外光谱技术已成功地应用于食品、医药和农业等许多领域[1-4]。然而,由于仪器的多样性,所建立的校正模型已经不适用于新样本,但是重新建立校正模型需要大量的工作和时间。模型传递(Calibration transfer)为这类问题的解决提供了可行途径,其本质是克服样本在不同仪器间测量信号的不一致性,使得主机建立的校正模型可以用于其他仪器[5-6]。
近年来,国内外学者对模型传递在食品安全领域的应用进行了大量研究。刘锐等[7]使用直接标准化算法(Direct standardized,DS)和分段直接标准化(Piecewise direct standardization,PDS)对牛奶的成分进行模型传递研究。赵政[8]将斜率截距(Slope/bias,S/B)算法应用到新鲜度猪肉的挥发性和盐基氮原子含量的模型传递。CHEN等[9]提出了一种基于极限学习机自编码器的模型传递方法(Transfer via extreme learning machine auto-encoder method,TEAM),通过对玉米、烟草、药品数据集的实验证明其预测性能较好。这些传统算法都成功将校正模型进行传递并取得不错效果,但存在参数设置复杂、效率低等缺点。
随着计算机技术的快速发展,迁移学习(Transfer learning)逐渐成为研究热点,其核心思想是将某个领域上学习到的知识迁移到不同但相关的领域中[10-11]。这与模型传递将主机建立的校正模型迁移到从机上的思路十分相近,所以迁移学习为模型传递提供了一种新思路。但现阶段迁移学习主要用于图像[12-13]、文本[14]、语义[15]等方面,戴文渊[16]提出TrAdaBoost算法并成功将其应用到跨领域的文本分类。迁移学习具有数据小、效率高和鲁棒性较好等优点[17],但其在模型传递领域的应用却鲜有报道。
本文采用TrAdaBoost算法,并结合极限学习机(Extreme learning machine,ELM)[18]建立传递模型,实现食用油酸值的校正模型在不同仪器之间传递。并与直接标准化算法(DS)、基于极限学习机自编码器的模型传递算法(TEAM)和缺损数据重构算法(Missing data recovery,MDR)[19]进行对比研究,以期将迁移学习更好地应用于模型传递领域。
1 材料与方法
1.1 材料
实验食用油样本来源于北京古船食品有限公司,选择了5种食用油(玉米油、芝麻香油、大豆油、橄榄油、小磨香油)共计129个样本。并依据GB/T 5530—2005《动植物油脂 酸值和酸度测定》[20]测定所有食用油样本的酸值。
1.2 实验仪器
实验在北京工商大学光谱技术与品质检测实验室完成,光谱检测仪器为Bruker公司的VERTEX-70型傅里叶红外光谱仪和MATRIX-F型傅里叶红外光谱仪。实验设定MATRIX-F型光谱仪为主机,VERTEX-70型光谱仪为从机。仪器参数详见表1。

表1 光谱仪器和参数Tab.1 Spectroscopic instruments and parameters
1.3 光谱采集
使用2台近红外光谱仪分别采集食用油样本信息。采集时仪器参数设置为:分辨率16 cm-1;样本扫描次数32;背景扫描次数为32;光谱的采集范围9 000~5 000 cm-1;光阑6 mm;扫描频率10 kHz。
1.4 数据分析与处理
1.4.1光谱数据预处理
由于客观存在或人为因素,实验采集到的光谱数据通常会掺入噪声干扰,甚至使得数据不再完整。因此,光谱数据在建立校正模型之前必须进行预处理,压缩建模光谱集数据的规模,从而平滑噪声并剔除奇异数据[21]。在全光谱范围内比较了有限脉冲响应(Finite impulse response,FIR)[22]、多元散射校正(Multiplicative scatter correction,MSC)[23]、正交信号校正(Orthogonal signal correction,OSC)[24]和标准正态变量变换(Standard normalized variate,SNV)[25]共4种预处理方法对ELM模型性能的影响,发现经SNV预处理后的光谱能有效提高ELM模型的性能,因此,本实验以SNV预处理后的光谱作为后续分析的基础。
1.4.2样本划分方法
建立校正模型前,需要将食用油样品集划分为训练集和测试集。Kennard-Stone[26]算法是一种有效的样品集划分方法。其算法是通过计算样品之间的欧氏距离(Euclidean distance),选择代表性强的样品作为训练集样品,其余的作为测试集,从而提高校正模型性能。
1.5 建立PCA-ELM-TrAdaBoost模型传递分析模型
1.5.1PCA降维
由于食用油数据集中的样本数量远小于波数,因此需要降维处理减少数据的复杂度。PCA是常用的化学计量工具,它可以将数据从高维空间投影到低维空间,并尽可能保留原始数据的有效信息[27]。
1.5.2ELM校正模型
ELM的拓扑结构是一个经典的前馈神经网络,具有输入层、隐藏层和输出层共3层。隐藏神经元参数是随机分配的,输出权重可以通过使用Moore-Penrose广义逆矩阵进行分析,ELM算法具有学习速度快、可调参数少等优点[28]。本文采用加权ELM算法建立校正模型,将降维后的食用油数据作为神经元输入,油酸值预测值作为神经元输出,隐藏层节点设为20,并选用Sigmoid作为激活函数。
1.5.3TrAdaBoost模型传递方法原理
现阶段迁移学习大致分为3类:基于实例的迁移、基于特征的迁移和基于共享参数的迁移[29-30]。其中TrAdaBoost算法就是基于实例的迁移学习,其核心思想是:对源域Ds的标记数据实例进行有效权重分配,使源域实例分布接近目标域Dt的实例分布,从而在目标领域中建立一个可靠的校正模型实现模型传递[31-32]。其主要步骤为:
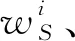
(1)
(2)
(3)
式中m、n——源域、目标域训练集样本数量
(2)计算误差。建立加权ELM校正模型。将训练集Xi经PCA降维后输入到校正模型中,输出预测值Yi,其与真实值Ti的预测误差为εi,计算式为
(4)
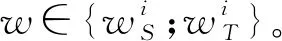
(5)
(6)
其中
式中βk——每次迭代的学习机权重
(4)达到最大迭代次数N后,输出ELM校正模型目标域的最终预测值YN。
1.6 模型传递的评价
模型的评价参数选择决定系数(Correlation coefficient of cross-validation,R2)和预测集均方根误差(Root mean square error of prediction,RMSEP)。R2越大表明光谱信息与食用油理化值的相关性越好,RMSEP越小,表明预测性能越好,模型传递的效果越好。
2 结果与分析
2.1 食用油光谱特征分析
主机和从机所采集的食用油样品光谱经SNV预处理后波数在9 000~5 000 cm-1范围内,共2 074个波数点(图1)。观察发现,8 700 cm-1和8 200 cm-1附近有2处主要的吸收峰,且其分别可能是由C—H(CH3,CH2)基团的2ν二倍频和2ν+2β组合频作用所引起的[33]。
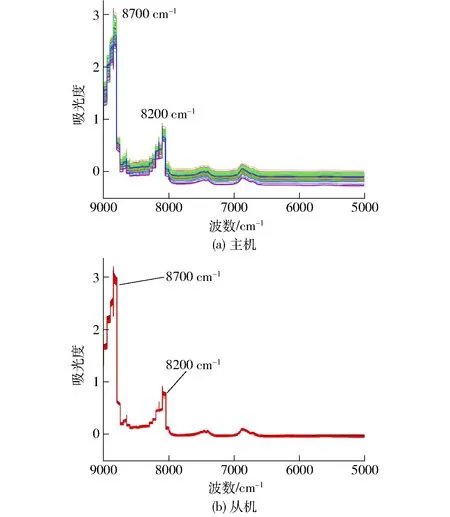
图1 经SNV预处理后的主机与从机的食用油吸光度Fig.1 Spectra of edible oil from master and slave after SNV pretreatment
2.2 样本划分
采用Kennard-Stone算法对129个食用油样品进行数据划分,训练集与预测集的比例约为3∶1,所以有97个样本作为训练集,32个样本作为预测集。食用油样本的数据集划分的具体情况如表2所示,训练集的油酸质量比为0.08~2.12 mg/g,涵盖了较宽的范围,有助于构建稳定的数学模型。且预测集的油酸质量比为0.09~1.82 mg/g,在训练集的油酸质量比范围之内,表明该子集可以对模型的预测性能进行验证。

表2 食用油样品的数据集划分Tab.2 Data set division of edible oil
2.3 主成分分析
由于原始光谱数据包含2 074个波数点,为了降低模型的复杂度和计算量,故对数据采用PCA主成分分析。前5个主成分的贡献率分别为70.52%、16.79%、4.15%、3.29%和1.21%。通过计算可知,前5个主成分的累计贡献率已经达到了95.96%,故本文使用5个主成分进行建模分析。
2.4 模型预测结果
利用在主机上已建立好的ELM模型分别预测主机和从机上的32个预测集样品的油酸质量比,并循环20次取平均值。利用主机模型预测主机样品集时,预测值与真实值的决定系数R2为0.922,预测集均方根误差(RMSEP)为0.198 mg/g,预测效果较好。而当从机样品集未进行模型传递直接代入主机模型进行预测时,决定系数R2下降到0.489,预测集均方根误差(RMSEP)提高到4.824 mg/g,预测结果产生较大差异。
图2为2台光谱仪的预测集与真实值差值图,其中Δ1为真实值与主机预测值的差值,Δ2为真实值与从机样品集直接应用于主机模型预测值的差值。可以看出Δ1几乎为0,主机预测值与真实值相差不大,说明预测较为准确。但当从机样品集直接应用于主机模型时,Δ2较大,预测值与真实值产生较大偏差,所以主机建立的校正模型无法直接应用于从机样品,需要进行模型传递改善预测效果。
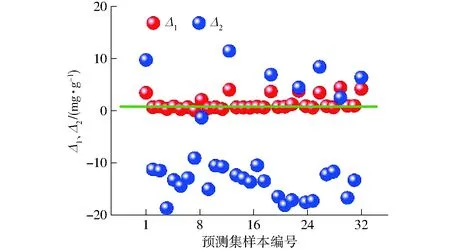
图2 2种模型的油酸质量比预测值与真实值差值图Fig.2 Difference of predicted and true values between two models
2.5 基于TrAdaBoost算法模型传递及预测结果
首先,按照算法要求将97个主机训练集和97个从机训练集进行合并,形成一个新的训练集。其次,对新训练集进行PCA处理并选取5个主成分,建立PCA-ELM-TrAdaBoost模型传递分析模型。最后,将从机的32个样本代入上述传递后的主机模型中进行预测,并循环20次取平均值。
图3为循环20次的模型传递与未传递的决定系数R2对比图,经过模型传递后的从机预测值与真实值的R2较高且比较稳定,在0.9左右浮动,而未经过模型传递的决定系数R2相对较低且不稳定。

图3 传递与未传递的决定系数R2对比Fig.3 R2 comparison between transfer and un-transfer
图4为经过模型传递后从机预测值与真实值差值图,可以看出经模型传递后预测值与真实值差值(Δ)几乎为0,预测值接近真实值,说明模型预测能力有所改善。决定系数R2从0.489提高到0.892,RMSEP从原先的4.824 mg/g降低到0.267 mg/g。说明经TrAdaBoost算法传递后的主机模型能更有效适用从机样本,从而减少主机与从机间的数据差异。
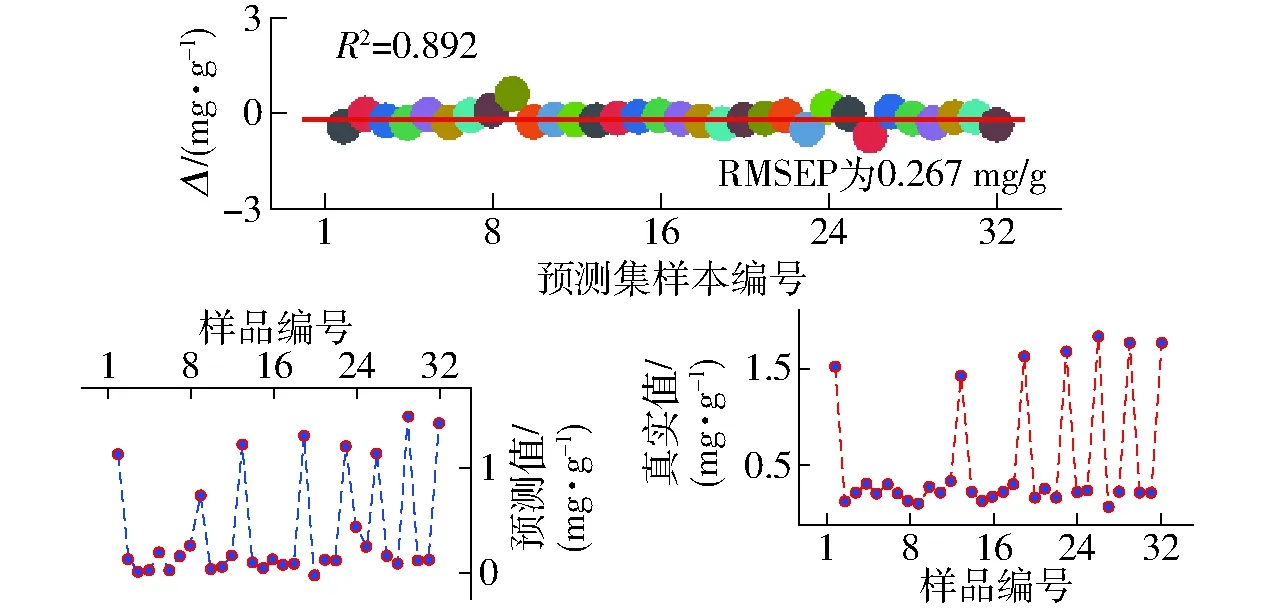
图4 模型传递后的预测值与真实值差值图Fig.4 Difference of predicted and true values between transfer and un-transfer
2.6 标准样品数量对模型传递的影响
为了取得较好的模型传递效果,采用Kennard-Stone算法依次从主机训练集中选取0、10、…、90个样品作为标准化样品集,对TrAdaBoost算法进行测试。图5为不同标准化样品数量对TrAdaBoost模型的影响情况。当主机样品数为0时,此时仍是从机样品直接在主机模型预测的结果。随着主机样品数的增加,RMSEP下降到稳定值后无明显变化,说明标准样品集的数量对TrAdaBoost算法的影响很小。
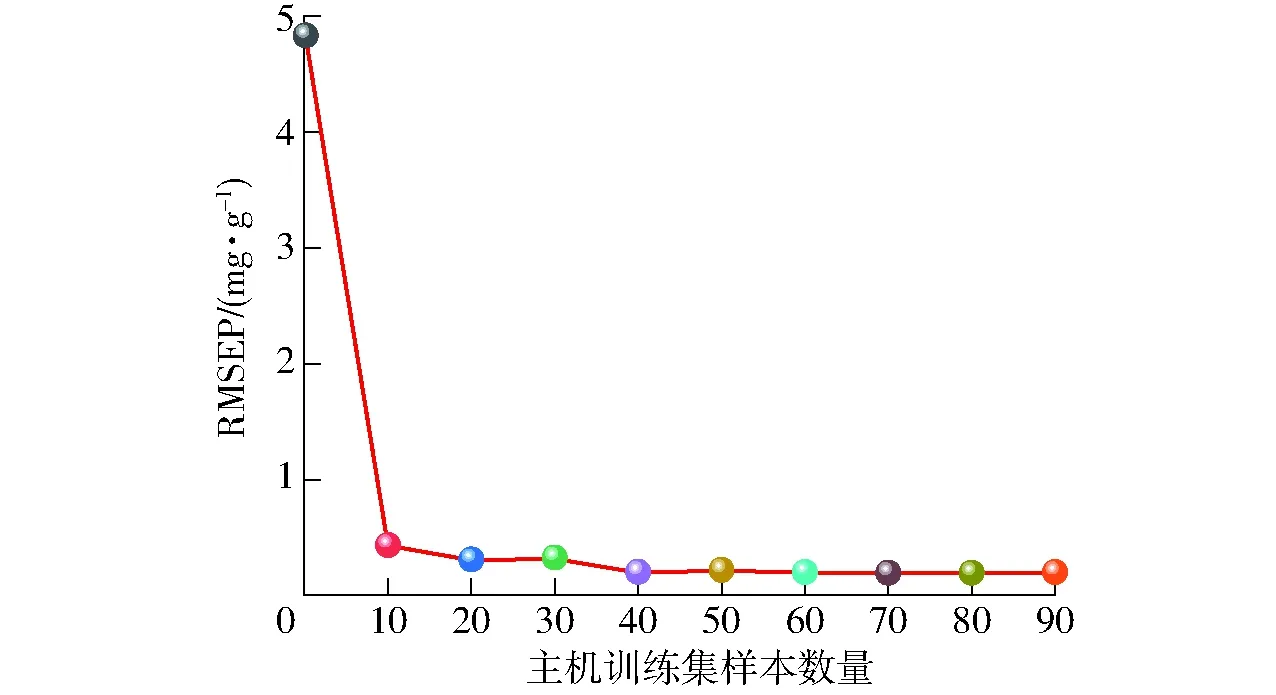
图5 不同标准化样品数对模型的影响Fig.5 Influence of number of samples on model
2.7 TrAdaBoost算法与其他算法的比较
为了评估TrAdaBoost算法的模型传递的性能,采用DS算法、TEAM算法和MDR算法进行对比测试。DS算法的基本思想是先建立主、从机光谱数据的数学函数关系,再用函数关系转换从机光谱数据,从而减少不同仪器间所测同一样本光谱数据的差异,实现模型在不同仪器间传递。TEAM算法将主机光谱作为学习目标,选择隐藏层中权重与偏差正交的节点,利用极限学习机的快速逼近能力与泛化性能建立主机和从机光谱之间的关系,以减少传递后的预测误差。MDR算法通过构建光谱转换矩阵,将待转换光谱视作缺失数据,通过多次迭代计算,可逐步实现从机光谱向主机光谱方向的转换,再预测时能够得到从机与主机光谱数据较小偏差的结果。
为了对比4种模型传递算法,样本的数据集划分、主成分个数以及ELM隐藏节点数均相同。经4种算法传递后的主机模型分别预测从机样品的油酸质量比,并循环20次计算平均R2和RMSEP,以评估传递模型的性能,如图6所示。
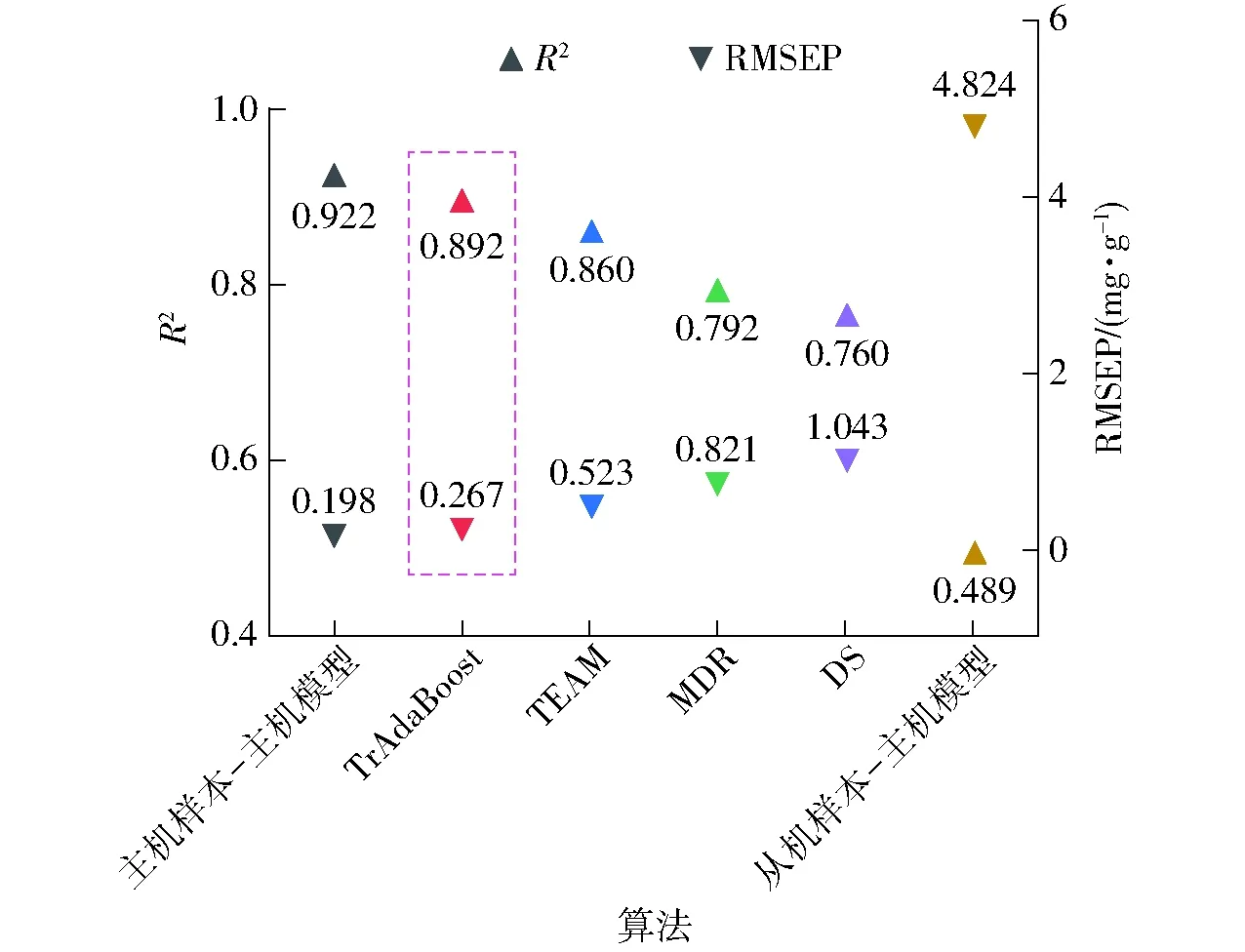
图6 不同算法下的模型R2和RMSEPFig.6 R2 and RMSEP results by different calibration transfer methods
对比4种算法,将从机样本代入经TrAdaBoost算法转换后的主机模型,其预测能力效果最好,R2为0.892,RMSEP为0.267 mg/g,十分接近主机本身的样本代入主机模型的预测值,R2为0.922和RMSEP为0.198 mg/g。预测效果由优到差依次为TEAM算法、MDR算法和DS算法,但这3种模型传递算法的预测能力均有所改善,均大于从机样本直接应用到主机模型上的预测值。TrAdaBoost模型预测效果比其他3种算法好的原因可能是该算法将主机样本和从机样本进行合并,新产生的训练集因为包含主机样本,使得拟合效果更接近主机模型,以致在预测时可以更好地适应主机模型。
3 结论
(1)将迁移学习的方法应用到近红外光谱中模型传递领域,采用TrAdaBoost算法结合ELM模型,实现了食用油酸质量比校正模型在不同仪器之间的传递。并与DS算法、TEAM算法和MDR算法进行对比研究。
(2)经模型传递后的主机模型的从机样本油酸质量比预测模型R2从0.489提高到0.892,RMSEP从4.824 mg/g降低到0.267 mg/g。对比其余3种算法,TrAdaBoost算法的预测结果最好,且预测值十分接近主机模型的预测结果,此外模型的建立几乎不受标准样品数量的影响。
(3)TrAdaBoost算法可以有效使不同仪器之间的光谱数据进行转换,提高了从机样本在主机模型的适应度,这对迁移学习应用于模型传递领域提供了研究思路,使近红外光谱技术应用于食用油检测具有实际意义。
