复杂语义可搜索加密研究*
2022-03-10刘晋璐
刘晋璐, 秦 静,2, 汪 青, 赵 博, 张 茜, 苏 烨
1. 山东大学 数学学院, 济南 250100
2. 中国科学院 信息工程研究所 信息安全国家重点实验室, 北京 100093
1 引言
随着信息时代的高速发展, 互联网技术已成为支撑社会发展的“基建”, 以互联网为基础的先进技术方兴未艾, 深刻地影响着社会生产方式的改变, 加快了人类文明的发展进程. 例如, 云医疗系统[1]革新了医生诊断病情的方式, 有利于实现精准医疗; 物联网技术[2–4]可以增加系统内设备之间的协调性和灵活性,有利于发展高精尖生产工艺等等. 这些新兴技术在运行和使用过程中会产生大量的数据, 如果将这些数据存储在本地, 不断累积的数据会对系统造成巨大的存储负担, 并且所需要的存储设备也会影响部署系统时的灵活性. 此时, 云计算服务为解决数据存储问题提供了重要的技术选择[5,6]. 借助互联网技术尤其是5G通讯技术可以快速地将这些数据存储到具有强大数据存储和处理能力的云服务器上, 并且可以根据实际需求在云服务器端对数据进行处理[7–11]. 因此, 云计算服务在这些新兴技术中扮演着重要的角色, 不仅可以减轻本地的存储负担, 还可以帮助系统执行复杂的计算.
尽管云计算服务在数据存储和计算处理方面具有巨大的优势, 为信息社会的发展提供了有力支撑, 但是用户数据泄漏事件时有发生, 如何安全地使用云计算服务就成为了一个重要的课题, 其中满足存储在云服务器中数据的隐私性是安全使用云计算服务的最基本要求. 密码学作为保障信息安全的重要方法, 在云计算安全中发挥着不可替代的作用. 为保护云数据安全, 用户可首先使用加密算法对数据进行加密处理然后再上传到云服务器中存储, 例如可以使用AES、RSA 或者ElGamal 等传统加密算法将明文数据转化为没有实际意义的密文. 为了使用这些加密数据, 可以采用文献[12,13] 中提出的“下载-解密-使用” 模式,用户首先将所需的数据下载并存储到本地, 对这些数据解密得到相应的明文数据后才可以进行后续的使用和处理. 在该模式下, 对云服务器中的加密数据进行搜索并定位目标数据是整个过程的基础. 但是, 加密数据的“无意义性” 在保证隐私性的同时, 也对搜索和定位目标数据带来了困难. 数据的隐私性与可使用性一直是一对主要矛盾, 而可搜索加密技术[14–16]赋予了密文被实施关键词搜索的能力, 不仅可以保证数据的隐私性, 还突破了传统加密方案不可对加密数据进行搜索的瓶颈.
可搜索加密于2000 年由Song 等人[14]首次提出, 主要分为对称可搜索加密(searchable symmetric encryption, SSE)[14]和公钥可搜索加密(public key encryption with keyword search, PEKS)[15]. 由于SSE 使用的是伪随机函数等对称密码技术, 在运行效率方面表现出色, 但由于在生成索引和陷门时使用同一个密钥, 数据拥有者和数据使用者需要共享密钥才能实现对密文的搜索, 而PEKS 使用的是基于身份的加密等公钥密码技术, 因此可以实现丰富的性质和更高的安全性, 但运行效率比SSE 低. 如图1 所示, 可搜索加密有以下四个步骤:
(1) 加密: 数据拥有者在本地使用密钥对明文文件加密处理得到密文数据, 并将其上传到云服务器.
(2) 陷门生成: 具有搜索能力的用户根据搜索关键词生成陷门, 并将其上传到云服务器.
(3) 搜索: 云服务器依据用户上传的陷门, 对密文数据进行搜索得到匹配的密文文件并返回给用户.
(4) 解密: 用户对服务器返回的密文文件解密得到对应的明文文件.
早期的大多数可搜索加密只能实现完整的、精确的单关键词搜索, 且将包含搜索关键词的文件全部返回给用户. 但在实际执行搜索时, 一方面用户经常会出现对要搜索的关键词记忆不准确, 拼写错误的情形或以两个及以上关键词作为搜索条件; 另一方面, 将包含搜索关键词的文件全部返回给用户, 而不考虑文件与搜索关键词之间相关性的搜索不仅会导致不必要的网络流量, 而且使得用户必须对搜索到的所有文件进行处理, 以找到符合他们兴趣的文件, 这在当今“按需付费” 云范例中是不希望出现的. 因此, 为了使得可搜索加密更符合实际需求, 各种功能多样化的可搜索加密方案被提出, 例如: 通配符可搜索加密、模糊关键词可搜索加密、多关键词可搜索加密等. 为了减少不必要的网络流量, 对于加密云数据进行有效而安全的排序关键词搜索方案被提出, 即根据搜索结果和排序标准返回与搜索关键词相关性最强的前k个文件, 也被称为返回top-k结果的可搜索加密. 我们把符合搜索条件的所有文件全部返回给用户且只能实现完整的、精确的单关键词可搜索加密称为传统可搜索加密, 而将通配符、模糊等这种功能多样化的可搜索加密统称为复杂语义可搜索加密.
本文主要对复杂语义SSE 进行研究, 关注近年来通配符、模糊关键词、多关键词这三类复杂语义SSE的研究进展, 并对三者之间的关系进行分析, 最后提出现阶段这三类复杂语义加密搜索需要解决的问题和未来研究思路.
2 复杂语义对称可搜索加密
2.1 通配符对称可搜索加密
虽然利用传统的可搜索加密方案可以实现在密文中搜索目标数据, 但这些方案都只支持完整的关键词搜索. 而在实际搜索时, 用户经常会出现: (1) 对要搜索的关键词记忆不准确或不完整, 例如: 用户想要搜索2020 年8 月某一天保存的一份文件, 但记不清具体哪天; (2) 不需要准确搜索, 只需要满足一个或多个属性, 例如: 在员工信息管理系统里面, 管理员想要搜索居住地为山东省的员工名单.
对于上述两种情形, 如果利用传统的可搜索加密, 则用户无法根据搜索目标直接输入完整的关键词进行搜索, 只能通过搜索目标枚举所有可能的关键词, 即对于情形(1): 用户对31 个关键词“2020/08/01”、“2020/08/02”、···、“2020/08/31” 分别生成陷门进行搜索得到2020 年8 月保存的所有文件然后进行筛选得到目标文件; 对于情形(2): 管理员分别对关键词“山东省济南市”、“山东省临沂市”、“山东省青岛市” 等生成陷门进行搜索得到居住地为山东省的员工名单.
显然, 这种通过枚举所有可能的陷门进行搜索的方法是不高效的. 因此, 通配符可搜索加密被提出. 通配符主要有“?” 和“*” 两种, “?” 代表一个字符, 称其为单字符通配符; “*” 可以代表任意多个字符, 称其为多字符通配符. 对于上述两种情形, 用户可对关键词“2020/08/??” 生成陷门, 管理员可对关键词“山东省*” 生成陷门进行搜索. 因此, 相对于目标为完整关键词的传统可搜索加密, 通配符可搜索加密可以支持关键词的部分匹配而不只限于关键词的完整匹配, 应用更加广泛.
现有的大多数通配符SSE 都基于布隆过滤器(Bloom filter, BF)[17]构造索引.
布隆过滤器于1970 年由布隆提出[17], 是一种可以进行集合成员判定的数据结构. BF 使用一个m比特的数组代表一个集合, 该数组的所有位置被初始化为0. 对于一个给定的集合S={s1,s2,··· ,sn},使用l个独立的哈希函数hi:{0,1}*→[1,m],1≤i ≤l计算集合中每个元素对应的l个哈希值, 然后将BF 中哈希值对应的位置设置为1, 这样就把集合S中的每个元素插入到了BF 中. 为了判断一个元素q是否属于一个集合S, 计算q对应的l个哈希值h1(q),h2(q),··· ,hl(q), 检测集合S对应的BF 中这l个位置是否全为1, 若有一个不为1, 则q一定不属于集合S; 若l个位置全为1, 则有很大概率认为q ∈S,即有一定的概率会出现假阳性, 这是由于这l个位置可能是由其它元素设置为1 而不是q. 如图2 所示为BF 生成的一个简单例子, 其中S={s1,s2},l= 3,h1(s1) = 2,h2(s1) = 7,h3(s1) = 8,h1(s2) = 5,h2(s2)=2,h3(s2)=1:
根据索引和陷门生成时对关键词的处理方式可将基于BF 的通配符SSE 分为以下两类:
2.1.1 枚举
2011 年, B¨osch 等人[18]利用布隆过滤器与伪随机函数构造联合通配符对称可搜索加密方案. 该方案基于Goh 等人[19]的Z-IDX 索引, 将r个哈希函数作用在文件的每个关键词上, 映射到布隆过滤器中, 对每个文件生成一个布隆过滤器, 把过滤器作为矩阵的一行, 构成一个n×b阶矩阵, 作为所有文件的索引, 其中n是文件的个数,b是布隆过滤器的大小. 但由于不同文件中的相同关键词在布隆过滤器中的位置是相同的, 敌手可以根据两个文件的布隆过滤器了解他们的相似性, 因此该方案不能抵抗相关性攻击.B¨osch 等人提出隐藏索引的方法以抵抗相关性攻击, 即对布隆过滤器的每一比特生成一个掩码, 与该比特进行异或, 得到加密的布隆过滤器, 将其作为索引上传到服务器. 在搜索时, 服务器基于陷门返回加密过滤器对应的列, 用户在本地解密得到搜索结果. 为了支持通配符搜索, 在构造索引时, 根据通配符在关键词中的个数、位置、代表的字符数枚举关键词通配符形式的变体, 然后将关键词及其所有的变体映射到过滤器中. 虽然该方案的效率比文献[20] 中支持通配符的非对称搜索方案有所提高且一个通配符可以代表多个字符, 但该方案在进行通配符搜索时, 对关键词含通配符的形式进行枚举, 并将这些关键词映射到过滤器上, 导致预处理成本大且服务器端索引存储量大.
2016 年, Hu 等人[21]提出了一个多功能对称可搜索加密方案, 能够支持通配符搜索、相似搜索(编辑距离和汉明距离) 和模糊搜索, 并且支持分离关键词搜索和对文件的更新. 该方案的索引为倒排索引, 为文件集中每个不同的关键词建立一个布隆过滤器, 但索引生成方式与文献[18,19] 有些不同. 为了减少存储量, 该方案将矩阵型的索引压缩为数组形式, 即索引为一个含有t个单元的数组T, 数组的每个单元记录矩阵型索引中每一列为1 的位置对应的关键词. 对搜索关键词生成陷门时, 需要枚举出所有可能的关键词, 然后用r个hash 函数作用在每个关键词上建立一个BF; 在进行相似搜索时, 需要用户提取出与搜索关键词的(编辑或汉明) 距离满足阈值条件的所有关键词, 然后用r个hash 函数作用在每个关键词上建立一个BF 从而得到陷门; 在进行模糊搜索时, 需要生成两个陷门, 一个是精确搜索的陷门, 另一个是相似搜索的陷门. 搜索过程也与之前方案中的方法不同, 对于给定的陷门BF 和索引T, 对BF 的每个为0 的位置i, 在索引中提取出T[i] 中的所有关键词, 得到关键词集S, 计算S在文件集的所有关键词中的补集¯S, 返回给用户与¯S中关键词对应的所有I′, 索引建立与搜索过程如图3 所示. 该方案虽然支持多种类型的搜索, 且能够实现多字符通配符搜索, 但在生成陷门时, 需要提取出所有可能的关键词, 预处理成本大且搜索时通信复杂度大.
2.1.2 提取特征
B¨osch 等人[18]与Hu 等人[21]的方案基于关键词整体建立索引, 所以需要将关键词通配符所有可能的形式进行枚举, 效率低, 存储量大. 为了解决上述问题, 文献[22–25] 提出对关键词提取特征实现通配符搜索的方法.
2012 年, Suga 等人[22]通过提取关键词中所有单个字符对应位置级联字符的特征, 为每个关键词构造一个布隆过滤器, 建立倒排索引, 提出了一个支持多种类型搜索的可搜索加密方案. 如图4 所示, 在生成索引时, 首先按字符位置级联字符的方式提取每个关键词的特征集合(如cloud 对应的特征集合为{1||c,2||l,3||o,4||u,5||d}), 然后将特征集合中的每个元素通过哈希函数映射到过滤器中, 生成该关键词对应的过滤器索引. 在生成搜索关键词陷门时, 按相同的方式提取非通配符的字符特征(如*lou* 对应的特征集合为{2||l,3||o,4||u}) 生成过滤器. 当搜索关键词与索引关键词匹配时, 搜索关键词的特征集为索引关键词特征集的子集, 故在陷门过滤器为1 的位置, 在索引过滤器中也必为1. 虽然该方案不需要通过枚举的方式来实现通配符搜索, 但由于提取特征方式的局限性, 不适用于多字符通配符搜索, 不具有实用性.
2016 年, Hu 等人[23]为了解决文献[22] 中一个通配符只能代表一个字符的局限性, 提出了一种新的关键词特征提取方法, 使得一个通配符可以代表任意多个字符, 具体操作如下: 对于陷门中的关键词, 第一个通配符前面的字符按正序记录, 最后一个通配符后面的字符按倒序记录, 除此之外, 记录除通配符外所有字符的存在性(如c*o*d 对应的特征集合为{c||1,d||-1,c||0,o||0,d||0}). 最后, 将这些记录对应的哈希值添加到过滤器中. 对于索引中的关键词, 分别记录每个字符的正序、倒序、存在性, 如cloud 对应的特征集合为:{c||1,l||2,o||3,u||4,d||5,d||-1,u||-2,o||-3,l||-4,c||-5,c||0,l||0,o||0,o||0,u||0,d||0}, 然后将这些记录的哈希值添加到过滤器中. 图5 为上述通配符搜索的一个具体示例. 由于上述通配符搜索技术存在一定的的错误概率, 如关键词cloud 能够匹配陷门关键词c*uo*d 与c*od*, 但cloud 并不满足这两个通配符形式. 因此Hu 等人提出通过记录关键词的n-gram(关键词中出现的连续n个字符)代替上述方法中关键词字符的存在性来避免这种错误. 在上述通配符搜索技术的基础上, Hu 等人利用与文献[22]相同的方法提出了一个支持通配符搜索的对称可搜索加密方案, 并证明该方案达到了IND-CKA 安全. 但2021 年Chatterjee 等人[26]给出了一个具体的攻击, 指出该方案并不能达到IND-CKA 安全. 该攻击利用方案在索引和陷门生成时直接将字符级联位置的哈希值对应的布隆过滤器的位置设置为1(即相同的字符在不同的关键词索引、陷门中对应的哈希值相同), 通过两个关键词的过滤器的交集得到两个关键词中公共字符对应的陷门, 进而选择合适的挑战关键词集, 使得两个关键词集的索引可区分.
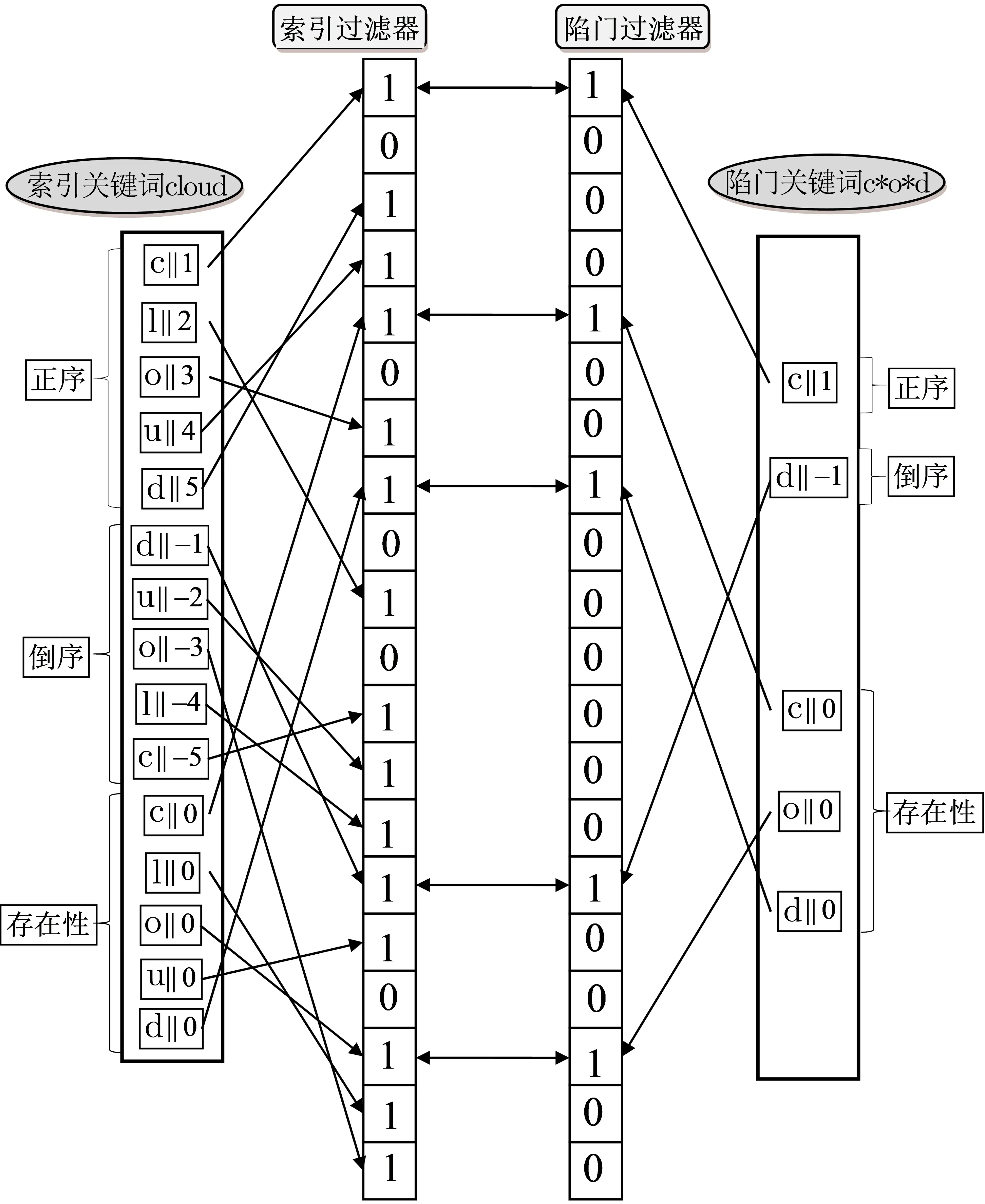
图5 通配符搜索Figure 5 Wildcard search
2016 年, Zhao 等人[24]通过对文献[22] 中关键词特征提取方式的改进, 使文献[24] 方案中的通配符搜索能够同时支持单字符通配符“?” 与多字符通配符“*”. 但与文献[22] 的倒排索引不同, Zhao 等人通过为每个文件的每个关键词建立一个布隆过滤器索引, 每个文件的索引都可以看作一个m×b的二进制矩阵, 其中m表示一个文件中关键词的个数,b表示单个布隆过滤器的大小. 与文献[18] 类似, Zhao 等人首先提出一个基础方案, 但该方案不能抵抗相关性攻击, 因此在该方案的基础上, Zhao 等人提出了一个与文献[18] 隐藏索引的方式不同的隐藏索引的方案, 首先区分不同的关键词在不同文件中的身份, 即为每一个关键词对应的过滤器生成一个ID, 然后为每个布隆过滤器的每个比特生成一个掩码, 并将该掩码与原过滤器对应比特进行异或, 得到隐藏索引. 搜索时, 在服务器端进行解密得到搜索结果, 如图6 所示. 与文献[18]中2-round 的隐藏索引方案相比, 该隐藏索引方案为1-round, 效率更高. 但因为是正向索引, 每个文件的索引均为一个m×b的二进制矩阵且关键词的特征提取较为繁琐, 导致存储量较大, 搜索速率较低.

图6 隐藏索引构建Figure 6 Building of hidden index
2019 年, 于文[25]在文献[23] 的基础上, 利用Lai 等人[27]提出的一种轻量级对称密钥隐藏向量加密技术, 将文献[23] 中索引过滤器和陷门过滤器分别看作索引向量和查询向量, 然后对布隆过滤器加密(如图7 所示), 提出了一个更加安全的通配符搜索方案. 该方案的数据保密性更强, 而且在搜索时避免了陷门和索引的两个布隆过滤器之间比特值的一一匹配, 提高了搜索效率. 但在该方案中, 过滤器的每一比特都要通过一个伪随机函数进行加密(用带密钥的hash 函数, 例如HMAC-SHA256 作为伪随机函数), 生成256 比特的密文, 因此索引的存储量扩大为原来的256 倍.

图7 隐藏向量加密示例Figure 7 Example of hidden vector encryption
2.2 模糊关键词对称可搜索加密
传统的可搜索加密只能实现精确关键词的搜索, 而缺乏对微小的拼写及格式错误的容忍, 但这正是在现实的搜索中经常出现的. 例如: 用户由于粗心在搜索包含关键词“word” 的文档时将搜索关键词输入为“woed” 或数据拥有者将密文文档上传到云服务器时, 预设的关键词为“PO Box”, 但由于用户缺乏对服务器端数据的确切认识, 输入的搜索关键词为“P.O. Box”.
在上述两种情形下, 由于关键词“woed” 与“P.O. Box” 都不是索引关键词, 故传统的精确关键词搜索将无法返回用户感兴趣的文件.
与精确关键词相比, 模糊关键词搜索允许用户输入中有微小的拼写错误或形式不一致问题. 对于上述两种情形, 模糊关键词搜索可以根据查询关键词“woed” 找到包含索引关键词“word” 的文档, 可以根据查询关键词“P.O. Box” 找到包含索引关键词“PO Box” 的文档. 因此, 模糊关键词搜索极大地提高了系统可用性和用户的搜索体验.
基于使用的工具, 可将现有的模糊关键词SSE 分为以下两类:
2.2.1 编辑距离
编辑距离(edit distance), 又称莱文斯坦(Levenshtein) 距离, 是指两个字符串之间, 由一个转变为另一个所需要用到的最少编辑操作. 编辑操作包括: (1) 插入(insert), 即在一个字符串中插入一个字符; (2)删除(delete), 即从一个字符串中删除一个字符; (3) 替换(substitute), 即在一个字符串中将一个字符改变为另一个字符.


2011 年, Liu 等人[29]指出文献[28] 中基于通配符的模糊关键词集构造技术使得方案需要较大的索引存储空间, 为了减少索引存储量, 他们提出基于字典的模糊关键词集构造方法, 即模糊关键词集中的关键词必须是字典中有意义的词汇, 从而减少无意义的候选关键词, 进而减少了文档索引所需的存储空间,同时减少了搜索时陷门与索引的匹配时间, 提高了搜索效率.
虽然基于字典的模糊关键词集构造方法较基于通配符的模糊关键词集构造极大的减少了存储空间, 提高了效率, 但这两个方案都是通过构造模糊关键词集实现模糊搜索的功能, 索引大小都与关键词数量成线性关系.
2.2.2 局部敏感哈希
局部敏感哈希(locality sensitive hashing, LSH)[30]是一种针对海量高维数据的快速最近邻查找算法, 其基本思想是: 给定一个度量距离, 原始高维数据空间中的两个相邻的数据点通过相同的映射或投影变换后会有很大概率被映射到新的低维空间的同一位置, 而不相邻的两个数据点被映射到低维空间相同位置的概率很小. 一个哈希函数簇H是(r1,r2,p1,p2)-敏感的如果对于任意两点s,t和h ∈H满足:
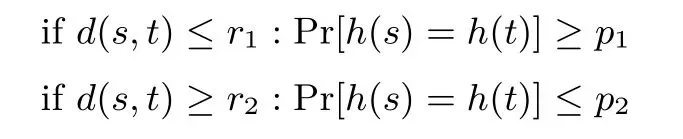
其中d(s,t) 为点s和点t之间的距离.
依据搜索的数据类型, 可将基于LSH 的模糊关键词SSE 分为以下三类:
(1) 英文关键词
2012 年, Kuzu 等人[31]基于局部敏感哈希设计了一个支持模糊搜索的密文搜索方案, 该方案利用LSH 将相似的关键词以较高的概率映到相同的桶中, 而不相似的关键词映到相同桶中的概率较低的特点来筛选搜索结果, 而不需要构造模糊关键词集. 具体地, 如图8 所示, 在构造索引时, 首先提取每个文件的特征(关键词); 其次, 将特征转化为其对应的向量; 然后利用min-hash 将特征向量映到对应的桶中, 桶中存储特征对应的比特向量, 即向量的每个分量对应文件集的一个文件, 若文件包含该特征, 则对应分量为1, 否则为0; 最后, 分别利用伪随机置换和选择明文攻击伪随机性(pseudo-randomness against chosen plaintext attacks, PCPA) 安全的加密方案加密桶的标识符和桶中的比特向量. 搜索时, 需要两轮交互才能搜索到匹配的密文文档. 具体地, 用户按照与索引构造时相同的方式生成询问特征对应的桶标识符, 并利用伪随机置换生成陷门, 服务器返回陷门对应桶中加密的比特向量并将其发送给用户, 用户利用密钥解密, 得到最终需要的文件标识符, 并向服务器请求返回对应密文文件.
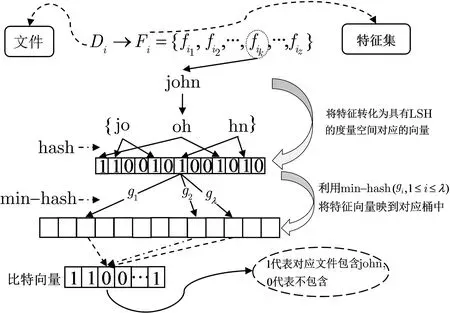
图8 LSH 索引Figure 8 LSH 索引
为了防止访问模式的泄露, 基于上述基础的搜索方案, 文献[31] 又提出了一个双服务器的搜索方案.在该双服务器方案中, 假设两个服务器都是诚实但好奇的, 且服务器之间不会共谋, 数据拥有者将索引和密文文件分别发送给两个服务器, 在搜索时两个服务器各执行基础搜索方案两轮交互中的一轮. 进一步地,在双服务器搜索方案的基础上, 为了减轻用户端的计算负担, 文献[31] 使用Paillier 加密实现了双服务器下的一轮交互搜索方案.
虽然文献[31] 利用LSH 生成索引, 使得不需要构造模糊关键词集也实现了模糊搜索功能, 但该方案需要两轮交互且仅支持单关键词搜索.
2014 年, Wang 等人[32]利用局部敏感哈希技术提出了一个在已知密文模型下安全的多关键词模糊搜索方案. 与文献[31] 不同的是, 在将关键词转化为具有LSH 的度量空间对应的向量时, 文献[31]利用bigram (关键词中出现的连续两个字符) 的哈希值生成关键词对应向量, 而该方案直接利用关键词的bigram 生成对应的bigram 向量, 从而避免了生成向量时哈希碰撞的情形; 其次在文献[31] 中通过Jaccard 距离度量相似性, 进而利用min-hash 生成索引, 而该方案通过欧几里得距离度量相似性, 利用p-stable hash 生成索引. 具体地, 如图9 所示, 一个关键词首先被转化为一个bigram 集, 然后使用一个262维的比特向量来表示一个bigram 集, 向量中的每个分量代表所有262个bigram 中的其中一个. 对于一个给定关键词的bigram 集, 将出现在bigram 集中的bigram 对应分量设置为1; 其次, 为每个文件构造一个BF 索引, 将文件集中包含的所有关键词对应的bigram 向量通过p-stable hash 映到过滤器中,即将bigram 向量对应的p-stable hash 值对应的BF 位置设置为1. 按照同样的方式可生成搜索关键词(集) 对应的向量. 为了保护关键词的隐私, 利用安全KNN 加密文件向量与询问向量生成安全索引与陷门. 搜索时, 计算陷门与每个文件的安全索引的内积即可得到搜索关键词(集) 与文件的相关性得分, 内积越大, 则有越大的概率说明文件包含越多的搜索关键词. 为了进一步地提高安全性, 基于基础方案, Wang等人通过将原本的LSH 替换为一个伪随机函数与p-stable hash 函数的复合得到了一个在已知背景模型下安全的模糊搜索方案.
2017 年, Fu 等人[33]指出在文献[32] 中将关键词转化为bigram 会增大欧几里得距离, 对除一个字母拼写错误以外的其它拼写错误不是有效的, 并且该方案不支持相同词根的关键词搜索, 也没有考虑关键词和文件之间的相关性. 基于上述弊端, 如图10 所示, Fu 等人进行了以下几点改进: 引入词根提取算法(stemming algorithm) 使得可以实现相同词根的关键词搜索; 将关键词转化为uni-gram (关键词中出现的单个字符), 可以有效减小欧几里得距离; 将文件与关键词的相关性考虑在内, 即将关键词向量通过哈希映到过滤器时, 将对应的哈希值位置设置为关键词对应的相关性分数而不是1, 体现了关键词和文件之间的相关性. 基于以上改进, 文献[33] 实现了更有效、准确的多关键词模糊搜索.
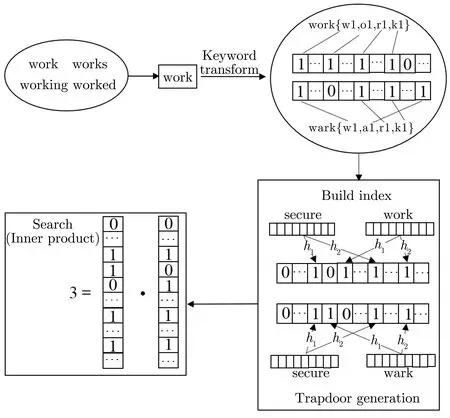
图10 有效的多关键词模糊搜索Figure 10 Efficient multi-keyword fuzzy search
2017 年, Yang 等人[34]通过对关键词提取n-gram 特征, 将传统的针对文档的sim-hash 算法改进使其能够对关键词生成指纹, 从而对文件集建立倒排索引, 搜索时计算搜索关键词对应的sim-hash 指纹,并计算索引关键词和搜索关键词sim-hash 指纹之间的汉明距离, 然后依据汉明距离从小到大的顺序将top-k的密文文件返回给用户. 但由于包含一个关键词的文档往往不只一篇, 因此仅仅基于汉明距离只能实现较粗糙的排序结果. 为了实现更细粒度的排序, 利用TF-IDF 原则计算关键词的相关度分数, 并对其进行保序加密操作, 实现了相关度分数的隐私保护, 最后按照汉明距离优先, 相关度分数次之的双因子排序规则实现了更精确的排序. 更进一步地, 为了使得方案更适用于海量数据集, 通过构造指纹索引树来提高搜索效率, 同时为了达到在不需要遍历整棵树的情况下能够比较汉明距离, 设计了一种新型的遍历方法.
2019 年, Cao 等人[35]指出为了实现对密文数据的模糊关键词搜索, 在对关键词预处理时, Wang 等人[32]提出的“2-gram” 方法只对拼写错误的模糊搜索有效, 而不能有效的处理字母顺序颠倒, 增加或删除字母的情况, Fu 等人[33]提出的“uni-gram” 方法虽然在处理字母顺序颠倒, 增加或删除字母的情况时比“2-gram” 更有效, 但由于其缺少字母顺序的信息, 因此文献[33] 无法识别“相同字母异序词”, 例如:“devil” 与“lived”. 因此, 为了提高搜索准确性, Cao 等人提出一种新颖的方法将关键词转化为“orderpreserved uni-gram(OPU)” 向量. 具体地, 每个关键词被转化为一个u×26+30 维的向量, 其中u为关键词中的字母数, 可以将该向量看作u个字母块和一个数字与符号块, 一个字母块对应26 比特, 代表26个英文字母‘a’ 到‘z’, 关键词中出现的字母对应分量为1, 其余为0. 数字与符号块共对应30 比特, 其中10 比特对应数字‘0’ 到‘9’, 剩余20 比特对应关键词中广泛出现的符号. 进一步地, 为了减弱字母顺序的混乱对搜索准确性的影响, Cao 等人引入一个“传感” 机制, 将原本的二进制向量转化为浮点数向量. 每个关键词转化为向量后, 利用LSH 得到BF, 然后将每个文件包含的关键词对应的BF 合并得到每个文件对应的BF. 为了提高搜索效率, Cao 等人基于k-means 聚类算法将相似的文件划分到一个类中进而得到一个等级索引树(hierarchical index tree, HIT), 最后利用安全KNN 加密HIT 的每个结点保证安全性和隐私性.
2020 年, Zhong 等人[36]指出虽然文献[33] 比文献[32] 有更准确的搜索结果, 但其搜索时间与文件数量n成正比, 即为O(n), 搜索效率低. 因此基于文献[33], Zhong 等人引入平衡二叉树将所有的BF 索引聚合到一起, 使得搜索时间减少为O(rlogn).
(2) 中文关键词
虽然上述方案[31–36]在无需构造模糊关键词集的情况下可以实现模糊关键词搜索, 但这些方案都旨在实现英文关键词的模糊搜索, 而汉字是典型的非字母语言, 词语是灵活多样的, 因此上述方案不适用于中文关键词的模糊关键词搜索.
2019 年, Yang 等人[37]在设计了两个中文关键字向量生成算法的基础上, 利用文献[32] 的思想, 通过LSH 和BF 提出了两个可以用于中文字符的模糊多关键词排序可搜索加密. 具体地, 在第一个基础中文多关键词模糊排序搜索方案(basic Chinese multi-keyword fuzzy rank search scheme, BCMS) 中, 中文关键词向量生成算法将一个中文关键词转换为一个拼音串, 该拼音串又被分为声母、韵母和声调三部分.关键词向量的结构如图11 所示, 方案使用一个63 比特的向量代表一个关键词, 前23 比特代表中文的23个声母, 中间的24 比特代表24 个韵母, 最后的16 比特代表关键词中词的位置和声调(为“ab” 这样的形式, 其中“a” 代表在关键词中的第1–4 个词, “b” 代表汉语拼音的四个声调). 如果该元素存在于拼音字符串中, 则对应位置被设置为1, 否则设置为0. 例如, 关键词“实验” 的音节分割集为{sh,i,12,y,an,24},其中“12” 表示在关键词“实验” 中第一个词“实” 为二声, “24” 表示第二个词“验” 为四声. 由于在基础方案中, 关键词向量生成算法没有考虑不同方式拼写错误的差异, 也没有考虑关键词术语的权重, 导致搜索结果不够准确. 因此为了提高搜索准确性, 基于BCMS, 提出了一个增强的中文多关键词模糊排序搜索方案(enhanced Chinese multi-keyword fuzzy rank search scheme, ECMS), 该方案基于uni-gram 将一个拼音串转换为一个关键词向量, 扩大了拼音字符串中不同方式拼写错误的差异, 从而使排序结果更加准确. 具体地, 该关键词向量生成算法将中文关键词转换为一个拼音串, 然后使用uni-gram 方法分离拼音串. 关键词向量的结构如图12 所示, 方案使用一个120 比特的向量代表一个关键词, 第一个26 比特代表关键词中第一个词的英文26 个字符, 同理第二个、第三个、第四个26 比特分别代表第二、三、四个词的英文26 个字符, 最后16 比特代表词的位置和声调(BCMS). 如果该元素存在于拼音字符串中, 则对应位置被设置为1, 否则设置为0, 例如, 关键词“故事” 的音节分割集为{g1,u1,14,s2,h2,i2,24}, 其中“g1”表示英文字符“g” 来自第一个词“故”. 此外, 增强的方案通过结合关键词向量的欧几里得距离, 关键词频率和加权区域得分提出了一个三因子排序算法, 进一步提高了搜索准确性.
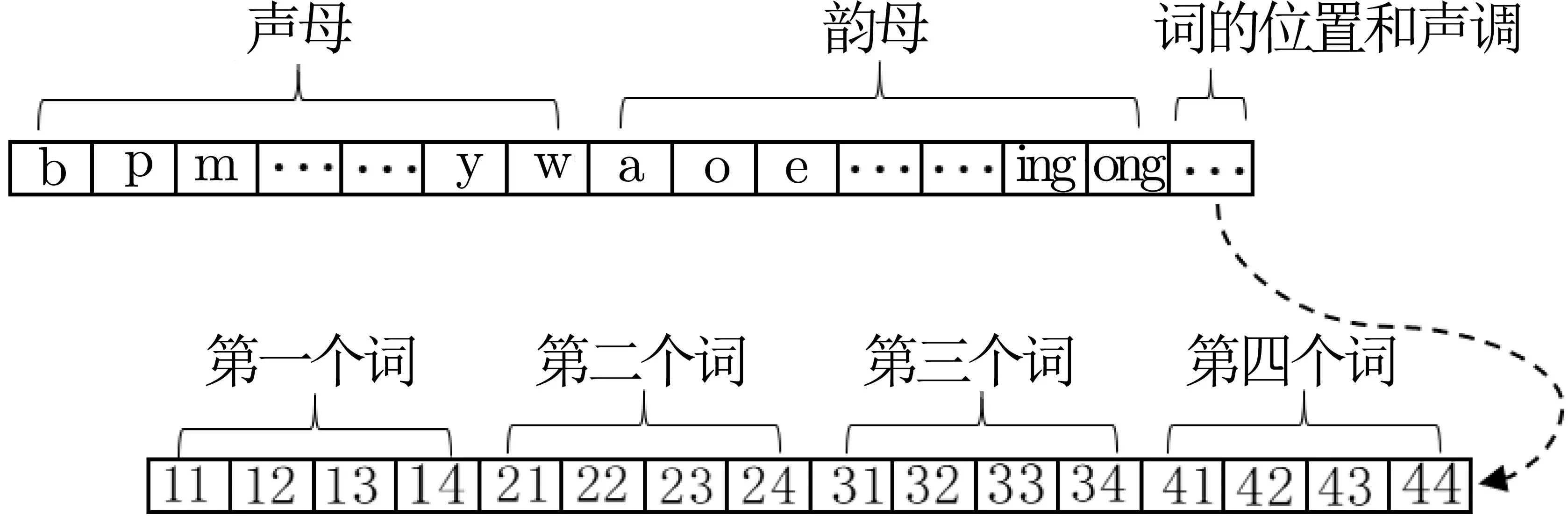
图11 基础方案关键词向量Figure 11 Keyword vector in BCMS
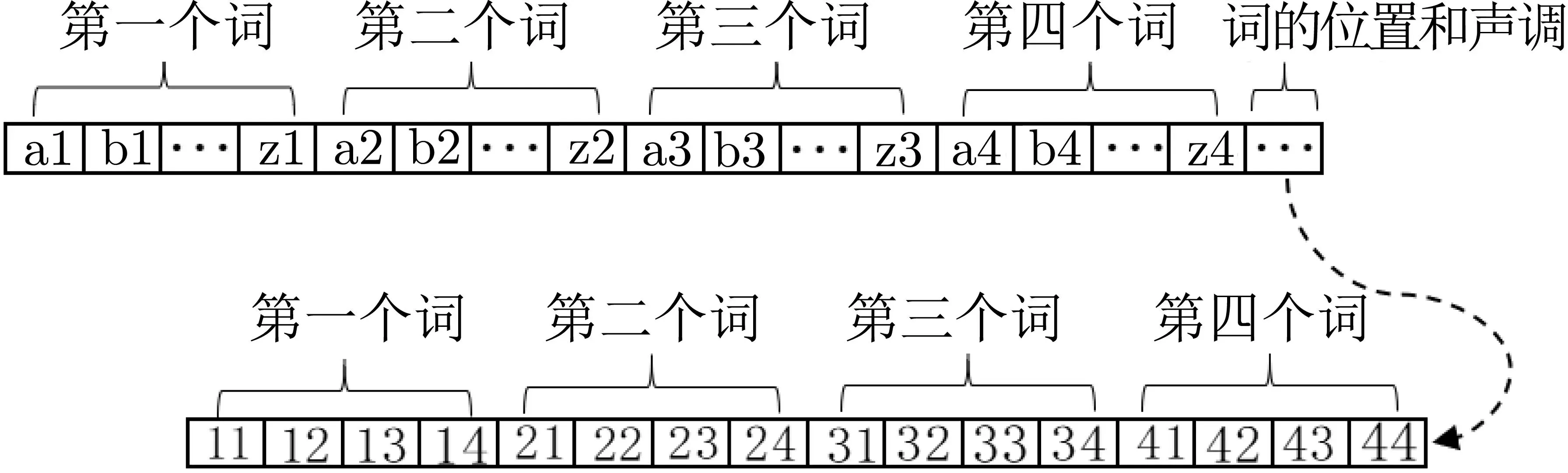
图12 增强方案关键词向量Figure 12 Keyword vector in ECMS
(3) 功能多样的数据
虽然上述提到的方案[31–37]基于LSH 实现了模糊关键词搜索, 但由于用户上传到云服务器的文件不只有文本文件, 故设计能够对于各种类型的加密文件, 例如: 图像、音频、视频文件的模糊可搜索方案是很有必要的.
2016 年, Wang 等人[38]通过将搜索标准视为高维特征向量而不是关键词, 解决了在加密的功能丰富的多媒体数据上支持大规模相似性搜索的挑战. Wang 等人利用特征提取算法, 对文件提取特征进而得到每个文件fi对应的特征向量pi, 然后计算每个特征向量对应的LSH 值的方式构造索引. 具体地, 如图13 所示,M个LSH 哈希函数被用来生成M个哈希表, 每个哈希表对应有m个桶, 故共有Mm个桶,依次计算每个文件特征向量对应的M个桶, 然后将其对应的倒排文件向量(inverter file identifier, IFV)存储于桶中, IFV 的每个分量对应一个文件, 分量为1 则代表该文件的特征向量被LSH 映到桶中. 计算每个桶中存储的所有的IFV 的或得到该桶对应的IFV, 为了减小搜索结果假阳性的概率, 桶中最终存储的IFV 为其左右相邻的桶对应的IFV 与自身的IFV 的或, 另外, 通过相同的方式构造所要添加文件的子索引或将IFV 中所要删除文件对应分量设置为0 的方式可以实现文件动态的增加或删除. 搜索时, 利用相同的方式, 得到搜索文件对应的M个桶的位置, 对M个桶中IFV 求交得到一个新的向量, 将该向量为1 的分量对应的密文文件返回给用户. 在上述没有保护索引隐私的基础构造的基础上, Wang 等人分别利用Paillier 同态加密和伪随机置换加密IFV 设计了两个适应性选择询问攻击安全和前向安全的相似搜索方案.
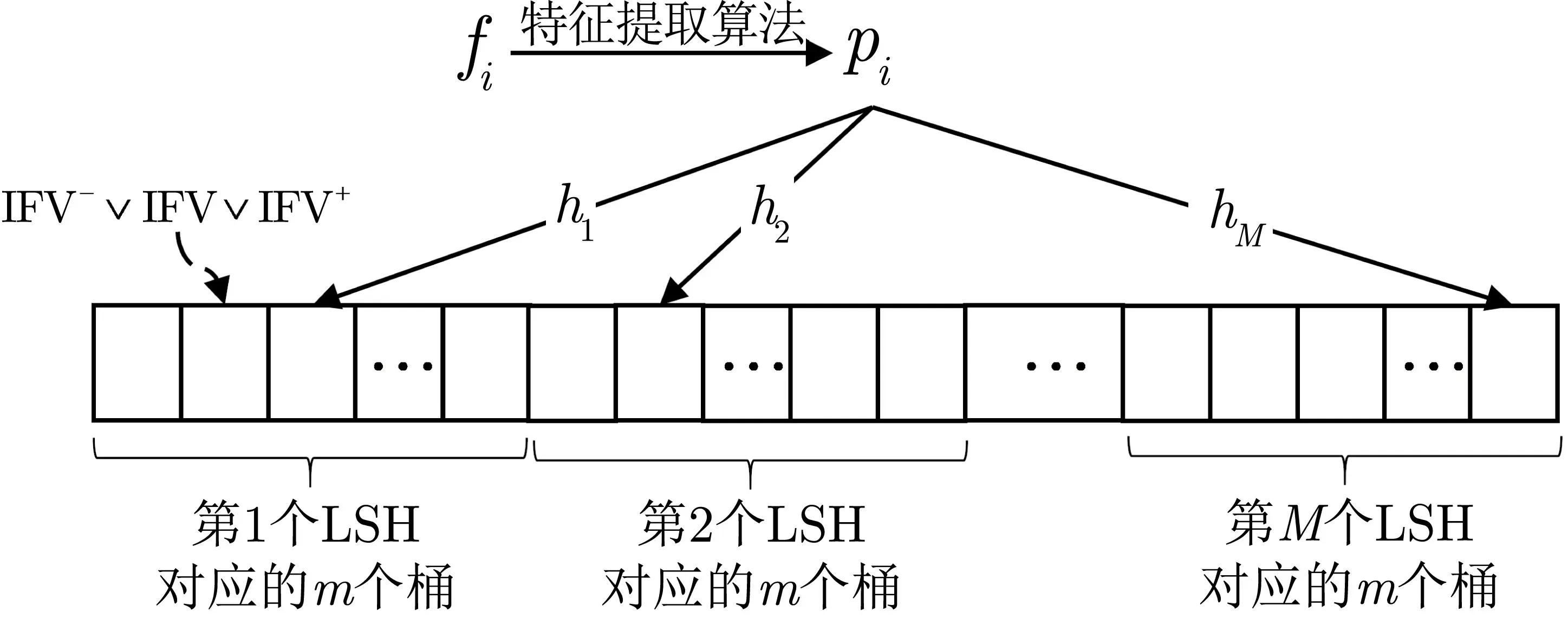
图13 基础索引结构Figure 13 Structure of basic index
2.3 多关键词对称可搜索加密
在传统的可搜索加密方案中, 用户只能通过对单个关键词生成陷门的方式进行搜索. 但在实际执行搜索操作时, 仅使用一个关键词往往无法准确描述需要搜索的目标数据, 例如: 管理员需要在学生信息管理系统搜索“硕士二年级” 或“硕士三年级” 的学生名单.
对于上述情形, 如果利用传统的可搜索加密, 通常有两种方法可以采用: (1) 为每个关键词分别生成陷门, 对每个关键词单独进行搜索, 再根据搜索关键词之间的逻辑关系对搜索结果进行交并集运算(由服务器或用户执行) 确定最终的文档集, 例如: 用户分别对关键词“硕士”、“二年级” 与“三年级” 生成陷门, 记作T1,T2,T3, 然后将T1,T2,T3上传到云服务器. 云服务器在接收到陷门后, 根据安全索引进行搜索得到分别包含关键词“硕士”、“二年级”与“三年级”的文件标识符,记作id1,id2,id3,然后将id1,id2,id3返回给用户, 用户端计算(id1∩id2)∪(id1∩id3), 得到最终的搜索结果id 集并向服务器请求返回密文文件. 或者用户也可以在上传陷门的同时, 将搜索关键词对应的逻辑关系上传到云服务器, 即(T1∩T2)∪(T1∩T3),这时服务器在搜索得到单关键词对应的文件id 后, 可以直接进行交并运算, 最后返回对应密文文档; (2)对所有可能要搜索的关键词组合建立索引存储在服务器端, 以方便进行此类搜索, 例如: 用户除对所有的单关键词建立索引之外, 对“(硕士∩二年级)∪(硕士∩三年级)” 也生成相应的索引. 搜索时, 生成(硕士∩二年级)∪(硕士∩三年级) 对应陷门发送给服务器, 服务器根据安全索引进行搜索得到对应密文文件返回给用户.
显然, 上述两种利用传统可搜索加密搜索的方法都是不可取的. 方法(1) 会使服务器获知与每个单关键词匹配的文档, 泄露过多的信息; 方法(2) 会使索引存储以指数形式增长. 因此, 设计专门针对多关键词搜索的可搜索加密方案是很有实际意义和价值的.
根据搜索的多个关键词之间的逻辑关系, 可将多关键词可搜索加密分为以下三类:
(1) 联合关键词搜索(conjunctive-keyword search). 联合关键词搜索为多个关键词之间的逻辑关系为交的搜索, 即搜索同时包含搜索关键词集中所有关键词的文件.
(2) 分离关键词搜索(disjunctive-keyword search). 分离关键词搜索为多个关键词的逻辑关系为并的搜索, 即搜索包含搜索关键词集中关键词的文件.
(3) 布尔搜索(Boolean search). 布尔搜索是指多个关键词之间的逻辑关系为布尔运算的搜索.
上述三种类型的搜索统称为一般多关键词可搜索加密. 在实际搜索中, 为了提高搜索准确性, 减少带宽开销, 用户往往需要服务器根据搜索结果和排序标准返回与搜索条件相关性最强的前k个文件, 这种搜索称为多关键词排序可搜索加密.
因此, 基于是否对搜索结果排序, 可将现有的多关键词SSE 方案分为以下两类:
2.3.1 一般多关键词可搜索加密
2004 年, Golle 等人[39]最早对多关键词可搜索加密进行研究. 首先针对联合关键词形式的搜索定义了一个新的安全模型: 选择关键词攻击索引不可区分(indistinguishability of ciphertext from ciphertext,ICC), 与IND-CKA 本质上相同, 但由于该安全模型是针对联合关键词搜索提出的, 故在询问阶段ICC 允许询问联合关键词的陷门, 而在IND-CKA 中只允许询问单关键词的陷门. 其次提出了两个满足ICC 安全的支持联合关键词搜索的可搜索加密方案, 第一个方案无需双线性对运算, 只通过简单的指数运算和伪随机函数作用即可完成多关键词搜索, 安全性依赖于Decisional Diffie-Hellman (DDH) 假设, 每次查询的通信复杂度成本与文件集的大小n成线性关系, 然而, 该成本的线性部分可以被预先发送, 当用户确定感兴趣的查询关键词时, 用户发送常数大小的查询部分. 第二个方案的通信复杂度为常数, 但因基于双线性映射, 在搜索时需要双线性对计算, 效率较低, 该方案的安全性依赖于Bilinear Decisional Diffie-Hellman(BDDH) 假设.
文献[39] 实现了对于加密数据的联合关键词搜索功能, 虽然达到了ICC 安全, 但ICC 安全模型并没有考虑陷门的安全性, 在这两个方案中服务器都会知道用户搜索的关键词字段. 另外这两个方案都是通过构造正向索引, 依次遍历文件索引进行搜索, 即搜索时间复杂度与文件数量成线性关系, 因此该方法只适用于小型数据库.
2005 年, Ballard 等人[40]提出了两个联合关键词对称可搜索加密方案. 第一个方案基于Shamir 秘密共享, 虽然在效率方面较文献[39] 有所提升, 但通讯复杂度仍与文件数量成线性关系. 为了解决该问题,提出了第二个方案, 该方案基于双线性对, 以服务器端大量的计算量为代价使得通讯复杂度为常数, 比文献[39] 提出的通讯复杂度为常数的方案更为有效. 两个方案都在标准模型下是可证安全的.
虽然文献[40] 比文献[39] 更为有效, 但与文献[39] 有相同的缺陷, 在搜索时仍会泄露搜索关键词对应的字段, 索引也为正向索引, 即只适用于小型数据库.
对称可搜索加密中存在一个特定的安全问题, 当执行联合关键词搜索时, 陷门和搜索结果会揭示搜索关键词之间的关系. 例如, 如果关键词集A 的搜索结果是关键词集B 的超集, 则有很大概率说明A 是B的子集. 而大多数支持联合关键词搜索的方案[39,40]都不能抵抗这种包含关系(inclusion-relation, IR) 的攻击.
2013 年, Cai 等人[41]首次给出了针对IR 攻击正式的安全性定义IR-secure, 并提出了一个基于BF的安全联合关键词搜索方案CKS-SE. CKS-SE 通过在生成陷门时在搜索关键词集对应的伪随机函数值集合中随机选取t个值, 而不是全部的伪随机函数值作为陷门, 使得搜索关键词集与陷门之间生成多对多映射, 从而达到IR-secure.
2013 年, Cash 等人[42]指出通过对搜索关键词集中每个关键词进行单关键词搜索然后对搜索结果求交实现联合关键词搜索的方法复杂度高且泄露信息较多. 另外在现有的可以实现联合关键词搜索的方案[39,40] 中搜索效率与文件数量d成线性关系, 要么需要O(d) 的通信复杂度, 要么需要复杂度为O(d)的双线性对运算, 且都不能扩展到一般的布尔搜索. 因此, Cash 等人提出了第一个搜索效率为亚线性, 可以实现联合关键词搜索, 且可以扩展到一般布尔搜索的可搜索加密方案OXT(oblivious cross-tags) 协议.在提出OXT 之前提出了一个基础协议BXT, BXT 利用了两个数据结构T-set 和X-set, T-set 和X-set存储的都为包含对应关键词的文件标识符(identifier, ind) 向量, 但形式不同. T-set 中存储包含对应关键词ind 的密文(称为stag), 与倒排索引类似; X-set 存储(w,ind) 形式的密文(称为xtag). 搜索时, 用户首先选取搜索关键词集中词频最低的关键词(称为s-term), 生成对应的stag, 并生成其余搜索关键词(称为x-term) 对应的xtrap, 然后将所有的stag, xtrap 及最低词频关键词加密ind 的密钥上传到服务器. 服务器首先依据stag 对T-set 进行搜索得到包含最低词频关键词的密文ind, 并利用密钥解密得到明文ind集, 然后利用xtrap 对X-set 检测ind 集中每个文件是否包含其余关键词. BXT 使得联合关键词的搜索复杂度降为O(min{DB(wi)}), DB(wi) 为包含wi的文件数, 泄露的信息集中在min{DB(wi)}中ind与其他关键词的关系, 安全性有所提升. 但由于在生成陷门时xtag 与stag 是独立的, 故服务器可以通过在一次搜索中得到的xtrap 对另一次搜索中包含s-term 的ind 进行检测, 例如: 通过搜索历史(w1,w2)与(w′1,w′2), 服务器可以知道(w1,w′2) 与(w′1,w2) 的搜索结果.
为了解决上述问题, Cash 等人最终提出OXT 协议, 更改主要体现在生成陷门时, 使得x-term 的陷门与s-term 的陷门不是独立的, 进而服务器不能由用户生成过的搜索陷门生成新的搜索陷门, 进一步提高了安全性.
虽然文献[42]可以实现一般的布尔搜索, 但只有在搜索表达式形式为w1∩φ(w2,··· ,wn)且DB(w1)较小时才是高效的. 而对于一般分离关键词形式的搜索, 需要找到一个所有文件包含的关键词w, 将搜索表达式转化为w ∩φ(w1,··· ,wn) 形式进行搜索, 而此时搜索复杂度仍为O(d). 另外在实际搜索场景中,搜索关键词集中每个关键词频次都很高的情形也是很常见的, 这时OXT 将不再是高效的.
2017 年, Kamara 等人[43]提出了非交互式高效的SSE 方案IEX, 解决了文献[42] 中OXT 只能对常规搜索形式的询问执行亚线性搜索的问题, 该方案能够对任意分离和布尔询问执行亚线性搜索, 实现最佳的通信复杂度, 即服务器返回没有重复的文件标识符的标签, 并且可以动态的增加和删除文件. Kamara等人首先针对询问w1∨w2∨···∨wq构造了最坏情况的亚线性分离关键词可搜索加密方案IEX, 由于每个布尔询问都可以表示成Δ1∧Δ2∧···∧Δl, Δi=wi,1∨wi,2∨···∨wi,q, 可以用IEX 方案实现布尔搜索. IEX 方案的索引EDB 由加密的字典EDX 和加密的全局多映射EMM 结构组成. IEX 只是一个抽象的结构, 需要对字典和多映射的结构加密方案具体实例化, Kamara 等人提出两种加密多映射的方案,分别是基于文献[44] 的2Lev 和文献[19] 的Z-IDX 构造, 前者提供了最优的通信复杂度, 但存储量巨大,后者平衡了效率和存储的关系, 使得存储量缩小近100 倍.
2018 年, Du 等人[45]对加密云存储的搜索提出了一个新的索引设计, 称为概率倒排索引编码结构.如图14 所示, 首先从文件集d={d1,d2,··· ,d#d}中提取关键词集w={w1,w2,··· ,w#w}, 为关键词集中的每个关键词生成一个数据标识符向量(data identifier vector, DIV), 如果文件dj包含关键词w, 则w对应div 的第j个分量为1, 否则为0. 其次初始化一个由m个桶组成的数组γ, 对于∀wj ∈w, 计算r个哈希桶的位置x1=h1(wj,sk1),··· ,xr=hr(wj,sk1), 对于每一个位置xi, 如果γ[xi] 为空, 则将divj直接存放在桶中, 否则将divj与桶中现存的向量做逐比特异或, 然后存放在桶中. 该索引结构支持联合和分离的多关键词搜索, 文件的动态更新, 但是没有保护div 的隐私. 因此, 在基础的倒排索引编码结构的基础上, Du 等人分别利用随机生成器(伪随机函数) 和同态生成器(同态加密) 提出了两个桶加密索引结构BEIS-I 与BEIS-II. BEIS-I 与BEIS-II 均支持联合和分离逻辑的多关键词搜索、文件的动态更新, 并满足CKA2 安全和前向隐私.
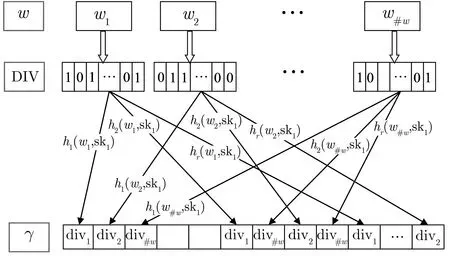
图14 概率倒排索引Figure 14 Probabilistic inverted index coding structure
2018 年, Lai 等人[27]明确指出OXT 方案[42]泄漏了单关键词结果模式(single keyword result pattern, SP), 关键词对结果模式(keyword pair result pattern, KPRP) 以及多重关键词跨查询交叉结果模式(intersection result pattern, IP) 泄漏. 为了解决OXT 中KPRP 的泄漏, Lai 等人提出HXT 方案,HXT 以OXT 为原型, 利用轻量级的对称隐藏向量加密判断在对称加密下搜索的关键词集是否为文件提取的关键词集. 在此过程中, 相较于OXT 多了一轮交互, 用于传输隐藏向量加密中的判断密文, 只有当服务器调用隐藏向量加密的query 算法返回true 时, 才表明此结果包含所有的关键词. 否则, 服务器只知道该文档不含有所有的关键词, 而不知道具体不含有哪些关键词, 因此关键词没有KPRP 的泄漏.
2020 年,Ma 等人[46]指出不管是OXT[42]还是HXT[27],都需要进行指数运算. 为了提高计算效率,Ma 等人提出了一个新的对称原语Hashed-based subset mmbership check (HSMC), 该原语通过sender和tester 之间的交互协议判断加密集合之间的子集关系, 执行完协议之后, 除集合之间的子集关系外, 不会泄漏其他信息, 并且该原语基于hash 运算, 效率较高. Ma 等人基于HSMC 提出两个方案PHXT 和FHXT, 与HXT 相比, PHXT 用HSMC 替换了HXT 中的隐藏向量; FHXT 把TSet 中的t向量而不是|t| 发送给用户, 因此在执行完HSMC 算法后, 用户可以直接解密获得对应的id, 因此少一轮交互.
2.3.2 多关键词排序可搜索加密
基于使用的工具, 多关键词排序可搜索加密可分为以下三类:
(1) 保序加密
2007 年, Swaminathan 等人[47]通过简单地将搜索关键词集中所有关键词的相关性分数相加, 将基于保序加密(order-preserving encryption, OPE) 的单关键词排序可搜索加密方案扩展到多关键词场景.如图15 所示, 左图为未加密的索引, 表中数据代表文件与关键词两两之间的明文相关性分数; 右图为密文索引, 表中数据为利用OPE 加密的文件与关键词两两之间的密文相关性分数. 搜索时, 直接将关键词集包含的关键词的密文相关性分数相加作为最终的相关性分数, 如搜索包含w1和w2的文件时,F1与搜索条件的相关性得分为15(12+3),F2与搜索条件的相关性得分为19(3+16). 由于OPE 会将原始数据扩展为范围更大的密文数据, 会使加密总分数不能完全保留排序, 例如未加密之前对于搜索条件w1∩w2,F3的相关性得分为1.6,F4的相关性得分为2.7, 即F4的相关性强于F3, 而利用OPE 加密后F4的相关性(21) 弱于F3(22), 因此排序结果不准确.
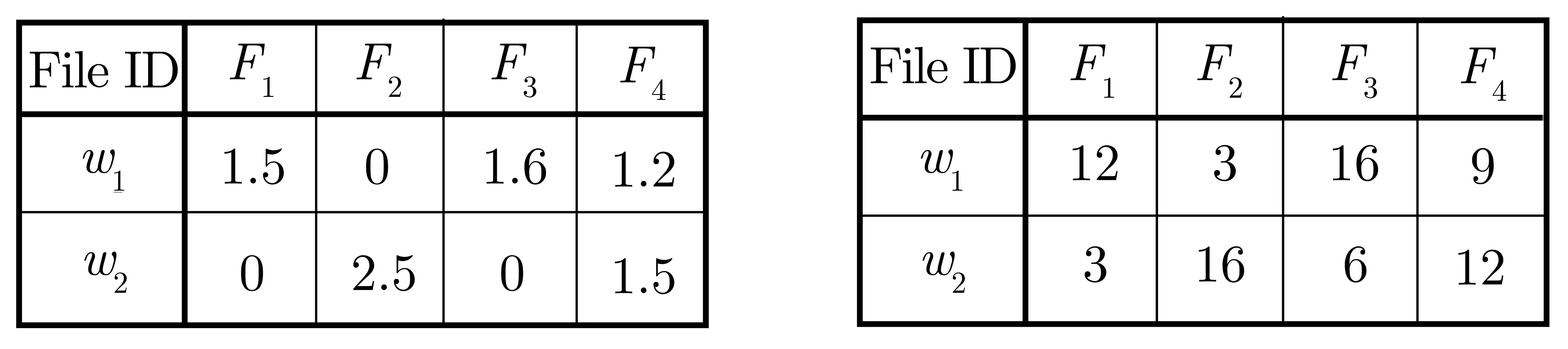
图15 基于OPE 的多关键词排序搜索Figure 15 Multi-keyword ranked search based on OPE
2012 年, Xu 等人[48]基于文献[47] 提出一个两步排序策略来实现更准确的排序结果. 第一步以“坐标匹配” 的方式对文档进行粗略排序, 即根据每个文档包含的搜索关键词的数量对文档进行分类, 在第二步中, 对于在第一步中得到的每个分类利用与文献[47] 相同的方法进行进一步地排序. 虽然Xu 等人的方案比文献[47] 排序准确性有所提高, 但由于在每个分类中仍采用与文献[47] 相同的方法, 故仍然存在相同的排序准确性问题, 且由于OPE 自身的加密特性, 会不可避免地泄露一些数据隐私.
(2) 向量空间模型——安全KNN
2011 年, Cao 等人[49]通过将每个文件和搜索关键词集表示为维数为关键词字典大小的0/1 向量, 结合安全的KNN 加密, 提出了多关键词密文排序搜索方案MRSE. 具体地, 向量的每个分量代表关键词字典中的一个关键词, 在生成文件对应的向量时, 若文件包含某个关键词, 则该关键词对应分量为1, 否则为0; 在生成搜索关键词集对应的向量时, 若搜索关键词集包含某关键词, 则该关键词对应分量为1, 否则为0. 通过安全的KNN 对文件向量和搜索向量加密, 计算加密的文件向量与加密的搜索向量之间的内积, 利用“坐标匹配” 度量文件与搜索多关键词之间的相关性, 内积越大, 说明对应文件包含的搜索关键词数越多, 相关性越强.
关键词词频在一定程度上反映了关键词对文件的重要程度, 对文件进行排序时应考虑关键词的重要程度. 而在MRSE 中将文件和搜索关键词集表示为0/1 向量只考虑了文件包含搜索关键词的数量, 并未考虑关键词对文件的重要程度.

由于文献[49,50] 在搜索时都需要通过计算每个文件向量与搜索向量的内积得到相关性分数然后排序, 因此搜索效率与文件数量是成线性关系的. 为了提高搜索效率, 后续研究者提出了许多新颖的索引树结构实现了优于线性搜索的搜索效率:
2015 年, Xia 等人[51]通过构建关键词平衡二叉树(keyword balanced binary tree, KBB-Tree) 索引提出一个动态的多关键词密文排序搜索方案DMRS. KBB-Tree 自下而上构建, 每个叶子节点代表一个文件, 存储该文件代表的文件向量, 中间结点存储筛选向量, 筛选向量的每个分量为其子节点对应分量的最大值. 利用安全KNN 加密每个节点存储的向量. 搜索时, 可通过筛选向量排除不包含搜索关键词文件的子树, 有效的缩小搜索范围, 并利用“深度优先搜索” 算法提高搜索效率.
由于在构建KBB-Tree 时, 叶子节点的放置是随机的, 而叶子节点的位置显然会影响搜索效率, 故可以通过选取有效的叶子节点放置方法提高DMRS 的搜索效率.
2015 年, Chen 等人[52]考虑文件之间的相关性, 在MRSE[50]的基础上提出了一个基于层次聚类的多关键词排序可搜索加密方案(MRSE-HCI).MRSE-HCI 通过引入二分k-means 的层次聚类方法自顶向下构建层次聚类索引树, 初始时整个文件集合为一个簇, 利用二分k-means 划分簇, 直至划分得到的子簇中包含的文件数量不超过给定的阈值. 划分簇的过程即为层次聚类索引树(hierarchical clustering index tree, HCI-Tree) 的构建过程. HCI-Tree 中每一个节点代表一个簇, 存储簇中所包含文件的数量和这些文件对应的中心向量, 叶子节点与其包含的文件直接关联. 文件向量同MRSE 仍利用TF-IDF 和向量空间模型生成, 并利用安全KNN 加密各个节点中的向量. 搜索时, 从HCI-Tree 第一层开始计算簇中心向量与搜索向量的内积, 然后选取内积小的结点继续进行该过程直到找到最小聚类簇, 计算最小聚类簇中文件向量与搜索向量的内积得到相关性得分, 若该最小聚类簇中的文件数量小于用户提前选定的所要搜索的文件数k, 则服务器追溯到该结点的父节点搜索得到该节点的兄弟节点, 重复此过程直到搜索到k个文件.
2019 年, Guo 等人[53]基于MRSE, 引入BF 构建平衡二叉索引树, 提高搜索效率. 索引树自下而上进行构建, 每个叶子节点对应一个文件, 存储文件id, 文件向量和文件的BF, 非叶子节点存储其子节点对应BF 的或, 利用安全KNN 加密叶子节点的文件向量. 根据搜索关键词生成其对应的搜索向量和BF. 搜索时, 首先利用BF 自上向下进行搜索, 排除掉不可能匹配的子树, 最后利用搜索向量与文件向量计算相关性分数得到top-k文件.
虽然通过树形索引的建立实现了优于线性搜索的搜索效率, 但由于原本通过将每个文件表示为空间向量模型中的点, 然后利用安全KNN 加密每个向量实现多关键词排序搜索的方法时空开销大, 而树形索引建立的同时会产生大量的中间节点, 进一步增加了时空开销.
(3) 向量空间模型——同态加密
2013 年, Yu 等人[54]通过引入相似相关性和方案稳健性的概念说明基于OPE 且在服务器端进行排序操作的多关键词密文排序可搜索加密技术会不可避免的泄露数据隐私, 并利用向量空间模型和同态加密(homomorphic encryption, HE) 设计了一个在用户端排序的搜索时需要两轮交互的多关键词密文排序搜索方案TRSE. 生成索引时, 首先为文件集中每个文件生成对应的文件向量, 向量的每个分量为对应关键词与文件的相关性分数, 然后利用HE 加密每个分量, 生成文件对应的索引; 陷门生成时, 根据搜索关键词集, 生成搜索向量, 若搜索关键词集包含某关键词, 则对应分量为1, 否则为0, 然后利用HE 加密每个分量. 搜索时服务器计算每个加密的文件向量与加密的搜索向量的内积, 得到密文相关性分数, 并将其发送给用户, 用户端进行解密得到明文相关性分数并进行排序, 最后向服务器请求返回相应的top-k密文文件.
虽然文献[54]在用户端完成排序操作, 在一定程度上保护了数据隐私, 但由于是基于同态加密实现的,效率较低且用户端计算量大.
3 复杂语义对称可搜索加密之间的关系
目前关于通配符、模糊关键词、多关键词这三种类型的复杂语义SSE 已有了一系列的研究成果. 但据我们所知, 目前还没有学者对这三者之间的关系进行过研究. 而探索这三者之间的关系, 一方面可以激发我们从多角度的思维设计这三种类型的复杂语义SSE 方案; 另一方面可以激发设计多种复杂语义结合的SSE 方案的思路. 因此, 本节不仅对已有的研究成果中这三类复杂语义SSE 之间的关系进行研究, 同时提出一种新的通配符SSE 关键词特征提取方式, 进而引入了一种将通配符SSE 转化为一般多关键词SSE 的方法.
3.1 通配符与模糊关键词对称可搜索加密的关系
通配符与模糊关键词搜索虽然是分别为解决不能进行完整关键词和精确关键词搜索而提出的两种不同的复杂语义可搜索加密, 但现有的关于这两种复杂语义搜索的研究成果又有紧密的联系. 如图16 所示,通过提取特征构造的通配符SSE 与基于LSH 的模糊关键词SSE 都是首先通过对索引关键词与搜索关键词提取特征得到特征集, 再利用哈希函数将特征集插入到过滤器中, 生成关键词对应的索引和陷门. 不同的是, 在通配符可搜索加密中, 只要索引关键词符合通配符关键词形式则表明匹配成功, 即索引关键词的特征集应包含陷门关键词的特征集, 故在搜索时直接比对陷门过滤器与索引过滤器即可; 而在模糊关键词搜索中我们想要搜索的是包含与搜索关键词尽可能相似的关键词的文件, 故需进一步计算索引过滤器和陷门过滤器的LSH 值, 利用LSH 的性质刻画两者的相似性.

图16 通配符与模糊关键词搜索对比Figure 16 Comparison between wildcard and fuzzy search
3.2 通配符与多关键词对称可搜索加密的关系
现有解决通配符可搜索加密的技术主要有枚举与提取特征两种, 虽然这两种技术是针对通配符搜索提出的, 但这两种通配符搜索技术本质上可分别转化分离关键词与联合关键词这两种形式的多关键词可搜索加密. 另外, 我们提出了一种新的关键词特征提取方式, 使得通配符可搜索加密可转化为一般的多关键词可搜索加密.
3.2.1 通过枚举构造的通配符SSE 可转化为分离关键词SSE
文献[21] 通过为文件集中每个关键词建立一个布隆过滤器, 然后将矩阵型的索引压缩为数组形式生成最终的索引. 为了实现通配符搜索, 对搜索关键词生成陷门时, 枚举所有可能的关键词, 然后用r个hash 函数作用在每个关键词上建立一个BF, 本质即为搜索语句为所有可能的关键词求并的分离关键词搜索.
3.2.2 通过提取特征构造的通配符SSE 可转化为联合关键词SSE
文献[22–24] 通过对索引关键词与搜索关键词提取特征, 然后将特征集通过哈希函数映到过滤器, 生成陷门过滤器和索引过滤器, 最后通过将陷门过滤器与每个关键词对应的索引过滤器比对进行搜索, 若陷门过滤器为1 的位置在索引过滤器对应位置也都为1, 则说明匹配成功, 即为对特征集同时包含搜索关键词特征集中所有特征的关键词的搜索, 例如在文献[23] 对含通配符的关键词c*o*d 提取得特征得到特征集{c||1,d||-1,c||0,o||0,d||0}, 本质即为搜索语句为(c||1)∩(d||-1)∩(c||0)∩(o||0)∩(d||0) 的联合关键词搜索.
3.2.3 通配符SSE 可转化为一般多关键词SSE
通过上述说明现有的一些通配符可搜索加密方案可转化为分离关键词搜索或联合关键词搜索. 现在我们提出一种新的关键词特征提取方式, 使得通配符SSE 可转化为一般的多关键词SSE. 我们根据关键词包含的通配符类型分情况说明: 当关键词包含单字符通配符“?” 时, 通过枚举通配符“?” 可能代表的字符然后提取关键词中所有的2-gram 字符串; 当关键词包含多字符通配符“*” 时, 提取关键词中除“*” 之外的2-gram 字符串. 下面我们通过具体的例子具体解释特征提取方式及如何将通配符搜索转化为一般多关键词搜索.
(1) 关键词key?ord 的特征集为{ke,ey,{ya,yb,··· ,yz},or,rd}, 可转化为搜索表达式为“ke∩ey∩(ya∪yb∪···∪yz)∩or∩rd” 的布尔关键词搜索;
(2) 关键词key*rd 的特征集为{ke,ey,rd}, 可转化为搜索表达式为“ke∩ey∩rd” 的联合关键词搜索.
3.3 模糊与多关键词对称可搜索加密的关系
利用编辑距离构造的模糊关键词SSE 可转化为分离关键词SSE. 具体地, 文献[28] 利用编辑距离刻画关键词之间的相似度, 通过通配符和克(gram) 两种技术来构造模糊关键词集合进而实现模糊关键词搜索. 搜索时, 只要索引关键词对应的模糊关键词集包含搜索关键词对应的模糊关键词集中的其中一个关键词, 则说明匹配成功, 即本质为搜索关键词对应的模糊关键词集中所有关键词的分离关键词搜索. 例如搜索关键词为CASTLE, 则编辑距离为1 的基于通配符的模糊关键词集合为SCASTLE,1={CASTLE,*CASTLE,*ASTLE,C*ASTLE,C*STLE,··· ,CASTL*E,CASTL*,CASTLE*}, 可以看做搜索语句为CASTLE∪*CASTLE∪*ASTLE∪C*ASTLE∪C*STLE∪···∪CASTL*E∪CASTL*∪CASTLE* 的分离关键词搜索.
图17 总结了我们上述提到的这三者之间的关系.
图17 三者之间的关系Figure 17 Relationship among three SSEs
4 存在问题及研究思路
从复杂语义可搜索加密提出的背景介绍中可以看出, 与只能实现完整的、精确的单关键词搜索的传统可搜索加密相比, 这些功能多样化的复杂语义可搜索加密更符合实际搜索场景. 但现阶段关于复杂语义可搜索加密的研究还尚未成熟, 仍存在一些待解决的问题.
4.1 通配符对称可搜索加密
通配符可搜索加密是为了解决用户在对密文数据搜索时不能提供完整关键词的情形而提出的, 在现有针对通配符搜索的两种主流技术中, 虽然提取特征技术比枚举技术在效率与存储方面都有所优化, 但由于其使用的工具BF 存在不可避免的弊端及提取特征的方式还尚未成熟, 使得基于提取特征技术的通配符可搜索加密还不足以应用于实践. 因此, 通配符对称可搜索加密未来的研究工作可围绕以下几点展开:
4.1.1 关键词特征提取方式的优化
基于布隆过滤器的通配符SSE 方案中, 通过对关键词提取特征构造索引和陷门的方案在效率和存储量方面与枚举法相比显然都是更为有效的. 在这些方案中, 文献[22] 提取特征的方式最为简单, 且服务器端存储量小, 但这种简便的提取方式使得方案只能实现单字符通配符关键词搜索. 文献[23,24] 通过对提取特征的方式进一步细化, 实现了多字符通配符关键词搜索, 但同时也导致效率降低、存储量增大. 由此可见, 关键词的特征提取方式对方案的搜索功能、效率和存储量都有重要的影响. 因此, 构造能够同时实现单字符和多字符通配符搜索且效率和存储量都较为有效的特征提取方式将是一项有意义的工作.
4.1.2 实现无假阳性通配符可搜索加密有效工具的探索
现有的大多数通配符SSE 都是基于布隆过滤器构造索引, 但如文献[55] 所指出, 布隆过滤器一个显著的弊端就是假阳性不可避免, 即会返回多余的密文文件给用户, 这不仅增加了通讯复杂度, 还增加了用户对密文文件的处理负担. 因此探索能够实现无假阳性搜索结果的通配符可搜索加密的有效工具将是一个有意义的研究.
4.2 模糊关键词对称可搜索加密
模糊关键词可搜索加密允许用户在对密文数据搜索时输入中存在微小的拼写错误或形式不一致问题.已有的模糊关键词对称可搜索加密方案大多数都是首先将关键词转化为向量, 然后利用LSH 刻画关键词的相似性. 但关键词向量转化方式还不够完善, 使得其不能有效地兼容搜索时的关键词拼写错误或形式不一致的问题, 且LSH 有其不可避免的弊端, 对搜索准确性和通讯复杂度有一定的影响. 因此, 我们对模糊关键词对称可搜索加密的研究应特别关注:
4.2.1 关键词向量转化方式
在现有的利用局部敏感哈希实现对密文数据的模糊关键词搜索方案中, 都需要首先将关键词转化为具有LSH 的度量空间对应的向量, 再利用LSH 度量关键词对应向量间的相似性. 文献[31,32] 通过提取关键词的“bigram” 特征生成关键词对应向量; 文献[33] 指出将关键词转化为“bigram” 会增大欧几里得距离, 对除一个字母拼写错误以外的其他拼写错误不是有效的, 且不支持相同词根的关键词搜索, 文献[33]通过引入“词根提取算法”, 且将关键词转化为“uni-gram” 实现了更为准确的搜索结果; 文献[35] 指出文献[33] 提出的将关键词转化为“uni-gram” 缺少了字母的顺序消息, 无法识别“相同字母异序词”. 为了提高搜索准确性, 文献[35] 提出将关键词转化为“order-preserving uni-gram” 向量. 由此可见关键词的向量转化方式, 对关键词之间相似性的刻画有重要的影响, 从而影响搜索准确性.
4.2.2 搜索相似关键词的有效工具
局部敏感哈希是一种针对海量高维数据的快速最邻近查找方法, 因此被用来搜索与陷门关键词相似的索引关键词, 但其不可避免的会同时存在假阳性与假阴性. 虽然我们可以通过已知的LSH 构造新的LSH从而减小假阳性与假阴性的概率, 但其概率始终会大于0, 搜索相似关键词的有效工具对搜索准确性、通讯复杂度都有重要影响.
4.3 多关键词对称可搜索加密
多关键词可搜索加密使得用户在对密文数据搜索时可以使用多个关键词刻画目标数据, 提高了用户的搜索体验. 但目前对多关键词加密搜索的研究, 多数只能实现联合关键词的有效搜索, 而对于更一般的布尔搜索还没有有效的解决方案. 除此之外, 为了减少通讯复杂度而提出的大多数多关键词排序搜索方案安全性较弱. 因此, 对多关键词对称可搜索加密的研究应特别关注:
4.3.1 有效的布尔可搜索加密方案的设计
在目前现有的多关键词可搜索加密方案中, 文献[27,42,46] 中使用的两级索引能够实现亚线性的联合关键词搜索, 在效率方面是较有优势的, 但时间复杂度随着搜索关键词数量的增加而增加, 且性能主要却决于s-term 中关键词的选择. 在实际搜索场景中, 搜索关键词集中每个关键词频次都很高的情形也是很常见的, 这时这些方案将不再是高效的. 另外, 这些方案只能对常规的搜索形式为w1∩φ(w2,··· ,wn)的询问实现亚线性的搜索, 而对于分离关键词形式的搜索, 搜索复杂度仍与文件数量成线性关系. 虽然文献[43] 提出了能够对任意分离和布尔询问执行亚线性搜索的方案IEX, 但对IEX 的两个具体实例化方案要么效率低, 要么存储量大. 因此, 设计有效的布尔可搜索加密方案是一个亟待解决的问题.
4.3.2 用户端排序的多关键词可搜索加密方案
现有的关于多关键词排序可搜索加密的研究工作中, 大多数排序操作在服务器端执行, 但在服务器端排序会不可避免的泄露一些统计信息, 这对有一定背景知识的敌手很容易造成一定的隐私泄露. 因此排序操作在用户端实现是更为安全的, 但现有的能在用户端排序的方案效率较低. 因此, 设计用户端排序的多关键词可搜索加密方案有重要意义.
5 总结
复杂语义可搜索加密虽然是依据用户在实际搜索时可能会出现的不同搜索情形提出的, 但现有的一些通配符、模糊关键词可搜索加密方案本质上可看作多关键词可搜索加密, 而且这些搜索情形往往也不是单独出现的, 因此, 各种类型的复杂语义可搜索加密并不是相互独立的, 设计多种复杂语义关键词搜索相结合的可搜索加密方案是很重要的.
