基于BTM 主题模型的对称可搜索加密方案*
2022-03-10薛玉洁陈兰香
薛玉洁, 陈兰香, 穆 怡
1. 福建师范大学 计算机与网络空间安全学院 福建省网络安全与密码技术重点实验室, 福州350117
2. 澳门城市大学 数据科学学院, 澳门
1 引言
随着互联网的迅速发展, 各种各样的数据文档与日俱增, 为了节约大规模数据的管理成本, 越来越多的企业选择将数据外包到第三方云存储服务器上. 云存储的发展带来数据加密的需求, 密文数据搜索得到极大关注, 取得了丰硕的研究成果. 但是当前的密文检索方案主要是基于关键词检索[1–7], 并没有考虑用户所查询的关键词与文档的潜在语义特征, 这可能导致云端返回的检索结果与用户期望的主题不一致, 从而限制了密文检索的准确度和效率.
近年来, 许多学者基于关键词检索实现了各种可搜索加密方案, 例如单关键词搜索[1,3,8–10]、多关键词搜索[11–15]、模糊关键词搜索[16,17]以及连接关键词搜索[12,13,18]等. 文献[11] 使用TF-IDF 向量空间模型来计算词频和反向文档频率, 相关度是TF-IDF 向量间的内积, 以此来比较关键词与文档的相关度.文献[7,9,19] 使用安全K最邻近算法(KNN) 生成加密文档向量和加密索引(倒排索引、树索引和布隆过滤器等), 加密后将其外包给云, 一旦用户需要开始检索, 将生成查询关键词的陷门, 并使用加密索引实现密文检索. 然而, 这些方案都没有考虑用户所查询的关键词和文档的潜在语义特征, 从而导致检索结果与用户期望不符. 此外, 传统的基于关键词的密文搜索方案需要对所有文档提取关键词, 然后根据所有关键词构建倒排索引, 其构建的索引规模都比较大, 因此需要探索能够缩小索引规模的方案.
主题模型是在文本建模与文本搜索等领域中发现文本间潜在语义的语义模型[20]. 1990 年, Deerwester 等[20]提出潜在语义分析(latent semantic analysis, LSA) 模型, 它主要利用奇异值分解(singular value decomposition, SVD) 降维的方式, 将词与文本映射到一个以主题作为维度的新的空间. 潜在狄利克雷分配(latent Dirichlet allocation, LDA) 模型[21]是最早被广泛应用的主题模型, 该模型是基于贝叶斯学习的话题模型, 主要应用于自然语言处理领域, 它将每个文档视为不同主题的混合体, 同时每个主题又被视为一组关键词, 同一主题中的关键词具有相似的语义. 然而传统的主题模型(上述LSA 与LDA等) 在处理短文本, 如直播间弹幕和微博, 会因为词语过于稀疏而使得模型效果不佳.
为了解决该问题, 文献[22] 在原来LDA 模型的基础上进行改进, 提出基于Biterm 的主题模型(biterm topic model, BTM), BTM 模型在短文本上的处理效果比LDA 好, 即使对于长文本, BTM 的效果也不比LDA 差. BTM 主题模型可用来对关键词和文档之间的潜在语义进行建模, 并揭示出主题、文档和关键词之间的关系. 基于主题进行检索的目标就是通过用户的待检索关键词找出对应主题, 通过主题来对文档进行搜索, 使得检索的文档从语义角度更加符合用户的期望.
借鉴BTM 主题模型在明文检索领域的优势, 本文提出一个基于BTM 主题模型的高效密文检索方案, 利用平衡二叉树和倒排索引构建安全索引. 数据拥有者首先训练出语料库在不同主题个数下的模型,并且分别计算它们的困惑度和一致性参数, 根据这两个参数指定语料库的主题个数. 然后提取每个主题的关键词概率分布向量, 生成主题-关键词的分布矩阵, 以此为基础构建出可实现主题检索的平衡二叉树索引. 每个文档都有一个包含潜在语义特征的主题向量, 由此易于构建文档-主题概率分布矩阵, 为了提升检索效率, 本文根据该矩阵构建出了主题-文档的倒排索引, 实现对文档的检索. 将基于平衡二叉树的关键词-主题索引和主题-文档倒排索引作为安全二级索引, 与加密文档一起外包给云服务器. 当使用多关键词构造陷门来检索k个最相关的文档时, 授权用户使用QueryTd 算法构造待检索关键词陷门, 将其发送给云服务器, 云服务器根据令牌进行二级索引检索, 返回关联度最高的加密文档作为检索结果, 授权用户使用密钥解密从而得到最终的明文文档. 因为主题向量的维数远小于现有方案中的关键词字典(TF-IDF 向量的维数), 所以该方案在搜索时间和索引空间开销方面均优于现有方案.
具体而言, 本文提出了一种基于BTM 主题模型的高效密文检索方案, 实现了以下功能:
(1) 使用BTM 主题模型对原始数据进行预处理, 完成数据清洗、文本特征提取、主题个数选取、概率分布提取等一系列操作, 为进一步构建文档的主题向量索引、关键词向量索引和查询陷门奠定了基础.
(2) 通过构建安全二级索引实现了根据多关键词高效检索密文文档这一过程. 其中一级索引的作用是通过多关键词确定检索文档的主题, 它是根据所提取主题中关键词的概率分布, 构建出的一棵规模较小的平衡二叉树索引; 二级索引的作用是根据一级索引所确定的主题来找到需要返回的密文文档集, 它是根据各个文档的主题概率分布, 构建出的一个倒排索引表.
(3) 构建的安全二级索引在一定程度上隔离开关键词和文档标识符, 从而降低第三方通过统计攻击来泄露用户隐私的概率. 本文根据已知密文攻击模型和已知背景知识攻击模型进行了安全性分析.
(4) 将本方案在真实的数据集上进行测试, 对查询结果的语义准确率进行了实验对比, 实验结果表明,本文方案在检索准确率和效率上都是最优的.
本文的组织结构如下: 第2 节介绍一些关于可搜索加密和主题模型的相关工作; 第3 节进行问题描述,并提出安全需求; 第4 节是符号描述和相关定义; 第5 节阐述整个系统的实现, 并进行安全性分析; 第6 节通过具体的实验对本方案进行准确率和效率评估; 最后第7 节总结本文.
2 相关工作
关键词密文检索方案. 早在1996 年, Goldreich 等人[23]提出不经意随机访问(oblivious RAM,ORAM) 模型实现软件保护, 因为该模型能够隐藏数据的访问模式, 可以实现极安全的可搜索加密方案,但是因为计算和通信开销过大而不太实用. 2000 年, Song 等人[1]首次提出可实际应用的可搜索加密方案, 这是一种线性扫描方案, 每次必须对整个文件集合进行检索. 2003 年, Goh[9]基于布隆过滤器和伪随机函数, 构造了可抵抗关键词语义攻击的安全索引, 但是当原始文档很大时, 检索效率较差. 2006 年,Curtmola[3]等人首次提出了两个基于倒排索引的关键词检索方案, 此后研究者们提出了大量基于倒排索引的对称可搜索加密方案.
2010 年, Wang 等人[10]提出基于保序对称加密算法(OPSE) 的支持结果排序的关键词检索方案.2011 年, Cao 等人[13]首次提出基于多关键词的可排序密文检索方案(multi-keyword ranked searchable encryption, MRSE). 2012 年, Wang 等人[8]又通过计算文档和检索关键词之间的相关性得分, 实现了top-k检索. 2017 年, Liu 等人[11]结合TF-IDF 模型, 提出了动态的可搜索对称加密方案实现多数据源关键词检索, 但是这一方案不能保证云服务器是诚实的. 为了丰富检索谓词, 2018 年, Zhang 等人[12]提出了多属性关键词联合密文检索技术, 他们构造了一个基于多属性树的索引结构, 但是共享密钥与双线性映射使得检索的通信开销很大. 2020 年, Li 等人[15]提出一个基于区块链的加密数据多关键词相似搜索方案, 该方案采用传统的二叉树索引来提高检索效率, 可以避免用户担心的恶意服务器的潜在错误行为.近些年, 很多对称可搜索加密方案[11,12,14,15]都是改进MRSE 方案, 或者通过直接建立树型索引来提高检索效率, 但是树的规模太大会极大地增加内存I/O 次数, 使得检索效率降低, 因此需要进一步探索减小索引规模并提高检索效率的方案.
基于语义相似度的密文检索方案. 2014 年, Xia 等人[24]和Fu 等人[25]都借助同义词扩展来实现多关键词可搜索加密. 2016 年, Chen 等人[26]利用层次聚类实现了多语义密文检索, 但是构建聚类索引的准确度不高, 计算开销和成本都很大. 2018 年, Fu 等人[27]应用各种不同的语义模型, 但是他们采用监督学习模型, 无法适应于多种数据集, 并且标签数据可能超过字典规模. 2019 年, Dai 等人[14]通过构建完全二叉树的方式实现了安全的语义感知密文检索, 但是构建的二叉树规模仍然比较大.
主题模型的研究现状. 1990 年, Deerwester 等人[20]最早提出潜在语义分析(latent semantic analysis, LSA) 主题模型, 此后, 主题模型得到广泛关注. 2000 年, Papadimitriou 等人[28]在此基础上提出了概率潜在语义分析(probabilistic LSA, PLSA), 并比较了PLSA 和LSA 的不同之处, 并讨论了PLSA在自动文档索引中的应用. 同年, Bellegarda 等人[29]提出将LSA 使用在自然语言处理中(NLP) 中.2003 年, Blei 等人[21]针对PLSA 具有严重过拟合的问题, 他们结合贝叶斯思想提出了潜在狄利克雷分配(latent Dirichlet allocation, LDA) 模型, 该模型在很多研究工作中得到应用. 例如, Heinrich 等人[30]基于LDA 提出一种高效的文本分析方法; Pang 等人[31]利用LDA 主题模型构建了一种针对企业文本搜索的主体意图混淆方法.
2005 年, 为了克服标准LDA 模型不能建模各个主题的关系的缺陷, Blei 等人[32]提出了相关主题模型(correlated topic model,CTM),CTM 模型可以描述主题间的相关性. 2006 年,Blei 等人[33]采用高斯分布对同一个主题的词分布进行规范化而提出动态主题模型(dynamic topic models, DTM), 与LDA 模型不同, DTM 引入时间因素, 从而刻画语料库主题随时间的动态演化. 2007 年, 为了描述多个主题间的相关性, Li[34]提出PAM (pachinko allocation model) 主题模型, 它使用一种有向无环图(directed acyclic graph, DAG) 结构去学习和表现主题相关性, 每个主题是基于它的孩子节点的狄利克雷分布, PAM 模型可以灵活地表现主题间的相关性, 具有更好的文本表现力. 2013 年, Yan 等人[22]为了解决已有主题模型在处理短文本时会因为文本中的词汇过于稀疏, 导致模型效果很差的缺陷, 提出了Biterm 主题模型(biterm topic model, BTM). 在短文本上BTM 的效果要比LDA 好, 即使是长文本, BTM 的效果也不比LDA 差.
随着主题模型研究的不断成熟, 许多学者开始将其应用于搜索领域. 2014 年, Wang 等人[35]提出了一个在关键词检索系统中掩盖主题意图的模型, 他们通过隐藏用户搜索关键词的主题意图来保护用户隐私,利用LDA 主题模型生成主题,构造一种新的虚拟查询生成算法实现了主体意图混淆. 2016 年,Moody等人[36]提出了将主题模型向量化的LDA2Vec, 它将Word2Vec 和LDA 的优点相结合, 利用深度学习的方法形成了一个新的算法用于文本挖掘和信息检索, 并取得了很好的效果.
2019 年, Dai 等人[14]首次将主题模型应用于密文检索, 他们利用LDA 模型建立关键词与文档之间的联系, 通过建立二叉树索引的方式实现了一个安全有效的密文检索系统. 由于大部分方案都是基于LDA 主题模型, 只适用于长文本数据集, 为了让主题模型在密文检索上的应用场景更加广阔, 我们采用BTM 主题模型在密文数据集上实现了一个基于文本语义的多关键词密文检索方案. 具有以下几方面优势:
(1) 方案基于无监督学习方法, 数据拥有者可以直接将其应用于不同的数据集.
(2) 方案可根据检索关键词来推断用户所要查询的文档主题.
(3) 二级索引的构建大大降低了向量维度, 提高了时间和空间效率.
3 问题描述
3.1 系统模型
系统模型包括三个实体: 数据拥有者、数据使用者和云服务器, 如图1 所示. 基于BTM 主题模型的密文检索系统主要包括七个步骤, 整个搜索过程可定义为一个七元组: BTM-MRSE=(GenKey, BuildIdxI,BuildIdxII, Encrypt, QueryTd, Search, Decrypt). 系统中每个算法的功能描述如下:
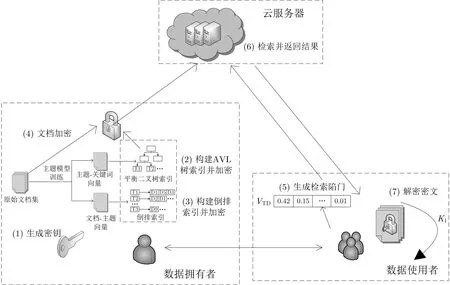
图1 系统模型Figure 1 System model
(1) GenKey: 生成密钥. 输入安全参数, 输出伪随机流作为加密文档集的密钥;
(2) BuildIdxI: 构建第一级安全索引. 通过主题模型生成主题-关键词的概率分布向量, 构造平衡二叉树索引, 并对平衡二叉树进行加密;
(3) BuildIdxII: 构建第二级安全索引. 通过主题模型生成文档-主题的概率分布向量, 构造倒排索引,并对倒排索引进行加密;
(4) Encrypt: 文档加密. 将文件拆分成固定长度的数据块, 再通过分组加密算法进行加密生成密文;
(5) QueryTd: 生成检索陷门. 数据使用者输入待检索的关键词集合和密钥集合, 生成检索陷门VTD;
(6) Search: 检索并返回结果. 云服务器收到检索陷门后, 先将它与一级平衡二叉树树安全索引进行匹配获取主题ID, 再根据主题ID 与二级倒排索引匹配获取文档索引, 最后根据文档索引返回密文集合给用户;
(7) Decrypt: 解密密文. 数据使用者收到来自云服务器返回的密文集合, 利用从数据拥有者授权获得的密钥K1将其解密.
3.2 设计目标
提出的方案需要实现的功能和满足的安全需求有:
(1) 构建安全二级索引. 数据拥有者利用主题模型生成的平衡二叉树索引和倒排索引组成的二级索引, 与加密文档存储在云服务器中供用户查询使用. 为了防止非法访问, 索引也必须以加密的形式存储;
(2) 云端数据的安全性. 数据拥有者先要生成对称密钥, 对原始文档数据进行加密后, 再发送到第三方云服务器存储, 保障数据的安全性;
(3) 陷门安全性. 数据拥有者向数据使用者发放加密检索陷门以授权数据使用者检索加密的索引与数据, 在此过程中需要保护检索陷门的安全性, 同时也要保护检索陷门不向服务器泄露索引和数据的任何信息.
3.3 安全模型
本方案中的云服务器被认为是“半诚实但好奇的”, 它会正确地执行收到的查询请求, 但对于查询信息和密文信息充满好奇, 想要获取用户文档的内容. 根据云服务器掌握的信息, 主要有以下两种安全模型[13]:
(1) 已知密文模型. 敌手知道用户存储的密文信息, 包括加密后的文档集合、密文索引以及陷门, 但并不知道密钥. 敌手只能依据这些信息来进行已知密文攻击;
(2) 己知背景信息模型. 云服务器不仅能够得到已知密文模型中可以得到的全部信息, 还具有记录查询结果、分析不同的陷门之间关系、数据统计分析等能力. 例如云服务器可以利用词频信息, 即包含关键词的文档数, 得到文档集合中每一个关键词的频率分布信息, 并进一步进行关键词攻击.
4 预备知识
4.1 符号定义
表1 为本文所用符号定义.
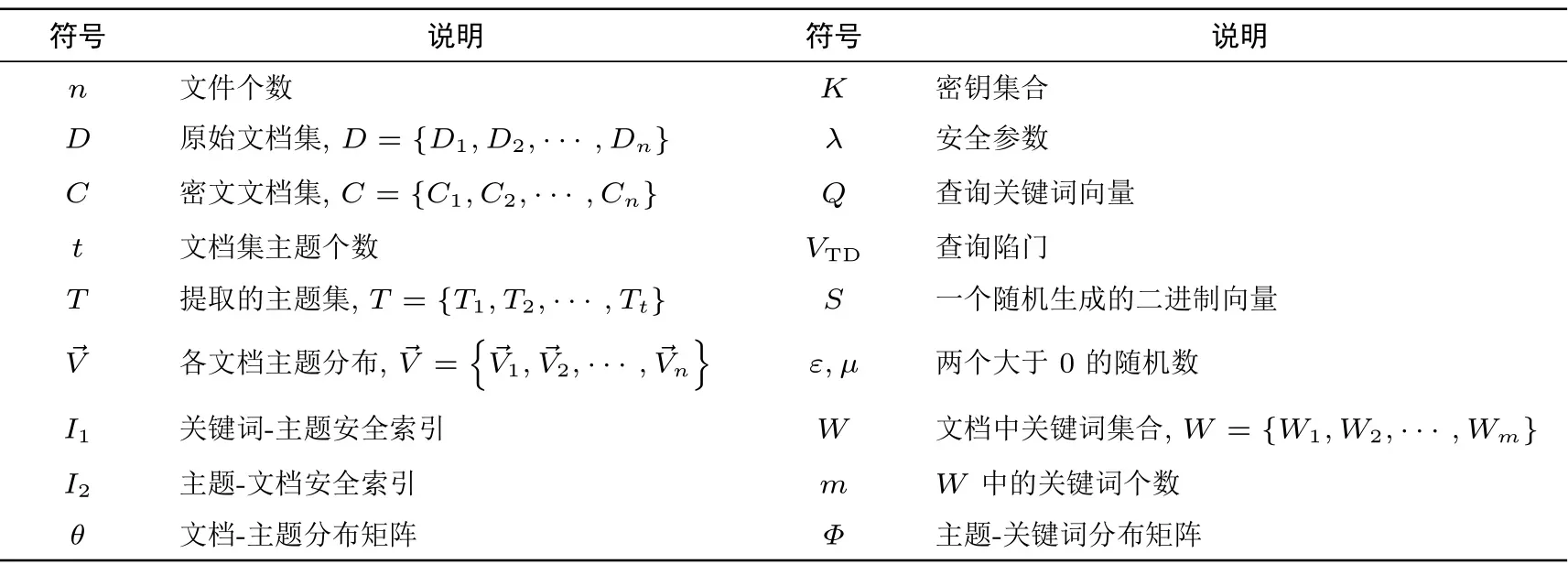
表1 符号定义Table 1 Symbol definition
4.2 BTM 主题模型
在过去的密文检索方案中, 判断文本之间的相似程度往往只是依赖于相同关键词出现的频率, 但是这种方法忽略了内在语义关联, 这将使得原本两个相似的文档因为没有相似的关键词而造成判断错误. 本文通过BTM 主题模型来解决这个问题, 其中概率图生成模型和Gibbs 采样算法是BTM 主题模型的主要理论基础, 下文我们将对此进行概述.
4.2.1 概率图生成模型
BTM 模型[22]是一种无监督统计学习模型, 它改进了LDA 主题模型, 共分为3 层贝叶斯概率生成模型, 如图2 所示. 三层概率生成模型分别为: 最外层的文本语料层、中间的文档层和里面的关键词层. 该模型主要通过对两个变量α和β进行参数学习来获取文本集的主题信息. 其中t为主题个数,N和M分别表示一篇文档中的关键词集和整个文档集,θ和Φ分别表示文档下的主题分布和主题下的词分布,α和β分别是它们的狄利克雷先验参数,Z为一篇文档的主题分布,W为关键词的向量表示.
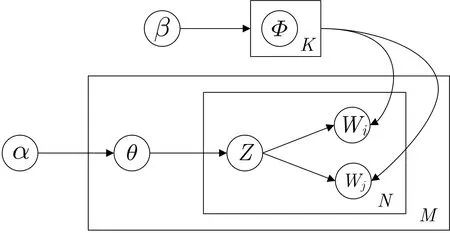
图2 概率图生成模型Figure 2 Probability graph generation model
整个模型的构建还需要用到如下两个分布, 一个是狄利克雷分布, 它是Beta 分布在M维度上的扩展情形, 是一个连续分布, 该分布的概率密度函数如公式(1)所示, 其中Γ(x) 表示伽马函数.
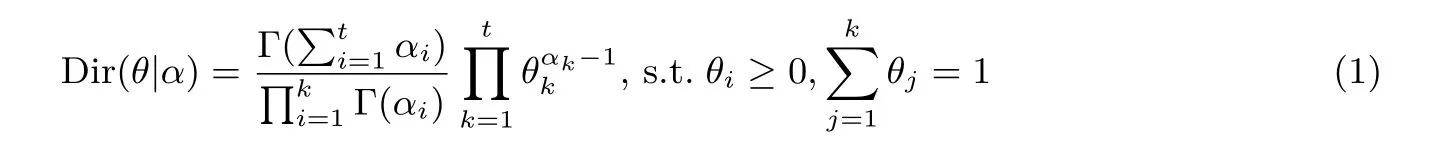
另一个是多项分布, 它是二项分布在N维度上的扩展情形, 是一个离散分布, 与狄利克雷分布组成了共轭分布, 其分布律如公式(2)所示, 其中pk表示第k个主题的概率.
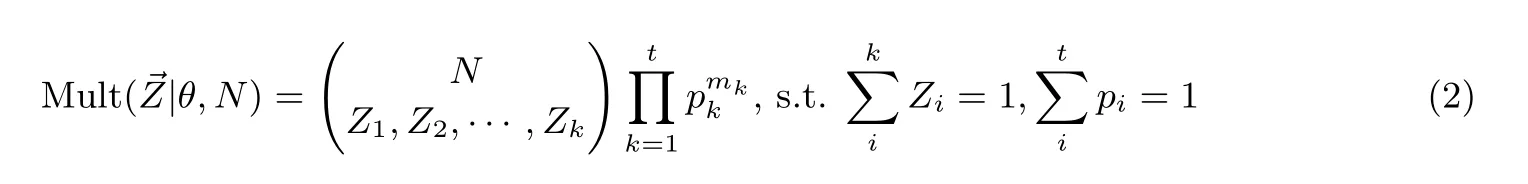
通过对所有数据的联合概率应用链式法则, 可得到主题z的条件概率如式(3)所示. 其中,b=(wi,wj)为通过多项式采样获得的一个关键词元组, 称为biterm,z-b表示除b以外的所有主题分配,N为整个biterm 集,|M| 表示整个文档集大小,nz表示b分配给主题z的次数,nw|z表示单词w分配给主题z的次数,α和β为概率图生成模型中的两个狄利克雷先验参数. 从计算出来的结果进行Gibbs 采样, 重新统计nw|znz, 直到最后Gibbs 参数收敛, 就是我们最后得到的BTM 主题模型.
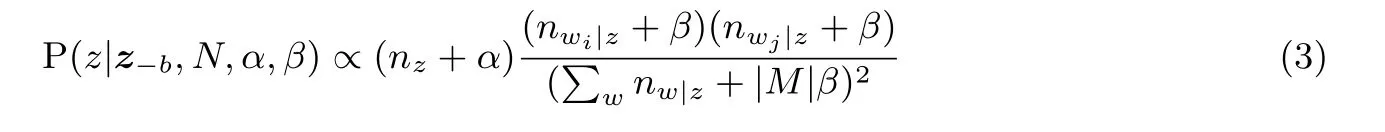
4.2.2 Gibbs 采样算法
为了对主题模型的参数θ和Φ进行学习, 我们采用马尔科夫链蒙特卡洛方法(Markov chain Monte Carlo, MCMC), 通过对词的主题采样来生成马氏链, 经过若干次的循环迭代后, 模型就会收敛, 生成两个矩阵分别为文本-主题分布矩阵θ和主题-关键词分布矩阵Φ, 矩阵中的元素值即为概率分布值, 其中每个元素值的计算如公式(4)所示. 其中t为主题个数,|N| 表示组成所有文档的关键词集大小,|M| 表示整个文档集大小,n代表采样的数量.
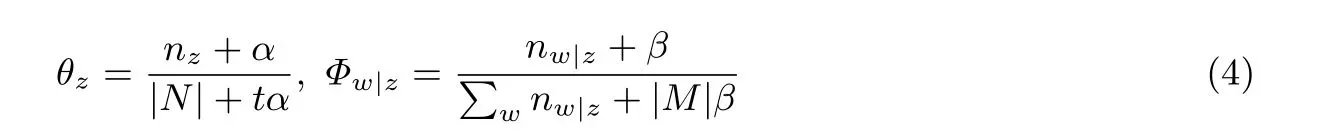
对词的主题采样过程采用了Gibbs 采样算法, 它主要有两大优势. 首先, Gibbs 采样算法是MCMC算法中的一种, 它很容易就能构造出多变量概率分布的随机样本, 尤其适合于主题模型中构造两个以上变量的联合概率分布; 其次, 由于公式(3)中后验概率P的计算很复杂且效率低下, 但是由于每个参数内部的元素是相互独立的, 因此我们可以采用这种独立采样算法来加快参数的收敛速度. Gibbs 采样算法的采样过程如算法1 所示.

算法1 GibbsSampling(t,α,β,N)→θ,Φ Input: The number of topics t, hyperparameters α,β, biterm set N Output: Multinomial parameter θ and Φ 1 for iter = 1 to Niter do 3 draw zb from P(z|z-b,N,α,β);2 for b ∈N do update nz,nwi|z and nwj|z;5 end 6 end 7 Compute the parameters θ as Eq. (4) and Φ as Eq. (5);8 Return θ and Φ;4
4.2.3 主题个数的选取
在进行BTM 主题模型构建之前, 需要对主题个数进行选取, 主题个数的选取是否精确直接决定了密文检索方案的准确度与效率. 确定语料库主题个数的方案通常采用困惑度和一致性指标[21,22], 困惑度越低, 表明文本主题分类越清晰; 一致性越高, 表明某些频率高的关键词越集中于同一主题. 困惑度的计算公式如公式(5)所示. 其中,D为语料库文档集合,M为文档集合的大小,Nd为每篇文档的关键词总数,p(wd) 表示文档中的关键词wd出现的总频率.
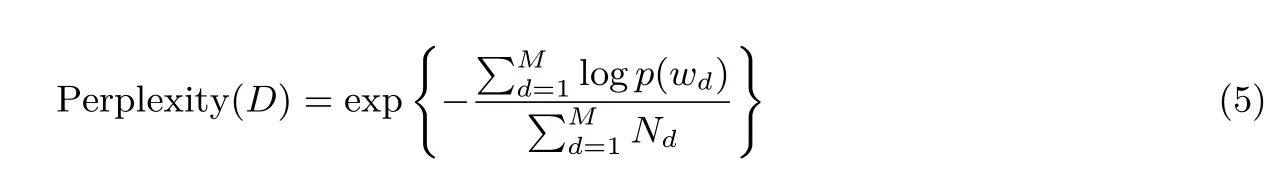
一致性指的是对于给定的主题T,计算出现概率最高的前m个关键词集,即wT={w1,w2,··· ,wm}.一致性的计算公式如公式(6)所示. 其中,t为主题个数,P(wTij) 为第i个主题中, 出现频率为第j高的关键词的概率值.
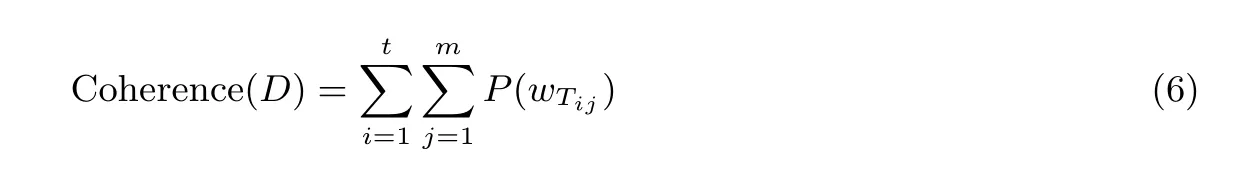
4.3 索引方案
4.3.1 倒排索引的建立
倒排索引实现了由关键词到文档的映射, 用户只要对关键词表进行检索, 就能找到包含该关键词的所有文档. 本方案根据倒排索引的思想建立主题-文档的倒排索引表, 即可根据主题来检索符合该主题的所有文档, 如图3 所示. 其中节点表示的是各个主题的标识符, 分别指向一组文档标识符列表, 并且每个文档根据其主题概率分布的数值从大到小排列, 从而控制返回最相关文档的个数. 索引建立的具体步骤见算法2.
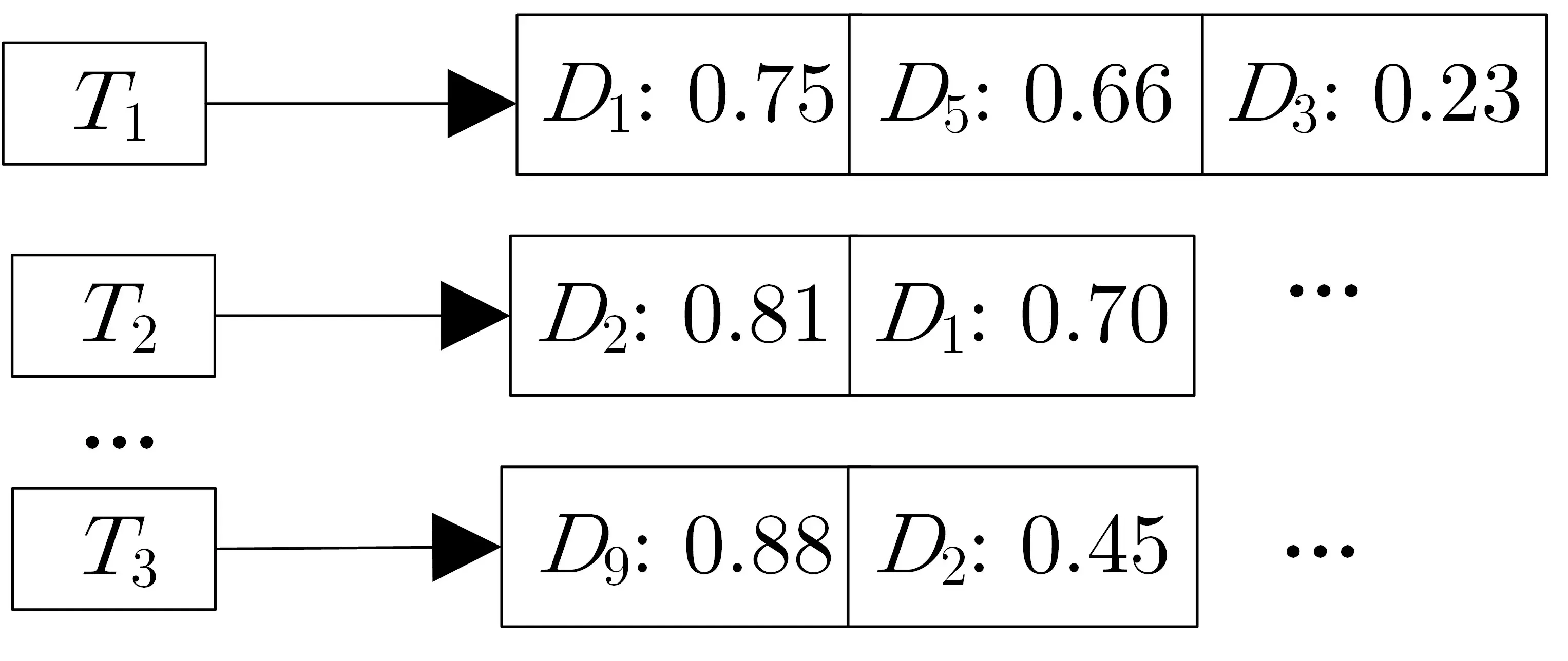
图3 倒排索引表Figure 3 Inverted index table

算法2 BuildInvertedIndex(→V,t)→I Input: Document-topic probability distribution vector →V, the number of topics t Output: An inverted index I 1 Traverse →Vi of →V = {→V1,→V2,··· ,→Vn}. →Vi = {Tj : Pj,···} represents the topic probability distribution of the ith document, where Pj is the probability that the ith document belongs to the jth topic. Once a new topic j appears, it creates a new list listj and insert (i, Pj) into listj ;2 Traverse the constructed inverted list, and sort each list according to the probability value of the nodes from largest to smallest ;3 Return I;
4.3.2 平衡二叉树索引的建立
平衡二叉树索引如图4 所示, 将主题模型生成的t个主题作为平衡二叉树的叶子节点, 节点的数值为关键词的概率分布向量, 即每个关键词在该主题下出现的概率; 父节点存储左右孩子节点所对应关键词概率的最大值. 索引建立的具体步骤见算法3.

图4 树型索引Figure 4 Tree index

算法3 BuildAVLIndex(T,W)→I Input: Topic-keyword probability distribution T, keywords collection W Output: A balanced binary tree index I 1 Construct t nodes corresponding to t topics as leaves. Each leaf stores a topic ID id and an array dataab.The size of the array is m, and the value is the vector T[i] (the probability distribution of all keywords corresponding to the ith topic). a and b represents the bth node in the ath layer ;2 Combine leaves in pairs to construct an AVLtree index from bottom to top ;3 The non-leaf node Rab stores the bigger dataab. When two nodes compose a new AVL tree, the values of dataab of the two child nodes are compared one by one, and the bigger one is kept in the corresponding position of the parent node’s dataab ;4 Return I;
4.4 安全KNN 技术
在密文检索的过程中, 为了防止两个向量相乘的结果泄露给第三方, 往往使用安全KNN 技术[7]中安全内积的方法来达到保护隐私的目的. 这一技术常被用来计算内积相似度[13], 具体加密过程如下所述.

5 基于BTM 的密文检索方案
5.1 算法描述
我们提出的基于BTM 的密文检索方案BTM-MRSE 包括七个算法: (GenKey, BuildIdxI, BuildIdxII, Encrypt, QueryTd, Search, Decrypt), 其中四个算法(GenKey, BuildIdxI, BuildIdxII, Encrypt)由数据拥有者负责执行, QueryTd 和Decrypt 由获得检索许可的用户执行, Search 操作由云服务器执行,具体步骤及主要算法描述如下.
5.1.1 Genkey(1λ)→K
首先由数据拥有者进行系统初始化, 生成系统密钥, 算法描述见算法4. 算法中λ是需要输入的系统安全参数, 输出K= (K1,K2,M1,M2,S). 第2 行获取两个密钥K1和K2,K1是用来加密明文数据的对称密钥,K2是用来加密二级索引的对称密钥; 第9 行获取M1和M2, 它们都是m×m维的可逆矩阵;第14 行生成S, 它是一个随机生成的m维向量, 它们对索引结点向量和查询向量进行加密; 第16 行获得最终的K.P(·) 是一个伪随机函数(pseudo-tandom gunction, PRF), 这里需要三个不同的随机密钥κ1,κ2,κ3, 其定义见公式(8), 其中k是随机密钥的长度,l是安全参数的长度.
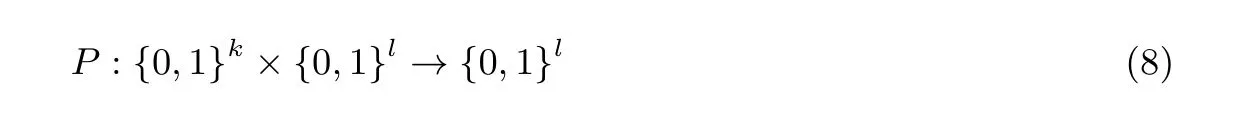

算法4 GenKey(1λ)→K Input: Secure parameter λ Output: K = {K1,K2,M1,M2,S}1 for i = 1,2 do 2 Ki ←Pκ1(λ);3 end 4 rowNum ←m, colNum ←m;5 for k = 1,2 do 6 for i = 1 : rowNum do 7 for j = 1 : colNum do 8 Mk[i][j] ←Pκ2(λ);end 10 end 11 end 12 for i = 1 : m do 9 13 Si ←Pκ3(λ);14 end 15 K ←{K1,K2,M1,M2,S};16 Return K;
5.1.2 BuildIdxI(D,M1,M2,S,ε)→I1
如算法5 所示, 建立索引前需利用BTM 模型进行文档主题提取. 第4 行采用算法1 进行采样, 其中两个超参数α和β为提前设定的默认参数; 第10 行从训练好的主题-关键词矩阵中提取主题-关键词的概率分布, 然后根据算法3 构建关键词-主题平衡二叉树索引. 最后利用输入的m+ε维随机二进制向量S对每个节点的关键词概率分布向量进行混淆, 其中第14 行将Ii拆分成两个随机数相加, 第21 行利用密钥M1和M2对索引中的每个节点利用安全KNN 技术加密, 输出安全索引I1. 其中maxTopicNum 表示的是文档集主题个数的最大估计值, 本文实验为15.

算法5 BuildIdxI(D,M1,M2,S,ε)→I1 Input: The set of all documents D, two matrices M1,M2, an (m+ε) vector S,an integer ε >0 Output: AVL secure index I1 1 for t = 1 : maxTopicNum do 2 for Di ∈D do 3 for N ∈Di do 4 Φt,θt ←GibbsSampling(t,α,β,N);5 Calculate Perplexityt and Coherencet using the calculation method of Sec. 4.2;end 7 end 8 end 9 Choose the best number of topics t according to Perplexityt and Coherencet;10 Obtain the best Φ,θ based on t, T ←Φ, I ←BuildAVLIndex(T,W);11 Extend all vectors in I to (m+ε)-dimension, that is, the last ε numbers of each vector is random;12 for i = 1 : m+ε do 6 13 if Si = 1 then 14 (I′i,I′′i ) ←Ii;15 end 16 else Si = 0 i = I′′i ;18 end 19 end 20 →I ←(I′,I′′);21 I1 ←SecureKNN(→I,M1,M2);22 Return I1;17 Ii = I′
5.1.3 BuildIdxII(D,K2)→I2
该算法利用BTM 模型生成文档-主题概率分布, 构建主题-文档倒排索引; 然后利用密钥K2进行加密, 生成主题-文档安全索引I2. 构建安全索引I2的过程如算法6 所示, 其中第2 行表示从训练得到的文档-主题矩阵中获取第i篇文档的主题概率分布向量, 第4 行见算法2.

算法6 BuildIdxII(T,θ,K2)→I2 Input: The topic-keyword vector T, the document-topic matrix θ, the key K2 Output: Topic-document secure index I2 1 for i = 1 : n do 2 →V[i] ←θ[i];3 end 4 I ←BuildInvertedIndex(→V,|T|) ;5 Encrypt index I using AES with K2 to get encrypted index I2 ;6 Return I2 ;
5.1.4 Encrypt(K1,D)→C
该算法输入密钥K1和明文文档集D={D1,D2,··· ,Dn}, 使用密钥K1对D进行加密, 得到密文文档集C={C1,C2,··· ,Cn}.
5.1.5 QueryTd(Q,M1,M2,S,ε)→VTD
数据使用者利用m维向量S对查询关键词向量Q进行混淆, 第4 行表示将Qi拆分成两个随机数相加, 第11 行利用安全KNN 技术采用密钥M1和M2进行加密, 最后生成检索陷门VTD, 具体过程如算法7 所示.

算法7 QueryTd(Q,M1,M2,S,ε)→VTD Input: Query vector Q, two matrices M1,M2, an (m+ε) vector S, an integer ε >0 Output: Query trapdoor VTD 1 Extend Q to (m+ε)-dimension, that is, the last ε numbers of each vector is random;2 for i = 1 : m+ε do 3 if Si = 1 then(Q′i,Q′′i) ←Qi ;5 end 6 else Si = 0 4 Qi = Q′i = Q′′i ;8 end 9 end 10 →Q ←(Q′,Q′′)11 VTD ←SecureKNN(→Q,M1,M2)12 Return VTD;7
5.1.6 Search(C,I1,I2,VTD,topK)→C′
该算法由云服务器将检索陷门依次与安全索引进行匹配, 并将配对的密文集合返回给数据用户. 密文检索的具体过程如算法8 所示. 其中第9 行从检索到的节点中获取主题id, 第10 行在安全倒排索引中根据主题id 获得文档索引向量, 第11–13 行获取前K个最相关的加密文档. 因为平衡二叉树的每个节点都是一个表示主题-关键词概率分布的向量, 而且父节点中元素取两个子节点中最大值, 当将查询陷门与树节点的向量执行安全内积运算时就可以得到概率最大的节点, 表明与查询向量更相近.

算法8 Search(C,I1,I2,VTD,topK)→C′Input: Ciphertext collection C, secure Index I1,I2, query trapdoor VTD, the number of required documents topK Output: The retrieved ciphertext collection C′1 Initialize the Root node of I1 as Node;2 while Node.lchild is not NULL do Node ←Node.lchild;7 end 8 end 9 id ←Node.id;10 →ID ←I2[id];11 for i = 1 : topK do 3 leftScore ←Node.lchild×VTD;4 rightScore ←Node.rchild×VTD;5 if leftScore ≥rightScore then 6 12 C′[i] ←C[→ID[i]];13 end 14 Return C′;
5.1.7 Decrypt(C′,K1)→D′
数据用户收到由云服务器返回的密文集合C′后, 用密钥K1进行解密, 得到最后所需的明文数据D′.
5.2 安全性分析
在本方案中, 云服务器被认为是“诚实但好奇” 的, 即云服务器诚实并正确地执行协议中的操作, 但是对操作过程中的敏感数据感到好奇. 根据云服务器可获取的信息, 本文采用Cao 等人[13]提出的两种威胁模型: 已知密文模型与已知背景模型.
定理1 提出的方案满足已知密文模型下的安全性.
证明: 在已知密文模型中, 敌手不能根据密文文档、加密索引和查询陷门推断明文的信息. 在此方案中, 云服务器仅知道加密文档集C, 加密的安全索引I1、I2和查询陷门VTD. 因此, 云服务器可以在此模型中进行唯密文攻击(COA)[37].
由于采用密钥K1对文档集D进行对称加密, 并且密钥只能在数据拥有者和数据用户之间共享, 同时密文C不受云服务器保护, 概率多项式时间(PPT) 的敌手不能以超过1/2 的概率区分一个文件的密文C是由明文A或者B加密得到的.
敌手可以对查询陷门进行统计攻击, 从统计信息中获取查询关键词对文档的重要程度. 但是, 由于本方案中查询向量的维度扩展到了(m+ε), 并且对VTD[m+j],0≤j <ε中的任意μ个位置设为0, 两个随机参数ε和μ使得相同的关键词的查询陷门和搜索的结果都不同, 最后查询向量VTD与树索引的第a层第b个向量Vab在不断乘积之后所得相关度分数的分布也会不同. 使用陷门对索引中每个节点计算评分的结果如下, 其中每次查询的∑ηv是随机的, 具有不可预测性:
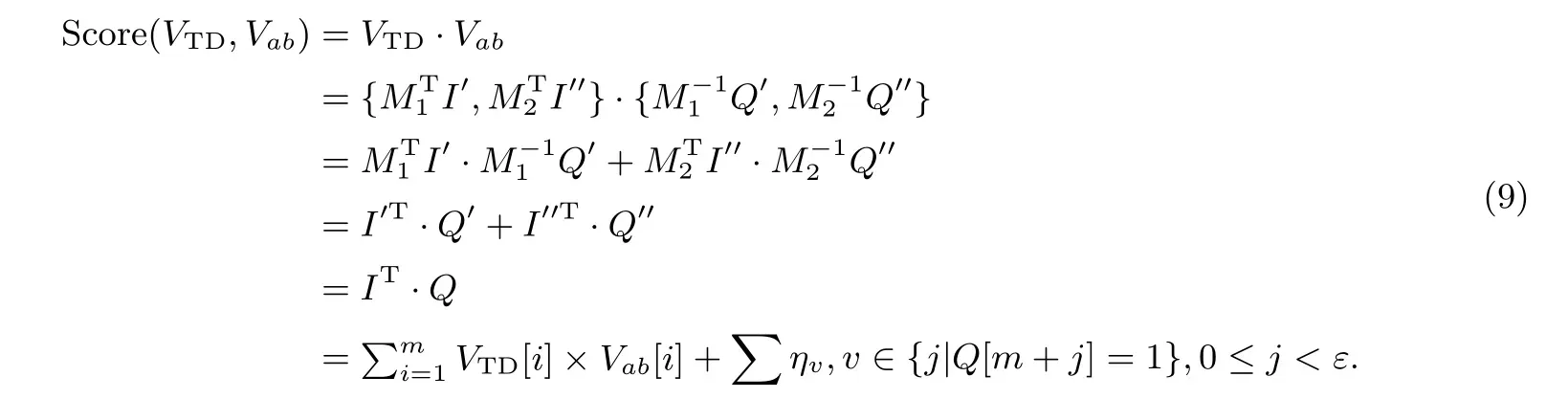
因此, 文档的隐私是得到保护的, 并且满足选择密文安全性(IND-CCA) 安全.
定理2 提出的方案满足已知背景模型下的安全性.
证明: 在已知背景模型中,假设云服务器可以获取更多知识: 任意两个查询操作是否包含相同的关键词, 以及每次查询的结果. 通过统计这些信息来揭示文本关键词的分布和文档中特定关键字的频率(TF),利用这些知识, 云服务器可以进行统计攻击[37], 进而分析出相应频率分布的直方图或值范围来推断(甚至直接识别出) 某些关键词[8,19].
假设S是一个模拟器,A为攻击者,B为挑战者. RealA(k) 表示的过程为:
(1)B输入一个安全参数k, 通过加密算法生成密钥K;
(2)A输入(I,D), 通过B获取(I,C),A选择q ∈{wi,I,D};
(3) 当执行查询请求时,q=wi, 攻击者从挑战者处获取查询令牌;
(4) 当执行更新操作时,q= (I,D), 攻击者首先生成辅助信息并将其发送给挑战者, 挑战者生成更新操作令牌并返回, 最后攻击者输出值b.
IdealA,S(k) 表示S模拟安全索引和密文集合, 并将其发送给A的过程:
(1) 当执行查询请求时,q=wi,S获取关键词和查询的结果;
(2) 当执行更新请求时,q= (I,D),S提供自适应查询中出现的所有关键词的更新输出, 攻击者还需向S发送辅助信息,S返回更新操作陷门, 最后攻击者输出值b.
对于任意攻击者A, 如果都存在满足如下公式的模拟器, 那么就可以认为该方案是安全的, 能够抵抗自适应选择关键词攻击. 其中,k是安全参数, negl(k) 表示概率可忽略.
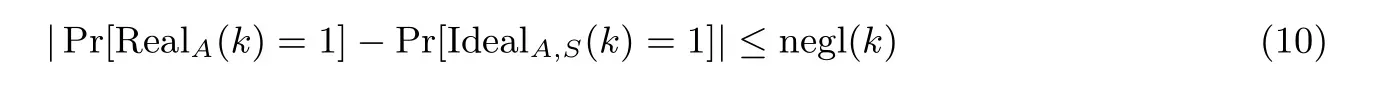
通过给定任意一个攻击者A和状态模拟器S, 模拟IdealA,S(k) 的过程,S按照5.1 节中所描述的算法构造安全索引和密文集合. 根据密钥的CPA 安全性, 由于对称密钥是通过伪随机函数生成, 与真实密钥无法进行区分, 因此模拟的文档加密过程相比于实际加密过程具有不可区分性, 并且S返回的结果和A通过随机预言机返回的结果相等, 因此对于任意的攻击者, RealA(k) 和IdealA,S(k) 的概率是能够被忽略不计的, 所以该方案满足适用性选择关键字攻击安全性(CKA2). 因此所提方案满足已知背景模型下的安全性.
6 实验评估
为了评估所提方案的查询效率和性能, 通过控制变量的方法进行实验, 并将本方案(BTM-MRSE) 与基于LDA 的多关键词可搜索加密方案(LDA-MRSE)[14]以及基于TF-IDF 的多关键词可搜索加密方案(TFIDF-MRSE)[19]进行对比. 实验环境为一台CPU 型号为Intel(R) Core(TM) i5-4590 3.30 GHz, 16 GB 内存的PC, 所有操作都在Jupyter Notebook 开发环境下完成, 使用Python 语言实现, 包括最后对实验数据的图表制作. 实验使用的数据集是清华大学THUCNews 新闻文本分类数据集的子集, 各个文档的长短不一, 语言为中文, 选取了其中10 种领域的文本作为实验数据, 每个领域6500 篇文本. 进行主题模型训练的训练集共有50 000 篇文本, 验证集共有5000 篇文本, 测试集共有10 000 篇文本.
6.1 主题个数的选取
根据4.2 节中主题个数的选取方法, 本文选取主题数量从1–15 个进行实验, 实验的效果如图5 所示,从t= 5 开始, 困惑度开始降低, 但是有可能是由于模型主题选取过多导致了过拟合, 因此要结合一致性进行判断. 由一致性可知当t= 9 时, 模型的一致性最高, 因此设定主题个数t为9 个作为本方案的主题模型训练参数.
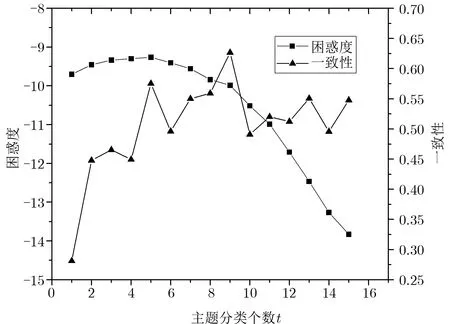
图5 困惑度和一致性相关分数Figure 5 Perplexity and coherence related scores
6.2 检索准确率
6.2.1 检索准确率比较
为了描述本文方案的检索准确率, 假设用户每次构造的查询陷门的所有关键词都属于同一类别, 并且不同类别的文档是没有相关性的. 我们提出的方案改进了多关键词密文检索的语义准确率, 因此, 我们使用查准率P来衡量数据用户检索得到的文档的语义准确率, 其计算方法如下:

其中, TP 代表返回的文档符合用户检索主题意图的文档数量, FP 代表不符合的数量. 本文评估了BTM-MRSE、LDA-MRSE 和TFIDF-MRSE 的检索准确率, 实验结果如图6 所示(其中k为算法8 中的topK, 即返回的文档数). 由于考虑了文档语义, 基于主题模型的两个密文检索方案在检索准确率上都要明显优于TFIDF-MRSE; 随着语料库的扩大, BTM-MRSE 的语义精度虽然有所降低, 但是准确率和稳定性上依然明显优于TFIDF-MRSE; 当总文档数较少时, BTM-MRSE 与LDA-MRSE 的准确率和稳定性都很高, 但是当总文档数大于30 000 时, BTM-MRSE 的准确率更高. 当返回文档数k=50 和k=100时, BTM-MRSE 的准确率均可达到95% 以上, 并且都高于其他两个方案.
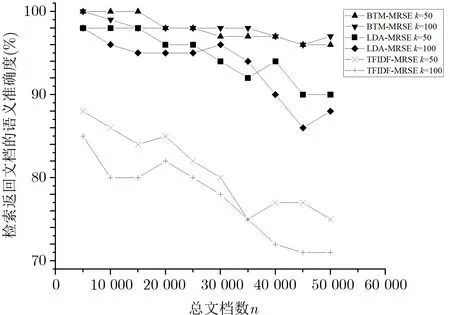
图6 语义准确率随n 变化对比图Figure 6 Semantic accuracy with different n
本方案的高准确率得益于主题模型对文档的主题分类过程, 并且随着总文档数量n的增加, BTM 主题模型相比于LDA 主题模型更能适应各类长短不一的文档, 因此BTM-MRSE 的稳定性更高, 能更好地反映文档的语义特征, 不会显著影响查询的语义精度, 这一方面体现了本方案的优越性.
6.2.2 检索准确率与扩展维度的关系
由于数据用户构建的查询向量维度就是整个关键词集合的大小m, 也是主题-关键词树状索引中节点的概率分布向量维度, 因此云服务器可以通过记录多次查询, 统计每个关键词查询的频率, 进行统计攻击.因此必须设置一个ε值, 将关键词维度m扩展到m+ε维, 即增加ε个随机数到查询向量的末尾, 混淆查询关键词以保证多次查询的无关联性. 本文在对BTM-MRSE 方案的实验过程中, 只改变ε和k的值,图7 为ε在四种取值下, 检索准确率P随k值变化的折线图.
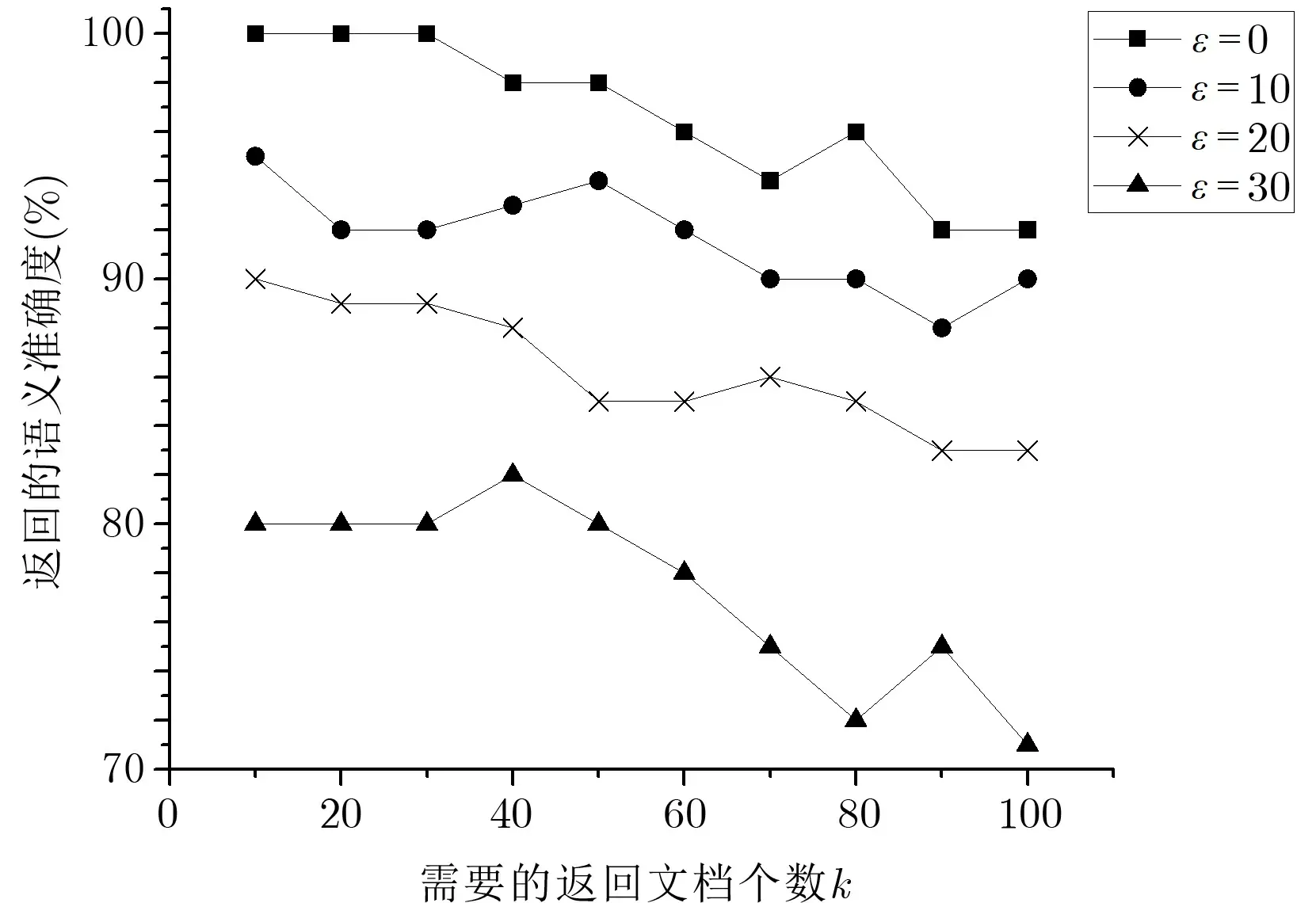
图7 不同ε 下, 语义准确率随k 变化对比图Figure 7 Comparison of semantic accuracy with different k under different ε
图7 表明: 参数k以及参数ε均对检索准确率有较大的影响. 其中随着参数ε的增加, 整体的准确率会有所降低, 但是检索的安全性会得到极大的提升, 因此对于ε值的设置, 需要对安全性和检索的准确率两方面进行权衡. 随着返回文档数k的增加, 不相关的文档数逐渐增多, 造成准确率下降, 这与使用的测试数据集关系比较密切. 如果测试数据集中满足查询条件的文档越多, 则准确率随着返回文档数k的增加不会显著降低. 当ε设置为10 或20 时, 准确率总体上较为稳定.
6.3 检索效率
密文检索效率很大程度上取决于索引构造方案, 这直接决定了索引大小、检索时间复杂度以及安全性.表2 将本文提出的基于BTM 主题模型的高效密文检索方案(BTM- MRSE) 与其他具有代表性的密文检索方案进行对比, 对比的指标包括索引类型、存储空间复杂度、检索的时间复杂度. 其中,M为文档匹配的关键词数量,m为文档集中关键词的总数,n为文档的总数,N为索引中文档标识符的数量,r为查询陷门匹配到的关键词数量,t为文档集的主题个数,σ为每个文档的主题分布个数, 一般假设t ≪n,r ≪m.
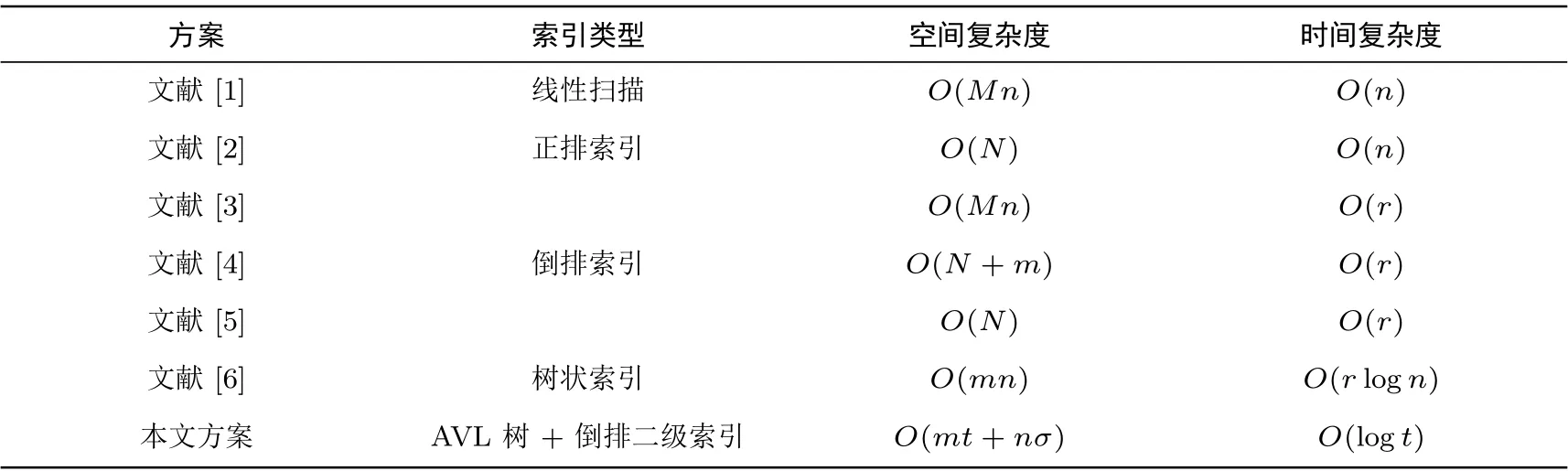
表2 方案对比Table 2 Scheme comparison
由表2 可知, 通过建立树状索引的方案的密文检索效率是最高的, 许多方案都选择以二叉树作为基本索引结构, 将文档标识符作为待检索的叶子节点, 非叶子节点存放文档的关键词信息. 然而, 当待检索文档的数量达到十万或百万数量级的时候, 树状索引的规模会变得很大, 往往需要多次磁盘I/O 时间, 一次I/O 时间通常要远远大于单次密文检索的时间, 这在很大程度上将制约密文检索的效率. 因此, 不仅需要通过建立AVL 树来降低树状索引的层数, 本方案还通过建立二级索引的方式对索引进一步进行降维处理.例如, 当AVL 树层数l为20 层时, 最多只能有52 万个文档, 本文将文档聚类为主题后, 由于主题个数t将远远小于文档数量n, 所以AVL 树的规模也将大大缩小.
7 总结
随着可搜索加密技术的发展, 仅仅使用关键词频率信息作为文档相关性度量的传统方案已无法满足用户的检索需求. 本文在保证云服务器上文档安全性的基础上, 首次将BTM 主题模型引入可搜索加密中,提出了基于BTM 主题模型的多关键词高效密文搜索方案. 本文选取了THUCNews 新闻数据集的一部分作为实验数据集, 这些文档经过主题模型的训练之后, 生成了主题-关键词矩阵和主题-文档矩阵. 我们通过引入主题模型来确定数据用户的潜在搜索意图, 解决了传统可搜索加密方案(基于词袋模型和TF-IDF模型) 中对语义的忽视. 将密文检索中的特定关键语替换为主题相关性, 实现了关键词和文档标识符存储的分离, 进一步提高了文档关键词的隐私保护, 也增强了查询关键词的隐私保护. 同时, 主题模型减小了索引节点中向量的维数, 从而提高了检索效率. 并且基于平衡二叉树的二级索引机制也进一步改善了密文检索的时间开销.
未来的工作可以对本文的模型做进一步扩展, 采用最新的ida2vec 主题模型[36]或基于深度学习的BTM 主题模型, 进一步提升密文检索的效率和查询准确率.
